- Scikit Learn 教程
- Scikit Learn - 首頁
- Scikit Learn - 簡介
- Scikit Learn - 建模過程
- Scikit Learn - 資料表示
- Scikit Learn - 估計器 API
- Scikit Learn - 約定
- Scikit Learn - 線性模型
- Scikit Learn - 擴充套件線性模型
- 隨機梯度下降
- Scikit Learn - 支援向量機
- Scikit Learn - 異常檢測
- Scikit Learn - K 近鄰演算法
- Scikit Learn - KNN 學習
- 樸素貝葉斯分類
- Scikit Learn - 決策樹
- 隨機決策樹
- Scikit Learn - 整合方法
- Scikit Learn - 聚類方法
- 聚類效能評估
- 使用 PCA 的降維
- Scikit Learn 有用資源
- Scikit Learn 快速指南
- Scikit Learn - 有用資源
- Scikit Learn - 討論
Scikit Learn 快速指南
Scikit Learn - 簡介
在本章中,我們將瞭解什麼是 Scikit-Learn 或 Sklearn,Scikit-Learn 的起源以及其他相關主題,例如負責 Scikit-Learn 的開發和維護的社群和貢獻者、它的先決條件、安裝及其功能。
什麼是 Scikit-Learn (Sklearn)
Scikit-learn (Sklearn) 是 Python 中最有用和最強大的機器學習庫。它提供了一系列高效的機器學習和統計建模工具,包括透過 Python 中的一致介面進行分類、迴歸、聚類和降維。這個庫主要用 Python 編寫,構建於NumPy、SciPy 和Matplotlib 之上。
Scikit-Learn 的起源
它最初被稱為scikits.learn,最初由 David Cournapeau 於 2007 年作為 Google Summer of Code 專案開發。後來,在 2010 年,來自 FIRCA(法國計算機科學與自動化研究所)的 Fabian Pedregosa、Gael Varoquaux、Alexandre Gramfort 和 Vincent Michel 將該專案提升到另一個層次,並在 2010 年 2 月 1 日釋出了第一個公開版本(v0.1 beta)。
讓我們來看看它的版本歷史 -
2019 年 5 月:scikit-learn 0.21.0
2019 年 3 月:scikit-learn 0.20.3
2018 年 12 月:scikit-learn 0.20.2
2018 年 11 月:scikit-learn 0.20.1
2018 年 9 月:scikit-learn 0.20.0
2018 年 7 月:scikit-learn 0.19.2
2017 年 7 月:scikit-learn 0.19.0
2016 年 9 月:scikit-learn 0.18.0
2015 年 11 月:scikit-learn 0.17.0
2015 年 3 月:scikit-learn 0.16.0
2014 年 7 月:scikit-learn 0.15.0
2013 年 8 月:scikit-learn 0.14
社群與貢獻者
Scikit-learn 是一個社群專案,任何人都可以為其做出貢獻。該專案託管在https://github.com/scikit-learn/scikit-learn。以下人員目前是 Sklearn 開發和維護的核心貢獻者 -
Joris Van den Bossche(資料科學家)
Thomas J Fan(軟體開發工程師)
Alexandre Gramfort(機器學習研究員)
Olivier Grisel(機器學習專家)
Nicolas Hug(副研究科學家)
Andreas Mueller(機器學習科學家)
Hanmin Qin(軟體工程師)
Adrin Jalali(開源開發者)
Nelle Varoquaux(資料科學研究員)
Roman Yurchak(資料科學家)
Booking.com、JP Morgan、Evernote、Inria、AWeber、Spotify 等眾多組織都在使用 Sklearn。
先決條件
在我們開始使用 scikit-learn 最新版本之前,我們需要以下內容 -
Python (>=3.5)
NumPy (>= 1.11.0)
Scipy (>= 0.17.0)
Joblib (>= 0.11)
Sklearn 繪圖功能需要 Matplotlib (>= 1.5.1)。
使用資料結構和分析的一些 scikit-learn 示例需要 Pandas (>= 0.18.0)。
安裝
如果您已經安裝了 NumPy 和 Scipy,以下是用兩種最簡單的方法安裝 scikit-learn 的方法 -
使用 pip
可以使用以下命令透過 pip 安裝 scikit-learn -
pip install -U scikit-learn
使用 conda
可以使用以下命令透過 conda 安裝 scikit-learn -
conda install scikit-learn
另一方面,如果您的 Python 工作站上尚未安裝 NumPy 和 Scipy,則可以使用pip 或conda 來安裝它們。
使用 scikit-learn 的另一種方法是使用Canopy 和Anaconda 等 Python 發行版,因為它們都附帶了 scikit-learn 的最新版本。
功能
Scikit-learn 庫不側重於載入、操作和彙總資料,而是側重於對資料建模。Sklearn 提供的一些最流行的模型組如下 -
監督學習演算法 - 幾乎所有流行的監督學習演算法,如線性迴歸、支援向量機 (SVM)、決策樹等,都是 scikit-learn 的一部分。
無監督學習演算法 - 另一方面,它還包含從聚類、因子分析、PCA(主成分分析)到無監督神經網路的所有流行的無監督學習演算法。
聚類 - 此模型用於對未標記資料進行分組。
交叉驗證 - 用於檢查監督模型在未見資料上的準確性。
降維 - 用於減少資料中屬性的數量,可用於彙總、視覺化和特徵選擇。
整合方法 - 顧名思義,它用於組合多個監督模型的預測。
特徵提取 - 用於從資料中提取特徵以定義影像和文字資料中的屬性。
特徵選擇 - 用於識別有用的屬性以建立監督模型。
開源 - 它是一個開源庫,也可以在 BSD 許可下商業使用。
Scikit Learn - 建模過程
本章介紹 Sklearn 中涉及的建模過程。讓我們詳細瞭解一下,並從資料集載入開始。
資料集載入
資料的集合稱為資料集。它包含以下兩個組成部分 -
特徵 - 資料的變數稱為其特徵。它們也稱為預測變數、輸入或屬性。
特徵矩陣 - 如果有多個特徵,則為特徵的集合。
特徵名稱 - 所有特徵名稱的列表。
響應 - 基本上取決於特徵變數的輸出變數。它們也稱為目標、標籤或輸出。
響應向量 - 用於表示響應列。通常,我們只有一個響應列。
目標名稱 - 表示響應向量可能取的值。
Scikit-learn 有幾個示例資料集,例如用於分類的iris 和digits,以及用於迴歸的波士頓房價。
示例
以下是如何載入iris 資料集的示例 -
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
target_names = iris.target_names
print("Feature names:", feature_names)
print("Target names:", target_names)
print("\nFirst 10 rows of X:\n", X[:10])
輸出
Feature names: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] Target names: ['setosa' 'versicolor' 'virginica'] First 10 rows of X: [ [5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] [5.4 3.9 1.7 0.4] [4.6 3.4 1.4 0.3] [5. 3.4 1.5 0.2] [4.4 2.9 1.4 0.2] [4.9 3.1 1.5 0.1] ]
分割資料集
為了檢查模型的準確性,我們可以將資料集分成兩部分 -訓練集和測試集。使用訓練集訓練模型,使用測試集測試模型。之後,我們可以評估模型的效果。
示例
下面的示例將資料按 70:30 的比例分割,即 70% 的資料將用作訓練資料,30% 的資料將用作測試資料。資料集與上面的示例一樣是 iris 資料集。
from sklearn.datasets import load_iris iris = load_iris() X = iris.data y = iris.target from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( X, y, test_size = 0.3, random_state = 1 ) print(X_train.shape) print(X_test.shape) print(y_train.shape) print(y_test.shape)
輸出
(105, 4) (45, 4) (105,) (45,)
如上例所示,它使用 scikit-learn 的train_test_split() 函式分割資料集。此函式具有以下引數 -
X, y - 這裡,X 是特徵矩陣,y 是響應向量,需要分割。
test_size - 這表示測試資料與總給定資料的比率。在上例中,我們為 X 的 150 行設定test_data = 0.3。它將產生 150*0.3 = 45 行的測試資料。
random_size - 用於保證分割始終相同。這在需要可重複結果的情況下非常有用。
訓練模型
接下來,我們可以使用我們的資料集來訓練一些預測模型。如前所述,scikit-learn 具有廣泛的機器學習 (ML) 演算法,這些演算法具有用於擬合、預測準確性、召回率等的一致介面。
示例
在下面的示例中,我們將使用 KNN(K 近鄰)分類器。不必深入瞭解 KNN 演算法的細節,因為後面會有單獨的章節講解。此示例用於讓您瞭解實現部分。
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.4, random_state=1
)
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
classifier_knn = KNeighborsClassifier(n_neighbors = 3)
classifier_knn.fit(X_train, y_train)
y_pred = classifier_knn.predict(X_test)
# Finding accuracy by comparing actual response values(y_test)with predicted response value(y_pred)
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
# Providing sample data and the model will make prediction out of that data
sample = [[5, 5, 3, 2], [2, 4, 3, 5]]
preds = classifier_knn.predict(sample)
pred_species = [iris.target_names[p] for p in preds] print("Predictions:", pred_species)
輸出
Accuracy: 0.9833333333333333 Predictions: ['versicolor', 'virginica']
模型持久化
訓練模型後,最好使模型持久化以供將來使用,這樣我們就不需要反覆重新訓練它。這可以使用joblib 包的dump 和load 功能來完成。
考慮下面的示例,我們將儲存上面訓練的模型 (classifier_knn) 以供將來使用 -
from sklearn.externals import joblib joblib.dump(classifier_knn, 'iris_classifier_knn.joblib')
上面的程式碼會將模型儲存到名為 iris_classifier_knn.joblib 的檔案中。現在,可以使用以下程式碼從檔案中重新載入該物件 -
joblib.load('iris_classifier_knn.joblib')
資料預處理
由於我們處理大量原始資料,在將資料輸入機器學習演算法之前,我們需要將其轉換為有意義的資料。這個過程稱為資料預處理。Scikit-learn 有一個名為preprocessing 的包用於此目的。preprocessing 包具有以下技術 -
二值化
當我們需要將數值轉換為布林值時,使用此預處理技術。
示例
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]]
)
data_binarized = preprocessing.Binarizer(threshold=0.5).transform(input_data)
print("\nBinarized data:\n", data_binarized)
在上例中,我們使用閾值 = 0.5,因此所有大於 0.5 的值將轉換為 1,所有小於 0.5 的值將轉換為 0。
輸出
Binarized data: [ [ 1. 0. 1.] [ 0. 1. 1.] [ 0. 0. 1.] [ 1. 1. 0.] ]
均值移除
此技術用於消除特徵向量中的均值,以便每個特徵都以零為中心。
示例
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]]
)
#displaying the mean and the standard deviation of the input data
print("Mean =", input_data.mean(axis=0))
print("Stddeviation = ", input_data.std(axis=0))
#Removing the mean and the standard deviation of the input data
data_scaled = preprocessing.scale(input_data)
print("Mean_removed =", data_scaled.mean(axis=0))
print("Stddeviation_removed =", data_scaled.std(axis=0))
輸出
Mean = [ 1.75 -1.275 2.2 ] Stddeviation = [ 2.71431391 4.20022321 4.69414529] Mean_removed = [ 1.11022302e-16 0.00000000e+00 0.00000000e+00] Stddeviation_removed = [ 1. 1. 1.]
縮放
我們使用此預處理技術來縮放特徵向量。特徵向量的縮放很重要,因為特徵不應人為地過大或過小。
示例
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]
]
)
data_scaler_minmax = preprocessing.MinMaxScaler(feature_range=(0,1))
data_scaled_minmax = data_scaler_minmax.fit_transform(input_data)
print ("\nMin max scaled data:\n", data_scaled_minmax)
輸出
Min max scaled data: [ [ 0.48648649 0.58252427 0.99122807] [ 0. 1. 0.81578947] [ 0.27027027 0. 1. ] [ 1. 0.99029126 0. ] ]
歸一化
我們使用此預處理技術來修改特徵向量。特徵向量的歸一化是必要的,以便可以以共同的尺度測量特徵向量。歸一化有兩種型別,如下所示 -
L1 歸一化
也稱為最小絕對偏差。它以這樣的方式修改值,使得每一行中絕對值的總和始終保持為 1。以下示例顯示了在輸入資料上實現 L1 歸一化的過程。
示例
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]
]
)
data_normalized_l1 = preprocessing.normalize(input_data, norm='l1')
print("\nL1 normalized data:\n", data_normalized_l1)
輸出
L1 normalized data: [ [ 0.22105263 -0.2 0.57894737] [-0.2027027 0.32432432 0.47297297] [ 0.03571429 -0.56428571 0.4 ] [ 0.42142857 0.16428571 -0.41428571] ]
L2 歸一化
也稱為最小二乘法。它以這樣的方式修改值,使得每一行的平方和始終保持為1。以下示例顯示了在輸入資料上實現L2歸一化的過程。
示例
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]
]
)
data_normalized_l2 = preprocessing.normalize(input_data, norm='l2')
print("\nL1 normalized data:\n", data_normalized_l2)
輸出
L2 normalized data: [ [ 0.33946114 -0.30713151 0.88906489] [-0.33325106 0.53320169 0.7775858 ] [ 0.05156558 -0.81473612 0.57753446] [ 0.68706914 0.26784051 -0.6754239 ] ]
Scikit Learn - 資料表示
眾所周知,機器學習是關於從資料中建立模型的。為此,計算機必須首先理解資料。接下來,我們將討論各種表示資料的方法,以便計算機能夠理解——
資料表示為表格
在Scikit-learn中表示資料的最佳方法是表格形式。表格表示一個二維資料網格,其中行代表資料集的單個元素,列代表與這些單個元素相關的量。
示例
透過以下示例,我們可以使用python的seaborn庫,將iris資料集下載為Pandas DataFrame的形式。
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()
輸出
sepal_length sepal_width petal_length petal_width species 0 5.1 3.5 1.4 0.2 setosa 1 4.9 3.0 1.4 0.2 setosa 2 4.7 3.2 1.3 0.2 setosa 3 4.6 3.1 1.5 0.2 setosa 4 5.0 3.6 1.4 0.2 setosa
從上面的輸出中,我們可以看到資料的每一行代表一朵觀察到的花,行數代表資料集中花的總數。通常,我們將矩陣的行稱為樣本。
另一方面,資料的每一列代表描述每個樣本的定量資訊。通常,我們將矩陣的列稱為特徵。
資料作為特徵矩陣
特徵矩陣可以定義為表格佈局,其中資訊可以被認為是一個二維矩陣。它儲存在一個名為X的變數中,並假設它是一個二維矩陣,形狀為[n_samples, n_features]。它通常包含在NumPy陣列或Pandas DataFrame中。如前所述,樣本始終代表資料集描述的單個物件,而特徵則以定量方式描述每個樣本的不同觀察結果。
資料作為目標陣列
除了用X表示的特徵矩陣外,我們還有目標陣列。它也稱為標籤,用y表示。標籤或目標陣列通常是一維的,長度為n_samples。它通常包含在NumPy array或Pandas Series中。目標陣列可以同時具有連續數值和離散值。
目標陣列與特徵列有何不同?
