資料科學 - 快速指南
資料科學 - 入門
資料科學是從資料中提取和分析有用資訊以解決難以用分析方法解決的問題的過程。例如,當您訪問電子商務網站並在購買前檢視一些類別和產品時,您正在建立分析師可以用來了解您如何進行購買的資料。
它涉及不同的學科,如數學和統計建模,從其來源提取資料並應用資料視覺化技術。它還涉及處理大資料技術以收集結構化和非結構化資料。
它可以幫助您找到隱藏在原始資料中的模式。“資料科學”一詞的出現是因為數學統計、資料分析和“大資料”隨著時間的推移而發生了變化。
資料科學是一個跨學科領域,可以讓您從組織化和非組織化資料中學習。利用資料科學,您可以將業務問題轉化為研究專案,然後將其應用於現實世界的解決方案。
資料科學的歷史
John Tukey 在 1962 年使用“資料分析”一詞來定義一個類似於當前現代資料科學的領域。1985 年,C. F. Jeff Wu 在北京中國科學院的一次演講中首次將“資料科學”一詞作為統計學的替代詞。隨後,1992 年在蒙彼利埃第二大學舉辦的會議上,與會者在統計學領域認識到一個新領域的誕生,該領域以來自多種來源和形式的資料為中心,將已知的統計學和資料分析理念與計算機相結合。
Peter Naur 在 1974 年建議將“資料科學”一詞作為計算機科學的替代名稱。國際分類學會聯合會是第一個在 1996 年將資料科學作為特殊主題重點介紹的會議。然而,這個概念仍在變化。繼 1985 年在北京中國科學院的演講之後,C. F. Jeff Wu 在 1997 年再次提倡將統計學改名為資料科學。他認為,一個新的名稱將有助於統計學消除不準確的刻板印象和認知,例如與會計相關或僅限於資料描述。Hayashi Chikio 在 1998 年提出了資料科學,作為一個包含三個組成部分的新型跨學科概念:資料設計、資料收集和資料分析。
在 20 世紀 90 年代,“知識發現”和“資料探勘”是用於識別資料集(其規模正在增長)中模式的流行短語。
2012 年,工程師 Thomas H. Davenport 和 DJ Patil 宣稱“資料科學家:21 世紀最熱門的工作”,這個詞被《紐約時報》和《波士頓環球報》等主要大都市出版物採用。他們在十年後重複了這一點,並補充說“該職位比以往任何時候都更受歡迎”。
William S. Cleveland 通常與資料科學作為獨立領域的當前理解相關聯。在 2001 年的一項研究中,他主張將統計學發展為技術領域;需要一個新的名稱,因為這將從根本上改變該學科。在接下來的幾年裡,“資料科學”變得越來越普遍。2002 年,科學與技術資料委員會出版了《資料科學雜誌》。哥倫比亞大學於 2003 年創辦了《資料科學雜誌》。美國統計協會的統計學習和資料探勘分會於 2014 年將其名稱改為統計學習和資料科學分會,反映了資料科學日益普及。
2008 年,DJ Patil 和 Jeff Hammerbacher 被授予“資料科學家”的職業稱號。雖然它被國家科學委員會在其 2005 年的研究“長期數字資料收集:支援 21 世紀的研究和教學”中使用,但它指的是管理數字資料收集的任何重要角色。
關於資料科學的含義尚未達成一致,有些人認為它只是一個流行詞。大資料是營銷中類似的概念。資料科學家負責將海量資料轉化為有用的資訊,並開發軟體和演算法來幫助企業和組織確定最佳運營。
為什麼選擇資料科學?
根據 IDC 的資料,到 2025 年,全球資料將達到 175 澤位元組。資料科學幫助企業理解來自不同來源的大量資料,提取有用的見解,並做出更好的資料驅動決策。資料科學被廣泛應用於多個行業領域,如營銷、醫療保健、金融、銀行和政策工作。
以下是使用資料分析技術的重要優勢:
資料是現代時代的石油。藉助合適的工具、技術和演算法,我們可以利用資料創造獨特的競爭優勢。
資料科學可以透過使用複雜的機器學習技術來幫助檢測欺詐。
它可以幫助您避免嚴重的經濟損失。
能夠開發智慧機器
您可以使用情感分析來確定客戶的品牌忠誠度。這可以幫助您做出更好、更快的決策。
它使您能夠向合適的客戶推薦合適的商品,從而促進業務增長。
資料科學的需求
我們擁有的資料以及我們生成的資料量
根據福布斯的資料,2010 年至 2020 年期間,全球生成、複製、記錄和消費的資料總量激增了約 5000%,從 1.2 萬億吉位元組增加到 59 萬億吉位元組。
公司如何從資料科學中受益?
