
 資料結構
資料結構 網路
網路 關係型資料庫管理系統 (RDBMS)
關係型資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP在Pandas DataFrame中突出顯示負值為紅色,正值為黑色
資料分析是任何資料科學或分析任務的基本方面,資料探索過程中一個常見的要求是快速識別Pandas DataFrame中的負值和正值,以便有效地進行解釋。
在本文中,我們將探討一種使用Python中的Pandas庫的強大技術,以便在DataFrame中直觀地突出顯示負值為紅色,正值為黑色。透過採用這種方法,資料分析師和研究人員可以有效地區分正負趨勢,從而有助於深入的資料解釋和決策。
如何在Pandas DataFrame中突出顯示負值為紅色,正值為黑色?
有幾種方法可以突出顯示Pandas DataFrame中負值為紅色,正值為黑色。以下是三種常用的技術
方法一:使用Styler和Styler.applymap()
Pandas中的Styler類允許我們對DataFrame元素應用格式化。我們可以定義一個格式化函式,該函式檢查每個值的符號並返回相應的CSS樣式。然後,我們可以使用Styler.applymap()方法將此函式應用於DataFrame的每個元素。
方法二:使用Styler和Styler.background_gradient()
Styler.background_gradient()方法根據值對DataFrame應用漸變顏色對映。我們可以指定顏色範圍,例如從紅色到黑色,並將中點設定為零。此方法將自動分配顏色,負值顯示為紅色,正值顯示為黑色。
方法三:使用numpy.where()
我們可以使用numpy.where()函式建立一個新的DataFrame,其中值根據其符號替換為顏色程式碼。我們可以為負值分配紅色,為正值分配黑色。然後,我們可以以所需的顏色格式顯示DataFrame。
我們將使用程式示例來理解這些方法,但首先,讓我們看看我們將遵循的步驟
匯入必要的庫:
匯入Pandas用於處理DataFrame。
匯入numpy用於處理數值計算。
定義格式化函式:
highlight_values函式以一個值作為輸入,並返回用於格式化的CSS樣式屬性。它檢查值是否小於零,如果小於零則返回'color: red',否則返回'color: black'。
gradient_color函式以資料序列作為輸入,並使用序列的絕對值計算最大值(norm)。然後,它為序列中的每個元素返回一個CSS背景顏色樣式列表,為負值分配“紅色”,為正值分配“黑色”。
where_color函式使用numpy.where()建立一個新的DataFrame,其中值根據其符號替換為顏色程式碼。它為負值分配'color: red',為正值分配'color: black'。
建立一個示例DataFrame:
程式建立一個包含一些數值的示例DataFrame df。
應用格式化方法:
方法一:使用Styler和Styler.applymap():
使用df.style.對DataFrame df進行樣式設定。
將applymap()方法應用於樣式化的DataFrame,並將highlight_values函式作為引數傳遞。
將生成的樣式化DataFrame儲存為名為highlighted_values_method1.xlsx的Excel檔案。
方法二:使用Styler和Styler.background_gradient():
使用df.style.對DataFrame df進行樣式設定。
將apply()方法應用於樣式化的DataFrame,並將gradient_color函式作為引數傳遞。
將生成的樣式化DataFrame儲存為名為highlighted_values_method2.xlsx的Excel檔案。
方法三:使用numpy.where():
使用df.style.對DataFrame df進行樣式設定。
將apply()方法應用於樣式化的DataFrame,並將where_color函式作為引數傳遞。
將生成的樣式化DataFrame儲存為名為highlighted_values_method3.xlsx的Excel檔案。
示例
import pandas as pd
import numpy as np
# Method 1: Using Styler and Styler.applymap()
def highlight_values(x):
if x < 0:
return 'color: red'
else:
return 'color: black'
# Method 2: Using Styler and Styler.background_gradient()
def gradient_color(data):
norm = abs(data.values).max()
return ['background-color: {0}'.format('red' if x < 0 else 'black') for x in data]
# Method 3: Using numpy.where()
def where_color(df):
return np.where(df < 0, 'color: red', 'color: black')
# Create a sample DataFrame
data = {'A': [-2, 4, -1, 5, 0],
'B': [3, -6, 2, 7, -4],
'C': [-3, -2, 1, 6, -5]}
df = pd.DataFrame(data)
# Method 1: Using Styler and Styler.applymap()
styled_df = df.style.applymap(highlight_values)
styled_df.to_excel('highlighted_values_method1.xlsx', engine='openpyxl', index=False)
# Method 2: Using Styler and Styler.background_gradient()
styled_df = df.style.apply(gradient_color)
styled_df.to_excel('highlighted_values_method2.xlsx', engine='openpyxl', index=False)
# Method 3: Using numpy.where()
styled_df = df.style.apply(where_color)
styled_df.to_excel('highlighted_values_method3.xlsx', engine='openpyxl', index=False)
輸出
highlighted_values_method1.xlsx:
A B C -2 3 -3 4 -6 -2 -1 2 1 5 7 6 0 -4 -5
highlighted_values_method2.xlsx:
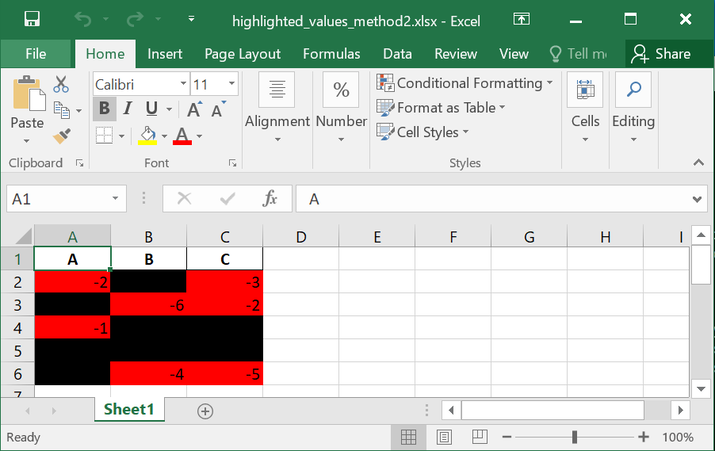
highlighted_values_method3.xlsx:
A B C -2 3 -3 4 -6 -2 -1 2 1 5 7 6 0 -4 -5
結論
總之,使用Pandas中的各種技術,例如Styler類和numpy.where(),我們可以輕鬆地突出顯示DataFrame中負值為紅色,正值為黑色。這些方法提供了一種有效的方法來直觀地解釋資料並識別趨勢或異常。

875 次瀏覽
