- Talend 教程
- Talend - 首頁
- Talend - 簡介
- Talend - 系統要求
- Talend - 安裝
- Talend Open Studio
- Talend - 資料整合
- Talend - 模型基礎
- 資料整合元件
- Talend - 作業設計
- Talend - 元資料
- Talend - 上下文變數
- Talend - 作業管理
- Talend - 處理作業執行
- Talend - 大資料
- Hadoop 分散式檔案系統
- Talend - Map Reduce
- Talend - 使用 Pig
- Talend - Hive
- Talend 有用資源
- Talend 快速指南
- Talend - 有用資源
- Talend - 討論
Talend 快速指南
Talend - 簡介
Talend 是一個軟體整合平臺,提供資料整合、資料質量、資料管理、資料準備和大資料解決方案。擁有 Talend 知識的 ETL 專業人員非常緊缺。此外,它是唯一一個擁有所有外掛能夠輕鬆整合到大資料生態系統的 ETL 工具。
根據 Gartner 的說法,Talend 位列資料整合工具領導者象限。
Talend 提供各種商業產品,如下所示:
- Talend 資料質量
- Talend 資料整合
- Talend 資料準備
- Talend 雲
- Talend 大資料
- Talend MDM(主資料管理)平臺
- Talend 資料服務平臺
- Talend 元資料管理器
- Talend 資料織物
Talend 還提供 Open Studio,這是一個廣泛用於資料整合和大資料的開源免費工具。
Talend - 系統要求
以下是下載和使用 Talend Open Studio 的系統要求:
推薦作業系統
- Microsoft Windows 10
- Ubuntu 16.04 LTS
- Apple macOS 10.13/High Sierra
記憶體需求
- 記憶體 - 最低 4 GB,推薦 8 GB
- 儲存空間 - 30 GB
此外,你還需要一個執行中的 Hadoop 叢集(最好是 Cloudera)。
注意 - 必須安裝 Java 8 並已設定環境變數。
Talend - 安裝
要下載適用於大資料和資料整合的 Talend Open Studio,請按照以下步驟操作:
步驟 1 - 轉到頁面:https://www.talend.com/products/big-data/big-data-open-studio/ 並單擊下載按鈕。您會看到 TOS_BD_xxxxxxx.zip 檔案開始下載。
步驟 2 - 下載完成後,解壓縮 zip 檔案,它將建立一個包含所有 Talend 檔案的資料夾。
步驟 3 - 開啟 Talend 資料夾並雙擊可執行檔案:TOS_BD-win-x86_64.exe。接受使用者許可協議。

步驟 4 - 建立一個新專案並單擊“完成”。
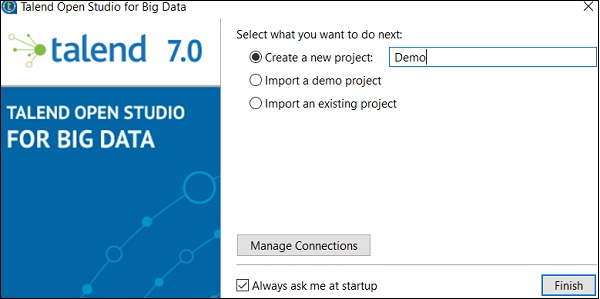
步驟 5 - 如果您收到 Windows 安全警報,請單擊“允許訪問”。
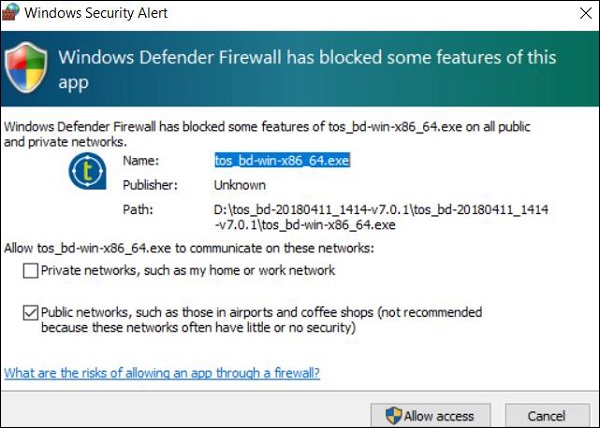
步驟 6 - 現在,將開啟 Talend Open Studio 歡迎頁面。
步驟 7 - 單擊“完成”以安裝所需的第三方庫。

步驟 8 - 接受條款並單擊“完成”。

步驟 9 - 單擊“是”。

現在,您的 Talend Open Studio 已準備好必要的庫。
Talend Open Studio
Talend Open Studio 是一款免費的開源 ETL 工具,用於資料整合和大資料。它是一個基於 Eclipse 的開發工具和作業設計器。您只需拖放元件並連線它們即可建立和執行 ETL 或 ETL 作業。該工具將自動為作業建立 Java 程式碼,您無需編寫任何程式碼。
有多種選項可以連線到資料來源,例如 RDBMS、Excel、SaaS 大資料生態系統以及 SAP、CRM、Dropbox 等應用程式和技術。
Talend Open Studio 提供的一些重要優勢如下:
提供資料整合和同步所需的所有功能,包括 900 多個元件、內建聯結器、將作業自動轉換為 Java 程式碼等等。
該工具完全免費,因此可以節省大量成本。
在過去的 12 年中,許多大型組織已採用 TOS 進行資料整合,這表明該工具具有很高的信任度。
Talend 的資料整合社群非常活躍。
Talend 不斷向這些工具新增新功能,文件結構清晰,易於理解。
Talend - 資料整合
大多陣列織從多個地方獲取資料並將其分別儲存。現在,如果組織需要進行決策,則必須從不同的來源獲取資料,將其放入統一檢視中,然後對其進行分析以獲得結果。此過程稱為資料整合。
優勢
資料整合提供了許多好處,如下所述:
改善試圖訪問組織資料的不同團隊之間的協作。
節省時間並簡化資料分析,因為資料已有效整合。
自動化的資料整合流程同步資料並簡化即時和定期報告,否則如果手動完成將非常耗時。
從多個來源整合的的資料會隨著時間的推移而成熟和改進,最終有助於提高資料質量。
使用專案
在本節中,讓我們瞭解如何處理 Talend 專案:
建立專案
雙擊 TOS Big Data 可執行檔案,將開啟如下所示的視窗。
選擇“建立新專案”選項,提及專案名稱,然後單擊“建立”。
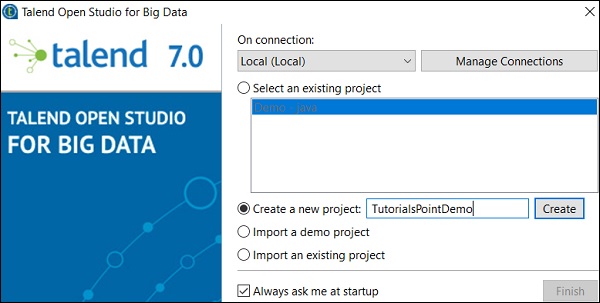
選擇您建立的專案,然後單擊“完成”。
匯入專案
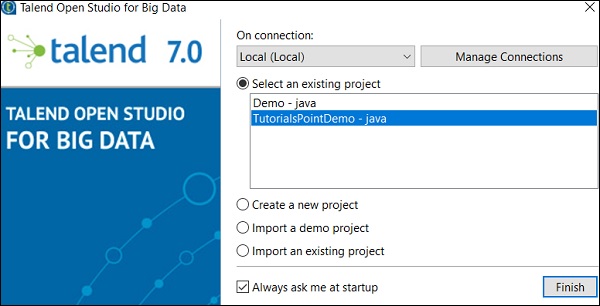
雙擊 TOS Big Data 可執行檔案,您將看到如下所示的視窗。選擇“匯入演示專案”選項,然後單擊“選擇”。
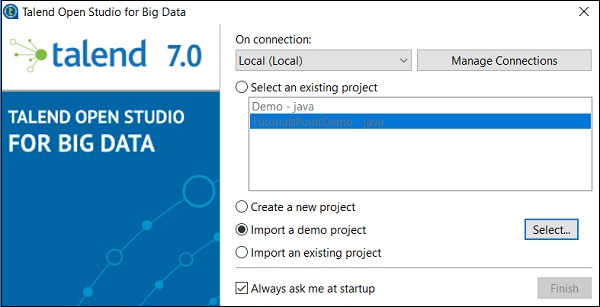
您可以從以下選項中選擇。這裡我們選擇“資料整合演示”。現在,單擊“完成”。
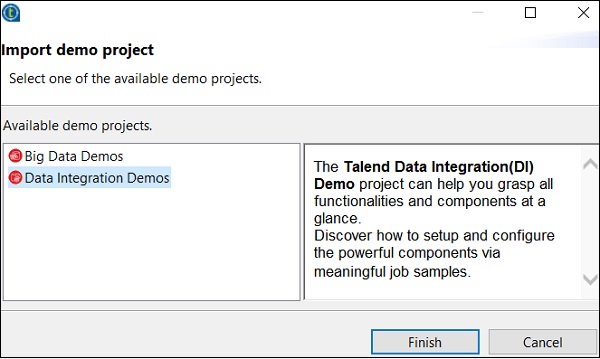
現在,輸入專案名稱和說明。單擊“完成”。
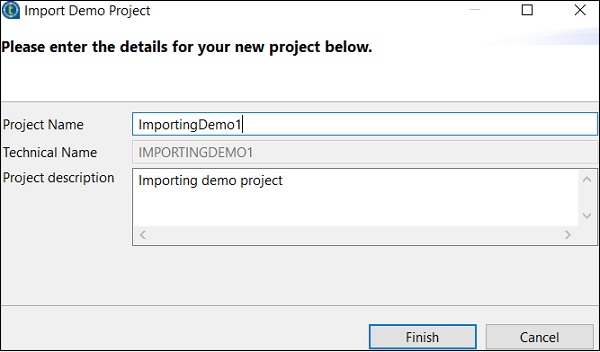
您可以在現有專案列表中看到已匯入的專案。
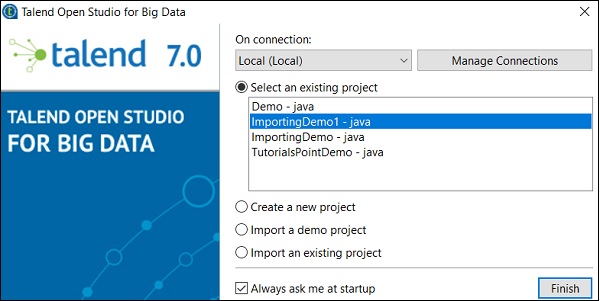
現在,讓我們瞭解如何匯入現有的 Talend 專案。
選擇“匯入現有專案”選項,然後單擊“選擇”。
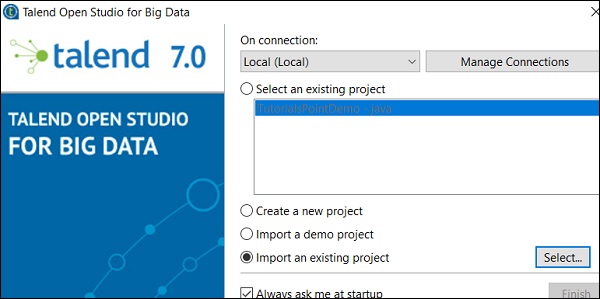
輸入專案名稱並選擇“選擇根目錄”選項。
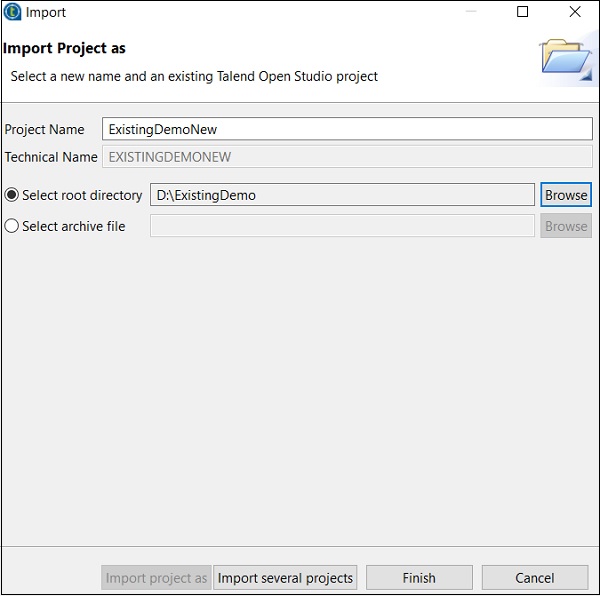
瀏覽您現有的 Talend 專案主目錄,然後單擊“完成”。
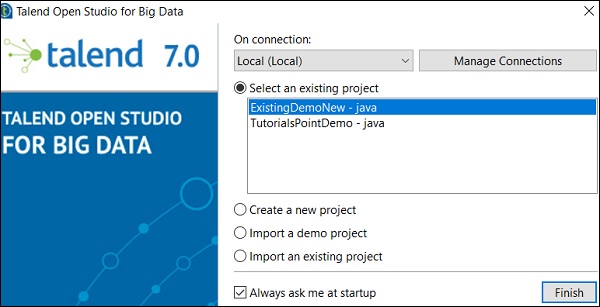
您的現有 Talend 專案將被匯入。
開啟專案
從現有專案中選擇一個專案,然後單擊“完成”。這將開啟該 Talend 專案。