許多企業正在進行資料轉型(將其 IT 架構轉換為支援資料科學的架構),有資料訓練營等。的確,這有一個簡單的解釋:資料科學提供了有價值的見解。
一些公司正被那些基於資料做出決策的公司擊敗。例如,福特公司在 2006 年虧損了 126 億美元。在失敗之後,他們聘請了一位資深資料科學家來管理資料並進行了為期三年的改造。這最終導致了近 230 萬輛汽車的銷售,並在 2009 年實現了全年盈利。
資料科學家的需求和平均薪資
根據印度今日報的報道,由於企業和服務的快速數字化,印度是全球第二大資料科學中心。分析師預計,到 2026 年,該國將擁有超過 1100 萬個就業機會。事實上,自 2019 年以來,資料科學領域的招聘增長了 46%。
美國銀行是十年前第一個向客戶提供手機銀行服務的金融機構之一。最近,美國銀行推出了其首個虛擬財務助手 Erica。它被認為是世界上最好的金融發明。
Erica 目前為全球超過 4500 萬客戶提供客戶顧問服務。Erica 使用語音識別來獲取客戶反饋,這代表了資料科學的技術發展。
資料科學和機器學習曲線非常陡峭。儘管印度每年湧現出大量資料科學家,但擁有必要技能和專業知識的人相對較少。因此,擁有專業資料技能的人才非常搶手。
資料科學的影響
資料科學對現代文明的各個方面產生了重大影響。資料科學對組織的重要性日益提高。根據一項研究,到 2023 年,全球資料科學市場規模將達到 1150 億美元。
醫療保健行業受益於資料科學的興起。2008 年,谷歌員工意識到他們可以即時監控流感病毒株。之前的技術只能提供每週的病例更新。谷歌能夠利用資料科學構建了首批疾病傳播監控系統之一。
體育行業也從資料科學中獲益。2019 年,一位資料科學家找到了衡量和計算射門嘗試如何提高足球隊獲勝機率的方法。實際上,資料科學被用於輕鬆計算各種運動中的統計資料。
政府機構也每天都在使用資料科學。全球各地的政府都使用資料庫來監控有關社會保障、稅收和其他與居民相關的資料資訊。政府對新興技術的應用不斷發展。
隨著網際網路成為人類交流的主要媒介,電子商務的普及程度也越來越高。利用資料科學,線上企業可以監控整個客戶體驗,包括營銷活動、購買和消費趨勢。廣告可能是電子商務企業使用資料科學的最典型案例之一。您是否曾經在網上搜索過東西或訪問過電子商務產品網站,結果卻在社交媒體網站和部落格上被該產品的廣告轟炸?
廣告畫素是線上收集和分析使用者資訊不可或缺的一部分。公司利用線上消費者行為在整個網際網路上重新定位潛在消費者。這種對客戶資訊的使用超出了電子商務的範圍。像 Tinder 和 Facebook 這樣的應用程式使用演算法來幫助使用者準確找到他們正在尋找的東西。網際網路是一個不斷增長的資料寶庫,對這些資料的收集和分析也將繼續擴充套件。
資料科學 - 什麼是資料?
資料科學中的資料是什麼?
資料是資料科學的基礎。資料是對特定字元、數量或符號的系統記錄,計算機對其進行操作,可以儲存和傳輸。它是一組為了特定目的(例如調查或分析)而使用的編譯資料。當資料被結構化時,可以將其稱為資訊。資料來源(原始資料、二次資料)也是一個重要的考慮因素。
資料有多種形式,但通常可以認為是某些隨機實驗的結果——一個事先無法確定結果的實驗,但其運作方式仍然可以進行分析。隨機實驗的資料通常儲存在表格或電子表格中。表示變數的統計約定通常稱為特徵或列,單個專案(或單位)稱為行。
資料型別
資料主要有兩種型別,它們是:
定性資料
定性資料由無法計數、量化或簡單地用數字表示的資訊組成。它從文字、音訊和圖片中收集,並使用資料視覺化工具進行分發,包括詞雲、概念圖、圖形資料庫、時間軸和資訊圖表。
定性資料分析的目的是回答有關個人活動和動機的問題。收集和分析此類資料可能非常耗時。處理定性資料的研究人員或分析師被稱為定性研究人員或分析師。
定性資料可以為任何行業、使用者群體或產品提供重要的統計資料。
定性資料型別
定性資料主要有兩種型別,它們是:
名義資料
在統計學中,名義資料(也稱為名義尺度)用於指定變數,而無需賦予數值。它是測量尺度中最基本的一種型別。與順序資料相比,名義資料無法排序或量化。
例如,人的姓名、頭髮的顏色、國籍等。假設一個名叫Aby的女孩,她的頭髮是棕色的,來自美國。
名義資料可以是定性的,也可以是定量的。但是,與定量標籤(例如,識別號)沒有關聯的數值或連結。相反,幾個定性資料類別可以用名義形式表示。這些可能包括單詞、字母和符號。個人姓名、性別和國籍是一些最常見的名義資料示例。
分析名義資料
使用分組方法可以分析名義資料。可以將變數分類到組中,並確定每個類別的頻率或百分比。資料也可以以圖形方式顯示,例如使用餅圖。

雖然名義資料不能使用數學運算子進行處理,但仍然可以使用統計技術對其進行研究。假設檢驗是評估和分析資料的一種方法。
對於名義資料,可以使用卡方檢驗等非引數檢驗來檢驗假設。卡方檢驗的目的是評估預測頻率與給定值的實際頻率之間是否存在統計學上的顯著差異。
順序資料
順序資料是統計學中的一種資料型別,其中值具有自然順序。關於順序資料最重要的一點是,你無法判斷資料值之間的差異是什麼。大多數情況下,資料類別的寬度與基礎屬性的增量不匹配。
在某些情況下,可以透過對資料值進行分組來找到區間資料或比率資料的特徵。例如,收入範圍是順序資料,而實際收入是比率資料。
