- Lucene 教程
- Lucene - 首頁
- Lucene - 概述
- Lucene - 環境搭建
- Lucene - 第一個應用程式
- Lucene - 索引類
- Lucene - 搜尋類
- Lucene - 索引過程
- Lucene - 索引操作
- Lucene - 搜尋操作
- Lucene - 查詢程式設計
- Lucene - 分析
- Lucene - 排序
- Lucene 有用資源
- Lucene 快速指南
- Lucene - 有用資源
- Lucene - 討論
Lucene 快速指南
Lucene - 概述
Lucene是一個簡單而強大的基於Java的搜尋庫。它可以用於任何應用程式,為其新增搜尋功能。Lucene是一個開源專案,具有可擴充套件性。這個高效能的庫用於索引和搜尋幾乎任何型別的文字。Lucene庫提供了任何搜尋應用程式所需的核心操作:索引和搜尋。
搜尋應用程式是如何工作的?
搜尋應用程式執行所有或部分以下操作:
| 步驟 | 標題 | 描述 |
|---|---|---|
| 1 | 獲取原始內容 |
任何搜尋應用程式的第一步是收集目標內容,搜尋應用程式將在此內容上進行搜尋。 |
| 2 | 構建文件 |
下一步是從原始內容構建文件,搜尋應用程式可以輕鬆理解和解釋這些文件。 |
| 3 | 分析文件 |
在索引過程開始之前,需要分析文件,確定文字的哪些部分適合索引。此過程即為文件分析。 |
| 4 | 索引文件 |
一旦文件構建並分析完畢,下一步就是對其進行索引,以便可以基於某些鍵而不是文件的全部內容來檢索該文件。索引過程類似於書籍結尾處的索引,其中列出了常用詞及其頁碼,以便可以快速查詢這些詞,而無需搜尋整本書。 |
| 5 | 搜尋使用者介面 |
一旦索引資料庫準備就緒,應用程式就可以進行任何搜尋。為了方便使用者進行搜尋,應用程式必須為使用者提供一種方法或使用者介面,使用者可以在其中輸入文字並啟動搜尋過程。 |
| 6 | 構建查詢 |
一旦使用者請求搜尋文字,應用程式應該使用該文字準備一個查詢物件,該物件可用於查詢索引資料庫以獲取相關詳細資訊。 |
| 7 | 搜尋查詢 |
使用查詢物件,然後檢查索引資料庫以獲取相關詳細資訊和內容文件。 |
| 8 | 呈現結果 |
收到結果後,應用程式應該決定如何使用使用者介面向用戶顯示結果。例如,第一次顯示多少資訊等等。 |
除了這些基本操作外,搜尋應用程式還可以提供管理使用者介面,並幫助應用程式管理員根據使用者配置檔案控制搜尋級別。搜尋結果分析是任何搜尋應用程式的另一個重要和高階方面。
Lucene在搜尋應用程式中的作用
Lucene在上面提到的步驟2到步驟7中發揮作用,並提供執行所需操作的類。簡而言之,Lucene是任何搜尋應用程式的核心,並提供與索引和搜尋相關的關鍵操作。獲取內容和顯示結果留給應用程式部分處理。
在下一章中,我們將使用Lucene搜尋庫執行一個簡單的搜尋應用程式。
Lucene - 環境搭建
本教程將指導您如何準備開發環境以開始使用Spring框架的工作。本教程還將教您如何在設定Spring框架之前在您的機器上設定JDK、Tomcat和Eclipse:
步驟1 - Java開發工具包(JDK)設定
您可以從Oracle的Java網站下載最新版本的SDK:Java SE 下載。您將在下載的檔案中找到安裝JDK的說明;請按照給定的說明安裝和配置設定。最後,設定PATH和JAVA_HOME環境變數以引用包含Java和javac的目錄,通常分別為java_install_dir/bin和java_install_dir。
如果您執行的是Windows並將JDK安裝在C:\jdk1.6.0_15,則必須將以下行新增到您的C:\autoexec.bat檔案中。
set PATH = C:\jdk1.6.0_15\bin;%PATH% set JAVA_HOME = C:\jdk1.6.0_15
或者,在Windows NT/2000/XP上,您也可以右鍵單擊我的電腦,選擇屬性,然後選擇高階,然後選擇環境變數。然後,您將更新PATH值並按確定按鈕。
在Unix(Solaris、Linux等)上,如果SDK安裝在/usr/local/jdk1.6.0_15,並且您使用的是C shell,則您將把以下內容新增到您的.cshrc檔案中。
setenv PATH /usr/local/jdk1.6.0_15/bin:$PATH setenv JAVA_HOME /usr/local/jdk1.6.0_15
或者,如果您使用整合開發環境(IDE),如Borland JBuilder、Eclipse、IntelliJ IDEA或Sun ONE Studio,請編譯並執行一個簡單的程式以確認IDE知道您安裝Java的位置,否則請按照IDE文件中給出的說明進行正確的設定。
步驟2 - Eclipse IDE設定
本教程中的所有示例均使用Eclipse IDE編寫。因此,我建議您應該在您的機器上安裝最新版本的Eclipse。
要安裝Eclipse IDE,請從https://www.eclipse.org/downloads/下載最新的Eclipse二進位制檔案。下載安裝程式後,將二進位制分發版解壓縮到方便的位置。例如,在Windows上的C:\eclipse或Linux/Unix上的/usr/local/eclipse,最後適當地設定PATH變數。
可以透過在Windows機器上執行以下命令啟動Eclipse,或者您可以簡單地雙擊eclipse.exe
%C:\eclipse\eclipse.exe
可以透過在Unix(Solaris、Linux等)機器上執行以下命令啟動Eclipse:
$/usr/local/eclipse/eclipse