刪除專案
要刪除專案,請單擊“管理連線”。
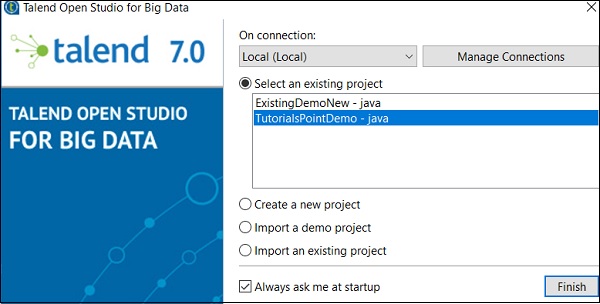
單擊“刪除現有專案”。
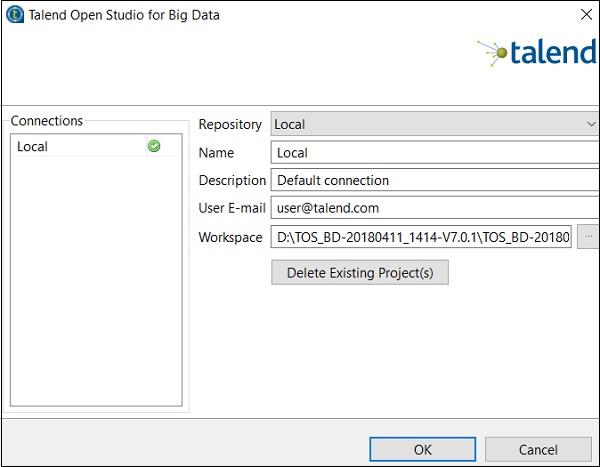
選擇要刪除的專案,然後單擊“確定”。
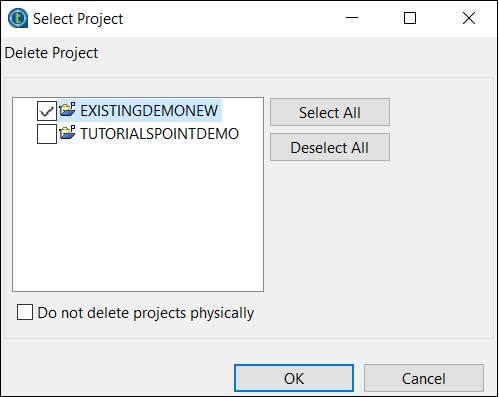
再次單擊“確定”。
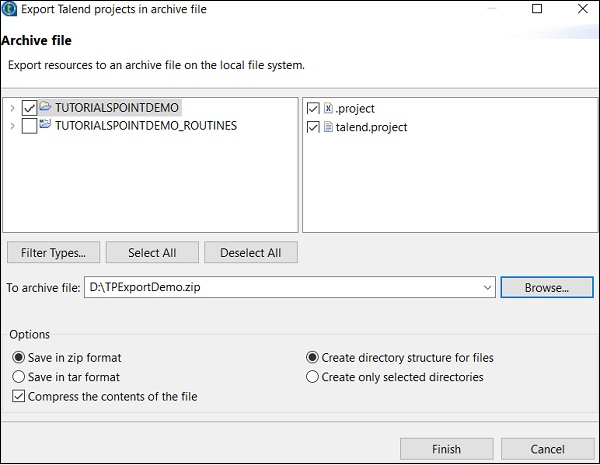
匯出專案
單擊“匯出專案”選項。
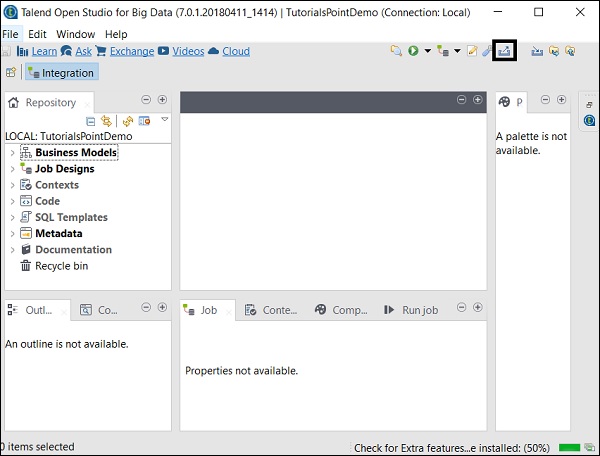
選擇要匯出的專案,並指定應將其匯出到的路徑。單擊“完成”。
Talend - 模型基礎
業務模型是資料整合專案的圖形表示。它是業務工作流程的非技術表示。
為什麼需要業務模型?
構建業務模型是為了向高層管理人員展示您的工作內容,它還可以讓您的團隊瞭解您試圖實現的目標。設計業務模型被認為是組織在其資料整合專案開始時採用的最佳實踐之一。此外,它有助於降低成本,並能發現和解決專案中的瓶頸。如果需要,可以在專案實施期間和之後修改模型。
在 Talend Open Studio 中建立業務模型
Talend Open Studio 提供多個形狀和聯結器來建立和設計業務模型。業務模型中的每個模組都可以附加文件。
Talend Open Studio 提供以下形狀和聯結器選項來建立業務模型:
決策 - 此形狀用於在模型中放置 if 條件。
操作 - 此形狀用於顯示任何轉換、翻譯或格式化。
終端 - 此形狀顯示輸出終端型別。
資料 - 此形狀用於顯示資料型別。
文件 - 此形狀用於插入文件物件,該物件可用於已處理資料的輸入/輸出。
輸入 - 此形狀用於插入輸入物件,使用者可以使用該物件手動傳遞資料。
列表 - 此形狀包含提取的資料,可以將其定義為僅在列表中儲存某種型別的資料。
資料庫 - 此形狀用於儲存輸入/輸出資料。
參與者 - 此形狀象徵著參與決策和技術流程的個人。
橢圓 - 插入橢圓形狀。
齒輪 - 此形狀顯示必須由 Talend 作業替換的手動程式。
Talend - 資料整合元件
Talend 中的所有操作均由聯結器和元件執行。Talend 提供 800 多個聯結器和元件來執行多項操作。這些元件存在於調色盤中,並且有 21 個主要類別屬於這些元件。您可以選擇聯結器並將其拖放到設計器窗格中,它將自動建立 Java 程式碼,當您儲存 Talend 程式碼時,該程式碼將被編譯。
包含元件的主要類別如下所示:
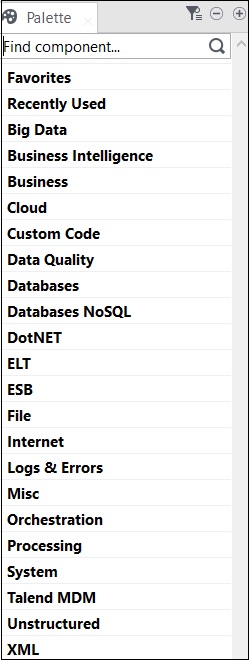
以下是 Talend Open Studio 中廣泛使用的資料整合聯結器和元件的列表:
tMysqlConnection - 連線到元件中定義的 MySQL 資料庫。
tMysqlInput - 執行資料庫查詢以讀取資料庫並提取欄位(表、檢視等),具體取決於查詢。
tMysqlOutput - 用於寫入、更新、修改 MySQL 資料庫中的資料。
tFileInputDelimited - 行讀入分隔符檔案,並將它們分成單獨的欄位,然後傳遞到下一個元件。
tFileInputExcel - 行讀入excel檔案,並將它們分成單獨的欄位,然後傳遞到下一個元件。
tFileList - 從給定的檔案掩碼模式獲取所有檔案和目錄。
tFileArchive - 將一組檔案或資料夾壓縮到 zip、gzip 或 tar.gz 歸檔檔案中。
tRowGenerator − 提供一個編輯器,您可以在其中編寫函式或選擇表示式來生成示例資料。
tMsgBox − 返回一個帶有指定訊息和“確定”按鈕的對話方塊。
tLogRow − 監控正在處理的資料。它在執行控制檯中顯示資料/輸出。
tPreJob − 定義在實際作業開始之前將執行的子作業。
tMap − 充當 Talend Studio 中的外掛。它從一個或多個來源獲取資料,對其進行轉換,然後將轉換後的資料傳送到一個或多個目標。
tJoin − 透過在主流程和查詢流程之間執行內連線和外連線來連線兩個表。
tJava − 使您能夠在 Talend 程式中使用個性化的 Java 程式碼。
tRunJob − 透過一個接一個地執行 Talend 作業來管理複雜的作業系統。
Talend - 作業設計
這是業務模型的技術實現/圖形表示。在此設計中,一個或多個元件相互連線以執行資料整合過程。因此,當您在設計面板中拖放元件並使用聯結器連線它們時,作業設計會將所有內容轉換為程式碼,並建立一個完整的可執行程式,從而形成資料流。
建立作業
在資源庫視窗中,右鍵單擊“作業設計”,然後單擊“建立作業”。
提供作業的名稱、用途和說明,然後單擊“完成”。
您會看到您的作業已在“作業設計”下建立。
現在,讓我們使用此作業新增元件、連線並配置它們。在這裡,我們將採用 Excel 檔案作為輸入,並生成具有相同資料的 Excel 檔案作為輸出。
向作業新增元件
調色盤中有幾個元件可供選擇。還有一個搜尋選項,您可以在其中輸入元件的名稱以選擇它。
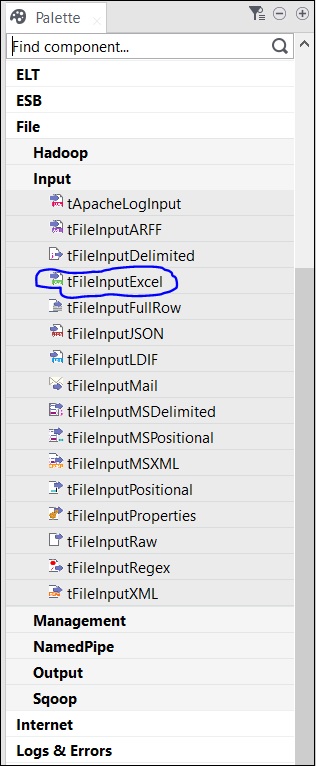
由於此處我們將 Excel 檔案作為輸入,因此我們將從調色盤中將 tFileInputExcel 元件拖放到設計器視窗。