順序資料不能像區間資料或比率資料那樣用數學運算子進行更改。因此,中位數是確定一組順序資料中間位置的唯一方法。
這種資料型別在金融和經濟領域廣泛存在。考慮一項研究不同國家GDP水平的經濟研究。如果報告根據各國的GDP對它們進行排名,則排名為順序統計資料。
分析順序資料
使用視覺化工具評估順序資料是最簡單的方法。例如,資料可以顯示為表格,其中每一行表示一個單獨的類別。此外,它們還可以使用不同的圖表以圖形方式表示。條形圖是用於顯示此類資料的最流行的圖形樣式。

順序資料還可以使用複雜的統計分析方法(如假設檢驗)進行研究。請注意,t檢驗和ANOVA等引數程式不能用於這些資料集。只有非引數檢驗,如Mann-Whitney U檢驗或Wilcoxon配對檢驗,才能用於評估關於資料的零假設。
定性資料收集方法
以下是收集定性資料的一些方法和收集方法:
資料記錄 - 利用已存在的資料作為資料來源是進行定性研究的最佳方法。類似於訪問圖書館,您可以查閱書籍和其他參考材料以獲取可用於研究的資料。
訪談 - 個人訪談是獲取定性研究演繹資料最常見的方法之一。訪談可以是隨意的,並且沒有固定的計劃。它通常像一次談話。面試官或研究人員直接從被訪談者那裡獲取資訊。
焦點小組 - 焦點小組由6到10人組成,他們相互交談。主持人負責監督談話並根據焦點問題引導談話。
案例研究 - 案例研究是對個人或群體的深入分析,重點關注發展特徵與環境之間的關係。
觀察 - 這種方法是研究人員觀察物件並記錄下來,以找出未經提示的先天反應和反應。
定量資料
定量資料由數值組成,具有數值特徵,並且可以對這種型別的資料執行數學運算,例如加法。由於其定量特徵,定量資料在數學上是可驗證和可評估的。
它們數學推導的簡單性使得可以控制不同引數的測量。通常,它是透過對人口子集進行的調查、民意調查或問卷調查收集的,用於統計分析。研究人員能夠將收集到的發現應用於整個人群。
定量資料型別
定量資料主要有兩種型別,它們是:
離散資料
這些資料只能取某些值,而不是一個範圍。例如,關於人口的血型或性別的的資料被認為是離散資料。
離散定量資料的示例可能是訪問您網站的訪客數量;您可能在一天內有150次訪問,但不會有150.6次訪問。通常,使用計數圖、條形圖和餅圖來表示離散資料。
離散資料的特徵
由於離散資料易於總結和計算,因此它常用於基礎統計分析。讓我們看一下離散資料的一些其他重要特徵:
離散資料由離散變數組成,這些變數是有限的、可測量的、可數的,並且不能為負數(5、10、15等)。
簡單的統計方法,如條形圖、折線圖和餅圖,可以輕鬆地顯示和解釋離散資料。
資料也可以是分類的,這意味著它具有固定數量的資料值,例如一個人的性別。
既受時間約束又受空間約束的資料以隨機方式分佈。離散分佈使得更容易檢視離散值。
連續資料
這些資料可以在某個範圍內取值,包括最大值和最小值。最大值和最小值之間的差稱為資料範圍。例如,您學校兒童的身高和體重。這被認為是連續資料。連續資料的表格表示稱為頻率分佈。這些可以用直方圖以視覺方式表示。
連續資料的特徵
另一方面,連續資料可以是數字,也可以是隨時間和日期分佈。這種資料型別使用高階統計分析方法,因為存在無限數量的可能值。關於連續資料的重要特徵是:
連續資料會隨時間變化,並且在不同的時間點,它可以具有不同的值。
可能不是整數的隨機變數構成連續資料。
諸如折線圖、偏度等資料分析工具用於測量連續資料。
一種常用的一種連續資料分析是迴歸分析。
定量資料收集方法
以下是收集定量資料的一些方法和收集方法:
調查和問卷 - 這些型別的研究非常適合從使用者和客戶那裡獲取詳細的反饋,特別是關於人們對產品、服務或體驗的感受。
開源資料集 - 線上可以找到許多公共資料集,並且可以免費進行分析。研究人員有時會檢視已經收集的資料,並嘗試以適合他們自己研究專案的方式找出其含義。
實驗 − 一種常見的方法是實驗,通常包括一個對照組和一個實驗組。實驗的設定是為了能夠控制條件,並根據需要改變條件。
抽樣 − 當資料點很多時,可能無法調查每個人或每個資料點。在這種情況下,可以使用抽樣方法進行定量研究。抽樣是選擇一個代表整體的資料樣本的過程。抽樣分為兩種型別:隨機抽樣(也稱為機率抽樣)和非隨機抽樣。
資料收集型別
根據來源,資料收集可以分為兩種型別:
原始資料 − 這些資料是調查人員為了特定目的首次獲取的資料。原始資料是“純淨”的,因為它們沒有經過任何統計處理,並且是真實的。原始資料的例子包括印度人口普查。
二手資料 − 這些資料最初是由某個實體收集的。這意味著此類資料已由研究人員或調查人員收集,並且以已釋出或未釋出的形式可用。此資料是不純淨的,因為之前可能已經對其進行了統計計算。例如,可在印度政府或財政部網站或其他檔案、書籍、期刊等中獲得的資訊。
大資料
大資料被定義為資料量更大,需要克服處理它們的物流挑戰。大資料指的是更大、更復雜的資料集,特別是來自新資料來源的資料集。某些資料集非常龐大,以至於傳統的資料庫軟體無法處理它們。但是,這些海量資料可以用來解決以前無法解決的業務難題。
資料科學是研究如何分析海量資料並從中獲取資訊的學科。您可以將大資料和資料科學比作原油和煉油廠。資料科學和大資料來源於統計學和傳統的資料管理方式,但現在被視為獨立的領域。
人們通常使用三個 V 來描述大資料的特徵:
體積 − 有多少資訊?
