NLP - 資訊檢索
資訊檢索 (IR) 可以定義為一種軟體程式,它處理從文件儲存庫(特別是文字資訊)中組織、儲存、檢索和評估資訊。該系統幫助使用者找到他們需要的資訊,但它不會明確地返回問題的答案。它告知可能包含所需資訊文件的存在和位置。滿足使用者需求的文件稱為相關文件。完美的 IR 系統只會檢索相關文件。
藉助下圖,我們可以瞭解資訊檢索 (IR) 的過程:
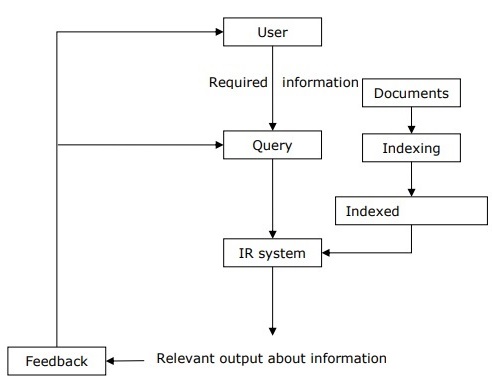
從上圖可以清楚地看出,需要資訊的使用者必須以自然語言查詢的形式提出請求。然後,IR 系統將透過以文件形式檢索相關輸出,來響應所需資訊。
資訊檢索 (IR) 系統中的經典問題
IR 研究的主要目標是開發一個從文件儲存庫中檢索資訊的模型。在這裡,我們將討論一個與 IR 系統相關的經典問題,稱為 **臨時檢索問題**。
在臨時檢索中,使用者必須輸入一個用自然語言描述所需資訊的查詢。然後,IR 系統將返回與所需資訊相關的所需文件。例如,假設我們在網際網路上搜索某些內容,它會提供一些根據我們的需求相關的精確頁面,但也可能有一些不相關的頁面。這是由於臨時檢索問題造成的。
臨時檢索的方面
以下是 IR 研究中解決的一些臨時檢索方面:
使用者如何藉助相關反饋改進查詢的原始表述?
如何實現資料庫合併,即如何將來自不同文字資料庫的結果合併到一個結果集中?
如何處理部分損壞的資料?哪些模型適用於此?
資訊檢索 (IR) 模型
在數學上,模型被用於許多科學領域,其目標是理解現實世界中的一些現象。資訊檢索模型預測並解釋使用者在與給定查詢相關的方面會發現什麼。IR 模型基本上是一個模式,它定義了上述檢索過程的各個方面,幷包括以下內容:
文件模型。
查詢模型。
將查詢與文件進行比較的匹配函式。
在數學上,檢索模型包括:
**D** - 文件表示。
**R** - 查詢表示。
**F** - D、Q 的建模框架以及它們之間關係。
**R (q,di)** - 一個相似度函式,根據查詢對文件進行排序。它也稱為排序。
資訊檢索 (IR) 模型的型別
資訊模型 (IR) 模型可以分為以下三種模型:
經典 IR 模型
這是最簡單且易於實現的 IR 模型。該模型基於數學知識,易於識別和理解。布林、向量和機率是三種經典的 IR 模型。
非經典 IR 模型
它與經典 IR 模型完全相反。此類 IR 模型基於相似性、機率、布林運算以外的原理。資訊邏輯模型、情境理論模型和互動模型是非經典 IR 模型的示例。
替代 IR 模型
它是經典 IR 模型的增強,利用了來自其他領域的一些特定技術。聚類模型、模糊模型和潛在語義索引 (LSI) 模型是替代 IR 模型的示例。
資訊檢索 (IR) 系統的設計特徵
現在讓我們學習一下 IR 系統的設計特徵:
倒排索引
大多數 IR 系統的主要資料結構採用倒排索引的形式。我們可以將倒排索引定義為一種資料結構,它列出每個單詞包含它的所有文件以及在文件中出現的頻率。它可以輕鬆搜尋查詢詞的“命中”。
停用詞消除
停用詞是指那些頻率很高的詞,被認為不太可能用於搜尋。它們的語義權重較低。所有此類單詞都位於一個稱為停用詞列表的列表中。例如,冠詞“a”、“an”、“the”和介詞如“in”、“of”、“for”、“at”等是停用詞的示例。停用詞列表可以顯著減少倒排索引的大小。根據齊夫定律,包含幾十個單詞的停用詞列表將倒排索引的大小減少了近一半。另一方面,有時停用詞的消除可能會導致用於搜尋的有用術語的消除。例如,如果我們從“維生素 A”中消除字母“A”,則它將沒有任何意義。
詞幹提取
詞幹提取,形態分析的簡化形式,是透過擷取單詞結尾來提取單詞基本形式的啟發式過程。例如,單詞 laughing、laughs、laughed 將被詞幹提取為根詞 laugh。
在我們接下來的章節中,我們將討論一些重要且有用的 IR 模型。
布林模型
這是最古老的資訊檢索 (IR) 模型。該模型基於集合論和布林代數,其中文件是術語的集合,查詢是術語上的布林表示式。布林模型可以定義為:
**D** - 一組詞,即文件中存在的索引詞。這裡,每個詞要麼存在 (1),要麼不存在 (0)。
**Q** - 一個布林表示式,其中術語是索引詞,運算子是邏輯積 - AND、邏輯和 - OR 和邏輯差 - NOT
**F** - 布林代數,作用於術語集以及文件集
如果我們談論相關反饋,那麼在布林 IR 模型中,相關預測可以定義如下:
**R** - 當且僅當文件滿足查詢表示式時,才預測文件與查詢表示式相關,如下所示:
((𝑡𝑒𝑥𝑡 ˅ 𝑖𝑛𝑓𝑜𝑟𝑚𝑎𝑡𝑖𝑜𝑛) ˄ 𝑟𝑒𝑟𝑖𝑒𝑣𝑎𝑙 ˄ ˜ 𝑡ℎ𝑒𝑜𝑟𝑦)
我們可以透過將查詢詞解釋為文件集的明確定義來解釋此模型。
例如,查詢詞 **“經濟”** 定義了用術語 **“經濟”** 索引的文件集。
現在,使用布林 AND 運算子組合術語後的結果是什麼?它將定義一個文件集,該文件集小於或等於任何單個術語的文件集。例如,帶有術語 **“社會”** 和 **“經濟”** 的查詢將生成用這兩個術語索引的文件集。換句話說,這兩個集合的交集的文件集。
現在,使用布林 OR 運算子組合術語後的結果是什麼?它將定義一個文件集,該文件集大於或等於任何單個術語的文件集。例如,帶有術語 **“社會”** 或 **“經濟”** 的查詢將生成用術語 **“社會”** 或 **“經濟”** 索引的文件集。換句話說,這兩個集合的並集的文件集。
布林模型的優點
布林模型的優點如下:
最簡單的模型,基於集合。
易於理解和實現。
它只檢索完全匹配。
它讓使用者對系統有一種控制感。
布林模型的缺點
布林模型的缺點如下:
該模型的相似度函式是布林函式。因此,不會有任何部分匹配。這可能會讓使用者感到煩惱。
在此模型中,布林運算子的使用比關鍵詞的影響更大。
查詢語言具有表現力,但也過於複雜。
檢索到的文件沒有排名。
向量空間模型
由於布林模型的上述缺點,Gerard Salton 和他的同事提出了一種基於 Luhn 相似性準則的模型。Luhn 制定的相似性準則指出,“兩個表示在給定元素及其分佈方面越一致,則它們表示相似資訊的機率就越高。”
請考慮以下要點,以更深入地瞭解向量空間模型:
索引表示(文件)和查詢被視為嵌入在高維歐幾里得空間中的向量。
文件向量與查詢向量的相似度度量通常是它們之間角度的餘弦。
餘弦相似度度量公式
餘弦是歸一化的點積,可以使用以下公式計算:
$$Score \lgroup \vec{d} \vec{q} \rgroup= \frac{\sum_{k=1}^m d_{k}\:.q_{k}}{\sqrt{\sum_{k=1}^m\lgroup d_{k}\rgroup^2}\:.\sqrt{\sum_{k=1}^m}m\lgroup q_{k}\rgroup^2 }$$
$$Score \lgroup \vec{d} \vec{q}\rgroup =1\:when\:d =q $$
$$Score \lgroup \vec{d} \vec{q}\rgroup =0\:when\:d\:and\:q\:share\:no\:items$$
帶查詢和文件的向量空間表示
查詢和文件由二維向量空間表示。術語為 **“汽車”** 和 **“保險”**。向量空間中有一個查詢和三個文件。
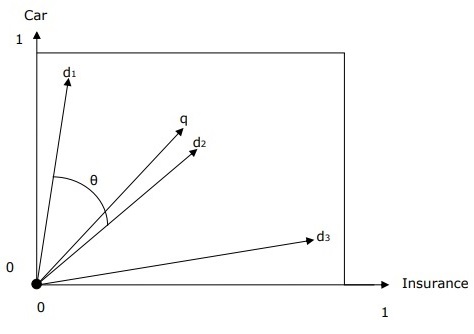
針對術語“汽車”和“保險”的排名最高的文件將是文件 **d2**,因為 **q** 和 **d2** 之間的角度最小。其背後的原因是,“汽車”和“保險”這兩個概念在 d2 中都很突出,因此權重很高。另一方面,**d1** 和 **d3** 也提到了這兩個術語,但在每種情況下,其中一個都不是文件中的核心重要術語。
術語權重
詞項權重指的是向量空間中詞項的權重。詞項權重越高,該詞項對餘弦相似度的影響就越大。模型中應該為更重要的詞項分配更大的權重。現在的問題是,我們如何對詞項權重進行建模。
一種方法是將文件中詞項出現的次數作為其詞項權重。但是,你認為這是一種有效的方法嗎?