現在,如果您單擊設計器視窗中的任何位置,都會出現一個搜尋框。找到 tLogRow 並選擇它以將其帶入設計器視窗。
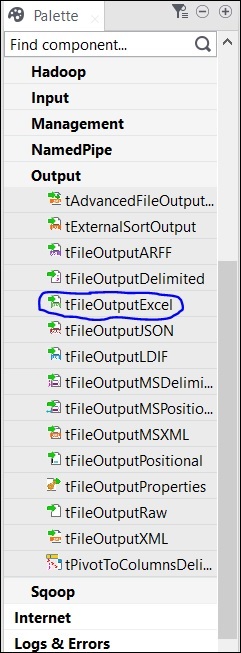
最後,從調色盤中選擇 tFileOutputExcel 元件,並將其拖放到設計器視窗。
現在,元件的新增已完成。
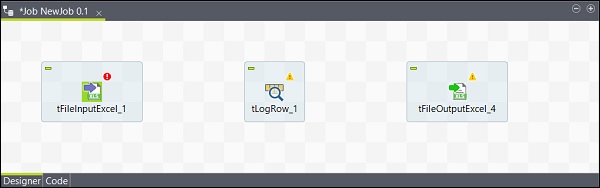
連線元件
新增元件後,必須連線它們。右鍵單擊第一個元件 tFileInputExcel,然後繪製一條主線到 tLogRow,如下所示。
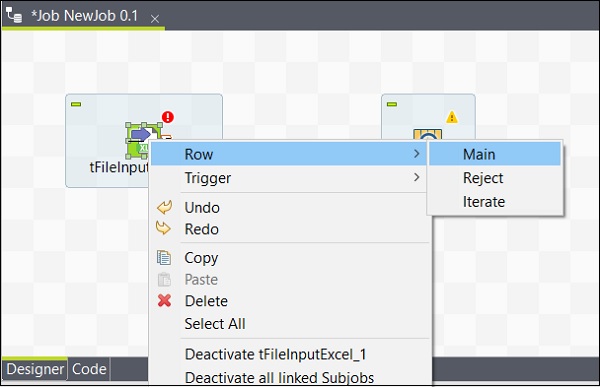
同樣,右鍵單擊 tLogRow,然後在 tFileOutputExcel 上繪製一條主線。現在,您的元件已連線。
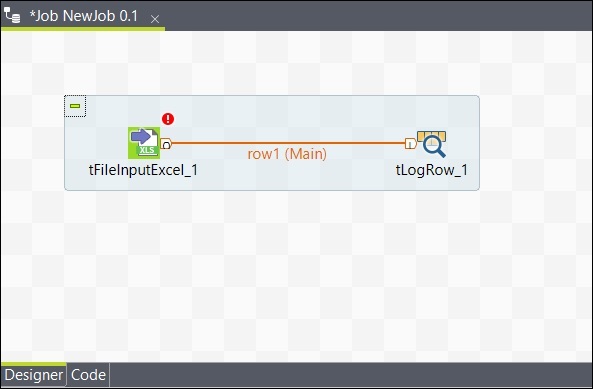
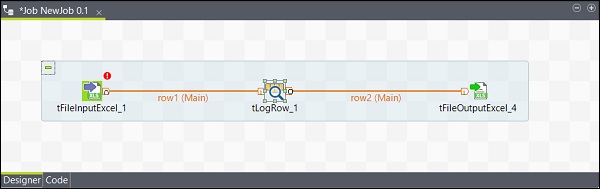
配置元件
在作業中新增和連線元件後,您需要配置它們。為此,雙擊第一個元件 tFileInputExcel 進行配置。在“檔名/流”中提供輸入檔案的路徑,如下所示。
如果您的 Excel 檔案的第 1 行包含列名,請在“標題”選項中輸入 1。