我們可以透過一點來區分兩者,即目標陣列通常是我們想要從資料中預測的量,即在統計術語中它是因變數。
示例
在下面的例子中,從iris資料集中,我們根據其他測量結果來預測花的種類。在這種情況下,Species列將被視為特徵。
import seaborn as sns
iris = sns.load_dataset('iris')
%matplotlib inline
import seaborn as sns; sns.set()
sns.pairplot(iris, hue='species', height=3);
輸出
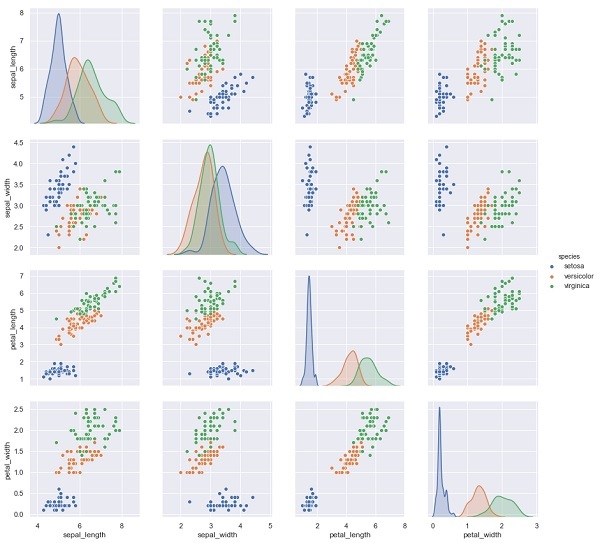
X_iris = iris.drop('species', axis=1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
輸出
(150,4) (150,)
Scikit Learn - 估計器 API
在本章中,我們將學習估計器API(應用程式程式設計介面)。讓我們從瞭解什麼是估計器API開始。
什麼是估計器API
它是Scikit-learn實現的主要API之一。它為廣泛的機器學習應用提供了一個一致的介面,這就是為什麼Scikit-Learn中的所有機器學習演算法都是透過估計器API實現的。從資料中學習(擬合數據)的物件是一個估計器。它可以與任何演算法一起使用,例如分類、迴歸、聚類,甚至與轉換器一起使用,轉換器可以從原始資料中提取有用的特徵。
為了擬合數據,所有估計器物件都公開了一個fit方法,如下所示:
estimator.fit(data)
接下來,所有估計器的引數都可以在例項化時透過相應的屬性設定,如下所示。
estimator = Estimator (param1=1, param2=2) estimator.param1
上述結果將為1。
一旦資料與估計器擬合,引數就會根據現有的資料進行估計。現在,所有估計的引數都將是估計器物件的屬性,以下劃線結尾,如下所示:
estimator.estimated_param_
估計器API的用途
估計器的主要用途如下:
模型的估計和解碼
估計器物件用於模型的估計和解碼。此外,模型被估計為以下內容的確定性函式:
在物件構造中提供的引數。
如果估計器的random_state引數設定為None,則為全域性隨機狀態(numpy.random)。
傳遞給最近一次呼叫fit、fit_transform或fit_predict的任何資料。
傳遞給一系列partial_fit呼叫的任何資料。
將非矩形資料表示對映到矩形資料
它將非矩形資料表示對映到矩形資料。簡單來說,它接收輸入,其中每個樣本不表示為固定長度的類似陣列的物件,併為每個樣本生成一個類似陣列的特徵物件。
核心樣本和異常樣本之間的區別
它使用以下方法對核心樣本和異常樣本之間的區別進行建模:
fit
如果為轉導式,則為fit_predict
如果為歸納式,則為predict
指導原則
在設計Scikit-Learn API時,考慮了以下指導原則:
一致性
此原則指出,所有物件都應共享一個從有限方法集中提取的通用介面。文件也應該保持一致。
有限的物件層次結構
此指導原則指出:
演算法應由Python類表示。
資料集應以標準格式表示,例如NumPy陣列、Pandas DataFrame、SciPy稀疏矩陣。
引數名稱應使用標準Python字串。
組合
眾所周知,機器學習演算法可以表示為許多基本演算法的序列。Scikit-learn在需要時會使用這些基本演算法。
合理的預設值
根據此原則,Scikit-learn庫在機器學習模型需要使用者指定引數時定義一個合適的預設值。
檢查
根據此指導原則,每個指定的引數值都作為公共屬性公開。
使用估計器API的步驟
以下是使用Scikit-Learn估計器API的步驟:
步驟1:選擇模型類別
在第一步中,我們需要選擇一個模型類別。這可以透過從Scikit-learn匯入相應的估計器類來完成。
步驟2:選擇模型超引數
在此步驟中,我們需要選擇類模型超引數。這可以透過使用所需的值例項化類來完成。
步驟3:整理資料
接下來,我們需要將資料整理成特徵矩陣(X)和目標向量(y)。
步驟4:模型擬合
現在,我們需要將模型擬合到您的資料。這可以透過呼叫模型例項的fit()方法來完成。
步驟5:應用模型
擬合模型後,我們可以將其應用於新資料。對於監督學習,使用predict()方法預測未知資料的標籤。而對於無監督學習,使用predict()或transform()來推斷資料的屬性。
監督學習示例
在這裡,作為此過程的一個示例,我們採用將直線擬合到(x,y)資料(即簡單線性迴歸)的常見情況。
首先,我們需要載入資料集,我們使用iris資料集:
示例
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
輸出
(150, 4)
示例
y_iris = iris['species'] y_iris.shape
輸出
(150,)
示例
現在,對於這個迴歸示例,我們將使用以下樣本資料:
%matplotlib inline import matplotlib.pyplot as plt import numpy as np rng = np.random.RandomState(35) x = 10*rng.rand(40) y = 2*x-1+rng.randn(40) plt.scatter(x,y);
輸出

因此,我們有上述資料用於我們的線性迴歸示例。
現在,使用此資料,我們可以應用上述步驟。
選擇模型類別
在這裡,為了計算簡單的線性迴歸模型,我們需要匯入線性迴歸類,如下所示:
from sklearn.linear_model import LinearRegression
選擇模型超引數
一旦我們選擇了一個模型類別,我們需要做出一些重要的選擇,這些選擇通常表示為超引數,或者必須在模型擬合到資料之前設定的引數。在這裡,對於這個線性迴歸示例,我們想使用fit_intercept超引數來擬合截距,如下所示:
示例
model = LinearRegression(fit_intercept = True) model
輸出
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None, normalize = False)
整理資料
現在,我們知道我們的目標變數y處於正確的形式,即長度為n_samples的一維陣列。但是,我們需要重塑特徵矩陣X,使其成為大小為[n_samples, n_features]的矩陣。這可以如下完成:
示例
X = x[:, np.newaxis] X.shape
輸出
(40, 1)
模型擬合
一旦我們整理好資料,就該擬合模型了,即,將我們的模型應用於資料。這可以藉助fit()方法完成,如下所示:
示例
model.fit(X, y)
輸出
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None,normalize = False)
在Scikit-learn中,fit()過程有一些尾隨下劃線。
對於此示例,以下引數顯示了資料簡單線性擬合的斜率:
示例
model.coef_
輸出
array([1.99839352])
以下引數表示對資料的簡單線性擬合的截距:
示例
model.intercept_
輸出
-0.9895459457775022
將模型應用於新資料
訓練模型後,我們可以將其應用於新資料。監督機器學習的主要任務是根據不是訓練集一部分的新資料來評估模型。這可以藉助predict()方法完成,如下所示:
示例
xfit = np.linspace(-1, 11) Xfit = xfit[:, np.newaxis] yfit = model.predict(Xfit) plt.scatter(x, y) plt.plot(xfit, yfit);
輸出

完整的可執行示例
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model
X = x[:, np.newaxis]
X.shape
model.fit(X, y)
model.coef_
model.intercept_
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit);
無監督學習示例
在這裡,作為此過程的一個示例,我們採用降低Iris資料集維數的常見情況,以便我們可以更輕鬆地對其進行視覺化。對於此示例,我們將使用主成分分析 (PCA),這是一種快速的線性降維技術。
像上面給出的示例一樣,我們可以載入並繪製來自iris資料集的隨機資料。之後,我們可以按照以下步驟操作:
選擇模型類別
from sklearn.decomposition import PCA
選擇模型超引數
示例
model = PCA(n_components=2) model
輸出
PCA(copy = True, iterated_power = 'auto', n_components = 2, random_state = None, svd_solver = 'auto', tol = 0.0, whiten = False)
模型擬合
示例
model.fit(X_iris)
輸出
PCA(copy = True, iterated_power = 'auto', n_components = 2, random_state = None, svd_solver = 'auto', tol = 0.0, whiten = False)
將資料轉換為二維
示例
X_2D = model.transform(X_iris)
現在,我們可以繪製結果,如下所示:
輸出
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue = 'species', data = iris, fit_reg = False);
輸出

完整的可執行示例
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.decomposition import PCA
model = PCA(n_components=2)
model
model.fit(X_iris)
X_2D = model.transform(X_iris)
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue='species', data=iris, fit_reg=False);
Scikit Learn - 約定
Scikit-learn的物件共享一個統一的基本API,它包含以下三個互補介面:
估計器介面 - 用於構建和擬合模型。
預測器介面 - 用於進行預測。
轉換器介面 - 用於轉換資料。
這些API採用簡單的約定,設計選擇以避免框架程式碼的激增為指導。
約定的目的
約定的目的是確保API遵循以下廣泛的原則:
一致性 - 所有物件,無論是基本物件還是複合物件,都必須共享一個一致的介面,該介面進一步由有限的一組方法組成。
檢查 - 建構函式引數和學習演算法確定的引數值應儲存並作為公共屬性公開。
避免類激增 - 資料集應表示為NumPy陣列或Scipy稀疏矩陣,而超引數名稱和值應表示為標準Python字串,以避免框架程式碼的激增。
組合 - 無論演算法是表示為資料轉換的序列或組合,還是自然地被視為引數化在其他演算法上的元演算法,都應使用現有的構建塊進行實現和組合。
合理的預設值 - 在scikit-learn中,每當操作需要使用者定義的引數時,都會定義一個合適的預設值。此預設值應導致操作以合理的方式執行,例如,為手頭的任務提供基線解決方案。
各種約定
Sklearn中可用的約定解釋如下:
型別轉換
文件說明輸入應轉換為float64型別。以下示例將解釋如何使用sklearn.random_projection模組降低資料的維度。
示例
import numpy as np from sklearn import random_projection rannge = np.random.RandomState(0) X = range.rand(10,2000) X = np.array(X, dtype = 'float32') X.dtype Transformer_data = random_projection.GaussianRandomProjection() X_new = transformer.fit_transform(X) X_new.dtype
輸出
dtype('float32')
dtype('float64')
在上述示例中,我們可以看到X是float32型別,透過fit_transform(X)轉換為float64型別。
重新擬合和更新引數
估計器的超引數可以在構造後透過set_params()方法更新和重新擬合。讓我們看下面的例子來理解它。
示例
import numpy as np from sklearn.datasets import load_iris from sklearn.svm import SVC X, y = load_iris(return_X_y = True) clf = SVC() clf.set_params(kernel = 'linear').fit(X, y) clf.predict(X[:5])
輸出
array([0, 0, 0, 0, 0])
估計器構造完成後,上面的程式碼將透過SVC.set_params()將預設核心rbf更改為線性。
現在,下面的程式碼將把核心改回rbf以重新擬合估計器並進行第二次預測。
示例
clf.set_params(kernel = 'rbf', gamma = 'scale').fit(X, y) clf.predict(X[:5])
輸出
array([0, 0, 0, 0, 0])
完整程式碼
以下是完整的可執行程式。
import numpy as np from sklearn.datasets import load_iris from sklearn.svm import SVC X, y = load_iris(return_X_y = True) clf = SVC() clf.set_params(kernel = 'linear').fit(X, y) clf.predict(X[:5]) clf.set_params(kernel = 'rbf', gamma = 'scale').fit(X, y) clf.predict(X[:5])
多類別和多標籤擬合
在多類別擬合的情況下,學習和預測任務都取決於所擬合目標資料的格式。使用的模組是sklearn.multiclass。請檢視下面的示例,其中多類別分類器擬合在一維陣列上。
示例
from sklearn.svm import SVC from sklearn.multiclass import OneVsRestClassifier from sklearn.preprocessing import LabelBinarizer X = [[1, 2], [3, 4], [4, 5], [5, 2], [1, 1]] y = [0, 0, 1, 1, 2] classif = OneVsRestClassifier(estimator = SVC(gamma = 'scale',random_state = 0)) classif.fit(X, y).predict(X)
輸出
array([0, 0, 1, 1, 2])
在上面的例子中,分類器擬合在多類別標籤的一維陣列上,因此predict()方法提供了相應的多類別預測。但另一方面,也可以擬合在二維的二元標籤指示器陣列上,如下所示:
示例
from sklearn.svm import SVC from sklearn.multiclass import OneVsRestClassifier from sklearn.preprocessing import LabelBinarizer X = [[1, 2], [3, 4], [4, 5], [5, 2], [1, 1]] y = LabelBinarizer().fit_transform(y) classif.fit(X, y).predict(X)
輸出
array(
[
[0, 0, 0],
[0, 0, 0],
[0, 1, 0],
[0, 1, 0],
[0, 0, 0]
]
)
類似地,在多標籤擬合的情況下,一個例項可以被賦予多個標籤,如下所示:
示例
from sklearn.preprocessing import MultiLabelBinarizer y = [[0, 1], [0, 2], [1, 3], [0, 2, 3], [2, 4]] y = MultiLabelBinarizer().fit_transform(y) classif.fit(X, y).predict(X)
輸出
array(
[
[1, 0, 1, 0, 0],
[1, 0, 1, 0, 0],
[1, 0, 1, 1, 0],
[1, 0, 1, 1, 0],
[1, 0, 1, 0, 0]
]
)
在上面的示例中,sklearn.MultiLabelBinarizer用於將多標籤的二維陣列二值化以進行擬合。這就是為什麼predict()函式輸出一個二維陣列,其中每個例項都有多個標籤。
Scikit Learn - 線性模型
本章將幫助您學習Scikit-Learn中的線性建模。讓我們首先了解Sklearn中的線性迴歸是什麼。
下表列出了Scikit-Learn提供的各種線性模型:
| 序號 | 模型和描述 |
|---|---|
| 1 |
這是最好的統計模型之一,它研究因變數(Y)與給定的一組自變數(X)之間的關係。 |
| 2 |
邏輯迴歸,儘管其名稱如此,但它是一種分類演算法,而不是迴歸演算法。基於給定的一組自變數,它用於估計離散值(0或1,是/否,真/假)。 |
| 3 |
嶺迴歸或Tikhonov正則化是一種正則化技術,它執行L2正則化。它透過新增等於係數大小平方的懲罰(收縮量)來修改損失函式。 |
| 4 |
貝葉斯迴歸允許使用機率分佈器而不是點估計來制定線性迴歸,從而提供了一種自然的機制來應對資料不足或資料分佈不佳的情況。 |
| 5 |
LASSO是一種執行L1正則化的正則化技術。它透過新增等於係數絕對值之和的懲罰(收縮量)來修改損失函式。 |
| 6 |
它允許聯合擬合多個迴歸問題,強制所有迴歸問題(也稱為任務)的選擇特徵相同。Sklearn提供了一個名為MultiTaskLasso的線性模型,它使用混合L1、L2範數進行正則化訓練,從而聯合估計多個迴歸問題的稀疏係數。 |
| 7 |
彈性網路是一種正則化迴歸方法,它線性組合LASSO和嶺迴歸方法的兩種懲罰,即L1和L2。當存在多個相關特徵時,它非常有用。 |
| 8 |
這是一個彈性網路模型,允許聯合擬合多個迴歸問題,強制所有迴歸問題(也稱為任務)的選擇特徵相同。 |
Scikit Learn - 擴充套件線性模型
本章重點介紹Sklearn中的多項式特徵和管道工具。
多項式特徵介紹
在資料的非線性函式上訓練的線性模型通常保持線性方法的快速效能。它還允許它們擬合更廣泛的資料範圍。這就是為什麼在機器學習中使用這種在非線性函式上訓練的線性模型的原因。
一個例子是,可以透過從係數構造多項式特徵來擴充套件簡單的線性迴歸。
數學上,假設我們有標準線性迴歸模型,那麼對於二維資料,它看起來像這樣:
$$Y=W_{0}+W_{1}X_{1}+W_{2}X_{2}$$現在,我們可以將特徵組合在二階多項式中,我們的模型將如下所示:
$$Y=W_{0}+W_{1}X_{1}+W_{2}X_{2}+W_{3}X_{1}X_{2}+W_{4}X_1^2+W_{5}X_2^2$$上面仍然是一個線性模型。在這裡,我們看到由此產生的多項式迴歸屬於線性模型的同一類,並且可以類似地求解。
為此,scikit-learn提供了一個名為PolynomialFeatures的模組。此模組將輸入資料矩陣轉換為給定次數的新資料矩陣。
引數
下表包含PolynomialFeatures模組使用的引數
| 序號 | 引數和描述 |
|---|---|
| 1 |
degree − 整數,預設值 = 2 它表示多項式特徵的次數。 |
| 2 |
interaction_only − 布林值,預設值 = false 預設情況下,它是false,但如果設定為true,則會生成大多數次數不同的輸入特徵的乘積特徵。這些特徵稱為互動特徵。 |
| 3 |
include_bias − 布林值,預設值 = true 它包括一個偏差列,即所有多項式冪都為零的特徵。 |
| 4 |
order − str in {‘C’, ‘F’},預設值 = ‘C’ 此引數表示密集情況下輸出陣列的順序。’F’順序意味著計算速度更快,但另一方面,它可能會減慢後續估計器的速度。 |
屬性
下表包含PolynomialFeatures模組使用的屬性
| 序號 | 屬性和描述 |
|---|---|
| 1 |
powers_ − 陣列,形狀 (n_output_features, n_input_features) 它顯示powers_[i,j]是第i個輸出中第j個輸入的指數。 |
| 2 |
n_input_features_ − int 顧名思義,它給出輸入特徵的總數。 |
| 3 |
n_output_features_ − int 顧名思義,它給出多項式輸出特徵的總數。 |
實現示例
下面的Python指令碼使用PolynomialFeatures轉換器將8的陣列轉換為形狀(4,2):
from sklearn.preprocessing import PolynomialFeatures import numpy as np Y = np.arange(8).reshape(4, 2) poly = PolynomialFeatures(degree=2) poly.fit_transform(Y)
輸出
array(
[
[ 1., 0., 1., 0., 0., 1.],
[ 1., 2., 3., 4., 6., 9.],
[ 1., 4., 5., 16., 20., 25.],
[ 1., 6., 7., 36., 42., 49.]
]
)
使用管道工具簡化流程
上述預處理,即,將輸入資料矩陣轉換為給定次數的新資料矩陣,可以使用Pipeline工具簡化,這些工具基本上用於將多個估計器連結到一個。
示例
下面的python指令碼使用Scikit-learn的管道工具來簡化預處理(將擬合到三階多項式資料)。
#First, import the necessary packages.