另一種更有效的方法是使用**詞頻 (tfij)、文件頻率 (dfi)** 和**集合頻率 (cfi)**。
詞頻 (tfij)
它可以定義為**wi** 在**dj** 中出現的次數。詞頻捕捉的資訊是某個詞在給定文件中的顯著程度,換句話說,詞頻越高,該詞就越能很好地描述文件的內容。
文件頻率 (dfi)
它可以定義為集合中包含**wi** 的文件總數。它是一個資訊量指標。與語義不集中的詞不同,語義集中的詞會在文件中出現多次。
集合頻率 (cfi)
它可以定義為**wi** 在整個集合中出現的總次數。
數學上,$df_{i}\leq cf_{i}\:and\:\sum_{j}tf_{ij} = cf_{i}$
文件頻率權重的形式
現在讓我們學習文件頻率權重的不同形式。這些形式描述如下:
詞頻因子
這也被稱為詞頻因子,這意味著如果某個詞項**t** 在文件中經常出現,那麼包含**t** 的查詢應該檢索該文件。我們可以將詞項的**詞頻 (tfij)** 和**文件頻率 (dfi)** 組合成一個權重,如下所示:
$$weight \left ( i,j \right ) =\begin{cases}(1+log(tf_{ij}))log\frac{N}{df_{i}}\:if\:tf_{i,j}\:\geq1\\0 \:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\: if\:tf_{i,j}\:=0\end{cases}$$
這裡 N 是文件總數。
逆文件頻率 (idf)
這是另一種文件頻率權重形式,通常稱為 idf 權重或逆文件頻率權重。idf 權重的一個重要點是,詞項在整個集合中的稀缺性是其重要性的衡量標準,而重要性與出現頻率成反比。
數學上,
$$idf_{t} = log\left(1+\frac{N}{n_{t}}\right)$$
$$idf_{t} = log\left(\frac{N-n_{t}}{n_{t}}\right)$$
這裡,
N = 集合中的文件數
nt = 包含詞項 t 的文件數
使用者查詢改進
任何資訊檢索系統的首要目標必須是準確性——根據使用者的需求生成相關的文件。但是,這裡出現的問題是如何透過改進使用者的查詢形成風格來提高輸出。當然,任何 IR 系統的輸出都取決於使用者的查詢,而格式良好的查詢將產生更準確的結果。使用者可以透過相關反饋來改進其查詢,這是任何 IR 模型的重要方面。
相關反饋
相關反饋採用給定查詢最初返回的輸出。此初始輸出可用於收集使用者資訊,並瞭解該輸出是否相關以執行新查詢。反饋可以分類如下:
顯式反饋
它可以定義為從相關性評估者那裡獲得的反饋。這些評估者還會指示從查詢中檢索到的文件的相關性。為了提高查詢檢索效能,需要將相關反饋資訊與原始查詢插值。
系統評估人員或其他使用者可以透過以下相關性系統明確地指示相關性:
**二元相關性系統** - 此相關反饋系統指示文件對於給定查詢要麼相關 (1) 要麼不相關 (0)。
**分級相關性系統** - 分級相關反饋系統根據使用數字、字母或描述進行分級來指示文件對於給定查詢的相關性。描述可以是“不相關”、“有點相關”、“非常相關”或“相關”。
隱式反饋
它是從使用者行為中推斷出的反饋。行為包括使用者檢視文件花費的時間長短、選擇檢視哪些文件、頁面瀏覽和滾動操作等。隱式反饋的最佳示例之一是**停留時間**,它衡量使用者花費在檢視搜尋結果中連結到的頁面上的時間。
偽反饋
它也稱為盲反饋。它提供了一種自動本地分析的方法。偽相關反饋使相關反饋的手動部分自動化,以便使用者無需擴充套件互動即可獲得改進的檢索效能。此反饋系統的主要優點是它不需要像顯式相關反饋系統那樣的評估人員。
考慮以下步驟來實現此反饋:
**步驟 1** - 首先,初始查詢返回的結果必須作為相關結果。相關結果的範圍必須在排名前 10-50 的結果中。
**步驟 2** - 現在,例如使用詞頻 (tf) - 逆文件頻率 (idf) 權重從文件中選擇前 20-30 個詞項。
**步驟 3** - 將這些詞項新增到查詢中並匹配返回的文件。然後返回最相關的文件。