多樣性 − 不同型別的資料有多大差異?
速度 − 新的資訊片段生成的速度有多快?
如何在資料科學中使用資料?
每個資料都必須經過預處理。這是一系列必不可少的流程,將原始資料轉換為更易於理解和更有價值的格式,以便進行進一步處理。常見的程式包括:
收集和儲存資料集
資料清洗
處理缺失資料
噪聲資料
資料整合
資料轉換
泛化
標準化
屬性選擇
聚合
我們將在後續章節中詳細討論這些流程。
資料科學 - 生命週期
什麼是資料科學生命週期?
資料科學生命週期是一種系統的方法,用於找到解決資料問題的方法,它展示了開發、交付/部署和維護資料科學專案所採取的步驟。我們可以假設一個一般的資料科學生命週期,其中包含一些最重要的常見步驟,如下圖所示,但一些步驟可能因專案而異,因為每個專案都不同,所以生命週期可能會有所不同,因為並非每個資料科學專案都是以相同的方式構建的。
標準的資料科學生命週期方法包括使用機器學習演算法和統計程式,從而產生更準確的預測模型。資料提取、準備、清洗、建模、評估等是資料科學的一些最重要階段。這種技術在資料科學領域被稱為“資料探勘跨行業標準流程”。
資料科學生命週期有多少個階段?
資料科學生命週期主要有六個階段:

識別問題並瞭解業務
與任何其他業務生命週期一樣,資料科學生命週期始於“為什麼?”。資料科學過程中最重要的部分之一是確定問題是什麼。這有助於找到一個明確的目標,所有其他步驟都圍繞它進行計劃。簡而言之,瞭解業務目標至關重要,因為它將決定分析的最終目標。
此階段應評估業務趨勢,評估可比分析的案例研究,並研究行業的領域。該小組將評估專案在現有員工、裝置、時間和技術方面的可行性。當這些因素被發現和評估後,將形成一個初步假設來解決現有環境導致的業務問題。此階段應:
說明問題必須立即解決並需要答案的原因。
說明業務專案的潛在價值。
確定與專案相關的風險,包括倫理問題。
建立並傳達一個靈活且高度整合的專案計劃。
資料收集
資料科學生命週期的下一步是資料收集,這意味著從適當且可靠的來源獲取原始資料。收集的資料可以是有組織的或無組織的。資料可以從網站日誌、社交媒體資料、線上資料儲存庫以及甚至使用 API 從線上源流式傳輸的資料中收集,還可以透過網路抓取或儲存在 Excel 或任何其他來源中的資料。
執行此工作的人員應瞭解可用不同資料集之間的區別以及組織如何投資其資料。專業人員難以跟蹤每個資料片段的來源以及它是否是最新的。在整個資料科學專案的生命週期中,跟蹤此資訊非常重要,因為它可以幫助檢驗假設或執行任何其他新實驗。
資訊可以透過調查或更普遍的自動化資料收集方法(例如網際網路cookie)來收集,網際網路cookie是未經分析的資料的主要來源。
我們還可以使用二手資料,這是一種開源資料集。有很多可用的網站,我們可以從中收集資料,例如
Kaggle (https://www.kaggle.com/datasets),
Google 公共資料集 (https://cloud.google.com/bigquery/public-data/)
Python 中有一些預定義的資料集。讓我們從 Python 中匯入 Iris 資料集並使用它來定義資料科學的各個階段。
from sklearn.datasets import load_iris import pandas as pd # Load Data iris = load_iris() # Create a dataframe df = pd.DataFrame(iris.data, columns = iris.feature_names) df['target'] = iris.target X = iris.data
資料處理
在從可靠來源收集高質量資料後,下一步是處理它。資料處理的目的是確保獲取的資料是否存在任何問題,以便在繼續下一個階段之前解決這些問題。如果沒有此步驟,我們可能會產生錯誤或不準確的結果。
獲取的資料可能存在一些問題。例如,資料在多行或多列中可能有多個缺失值。它可能包含多個異常值、不準確的數字、具有不同時區的的時間戳等。資料可能在日期範圍內存在問題。在某些國家/地區,日期格式為 DD/MM/YYYY,而在其他國家/地區,則寫為 MM/DD/YYYY。在資料收集過程中可能會發生許多問題,例如,如果資料是從多個溫度計收集的,並且其中任何一個有缺陷,則可能需要丟棄或重新收集資料。
在此階段,必須解決資料中的各種問題。其中一些問題有多種解決方案,例如,如果資料包含缺失值,我們可以用零或該列的平均值替換它們。但是,如果該列缺少大量值,則最好完全刪除該列,因為它包含很少的資料,以至於無法在我們的資料科學生命週期方法中用於解決問題。
當所有時區都混合在一起時,我們無法使用這些列中的資料,並且可能不得不刪除它們,直到我們可以定義提供的時間戳中使用的時區。如果我們知道每個時間戳收集時使用的時區,我們可以將所有時間戳資料轉換為某個特定時區。這樣,就有許多策略可以解決獲取的資料中可能存在的問題。
我們將訪問資料,然後使用 Python 將其儲存在資料框中。
from sklearn.datasets import load_iris import pandas as pd import numpy as np # Load Data iris = load_iris() # Create a dataframe df = pd.DataFrame(iris.data, columns = iris.feature_names) df['target'] = iris.target X = iris.data
所有資料都必須以數字表示形式用於機器學習模型。這意味著,如果資料集包含分類資料,則必須將其轉換為數字值,然後才能執行模型。因此,我們將實現標籤編碼。
標籤編碼
species = []