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
import numpy as np
#Next, create an object of Pipeline tool
Stream_model = Pipeline([('poly', PolynomialFeatures(degree=3)), ('linear', LinearRegression(fit_intercept=False))])
#Provide the size of array and order of polynomial data to fit the model.
x = np.arange(5)
y = 3 - 2 * x + x ** 2 - x ** 3
Stream_model = model.fit(x[:, np.newaxis], y)
#Calculate the input polynomial coefficients.
Stream_model.named_steps['linear'].coef_
輸出
array([ 3., -2., 1., -1.])
上面的輸出顯示,在多項式特徵上訓練的線性模型能夠恢復精確的輸入多項式係數。
Scikit Learn - 隨機梯度下降
在這裡,我們將學習Sklearn中的一種最佳化演算法,稱為隨機梯度下降 (SGD)。
隨機梯度下降 (SGD) 是一種簡單而有效的最佳化演算法,用於查詢函式的引數/係數的值,以最小化成本函式。換句話說,它用於在凸損失函式(例如 SVM 和邏輯迴歸)下進行線性分類器的判別學習。它已成功應用於大規模資料集,因為對係數的更新是在每個訓練例項中執行的,而不是在例項結束時執行。
SGD 分類器
隨機梯度下降 (SGD) 分類器基本上實現了一個簡單的 SGD 學習例程,支援各種用於分類的損失函式和懲罰。Scikit-learn 提供SGDClassifier模組來實現 SGD 分類。
引數
下表包含SGDClassifier模組使用的引數:
| 序號 | 引數和描述 |
|---|---|
| 1 |
loss − str,預設值 = ‘hinge’ 它表示實現時要使用的損失函式。預設值為“hinge”,這將給我們一個線性 SVM。可以使用的其他選項包括:
|
| 2 |
penalty − str,‘none’,‘l2’,‘l1’,‘elasticnet’ 它是模型中使用的正則化項。預設情況下,它是 L2。我們也可以使用 L1 或“elasticnet;但兩者都可能使模型稀疏,因此無法使用 L2 實現。 |
| 3 |
alpha − float,預設值 = 0.0001 Alpha,乘以正則化項的常數,是一個調整引數,它決定我們想要懲罰模型的程度。預設值為 0.0001。 |
| 4 |
l1_ratio − float,預設值 = 0.15 這稱為 ElasticNet 混合引數。其範圍為 0 <= l1_ratio <= 1。如果 l1_ratio = 1,則懲罰將是 L1 懲罰。如果 l1_ratio = 0,則懲罰將是 L2 懲罰。 |
| 5 |
fit_intercept − 布林值,預設值 = True 此引數指定應向決策函式新增常數(偏差或截距)。如果將其設定為 false,則計算中不會使用截距,並且將假設資料已居中。 |
| 6 |
tol − float 或 none,可選,預設值 = 1.e-3 此引數表示迭代的停止條件。其預設值為 False,但如果設定為 None,則當 𝒍loss > best_loss - tol 連續 n_iter_no_change 個時期時,迭代將停止。 |
| 7 |
shuffle − 布林值,可選,預設值 = True 此引數表示我們是否希望在每個時期之後對訓練資料進行洗牌。 |
| 8 |
verbose − 整數,預設值 = 0 它表示詳細程度。其預設值為 0。 |
| 9 |
epsilon − float,預設值 = 0.1 此引數指定不敏感區域的寬度。如果 loss = ‘epsilon-insensitive’,則當前預測與正確標籤之間的任何差異小於閾值都將被忽略。 |
| 10 |
max_iter − int,可選,預設值 = 1000 顧名思義,它表示對時期(即訓練資料)的最大迭代次數。 |
| 11 |
warm_start − bool,可選,預設值 = false 將此引數設定為 True,我們可以重用對 fit 的先前呼叫的解決方案作為初始化。如果我們選擇預設值 false,它將擦除以前的解決方案。 |
| 12 |
random_state − int,RandomState 例項或 None,可選,預設值 = none 此引數表示用於對資料進行洗牌的偽隨機數生成的種子。以下是選項:
|
| 13 |
n_jobs − int 或 none,可選,預設值 = None 它表示用於多類別問題的 OVA(一對多)計算的 CPU 數量。預設值為 none,這意味著 1。 |
| 14 |
learning_rate − string,可選,預設值 = ‘optimal’
|
| 15 |
eta0 − double,預設值 = 0.0 它表示上述學習率選項(即“constant”、“invscalling”或“adaptive”)的初始學習率。 |
| 16 |
power_t − idouble,預設值 =0.5 它是“incscalling”學習率的指數。 |
| 17 |
early_stopping − bool,預設值 = False 此引數表示是否使用提前停止策略,當驗證分數不再提高時終止訓練。其預設值為false,但當設定為true時,它會自動將訓練資料的一部分(分層抽樣)作為驗證集,並在驗證分數不再提高時停止訓練。 |
| 18 |
validation_fraction − 浮點數,預設值 = 0.1 僅在early_stopping為true時使用。它表示用於提前停止訓練而預留的驗證集所佔訓練資料的比例。 |
| 19 |
n_iter_no_change − 整數,預設值=5 它表示演算法在提前停止前允許執行多少次迭代而不改進。 |
| 20 |
class_weight − 字典,{class_label: weight} 或 “balanced”,或 None,可選 此引數表示與各類別相關的權重。如果沒有提供,則假定所有類別的權重為1。 |
| 20 |
warm_start − bool,可選,預設值 = false 將此引數設定為 True,我們可以重用對 fit 的先前呼叫的解決方案作為初始化。如果我們選擇預設值 false,它將擦除以前的解決方案。 |
| 21 |
average − 布林值或整數,可選,預設值 = false 它表示用於多類別問題的 OVA(一對多)計算的 CPU 數量。預設值為 none,這意味著 1。 |
屬性
下表列出了SGDClassifier模組使用的屬性 −
| 序號 | 屬性和描述 |
|---|---|
| 1 |
coef_ − 陣列,形狀為(1, n_features)(如果n_classes==2),否則為(n_classes, n_features) 此屬性提供了分配給特徵的權重。 |
| 2 |
intercept_ − 陣列,形狀為(1,)(如果n_classes==2),否則為(n_classes,) 它表示決策函式中的常數項。 |
| 3 |
n_iter_ − 整數 它給出達到停止準則所需的迭代次數。 |
實現示例
與其他分類器一樣,隨機梯度下降 (SGD) 必須使用以下兩個陣列進行擬合 −
一個名為X的陣列,包含訓練樣本。其大小為[n_samples, n_features]。
一個名為Y的陣列,包含目標值,即訓練樣本的類別標籤。其大小為[n_samples]。
示例
下面的Python指令碼使用SGDClassifier線性模型 −
import numpy as np from sklearn import linear_model X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]]) Y = np.array([1, 1, 2, 2]) SGDClf = linear_model.SGDClassifier(max_iter = 1000, tol=1e-3,penalty = "elasticnet") SGDClf.fit(X, Y)
輸出
SGDClassifier( alpha = 0.0001, average = False, class_weight = None, early_stopping = False, epsilon = 0.1, eta0 = 0.0, fit_intercept = True, l1_ratio = 0.15, learning_rate = 'optimal', loss = 'hinge', max_iter = 1000, n_iter = None, n_iter_no_change = 5, n_jobs = None, penalty = 'elasticnet', power_t = 0.5, random_state = None, shuffle = True, tol = 0.001, validation_fraction = 0.1, verbose = 0, warm_start = False )
示例
現在,擬合完成後,模型可以預測新值,如下所示 −
SGDClf.predict([[2.,2.]])
輸出
array([2])
示例
對於上述示例,我們可以使用以下Python指令碼獲取權重向量 −
SGDClf.coef_
輸出
array([[19.54811198, 9.77200712]])
示例
同樣,我們可以使用以下Python指令碼獲取截距值 −
SGDClf.intercept_
輸出
array([10.])
示例
我們可以使用SGDClassifier.decision_function獲取到超平面的帶符號距離,如下面的Python指令碼所示 −
SGDClf.decision_function([[2., 2.]])
輸出
array([68.6402382])
SGD迴歸器
隨機梯度下降 (SGD) 迴歸器基本上實現了一個簡單的SGD學習程式,支援各種損失函式和懲罰項以擬合線性迴歸模型。Scikit-learn 提供SGDRegressor模組來實現SGD迴歸。
引數
SGDRegressor使用的引數與SGDClassifier模組中使用的引數幾乎相同。區別在於“loss”引數。對於SGDRegressor模組的loss引數,其有效值為:
squared_loss − 指的是普通最小二乘擬合。
huber: SGDRegressor − 透過在超過epsilon距離後從平方損失切換到線性損失來糾正異常值。“huber”的作用是修改“squared_loss”,以便演算法更少地關注糾正異常值。
epsilon_insensitive − 實際上,它忽略小於epsilon的誤差。
squared_epsilon_insensitive − 與epsilon_insensitive相同。唯一的區別在於,它在超過epsilon的容差後變為平方損失。
另一個區別是名為“power_t”的引數的預設值為0.25,而不是SGDClassifier中的0.5。此外,它沒有“class_weight”和“n_jobs”引數。
屬性
SGDRegressor的屬性也與SGDClassifier模組的屬性相同。它另外還有三個屬性:
average_coef_ − 陣列,形狀為(n_features,)
顧名思義,它提供了分配給特徵的平均權重。
average_intercept_ − 陣列,形狀為(1,)
顧名思義,它提供了平均截距項。
t_ − 整數
它提供了在訓練階段執行的權重更新次數。
注意 − average_coef_ 和 average_intercept_ 屬性只有在將‘average’引數設定為True後才能使用。
實現示例
下面的Python指令碼使用SGDRegressor線性模型 −
import numpy as np from sklearn import linear_model n_samples, n_features = 10, 5 rng = np.random.RandomState(0) y = rng.randn(n_samples) X = rng.randn(n_samples, n_features) SGDReg =linear_model.SGDRegressor( max_iter = 1000,penalty = "elasticnet",loss = 'huber',tol = 1e-3, average = True ) SGDReg.fit(X, y)
輸出
SGDRegressor( alpha = 0.0001, average = True, early_stopping = False, epsilon = 0.1, eta0 = 0.01, fit_intercept = True, l1_ratio = 0.15, learning_rate = 'invscaling', loss = 'huber', max_iter = 1000, n_iter = None, n_iter_no_change = 5, penalty = 'elasticnet', power_t = 0.25, random_state = None, shuffle = True, tol = 0.001, validation_fraction = 0.1, verbose = 0, warm_start = False )
示例
現在,擬合完成後,我們可以使用以下Python指令碼獲取權重向量 −
SGDReg.coef_
輸出
array([-0.00423314, 0.00362922, -0.00380136, 0.00585455, 0.00396787])
示例
同樣,我們可以使用以下Python指令碼獲取截距值 −
SGReg.intercept_
輸出
SGReg.intercept_
示例
我們可以使用以下Python指令碼獲取訓練階段的權重更新次數 −
SGDReg.t_
輸出
61.0
SGD的優缺點
以下是SGD的優點 −
隨機梯度下降 (SGD) 非常高效。
它非常易於實現,因為有很多程式碼調整的機會。
以下是SGD的缺點 −
隨機梯度下降 (SGD) 需要多個超引數,例如正則化引數。
它對特徵縮放敏感。
Scikit Learn - 支援向量機
本章介紹一種稱為支援向量機 (SVM) 的機器學習方法。
簡介
支援向量機 (SVM) 是一種功能強大且靈活的有監督機器學習方法,用於分類、迴歸和異常值檢測。SVM 在高維空間中非常高效,通常用於分類問題。SVM 流行且記憶體效率高,因為它們在決策函式中只使用訓練點的一個子集。
SVM 的主要目標是將資料集劃分成多個類別,以便找到一個最大間隔超平面 (MMH),這可以透過以下兩個步驟完成 −
支援向量機將首先迭代生成超平面,以最佳方式分離類別。
之後,它將選擇能夠正確分離類別的超平面。
SVM 中的一些重要概念如下 −
支援向量 − 可以定義為最接近超平面的資料點。支援向量有助於確定分離線。
超平面 − 分隔具有不同類別的物件集的決策平面或空間。
間隔 − 不同類別最接近資料點之間的兩條線之間的間隙稱為間隔。
下圖將使您深入瞭解這些 SVM 概念 −

Scikit-learn 中的 SVM 支援稀疏和密集樣本向量作為輸入。
SVM 分類
Scikit-learn 提供了三個類,即SVC、NuSVC和LinearSVC,它們可以執行多類分類。
SVC
它是C-支援向量分類,其實現基於libsvm。scikit-learn 使用的模組是sklearn.svm.SVC。此類根據一對一方案處理多類支援。
引數
下表列出了sklearn.svm.SVC類使用的引數 −
| 序號 | 引數和描述 |
|---|---|
| 1 |
C − 浮點數,可選,預設值 = 1.0 它是誤差項的懲罰引數。 |
| 2 |
kernel − 字串,可選,預設值 = ‘rbf’ 此引數指定要在演算法中使用的核心型別。我們可以從‘linear’、‘poly’、‘rbf’、‘sigmoid’、‘precomputed’中選擇一個。核心的預設值為‘rbf’。 |
| 3 |
degree − 整數,可選,預設值 = 3 它表示“poly”核心函式的度數,其他核心將忽略它。 |
| 4 |
gamma − {‘scale’、‘auto’} 或浮點數, 它是核心“rbf”、“poly”和“sigmoid”的核心係數。 |
| 5 |
可選預設值 − = ‘scale’ 如果選擇預設值,即 gamma = ‘scale’,則SVC 使用的 gamma 值為 1/(𝑛_𝑓𝑒𝑎𝑡𝑢𝑟𝑒𝑠∗𝑋.𝑣𝑎𝑟())。 另一方面,如果 gamma = ‘auto’,它使用 1/𝑛_𝑓𝑒𝑎𝑡𝑢𝑟𝑒𝑠。 |
| 6 |
coef0 − 浮點數,可選,預設值=0.0 核心函式中的常數項,僅在“poly”和“sigmoid”中有效。 |
| 7 |
tol − 浮點數,可選,預設值 = 1.e-3 此引數表示迭代的停止準則。 |
| 8 |
shrinking − 布林值,可選,預設值 = True 此引數表示是否要使用收縮啟發式。 |
| 9 |
verbose − 布林值,預設值:false 啟用或停用詳細輸出。其預設值為false。 |
| 10 |
probability − 布林值,可選,預設值 = false 此引數啟用或停用機率估計。預設值為false,但在呼叫fit之前必須啟用它。 |
| 11 |
max_iter − 整數,可選,預設值 = -1 顧名思義,它表示求解器中的最大迭代次數。值為-1表示迭代次數沒有限制。 |
| 12 |
cache_size − 浮點數,可選 此引數將指定核心快取的大小。值為MB(兆位元組)。 |
| 13 |
random_state − int,RandomState 例項或 None,可選,預設值 = none 此引數表示生成的偽隨機數的種子,該種子在洗牌資料時使用。選項如下:
|
| 14 |
class_weight − {字典、‘balanced’},可選 此引數將SVC的第j類的引數C設定為𝑐𝑙𝑎𝑠𝑠_𝑤𝑒𝑖𝑔ℎ𝑡[𝑗]∗𝐶。如果使用預設選項,則表示所有類別的權重都為1。另一方面,如果選擇class_weight:balanced,它將使用y的值來自動調整權重。 |
| 15 |
decision_function_shape − ‘ovo’、‘ovr’,預設值 = ‘ovr’ 此引數將決定演算法是否返回與所有其他分類器形狀相同的‘ovr’(一對多)決策函式,還是libsvm的原始ovo(一對一)決策函式。 |
| 16 |
break_ties − 布林值,可選,預設值 = false True − predict 將根據 decision_function 的置信度值打破平局 False − predict 將返回平局類別中的第一個類別。 |
屬性
下表列出了sklearn.svm.SVC類使用的屬性 −
| 序號 | 屬性和描述 |
|---|---|
| 1 |
support_ − 類陣列,形狀 = [n_SV] 它返回支援向量的索引。 |
| 2 |
support_vectors_ − 類陣列,形狀 = [n_SV, n_features] 它返回支援向量。 |
| 3 |
n_support_ − 類陣列,dtype=int32,形狀 = [n_class] 它表示每個類別的支援向量數量。 |
| 4 |
dual_coef_ − 陣列,形狀 = [n_class-1,n_SV] 這些是決策函式中支援向量的係數。 |
| 5 |
coef_ − 陣列,形狀 = [n_class * (n_class-1)/2, n_features] 此屬性僅線上性核心情況下可用,它提供了分配給特徵的權重。 |
| 6 |
intercept_ − 陣列,形狀 = [n_class * (n_class-1)/2] 它表示決策函式中的常數項。 |
| 7 |
fit_status_ − 整數 如果正確擬合,輸出將為0。如果錯誤擬合,輸出將為1。 |
| 8 |
classes_ − 形狀為[n_classes]的陣列 它給出類別的標籤。 |
實現示例
與其他分類器一樣,SVC 也必須使用以下兩個陣列進行擬合 −
一個名為X的陣列,包含訓練樣本。其大小為[n_samples, n_features]。
一個名為Y的陣列,包含目標值,即訓練樣本的類別標籤。其大小為[n_samples]。
下面的Python指令碼使用sklearn.svm.SVC類 −
import numpy as np X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]]) y = np.array([1, 1, 2, 2]) from sklearn.svm import SVC SVCClf = SVC(kernel = 'linear',gamma = 'scale', shrinking = False,) SVCClf.fit(X, y)
輸出
SVC(C = 1.0, cache_size = 200, class_weight = None, coef0 = 0.0, decision_function_shape = 'ovr', degree = 3, gamma = 'scale', kernel = 'linear', max_iter = -1, probability = False, random_state = None, shrinking = False, tol = 0.001, verbose = False)
示例
現在,擬合完成後,我們可以使用以下Python指令碼獲取權重向量 −
SVCClf.coef_
輸出
array([[0.5, 0.5]])
示例
同樣,我們可以獲取其他屬性的值,如下所示 −
SVCClf.predict([[-0.5,-0.8]])
輸出
array([1])
示例
SVCClf.n_support_
輸出
array([1, 1])
示例
SVCClf.support_vectors_
輸出
array(
[
[-1., -1.],
[ 1., 1.]