成功啟動後,應顯示以下結果:
步驟3 - 設定Lucene框架庫
如果啟動成功,則可以繼續設定Lucene框架。以下是您在機器上下載和安裝框架的簡單步驟。
https://archive.apache.org/dist/lucene/java/3.6.2/
選擇您是想在Windows還是Unix上安裝Lucene,然後繼續下一步下載Windows的.zip檔案和Unix的.tz檔案。
從https://archive.apache.org/dist/lucene/java/下載合適的Lucene框架二進位制檔案版本。
在撰寫本教程時,我在我的Windows機器上下載了lucene-3.6.2.zip,當您解壓縮下載的檔案時,它將在C:\lucene-3.6.2中為您提供如下所示的目錄結構。

您將在C:\lucene-3.6.2目錄中找到所有Lucene庫。確保您正確地在此目錄上設定CLASSPATH變數,否則,在執行應用程式時將遇到問題。如果您使用的是Eclipse,則不需要設定CLASSPATH,因為所有設定都將透過Eclipse完成。
完成最後一步後,您就可以繼續進行第一個Lucene示例,您將在下一章中看到。
Lucene - 第一個應用程式
在本章中,我們將學習使用Lucene框架進行實際程式設計。在開始使用Lucene框架編寫您的第一個示例之前,您必須確保已正確設定Lucene環境,如Lucene - 環境搭建教程中所述。建議您瞭解Eclipse IDE的工作知識。
現在讓我們繼續編寫一個簡單的搜尋應用程式,該應用程式將列印找到的搜尋結果數量。我們還將看到在此過程中建立的索引列表。
步驟1 - 建立Java專案
第一步是使用Eclipse IDE建立一個簡單的Java專案。選擇檔案 > 新建 > 專案選項,最後從嚮導列表中選擇Java專案嚮導。現在使用嚮導視窗將您的專案命名為LuceneFirstApplication,如下所示:

成功建立專案後,您的專案資源管理器中將包含以下內容:
步驟2 - 新增所需的庫
現在讓我們在專案中新增Lucene核心框架庫。為此,右鍵單擊您的專案名稱LuceneFirstApplication,然後按照上下文選單中提供的以下選項操作:構建路徑 > 配置構建路徑,以顯示Java構建路徑視窗,如下所示:
現在使用庫選項卡下提供的新增外部JAR按鈕,從Lucene安裝目錄新增以下核心JAR:
- lucene-core-3.6.2
步驟3 - 建立原始檔
現在讓我們在LuceneFirstApplication專案下建立實際的原始檔。首先,我們需要建立一個名為com.tutorialspoint.lucene的包。為此,右鍵單擊包資源管理器部分中的src,然後選擇:新建 > 包。
接下來,我們將在com.tutorialspoint.lucene包下建立LuceneTester.java和其他Java類。
LuceneConstants.java
此類用於提供要在示例應用程式中使用的各種常量。
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
此類用作.txt 檔案過濾器。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Indexer.java
此類用於索引原始資料,以便我們可以使用Lucene庫對其進行搜尋。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.numDocs();
}
}
Searcher.java
此類用於搜尋Indexer建立的索引以搜尋請求的內容。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}
LuceneTester.java
此類用於測試lucene庫的索引和搜尋功能。
package com.tutorialspoint.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Indexer indexer;
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
private void search(String searchQuery) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime));
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "
+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}
步驟4 - 資料和索引目錄建立
我們使用了10個文字檔案(從record1.txt到record10.txt),其中包含學生姓名和其他詳細資訊,並將它們放在E:\Lucene\Data目錄中。測試資料。應建立索引目錄路徑為E:\Lucene\Index。執行此程式後,您可以在該資料夾中看到建立的索引檔案列表。
步驟5 - 執行程式
完成原始碼、原始資料、資料目錄和索引目錄的建立後,您就可以編譯和執行程式了。為此,保持LuceneTester.Java檔案選項卡處於活動狀態,並使用Eclipse IDE中提供的執行選項或使用Ctrl + F11來編譯和執行LuceneTester應用程式。如果應用程式成功執行,它將在Eclipse IDE的控制檯中列印以下訊息:
Indexing E:\Lucene\Data\record1.txt Indexing E:\Lucene\Data\record10.txt Indexing E:\Lucene\Data\record2.txt Indexing E:\Lucene\Data\record3.txt Indexing E:\Lucene\Data\record4.txt Indexing E:\Lucene\Data\record5.txt Indexing E:\Lucene\Data\record6.txt Indexing E:\Lucene\Data\record7.txt Indexing E:\Lucene\Data\record8.txt Indexing E:\Lucene\Data\record9.txt 10 File indexed, time taken: 109 ms 1 documents found. Time :0 File: E:\Lucene\Data\record4.txt
成功執行程式後,您的索引目錄中將包含以下內容:

Lucene - 索引類
索引過程是Lucene提供的核心功能之一。下圖說明了索引過程和類的使用。IndexWriter是索引過程中最重要和最核心的元件。
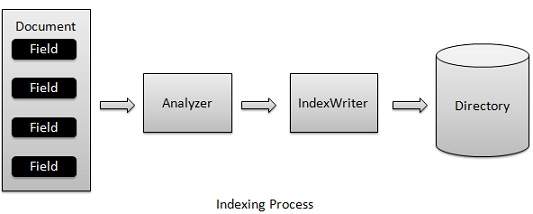
我們將包含欄位(Field)的文件(Document)新增到IndexWriter中,IndexWriter使用分析器(Analyzer)分析文件(Document),然後根據需要建立/開啟/編輯索引,並將它們儲存/更新到目錄(Directory)中。IndexWriter用於更新或建立索引,不用於讀取索引。
索引類
以下是索引過程中常用的一些類。
| 序號 | 類與描述 |
|---|---|
| 1 | IndexWriter
此類是核心元件,在索引過程中建立/更新索引。 |
| 2 | Directory
此類表示索引的儲存位置。 |
| 3 | Analyzer
此類負責分析文件並從要索引的文字中獲取標記/單詞。如果沒有進行分析,IndexWriter就無法建立索引。 |
| 4 | Document
此類表示一個虛擬文件,其中包含欄位(Field),欄位是一個物件,可以包含物理文件的內容、元資料等。只有分析器(Analyzer)才能理解Document。 |
| 5 | Field
這是索引過程的最小單位或起點。它表示鍵值對關係,其中鍵用於標識要索引的值。例如,一個用於表示文件內容的欄位,其鍵為“contents”,值可能包含文件文字或數值內容的一部分或全部。Lucene只能索引文字或數值內容。 |
Lucene - 搜尋類
搜尋過程也是Lucene提供的核心功能之一。其流程與索引過程類似。Lucene的基本搜尋可以使用以下類進行,這些類也可以被稱為所有搜尋相關操作的基礎類。
搜尋類
以下是搜尋過程中常用的一些類。
| 序號 | 類與描述 |
|---|---|
| 1 | IndexSearcher
此類是核心元件,讀取/搜尋索引過程結束後建立的索引。它接收指向包含索引的位置的目錄例項。 |
| 2 | Term
此類是搜尋的最小單位。它類似於索引過程中的Field。 |
| 3 | Query
Query是一個抽象類,包含各種實用方法,是Lucene在搜尋過程中使用所有型別查詢的父類。 |
| 4 | TermQuery
TermQuery是最常用的查詢物件,也是Lucene可以使用的許多複雜查詢的基礎。 |
| 5 | TopDocs
TopDocs指向與搜尋條件匹配的前N個搜尋結果。它是一個簡單的容器,包含指向文件的指標,這些文件是搜尋結果的輸出。 |
Lucene - 索引過程
索引過程是Lucene提供的核心功能之一。下圖說明了索引過程和類的使用。IndexWriter是索引過程中最重要的核心元件。
我們將包含欄位(Field)的文件(Document)新增到IndexWriter中,IndexWriter使用分析器(Analyzer)分析文件,然後建立/開啟/編輯索引,並將它們儲存/更新到目錄(Directory)中。IndexWriter用於更新或建立索引,不用於讀取索引。
現在,我們將透過一個基本示例逐步講解索引過程。
建立文件
建立一個方法,從文字檔案中獲取Lucene文件。
建立各種型別的欄位,這些欄位是鍵值對,鍵為名稱,值為要索引的內容。
設定欄位是否要分析。在本例中,只有內容需要分析,因為它可能包含諸如a、am、are、an等在搜尋操作中不需要的資料。
將新建立的欄位新增到文件物件,並將其返回給呼叫方法。
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS,
new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
建立IndexWriter
IndexWriter類是核心元件,在索引過程中建立/更新索引。請按照以下步驟建立IndexWriter:
步驟1 - 建立IndexWriter物件。
步驟2 - 建立一個Lucene目錄,該目錄應指向儲存索引的位置。
步驟3 - 使用索引目錄、包含版本資訊的標準分析器和其他必需/可選引數初始化建立的IndexWriter物件。
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}
開始索引過程
以下程式顯示如何啟動索引過程:
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
示例應用程式
為了測試索引過程,我們需要建立一個Lucene應用程式測試。
| 步驟 | 描述 |
|---|---|