for i in range(len(df['target'])):
if df['target'][i] == 0:
species.append("setosa")
elif df['target'][i] == 1:
species.append('versicolor')
else:
species.append('virginica')
df['species'] = species
labels = np.asarray(df.species)
df.sample(10)
labels = np.asarray(df.species)
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(labels)
labels = le.transform(labels)
df_selected1 = df.drop(['sepal length (cm)', 'sepal width (cm)', "species"], axis=1)
資料分析
資料分析探索性資料分析 (EDA) 是一組用於分析資料的視覺化技術。使用此方法,我們可以獲取有關資料統計摘要的特定詳細資訊。此外,我們將能夠處理重複數字、異常值並識別集合中的趨勢或模式。
在此階段,我們試圖更好地理解獲取和處理的資料。我們應用統計和分析技術來對資料得出結論,並確定資料集中多列之間的關係。我們可以使用視覺化(例如圖片、圖形、圖表、繪圖等)來更好地理解和描述資料。
專業人員使用資料統計技術(例如平均值和中位數)來更好地理解資料。他們還視覺化資料並評估其分佈模式,使用直方圖、頻譜分析和總體分佈。資料將根據問題進行分析。
示例
以下程式碼用於檢查資料集中是否存在任何空值:
df.isnull().sum()
輸出
sepal length (cm) 0 sepal width (cm) 0 petal length (cm) 0 petal width (cm) 0 target 0 species 0 dtype: int64
從以上輸出中,我們可以得出結論,資料集中沒有空值,因為該列中所有空值的總和為 0。
我們將使用 shape 引數來檢查資料集的形狀(行、列):
示例
df.shape
輸出
(150, 5)
現在,我們將使用 info() 來檢查列及其資料型別:
示例
df.info()
輸出
<class 'pandas.core.frame.DataFrame'> RangeIndex: 150 entries, 0 to 149 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sepal length (cm) 150 non-null float64 1 sepal width (cm) 150 non-null float64 2 petal length (cm) 150 non-null float64 3 petal width (cm) 150 non-null float64 4 target 150 non-null int64 dtypes: float64(4), int64(1) memory usage: 6.0 KB
只有一列包含類別資料,而其他列包含非空數字值。
現在,我們將對資料使用 describe()。describe() 方法對資料集執行基本統計計算,例如極值、資料點數、標準差等。任何缺失值或 NaN 值都會立即被忽略。describe() 方法準確地描述了資料的分佈。
示例
df.describe()
輸出
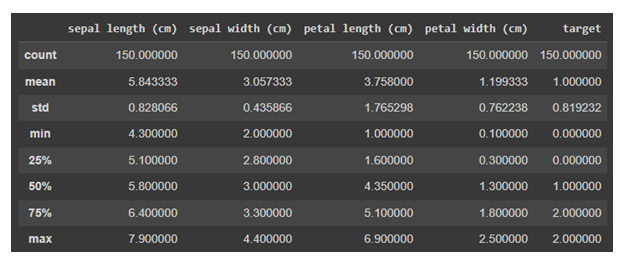
資料視覺化
目標列 − 我們的目標列將是 Species 列,因為我們最終只需要基於物種的結果。
Matplotlib 和 seaborn 庫將用於資料視覺化。
以下是物種計數圖:
示例
import seaborn as sns import matplotlib.pyplot as plt sns.countplot(x='species', data=df, ) plt.show()
輸出
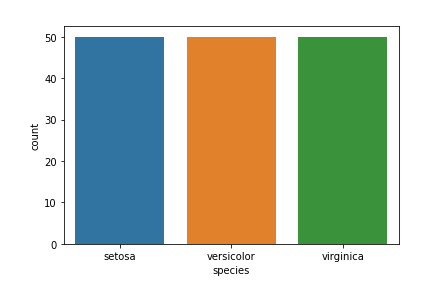
資料科學中還有許多其他視覺化圖。要了解更多資訊,請參考 https://tutorialspoint.tw/machine_learning_with_python
資料建模
資料建模是資料科學中最重要的方面之一,有時也被稱為資料分析的核心。模型的預期輸出應該來源於準備和分析過的資料。在達到指定標準之前,將選擇和構建執行資料模型所需的執行環境。
在此階段,我們開發用於訓練和測試模型以執行生產相關任務的資料集。它還涉及選擇正確的模型型別並確定問題是否涉及分類、迴歸或聚類。在分析模型型別後,我們必須選擇合適的實現演算法。必須謹慎執行此操作,因為它對於從提供的資料中提取相關見解至關重要。
這裡機器學習就派上用場了。機器學習基本上分為分類、迴歸或聚類模型,並且每個模型都有一些應用於資料集以獲取相關資訊的演算法。這些模型在此階段使用。我們將在機器學習章節中詳細討論這些模型。
模型部署
我們已經到達了資料科學生命週期的最後階段。經過詳細的審查過程,模型終於可以以所需的格式和選定的渠道部署。請注意,除非機器學習模型部署到生產環境中,否則它沒有任何用處。一般來說,這些模型與產品和應用程式相關聯並整合在一起。
模型部署包含建立必要的交付方法,以便將模型部署到市場消費者或其他系統。機器學習模型也正在裝置上實施,並獲得認可和吸引力。根據專案的複雜程度,此階段可能從Tableau儀表板上的基本模型輸出到擁有數百萬使用者的複雜雲端部署。
誰參與了資料科學生命週期?