]
)
示例
SVCClf.support_
輸出
array([0, 2])
示例
SVCClf.intercept_
輸出
array([-0.])
示例
SVCClf.fit_status_
輸出
0
NuSVC
NuSVC 是 Nu 支援向量分類。它是scikit-learn提供的另一個可以執行多類分類的類。它類似於SVC,但NuSVC接受略微不同的引數集。與SVC不同的引數如下:
nu − 浮點數,可選,預設值 = 0.5
它表示訓練錯誤比例的上限和支援向量比例的下限。其值應在 (0,1] 區間內。
其餘引數和屬性與 SVC 相同。
實現示例
我們也可以使用sklearn.svm.NuSVC類實現相同的示例。
import numpy as np X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]]) y = np.array([1, 1, 2, 2]) from sklearn.svm import NuSVC NuSVCClf = NuSVC(kernel = 'linear',gamma = 'scale', shrinking = False,) NuSVCClf.fit(X, y)
輸出
NuSVC(cache_size = 200, class_weight = None, coef0 = 0.0, decision_function_shape = 'ovr', degree = 3, gamma = 'scale', kernel = 'linear', max_iter = -1, nu = 0.5, probability = False, random_state = None, shrinking = False, tol = 0.001, verbose = False)
我們可以像 SVC 那樣獲取其餘屬性的輸出。
LinearSVC
它是線性支援向量分類器。它類似於具有 kernel = 'linear' 的 SVC。它們的區別在於LinearSVC基於liblinear實現,而SVC基於libsvm實現。這就是LinearSVC在懲罰項和損失函式的選擇上具有更大靈活性的原因。它也更能適應大量的樣本。
如果我們談論它的引數和屬性,它不支援'kernel',因為它被假定為線性,並且它也缺少一些屬性,例如support_,support_vectors_,n_support_,fit_status_和dual_coef_。
但是,它支援penalty和loss引數,如下所示:
penalty − 字串,L1 或 L2(預設 = 'L2')
此引數用於指定懲罰(正則化)中使用的範數(L1 或 L2)。
loss − 字串,hinge,squared_hinge(預設 = squared_hinge)
它表示損失函式,其中 'hinge' 是標準 SVM 損失,'squared_hinge' 是 hinge 損失的平方。
實現示例
以下 Python 指令碼使用sklearn.svm.LinearSVC類:
from sklearn.svm import LinearSVC from sklearn.datasets import make_classification X, y = make_classification(n_features = 4, random_state = 0) LSVCClf = LinearSVC(dual = False, random_state = 0, penalty = 'l1',tol = 1e-5) LSVCClf.fit(X, y)
輸出
LinearSVC(C = 1.0, class_weight = None, dual = False, fit_intercept = True, intercept_scaling = 1, loss = 'squared_hinge', max_iter = 1000, multi_class = 'ovr', penalty = 'l1', random_state = 0, tol = 1e-05, verbose = 0)
示例
現在,擬合完成後,模型可以預測新值,如下所示 −
LSVCClf.predict([[0,0,0,0]])
輸出
[1]
示例
對於上述示例,我們可以使用以下Python指令碼獲取權重向量 −
LSVCClf.coef_
輸出
[[0. 0. 0.91214955 0.22630686]]
示例
同樣,我們可以使用以下Python指令碼獲取截距值 −
LSVCClf.intercept_
輸出
[0.26860518]
SVM 迴歸
如前所述,SVM 用於分類和迴歸問題。Scikit-learn 的支援向量分類 (SVC) 方法也可以擴充套件到解決迴歸問題。這種擴充套件的方法稱為支援向量迴歸 (SVR)。
SVM 和 SVR 的基本相似性
SVC 建立的模型僅依賴於訓練資料的一個子集。為什麼?因為構建模型的成本函式並不關心位於邊界之外的訓練資料點。
而 SVR(支援向量迴歸)生成的模型也僅依賴於訓練資料的一個子集。為什麼?因為構建模型的成本函式忽略了任何接近模型預測的訓練資料點。
Scikit-learn 提供三個類,即SVR、NuSVR 和 LinearSVR,作為 SVR 的三種不同實現。
SVR
它是 Epsilon-支援向量迴歸,其實現基於libsvm。與SVC相反,模型中有兩個自由引數,即'C'和'epsilon'。
epsilon − 浮點數,可選,預設 = 0.1
它表示 epsilon-SVR 模型中的 epsilon,並指定 epsilon 管,在該管內,訓練損失函式中與預測值與實際值距離在 epsilon 之內的點沒有關聯的懲罰。
其餘引數和屬性與我們在SVC中使用的相似。
實現示例
以下 Python 指令碼使用sklearn.svm.SVR類:
from sklearn import svm X = [[1, 1], [2, 2]] y = [1, 2] SVRReg = svm.SVR(kernel = ’linear’, gamma = ’auto’) SVRReg.fit(X, y)
輸出
SVR(C = 1.0, cache_size = 200, coef0 = 0.0, degree = 3, epsilon = 0.1, gamma = 'auto', kernel = 'linear', max_iter = -1, shrinking = True, tol = 0.001, verbose = False)
示例
現在,擬合完成後,我們可以使用以下Python指令碼獲取權重向量 −
SVRReg.coef_
輸出
array([[0.4, 0.4]])
示例
同樣,我們可以獲取其他屬性的值,如下所示 −
SVRReg.predict([[1,1]])
輸出
array([1.1])
同樣,我們也可以獲取其他屬性的值。
NuSVR
NuSVR 是 Nu 支援向量迴歸。它類似於 NuSVC,但 NuSVR 使用引數nu來控制支援向量的數量。此外,與 NuSVC 中nu替換 C 引數不同,這裡它替換了epsilon。
實現示例
以下 Python 指令碼使用sklearn.svm.SVR類:
from sklearn.svm import NuSVR import numpy as np n_samples, n_features = 20, 15 np.random.seed(0) y = np.random.randn(n_samples) X = np.random.randn(n_samples, n_features) NuSVRReg = NuSVR(kernel = 'linear', gamma = 'auto',C = 1.0, nu = 0.1)^M NuSVRReg.fit(X, y)
輸出
NuSVR(C = 1.0, cache_size = 200, coef0 = 0.0, degree = 3, gamma = 'auto', kernel = 'linear', max_iter = -1, nu = 0.1, shrinking = True, tol = 0.001, verbose = False)
示例
現在,擬合完成後,我們可以使用以下Python指令碼獲取權重向量 −
NuSVRReg.coef_
輸出
array(
[
[-0.14904483, 0.04596145, 0.22605216, -0.08125403, 0.06564533,
0.01104285, 0.04068767, 0.2918337 , -0.13473211, 0.36006765,
-0.2185713 , -0.31836476, -0.03048429, 0.16102126, -0.29317051]
]
)
同樣,我們也可以獲取其他屬性的值。
LinearSVR
它是線性支援向量迴歸。它類似於具有 kernel = 'linear' 的 SVR。它們的區別在於LinearSVR基於liblinear實現,而SVC基於libsvm實現。這就是LinearSVR在懲罰項和損失函式的選擇上具有更大靈活性的原因。它也更能適應大量的樣本。
如果我們談論它的引數和屬性,它不支援'kernel',因為它被假定為線性,並且它也缺少一些屬性,例如support_,support_vectors_,n_support_,fit_status_和dual_coef_。
但是,它支援如下所示的 'loss' 引數:
loss − 字串,可選,預設 = 'epsilon_insensitive'
它表示損失函式,其中 epsilon_insensitive 損失是 L1 損失,平方 epsilon_insensitive 損失是 L2 損失。
實現示例
以下 Python 指令碼使用sklearn.svm.LinearSVR類:
from sklearn.svm import LinearSVR from sklearn.datasets import make_regression X, y = make_regression(n_features = 4, random_state = 0) LSVRReg = LinearSVR(dual = False, random_state = 0, loss = 'squared_epsilon_insensitive',tol = 1e-5) LSVRReg.fit(X, y)
輸出
LinearSVR( C=1.0, dual=False, epsilon=0.0, fit_intercept=True, intercept_scaling=1.0, loss='squared_epsilon_insensitive', max_iter=1000, random_state=0, tol=1e-05, verbose=0 )
示例
現在,擬合完成後,模型可以預測新值,如下所示 −
LSRReg.predict([[0,0,0,0]])
輸出
array([-0.01041416])
示例
對於上述示例,我們可以使用以下Python指令碼獲取權重向量 −
LSRReg.coef_
輸出
array([20.47354746, 34.08619401, 67.23189022, 87.47017787])
示例
同樣,我們可以使用以下Python指令碼獲取截距值 −
LSRReg.intercept_
輸出
array([-0.01041416])
Scikit Learn - 異常檢測
在這裡,我們將學習什麼是 Sklearn 中的異常檢測以及它如何用於識別資料點。
異常檢測是一種用於識別資料集中與其餘資料不匹配的資料點的技術。它在商業中有很多應用,例如欺詐檢測、入侵檢測、系統健康監控、監控和預測性維護。異常(也稱為異常值)可以分為以下三類:
點異常− 當單個數據實例相對於其餘資料被認為是異常時發生。
上下文異常− 此類異常是特定於上下文的。如果資料例項在特定上下文中是異常的,則會發生這種情況。
集體異常− 當一組相關的資料例項相對於整個資料集而不是單個值是異常時發生。
方法
可以使用兩種方法,即異常值檢測和新穎性檢測,進行異常檢測。有必要了解它們之間的區別。
異常值檢測
訓練資料包含遠離其餘資料的異常值。此類異常值定義為觀察值。這就是為什麼異常值檢測估計器總是試圖擬合具有最集中訓練資料的區域,同時忽略異常觀察值的原因。它也稱為無監督異常檢測。
新穎性檢測
它關注的是檢測訓練資料中未包含的新觀測值中的未觀察到的模式。這裡,訓練資料沒有被異常值汙染。它也稱為半監督異常檢測。
scikit-learn 提供了一組 ML 工具,可用於異常值檢測和新穎性檢測。這些工具首先透過使用 fit() 方法無監督地從資料中實現物件學習,如下所示:
estimator.fit(X_train)
現在,新的觀察結果將使用 predict() 方法分類為內點 (標記為 1) 或異常點 (標記為 -1),如下所示:
estimator.fit(X_test)
估計器將首先計算原始評分函式,然後預測方法將對該原始評分函式使用閾值。我們可以藉助score_sample方法訪問此原始評分函式,並可以透過contamination引數控制閾值。
我們還可以定義decision_function方法,該方法將異常值定義為負值,將內點定義為非負值。
estimator.decision_function(X_test)
Sklearn 的異常值檢測演算法
讓我們首先了解什麼是橢圓包絡。
擬合橢圓包絡
該演算法假設常規資料來自已知分佈,例如高斯分佈。對於異常值檢測,Scikit-learn 提供了一個名為covariance.EllipticEnvelop的物件。
此物件將穩健的協方差估計擬合到資料,從而將橢圓擬合到中心資料點。它忽略中心模式之外的點。
引數
下表包含sklearn.covariance.EllipticEnvelop方法使用的引數:
| 序號 | 引數和描述 |
|---|---|
| 1 |
store_precision − 布林值,可選,預設 = True 如果儲存估計的精度,我們可以指定它。 |
| 2 |
assume_centered − 布林值,可選,預設 = False 如果我們將其設定為 False,它將使用 FastMCD 演算法直接計算穩健的位置和協方差。另一方面,如果設定為 True,它將計算穩健位置和協方差的支援。 |
| 3 |
support_fraction − (0., 1.) 內的浮點數,可選,預設 = None 此引數告訴方法有多少比例的點應包含在原始 MCD 估計的支援中。 |
| 4 |
contamination − (0., 1.) 內的浮點數,可選,預設 = 0.1 它提供了資料集中異常值的比例。 |
| 5 |
random_state − int,RandomState 例項或 None,可選,預設值 = none 此引數表示生成的偽隨機數的種子,該種子在洗牌資料時使用。選項如下:
|
屬性
下表包含sklearn.covariance.EllipticEnvelop方法使用的屬性:
| 序號 | 屬性和描述 |
|---|---|
| 1 |
support_ − 類似陣列,形狀 (n_samples,) 它表示用於計算位置和形狀的穩健估計的觀察值的掩碼。 |
| 2 |
location_ − 類似陣列,形狀 (n_features) 它返回估計的穩健位置。 |
| 3 |
covariance_ − 類似陣列,形狀 (n_features, n_features) 它返回估計的穩健協方差矩陣。 |
| 4 |
precision_ − 類似陣列,形狀 (n_features, n_features) 它返回估計的偽逆矩陣。 |
| 5 |
offset_ − 浮點數 它用於根據原始分數定義決策函式。decision_function = score_samples - offset_ |
實現示例
import numpy as np^M from sklearn.covariance import EllipticEnvelope^M true_cov = np.array([[.5, .6],[.6, .4]]) X = np.random.RandomState(0).multivariate_normal(mean = [0, 0], cov=true_cov,size=500) cov = EllipticEnvelope(random_state = 0).fit(X)^M # Now we can use predict method. It will return 1 for an inlier and -1 for an outlier. cov.predict([[0, 0],[2, 2]])
輸出
array([ 1, -1])
隔離森林
對於高維資料集,一種有效的異常值檢測方法是使用隨機森林。scikit-learn 提供了ensemble.IsolationForest方法,該方法透過隨機選擇特徵來隔離觀察值。之後,它會在所選特徵的最大值和最小值之間隨機選擇一個值。
在這裡,隔離樣本所需的分割次數等於從根節點到終止節點的路徑長度。
引數
下表包含sklearn.ensemble.IsolationForest方法使用的引數:
| 序號 | 引數和描述 |
|---|---|
| 1 |
n_estimators − 整數,可選,預設 = 100 它表示整合中基本估計器的數量。 |
| 2 |
max_samples − 整數或浮點數,可選,預設 = “auto” 它表示要從 X 中抽取以訓練每個基本估計器的樣本數。如果我們選擇整數作為其值,它將抽取 max_samples 個樣本。如果我們選擇浮點數作為其值,它將抽取 max_samples * 𝑋.shape[0] 個樣本。並且,如果我們選擇 auto 作為其值,它將抽取 max_samples = min(256, n_samples)。 |
| 3 |
support_fraction − (0., 1.) 內的浮點數,可選,預設 = None 此引數告訴方法有多少比例的點應包含在原始 MCD 估計的支援中。 |
| 4 |
contamination − auto 或浮點數,可選,預設 = auto 它提供了資料集中異常值的比例。如果我們將其設定為預設值,即 auto,它將像在原始論文中一樣確定閾值。如果設定為浮點數,則汙染範圍將在 [0,0.5] 範圍內。 |
| 5 |
random_state − int,RandomState 例項或 None,可選,預設值 = none 此引數表示生成的偽隨機數的種子,該種子在洗牌資料時使用。選項如下:
|
| 6 |
max_features − 整數或浮點數,可選(預設 = 1.0) 它表示要從 X 中抽取以訓練每個基本估計器的特徵數。如果我們選擇整數作為其值,它將抽取 max_features 個特徵。如果我們選擇浮點數作為其值,它將抽取 max_features * X.shape[1] 個樣本。 |