| 1 | 如Lucene - 第一個應用程式章節所述,在com.tutorialspoint.lucene包下建立一個名為LuceneFirstApplication的專案。您也可以使用Lucene - 第一個應用程式章節中建立的專案來理解索引過程。 |
| 2 | 如Lucene - 第一個應用程式章節所述,建立LuceneConstants.java,TextFileFilter.java和Indexer.java。保持其餘檔案不變。 |
| 3 | 建立如下所示的LuceneTester.java。 |
| 4 | 清理並構建應用程式,以確保業務邏輯按要求工作。 |
LuceneConstants.java
此類用於提供要在示例應用程式中使用的各種常量。
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
此類用作.txt檔案過濾器。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Indexer.java
此類用於索引原始資料,以便我們可以使用Lucene庫對其進行搜尋。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS,
new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.numDocs();
}
}
LuceneTester.java
此類用於測試Lucene庫的索引功能。
package com.tutorialspoint.lucene;
import java.io.IOException;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Indexer indexer;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
} catch (IOException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
}
資料和索引目錄建立
我們使用了10個文字檔案,從record1.txt到record10.txt,包含學生姓名和其他詳細資訊,並將它們放在E:\Lucene\Data目錄中。測試資料。應建立索引目錄路徑為E:\Lucene\Index。執行此程式後,您可以在該資料夾中看到建立的索引檔案列表。
執行程式
完成原始碼、原始資料、資料目錄和索引目錄的建立後,您可以透過編譯和執行程式繼續進行。為此,請保持LuceneTester.Java檔案選項卡處於活動狀態,並使用Eclipse IDE中提供的執行選項,或使用Ctrl + F11編譯和執行LuceneTester應用程式。如果您的應用程式成功執行,它將在Eclipse IDE的控制檯中列印以下訊息:
Indexing E:\Lucene\Data\record1.txt Indexing E:\Lucene\Data\record10.txt Indexing E:\Lucene\Data\record2.txt Indexing E:\Lucene\Data\record3.txt Indexing E:\Lucene\Data\record4.txt Indexing E:\Lucene\Data\record5.txt Indexing E:\Lucene\Data\record6.txt Indexing E:\Lucene\Data\record7.txt Indexing E:\Lucene\Data\record8.txt Indexing E:\Lucene\Data\record9.txt 10 File indexed, time taken: 109 ms
成功執行程式後,您的索引目錄中將包含以下內容:
Lucene - 索引操作
在本節中,我們將討論索引的四個主要操作。這些操作在不同時間非常有用,並在整個軟體搜尋應用程式中使用。
索引操作
以下是索引過程中常用的一些操作。
| 序號 | 操作與描述 |
|---|---|
| 1 | 新增文件
此操作用於索引過程的初始階段,以對新可用內容建立索引。 |
| 2 | 更新文件
此操作用於更新索引以反映更新內容中的更改。它類似於重新建立索引。 |
| 3 | 刪除文件
此操作用於更新索引以排除不需要索引/搜尋的文件。 |
| 4 | 欄位選項
欄位選項指定一種方式或控制欄位內容的可搜尋方式。 |
Lucene - 搜尋操作
搜尋過程是Lucene提供的核心功能之一。下圖說明了該過程及其使用。IndexSearcher是搜尋過程的核心元件之一。
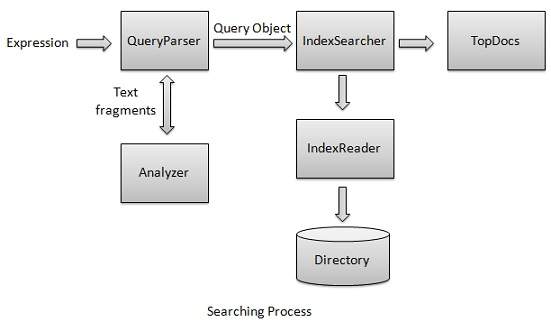
我們首先建立包含索引的目錄(Directory),然後將其傳遞給IndexSearcher,IndexSearcher使用IndexReader開啟目錄。然後,我們使用Term建立一個Query,並透過將Query傳遞給搜尋器來使用IndexSearcher進行搜尋。IndexSearcher返回一個TopDocs物件,該物件包含搜尋詳細資訊以及作為搜尋操作結果的Document的文件ID。
我們現在將向您展示一種分步方法,並幫助您使用基本示例來理解索引過程。
建立一個QueryParser
QueryParser類將使用者輸入解析為Lucene可理解的格式查詢。請按照以下步驟建立QueryParser:
步驟1 - 建立QueryParser物件。
步驟2 - 使用包含版本資訊和要在此查詢上執行的索引名稱的標準分析器初始化建立的QueryParser物件。
QueryParser queryParser;