單擊“編輯架構”,並根據您的輸入 Excel 檔案新增列及其型別。新增架構後,單擊“確定”。
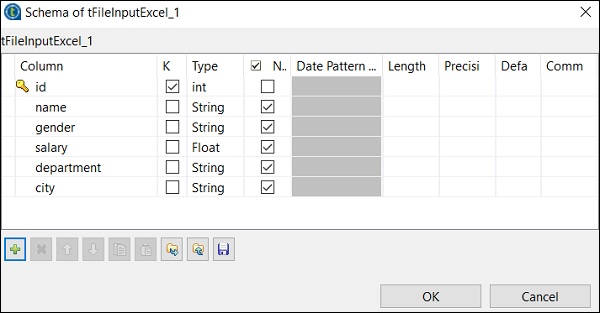
單擊“是”。

在 tLogRow 元件中,單擊“同步列”,並選擇要從中生成行的模式。在這裡,我們選擇了以“,”作為欄位分隔符的基本模式。
最後,在 tFileOutputExcel 元件中,提供要儲存輸出 Excel 檔案的資料夾路徑和檔名。
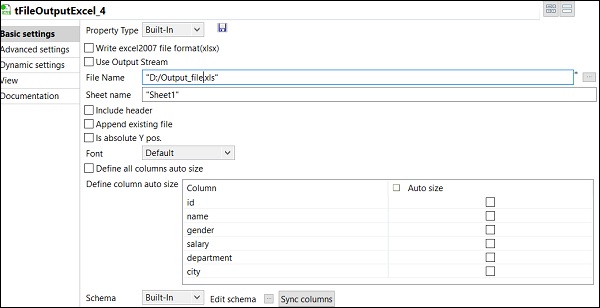
以及工作表名稱。單擊“同步列”。
執行作業
完成新增、連線和配置元件後,您就可以執行 Talend 作業了。單擊“執行”按鈕開始執行。


您將在基本模式下看到輸出,並以“,”作為分隔符。
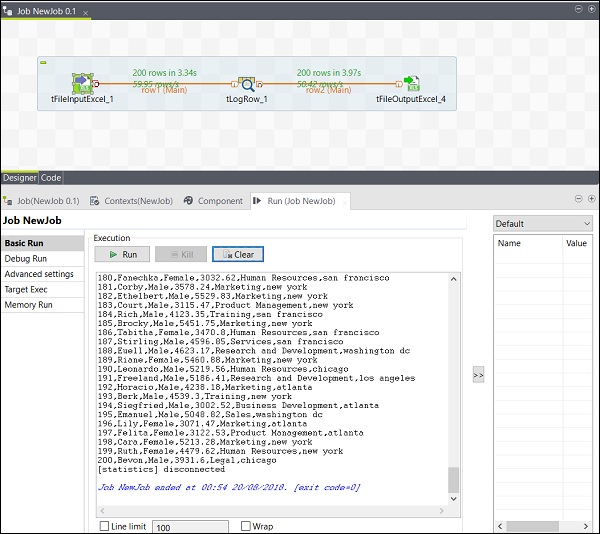
您還可以看到您的輸出已儲存為 Excel 檔案,儲存在您指定的輸出路徑。
Talend - 元資料
元資料基本上是指關於資料的資料。它說明了資料的什麼、何時、為什麼、誰、何地、哪個和如何。在 Talend 中,元資料包含 Talend Studio 中存在的資料的全部資訊。元資料選項位於 Talend Open Studio 的“資源庫”窗格中。
各種來源,例如資料庫連線、不同型別的檔案、LDAP、Azure、Salesforce、Web 服務 FTP、Hadoop 叢集以及許多其他選項都位於 Talend 元資料下。
Talend Open Studio 中元資料的主要用途是,您只需從資源庫面板中的元資料中簡單地拖放即可在多個作業中使用這些資料來源。
Talend - 上下文變數
上下文變數是可以具有不同環境中不同值的變數。您可以建立一個上下文組來儲存多個上下文變數。您無需逐個將每個上下文變數新增到作業中,只需將上下文組新增到作業中即可。
這些變數用於使程式碼準備好投入生產。這意味著透過使用上下文變數,您可以將程式碼移動到開發、測試或生產環境中,它將在所有環境中執行。
在任何作業中,您都可以轉到如下所示的“上下文”選項卡並新增上下文變數。
Talend - 作業管理
在本章中,讓我們瞭解在 Talend 中管理作業以及包含的相應功能。
啟用/停用元件
啟用/停用元件非常簡單。您只需要選擇元件,右鍵單擊它,然後選擇停用或啟用該元件選項即可。

匯入/匯出專案和構建作業
要從作業中匯出專案,請右鍵單擊“作業設計”中的作業,然後單擊“匯出專案”。


輸入要匯出專案的路徑,然後單擊“完成”。

要從作業中匯入專案,請右鍵單擊“作業設計”中的作業,然後單擊“匯入專案”。
瀏覽要從中匯入專案的根目錄。
選擇所有複選框,然後單擊“完成”。

Talend - 處理作業執行
在本章中,讓我們瞭解在 Talend 中處理作業執行。
要構建作業,請右鍵單擊該作業並選擇“構建作業”選項。
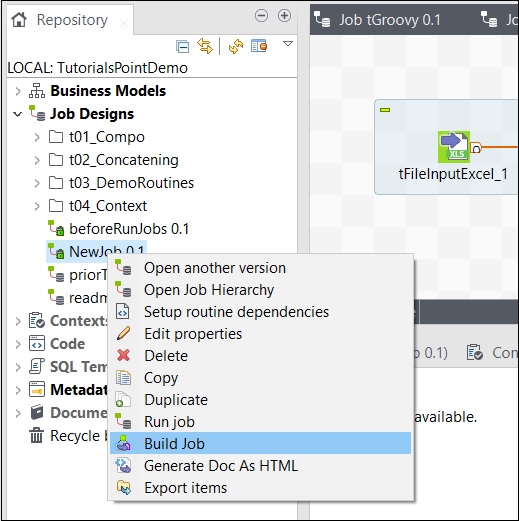
提及要存檔作業的路徑,選擇作業版本和構建型別,然後單擊“完成”。
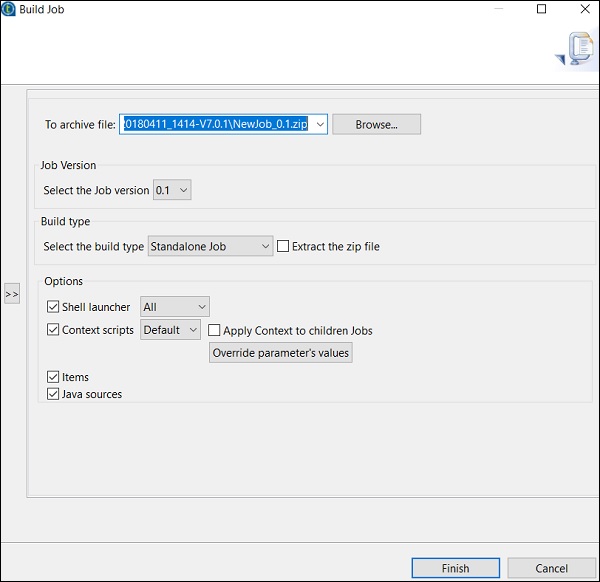
如何在普通模式下執行作業
要在普通節點中執行作業,您需要選擇“基本執行”,然後單擊“執行”按鈕以開始執行。

如何在除錯模式下執行作業
要在除錯模式下執行作業,請在要除錯的元件中新增斷點。
然後,選擇並右鍵單擊元件,單擊“新增斷點”選項。請注意,此處我們在 tFileInputExcel 和 tLogRow 元件中添加了斷點。然後,轉到“除錯執行”,然後單擊“Java 除錯”按鈕。
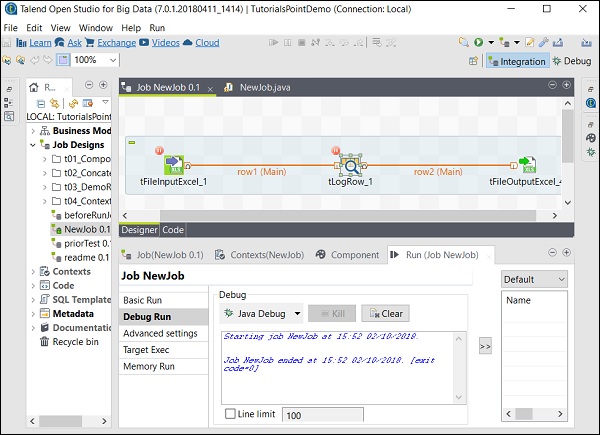
您可以從以下螢幕截圖中觀察到,作業現在將在除錯模式下執行,並根據我們提到的斷點進行執行。

