- 自然語言工具包教程
- 自然語言工具包 - 首頁
- 自然語言工具包 - 簡介
- 自然語言工具包 - 入門
- 自然語言工具包 - 文字分詞
- 訓練分詞器和過濾停用詞
- 在Wordnet中查詢單詞
- 詞幹提取與詞形還原
- 自然語言工具包 - 單詞替換
- 同義詞和反義詞替換
- 語料庫讀取器和自定義語料庫
- 詞性標註基礎
- 自然語言工具包 - 一元標註器
- 自然語言工具包 - 組合標註器
- 自然語言工具包 - 更多NLTK標註器
- 自然語言工具包 - 語法分析
- 組塊提取和資訊抽取
- 自然語言工具包 - 轉換組塊
- 自然語言工具包 - 轉換樹
- 自然語言工具包 - 文字分類
- 自然語言工具包資源
- 自然語言工具包 - 快速指南
- 自然語言工具包 - 有用資源
- 自然語言工具包 - 討論
詞幹提取與詞形還原
什麼是詞幹提取?
詞幹提取是一種透過去除詞綴來提取單詞基本形式的技術。就像把樹的枝幹砍掉到樹幹一樣。例如,單詞eating, eats, eaten的詞幹是eat。
搜尋引擎使用詞幹提取來索引單詞。因此,搜尋引擎可以只儲存單詞的所有形式的詞幹,而不是儲存所有形式。這樣,詞幹提取減少了索引的大小並提高了檢索精度。
各種詞幹提取演算法
在NLTK中,stemmerI,它具有stem()方法,介面包含了我們接下來要介紹的所有詞幹提取器。讓我們用下面的圖表來理解它
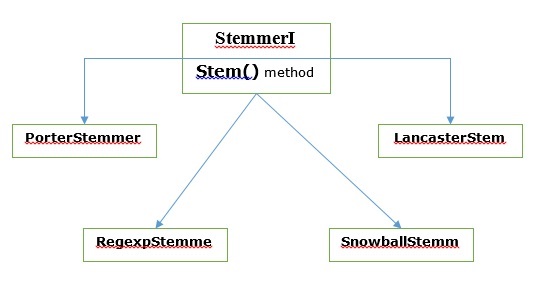
Porter詞幹提取演算法
它是最常見的詞幹提取演算法之一,主要用於去除和替換英語單詞的常用字尾。
PorterStemmer類
NLTK具有PorterStemmer類,藉助該類,我們可以輕鬆地為要提取詞幹的單詞實現Porter詞幹提取演算法。此類瞭解多種規則單詞形式和字尾,藉助這些形式和字尾,它可以將輸入單詞轉換為最終詞幹。生成的詞幹通常是一個較短的單詞,具有相同的根含義。讓我們看一個例子:
首先,我們需要匯入自然語言工具包(nltk)。
import nltk
現在,匯入PorterStemmer類以實現Porter詞幹提取演算法。
from nltk.stem import PorterStemmer
接下來,建立一個Porter Stemmer類的例項,如下所示:
word_stemmer = PorterStemmer()
現在,輸入要提取詞幹的單詞。
word_stemmer.stem('writing')
輸出
'write'
word_stemmer.stem('eating')
輸出
'eat'
完整的實現示例
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('writing')
輸出
'write'
Lancaster詞幹提取演算法
它是在蘭開斯特大學開發的,也是另一種非常常見的詞幹提取演算法。
LancasterStemmer類
NLTK具有LancasterStemmer類,藉助該類,我們可以輕鬆地為要提取詞幹的單詞實現Lancaster詞幹提取演算法。讓我們看一個例子:
首先,我們需要匯入自然語言工具包(nltk)。
import nltk
現在,匯入LancasterStemmer類以實現Lancaster詞幹提取演算法。
from nltk.stem import LancasterStemmer
接下來,建立一個LancasterStemmer類的例項,如下所示:
Lanc_stemmer = LancasterStemmer()
現在,輸入要提取詞幹的單詞。
Lanc_stemmer.stem('eats')
輸出
'eat'
完整的實現示例
import nltk
from nltk.stem import LancatserStemmer
Lanc_stemmer = LancasterStemmer()
Lanc_stemmer.stem('eats')
輸出
'eat'
正則表示式詞幹提取演算法
藉助此詞幹提取演算法,我們可以構建自己的詞幹提取器。
RegexpStemmer類
NLTK具有RegexpStemmer類,藉助該類,我們可以輕鬆地實現正則表示式詞幹提取演算法。它基本上採用單個正則表示式,並刪除與該表示式匹配的任何字首或字尾。讓我們看一個例子:
首先,我們需要匯入自然語言工具包(nltk)。
import nltk
現在,匯入RegexpStemmer類以實現正則表示式詞幹提取演算法。
from nltk.stem import RegexpStemmer
接下來,建立一個RegexpStemmer類的例項,並提供要從單詞中刪除的字尾或字首,如下所示:
Reg_stemmer = RegexpStemmer(‘ing’)
現在,輸入要提取詞幹的單詞。
Reg_stemmer.stem('eating')
輸出
'eat'
Reg_stemmer.stem('ingeat')
輸出
'eat'
Reg_stemmer.stem('eats')
輸出
'eat'
完整的實現示例
import nltk
from nltk.stem import RegexpStemmer
Reg_stemmer = RegexpStemmer()
Reg_stemmer.stem('ingeat')
輸出
'eat'
Snowball詞幹提取演算法
這是另一種非常有用的詞幹提取演算法。
SnowballStemmer類
NLTK具有SnowballStemmer類,藉助該類,我們可以輕鬆地實現Snowball詞幹提取演算法。它支援15種非英語語言。為了使用此詞幹提取類,我們需要使用所用語言的名稱建立一個例項,然後呼叫stem()方法。讓我們看一個例子:
首先,我們需要匯入自然語言工具包(nltk)。
import nltk
現在,匯入SnowballStemmer類以實現Snowball詞幹提取演算法。
from nltk.stem import SnowballStemmer
讓我們看看它支援的語言:
SnowballStemmer.languages
輸出
( 'arabic', 'danish', 'dutch', 'english', 'finnish', 'french', 'german', 'hungarian', 'italian', 'norwegian', 'porter', 'portuguese', 'romanian', 'russian', 'spanish', 'swedish' )
接下來,使用要使用的語言建立一個SnowballStemmer類的例項。這裡,我們為“法語”建立詞幹提取器。
French_stemmer = SnowballStemmer(‘french’)
現在,呼叫stem()方法並輸入要提取詞幹的單詞。
French_stemmer.stem (‘Bonjoura’)
輸出
'bonjour'
完整的實現示例
import nltk from nltk.stem import SnowballStemmer French_stemmer = SnowballStemmer(‘french’) French_stemmer.stem (‘Bonjoura’)
輸出
'bonjour'
什麼是詞形還原?
詞形還原技術類似於詞幹提取。詞形還原後得到的輸出稱為“詞形”,它是根單詞,而不是詞幹提取的輸出。詞形還原後,我們將得到一個具有相同含義的有效單詞。
NLTK提供了WordNetLemmatizer類,它是wordnet語料庫的簡單包裝器。此類使用morphy()函式到WordNet CorpusReader類以查詢詞形。讓我們用一個例子來理解它:
示例
首先,我們需要匯入自然語言工具包(nltk)。
import nltk
現在,匯入WordNetLemmatizer類以實現詞形還原技術。
from nltk.stem import WordNetLemmatizer
接下來,建立一個WordNetLemmatizer類的例項。
lemmatizer = WordNetLemmatizer()
現在,呼叫lemmatize()方法並輸入要查詢詞形的單詞。
lemmatizer.lemmatize('eating')
輸出
'eating'
lemmatizer.lemmatize('books')
輸出
'book'
完整的實現示例
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize('books')
輸出
'book'
詞幹提取與詞形還原的區別
讓我們藉助以下示例瞭解詞幹提取和詞形還原的區別:
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('believes')
輸出
believ
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize(' believes ')
輸出
believ
兩個程式的輸出說明了詞幹提取和詞形還原之間的主要區別。PorterStemmer類從單詞中擷取“es”。另一方面,WordNetLemmatizer類查詢一個有效的單詞。簡單來說,詞幹提取技術只關注單詞的形式,而詞形還原技術則關注單詞的含義。這意味著應用詞形還原後,我們始終會得到一個有效的單詞。