從個人層面到組織層面,資料正在海量的伺服器和資料倉庫中生成、收集和儲存。但是您如何訪問這個龐大的資料儲存庫呢?這就是資料科學家發揮作用的地方,因為他們專門負責從非結構化文字和統計資料中提取見解和模式。
下面,我們介紹了參與資料科學生命週期的資料科學團隊的眾多職位描述。
| 序號 | 職位描述及職責 |
|---|---|
| 1 | 業務分析師
瞭解業務需求並找到合適的目標客戶。 |
| 2 | 資料分析師
格式化和清理原始資料,解釋和視覺化資料以執行分析並提供相同的技術摘要 |
| 3 | 資料科學家
提高機器學習模型的質量。 |
| 4 | 資料工程師
他們負責從社交網路、網站、部落格和其他內部和外部網路來源收集資料,以便進行進一步分析。 |
| 5 | 資料架構師
連線、集中、保護並跟上組織的資料來源。 |
| 6 | 機器學習工程師
設計和實現與機器學習相關的演算法和應用程式。 |
資料科學 - 先決條件
要成為一名成功的資料科學家,您需要具備多種技術和非技術技能。一些技能對於成為一名精通資料科學的人員至關重要,而另一些技能則只是為了讓資料科學家的工作更容易。不同的職位角色決定了您需要具備的特定技能水平。
下面列出了一些成為資料科學家所需的技能。
技術技能
Python
資料科學家大量使用Python,因為它是最流行的程式語言之一,易於學習,並且擁有可用於資料處理和資料分析的廣泛庫。由於它是一種靈活的語言,因此可用於資料科學的所有階段,例如資料探勘或執行應用程式。Python擁有一個龐大的開源庫,其中包含強大的資料科學庫,例如Numpy、Pandas、Matplotlib、PyTorch、Keras、Scikit Learn、Seaborn等。這些庫有助於執行不同的資料科學任務,例如讀取大型資料集、繪製和視覺化資料和相關性、將機器學習模型訓練和擬合到您的資料、評估模型的效能等。
SQL
在開始學習資料科學之前,SQL是另一個必不可少的先決條件。與其他程式語言相比,SQL相對簡單,但成為資料科學家是必不可少的。這種程式語言用於管理和查詢關係資料庫中儲存的資料。我們可以使用SQL檢索、插入、更新和刪除資料。要從資料中提取見解,能夠建立包含聯接、group by、having等的複雜SQL查詢至關重要。聯接方法使您能夠同時查詢多個表。SQL還能夠執行分析操作並轉換資料庫結構。
R
R是一種高階語言,用於建立複雜的統計模型。R還允許您使用陣列、矩陣和向量。R以其圖形庫而聞名,這些庫允許使用者繪製漂亮的圖形並使其易於理解。
使用R Shiny,程式設計師可以使用R建立Web應用程式,用於將視覺化嵌入網頁併為使用者提供大量互動方式。此外,資料提取是資料科學的關鍵部分。R允許您將R程式碼連線到資料庫管理系統。
R還為更高階的資料分析提供了許多選項,例如構建預測模型、機器學習演算法等。R還有一些用於處理影像的包。
統計學
在資料科學中,儲存和轉換資料模式以進行預測的高階機器學習演算法在很大程度上依賴於統計學。資料科學家利用統計學來收集、評估、分析和從資料中得出結論,以及應用相關的定量數學模型和變數。資料科學家在商業中擔任程式設計師、研究人員和管理人員等角色,所有這些學科都具有統計學基礎。統計學在資料科學中的重要性與程式語言相當。
Hadoop
資料科學家對海量資料執行操作,但有時系統的記憶體無法對這些海量資料進行處理。那麼如何在如此海量的資料上執行資料處理呢?這裡Hadoop就派上用場了。它用於快速將資料劃分為多個伺服器並傳輸資料以進行資料處理和其他操作,例如過濾。雖然Hadoop基於分散式計算的概念,但許多公司要求資料科學家對分散式系統原理(如Pig、Hive、MapReduce等)有基本的瞭解。一些公司已經開始使用Hadoop即服務(HaaS),這是雲端Hadoop的另一種名稱,因此資料科學家無需瞭解Hadoop的內部工作原理。
Spark
Spark是一個用於大資料計算的框架,類似於Hadoop,並在資料科學領域獲得了一些普及。Hadoop從磁碟讀取資料並向磁碟寫入資料,而另一方面,Spark在系統記憶體中計算計算結果,使其比Hadoop相對更容易且更快。Apache Spark的功能是加速複雜演算法,它專門為資料科學而設計。如果資料集很大,則它會分發資料處理,從而節省大量時間。使用Apache Spark的主要原因是其速度以及它提供的執行資料科學任務和流程的平臺。可以在單臺機器或機器叢集上執行Spark,這使得使用起來非常方便。
機器學習
機器學習是資料科學的關鍵組成部分。機器學習演算法是分析海量資料的有效方法。它可以幫助自動化各種與資料科學相關的操作。然而,開始從事該行業並不需要深入瞭解機器學習原理。大多數資料科學家缺乏機器學習技能。只有一小部分資料科學家在推薦引擎、對抗性學習、強化學習、自然語言處理、異常值檢測、時間序列分析、計算機視覺、生存分析等高階主題方面擁有豐富的知識和專業知識。因此,這些能力將幫助您在資料科學職業中脫穎而出。
