
 資料結構
資料結構 網路
網路 關係型資料庫管理系統
關係型資料庫管理系統 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP誤報與漏報
簡介
準確預測與不準確預測的比率繪製在一個稱為混淆矩陣的矩陣中。這將指代二元分類器(錯誤預測)中真陰性和真陽性(正確預測)與假陰性和假陽性的比率。在資料清理、預處理和解析之後,我們首先將資料饋送到一個有效的模型,該模型自然會以機率的形式生成結果。等等!但是我們如何評估模型的效能呢?
更高的效能,更好的有效性——這正是我們想要的。這時,混淆矩陣就派上用場了。混淆矩陣是機器學習分類的過程評估。本文將介紹假陽性和假陰性之間的區別。
混淆矩陣
它是使用機器學習進行分類問題的效能指標,其輸出可以是兩個甚至多個類別。表中存在四種可能的預測值和實際值組合。
與混淆矩陣相關的術語有:
真陽性 - 實際值和預測值都為正的情況。
真陰性 - 實際值和預測值都為負的情況。
假陽性 - 實際值為負,預測值為正的情況。
假陰性 - 實際值為正,預測值為負的情況。
混淆矩陣的格式如下:
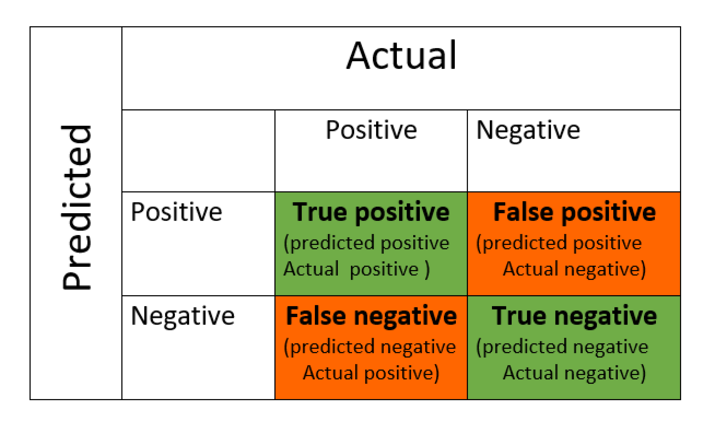
讓我們看一個例子:
假設我們想弄清楚血液癌症檢測能夠預測患者感染狀態的準確程度。這裡的冠狀病毒檢測用於區分兩種可能的狀態:感染和正常。
真陽性 - 分類器表明該人感染了,第二次癌症檢測證實了這一發現。因此,測試是正確的。
假陽性 - 某人的初步檢測結果呈陽性,但隨後的 PCR 檢測顯示該人實際上是陰性,未感染。
真陰性 - 分類器將快速檢測分類為陰性,並且該人實際上沒有感染。
假陰性 - 分類器將快速檢測分類為陽性,但該人實際上已感染且不健康,因此檢測結果應為陰性。
假陽性和假陰性之間的區別
以下是假陽性和假陰性之間的一些主要區別:
假陽性 |
假陰性 |
|---|---|
實際值為負,預測值為正的情況 |
實際值為正,預測值為負的情況。 |
也稱為“第一類錯誤” |
也稱為“第二類錯誤” |
具有兩個類別(真和假)的二元分類示例可以幫助您理解這一點。假陽性值是指那些被認為屬於“真”類別的值,但實際上它們不屬於“真”類別,而是屬於“假”類別。 |
具有兩個類別(真和假)的二元分類場景可以幫助您理解這一點。假陰性值是指那些被認為屬於“假”類別的值,但實際上它們屬於“真”類別。 |
這顯示了分類器錯誤預測期望結果的頻率。 |
此錯誤顯示了分類器錯誤預測不利結果的頻率。 |
假陽性率,也稱為誤報率,可以定義為假陽性與假陽性和真陰性之和的比率 |
假陰性與假陰性和真陽性之和的比率稱為假陰性率,通常稱為漏報率 |
非垃圾郵件被錯誤地識別為垃圾郵件。 |
垃圾郵件被錯誤地識別為非垃圾郵件。 |
結論
在本文中,我們瞭解了假陽性和假陰性之間的區別。我們如何評估機器學習模型將決定它們是成功還是失敗。為了公平地評估模型的效能,需要進行徹底的模型分析。
我們已經瞭解瞭如何使用混淆矩陣檢查機器學習分類器或模型是否正確預測了值以及模型的準確性。因此,混淆矩陣有助於評估分類器。它包含四個欄位:真陽性、真陰性、假陽性和假陰性。

601 次檢視