| 7 | bootstrap − 布林值,可選(預設 = False) 其預設選項為 False,這意味著將不進行替換地進行取樣。另一方面,如果設定為 True,則表示單個樹擬合訓練資料的隨機子集,並進行替換取樣。 |
| 8 |
n_jobs − 整數或 None,可選(預設 = None) 它表示要為fit()和predict()方法並行執行的作業數。 |
| 9 |
verbose − 整數,可選(預設 = 0) 此引數控制樹構建過程的詳細程度。 |
| 10 |
warm_start − 布林值,可選(預設 = False) 如果 warm_start = true,我們可以重複使用之前的呼叫解決方案來擬合,並且可以向整合中新增更多估計器。但是,如果設定為 false,我們需要擬合一個全新的森林。 |
屬性
下表包含sklearn.ensemble.IsolationForest方法使用的屬性:
| 序號 | 屬性和描述 |
|---|---|
| 1 |
estimators_ − DecisionTreeClassifier 列表 提供所有擬合的子估計器的集合。 |
| 2 |
max_samples_ − 整數 它提供使用的實際樣本數。 |
| 3 |
offset_ − 浮點數 它用於根據原始分數定義決策函式。decision_function = score_samples - offset_ |
實現示例
下面的 Python 指令碼將使用sklearn.ensemble.IsolationForest方法在給定資料上擬合10棵樹。
from sklearn.ensemble import IsolationForest import numpy as np X = np.array([[-1, -2], [-3, -3], [-3, -4], [0, 0], [-50, 60]]) OUTDClf = IsolationForest(n_estimators = 10) OUTDclf.fit(X)
輸出
IsolationForest( behaviour = 'old', bootstrap = False, contamination='legacy', max_features = 1.0, max_samples = 'auto', n_estimators = 10, n_jobs=None, random_state = None, verbose = 0 )
區域性異常因子
區域性異常因子 (LOF) 演算法是另一種有效的演算法,用於對高維資料執行異常值檢測。scikit-learn 提供了neighbors.LocalOutlierFactor 方法,該方法計算一個分數,稱為區域性異常因子,反映了觀測值的異常程度。該演算法的主要邏輯是檢測密度明顯低於其鄰居的樣本。這就是為什麼它根據其鄰居來測量給定資料點的區域性密度偏差。
引數
下表列出了sklearn.neighbors.LocalOutlierFactor方法使用的引數。
| 序號 | 引數和描述 |
|---|---|
| 1 |
n_neighbors − int,可選,預設為 20 它表示 kneighbors 查詢預設使用的鄰居數。如果使用點,則將使用所有樣本。 |
| 2 |
algorithm − 可選 用於計算最近鄰居的演算法。
|
| 3 |
leaf_size − int,可選,預設為 30 此引數的值會影響構建和查詢的速度。它還會影響儲存樹所需的記憶體。此引數傳遞給 BallTree 或 KdTree 演算法。 |
| 4 |
contamination − auto 或浮點數,可選,預設 = auto 它提供了資料集中異常值的比例。如果我們將其設定為預設值,即 auto,它將像在原始論文中一樣確定閾值。如果設定為浮點數,則汙染範圍將在 [0,0.5] 範圍內。 |
| 5 |
metric − 字串或可呼叫物件,預設值 它表示用於距離計算的度量。 |
| 6 |
P − int,可選(預設為 2) 它是 Minkowski 度量的引數。P=1 等效於使用 manhattan_distance,即 L1,而 P=2 等效於使用 euclidean_distance,即 L2。 |
| 7 |
novelty − 布林值,(預設為 False) 預設情況下,LOF 演算法用於異常值檢測,但如果我們將 novelty 設定為 true,則可以將其用於新穎性檢測。 |
| 8 |
n_jobs − 整數或 None,可選(預設 = None) 它表示要為 fit() 和 predict() 方法並行執行的作業數。 |
屬性
下表列出了sklearn.neighbors.LocalOutlierFactor方法使用的屬性。
| 序號 | 屬性和描述 |
|---|---|
| 1 |
negative_outlier_factor_ − numpy 陣列,形狀 (n_samples,) 提供訓練樣本的相反 LOF。 |
| 2 |
n_neighbors_ − 整數 它提供用於鄰居查詢的實際鄰居數。 |
| 3 |
offset_ − 浮點數 它用於根據原始分數定義二元標籤。 |
實現示例
下面給出的 Python 指令碼將使用sklearn.neighbors.LocalOutlierFactor方法從任何與我們的資料集對應的陣列構建 NeighborsClassifier 類。
from sklearn.neighbors import NearestNeighbors samples = [[0., 0., 0.], [0., .5, 0.], [1., 1., .5]] LOFneigh = NearestNeighbors(n_neighbors = 1, algorithm = "ball_tree",p=1) LOFneigh.fit(samples)
輸出
NearestNeighbors( algorithm = 'ball_tree', leaf_size = 30, metric='minkowski', metric_params = None, n_jobs = None, n_neighbors = 1, p = 1, radius = 1.0 )
示例
現在,我們可以使用下面的 Python 指令碼,從這個構建的分類器中詢問與 [0.5, 1., 1.5] 最接近的點。
print(neigh.kneighbors([[.5, 1., 1.5]])
輸出
(array([[1.7]]), array([[1]], dtype = int64))
一類 SVM
由 Schölkopf 等人提出的 One-Class SVM 是一種無監督的異常值檢測方法。它在高維資料中也非常有效,並估計高維分佈的支援。它在Sklearn.svm.OneClassSVM 物件的支援向量機模組中實現。為了定義邊界,它需要一個核(最常用的是 RBF)和一個標量引數。
為了更好地理解,讓我們用svm.OneClassSVM物件擬合我們的資料。
示例
from sklearn.svm import OneClassSVM X = [[0], [0.89], [0.90], [0.91], [1]] OSVMclf = OneClassSVM(gamma = 'scale').fit(X)
現在,我們可以按如下方式獲取輸入資料的 score_samples:
OSVMclf.score_samples(X)
輸出
array([1.12218594, 1.58645126, 1.58673086, 1.58645127, 1.55713767])
Scikit Learn - K 近鄰 (KNN)
本章將幫助您瞭解 Sklearn 中的最近鄰方法。
基於鄰域的學習方法既有監督又有非監督型別。監督的基於鄰域的學習可用於分類和迴歸預測問題,但在工業中主要用於分類預測問題。
基於鄰域的學習方法沒有專門的訓練階段,並在分類時使用所有資料進行訓練。它也不對底層資料做任何假設。這就是它們本質上是懶惰的和非引數的原因。
最近鄰方法背後的主要原理是:
找到距離新資料點最近的預定義數量的訓練樣本。
根據這些訓練樣本預測標籤。
這裡,樣本數量可以是使用者定義的常量(如在 K 近鄰學習中),也可以根據點的區域性密度而變化(如在基於半徑的鄰域學習中)。
sklearn.neighbors 模組
Scikit-learn 有sklearn.neighbors模組,它為基於無監督和監督鄰域的學習方法提供功能。作為輸入,此模組中的類可以處理 NumPy 陣列或scipy.sparse矩陣。
演算法型別
可在基於鄰域的方法的實現中使用的不同型別的演算法如下:
暴力搜尋
計算資料集中所有點對之間的距離的暴力方法提供了最簡單的最近鄰搜尋實現。從數學上講,對於 D 維中的 N 個樣本,暴力方法的規模為O[DN2]。
對於小的資料樣本,此演算法非常有用,但是隨著樣本數量的增加,它變得不可行。可以透過編寫關鍵字algorithm='brute'來啟用暴力搜尋。
KD 樹
為了解決暴力方法的計算效率低下的問題,人們發明了一種基於樹的資料結構,即 KD 樹資料結構。基本上,KD 樹是一種二叉樹結構,稱為 K 維樹。它透過將引數空間沿資料軸遞迴地劃分成巢狀的正交區域來劃分引數空間,並將資料點填充到這些區域中。
優點
以下是 KD 樹演算法的一些優點:
構建速度快 − 由於分割槽僅沿資料軸進行,因此 KD 樹的構建速度非常快。
距離計算少 − 此演算法只需要很少的距離計算就能確定查詢點的最近鄰。它只需要O[log(N)]次距離計算。
缺點
僅對低維鄰域搜尋速度快 − 它對低維 (D < 20) 鄰域搜尋速度非常快,但是隨著 D 的增長,它變得效率低下。由於分割槽僅沿資料軸進行,
可以透過編寫關鍵字algorithm='kd_tree'來啟用 KD 樹鄰域搜尋。
球樹
眾所周知,KD 樹在更高維度上效率低下,因此,為了解決 KD 樹的這種效率低下,開發了球樹資料結構。從數學上講,它將資料遞迴地劃分為由質心 C 和半徑 r 定義的節點,使得節點中的每個點都位於由質心C和半徑r定義的超球體內。它使用下面給出的三角不等式,減少了最近鄰搜尋的候選點數
$$ \arrowvert X+Y\arrowvert\leq \arrowvert X\arrowvert+\arrowvert Y\arrowvert $$優點
以下是球樹演算法的一些優點:
在高度結構化的資料上效率高 − 由於球樹將資料劃分成一系列巢狀的超球體,因此它在高度結構化的資料上效率很高。
優於 KD 樹 − 球樹在高維情況下優於 KD 樹,因為它具有球樹節點的球形幾何形狀。
缺點
代價高昂 − 將資料劃分成一系列巢狀的超球體使其構建代價非常高昂。
可以透過編寫關鍵字algorithm='ball_tree'來啟用球樹鄰域搜尋。
選擇最近鄰演算法
為給定資料集選擇最佳演算法取決於以下因素:
樣本數 (N) 和維度 (D)
在選擇最近鄰演算法時,這是最重要的因素。原因如下:
暴力演算法的查詢時間增長為 O[DN]。
球樹演算法的查詢時間增長為 O[D log(N)]。
KD 樹演算法的查詢時間隨 D 的變化方式很奇怪,很難表徵。當 D < 20 時,成本為 O[D log(N)],此演算法非常有效。另一方面,當 D > 20 時,它效率低下,因為成本增加到接近 O[DN]。
資料結構
影響這些演算法效能的另一個因素是資料的內在維度或資料的稀疏性。這是因為球樹和 KD 樹演算法的查詢時間會受到它的很大影響。而暴力演算法的查詢時間不受資料結構的影響。通常,球樹和 KD 樹演算法在應用於具有較小內在維度的稀疏資料時會產生更快的查詢時間。
鄰居數 (k)
為查詢點請求的鄰居數 (k) 會影響球樹和 KD 樹演算法的查詢時間。隨著鄰居數 (k) 的增加,它們的查詢時間會變慢。而暴力演算法的查詢時間將不受 k 值的影響。
查詢點數
因為它們需要構建階段,所以如果查詢點很多,KD 樹和球樹演算法將非常有效。另一方面,如果查詢點較少,則暴力演算法的效能優於 KD 樹和球樹演算法。
Scikit Learn - KNN 學習
k-NN (k 近鄰) 是最簡單的機器學習演算法之一,其本質是非引數的和懶惰的。非引數意味著對底層資料分佈沒有假設,即模型結構由資料集決定。懶惰或基於例項的學習意味著為了生成模型,它不需要任何訓練資料點,並且在測試階段使用所有訓練資料。
k-NN 演算法包括以下兩個步驟:
步驟 1
在此步驟中,它計算並存儲訓練集中每個樣本的 k 個最近鄰。
步驟 2
在此步驟中,對於未標記的樣本,它從資料集中檢索 k 個最近鄰。然後,在這些 k 個最近鄰中,它透過投票來預測類別(得票最多的類別獲勝)。
實現 k 近鄰演算法的模組sklearn.neighbors為無監督和監督基於鄰域的學習方法提供了功能。
無監督最近鄰實現不同的演算法(BallTree、KDTree 或暴力搜尋)來為每個樣本找到最近鄰。這個無監督版本基本上只是上面討論的步驟 1,並且是許多演算法(KNN 和 K 均值是最著名的)的基礎,這些演算法需要鄰域搜尋。簡單來說,它是用於實現鄰域搜尋的無監督學習器。
另一方面,監督的基於鄰域的學習用於分類和迴歸。
無監督 KNN 學習
如上所述,存在許多像 KNN 和 K 均值這樣的演算法需要最近鄰搜尋。這就是為什麼 Scikit-learn 決定將其鄰域搜尋部分實現為它自己的“學習器”。將鄰域搜尋作為單獨的學習器的原因是,為了尋找最近鄰而計算所有成對距離顯然效率不高。讓我們看看 Sklearn 用於實現無監督最近鄰學習的模組以及示例。
Scikit-learn 模組
sklearn.neighbors.NearestNeighbors 模組用於實現無監督最近鄰學習。它使用名為 BallTree、KDTree 或 Brute Force 的特定最近鄰演算法。換句話說,它充當這三種演算法的統一介面。
引數
下表列出了NearestNeighbors 模組使用的引數:
| 序號 | 引數和描述 |
|---|---|
| 1 |
n_neighbors − int,可選 要獲取的鄰居數量。預設值為 5。 |
| 2 |
radius − float,可選 它限制返回鄰居的距離。預設值為 1.0。 |
| 3 |
algorithm − {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’},可選 此引數將採用您要用於計算最近鄰的演算法(BallTree、KDTree 或 Brute-force)。如果您提供 'auto',它將嘗試根據傳遞給 fit 方法的值確定最合適的演算法。 |
| 4 |
leaf_size − int,可選 它可以影響構建和查詢的速度以及儲存樹所需的記憶體。它傳遞給 BallTree 或 KDTree。雖然最佳值取決於問題的性質,但其預設值為 30。 |
| 5 |
metric − 字串或可呼叫物件 這是用於計算點之間距離的度量。我們可以將其作為字串或可呼叫函式傳遞。對於可呼叫函式,度量標準將應用於每一對行,並記錄結果值。這不如將度量名稱作為字串傳遞高效。 我們可以從 scikit-learn 或 scipy.spatial.distance 中選擇度量標準。有效值為: Scikit-learn − [‘cosine’,’manhattan’,’Euclidean’, ‘l1’,’l2’, ‘cityblock’] Scipy.spatial.distance − [‘braycurtis’,’canberra’,’chebyshev’,’dice’,’hamming’,’jaccard’, ‘correlation’,’kulsinski’,’mahalanobis’,’minkowski’,’rogerstanimoto’,’russellrao’, ‘sokalmicheme’,’sokalsneath’, ‘seuclidean’, ‘sqeuclidean’, ‘yule’]。 預設度量為 'Minkowski'。 |
| 6 |
P − 整數,可選 它是 Minkowski 度量的引數。預設值為 2,相當於使用 Euclidean_distance(l2)。 |
| 7 |
metric_params − dict,可選 這是度量函式的其他關鍵字引數。預設值為 None。 |
| 8 |
N_jobs − int 或 None,可選 它表示要為鄰居搜尋執行的並行作業數。預設值為 None。 |
實現示例
下面的示例將使用sklearn.neighbors.NearestNeighbors 模組查詢兩組資料之間的最近鄰。
首先,我們需要匯入所需的模組和包:
from sklearn.neighbors import NearestNeighbors import numpy as np
現在,匯入包後,定義我們想要找到最近鄰的資料集:
Input_data = np.array([[-1, 1], [-2, 2], [-3, 3], [1, 2], [2, 3], [3, 4],[4, 5]])
接下來,應用無監督學習演算法,如下所示:
nrst_neigh = NearestNeighbors(n_neighbors = 3, algorithm = 'ball_tree')
接下來,用輸入資料集擬合模型。
nrst_neigh.fit(Input_data)
現在,找到資料集的 K 近鄰。它將返回每個點的鄰居的索引和距離。
distances, indices = nbrs.kneighbors(Input_data) indices
輸出
array(
[
[0, 1, 3],
[1, 2, 0],
[2, 1, 0],
[3, 4, 0],
[4, 5, 3],
[5, 6, 4],
[6, 5, 4]
], dtype = int64
)
distances
輸出
array(
[
[0. , 1.41421356, 2.23606798],
[0. , 1.41421356, 1.41421356],
[0. , 1.41421356, 2.82842712],
[0. , 1.41421356, 2.23606798],
[0. , 1.41421356, 1.41421356],
[0. , 1.41421356, 1.41421356],
[0. , 1.41421356, 2.82842712]
]
)
上述輸出表明,每個點的最近鄰都是該點本身,即為零。這是因為查詢集與訓練集匹配。
示例
我們還可以透過生成稀疏圖來顯示相鄰點之間的連線,如下所示:
nrst_neigh.kneighbors_graph(Input_data).toarray()
輸出
array(
[
[1., 1., 0., 1., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 0.],
[1., 0., 0., 1., 1., 0., 0.],
[0., 0., 0., 1., 1., 1., 0.],
[0., 0., 0., 0., 1., 1., 1.],
[0., 0., 0., 0., 1., 1., 1.]
