- Scikit Learn 教程
- Scikit Learn - 首頁
- Scikit Learn - 簡介
- Scikit Learn - 建模過程
- Scikit Learn - 資料表示
- Scikit Learn - 估計器 API
- Scikit Learn - 約定
- Scikit Learn - 線性建模
- Scikit Learn - 擴充套件線性建模
- 隨機梯度下降
- Scikit Learn - 支援向量機
- Scikit Learn - 異常檢測
- Scikit Learn - K 近鄰演算法
- Scikit Learn - KNN 學習
- 樸素貝葉斯分類
- Scikit Learn - 決策樹
- 隨機決策樹
- Scikit Learn - 整合方法
- Scikit Learn - 聚類方法
- 聚類效能評估
- 使用 PCA 進行降維
- Scikit Learn 有用資源
- Scikit Learn - 快速指南
- Scikit Learn - 有用資源
- Scikit Learn - 討論
Scikit Learn - 資料表示
眾所周知,機器學習是關於從資料中建立模型的。為此,計算機必須首先理解資料。接下來,我們將討論各種表示資料的方法,以便計算機能夠理解它們 -
資料作為表格
在 Scikit-learn 中表示資料的最佳方法是表格形式。表格表示一個二維資料網格,其中行表示資料集的各個元素,列表示與這些各個元素相關的數量。
示例
透過以下示例,我們可以使用 Python 的 seaborn 庫將 鳶尾花資料集 下載為 Pandas DataFrame 的形式。
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()
輸出
sepal_length sepal_width petal_length petal_width species 0 5.1 3.5 1.4 0.2 setosa 1 4.9 3.0 1.4 0.2 setosa 2 4.7 3.2 1.3 0.2 setosa 3 4.6 3.1 1.5 0.2 setosa 4 5.0 3.6 1.4 0.2 setosa
從以上輸出可以看出,資料的每一行都代表一朵觀察到的花,行數代表資料集中花的總數。通常,我們將矩陣的行稱為樣本。
另一方面,資料的每一列都代表描述每個樣本的定量資訊。通常,我們將矩陣的列稱為特徵。
資料作為特徵矩陣
特徵矩陣可以定義為表格佈局,其中資訊可以被認為是二維矩陣。它儲存在一個名為 X 的變數中,並假定為二維,形狀為 [n_samples, n_features]。大多數情況下,它包含在 NumPy 陣列或 Pandas DataFrame 中。如前所述,樣本始終表示資料集描述的單個物件,特徵以定量方式描述每個樣本的不同觀察結果。
資料作為目標陣列
除了用 X 表示的特徵矩陣之外,我們還有目標陣列。它也稱為標籤。它用 y 表示。標籤或目標陣列通常是一維的,長度為 n_samples。它通常包含在 NumPy 的 陣列 或 Pandas 的 序列 中。目標陣列可以同時具有連續數值和離散值。
目標陣列與特徵列有何不同?
我們可以透過一點來區分兩者,即目標陣列通常是我們想要從資料中預測的數量,即在統計學上它是因變數。
示例
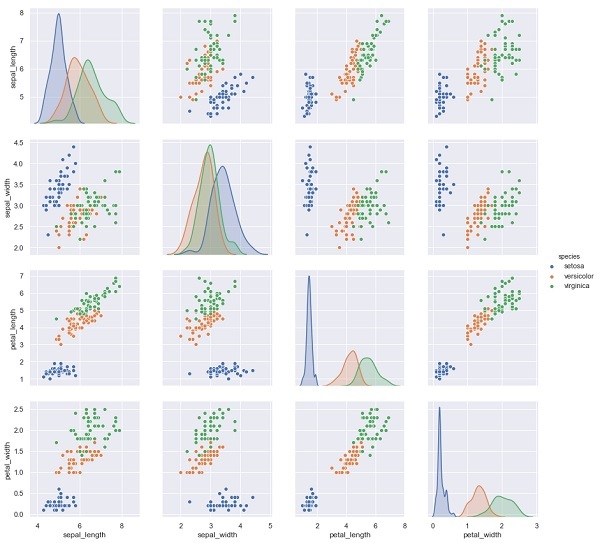
在下面的示例中,從鳶尾花資料集中,我們根據其他測量結果預測花的種類。在這種情況下,Species 列將被視為特徵。
import seaborn as sns
iris = sns.load_dataset('iris')
%matplotlib inline
import seaborn as sns; sns.set()
sns.pairplot(iris, hue='species', height=3);
輸出
X_iris = iris.drop('species', axis=1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
輸出
(150,4) (150,)
廣告