非技術技能
業務領域理解
對特定業務領域或領域的瞭解越多,資料科學家對來自該特定領域的資料進行分析就越容易。
資料理解
資料科學完全圍繞資料展開,因此瞭解資料、資料如何儲存、表格、行和列的知識非常重要。
批判性思維和邏輯思維
批判性思維是指在弄清和理解想法如何組合在一起時能夠清晰和邏輯地思考的能力。在資料科學中,您需要能夠批判性地思考以獲得有用的見解並改進業務運營。批判性思維可能是資料科學中最重要的技能之一。它使他們更容易深入瞭解資訊並找到最重要的事情。
產品理解
設計模型並不是資料科學家的全部工作。資料科學家必須提出可用於提高產品質量的見解。透過系統的方法,專業人員如果瞭解整個產品,可以快速加速。他們可以幫助模型啟動(引導)並改進特徵工程。這項技能還有助於他們透過揭示他們之前可能沒有想到的產品的想法和見解來改進他們的敘事能力。
適應性
在現代人才招聘過程中,資料科學家最需要的軟技能之一是適應能力。由於新技術正在更快地開發和使用,專業人員必須快速學習如何使用它們。作為一名資料科學家,您必須跟上不斷變化的業務趨勢並能夠適應。
資料科學 - 應用
資料科學涉及不同的學科,如數學和統計建模、從源頭提取資料以及應用資料視覺化技術。它還涉及處理大資料技術以收集結構化和非結構化資料。下面,我們將看到資料科學的一些應用 -
遊戲行業
透過在社交媒體上建立影響力,體育組織處理許多問題。遊戲公司Zynga已經制作了社交媒體遊戲,如Zynga Poker、Farmville、Chess with Friends、Speed Guess Something和Words with Friends。這產生了大量使用者連線和大量資料。
遊戲行業需要資料科學來利用從所有社交網路上的玩家那裡獲取的資料。資料分析為玩家提供了一種引人入勝、創新的娛樂方式,讓他們在競爭中保持領先!資料科學最有趣的應用之一是在遊戲建立的功能和流程中。
醫療保健
資料科學在醫療保健領域發揮著重要作用。資料科學家的職責是將所有資料科學方法整合到醫療保健軟體中。資料科學家幫助從資料中收集有用的見解,以建立預測模型。資料科學家在醫療保健領域的主要職責如下:
收集患者資訊
分析醫院的需求
組織和分類資料以供使用
使用各種方法實施資料分析
使用演算法從資料中提取見解。
與開發人員一起開發預測模型。
下面列出了一些資料科學的應用:
醫學影像分析
資料科學透過對掃描影像進行影像分析來幫助確定人體異常情況,從而協助醫生制定合適的治療方案。這些影像檢查包括X射線、超聲波、MRI(磁共振成像)和CT掃描等。醫生能夠透過研究這些測試照片獲得重要資訊,從而為患者提供更好的護理。
預測分析
使用資料科學開發的預測分析模型預測患者的病情。此外,它還有助於制定針對患者合適治療的策略。預測分析是資料科學中一項非常重要的工具,在醫療保健行業中發揮著重要作用。
影像識別
影像識別是一種影像處理技術,可以識別影像中的所有內容,包括人物、圖案、徽標、物品、位置、顏色和形狀。
資料科學技術已經開始識別人的面部並將其與資料庫中的所有影像進行匹配。此外,配備攝像頭的手機正在生成無限數量的數字影像和影片。企業正在利用海量的數字資料為客戶提供更優質、更便捷的服務。通常,AI的面部識別系統會分析所有面部特徵,並將其與資料庫進行比較以找到匹配項。
例如,iPhone中Face ID功能中的面部檢測。
推薦系統
隨著線上購物變得越來越普遍,電子商務平臺能夠捕捉使用者的購物偏好以及市場上各種產品的表現。這導致了推薦系統的建立,這些系統建立預測購物者需求的模型,並顯示購物者最有可能購買的產品。像亞馬遜和Netflix這樣的公司使用推薦系統,以便幫助使用者找到他們正在尋找的正確的電影或產品。
航空公司航線規劃
航空業中的資料科學提供了許多機會。高空飛行的飛機提供了關於發動機系統、燃油效率、天氣、乘客資訊等的大量資料。當該行業使用配備感測器和其他資料收集技術的更現代化的飛機時,將建立更多資料。如果使用得當,這些資料可能會為該行業提供新的可能性。
它還有助於確定是直接降落在目的地還是在途中進行中途停留,例如航班可以有一條直達路線。
金融
資料科學在銀行業的重要性及其相關性與資料科學在企業決策的其他領域的重要性及其相關性相當。金融資料科學專業人員透過幫助相關團隊(特別是投資和財務團隊)開發工具和儀表板來增強投資流程,為公司內的相關團隊提供支援和幫助。
改善醫療保健服務
醫療保健行業處理各種資料,這些資料可以分為技術資料、財務資料、患者資訊、藥物資訊和法律法規。所有這些資料都需要以協調的方式進行分析,以產生能夠節省成本的見解,既能為醫療保健提供者節省成本,也能為護理接收者節省成本,同時保持合規性。