public Searcher(String indexDirectoryPath) throws IOException {
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
建立一個IndexSearcher
IndexSearcher類是核心元件,搜尋在索引過程中建立的索引。請按照以下步驟建立IndexSearcher:
步驟1 - 建立IndexSearcher物件。
步驟2 - 建立一個Lucene目錄,該目錄應指向儲存索引的位置。
步驟3 - 使用索引目錄初始化建立的IndexSearcher物件。
IndexSearcher indexSearcher;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
}
進行搜尋
請按照以下步驟進行搜尋:
步驟1 - 透過QueryParser解析搜尋表示式來建立Query物件。
步驟2 - 透過呼叫IndexSearcher.search()方法進行搜尋。
Query query;
public TopDocs search( String searchQuery) throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
獲取文件
以下程式顯示如何獲取文件。
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
關閉IndexSearcher
以下程式顯示如何關閉IndexSearcher。
public void close() throws IOException {
indexSearcher.close();
}
示例應用程式
讓我們建立一個測試Lucene應用程式來測試搜尋過程。
| 步驟 | 描述 |
|---|---|
| 1 | 如Lucene - 第一個應用程式章節所述,在com.tutorialspoint.lucene包下建立一個名為LuceneFirstApplication的專案。您也可以使用Lucene - 第一個應用程式章節中建立的專案來理解搜尋過程。 |
| 2 | 如Lucene - 第一個應用程式章節所述,建立LuceneConstants.java,TextFileFilter.java和Searcher.java。保持其餘檔案不變。 |
| 3 | 建立如下所示的LuceneTester.java。 |
| 4 | 清理並構建應用程式,以確保業務邏輯按要求工作。 |
LuceneConstants.java
此類用於提供要在示例應用程式中使用的各種常量。
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
此類用作.txt檔案過濾器。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Searcher.java
此類用於讀取對原始資料進行的索引,並使用Lucene庫搜尋資料。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}
LuceneTester.java
此類用於測試Lucene庫的搜尋功能。
package com.tutorialspoint.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void search(String searchQuery) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) +" ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}
資料和索引目錄建立
我們使用了10個文字檔案,命名為record1.txt到record10.txt,其中包含學生姓名和其他詳細資訊,並將它們放在E:\Lucene\Data目錄下。測試資料。索引目錄路徑應建立為E:\Lucene\Index。在執行Lucene - 索引過程章節中的索引程式後,您可以在該資料夾中看到已建立的索引檔案列表。
執行程式
完成原始碼、原始資料、資料目錄、索引目錄和索引的建立後,您可以繼續編譯並執行程式。為此,請保持LuceneTester.Java檔案選項卡處於活動狀態,並使用Eclipse IDE中提供的“執行”選項,或使用Ctrl + F11編譯並執行您的LuceneTester應用程式。如果您的應用程式成功執行,它將在Eclipse IDE的控制檯中列印以下訊息:
1 documents found. Time :29 ms File: E:\Lucene\Data\record4.txt
Lucene - 查詢程式設計
我們在之前的章節Lucene - 搜尋操作中看到,Lucene使用IndexSearcher進行搜尋,並使用QueryParser建立的Query物件作為輸入。在本節中,我們將討論各種型別的Query物件以及以程式設計方式建立它們的不同方法。建立不同型別的Query物件可以控制要進行的搜尋型別。
考慮許多應用程式提供的“高階搜尋”案例,其中為使用者提供了多個選項來限制搜尋結果。透過Query程式設計,我們可以很容易地實現這一點。
以下是我們將陸續討論的Query型別列表。
| 序號 | 類與描述 |
|---|---|
| 1 | TermQuery
此類是核心元件,在索引過程中建立/更新索引。 |
| 2 | TermRangeQuery
當需要搜尋一定範圍的文字術語時,使用TermRangeQuery。 |
| 3 | PrefixQuery
PrefixQuery用於匹配索引以指定字串開頭的文件。 |