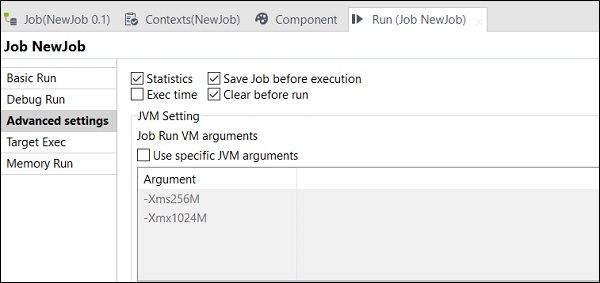
高階設定
在高階設定中,您可以從統計資訊、執行時間、執行前儲存作業、執行前清除和 JVM 設定中進行選擇。此處解釋了每個選項的功能:
統計資訊 − 顯示處理的效能率;
執行時間 − 執行作業所花費的時間。
執行前儲存作業 − 在執行開始之前自動儲存作業。
執行前清除 − 從輸出控制檯中刪除所有內容。
JVM 設定 − 幫助我們配置自己的 Java 引數。
Talend - 大資料
帶有大資料的 Open Studio 的標語是“使用領先的免費開源大資料 ETL 工具簡化 ETL 和 ELT”。在本章中,讓我們瞭解 Talend 作為在大資料環境中處理資料的工具的用法。
介紹
Talend Open Studio – Big Data 是一款免費的開源工具,可讓您在大資料環境中非常輕鬆地處理資料。Talend Open Studio 中提供了大量的大資料元件,只需簡單地拖放幾個 Hadoop 元件,即可建立和執行 Hadoop 作業。
此外,我們無需編寫大量 MapReduce 程式碼;Talend Open Studio Big data 透過其中提供的元件幫助您做到這一點。它會自動為您生成 MapReduce 程式碼,您只需拖放元件並配置一些引數即可。
它還允許您連線到多個大資料發行版,例如 Cloudera、HortonWorks、MapR、Amazon EMR 甚至 Apache。
用於大資料的 Talend 元件
下面顯示了在“大資料”下包含的用於在大資料環境中執行作業的元件類別列表:
下面顯示了 Talend Open Studio 中的大資料聯結器和元件列表:
tHDFSConnection − 用於連線到 HDFS(Hadoop 分散式檔案系統)。
tHDFSInput − 從給定的 hdfs 路徑讀取資料,將其放入 Talend 架構中,然後將其傳遞給作業中的下一個元件。
tHDFSList − 檢索給定 hdfs 路徑中的所有檔案和資料夾。
tHDFSPut − 將檔案/資料夾從本地檔案系統(使用者定義)複製到給定路徑的 hdfs。
tHDFSGet − 將檔案/資料夾從 hdfs 複製到給定路徑的本地檔案系統(使用者定義)。
tHDFSDelete − 從 HDFS 刪除檔案。
tHDFSExist − 檢查檔案是否存在於 HDFS 上。
tHDFSOutput − 將資料流寫入 HDFS。
tCassandraConnection − 開啟與 Cassandra 伺服器的連線。
tCassandraRow − 在指定的資料庫上執行 CQL(Cassandra 查詢語言)查詢。
tHBaseConnection − 開啟與 HBase 資料庫的連線。
tHBaseInput − 從 HBase 資料庫讀取資料。
tHiveConnection − 開啟與 Hive 資料庫的連線。
tHiveCreateTable − 在 Hive 資料庫中建立一個表。
tHiveInput − 從 Hive 資料庫讀取資料。
tHiveLoad − 將資料寫入 Hive 表或指定的目錄。
tHiveRow − 在指定的資料庫上執行 HiveQL 查詢。
tPigLoad − 將輸入資料載入到輸出流。
tPigMap − 用於在 Pig 過程中轉換和路由資料。
tPigJoin − 基於連線鍵執行兩個檔案的連線操作。
tPigCoGroup − 對來自多個輸入的資料進行分組和聚合。
tPigSort − 根據一個或多個定義的排序鍵對給定資料進行排序。
tPigStoreResult − 將 Pig 操作的結果儲存在定義的儲存空間中。
tPigFilterRow − 篩選指定的列,以便根據給定條件拆分資料。
tPigDistinct − 從關係中刪除重複元組。
tSqoopImport − 將資料從關係資料庫(如 MySQL、Oracle DB)傳輸到 HDFS。
tSqoopExport − 將資料從 HDFS 傳輸到關係資料庫(如 MySQL、Oracle DB)。
Talend - Hadoop 分散式檔案系統
在本章中,讓我們詳細瞭解 Talend 如何與 Hadoop 分散式檔案系統協同工作。
設定和先決條件
在我們繼續使用 Talend 和 HDFS 之前,我們應該瞭解為此目的應滿足的設定和先決條件。
在這裡,我們在 VirtualBox 上執行 Cloudera 快速入門 5.10 VM。此 VM 必須使用專用主機網路。
專用主機網路 IP:192.168.56.101
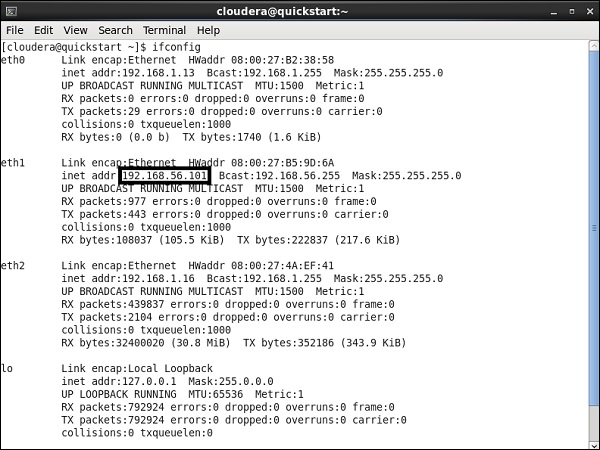
您必須在 Cloudera Manager 上執行相同的 host。
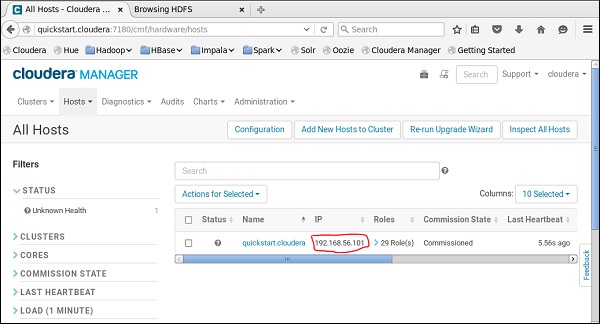
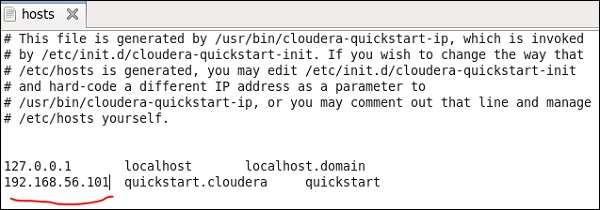
現在,在您的 Windows 系統上,轉到 c:\Windows\System32\Drivers\etc\hosts 並使用記事本編輯此檔案,如下所示。
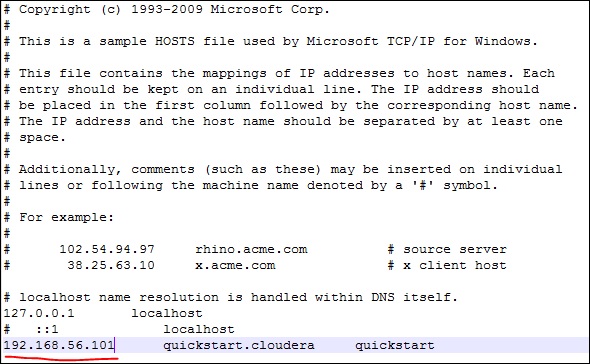
同樣,在您的 Cloudera 快速入門 VM 上,編輯您的 /etc/hosts 檔案,如下所示。
sudo gedit /etc/hosts
設定 Hadoop 連線
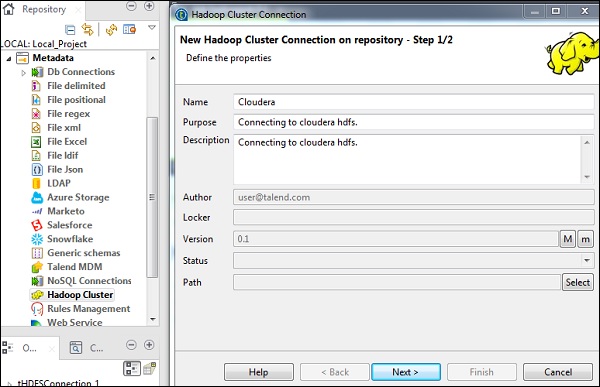
在資源庫面板中,轉到“元資料”。右鍵單擊“Hadoop 叢集”,然後建立一個新的叢集。為該 Hadoop 叢集連線提供名稱、用途和說明。
單擊“下一步”。
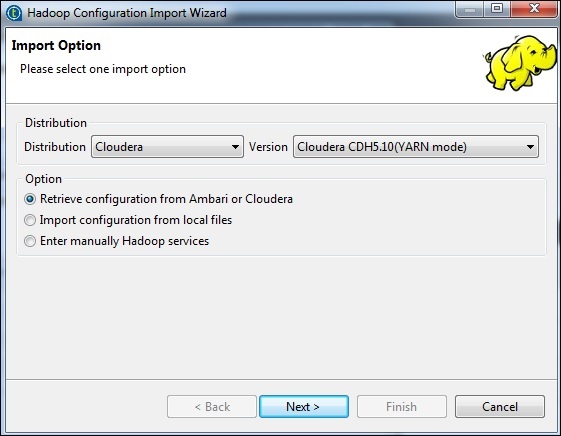
選擇發行版為 Cloudera,然後選擇您正在使用的版本。選擇“檢索配置”選項,然後單擊“下一步”。
輸入管理器憑據(帶埠的 URI、使用者名稱、密碼),如下所示,然後單擊“連線”。如果詳細資訊正確,您將在已發現的叢集下獲得 Cloudera QuickStart。
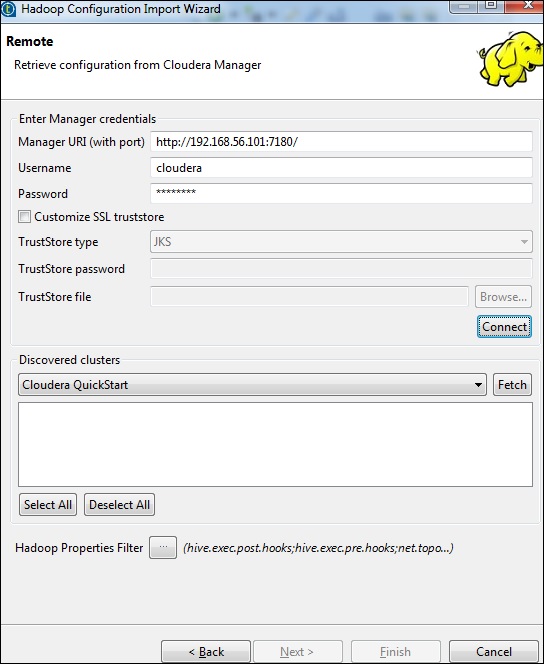
單擊“獲取”。這將獲取 HDFS、YARN、HBASE、HIVE 的所有連線和配置。
選擇“全部”,然後單擊“完成”。
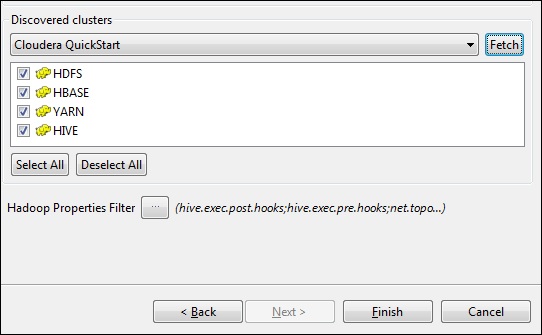
請注意,所有連線引數都將自動填充。在使用者名稱中提及 cloudera,然後單擊“完成”。

