- 自然語言工具包教程
- 自然語言工具包 - 首頁
- 自然語言工具包 - 簡介
- 自然語言工具包 - 入門
- 自然語言工具包 - 文字分詞
- 訓練分詞器和過濾停用詞
- 在Wordnet中查詢單詞
- 詞幹提取和詞形還原
- 自然語言工具包 - 詞語替換
- 同義詞和反義詞替換
- 語料庫讀取器和自定義語料庫
- 詞性標註基礎
- 自然語言工具包 - 一元標註器
- 自然語言工具包 - 組合標註器
- 自然語言工具包 - 更多NLTK標註器
- 自然語言工具包 - 語法分析
- 組塊和資訊提取
- 自然語言工具包 - 轉換組塊
- 自然語言工具包 - 轉換樹
- 自然語言工具包 - 文字分類
- 自然語言工具包資源
- 自然語言工具包 - 快速指南
- 自然語言工具包 - 有用資源
- 自然語言工具包 - 討論
自然語言工具包 - 語法分析
語法分析及其在NLP中的相關性
單詞“Parsing”(源自拉丁語單詞‘pars’,意思是‘部分’)用於從文字中提取確切含義或字典含義。它也稱為句法分析或語法分析。透過比較形式語法的規則,句法分析檢查文字的意義性。例如,句子“給我熱冰淇淋”將被語法分析器或句法分析器拒絕。
從這個意義上說,我們可以將語法分析或句法分析定義如下:
可以將其定義為分析自然語言中符合形式語法規則的符號串的過程。
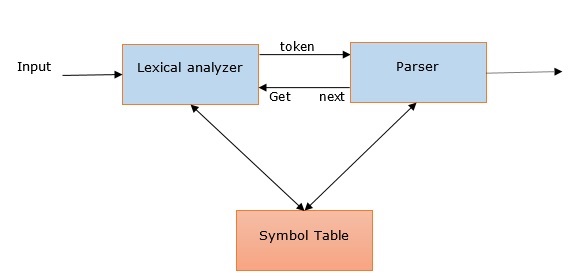
我們可以透過以下幾點了解語法分析在NLP中的相關性:
語法分析器用於報告任何語法錯誤。
它有助於從常見錯誤中恢復,以便可以繼續處理程式的其餘部分。
藉助語法分析器建立語法樹。
語法分析器用於建立符號表,符號表在NLP中起著重要作用。
語法分析器還用於生成中間表示(IR)。
深層語法分析與淺層語法分析
| 深層語法分析 | 淺層語法分析 |
|---|---|
| 在深層語法分析中,搜尋策略將為句子提供完整的句法結構。 | 它是從給定任務中解析句法資訊的有限部分的任務。 |
| 它適用於複雜的NLP應用。 | 它可用於不太複雜的NLP應用。 |
| 對話系統和摘要是使用深層語法分析的NLP應用示例。 | 資訊提取和文字挖掘是使用深層語法分析的NLP應用示例。 |
| 它也稱為完全語法分析。 | 它也稱為組塊。 |
各種型別的語法分析器
如前所述,語法分析器基本上是語法的過程化解釋。它在搜尋各種樹的空間後,為給定句子找到最優樹。讓我們看看下面一些可用的語法分析器:
遞迴下降語法分析器
遞迴下降語法分析是最直接的語法分析形式之一。以下是關於遞迴下降語法分析器的一些要點:
它遵循自頂向下的過程。
它嘗試驗證輸入流的語法是否正確。
它從左到右讀取輸入句子。
遞迴下降語法分析器的一個必要操作是從輸入流中讀取字元並將它們與語法中的終結符匹配。
移進-歸約語法分析器
以下是關於移進-歸約語法分析器的一些要點:
它遵循簡單的自底向上的過程。
它試圖找到與語法產生式的右側相對應的單詞和短語序列,並用產生式的左側替換它們。
上述查詢單詞序列的嘗試將持續到整個句子被歸約。
換句話說,移進-歸約語法分析器從輸入符號開始,嘗試構建語法樹直到起始符號。
圖表語法分析器
以下是關於圖表語法分析器的一些要點:
它主要對歧義語法(包括自然語言語法)有用或適用。
它將動態規劃應用於語法分析問題。
由於動態規劃,部分假設結果儲存在一個稱為“圖表”的結構中。
“圖表”也可以重複使用。
正則表示式語法分析器
正則表示式語法分析是最常用的語法分析技術之一。以下是關於正則表示式語法分析器的一些要點:
顧名思義,它在詞性標註字串之上使用以語法形式定義的正則表示式。
它基本上使用這些正則表示式來解析輸入句子並從中生成語法樹。
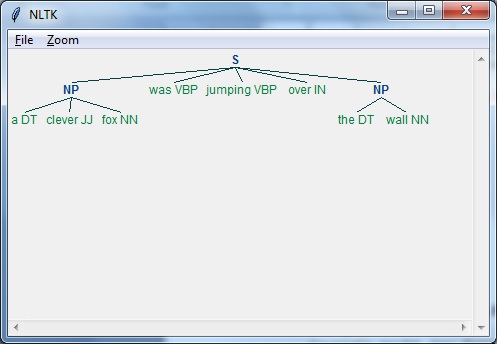
示例
以下是正則表示式語法分析器的示例:
import nltk
sentence = [
("a", "DT"),
("clever", "JJ"),
("fox","NN"),
("was","VBP"),
("jumping","VBP"),
("over","IN"),
("the","DT"),
("wall","NN")
]
grammar = "NP:{<DT>?<JJ>*<NN>}"
Reg_parser = nltk.RegexpParser(grammar)
Reg_parser.parse(sentence)
Output = Reg_parser.parse(sentence)
Output.draw()
輸出
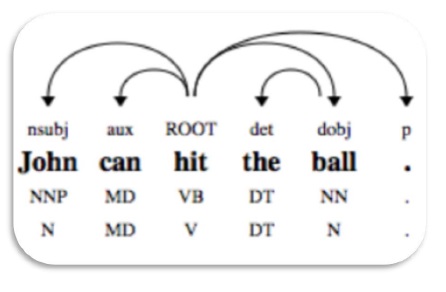
依存語法分析
依存語法分析(DP)是一種現代的語法分析機制,其主要概念是每個語言單位(即單詞)透過直接連結相互關聯。這些直接連結實際上是語言學中的“依存關係”。例如,下圖顯示了句子“John can hit the ball”的依存語法。
NLTK包
我們有以下兩種方法可以使用NLTK進行依存語法分析:
機率投影依存語法分析器
這是我們使用NLTK進行依存語法分析的第一種方法。但是此語法分析器受限於使用有限的訓練資料進行訓練。
斯坦福語法分析器
這是我們使用NLTK進行依存語法分析的另一種方法。斯坦福語法分析器是最先進的依存語法分析器。NLTK有一個包裝器。要使用它,我們需要下載以下兩件事:
所需語言的語言模型。例如,英語語言模型。
示例
下載完模型後,我們可以透過NLTK如下使用它:
from nltk.parse.stanford import StanfordDependencyParser
path_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser.jar'
path_models_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser-3.4.1-models.jar'
dep_parser = StanfordDependencyParser(
path_to_jar = path_jar, path_to_models_jar = path_models_jar
)
result = dep_parser.raw_parse('I shot an elephant in my sleep')
depndency = result.next()
list(dependency.triples())
輸出
[ ((u'shot', u'VBD'), u'nsubj', (u'I', u'PRP')), ((u'shot', u'VBD'), u'dobj', (u'elephant', u'NN')), ((u'elephant', u'NN'), u'det', (u'an', u'DT')), ((u'shot', u'VBD'), u'prep', (u'in', u'IN')), ((u'in', u'IN'), u'pobj', (u'sleep', u'NN')), ((u'sleep', u'NN'), u'poss', (u'my', u'PRP$')) ]