| 4 | BooleanQuery
BooleanQuery用於搜尋多個查詢的結果文件,使用AND、OR或NOT運算子。 |
| 5 | PhraseQuery
Phrase query用於搜尋包含特定術語序列的文件。 |
| 6 | WildCardQuery
WildcardQuery用於使用萬用字元進行搜尋,例如'*'代表任何字元序列,'?'匹配單個字元。 |
| 7 | FuzzyQuery
FuzzyQuery用於使用模糊實現進行搜尋,這是一種基於編輯距離演算法的近似搜尋。 |
| 8 | MatchAllDocsQuery
顧名思義,MatchAllDocsQuery匹配所有文件。 |
Lucene - 分析
在我們之前的章節中,我們已經看到Lucene使用IndexWriter透過Analyzer分析Document(s),然後根據需要建立/開啟/編輯索引。在本節中,我們將討論分析過程中使用的各種型別的Analyzer物件和其他相關物件。瞭解分析過程和分析器的執行方式將使您深入瞭解Lucene如何索引文件。
以下是我們將陸續討論的物件列表。
| 序號 | 類與描述 |
|---|---|
| 1 | Token
Token表示文件中的文字或單詞,以及相關詳細資訊,例如其元資料(位置、起始偏移量、結束偏移量、標記型別及其位置增量)。 |
| 2 | TokenStream
TokenStream是分析過程的輸出,它包含一系列標記。它是一個抽象類。 |
| 3 | Analyzer
這是每種型別的Analyzer的抽象基類。 |
| 4 | WhitespaceAnalyzer
此分析器根據空格拆分文件中的文字。 |
| 5 | SimpleAnalyzer
此分析器根據非字母字元拆分文件中的文字,並將文字轉換為小寫。 |
| 6 | StopAnalyzer
此分析器的工作方式與SimpleAnalyzer相同,並刪除常用詞,例如'a'、'an'、'the'等。 |
| 7 | StandardAnalyzer
這是最複雜的分析器,能夠處理姓名、電子郵件地址等。它將每個標記轉換為小寫,並刪除任何常用詞和標點符號。 |
Lucene - 排序
在本節中,我們將瞭解Lucene預設提供或可根據需要操作的搜尋結果排序順序。
按相關性排序
這是Lucene使用的預設排序模式。Lucene按最相關的命中結果從上到下提供結果。
private void sortUsingRelevance(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
searcher.setDefaultFieldSortScoring(true, false);
//do the search
TopDocs hits = searcher.search(query,Sort.RELEVANCE);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
按索引順序排序
這是Lucene使用的排序模式。在此,第一個索引的文件將首先顯示在搜尋結果中。
private void sortUsingIndex(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
searcher.setDefaultFieldSortScoring(true, false);
//do the search
TopDocs hits = searcher.search(query,Sort.INDEXORDER);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
示例應用程式
讓我們建立一個測試Lucene應用程式來測試排序過程。
| 步驟 | 描述 |
|---|---|
| 1 | 如Lucene - 第一個應用程式章節所述,在com.tutorialspoint.lucene包下建立一個名為LuceneFirstApplication的專案。您也可以使用Lucene - 第一個應用程式章節中建立的專案來理解搜尋過程。 |
| 2 | 按照Lucene - 第一個應用程式章節中的說明建立LuceneConstants.java和Searcher.java。保持其餘檔案不變。 |
| 3 | 建立如下所示的LuceneTester.java。 |
| 4 | 清理並構建應用程式,以確保業務邏輯按要求工作。 |
LuceneConstants.java
此類用於提供要在示例應用程式中使用的各種常量。
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
Searcher.java
此類用於讀取對原始資料進行的索引,並使用Lucene庫搜尋資料。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory
= FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query)
throws IOException, ParseException {
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query,Sort sort)
throws IOException, ParseException {
return indexSearcher.search(query,
LuceneConstants.MAX_SEARCH,sort);
}
public void setDefaultFieldSortScoring(boolean doTrackScores,