]
)
一旦我們擬合了無監督NearestNeighbors 模型,資料將儲存在基於引數'algorithm'設定的值的資料結構中。之後,我們可以在需要鄰居搜尋的模型中使用這個無監督學習器的kneighbors。
完整的可執行程式
from sklearn.neighbors import NearestNeighbors import numpy as np Input_data = np.array([[-1, 1], [-2, 2], [-3, 3], [1, 2], [2, 3], [3, 4],[4, 5]]) nrst_neigh = NearestNeighbors(n_neighbors = 3, algorithm='ball_tree') nrst_neigh.fit(Input_data) distances, indices = nbrs.kneighbors(Input_data) indices distances nrst_neigh.kneighbors_graph(Input_data).toarray()
有監督 KNN 學習
有監督的基於鄰居的學習用於以下方面:
- 分類,用於具有離散標籤的資料
- 迴歸,用於具有連續標籤的資料。
最近鄰分類器
我們可以藉助以下兩個特徵來理解基於鄰居的分類:
- 它是根據每個點的最近鄰的簡單多數投票計算的。
- 它只是儲存訓練資料的例項,因此它是一種非泛化學習。
Scikit-learn 模組
以下是 scikit-learn 使用的兩種不同型別的最近鄰分類器:
| 序號 | 分類器和描述 |
|---|---|
| 1. | KNeighborsClassifier
分類器名稱中的 K 代表 k 個最近鄰,其中 k 是使用者指定的整數值。因此,顧名思義,此分類器實現了基於 k 個最近鄰的學習。k 值的選擇取決於資料。 |
| 2. | RadiusNeighborsClassifier
分類器名稱中的 Radius 代表指定半徑 r 內的最近鄰,其中 r 是使用者指定的浮點值。因此,顧名思義,此分類器實現了基於每個訓練點固定半徑 r 內的鄰居數量的學習。 |
最近鄰迴歸器
它用於資料標籤本質上是連續的情況。分配的資料標籤是根據其最近鄰的標籤的平均值計算的。
以下是 scikit-learn 使用的兩種不同型別的最近鄰迴歸器:
KNeighborsRegressor
迴歸器名稱中的 K 代表 k 個最近鄰,其中k是使用者指定的整數值。因此,顧名思義,此迴歸器實現了基於 k 個最近鄰的學習。k 值的選擇取決於資料。讓我們透過一個實現示例來更好地理解它。
以下是 scikit-learn 使用的兩種不同型別的最近鄰迴歸器:
實現示例
在這個示例中,我們將使用 scikit-learn KNeighborsRegressor 在名為 Iris 花資料集的資料集上實現 KNN。
首先,匯入 iris 資料集,如下所示:
from sklearn.datasets import load_iris iris = load_iris()
現在,我們需要將資料分成訓練資料和測試資料。我們將使用 Sklearn train_test_split 函式將資料分成 70(訓練資料)和 20(測試資料)的比例:
X = iris.data[:, :4] y = iris.target from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20)
接下來,我們將使用 Sklearn 預處理模組進行資料縮放,如下所示:
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaler.fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test)
接下來,從 Sklearn 匯入KNeighborsRegressor 類,並提供鄰居的值,如下所示。
示例
import numpy as np from sklearn.neighbors import KNeighborsRegressor knnr = KNeighborsRegressor(n_neighbors = 8) knnr.fit(X_train, y_train)
輸出
KNeighborsRegressor( algorithm = 'auto', leaf_size = 30, metric = 'minkowski', metric_params = None, n_jobs = None, n_neighbors = 8, p = 2, weights = 'uniform' )
示例
現在,我們可以找到 MSE(均方誤差),如下所示:
print ("The MSE is:",format(np.power(y-knnr.predict(X),4).mean()))
輸出
The MSE is: 4.4333349609375
示例
現在,用它來預測值,如下所示:
X = [[0], [1], [2], [3]] y = [0, 0, 1, 1] from sklearn.neighbors import KNeighborsRegressor knnr = KNeighborsRegressor(n_neighbors = 3) knnr.fit(X, y) print(knnr.predict([[2.5]]))
輸出
[0.66666667]
完整的可執行程式
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:, :4]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
knnr = KNeighborsRegressor(n_neighbors=8)
knnr.fit(X_train, y_train)
print ("The MSE is:",format(np.power(y-knnr.predict(X),4).mean()))
X = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
from sklearn.neighbors import KNeighborsRegressor
knnr = KNeighborsRegressor(n_neighbors=3)
knnr.fit(X, y)
print(knnr.predict([[2.5]]))
RadiusNeighborsRegressor
迴歸器名稱中的 Radius 代表指定半徑 r 內的最近鄰,其中 r 是使用者指定的浮點值。因此,顧名思義,此迴歸器實現了基於每個訓練點固定半徑 r 內的鄰居數量的學習。讓我們透過一個實現示例來更好地理解它:
實現示例
在這個示例中,我們將使用 scikit-learn RadiusNeighborsRegressor 在名為 Iris 花資料集的資料集上實現 KNN:
首先,匯入 iris 資料集,如下所示:
from sklearn.datasets import load_iris iris = load_iris()
現在,我們需要將資料分成訓練資料和測試資料。我們將使用 Sklearn train_test_split 函式將資料分成 70(訓練資料)和 20(測試資料)的比例:
X = iris.data[:, :4] y = iris.target from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
接下來,我們將使用 Sklearn 預處理模組進行資料縮放,如下所示:
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaler.fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test)
接下來,從 Sklearn 匯入RadiusneighborsRegressor 類,並提供半徑的值,如下所示:
import numpy as np from sklearn.neighbors import RadiusNeighborsRegressor knnr_r = RadiusNeighborsRegressor(radius=1) knnr_r.fit(X_train, y_train)
示例
現在,我們可以找到 MSE(均方誤差),如下所示:
print ("The MSE is:",format(np.power(y-knnr_r.predict(X),4).mean()))
輸出
The MSE is: The MSE is: 5.666666666666667
示例
現在,用它來預測值,如下所示:
X = [[0], [1], [2], [3]] y = [0, 0, 1, 1] from sklearn.neighbors import RadiusNeighborsRegressor knnr_r = RadiusNeighborsRegressor(radius=1) knnr_r.fit(X, y) print(knnr_r.predict([[2.5]]))
輸出
[1.]
完整的可執行程式
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:, :4]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
import numpy as np
from sklearn.neighbors import RadiusNeighborsRegressor
knnr_r = RadiusNeighborsRegressor(radius = 1)
knnr_r.fit(X_train, y_train)
print ("The MSE is:",format(np.power(y-knnr_r.predict(X),4).mean()))
X = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
from sklearn.neighbors import RadiusNeighborsRegressor
knnr_r = RadiusNeighborsRegressor(radius = 1)
knnr_r.fit(X, y)
print(knnr_r.predict([[2.5]]))
Scikit Learn - 使用樸素貝葉斯進行分類
樸素貝葉斯方法是一組基於應用貝葉斯定理的監督學習演算法,其強有力的假設是所有預測器都相互獨立,即一個特徵在一個類中的存在與同一類中任何其他特徵的存在無關。這是一個天真的假設,這就是為什麼這些方法被稱為樸素貝葉斯方法。
貝葉斯定理陳述了以下關係,以便找到類別的後驗機率,即標籤和一些觀察到的特徵的機率,$P\left(\begin{array}{c} Y\arrowvert features\end{array}\right)$。
$$P\left(\begin{array}{c} Y\arrowvert features\end{array}\right)=\left(\frac{P\lgroup Y\rgroup P\left(\begin{array}{c} features\arrowvert Y\end{array}\right)}{P\left(\begin{array}{c} features\end{array}\right)}\right)$$這裡,$P\left(\begin{array}{c} Y\arrowvert features\end{array}\right)$ 是類的後驗機率。
$P\left(\begin{array}{c} Y\end{array}\right)$ 是類的先驗機率。
$P\left(\begin{array}{c} features\arrowvert Y\end{array}\right)$ 是似然,即給定類的預測器的機率。
$P\left(\begin{array}{c} features\end{array}\right)$ 是預測器的先驗機率。
Scikit-learn 提供了不同的樸素貝葉斯分類器模型,即高斯、多項式、補充和伯努利。它們的主要區別在於它們對 𝑷$P\left(\begin{array}{c} features\arrowvert Y\end{array}\right)$(即給定類的預測器的機率)的分佈所做的假設。
| 序號 | 模型和描述 |
|---|---|
| 1 |
高斯樸素貝葉斯
高斯樸素貝葉斯分類器假設每個標籤的資料都來自簡單的正態分佈。 |
| 2 |
多項式樸素貝葉斯
它假設特徵來自簡單的多項式分佈。 |
| 3 |
伯努利樸素貝葉斯
該模型的假設是特徵本質上是二元的(0 和 1)。伯努利樸素貝葉斯分類的一個應用是使用“詞袋”模型進行文字分類。 |
| 4 |
補充樸素貝葉斯
它旨在糾正多項式貝葉斯分類器所做的嚴重假設。這種 NB 分類器適用於不平衡資料集。 |
構建樸素貝葉斯分類器
我們還可以將樸素貝葉斯分類器應用於 Scikit-learn 資料集。在下面的示例中,我們正在應用 GaussianNB 並擬合 Scikit-leran 的 breast_cancer 資料集。
示例
Import Sklearn from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split data = load_breast_cancer() label_names = data['target_names'] labels = data['target'] feature_names = data['feature_names'] features = data['data'] print(label_names) print(labels[0]) print(feature_names[0]) print(features[0]) train, test, train_labels, test_labels = train_test_split( features,labels,test_size = 0.40, random_state = 42 ) from sklearn.naive_bayes import GaussianNB GNBclf = GaussianNB() model = GNBclf.fit(train, train_labels) preds = GNBclf.predict(test) print(preds)
輸出
[ 1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0 0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0 1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0 1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0 1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1 ]
上述輸出包含一系列 0 和 1,它們基本上是來自腫瘤類別(即惡性和良性)的預測值。
Scikit Learn - 決策樹
在本章中,我們將學習 Sklearn 中稱為決策樹的學習方法。
決策樹 (DTs) 是最強大的非引數監督學習方法。它們可以用於分類和迴歸任務。DTs 的主要目標是建立一個模型,透過學習從資料特徵推匯出的簡單決策規則來預測目標變數值。決策樹有兩個主要實體;一個是根節點,資料在此處分割;另一個是決策節點或葉子節點,我們在此處獲得最終輸出。
決策樹演算法
下面解釋了不同的決策樹演算法:
ID3
它由 Ross Quinlan 於 1986 年開發。它也稱為迭代二分器 3。該演算法的主要目標是為每個節點找到那些分類特徵,這些特徵將為分類目標產生最大的資訊增益。
它允許樹生長到最大尺寸,然後為了提高樹對未見資料的處理能力,應用修剪步驟。該演算法的輸出將是多路樹。
C4.5
它是 ID3 的後繼者,它動態地定義一個離散屬性,該屬性將連續屬性值劃分為一組離散的區間。這就是它取消了分類特徵限制的原因。它將 ID3 訓練的樹轉換為一組“IF-THEN”規則。
為了確定應用這些規則的順序,將首先評估每個規則的準確性。
C5.0
它的工作方式類似於 C4.5,但它使用更少的記憶體並構建更小的規則集。它比 C4.5 更準確。
CART
它被稱為分類和迴歸樹演算法。它基本上透過使用特徵和閾值來生成二元分割,在每個節點產生最大的資訊增益(稱為基尼指數)。
同質性取決於基尼指數,基尼指數的值越高,同質性就越高。它類似於 C4.5 演算法,但不同之處在於它不計算規則集,也不支援數值目標變數(迴歸)。
決策樹分類
在本例中,決策變數是分類變數。
Sklearn 模組 − Scikit-learn 庫提供名為 DecisionTreeClassifier 的模組,用於對資料集執行多類分類。
引數
下表列出了 sklearn.tree.DecisionTreeClassifier 模組使用的引數:
| 序號 | 引數和描述 |
|---|---|
| 1 | criterion − 字串,可選,預設為 “gini” 它表示用於衡量分割質量的函式。支援的標準是“gini”和“entropy”。預設為 gini,表示基尼不純度,而 entropy 表示資訊增益。 |
| 2 | splitter − 字串,可選,預設為 “best” 它告訴模型在每個節點選擇哪個策略(“best”或“random”)進行分割。 |
| 3 | max_depth − 整數或 None,可選,預設為 None 此引數決定樹的最大深度。預設值為 None,這意味著節點將一直擴充套件,直到所有葉子節點都是純的,或者所有葉子節點包含的樣本數少於 min_smaples_split。 |
| 4 | min_samples_split − 整數,浮點數,可選,預設為 2 此引數提供拆分內部節點所需的最小樣本數。 |
| 5 | min_samples_leaf − 整數,浮點數,可選,預設為 1 此引數提供葉節點所需的最小樣本數。 |
| 6 | min_weight_fraction_leaf − 浮點數,可選,預設為 0. 使用此引數,模型將獲得葉節點所需的權重總和的最小加權分數。 |
| 7 | max_features − 整數,浮點數,字串或 None,可選,預設為 None 它為模型提供了在尋找最佳分割時要考慮的特徵數量。 |
| 8 | random_state − int,RandomState 例項或 None,可選,預設值 = none 此引數表示生成的偽隨機數的種子,該種子在洗牌資料時使用。選項如下:
|
| 9 | max_leaf_nodes − 整數或 None,可選,預設為 None 此引數將以最佳優先的方式生成具有 max_leaf_nodes 的樹。預設為 none,這意味著將有無限數量的葉子節點。 |
| 10 | min_impurity_decrease − 浮點數,可選,預設為 0. 此值用作節點分割的標準,因為如果此分割引起的雜質減少大於或等於 min_impurity_decrease 值,則模型將分割節點。 |
| 11 | min_impurity_split − 浮點數,預設為 1e-7 它表示樹增長中提前停止的閾值。 |
| 12 | class_weight − 字典,字典列表,“balanced”或 None,預設為 None 它表示與類關聯的權重。格式為 {class_label: weight}。如果我們使用預設選項,則表示所有類別的權重都為 1。另一方面,如果您選擇 class_weight: balanced,它將使用 y 的值來自動調整權重。 |
| 13 | presort − 布林值,可選,預設為 False 它告訴模型是否預先對資料進行排序,以加快擬合過程中尋找最佳分割的速度。預設為 false,但如果設定為 true,則可能會減慢訓練過程。 |
屬性
下表列出了 sklearn.tree.DecisionTreeClassifier 模組使用的屬性:
| 序號 | 引數和描述 |
|---|---|
| 1 | feature_importances_ − 形狀為 =[n_features] 的陣列 此屬性將返回特徵重要性。 |
| 2 | classes_: − 形狀為 = [n_classes] 的陣列或此類陣列的列表 它表示類標籤,即單輸出問題,或類標籤陣列列表,即多輸出問題。 |
| 3 | max_features_ − 整數 它表示 max_features 引數推斷出的值。 |
| 4 | n_classes_ − 整數或列表 它表示類的數量,即單輸出問題,或每個輸出的類數量列表,即多輸出問題。 |
| 5 | n_features_ − 整數 執行 fit() 方法時,它給出特徵的數量。 |
| 6 | n_outputs_ − 整數 執行 fit() 方法時,它給出輸出的數量。 |
方法
下表列出了 sklearn.tree.DecisionTreeClassifier 模組使用的方法:
| 序號 | 引數和描述 |
|---|---|
| 1 | apply(self, X[, check_input]) 此方法將返回葉子的索引。 |
| 2 | decision_path(self, X[, check_input]) 顧名思義,此方法將返回樹中的決策路徑。 |
| 3 | fit(self, X, y[, sample_weight, …]) fit() 方法將根據給定的訓練集 (X, y) 構建決策樹分類器。 |
| 4 | get_depth(self) 顧名思義,此方法將返回決策樹的深度。 |
| 5 | get_n_leaves(self) 顧名思義,此方法將返回決策樹的葉子數量。 |
| 6 | get_params(self[, deep]) 我們可以使用此方法獲取估計器的引數。 |
| 7 | predict(self, X[, check_input]) 它將預測 X 的類值。 |
| 8 | predict_log_proba(self, X) 它將預測我們提供的輸入樣本 X 的類對數機率。 |
| 9 | predict_proba(self, X[, check_input]) 它將預測我們提供的輸入樣本 X 的類機率。 |
| 10 | score(self, X, y[, sample_weight]) 顧名思義,score() 方法將返回給定測試資料和標籤上的平均精度。 |
| 11 | set_params(self, \*\*params) 我們可以使用此方法設定估計器的引數。 |
實現示例
下面的 Python 指令碼將使用 sklearn.tree.DecisionTreeClassifier 模組構建一個分類器,用於根據我們具有 25 個樣本和兩個特徵(“身高”和“頭髮長度”)的資料集預測男性或女性:
from sklearn import tree from sklearn.model_selection import train_test_split X=[[165,19],[175,32],[136,35],[174,65],[141,28],[176,15] ,[131,32],[166,6],[128,32],[179,10],[136,34],[186,2],[12 6,25],[176,28],[112,38],[169,9],[171,36],[116,25],[196,2 5], [196,38], [126,40], [197,20], [150,25], [140,32],[136,35]] Y=['Man','Woman','Woman','Man','Woman','Man','Woman','Ma n','Woman','Man','Woman','Man','Woman','Woman','Woman',' Man','Woman','Woman','Man', 'Woman', 'Woman', 'Man', 'Man', 'Woman', 'Woman'] data_feature_names = ['height','length of hair'] X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.3, random_state = 1) DTclf = tree.DecisionTreeClassifier() DTclf = clf.fit(X,Y) prediction = DTclf.predict([[135,29]]) print(prediction)
輸出
['Woman']
我們還可以透過使用以下 python predict_proba() 方法預測每個類的機率:
示例
prediction = DTclf.predict_proba([[135,29]]) print(prediction)
輸出
[[0. 1.]]
