- 分散式資料庫管理系統教程
- DDBMS - 首頁
- DDBMS - 資料庫概念
- DDBMS - 分散式資料庫
- 分散式資料庫設計
- 分散式資料庫環境
- DDBMS - 設計策略
- DDBMS - 分散式透明性
- DDBMS - 資料庫控制
- 分散式資料庫管理系統安全
- 資料庫安全與密碼學
- 分散式資料庫中的安全
- 分散式資料庫管理系統資源
- DDBMS - 快速指南
- DDBMS - 有用資源
- DDBMS - 討論
分散式資料庫管理系統 - 死鎖處理
本章概述了資料庫系統中的死鎖處理機制。我們將研究集中式和分散式資料庫系統中的死鎖處理機制。
什麼是死鎖?
死鎖是資料庫系統的一種狀態,其中兩個或多個事務相互等待對方持有的資料項。死鎖可以透過等待圖中的迴圈來指示。這是一個有向圖,其中頂點表示事務,邊表示等待資料項。
例如,在下面的等待圖中,事務T1正在等待被T3鎖定的資料項X。T3正在等待被T2鎖定的Y,而T2正在等待被T1鎖定的Z。因此,形成了一個等待迴圈,任何事務都不能繼續執行。
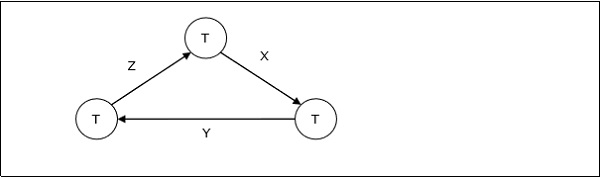
集中式系統中的死鎖處理
有三種經典的死鎖處理方法,即:
- 死鎖預防。
- 死鎖避免。
- 死鎖檢測和解除。
這三種方法都可以整合到集中式和分散式資料庫系統中。
死鎖預防
死鎖預防方法不允許任何事務獲取會導致死鎖的鎖。約定是,當多個事務請求鎖定相同的資料項時,只有一個事務可以獲得鎖。
最流行的死鎖預防方法之一是在開始執行之前預先獲取所有鎖。在這種方法中,事務在開始執行之前獲取所有鎖,並在整個事務期間保持這些鎖。如果另一個事務需要任何已獲取的鎖,則必須等到所有需要的鎖都可用。使用這種方法,可以防止系統死鎖,因為沒有任何等待的事務持有任何鎖。
死鎖避免
死鎖避免方法在死鎖發生之前處理死鎖。它分析事務和鎖以確定等待是否會導致死鎖。
該方法可以簡述如下。事務開始執行並請求它們需要鎖定的資料項。鎖管理器檢查鎖是否可用。如果可用,鎖管理器分配資料項,並且事務獲取鎖。但是,如果該項被其他事務以不相容模式鎖定,則鎖管理器將執行一個演算法來測試將事務保持在等待狀態是否會導致死鎖。相應地,演算法決定事務是否可以等待或應該中止其中一個事務。
為此,有兩種演算法,即**等待-死亡 (wait-die)** 和 **攻擊-等待 (wound-wait)**。讓我們假設有兩個事務 T1 和 T2,其中 T1 試圖鎖定已被 T2 鎖定的資料項。演算法如下:
**等待-死亡 (Wait-Die)** - 如果 T1 比 T2 舊,則允許 T1 等待。否則,如果 T1 比 T2 新,則中止 T1 並稍後重新啟動。
**攻擊-等待 (Wound-Wait)** - 如果 T1 比 T2 舊,則中止 T2 並稍後重新啟動。否則,如果 T1 比 T2 新,則允許 T1 等待。
死鎖檢測和解除
死鎖檢測和解除方法定期執行死鎖檢測演算法,並在存在死鎖時解除死鎖。當事務發出鎖定請求時,它不會檢查死鎖。當事務請求鎖時,鎖管理器檢查它是否可用。如果可用,則允許事務鎖定資料項;否則,允許事務等待。
由於在授予鎖定請求時沒有任何預防措施,因此某些事務可能會死鎖。為了檢測死鎖,鎖管理器定期檢查等待圖中是否存在迴圈。如果系統死鎖,鎖管理器將從每個迴圈中選擇一個受害者事務。受害者被中止並回滾;然後稍後重新啟動。一些用於受害者選擇的方 法包括:
- 選擇最年輕的事務。
- 選擇擁有最少資料項的事務。
- 選擇執行更新次數最少的事務。
- 選擇具有最小重啟開銷的事務。
- 選擇屬於兩個或多個迴圈的事務。
這種方法主要適用於事務量少且需要快速響應鎖定請求的系統。
分散式系統中的死鎖處理
分散式資料庫系統中的事務處理也是分散式的,即同一事務可能在多個站點上進行處理。分散式資料庫系統中存在的兩個主要死鎖處理問題在集中式系統中不存在,它們是**事務位置**和**事務控制**。一旦解決了這些問題,就可以透過任何死鎖預防、死鎖避免或死鎖檢測和解除方法來處理死鎖。
事務位置
