- Apache Flink 教程
- Apache Flink - 首頁
- Apache Flink - 大資料平臺
- 批處理與即時處理
- Apache Flink - 簡介
- Apache Flink - 架構
- Apache Flink - 系統需求
- Apache Flink - 設定/安裝
- Apache Flink - API 概念
- Apache Flink - Table API 和 SQL
- 建立 Flink 應用
- Apache Flink - 執行 Flink 程式
- Apache Flink - 庫
- Apache Flink - 機器學習
- Apache Flink - 使用案例
- Apache Flink - Flink vs Spark vs Hadoop
- Apache Flink - 總結
- Apache Flink 資源
- Apache Flink - 快速指南
- Apache Flink - 有用資源
- Apache Flink - 討論
Apache Flink - 簡介
Apache Flink 是一個即時處理框架,可以處理流式資料。它是一個開源的流處理框架,用於構建高效能、可擴充套件和準確的即時應用程式。它具有真正的流模型,不會將輸入資料視為批處理或微批處理。
Apache Flink 由 Data Artisans 公司建立,現在由 Apache Flink 社群在 Apache 許可下進行開發。該社群目前擁有超過 479 位貢獻者和 15500 多次提交。
Apache Flink 生態系統
下圖顯示了 Apache Flink 生態系統的不同層:
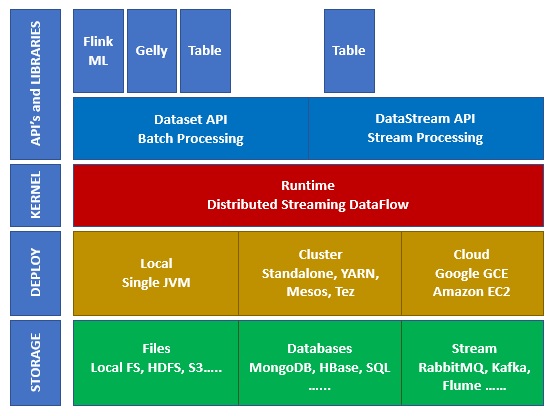
儲存
Apache Flink 可以從多個選項讀取/寫入資料。以下是基本儲存列表:
- HDFS (Hadoop 分散式檔案系統)
- 本地檔案系統
- S3
- RDBMS (MySQL、Oracle、MS SQL 等)
- MongoDB
- HBase
- Apache Kafka
- Apache Flume
部署
您可以將 Apache Flink 部署到本地模式、叢集模式或雲端。叢集模式可以是獨立模式、YARN 或 MESOS。
在雲端,Flink 可以部署到 AWS 或 GCP。
核心
這是執行時層,提供分散式處理、容錯性、可靠性、原生迭代處理能力等等。
API 和庫
這是 Apache Flink 的頂層,也是最重要的一層。它具有 Dataset API(負責批處理)和 Datastream API(負責流處理)。還有其他庫,例如 Flink ML(用於機器學習)、Gelly(用於圖處理)、Table API(用於 SQL)。這一層為 Apache Flink 提供了多樣化的功能。
廣告