這樣,您就成功連線到 Hadoop 叢集。

連線到 HDFS
在此作業中,我們將列出 HDFS 上存在的所有目錄和檔案。
首先,我們將建立一個作業,然後向其中新增 HDFS 元件。右鍵單擊“作業設計”,建立一個新作業 - hadoopjob。
現在從調色盤中新增 2 個元件 - tHDFSConnection 和 tHDFSList。右鍵單擊 tHDFSConnection,並使用“OnSubJobOk”觸發器連線這兩個元件。
現在,配置這兩個 Talend hdfs 元件。
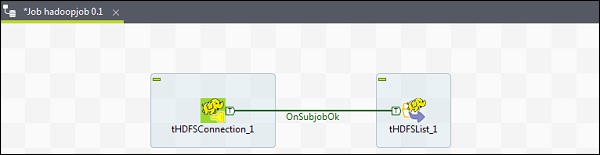
在 tHDFSConnection 中,選擇“Repository”作為屬性型別,並選擇您之前建立的 Hadoop cloudera 叢集。它將自動填充此元件所需的所有必要詳細資訊。

在 tHDFSList 中,選擇“使用現有連線”,並在元件列表中選擇您配置的 tHDFSConnection。
在“HDFS 目錄”選項中提供 HDFS 的主目錄路徑,然後單擊右側的瀏覽按鈕。
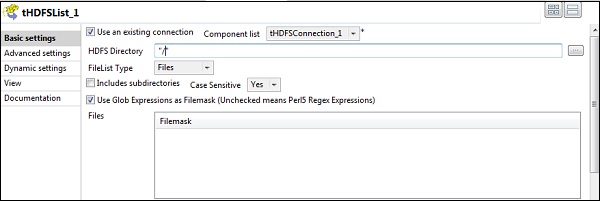
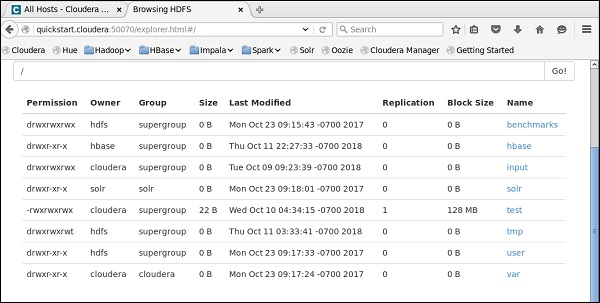
如果您已使用上述配置正確建立連線,您將看到如下所示的視窗。它將列出 HDFS 主目錄上存在的所有目錄和檔案。
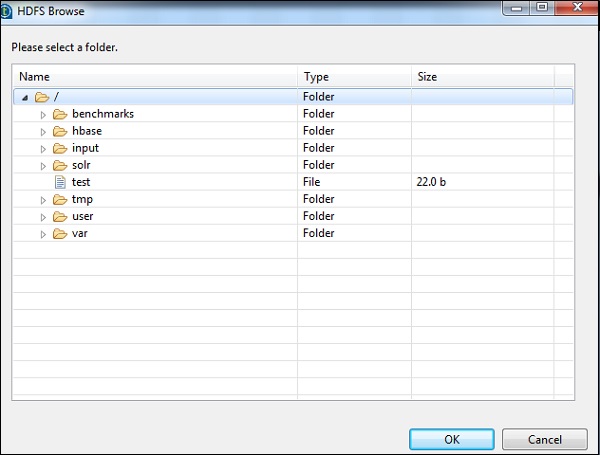
您可以透過檢查 Cloudera 上的 HDFS 來驗證這一點。
從 HDFS 讀取檔案
在本節中,讓我們瞭解如何在 Talend 中從 HDFS 讀取檔案。您可以為此建立一個新作業,但是在這裡我們使用現有的作業。
從調色盤將 3 個元件 - tHDFSConnection、tHDFSInput 和 tLogRow 拖放到設計器視窗。
右鍵單擊 tHDFSConnection,並使用“OnSubJobOk”觸發器連線 tHDFSInput 元件。
右鍵單擊 tHDFSInput,並將主連結拖動到 tLogRow。
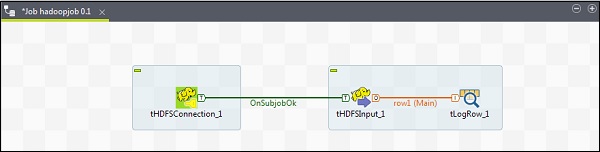
請注意,tHDFSConnection 將具有與之前相同的配置。在 tHDFSInput 中,選擇“使用現有連線”,然後從元件列表中選擇 tHDFSConnection。
在“檔名”中,提供要讀取的檔案的 HDFS 路徑。這裡我們讀取一個簡單的文字檔案,因此我們的檔案型別是“文字檔案”。類似地,根據您的輸入,填寫如下所示的行分隔符、欄位分隔符和標題詳細資訊。最後,單擊“編輯模式”按鈕。

