
 資料結構
資料結構 網路
網路 關係型資料庫管理系統 (RDBMS)
關係型資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP隨機森林與決策樹的區別
你有沒有想過計算機是如何進行決策的?演算法是一種它們經常使用的專業工具。隨機森林和決策樹是兩種廣受歡迎的用於確定決策的演算法。讓我們來研究一下它們及其功能。
介紹
當您探索機器學習的世界時,您可能會遇到“決策樹”和“隨機森林”之類的術語。這兩種方法都被廣泛用於資料驅動的預測。但是,它們究竟是什麼,它們又有什麼不同之處呢?即使您不熟悉這個主題,您也應該能夠理解其主要原理,因為我們將在本文中簡化並更容易地理解這些概念。我們將從基礎知識開始,解釋關鍵詞,然後使用易於理解的圖表來比較這兩種方法。
什麼是決策樹?
想象一下,您在一個電子遊戲中面臨十字路口,您必須做出選擇:向左走還是向右走。每個決定都有不同的結果。這就是決策樹的作用,它是一個根據各種選項或情況劃分成分支的模型,以幫助您做出決策。簡單來說,決策樹是一種使用流程圖狀結構的工具,其中
- 每個“節點”(就像遊戲中的檢查點)代表一個問題或條件。
- 每個“分支”(類似於不同的遊戲路徑)表示一個潛在的解決方案或結果。
- “葉子”是每個分支末端的最終結果,它們反映了樹所做的判斷或預測。
示例
假設您想根據天氣決定穿什麼。您的決策樹可能如下所示:
在下雨嗎?
- 是:穿雨衣。
- 否:冷嗎?
- 是:穿夾克。
- 否:穿T恤。
什麼是隨機森林?
現在,想象一下,您不是獨自玩遊戲,而是和一群朋友一起玩。每個朋友在每個十字路口都會做出自己的決定,最後,你們投票決定走哪條路。這類似於隨機森林的操作。隨機森林是許多決策樹的集合,它們共同工作以做出更準確的預測。這類似於詢問多位專家,而不是隻詢問一個人。森林中的每一棵樹都會提供一個預測,最終的決定由大多數樹做出。
示例
考慮一下,問100個人他們認為你是否應該穿T恤、夾克或雨衣。在聽取了每個朋友的意見後,你遵循共識。這類似於隨機森林的操作。
為什麼使用隨機森林而不是單個決策樹?
單個決策樹有時會犯錯誤,尤其是在它處理的資料複雜或沒有清晰模式的情況下。透過使用多棵樹(森林),隨機森林可以“平均”這些錯誤並做出更可靠的預測。
關鍵術語定義
- 節點:定義的節點是在決策樹中提出問題的位置。
- 分支:決策樹路線,象徵著對問題的回答。
- 葉子:分支末端的最終輸出或決策。
- 模型:用於根據資料進行預測的工具或演算法。
- 預測:模型建議的決策或結果。
決策樹和隨機森林的區別
讓我們使用簡單的表格來檢查隨機森林和決策樹之間的區別
| 方面 | 決策樹 | 隨機森林 |
| 基本結構 | 一棵單一的樹,透過根據特定條件或特徵將資料分成分支來做出決策。 | 多棵決策樹的集合,每棵樹做出自己的決策,最終輸出基於所有樹的多數投票或平均值。 |
| 易於理解 | 易於解釋和視覺化。流程圖狀結構直觀易懂,便於初學者掌握。 | 更復雜,更難以解釋,因為它涉及許多樹共同工作。它並不像視覺化或解釋那樣簡單。 |
| 計算時間 | 訓練和預測速度更快,因為它只使用一棵樹。適用於更簡單場景中的即時預測。 | 訓練和預測速度較慢,因為它涉及多棵樹。需要更多的計算資源,使其不太適合複雜場景中的即時預測。 |
| 處理過擬合 | 容易過擬合,特別是如果樹變得太深並且對訓練資料過於特定。這意味著它在新的、未見的資料上可能表現不佳。 | 由於多棵樹的平均效應,不易過擬合。樹木之間的多樣性有助於更好地泛化到新資料。 |
| 準確性 | 準確性會根據樹的深度和質量而變化。在複雜的資料集上通常不太準確。 | 通常更準確和更魯棒,因為它聚合了多棵樹的預測,減少了個體樹所犯錯誤的影響。 |
| 特徵重要性 | 可以根據其重要性自然地對特徵進行排序,因為它清楚地顯示了哪個特徵劃分資料並導致決策。 | 透過對所有樹進行平均,減少對任何單個特徵的偏差,從而提供更可靠的特徵重要性度量。 |
| 處理缺失資料 | 需要顯式處理缺失資料,例如插補或使用諸如代理分裂之類的技術。 | 可以透過基於不同資料子集跨樹進行拆分來更有效地處理缺失資料,通常不需要複雜的預處理。 |
| 處理不平衡資料 | 難以處理不平衡資料,因為它可能會偏向多數類,導致預測偏差。 | 透過使用諸如自舉和分層抽樣之類的技術來更好地處理不平衡資料,以確保在決策過程中更平衡的表示。 |
| 可擴充套件性 | 適用於小型到中型資料集,但隨著資料集大小的增加,效能可能會下降。 | 更好地擴充套件到大型資料集,因為樹的構建和預測的並行性質可以利用現代計算資源。 |
| 速度 | 訓練速度更快 | 由於多棵樹,訓練速度較慢 |
| 複雜性 | 簡單易懂 | 由於多棵樹而更加複雜 |
| 穩定性 | 對資料變化敏感 | 由於平均而更穩定 |
| 預測時間 | 預測速度更快 | 預測速度較慢 |
| 用例示例 | 適用於可解釋性至關重要的任務,例如信用評分、簡單的決策過程或醫療診斷(其中理解決策路徑很重要)。 | 非常適合複雜任務,例如影像分類、推薦系統以及準確性和穩健性比可解釋性更重要的其他場景。 |
| 調整引數 | 需要調整的超引數很少,例如樹的深度、分裂標準和每個葉子的最小樣本數,使其更容易最佳化。 | 需要調整更多的超引數,包括樹的數量、每棵樹的最大特徵和樹的深度,這可以使模型更靈活,但也更難以最佳化。 |
| 並行處理 | 通常不能從並行處理中受益,因為它是一棵單一的樹。 | 自然地受益於並行處理,因為森林中的每棵樹都可以獨立地生長和評估。 |
| 預測能力 | 可能難以處理資料中高度複雜的關係,因為它一次只基於一個特徵進行拆分。 | 由於多個樹的整合,更好地捕捉特徵之間複雜的關係和互動作用,這些樹考慮了資料的各個方面。 |
它們是如何工作的?
