- 分散式資料庫管理系統教程
- DDBMS - 首頁
- DDBMS - 資料庫管理系統概念
- DDBMS - 分散式資料庫
- 分散式資料庫設計
- 分散式資料庫環境
- DDBMS - 設計策略
- DDBMS - 分散式透明性
- DDBMS - 資料庫控制
- 分散式資料庫管理系統安全
- 資料庫安全與密碼學
- 分散式資料庫中的安全
- 分散式資料庫管理系統資源
- DDBMS - 快速指南
- DDBMS - 有用資源
- DDBMS - 討論
集中式系統中的查詢最佳化
一旦推匯出計算關係代數表示式的替代訪問路徑,就確定最佳訪問路徑。本章將探討集中式系統中的查詢最佳化,下一章將研究分散式系統中的查詢最佳化。
在集中式系統中,查詢處理的目標如下:
最小化查詢響應時間(向用戶查詢返回結果所需的時間)。
最大化系統吞吐量(在給定時間內處理的請求數量)。
減少處理所需的記憶體和儲存量。
提高並行性。
查詢解析和轉換
首先掃描SQL查詢。然後對其進行解析,以查詢語法錯誤和資料型別的正確性。如果查詢透過此步驟,則將其分解成更小的查詢塊。然後將每個塊轉換為等效的關係代數表示式。
查詢最佳化的步驟
查詢最佳化涉及三個步驟,即查詢樹生成、計劃生成和查詢計劃程式碼生成。
步驟1 - 查詢樹生成
查詢樹是一種樹形資料結構,表示關係代數表示式。查詢的表表示為葉節點。關係代數運算表示為內部節點。根表示整個查詢。
在執行過程中,只要運算元表可用,就會執行內部節點。然後用結果表替換該節點。這個過程對所有內部節點繼續進行,直到根節點被執行並被結果表替換。
例如,讓我們考慮以下模式:
員工表(EMPLOYEE)
| 員工ID (EmpID) | 員工姓名 (EName) | 薪水 (Salary) | 部門編號 (DeptNo) | 入職日期 (DateOfJoining) |
部門表(DEPARTMENT)
| 部門編號 (DNo) | 部門名稱 (DName) | 部門位置 (Location) |
示例1
讓我們考慮以下查詢:
$$ \pi_{EmpID} (\sigma_{EName = \small "ArunKumar"} {(EMPLOYEE)}) $$
相應的查詢樹將是:
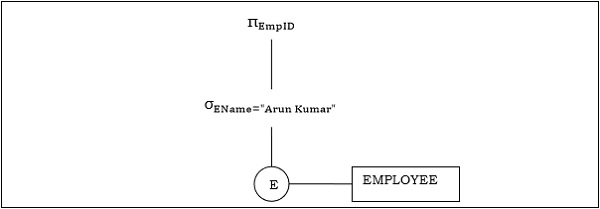
示例2
讓我們考慮另一個涉及連線的查詢。
$\pi_{EName, Salary} (\sigma_{DName = \small "Marketing"} {(DEPARTMENT)}) \bowtie_{DNo=DeptNo}{(EMPLOYEE)}$
以下是上述查詢的查詢樹。
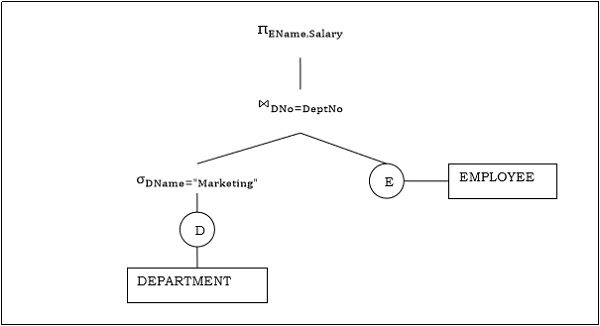
步驟2 - 查詢計劃生成
生成查詢樹後,將建立一個查詢計劃。查詢計劃是一個擴充套件的查詢樹,其中包含查詢樹中所有操作的訪問路徑。訪問路徑指定應如何執行樹中的關係運算。例如,選擇操作可以有一條訪問路徑,該路徑提供有關使用B+樹索引進行選擇的詳細資訊。
此外,查詢計劃還說明如何將中間表從一個運算子傳遞到下一個運算子,如何使用臨時表以及如何對運算子進行流水線處理/組合。
步驟3 - 程式碼生成
程式碼生成是查詢最佳化的最後一步。它是查詢的可執行形式,其形式取決於底層作業系統的型別。一旦生成查詢程式碼,執行管理器就會執行它併產生結果。
查詢最佳化的途徑
在查詢最佳化的方法中,最常用的是窮舉搜尋和基於啟發式演算法。
窮舉搜尋最佳化
在這些技術中,對於一個查詢,首先生成所有可能的查詢計劃,然後選擇最佳計劃。儘管這些技術提供了最佳解決方案,但由於解決方案空間很大,因此具有指數時間和空間複雜度。例如,動態規劃技術。
基於啟發式的最佳化
基於啟發式的最佳化使用基於規則的最佳化方法進行查詢最佳化。這些演算法具有多項式時間和空間複雜度,低於基於窮舉搜尋演算法的指數複雜度。但是,這些演算法並不一定產生最佳查詢計劃。
一些常見的啟發式規則是:
在連線操作之前執行選擇和投影操作。這是透過將選擇和投影操作向下移動到查詢樹來完成的。這減少了可用於連線的元組數量。
首先執行最嚴格的選擇/投影操作,然後再執行其他操作。
避免使用笛卡爾積運算,因為它們會導致非常大的中間表。