決策樹迴歸
在本例中,決策變數是連續變數。
Sklearn 模組 − Scikit-learn 庫提供名為 DecisionTreeRegressor 的模組,用於將決策樹應用於迴歸問題。
引數
DecisionTreeRegressor 使用的引數與 DecisionTreeClassifier 模組中使用的引數幾乎相同。區別在於 “criterion” 引數。對於 DecisionTreeRegressor 模組,“criterion: 字串,可選,預設為 “mse””引數具有以下值:
mse − 代表均方誤差。它等於方差減少作為特徵選擇標準。它使用每個終端節點的均值來最小化 L2 損失。
freidman_mse − 它也使用均方誤差,但使用了弗裡德曼的改進評分。
mae − 代表平均絕對誤差。它使用每個終端節點的中位數來最小化 L1 損失。
另一個區別是它沒有 ‘class_weight’ 引數。
屬性
DecisionTreeRegressor 的屬性也與 DecisionTreeClassifier 模組的屬性相同。區別在於它沒有 ‘classes_’ 和 ‘n_classes_’ 屬性。
方法
DecisionTreeRegressor 的方法也與 DecisionTreeClassifier 模組的方法相同。區別在於它沒有 ‘predict_log_proba()’ 和 ‘predict_proba()’ 屬性。
實現示例
決策樹迴歸模型中的 fit() 方法將採用 y 的浮點值。讓我們透過使用 Sklearn.tree.DecisionTreeRegressor 來檢視一個簡單的實現示例:
from sklearn import tree X = [[1, 1], [5, 5]] y = [0.1, 1.5] DTreg = tree.DecisionTreeRegressor() DTreg = clf.fit(X, y)
擬合後,我們可以使用此迴歸模型進行預測,如下所示:
DTreg.predict([[4, 5]])
輸出
array([1.5])
Scikit Learn - 隨機決策樹
本章將幫助您瞭解 Sklearn 中的隨機決策樹。
隨機決策樹演算法
眾所周知,決策樹通常透過遞迴分割資料進行訓練,但由於容易過擬合,它們已被轉換為隨機森林,方法是在資料的各種子樣本上訓練許多樹。sklearn.ensemble 模組包含以下兩種基於隨機決策樹的演算法:
隨機森林演算法
對於正在考慮的每個特徵,它計算區域性最佳特徵/分割組合。在隨機森林中,整合中的每個決策樹都是從訓練集中有放回地抽取的樣本構建的,然後從每個樣本中獲得預測,最後透過投票選擇最佳解決方案。它可用於分類和迴歸任務。
隨機森林分類
要建立隨機森林分類器,Scikit-learn 模組提供 sklearn.ensemble.RandomForestClassifier。在構建隨機森林分類器時,此模組使用的主要引數是 ‘max_features’ 和 ‘n_estimators’。
這裡,‘max_features’ 是在分割節點時要考慮的特徵隨機子集的大小。如果我們將此引數的值選擇為 none,則它將考慮所有特徵,而不是隨機子集。另一方面,n_estimators 是森林中的樹木數量。樹木數量越多,結果越好。但計算時間也會更長。
實現示例
在下面的示例中,我們使用 sklearn.ensemble.RandomForestClassifier 構建隨機森林分類器,並使用 cross_val_score 模組檢查其精度。
from sklearn.model_selection import cross_val_score from sklearn.datasets import make_blobs from sklearn.ensemble import RandomForestClassifier X, y = make_blobs(n_samples = 10000, n_features = 10, centers = 100,random_state = 0) RFclf = RandomForestClassifier(n_estimators = 10,max_depth = None,min_samples_split = 2, random_state = 0) scores = cross_val_score(RFclf, X, y, cv = 5) scores.mean()
輸出
0.9997
示例
我們還可以使用 sklearn 資料集構建隨機森林分類器。在下面的示例中,我們使用 iris 資料集。我們還將找到其精度分數和混淆矩陣。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
path = "https://archive.ics.uci.edu/ml/machine-learning-database
s/iris/iris.data"
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
dataset = pd.read_csv(path, names = headernames)
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 4].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)
RFclf = RandomForestClassifier(n_estimators = 50)
RFclf.fit(X_train, y_train)
y_pred = RFclf.predict(X_test)
result = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(result)
result1 = classification_report(y_test, y_pred)
print("Classification Report:",)
print (result1)
result2 = accuracy_score(y_test,y_pred)
print("Accuracy:",result2)
輸出
Confusion Matrix:
[[14 0 0]
[ 0 18 1]
[ 0 0 12]]
Classification Report:
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 14
Iris-versicolor 1.00 0.95 0.97 19
Iris-virginica 0.92 1.00 0.96 12
micro avg 0.98 0.98 0.98 45
macro avg 0.97 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
Accuracy: 0.9777777777777777
隨機森林迴歸
要建立隨機森林迴歸,Scikit-learn 模組提供 sklearn.ensemble.RandomForestRegressor。在構建隨機森林迴歸器時,它將使用與 sklearn.ensemble.RandomForestClassifier 使用的引數相同。
實現示例
在下面的示例中,我們使用 sklearn.ensemble.RandomForestregressor 構建隨機森林迴歸器,並使用 predict() 方法預測新值。
from sklearn.ensemble import RandomForestRegressor from sklearn.datasets import make_regression X, y = make_regression(n_features = 10, n_informative = 2,random_state = 0, shuffle = False) RFregr = RandomForestRegressor(max_depth = 10,random_state = 0,n_estimators = 100) RFregr.fit(X, y)
輸出
RandomForestRegressor( bootstrap = True, criterion = 'mse', max_depth = 10, max_features = 'auto', max_leaf_nodes = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None, oob_score = False, random_state = 0, verbose = 0, warm_start = False )
擬合後,我們可以從迴歸模型中進行預測,如下所示:
print(RFregr.predict([[0, 2, 3, 0, 1, 1, 1, 1, 2, 2]]))
輸出
[98.47729198]
極端隨機樹方法
對於正在考慮的每個特徵,它都會為分割選擇一個隨機值。使用極端隨機樹方法的好處是可以進一步降低模型的方差。使用這些方法的缺點是它會稍微增加偏差。
極端隨機樹方法分類
要使用極端隨機樹方法建立分類器,Scikit-learn 模組提供 sklearn.ensemble.ExtraTreesClassifier。它使用與 sklearn.ensemble.RandomForestClassifier 使用的引數相同。唯一的區別在於它們構建樹的方式,如上所述。
實現示例
在下面的示例中,我們使用 sklearn.ensemble.ExtraTreeClassifier 構建隨機森林分類器,並使用 cross_val_score 模組檢查其精度。
from sklearn.model_selection import cross_val_score from sklearn.datasets import make_blobs from sklearn.ensemble import ExtraTreesClassifier X, y = make_blobs(n_samples = 10000, n_features = 10, centers=100,random_state = 0) ETclf = ExtraTreesClassifier(n_estimators = 10,max_depth = None,min_samples_split = 10, random_state = 0) scores = cross_val_score(ETclf, X, y, cv = 5) scores.mean()
輸出
1.0
示例
我們還可以使用 sklearn 資料集使用極端隨機樹方法構建分類器。在下面的示例中,我們使用 Pima-Indian 資料集。
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.ensemble import ExtraTreesClassifier path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values X = array[:,0:8] Y = array[:,8] seed = 7 kfold = KFold(n_splits=10, random_state=seed) num_trees = 150 max_features = 5 ETclf = ExtraTreesClassifier(n_estimators=num_trees, max_features=max_features) results = cross_val_score(ETclf, X, Y, cv=kfold) print(results.mean())
輸出
0.7551435406698566
極端隨機樹方法迴歸
要建立**Extra-Tree**迴歸模型,Scikit-learn模組提供**sklearn.ensemble.ExtraTreesRegressor**。構建隨機森林迴歸器時,它將使用與**sklearn.ensemble.ExtraTreesClassifier**相同的引數。
實現示例
在下面的示例中,我們將應用**sklearn.ensemble.ExtraTreesRegressor**,並使用與建立隨機森林迴歸器時相同的資料。讓我們看看輸出結果的差異。
from sklearn.ensemble import ExtraTreesRegressor from sklearn.datasets import make_regression X, y = make_regression(n_features = 10, n_informative = 2,random_state = 0, shuffle = False) ETregr = ExtraTreesRegressor(max_depth = 10,random_state = 0,n_estimators = 100) ETregr.fit(X, y)
輸出
ExtraTreesRegressor(bootstrap = False, criterion = 'mse', max_depth = 10, max_features = 'auto', max_leaf_nodes = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None, oob_score = False, random_state = 0, verbose = 0, warm_start = False)
示例
擬合後,我們可以從迴歸模型中進行預測,如下所示:
print(ETregr.predict([[0, 2, 3, 0, 1, 1, 1, 1, 2, 2]]))
輸出
[85.50955817]
Scikit Learn - 整合方法
本章,我們將學習Sklearn中的提升方法,這使得能夠構建整合模型。
提升方法以增量的方式構建整合模型。其主要原理是透過依次訓練每個基礎模型估計器來增量構建模型。為了構建強大的整合模型,這些方法基本上結合了多個弱學習器,這些弱學習器在對訓練資料的多次迭代中依次進行訓練。sklearn.ensemble模組包含以下兩種提升方法。
AdaBoost
它是最成功的提升整合方法之一,其關鍵在於它賦予資料集例項權重的方式。這就是為什麼該演算法在構建後續模型時需要較少關注這些例項。
AdaBoost分類
要建立AdaBoost分類器,Scikit-learn模組提供**sklearn.ensemble.AdaBoostClassifier**。構建此分類器時,該模組使用的主要引數是**base_estimator**。這裡,base_estimator是從中構建提升整合模型的基礎估計器的值。如果我們將此引數的值設定為None,則基礎估計器將為**DecisionTreeClassifier(max_depth=1)**。
實現示例
在下面的示例中,我們將使用**sklearn.ensemble.AdaBoostClassifier**構建AdaBoost分類器,並預測並檢查其得分。
from sklearn.ensemble import AdaBoostClassifier from sklearn.datasets import make_classification X, y = make_classification(n_samples = 1000, n_features = 10,n_informative = 2, n_redundant = 0,random_state = 0, shuffle = False) ADBclf = AdaBoostClassifier(n_estimators = 100, random_state = 0) ADBclf.fit(X, y)
輸出
AdaBoostClassifier(algorithm = 'SAMME.R', base_estimator = None, learning_rate = 1.0, n_estimators = 100, random_state = 0)
示例
擬合後,我們可以預測新的值,如下所示:
print(ADBclf.predict([[0, 2, 3, 0, 1, 1, 1, 1, 2, 2]]))
輸出
[1]
示例
現在我們可以檢查得分,如下所示:
ADBclf.score(X, y)
輸出
0.995
示例
我們還可以使用sklearn資料集使用Extra-Tree方法構建分類器。例如,在下面給出的示例中,我們使用Pima-Indian資料集。
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.ensemble import AdaBoostClassifier path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names = headernames) array = data.values X = array[:,0:8] Y = array[:,8] seed = 5 kfold = KFold(n_splits = 10, random_state = seed) num_trees = 100 max_features = 5 ADBclf = AdaBoostClassifier(n_estimators = num_trees, max_features = max_features) results = cross_val_score(ADBclf, X, Y, cv = kfold) print(results.mean())
輸出
0.7851435406698566
AdaBoost迴歸
要使用AdaBoost方法建立迴歸器,Scikit-learn庫提供**sklearn.ensemble.AdaBoostRegressor**。構建迴歸器時,它將使用與**sklearn.ensemble.AdaBoostClassifier**相同的引數。
實現示例
在下面的示例中,我們將使用**sklearn.ensemble.AdaBoostRegressor**構建AdaBoost迴歸器,並使用predict()方法預測新值。
from sklearn.ensemble import AdaBoostRegressor from sklearn.datasets import make_regression X, y = make_regression(n_features = 10, n_informative = 2,random_state = 0, shuffle = False) ADBregr = RandomForestRegressor(random_state = 0,n_estimators = 100) ADBregr.fit(X, y)
輸出
AdaBoostRegressor(base_estimator = None, learning_rate = 1.0, loss = 'linear', n_estimators = 100, random_state = 0)
示例
擬合後,我們可以從迴歸模型中進行預測,如下所示:
print(ADBregr.predict([[0, 2, 3, 0, 1, 1, 1, 1, 2, 2]]))
輸出
[85.50955817]
梯度提升樹
它也稱為**梯度提升迴歸樹**(GRBT)。它基本上是將提升推廣到任意可微損失函式。它以弱預測模型整合的形式生成預測模型。它可用於迴歸和分類問題。它們的主要優勢在於它們能夠自然地處理混合型別資料。
梯度提升樹分類
要建立梯度提升樹分類器,Scikit-learn模組提供**sklearn.ensemble.GradientBoostingClassifier**。構建此分類器時,該模組使用的主要引數是“loss”。這裡,“loss”是要最佳化的損失函式的值。如果我們選擇loss = 'deviance',它指的是具有機率輸出的分類的偏差。
另一方面,如果我們將此引數的值設定為'exponential',則它將恢復AdaBoost演算法。引數**n_estimators**將控制弱學習器的數量。名為**learning_rate**的超引數(範圍為(0.0, 1.0])將透過收縮來控制過擬合。
實現示例
在下面的示例中,我們將使用**sklearn.ensemble.GradientBoostingClassifier**構建梯度提升分類器。我們將此分類器與50個弱學習器擬合。
from sklearn.datasets import make_hastie_10_2 from sklearn.ensemble import GradientBoostingClassifier X, y = make_hastie_10_2(random_state = 0) X_train, X_test = X[:5000], X[5000:] y_train, y_test = y[:5000], y[5000:] GDBclf = GradientBoostingClassifier(n_estimators = 50, learning_rate = 1.0,max_depth = 1, random_state = 0).fit(X_train, y_train) GDBclf.score(X_test, y_test)
輸出
0.8724285714285714
示例
我們還可以使用sklearn資料集使用梯度提升分類器構建分類器。在下面的示例中,我們使用Pima-Indian資料集。
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.ensemble import GradientBoostingClassifier path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names = headernames) array = data.values X = array[:,0:8] Y = array[:,8] seed = 5 kfold = KFold(n_splits = 10, random_state = seed) num_trees = 100 max_features = 5 ADBclf = GradientBoostingClassifier(n_estimators = num_trees, max_features = max_features) results = cross_val_score(ADBclf, X, Y, cv = kfold) print(results.mean())
輸出
0.7946582356674234
梯度提升樹迴歸
要使用梯度提升樹方法建立迴歸器,Scikit-learn庫提供**sklearn.ensemble.GradientBoostingRegressor**。它可以透過引數名稱loss指定迴歸的損失函式。loss的預設值為'ls'。
實現示例
在下面的示例中,我們將使用**sklearn.ensemble.GradientBoostingRegressor**構建梯度提升迴歸器,並使用mean_squared_error()方法找到均方誤差。
import numpy as np from sklearn.metrics import mean_squared_error from sklearn.datasets import make_friedman1 from sklearn.ensemble import GradientBoostingRegressor X, y = make_friedman1(n_samples = 2000, random_state = 0, noise = 1.0) X_train, X_test = X[:1000], X[1000:] y_train, y_test = y[:1000], y[1000:] GDBreg = GradientBoostingRegressor(n_estimators = 80, learning_rate=0.1, max_depth = 1, random_state = 0, loss = 'ls').fit(X_train, y_train)
擬合後,我們可以找到均方誤差,如下所示:
mean_squared_error(y_test, GDBreg.predict(X_test))
輸出
5.391246106657164
Scikit Learn - 聚類方法
在這裡,我們將學習Sklearn中的聚類方法,這將有助於識別資料樣本中的任何相似性。
聚類方法是最有用的無監督機器學習方法之一,用於查詢資料樣本之間的相似性和關係模式。之後,它們將這些樣本聚類到具有基於特徵的相似性的組中。聚類確定當前未標記資料中的內在分組,因此它很重要。
Scikit-learn庫使用**sklearn.cluster**對未標記資料進行聚類。在此模組下,scikit-learn包含以下聚類方法:
KMeans
此演算法計算質心並進行迭代,直到找到最佳質心。它需要指定聚類數量,這就是為什麼它假設它們已經知道。該演算法的主要邏輯是透過最小化稱為慣性的標準來分離樣本到n個方差相等的組中來對資料進行聚類。演算法識別的聚類數量用'K'表示。