由於我們的檔案只有純文字,我們只新增一列字串型別。現在,單擊“確定”。
注意 - 當您的輸入具有多種不同型別的列時,您需要在此處相應地提及模式。

在 tLogRow 元件中,單擊“編輯模式”中的“同步列”。
選擇您希望輸出列印的模式。

最後,單擊“執行”以執行作業。
成功讀取 HDFS 檔案後,您將看到以下輸出。

將檔案寫入 HDFS
讓我們看看如何在 Talend 中將檔案寫入 HDFS。從調色盤將 3 個元件 - tHDFSConnection、tFileInputDelimited 和 tHDFSOutput 拖放到設計器視窗。
右鍵單擊 tHDFSConnection,並使用“OnSubJobOk”觸發器連線 tFileInputDelimited 元件。
右鍵單擊 tFileInputDelimited,並將主連結拖動到 tHDFSOutput。
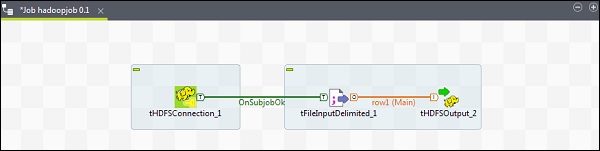
請注意,tHDFSConnection 將具有與之前相同的配置。
現在,在 tFileInputDelimited 中,在“檔名/流”選項中提供輸入檔案的路徑。這裡我們使用 csv 檔案作為輸入,因此欄位分隔符是“,”。
根據您的輸入檔案選擇標題、頁尾和限制。請注意,這裡我們的標題是 1,因為第 1 行包含列名,限制是 3,因為我們只將前 3 行寫入 HDFS。
現在,單擊“編輯模式”。
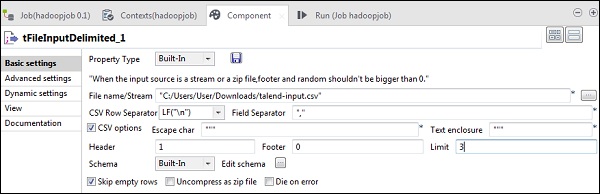
現在,根據我們的輸入檔案定義模式。我們的輸入檔案有 3 列,如下所示。
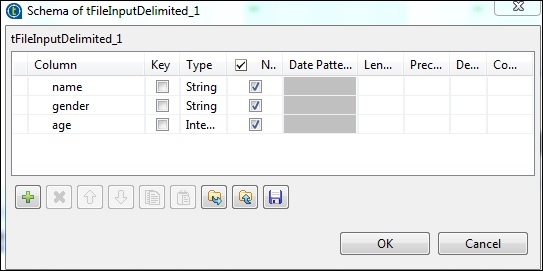
在 tHDFSOutput 元件中,單擊“同步列”。然後,在“使用現有連線”中選擇 tHDFSConnection。此外,在“檔名”中,提供您要寫入檔案的 HDFS 路徑。
請注意,檔案型別將是文字檔案,“操作”將是“建立”,“行分隔符”將是“\n”,欄位分隔符是“;”。
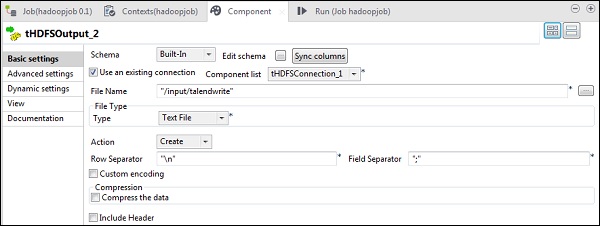
最後,單擊“執行”以執行您的作業。作業成功執行後,檢查您的檔案是否在 HDFS 上。
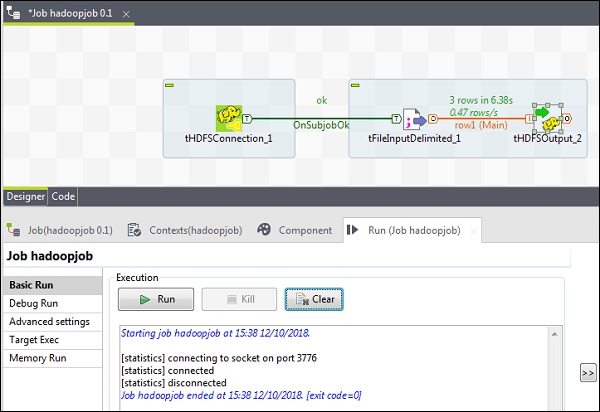
使用您在作業中提到的輸出路徑執行以下 hdfs 命令。
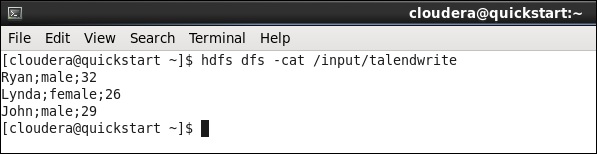
hdfs dfs -cat /input/talendwrite
如果您成功寫入 HDFS,您將看到以下輸出。
Talend - Map Reduce
在上一章中,我們瞭解了 Talend 如何與大資料一起工作。在本章中,讓我們瞭解如何在 Talend 中使用 MapReduce。
建立 Talend MapReduce 作業
讓我們學習如何在 Talend 上執行 MapReduce 作業。在這裡,我們將執行 MapReduce 單詞計數示例。
為此,請右鍵單擊“作業設計”,建立一個新作業 - MapreduceJob。提及作業的詳細資訊,然後單擊“完成”。

向 MapReduce 作業新增元件
要向 MapReduce 作業新增元件,請將 Talend 的五個元件 - tHDFSInput、tNormalize、tAggregateRow、tMap、tOutput 從調色盤拖放到設計器視窗。右鍵單擊 tHDFSInput 並建立到 tNormalize 的主連結。
右鍵單擊 tNormalize 並建立到 tAggregateRow 的主連結。然後,右鍵單擊 tAggregateRow 並建立到 tMap 的主連結。現在,右鍵單擊 tMap 並建立到 tHDFSOutput 的主連結。
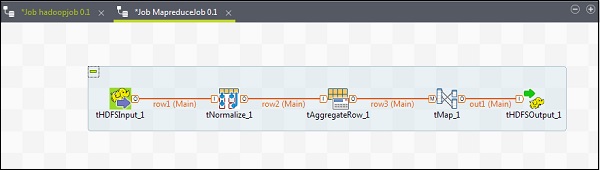
配置元件和轉換
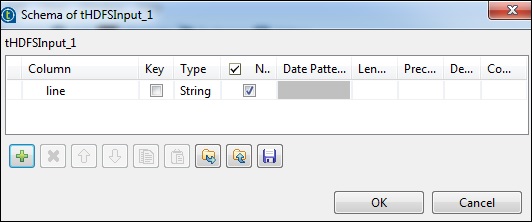
在 tHDFSInput 中,選擇分散式 cloudera 及其版本。請注意,NameNode URI 應為“hdfs://quickstart.cloudera:8020”,使用者名稱應為“cloudera”。在檔名選項中,提供輸入檔案到 MapReduce 作業的路徑。確保此輸入檔案存在於 HDFS 上。
現在,根據您的輸入檔案選擇檔案型別、行分隔符、檔案分隔符和標題。

單擊“編輯模式”並新增欄位“line”作為字串型別。
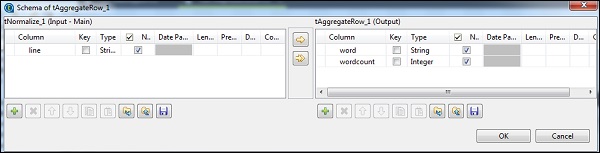
在 tNomalize 中,要規範化的列將是 line,專案分隔符將是空格 - >“ ”。現在,單擊“編輯模式”。tNormalize 將具有 line 列,而 tAggregateRow 將具有 2 列 word 和 wordcount,如下所示。

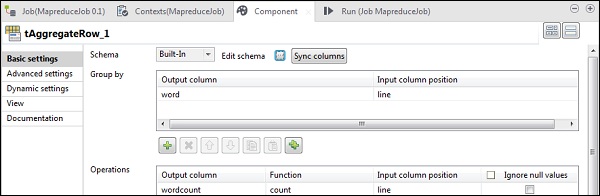
在 tAggregateRow 中,將 word 作為輸出列放在“分組依據”選項中。在“操作”中,將 wordcount 作為輸出列,函式為 count,輸入列位置為 line。
現在雙擊 tMap 元件以輸入對映編輯器並將輸入與所需的輸出對映。在此示例中,word 對映到 word,wordcount 對映到 wordcount。在表示式列中,單擊 […] 以輸入表示式構建器。
現在,從類別列表中選擇 StringHandling 和 UPCASE 函式。將表示式編輯為“StringHandling.UPCASE(row3.word)”,然後單擊“確定”。將 row3.wordcount 保留在與 wordcount 對應的表示式列中,如下所示。
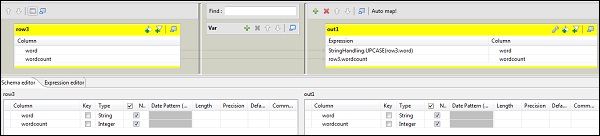
在 tHDFSOutput 中,從屬性型別作為儲存庫連線到我們建立的 Hadoop 叢集。觀察欄位將自動填充。在“檔名”中,提供要儲存輸出的輸出路徑。保持操作、行分隔符和欄位分隔符如下所示。

