自然語言處理 - Python
在本章中,我們將學習使用 Python 進行語言處理。
以下特性使 Python 不同於其他語言:
Python 是解釋型語言 - 我們不需要在執行 Python 程式之前編譯它,因為直譯器在執行時處理 Python。
互動式 - 我們可以直接與直譯器互動來編寫 Python 程式。
面向物件 - Python 本質上是面向物件的,這使得編寫程式更容易,因為它利用這種程式設計技術將程式碼封裝在物件中。
初學者易於學習 - Python 也被稱為初學者的語言,因為它非常易於理解,並且支援開發各種應用程式。
先決條件
最新發布的 Python 3 版本是 Python 3.7.1,適用於 Windows、Mac OS 和大多數 Linux 作業系統版本。
對於 Windows,我們可以訪問連結 www.python.org/downloads/windows/ 下載並安裝 Python。
對於 MAC OS,我們可以使用連結 www.python.org/downloads/mac-osx/。
在 Linux 的情況下,不同的 Linux 版本使用不同的包管理器來安裝新軟體包。
例如,要在 Ubuntu Linux 上安裝 Python 3,我們可以從終端使用以下命令:
$sudo apt-get install python3-minimal
要了解更多關於 Python 程式設計的資訊,請閱讀 Python 3 基礎教程 - Python 3
NLTK 入門
我們將使用 Python 庫 NLTK(自然語言工具包)來進行英語文字分析。自然語言工具包 (NLTK) 是一個 Python 庫集合,專門用於識別和標記自然語言(如英語)文字中發現的詞性。
安裝 NLTK
在開始使用 NLTK 之前,我們需要安裝它。我們可以使用以下命令在我們的 Python 環境中安裝它:
pip install nltk
如果我們使用的是 Anaconda,則可以使用以下命令構建 NLTK 的 Conda 包:
conda install -c anaconda nltk
下載 NLTK 的資料
安裝 NLTK 後,另一個重要的任務是下載其預設的文字庫,以便可以輕鬆使用。但是,在此之前,我們需要像匯入任何其他 Python 模組一樣匯入 NLTK。以下命令將幫助我們匯入 NLTK:
import nltk
現在,使用以下命令下載 NLTK 資料:
nltk.download()
安裝所有可用的 NLTK 軟體包需要一些時間。
其他必要的軟體包
一些其他 Python 軟體包,如 gensim 和 pattern,對於文字分析以及使用 NLTK 構建自然語言處理應用程式也必不可少。這些軟體包可以按如下所示安裝:
gensim
gensim 是一個強大的語義建模庫,可用於許多應用程式。我們可以透過以下命令安裝它:
pip install gensim
pattern
它可以用來使 gensim 軟體包正常工作。以下命令有助於安裝 pattern:
pip install pattern
分詞
分詞可以定義為將給定的文字分解成稱為標記的更小單元的過程。單詞、數字或標點符號可以是標記。它也可以稱為單詞分割。
示例
輸入 - 床和椅子是傢俱的型別。

NLTK 為我們提供了不同的分詞軟體包。我們可以根據我們的需求使用這些軟體包。軟體包及其安裝詳細資訊如下:
sent_tokenize 軟體包
此軟體包可用於將輸入文字劃分為句子。我們可以使用以下命令匯入它:
from nltk.tokenize import sent_tokenize
word_tokenize 軟體包
此軟體包可用於將輸入文字劃分為單詞。我們可以使用以下命令匯入它:
from nltk.tokenize import word_tokenize
WordPunctTokenizer 軟體包
此軟體包可用於將輸入文字劃分為單詞和標點符號。我們可以使用以下命令匯入它:
from nltk.tokenize import WordPuncttokenizer
詞幹提取
由於語法原因,語言包含大量變體。變體是指語言(英語和其他語言)具有一個單詞的不同形式。例如,諸如 democracy、democratic 和 democratization 之類的單詞。對於機器學習專案,機器理解這些不同的單詞(如上所示)具有相同的詞根形式非常重要。這就是為什麼在分析文字時提取單詞的詞根形式非常有用的原因。
詞幹提取是一個啟發式過程,它透過去除單詞的結尾來幫助提取單詞的詞根形式。
NLTK 模組提供的不同詞幹提取軟體包如下:
PorterStemmer 軟體包
此詞幹提取軟體包使用 Porter 演算法來提取單詞的詞根形式。我們可以使用以下命令匯入此軟體包:
from nltk.stem.porter import PorterStemmer
例如,‘write’ 將是將 ‘writing’ 作為輸入提供給此詞幹提取器時的輸出。
LancasterStemmer 軟體包
此詞幹提取軟體包使用 Lancaster 演算法來提取單詞的詞根形式。我們可以使用以下命令匯入此軟體包:
from nltk.stem.lancaster import LancasterStemmer
例如,‘writ’ 將是將 ‘writing’ 作為輸入提供給此詞幹提取器時的輸出。
SnowballStemmer 軟體包
此詞幹提取軟體包使用 Snowball 演算法來提取單詞的詞根形式。我們可以使用以下命令匯入此軟體包:
from nltk.stem.snowball import SnowballStemmer
例如,‘write’ 將是將 ‘writing’ 作為輸入提供給此詞幹提取器時的輸出。
詞形還原
這是另一種提取單詞詞根形式的方法,通常旨在透過使用詞彙和形態分析來去除屈折詞尾。詞形還原後,任何單詞的詞根形式稱為詞形。
NLTK 模組為詞形還原提供以下軟體包:
WordNetLemmatizer 軟體包
此軟體包將根據單詞用作名詞還是動詞來提取單詞的詞根形式。以下命令可用於匯入此軟體包:
from nltk.stem import WordNetLemmatizer
詞性標註計數 - 組塊分析
可以使用組塊分析來識別詞性 (POS) 和短語。它是自然語言處理中的重要過程之一。正如我們瞭解用於建立標記的分詞過程一樣,組塊分析實際上是對這些標記進行標記。換句話說,我們可以說我們可以透過組塊分析過程獲得句子的結構。
示例
在下面的示例中,我們將實現名詞短語組塊分析(一種組塊分析類別),它將使用 NLTK Python 模組在句子中查詢名詞短語組塊。
請考慮以下步驟來實現名詞短語組塊分析:
步驟 1:組塊語法定義
在此步驟中,我們需要定義組塊的語法。它將包含我們需要遵循的規則。
步驟 2:建立組塊分析器
接下來,我們需要建立一個組塊分析器。它將解析語法並給出輸出。
步驟 3:輸出
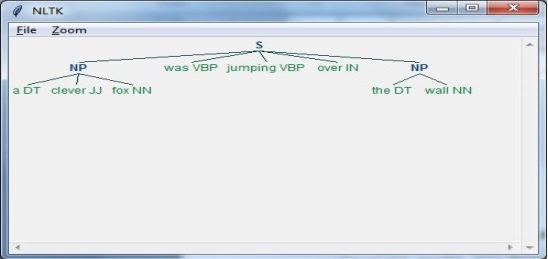
在此步驟中,我們將以樹狀格式獲得輸出。
執行 NLP 指令碼
首先匯入 NLTK 軟體包:
import nltk
現在,我們需要定義句子。
這裡,
DT 是限定詞
VBP 是動詞
JJ 是形容詞
IN 是介詞
NN 是名詞
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]
接下來,語法應該以正則表示式的形式給出。
grammar = "NP:{<DT>?<JJ>*<NN>}"
現在,我們需要定義一個用於解析語法的分析器。
parser_chunking = nltk.RegexpParser(grammar)
現在,分析器將如下解析句子:
parser_chunking.parse(sentence)
接下來,輸出將儲存在以下變數中:
Output = parser_chunking.parse(sentence)
現在,以下程式碼將幫助您以樹狀形式繪製輸出。
output.draw()