決策樹示例
- 從一個問題開始:“是陰天嗎?”
- 分支:如果是,則繼續下一個查詢:“可能會下雨嗎?”
- 做出決定:如果是,則決定是“帶傘”。
隨機森林示例
- 建立多個決策樹:每棵樹可以提出不同的問題,例如“颳風嗎?”或“是什麼季節?”
- 每棵樹做出一個決定:根據樹的不同,您可能想帶傘也可能不想帶傘。
- 投票:最終決定基於所有樹的多數投票。
概念視覺化
決策樹視覺化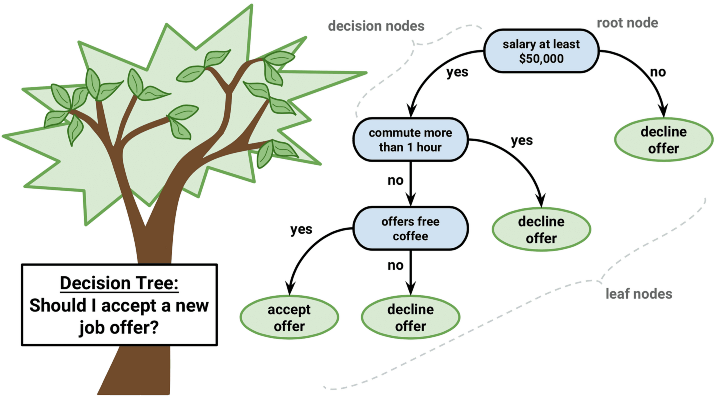
隨機森林視覺化
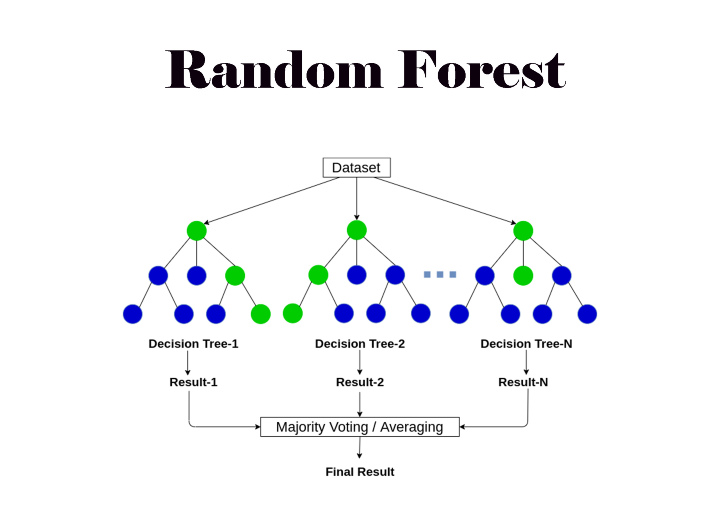
關於隨機森林與決策樹的常見問題
問:與決策樹相比,為什麼隨機森林被認為更準確?
答:因為它透過組合多棵樹的決策來減少出錯的可能性。
問:你能視覺化隨機森林嗎?
A: 隨機森林包含許多樹,難以視覺化。但其核心概念是,每棵樹的功能類似於決策樹,最終的決策是透過累加每棵樹的結果來確定的。
Q: 我可以對任何型別的資料使用隨機森林嗎?
A: 可以,隨機森林可以處理數值資料和分類資料。
結論
對於任何對機器學習感興趣的人來說,理解決策樹和隨機森林之間的區別至關重要。儘管決策樹簡單易懂,但隨機森林具有更高的準確性和可靠性。 透過理解這些概念,您現在擁有了進一步探索機器學習和資料科學的堅實基礎。您可以開始使用決策樹(更簡單的模型)或隨機森林(更復雜的模型)來利用資料做出更明智的預測。
64 次瀏覽
