- 自然語言工具包教程
- 自然語言工具包 - 首頁
- 自然語言工具包 - 簡介
- 自然語言工具包 - 快速入門
- 自然語言工具包 - 文字分詞
- 訓練分詞器和過濾停用詞
- 在Wordnet中查詢單詞
- 詞幹提取與詞形還原
- 自然語言工具包 - 單詞替換
- 同義詞和反義詞替換
- 語料庫讀取器和自定義語料庫
- 詞性標註基礎
- 自然語言工具包 - 單詞標註器
- 自然語言工具包 - 組合標註器
- 自然語言工具包 - 更多NLTK標註器
- 自然語言工具包 - 語法分析
- 分塊與資訊抽取
- 自然語言工具包 - 轉換分塊
- 自然語言工具包 - 轉換樹
- 自然語言工具包 - 文字分類
- 自然語言工具包資源
- 自然語言工具包 - 快速指南
- 自然語言工具包 - 有用資源
- 自然語言工具包 - 討論
分塊與資訊抽取
什麼是分塊?
分塊是自然語言處理中一個重要的過程,用於識別詞性(POS)和短語。簡單來說,透過分塊,我們可以得到句子的結構。它也稱為部分語法分析。
分塊模式和非分塊
分塊模式是詞性(POS)標籤的模式,定義了構成分塊的詞語型別。我們可以藉助修改後的正則表示式來定義分塊模式。
此外,我們還可以定義哪些詞語不應該出現在分塊中的模式,這些未被分塊的詞語稱為非分塊。
實現示例
在下面的例子中,除了解析句子“這本書有很多章節”的結果外,還有一個用於名詞短語的語法,它結合了分塊和非分塊模式:
import nltk
sentence = [
("the", "DT"),
("book", "NN"),
("has","VBZ"),
("many","JJ"),
("chapters","NNS")
]
chunker = nltk.RegexpParser(
r'''
NP:{<DT><NN.*><.*>*<NN.*>}
}<VB.*>{
'''
)
chunker.parse(sentence)
Output = chunker.parse(sentence)
Output.draw()
輸出
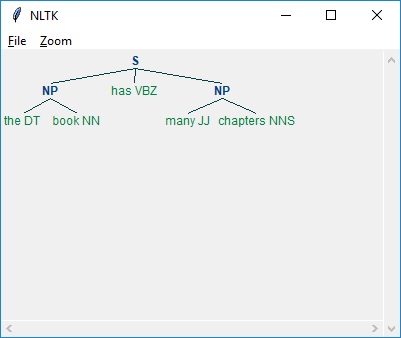
如上所示,指定分塊的模式是使用大括號,如下所示:
{<DT><NN>}
要指定非分塊,我們可以反轉大括號,如下所示:
}<VB>{.
現在,對於特定型別的短語,這些規則可以組合成一個語法。
資訊抽取
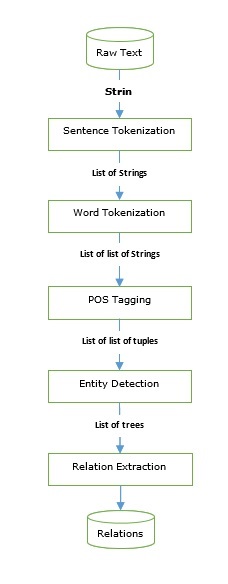
我們已經學習了可以用來構建資訊抽取引擎的標註器和解析器。讓我們來看一個基本的資訊抽取流程:
資訊抽取有很多應用,包括:
- 商業智慧
- 簡歷收集
- 媒體分析
- 情感檢測
- 專利檢索
- 郵件掃描
命名實體識別 (NER)
命名實體識別 (NER) 實際上是一種提取一些最常見的實體(如姓名、組織、位置等)的方法。讓我們來看一個例子,它包含了所有預處理步驟,例如句子分詞、詞性標註、分塊、NER,並遵循上圖中提供的流程。
示例
Import nltk file = open ( # provide here the absolute path for the file of text for which we want NER ) data_text = file.read() sentences = nltk.sent_tokenize(data_text) tokenized_sentences = [nltk.word_tokenize(sentence) for sentence in sentences] tagged_sentences = [nltk.pos_tag(sentence) for sentence in tokenized_sentences] for sent in tagged_sentences: print nltk.ne_chunk(sent)
一些修改後的命名實體識別 (NER) 也可以用來提取諸如產品名稱、生物醫學實體、品牌名稱等等的實體。
關係抽取
關係抽取是另一個常用的資訊抽取操作,它是提取不同實體之間不同關係的過程。可能存在不同的關係,例如繼承、同義詞、類似物等,其定義取決於資訊需求。例如,如果我們要查詢一本書的作者,那麼作者身份就是作者姓名和書名之間的一種關係。
示例
在下面的例子中,我們使用與上圖相同的IE流程,一直用到命名實體關係 (NER),並用基於NER標籤的關係模式對其進行擴充套件。
import nltk
import re
IN = re.compile(r'.*\bin\b(?!\b.+ing)')
for doc in nltk.corpus.ieer.parsed_docs('NYT_19980315'):
for rel in nltk.sem.extract_rels('ORG', 'LOC', doc, corpus = 'ieer',
pattern = IN):
print(nltk.sem.rtuple(rel))
輸出
[ORG: 'WHYY'] 'in' [LOC: 'Philadelphia'] [ORG: 'McGlashan & Sarrail'] 'firm in' [LOC: 'San Mateo'] [ORG: 'Freedom Forum'] 'in' [LOC: 'Arlington'] [ORG: 'Brookings Institution'] ', the research group in' [LOC: 'Washington'] [ORG: 'Idealab'] ', a self-described business incubator based in' [LOC: 'Los Angeles'] [ORG: 'Open Text'] ', based in' [LOC: 'Waterloo'] [ORG: 'WGBH'] 'in' [LOC: 'Boston'] [ORG: 'Bastille Opera'] 'in' [LOC: 'Paris'] [ORG: 'Omnicom'] 'in' [LOC: 'New York'] [ORG: 'DDB Needham'] 'in' [LOC: 'New York'] [ORG: 'Kaplan Thaler Group'] 'in' [LOC: 'New York'] [ORG: 'BBDO South'] 'in' [LOC: 'Atlanta'] [ORG: 'Georgia-Pacific'] 'in' [LOC: 'Atlanta']
在上例程式碼中,我們使用了一個名為ieer的內建語料庫。在這個語料庫中,句子已經被標記到命名實體關係 (NER)。在這裡,我們只需要指定我們想要的關係模式以及我們想要關係定義的NER型別。在我們的例子中,我們定義了組織和位置之間的關係。我們提取了所有這些模式的組合。