執行 MapReduce 作業
配置成功完成後,單擊“執行”並執行您的 MapReduce 作業。

轉到您的 HDFS 路徑並檢查輸出。請注意,所有單詞都將大寫,並帶有它們的字數。

Talend - 使用 Pig
在本章中,讓我們學習如何在 Talend 中使用 Pig 作業。
建立 Talend Pig 作業
在本節中,讓我們學習如何在 Talend 上執行 Pig 作業。在這裡,我們將處理 NYSE 資料以找出 IBM 的平均股票成交量。
為此,請右鍵單擊“作業設計”,建立一個新作業 - pigjob。提及作業的詳細資訊,然後單擊“完成”。
向 Pig 作業新增元件
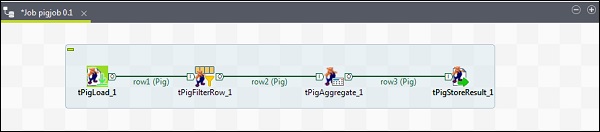
要向 Pig 作業新增元件,請從調色盤將四個 Talend 元件:tPigLoad、tPigFilterRow、tPigAggregate、tPigStoreResult 拖放到設計器視窗。
然後,右鍵單擊 tPigLoad 並建立 Pig 組合行到 tPigFilterRow。接下來,右鍵單擊 tPigFilterRow 並建立 Pig 組合行到 tPigAggregate。右鍵單擊 tPigAggregate 並建立 Pig 組合行到 tPigStoreResult。
配置元件和轉換
在 tPigLoad 中,將分散式設定為 cloudera 和 cloudera 的版本。請注意,NameNode URI 應為“hdfs://quickstart.cloudera:8020”,資源管理器應為“quickstart.cloudera:8020”。此外,使用者名稱應為“cloudera”。
在輸入檔案 URI 中,提供您的 NYSE 輸入檔案到 pig 作業的路徑。請注意,此輸入檔案應存在於 HDFS 上。

單擊“編輯模式”,新增列及其型別,如下所示。

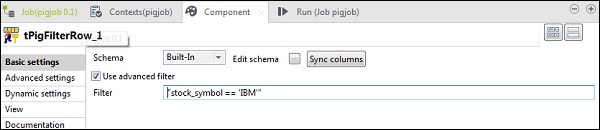
在 tPigFilterRow 中,選擇“使用高階過濾器”選項,並在“過濾器”選項中輸入“stock_symbol == ‘IBM’”。
在 tAggregateRow 中,單擊“編輯模式”並在輸出中新增 avg_stock_volume 列,如下所示。

現在,將 stock_exchange 列放在“分組依據”選項中。使用 count 函式和 stock_exchange 作為輸入列,在“操作”欄位中新增 avg_stock_volume 列。

在 tPigStoreResult 中,在“結果資料夾 URI”中提供要儲存 Pig 作業結果的輸出路徑。選擇 store 函式為 PigStorage,欄位分隔符(非強制性)為“\t”。
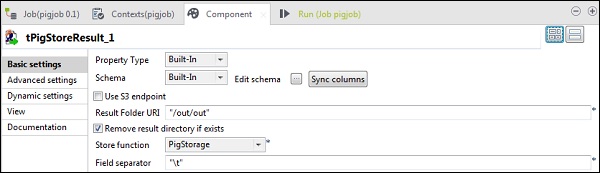
執行 Pig 作業
現在單擊“執行”以執行您的 Pig 作業。(忽略警告)
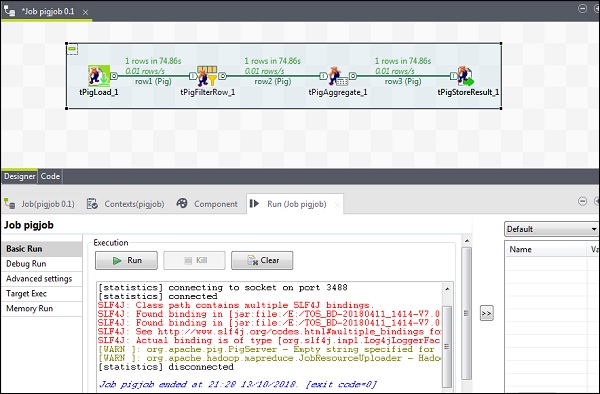
作業完成後,轉到您提到的用於儲存 pig 作業結果的 HDFS 路徑並檢查您的輸出。IBM 的平均股票成交量為 500。

Talend - Hive
在本章中,讓我們瞭解如何在 Talend 中使用 Hive 作業。
建立 Talend Hive 作業
例如,我們將 NYSE 資料載入到 Hive 表中並執行基本的 Hive 查詢。右鍵單擊“作業設計”,建立一個新作業 - hivejob。提及作業的詳細資訊,然後單擊“完成”。
向 Hive 作業新增元件
要向 Hive 作業新增元件,請從調色盤將五個 Talend 元件 - tHiveConnection、tHiveCreateTable、tHiveLoad、tHiveInput 和 tLogRow 拖放到設計器視窗。然後,右鍵單擊 tHiveConnection 並建立 OnSubjobOk 觸發器到 tHiveCreateTable。現在,右鍵單擊 tHiveCreateTable 並建立 OnSubjobOk 觸發器到 tHiveLoad。右鍵單擊 tHiveLoad 並建立迭代觸發器到 tHiveInput。最後,右鍵單擊 tHiveInput 並建立到 tLogRow 的主線。

配置元件和轉換
在 tHiveConnection 中,選擇分散式為 cloudera 及其正在使用的版本。請注意,連線模式將是獨立的,Hive 服務將是 Hive 2。還要檢查以下引數是否已相應設定 -
- 主機:“quickstart.cloudera”
- 埠:“10000”
- 資料庫:“default”
- 使用者名稱:“hive”
請注意,密碼將自動填充,無需編輯。其他Hadoop屬性也將預設並預設設定。

在tHiveCreateTable中,選擇“使用現有連線”,並將tHiveConnection放入元件列表。在預設資料庫中輸入您要建立的表名。保持其他引數如下所示。
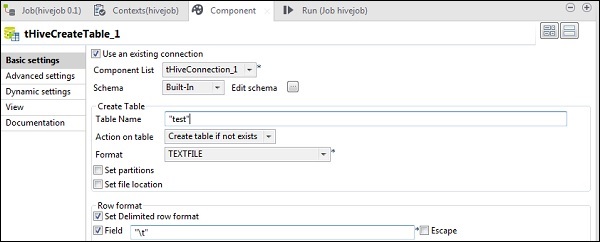
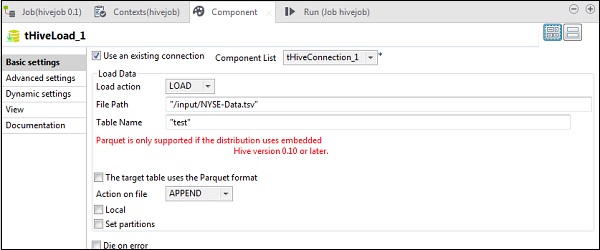
在tHiveLoad中,選擇“使用現有連線”,並將tHiveConnection放入元件列表。在載入操作中選擇LOAD。在“檔案路徑”中,輸入NYSE輸入檔案的HDFS路徑。在“表名”中指定您要載入輸入資料的表。保持其他引數如下所示。
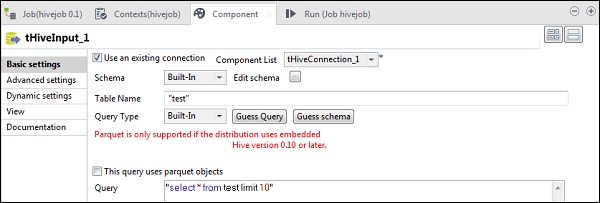
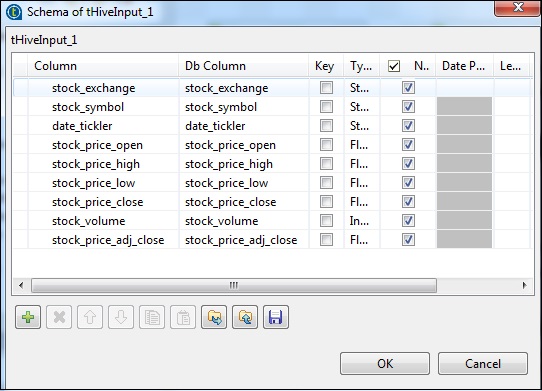
在tHiveInput中,選擇“使用現有連線”,並將tHiveConnection放入元件列表。點選編輯模式,新增列及其型別,如下面的模式快照所示。現在輸入您在tHiveCreateTable中建立的表名。
在查詢選項中輸入您想在Hive表上執行的查詢。這裡我們列印測試Hive表中前10行的所有列。
在tLogRow中,點選同步列,並選擇表模式以顯示輸出。

執行Hive作業
點選“執行”開始執行。如果所有連線和引數都設定正確,您將看到如下所示的查詢輸出。