分散式資料庫系統中的事務在多個站點上處理,並使用多個站點中的資料項。資料處理量在這些站點之間並不均勻分佈。處理的時間段也各不相同。因此,同一事務可能在某些站點處於活動狀態,而在其他站點處於非活動狀態。當兩個衝突的事務位於一個站點時,可能發生其中一個事務處於非活動狀態的情況。這種情況在集中式系統中不會出現。這個問題稱為事務位置問題。
這個問題可以透過菊花鏈模型來解決。在這個模型中,事務在從一個站點移動到另一個站點時攜帶某些詳細資訊。一些詳細資訊包括所需表列表、所需站點列表、已訪問表和站點列表、尚待訪問的表和站點列表以及已獲取鎖及其型別的列表。事務透過提交或中止終止後,應將資訊傳送到所有相關站點。
事務控制
事務控制與指定和控制分散式資料庫系統中處理事務所需的站點有關。關於在哪裡處理事務以及如何指定控制中心有很多選擇,例如:
- 可以選擇一臺伺服器作為控制中心。
- 控制中心可能會從一臺伺服器移動到另一臺伺服器。
- 控制責任可以由多臺伺服器共享。
分散式死鎖預防
就像集中式死鎖預防一樣,在分散式死鎖預防方法中,事務應該在開始執行之前獲取所有鎖。這可以防止死鎖。
事務進入的站點被指定為控制站點。控制站點向資料項所在站點發送訊息以鎖定這些項。然後等待確認。當所有站點都確認已鎖定資料項後,事務開始。如果任何站點或通訊鏈路發生故障,則事務必須等到它們被修復。
雖然實現簡單,但這 種方法有一些缺點:
預先獲取鎖需要很長時間來處理通訊延遲。這會增加事務所需的時間。
如果站點或鏈路發生故障,事務必須等待很長時間才能使站點恢復。同時,在執行的站點中,專案被鎖定。這可能會阻止其他事務執行。
如果控制站點發生故障,則無法與其他站點通訊。這些站點繼續保持其鎖定的資料項處於鎖定狀態,從而導致阻塞。
分散式死鎖避免
與集中式系統一樣,分散式死鎖避免在死鎖發生之前處理死鎖。此外,在分散式系統中,需要解決事務位置和事務控制問題。由於事務的分散式特性,可能會發生以下衝突:
- 同一站點中兩個事務之間的衝突。
- 不同站點中兩個事務之間的衝突。
發生衝突時,根據分散式等待-死亡或分散式攻擊-等待演算法,可以中止其中一個事務或允許其等待。
讓我們假設有兩個事務 T1 和 T2。T1 到達站點 P 並試圖鎖定已被 T2 鎖定的資料項。因此,在站點 P 處發生衝突。演算法如下:
分散式等待-死亡 (Wound-Die)
如果 T1 比 T2 舊,則允許 T1 等待。在站點 P 接收到一條訊息,表明 T2 已在所有站點成功提交或中止後,T1 可以恢復執行。
如果 T1 比 T2 新,則中止 T1。站點 P 的併發控制向 T1 已訪問的所有站點發送訊息以中止 T1。控制站點在 T1 已在所有站點成功中止時通知使用者。
分散式等待-等待 (Wait-Wait)
如果 T1 比 T2 舊,則需要中止 T2。如果 T2 在站點 P 處於活動狀態,則站點 P 中止並回滾 T2,然後將此訊息廣播到其他相關站點。如果 T2 已離開站點 P 但在站點 Q 處於活動狀態,則站點 P 廣播 T2 已被中止;然後站點 L 中止並回滾 T2 並將此訊息傳送到所有站點。
如果 T1 比 T2 新,則允許 T1 等待。在站點 P 接收到一條訊息,表明 T2 已完成處理後,T1 可以恢復執行。
分散式死鎖檢測
就像集中式死鎖檢測方法一樣,允許死鎖發生,並在檢測到時將其移除。當事務發出鎖定請求時,系統不會執行任何檢查。對於實現,建立全域性等待圖。全域性等待圖中存在迴圈表示死鎖。但是,很難發現死鎖,因為事務等待網路上的資源。
另外,死鎖檢測演算法可以使用計時器。每個事務都關聯一個計時器,該計時器設定為事務預計完成的時間段。如果事務在此時間段內未完成,則計時器超時,表明可能存在死鎖。
另一個用於死鎖處理的工具是死鎖檢測器。在集中式系統中,只有一個死鎖檢測器。在分散式系統中,可以有多個死鎖檢測器。死鎖檢測器可以查詢其控制的站點上的死鎖。在分散式系統中,死鎖檢測有三種方法,即:
集中式死鎖檢測器 − 指定一個站點作為中央死鎖檢測器。
分層死鎖檢測器 − 多個死鎖檢測器按層次結構排列。
分散式死鎖檢測器 − 所有站點都參與檢測和消除死鎖。