Scikit-learn使用**sklearn.cluster.KMeans**模組執行K均值聚類。在計算聚類中心和慣性值時,名為**sample_weight**的引數允許**sklearn.cluster.KMeans**模組為某些樣本分配更大的權重。
親和傳播
此演算法基於不同樣本對之間“訊息傳遞”的概念,直到收斂。它不需要在執行演算法之前指定聚類數量。該演算法的時間複雜度為O(N²T),這是其最大的缺點。
Scikit-learn使用**sklearn.cluster.AffinityPropagation**模組執行親和傳播聚類。
均值漂移
此演算法主要發現樣本平滑密度中的**塊**。它透過將點移向資料點的最高密度來迭代地將資料點分配給聚類。它不依賴於名為**bandwidth**的引數來指示要搜尋的區域的大小,而是自動設定聚類數量。
Scikit-learn使用**sklearn.cluster.MeanShift**模組執行均值漂移聚類。
譜聚類
在聚類之前,此演算法基本上使用資料相似矩陣的特徵值(即譜)來在較少的維度上執行降維。當聚類數量很大時,不建議使用此演算法。
Scikit-learn使用**sklearn.cluster.SpectralClustering**模組執行譜聚類。
層次聚類
此演算法透過連續合併或拆分聚類來構建巢狀聚類。此聚類層次結構表示為樹狀圖(即樹)。它分為以下兩類:
**凝聚層次演算法** - 在這種層次演算法中,每個資料點都被視為單個聚類。然後,它連續地將聚類對聚合在一起。這使用自下而上的方法。
**分裂層次演算法** - 在這種層次演算法中,所有資料點都被視為一個大的聚類。在聚類過程中,它透過使用自上而下的方法將一個大的聚類劃分為各種小的聚類。
Scikit-learn使用**sklearn.cluster.AgglomerativeClustering**模組執行凝聚層次聚類。
DBSCAN
它代表**“基於密度的噪聲應用空間聚類”**。此演算法基於“聚類”和“噪聲”的直觀概念,即聚類是資料空間中低密度區域中被低密度資料點區域分隔開的密集區域。
Scikit-learn使用**sklearn.cluster.DBSCAN**模組執行DBSCAN聚類。此演算法使用兩個重要引數,即min_samples和eps來定義密集。
引數**min_samples**的值越高或引數eps的值越低,表明形成聚類所需的較高資料點密度。
OPTICS
它代表**“排序點以識別聚類結構”**。此演算法還在空間資料中查詢基於密度的聚類。它的基本工作邏輯類似於DBSCAN。
它透過以這種方式對資料庫的點進行排序,使得空間上最接近的點在排序中成為相鄰點,從而解決了DBSCAN演算法的一個主要弱點——在不同密度的資料中檢測有意義的聚類的問題。
Scikit-learn使用**sklearn.cluster.OPTICS**模組執行OPTICS聚類。
BIRCH
它代表使用層次結構的平衡迭代減少和聚類。它用於對大型資料集執行層次聚類。它為給定資料構建一棵名為**CFT**(即**特徵特徵樹**)的樹。
CFT 的優點是稱為 CF(特徵特徵)節點的資料節點儲存了聚類所需的必要資訊,這進一步避免了需要將整個輸入資料儲存在記憶體中。
Scikit-learn使用**sklearn.cluster.Birch**模組執行BIRCH聚類。
比較聚類演算法
下表將對scikit-learn中的聚類演算法(基於引數、可擴充套件性和度量)進行比較。
| 序號 | 演算法名稱 | 引數 | 可擴充套件性 | 使用的度量 |
|---|---|---|---|---|
| 1 | K-Means | 聚類數 | 非常大的n_samples | 點之間的距離。 |
| 2 | 親和傳播 | 阻尼 | 它不能隨著n_samples擴充套件 | 圖距離 |
| 3 | 均值漂移 | 頻寬 | 它不能隨著n_samples擴充套件。 | 點之間的距離。 |
| 4 | 譜聚類 | 聚類數 | 中等程度的n_samples可擴充套件性。小程度的n_clusters可擴充套件性。 | 圖距離 |
| 5 | 層次聚類 | 距離閾值或聚類數 | 大的n_samples 大的n_clusters | 點之間的距離。 |
| 6 | DBSCAN | 鄰域大小 | 非常大的n_samples和中等n_clusters。 | 最近點距離 |
| 7 | OPTICS | 最小聚類成員資格 | 非常大的n_samples和大的n_clusters。 | 點之間的距離。 |
| 8 | BIRCH | 閾值,分支因子 | 大的n_samples 大的n_clusters | 點之間的歐幾里德距離。 |
Scikit-learn數字資料集上的K-Means聚類
在這個例子中,我們將對數字資料集應用K-means聚類。此演算法將在不使用原始標籤資訊的情況下識別相似的數字。實現是在Jupyter Notebook上完成的。
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans from sklearn.datasets import load_digits digits = load_digits() digits.data.shape
輸出
1797, 64)
此輸出顯示數字資料集具有1797個樣本和64個特徵。
示例
現在,執行K-Means聚類,如下所示:
kmeans = KMeans(n_clusters = 10, random_state = 0) clusters = kmeans.fit_predict(digits.data) kmeans.cluster_centers_.shape
輸出
(10, 64)
此輸出顯示K-means聚類建立了10個具有64個特徵的聚類。
示例
fig, ax = plt.subplots(2, 5, figsize = (8, 3)) centers = kmeans.cluster_centers_.reshape(10, 8, 8) for axi, center in zip(ax.flat, centers): axi.set(xticks = [], yticks = []) axi.imshow(center, interpolation = 'nearest', cmap = plt.cm.binary)
輸出
下面的輸出包含顯示K-Means聚類學習到的聚類中心的影像。
接下來,下面的Python指令碼將學習到的聚類標籤(透過K-Means)與其中找到的真實標籤匹配:
from scipy.stats import mode labels = np.zeros_like(clusters) for i in range(10): mask = (clusters == i) labels[mask] = mode(digits.target[mask])[0]
我們還可以使用下面提到的命令來檢查準確性。
from sklearn.metrics import accuracy_score accuracy_score(digits.target, labels)
輸出
0.7935447968836951
完整的實現示例
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans from sklearn.datasets import load_digits digits = load_digits() digits.data.shape kmeans = KMeans(n_clusters = 10, random_state = 0) clusters = kmeans.fit_predict(digits.data) kmeans.cluster_centers_.shape fig, ax = plt.subplots(2, 5, figsize = (8, 3)) centers = kmeans.cluster_centers_.reshape(10, 8, 8) for axi, center in zip(ax.flat, centers): axi.set(xticks=[], yticks = []) axi.imshow(center, interpolation = 'nearest', cmap = plt.cm.binary) from scipy.stats import mode labels = np.zeros_like(clusters) for i in range(10): mask = (clusters == i) labels[mask] = mode(digits.target[mask])[0] from sklearn.metrics import accuracy_score accuracy_score(digits.target, labels)
Scikit Learn - 聚類效能評估
有各種函式可以幫助我們評估聚類演算法的效能。
以下是Scikit-learn提供的一些重要且最常用的用於評估聚類效能的函式:
調整後的Rand指數
Rand指數是一個函式,它計算兩個聚類之間的相似性度量。對於此計算,Rand指數考慮所有樣本對,並計算在預測和真實聚類中被分配到相似或不同聚類的對。之後,使用以下公式將原始Rand指數得分“按機會調整”為調整後的Rand指數得分:
$$Adjusted\:RI=\left(RI-Expected_{-}RI\right)/\left(max\left(RI\right)-Expected_{-}RI\right)$$它有兩個引數,即**labels_true**(它是地面真實類標籤)和**labels_pred**(是要評估的聚類標籤)。
示例
from sklearn.metrics.cluster import adjusted_rand_score labels_true = [0, 0, 1, 1, 1, 1] labels_pred = [0, 0, 2, 2, 3, 3] adjusted_rand_score(labels_true, labels_pred)
輸出
0.4444444444444445
完美的標記得分將為1,而錯誤的標記或獨立的標記得分將為0或負數。
基於互資訊的得分
互資訊是一個計算兩個分配之間一致性的函式。它忽略排列。以下是可用版本:
歸一化互資訊 (NMI)
Scikit-learn 包含 **sklearn.metrics.normalized_mutual_info_score** 模組。
示例
from sklearn.metrics.cluster import normalized_mutual_info_score labels_true = [0, 0, 1, 1, 1, 1] labels_pred = [0, 0, 2, 2, 3, 3] normalized_mutual_info_score (labels_true, labels_pred)
輸出
0.7611702597222881
調整後的互資訊 (AMI)
Scikit-learn 包含 **sklearn.metrics.adjusted_mutual_info_score** 模組。
示例
from sklearn.metrics.cluster import adjusted_mutual_info_score labels_true = [0, 0, 1, 1, 1, 1] labels_pred = [0, 0, 2, 2, 3, 3] adjusted_mutual_info_score (labels_true, labels_pred)
輸出
0.4444444444444448
Fowlkes-Mallows 得分
Fowlkes-Mallows 函式測量一組點的兩個聚類的相似性。它可以定義為成對精確度和召回率的幾何平均數。
數學公式:
$$FMS=\frac{TP}{\sqrt{\left(TP+FP\right)\left(TP+FN\right)}}$$這裡,**TP = 真陽性** - 真實標籤和預測標籤中都屬於相同聚類的點對數量。
**FP = 假陽性** - 真實標籤中屬於相同聚類但在預測標籤中不屬於相同聚類的點對數量。
**FN = 假陰性** - 預測標籤中屬於相同聚類但在真實標籤中不屬於相同聚類的點對數量。
Scikit-learn 包含 **sklearn.metrics.fowlkes_mallows_score** 模組。
示例
from sklearn.metrics.cluster import fowlkes_mallows_score labels_true = [0, 0, 1, 1, 1, 1] labels_pred = [0, 0, 2, 2, 3, 3] fowlkes_mallows__score (labels_true, labels_pred)
輸出
0.6546536707079771
輪廓係數
輪廓函式將使用每個樣本的平均類內距離和平均最近類距離來計算所有樣本的平均輪廓係數。
數學公式:
$$S=\left(b-a\right)/max\left(a,b\right)$$這裡,a 是類內距離。
而 b 是平均最近類距離。
Scikit-learn 包含 **sklearn.metrics.silhouette_score** 模組。
示例
from sklearn import metrics.silhouette_score from sklearn.metrics import pairwise_distances from sklearn import datasets import numpy as np from sklearn.cluster import KMeans dataset = datasets.load_iris() X = dataset.data y = dataset.target kmeans_model = KMeans(n_clusters = 3, random_state = 1).fit(X) labels = kmeans_model.labels_ silhouette_score(X, labels, metric = 'euclidean')
輸出
0.5528190123564091
列聯表
此矩陣將報告每對可靠的 (真實值, 預測值) 的交集基數。分類問題的混淆矩陣是一個方形列聯表。
Scikit-learn 包含 **sklearn.metrics.contingency_matrix** 模組。
示例
from sklearn.metrics.cluster import contingency_matrix x = ["a", "a", "a", "b", "b", "b"] y = [1, 1, 2, 0, 1, 2] contingency_matrix(x, y)
輸出
array([ [0, 2, 1], [1, 1, 1] ])
上面輸出的第一行顯示,在真實聚類為“a”的三個樣本中,沒有一個在 0 中,兩個在 1 中,一個在 2 中。另一方面,第二行顯示,在真實聚類為“b”的三個樣本中,一個在 0 中,一個在 1 中,一個在 2 中。
Scikit-learn - 使用 PCA 的降維
降維是一種無監督機器學習方法,用於透過選擇一組主要特徵來減少每個資料樣本的特徵變數數量。主成分分析 (PCA) 是流行的降維演算法之一。
精確 PCA
**主成分分析** (PCA) 用於使用資料的**奇異值分解** (SVD) 進行線性降維,以將其投影到低維空間。在使用 PCA 進行分解時,在應用 SVD 之前,輸入資料對於每個特徵都被居中,但未縮放。
Scikit-learn ML 庫提供 **sklearn.decomposition.PCA** 模組,該模組實現為一個轉換器物件,在其 fit() 方法中學習 n 個成分。它也可以用於將新資料投影到這些成分上。
示例
下面的示例將使用 sklearn.decomposition.PCA 模組從 Pima 印第安人糖尿病資料集查詢最佳的 5 個主成分。
from pandas import read_csv
from sklearn.decomposition import PCA
path = r'C:\Users\Leekha\Desktop\pima-indians-diabetes.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', ‘class']
dataframe = read_csv(path, names = names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
pca = PCA(n_components = 5)
fit = pca.fit(X)
print(("Explained Variance: %s") % (fit.explained_variance_ratio_))
print(fit.components_)
輸出
Explained Variance: [0.88854663 0.06159078 0.02579012 0.01308614 0.00744094] [ [-2.02176587e-03 9.78115765e-02 1.60930503e-02 6.07566861e-029.93110844e-01 1.40108085e-02 5.37167919e-04 -3.56474430e-03] [-2.26488861e-02 -9.72210040e-01 -1.41909330e-01 5.78614699e-029.46266913e-02 -4.69729766e-02 -8.16804621e-04 -1.40168181e-01] [-2.24649003e-02 1.43428710e-01 -9.22467192e-01 -3.07013055e-012.09773019e-02 -1.32444542e-01 -6.39983017e-04 -1.25454310e-01] [-4.90459604e-02 1.19830016e-01 -2.62742788e-01 8.84369380e-01-6.55503615e-02 1.92801728e-01 2.69908637e-03 -3.01024330e-01] [ 1.51612874e-01 -8.79407680e-02 -2.32165009e-01 2.59973487e-01-1.72312241e-04 2.14744823e-02 1.64080684e-03 9.20504903e-01] ]
增量 PCA
**增量主成分分析** (IPCA) 用於解決主成分分析 (PCA) 最大的限制,即 PCA 只支援批次處理,這意味著所有要處理的輸入資料都必須適合記憶體。
Scikit-learn ML 庫提供 **sklearn.decomposition.IPCA** 模組,該模組可以透過在其 **partial_fit** 方法上對順序獲取的資料塊進行處理,或者透過啟用使用 **np.memmap**(記憶體對映檔案)來實現 Out-of-Core PCA,而無需將整個檔案載入到記憶體中。
與 PCA 相同,在使用 IPCA 進行分解時,在應用 SVD 之前,輸入資料對於每個特徵都被居中,但未縮放。
示例
下面的示例將在 Sklearn 數字資料集上使用 **sklearn.decomposition.IPCA** 模組。
from sklearn.datasets import load_digits from sklearn.decomposition import IncrementalPCA X, _ = load_digits(return_X_y = True) transformer = IncrementalPCA(n_components = 10, batch_size = 100) transformer.partial_fit(X[:100, :]) X_transformed = transformer.fit_transform(X) X_transformed.shape
輸出
(1797, 10)
在這裡,我們可以對較小的批次資料進行部分擬合(就像我們每批 100 個一樣),或者您可以讓 **fit()** 函式將資料分成批次。
核 PCA
核主成分分析是 PCA 的擴充套件,它使用核實現非線性降維。它支援 **transform** 和 **inverse_transform**。
Scikit-learn ML 庫提供 **sklearn.decomposition.KernelPCA** 模組。
示例
下面的示例將在 Sklearn 數字資料集上使用 **sklearn.decomposition.KernelPCA** 模組。我們使用 sigmoid 核。
from sklearn.datasets import load_digits from sklearn.decomposition import KernelPCA X, _ = load_digits(return_X_y = True) transformer = KernelPCA(n_components = 10, kernel = 'sigmoid') X_transformed = transformer.fit_transform(X) X_transformed.shape
輸出
(1797, 10)
使用隨機 SVD 的 PCA
使用隨機 SVD 的主成分分析 (PCA) 用於將資料投影到低維空間,同時保留大部分方差,方法是丟棄與較低奇異值相關的成分的奇異向量。在這裡,**sklearn.decomposition.PCA** 模組以及可選引數 **svd_solver='randomized'** 將非常有用。
示例
下面的示例將使用帶有可選引數 svd_solver='randomized' 的 **sklearn.decomposition.PCA** 模組從 Pima 印第安人糖尿病資料集查詢最佳的 7 個主成分。
from pandas import read_csv
from sklearn.decomposition import PCA
path = r'C:\Users\Leekha\Desktop\pima-indians-diabetes.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
dataframe = read_csv(path, names = names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
pca = PCA(n_components = 7,svd_solver = 'randomized')
fit = pca.fit(X)
print(("Explained Variance: %s") % (fit.explained_variance_ratio_))
print(fit.components_)
輸出
Explained Variance: [8.88546635e-01 6.15907837e-02 2.57901189e-02 1.30861374e-027.44093864e-03 3.02614919e-03 5.12444875e-04] [ [-2.02176587e-03 9.78115765e-02 1.60930503e-02 6.07566861e-029.93110844e-01 1.40108085e-02 5.37167919e-04 -3.56474430e-03] [-2.26488861e-02 -9.72210040e-01 -1.41909330e-01 5.78614699e-029.46266913e-02 -4.69729766e-02 -8.16804621e-04 -1.40168181e-01] [-2.24649003e-02 1.43428710e-01 -9.22467192e-01 -3.07013055e-012.09773019e-02 -1.32444542e-01 -6.39983017e-04 -1.25454310e-01] [-4.90459604e-02 1.19830016e-01 -2.62742788e-01 8.84369380e-01-6.55503615e-02 1.92801728e-01 2.69908637e-03 -3.01024330e-01] [ 1.51612874e-01 -8.79407680e-02 -2.32165009e-01 2.59973487e-01-1.72312241e-04 2.14744823e-02 1.64080684e-03 9.20504903e-01] [-5.04730888e-03 5.07391813e-02 7.56365525e-02 2.21363068e-01-6.13326472e-03 -9.70776708e-01 -2.02903702e-03 -1.51133239e-02] [ 9.86672995e-01 8.83426114e-04 -1.22975947e-03 -3.76444746e-041.42307394e-03 -2.73046214e-03 -6.34402965e-03 -1.62555343e-01] ]