- Lucene 教程
- Lucene - 首頁
- Lucene - 概述
- Lucene - 環境設定
- Lucene - 第一個應用程式
- Lucene - 索引類
- Lucene - 搜尋類
- Lucene - 索引過程
- Lucene - 索引操作
- Lucene - 搜尋操作
- Lucene - 查詢程式設計
- Lucene - 分析
- Lucene - 排序
- Lucene 有用資源
- Lucene - 快速指南
- Lucene - 有用資源
- Lucene - 討論
Lucene - 搜尋操作
搜尋過程是 Lucene 提供的核心功能之一。下圖說明了該過程及其用途。IndexSearcher 是搜尋過程的核心元件之一。
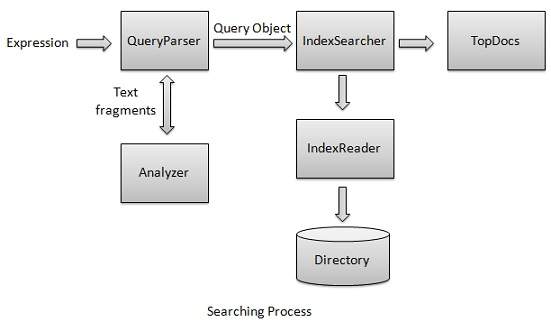
我們首先建立包含索引的Directory(s),然後將其傳遞給IndexSearcher,後者使用IndexReader開啟Directory。然後,我們使用Term建立一個Query,並透過將Query傳遞給搜尋器來使用IndexSearcher進行搜尋。IndexSearcher返回一個TopDocs物件,其中包含搜尋詳細資訊以及作為搜尋結果的Document的文件ID。
我們現在將向您展示一個分步方法,並幫助您使用一個基本示例理解索引過程。
建立 QueryParser
QueryParser 類將使用者輸入解析為 Lucene 可理解格式的查詢。請按照以下步驟建立 QueryParser:
步驟 1 - 建立 QueryParser 物件。
步驟 2 - 使用具有版本資訊和要在此查詢上執行的索引名稱的標準分析器初始化建立的 QueryParser 物件。
QueryParser queryParser;
public Searcher(String indexDirectoryPath) throws IOException {
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
建立 IndexSearcher
IndexSearcher 類充當核心元件,搜尋在索引過程中建立的索引。請按照以下步驟建立 IndexSearcher:
步驟 1 - 建立 IndexSearcher 物件。
步驟 2 - 建立一個 Lucene 目錄,該目錄應指向要儲存索引的位置。
步驟 3 - 使用索引目錄初始化建立的 IndexSearcher 物件。
IndexSearcher indexSearcher;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
}
進行搜尋
請按照以下步驟進行搜尋:
步驟 1 - 透過 QueryParser 解析搜尋表示式來建立 Query 物件。
步驟 2 - 透過呼叫 IndexSearcher.search() 方法進行搜尋。
Query query;
public TopDocs search( String searchQuery) throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
獲取文件
以下程式演示如何獲取文件。
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
關閉 IndexSearcher
以下程式演示如何關閉 IndexSearcher。
public void close() throws IOException {
indexSearcher.close();
}
示例應用程式
讓我們建立一個測試 Lucene 應用程式來測試搜尋過程。
| 步驟 | 描述 |
|---|---|
| 1 | 如Lucene - 第一個應用程式章節中所述,在com.tutorialspoint.lucene包下建立一個名為LuceneFirstApplication的專案。您也可以使用Lucene - 第一個應用程式章節中建立的專案來理解搜尋過程。 |
| 2 | 如Lucene - 第一個應用程式章節中所述,建立LuceneConstants.java,TextFileFilter.java和Searcher.java。保持其餘檔案不變。 |
| 3 | 建立如下所示的LuceneTester.java。 |
| 4 | 清理並構建應用程式,以確保業務邏輯按要求工作。 |
LuceneConstants.java
此類用於提供可在示例應用程式中使用的各種常量。
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
此類用作.txt檔案過濾器。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Searcher.java
此類用於讀取對原始資料生成的索引,並使用 Lucene 庫搜尋資料。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}
LuceneTester.java
此類用於測試 Lucene 庫的搜尋功能。
package com.tutorialspoint.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void search(String searchQuery) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) +" ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}
資料和索引目錄建立
我們使用了 10 個名為 record1.txt 到 record10.txt 的文字檔案,其中包含學生姓名和其他詳細資訊,並將它們放在 E:\Lucene\Data 目錄中。測試資料。應建立索引目錄路徑為 E:\Lucene\Index。在Lucene - 索引過程章節中執行索引程式後,您可以在該資料夾中看到建立的索引檔案列表。
執行程式
完成原始碼、原始資料、資料目錄、索引目錄和索引的建立後,您可以透過編譯和執行程式繼續進行。為此,請保持LuceneTester.Java檔案選項卡處於活動狀態,並使用 Eclipse IDE 中提供的“執行”選項,或使用Ctrl + F11編譯和執行您的LuceneTester應用程式。如果您的應用程式成功執行,它將在 Eclipse IDE 的控制檯中列印以下訊息:
1 documents found. Time :29 ms File: E:\Lucene\Data\record4.txt