- Talend 教程
- Talend - 首頁
- Talend - 簡介
- Talend - 系統需求
- Talend - 安裝
- Talend Open Studio
- Talend - 資料整合
- Talend - 模型基礎
- 資料整合元件
- Talend - 作業設計
- Talend - 元資料
- Talend - 上下文變數
- Talend - 作業管理
- Talend - 處理作業執行
- Talend - 大資料
- Hadoop 分散式檔案系統
- Talend - Map Reduce
- Talend - 使用 Pig
- Talend - Hive
- Talend 有用資源
- Talend - 快速指南
- Talend - 有用資源
- Talend - 討論
Talend - Map Reduce
在上一章中,我們瞭解了 Talend 如何處理大資料。在本章中,讓我們瞭解如何使用 Map Reduce 與 Talend。
建立 Talend MapReduce 作業
讓我們學習如何在 Talend 上執行 MapReduce 作業。在這裡,我們將執行一個 MapReduce 詞頻統計示例。
為此,右鍵單擊作業設計並建立一個新作業 - MapreduceJob。填寫作業的詳細資訊,然後單擊“完成”。

向 MapReduce 作業新增元件
要向 MapReduce 作業新增元件,請將 Talend 的五個元件 - tHDFSInput、tNormalize、tAggregateRow、tMap、tOutput 從調色盤拖放到設計器視窗。右鍵單擊 tHDFSInput 並建立到 tNormalize 的主連結。
右鍵單擊 tNormalize 並建立到 tAggregateRow 的主連結。然後,右鍵單擊 tAggregateRow 並建立到 tMap 的主連結。現在,右鍵單擊 tMap 並建立到 tHDFSOutput 的主連結。
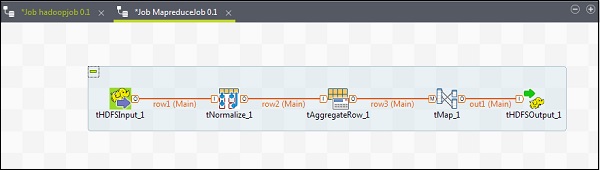
配置元件和轉換
在 tHDFSInput 中,選擇發行版 Cloudera 及其版本。請注意,NameNode URI 應為“hdfs://quickstart.cloudera:8020”,使用者名稱應為“cloudera”。在檔名選項中,提供 MapReduce 作業的輸入檔案的路徑。確保此輸入檔案存在於 HDFS 上。
現在,根據您的輸入檔案選擇檔案型別、行分隔符、檔案分隔符和標題。

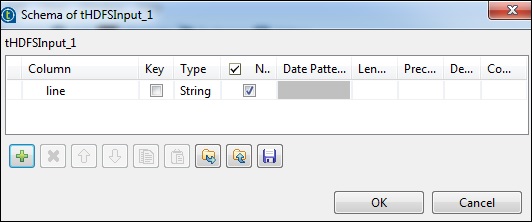
單擊“編輯模式”並新增欄位“line”作為字串型別。
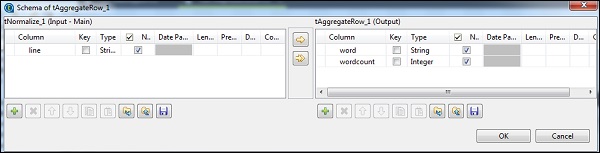
在 tNomalize 中,要規範化的列將是 line,專案分隔符將是空格 ->“”。現在,單擊“編輯模式”。tNormalize 將具有 line 列,而 tAggregateRow 將具有 2 列 word 和 wordcount,如下所示。

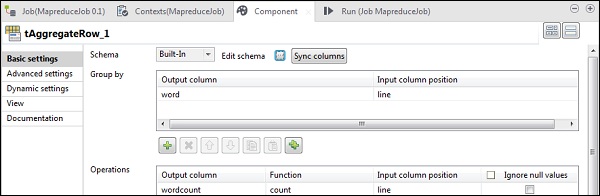
在 tAggregateRow 中,將 word 作為輸出列放入“分組依據”選項中。在“操作”中,將 wordcount 作為輸出列,函式為 count,輸入列位置為 line。
現在雙擊 tMap 元件以進入對映編輯器並將輸入與所需的輸出對映。在此示例中,word 對映到 word,wordcount 對映到 wordcount。在表示式列中,單擊 […] 以進入表示式構建器。
現在,從類別列表中選擇 StringHandling 和 UPCASE 函式。編輯表示式為“StringHandling.UPCASE(row3.word)”並單擊“確定”。將 row3.wordcount 保留在與 wordcount 相對應的表示式列中,如下所示。
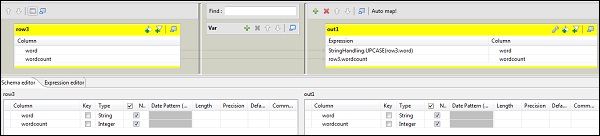
在 tHDFSOutput 中,從屬性型別為儲存庫的連線到我們建立的 Hadoop 叢集。注意欄位將自動填充。在檔名中,提供要儲存輸出的輸出路徑。保持操作、行分隔符和欄位分隔符如下所示。

執行 MapReduce 作業
配置成功完成後,單擊“執行”並執行您的 MapReduce 作業。

轉到您的 HDFS 路徑並檢查輸出。請注意,所有單詞都將大寫,並附帶其詞頻。