boolean doMaxScores) {
indexSearcher.setDefaultFieldSortScoring(
doTrackScores,doMaxScores);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}
LuceneTester.java
此類用於測試Lucene庫的搜尋功能。
package com.tutorialspoint.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.FuzzyQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Indexer indexer;
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.sortUsingRelevance("cord3.txt");
tester.sortUsingIndex("cord3.txt");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void sortUsingRelevance(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
searcher.setDefaultFieldSortScoring(true, false);
//do the search
TopDocs hits = searcher.search(query,Sort.RELEVANCE);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
private void sortUsingIndex(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
searcher.setDefaultFieldSortScoring(true, false);
//do the search
TopDocs hits = searcher.search(query,Sort.INDEXORDER);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}
資料和索引目錄建立
我們使用了10個文字檔案,從record1.txt到record10.txt,其中包含學生姓名和其他詳細資訊,並將它們放在E:\Lucene\Data目錄下。測試資料。索引目錄路徑應建立為E:\Lucene\Index。在執行Lucene - 索引過程章節中的索引程式後,您可以在該資料夾中看到已建立的索引檔案列表。
執行程式
完成原始碼、原始資料、資料目錄、索引目錄和索引的建立後,您可以編譯並執行程式。為此,請保持LuceneTester.Java檔案選項卡處於活動狀態,並使用Eclipse IDE中提供的“執行”選項,或使用Ctrl + F11編譯並執行您的LuceneTester應用程式。如果您的應用程式成功執行,它將在Eclipse IDE的控制檯中列印以下訊息:
10 documents found. Time :31ms Score: 1.3179655 File: E:\Lucene\Data\record3.txt Score: 0.790779 File: E:\Lucene\Data\record1.txt Score: 0.790779 File: E:\Lucene\Data\record2.txt Score: 0.790779 File: E:\Lucene\Data\record4.txt Score: 0.790779 File: E:\Lucene\Data\record5.txt Score: 0.790779 File: E:\Lucene\Data\record6.txt Score: 0.790779 File: E:\Lucene\Data\record7.txt Score: 0.790779 File: E:\Lucene\Data\record8.txt Score: 0.790779 File: E:\Lucene\Data\record9.txt Score: 0.2635932 File: E:\Lucene\Data\record10.txt 10 documents found. Time :0ms Score: 0.790779 File: E:\Lucene\Data\record1.txt Score: 0.2635932 File: E:\Lucene\Data\record10.txt Score: 0.790779 File: E:\Lucene\Data\record2.txt Score: 1.3179655 File: E:\Lucene\Data\record3.txt Score: 0.790779 File: E:\Lucene\Data\record4.txt Score: 0.790779 File: E:\Lucene\Data\record5.txt Score: 0.790779 File: E:\Lucene\Data\record6.txt Score: 0.790779 File: E:\Lucene\Data\record7.txt Score: 0.790779 File: E:\Lucene\Data\record8.txt Score: 0.790779 File: E:\Lucene\Data\record9.txt