計算機視覺
計算機識別影像的進步涉及處理來自同一類別多個物件的龐大影像資料集。例如,人臉識別。對這些資料集進行建模,並建立演算法以將模型應用於較新的影像(測試資料集)以獲得令人滿意的結果。處理這些龐大的資料集和建立模型需要資料科學中使用的各種工具。
高效的能源管理
隨著能源消耗需求的增長,能源生產公司需要更有效地管理能源生產和分配的各個階段。這包括最佳化生產方法、儲存和分配機制,以及研究客戶的消費模式。將來自所有這些來源的資料關聯起來並從中獲取見解似乎是一項艱鉅的任務。使用資料科學工具可以更容易地實現這一點。
網際網路搜尋
許多搜尋引擎使用資料科學來了解使用者行為和搜尋模式。這些搜尋引擎使用各種資料科學方法為每個使用者提供最相關的搜尋結果。隨著時間的推移,谷歌、雅虎、必應等搜尋引擎在幾秒鐘內回覆搜尋的能力越來越強。
語音識別
谷歌助手、蘋果Siri和微軟小娜都利用大型資料集,並由資料科學和自然語言處理(NLP)演算法提供支援。隨著分析更多資料,語音識別軟體得到改進,並對人性有了更深入的理解。
教育
當世界經歷COVID-19疫情時,大多數學生總是隨身攜帶電腦。印度教育體系一直在使用線上課程、作業和考試的電子提交等。對於我們大多數人來說,“線上”完成所有事情仍然具有挑戰性。技術和當代時代發生了轉變。因此,資料科學在教育中的作用比以往任何時候都更加重要,因為它進入了我們的教育體系。
現在,教師和學生的日常互動透過各種平臺被記錄下來,課堂參與度和其他因素正在被評估。因此,不斷增長的線上課程數量提高了教育資料的深度價值。
資料科學 - 機器學習
機器學習使機器能夠從資料中自動學習,從經驗中提高效能,並預測事物,而無需明確程式設計。機器學習主要關注開發允許計算機從資料和過去的經驗中自行學習的演算法。機器學習一詞最初由Arthur Samuel於1959年提出。
資料科學是從資料中獲取有益見解的科學,以便獲得最關鍵和相關的資訊來源。並在獲得可靠的資料流後,使用機器學習生成預測。
資料科學和機器學習是計算機科學的子領域,專注於分析和利用海量資料來改進產品、服務、基礎設施系統等開發和推向市場的過程。
這兩者之間的關係類似於正方形是長方形,但長方形不是正方形。資料科學是包含一切的長方形,而機器學習是作為自身實體的正方形。資料科學家在工作中經常使用這兩者,並且幾乎每個企業都越來越接受它們。
什麼是機器學習?
機器學習 (ML) 是一種演算法型別,它允許軟體在沒有專門程式設計的情況下更準確地預測未來會發生什麼。機器學習背後的基本思想是建立能夠將資料作為輸入並使用統計分析來預測輸出的演算法,同時在有新資料可用時更新輸出。
機器學習是人工智慧的一部分,它使用演算法來查詢資料中的模式,然後預測這些模式將來如何變化。這使工程師能夠使用統計分析來查詢資料中的模式。
Facebook、Twitter、Instagram、YouTube 和 TikTok 收集有關其使用者的資訊,根據您過去的行為,它可以猜測您的興趣和需求,並推薦適合您需求的產品、服務或文章。
機器學習是一組用於資料科學的工具和概念,但它們也出現在其他領域。資料科學家經常在工作中使用機器學習來幫助他們更快地獲取更多資訊或找出趨勢。
機器學習型別
機器學習可以分為三種類型的演算法:
監督學習
無監督學習
強化學習
監督學習
監督學習是一種機器學習和人工智慧型別。它也稱為“監督式機器學習”。它的特點是使用標記資料集來訓練演算法如何正確地分類資料或預測結果。當資料輸入模型時,其權重會發生變化,直到模型正確擬合。這是交叉驗證過程的一部分。監督學習幫助組織找到各種現實世界問題的規模化解決方案,例如將垃圾郵件分類到與收件箱分開的資料夾中,就像在 Gmail 中,我們有一個垃圾郵件資料夾。
監督學習演算法
一些監督學習演算法包括:
樸素貝葉斯 - 樸素貝葉斯是一種分類演算法,它基於貝葉斯定理的類條件獨立性原理。這意味著一個特徵的存在不會改變另一個特徵的可能性,並且每個預測變數對結果/結局的影響相同。
線性迴歸 - 線性迴歸用於發現因變數與一個或多個自變數之間的關係,並對未來可能發生的事情做出預測。當只有一個自變數和一個因變數時,稱為簡單線性迴歸。
邏輯迴歸 − 當因變數是連續型變數時,使用線性迴歸。當因變數是分類變數時,例如“真”或“假”或“是”或“否”,則使用邏輯迴歸。線性迴歸和邏輯迴歸都試圖找出資料輸入之間的關係。但是,邏輯迴歸主要用於解決二元分類問題,例如判斷特定郵件是否為垃圾郵件。
支援向量機(SVM) − 支援向量機是由弗拉基米爾·瓦普尼克開發的一種流行的監督學習模型。它可以用於對資料進行分類和預測。因此,它通常用於透過建立一個超平面來解決分類問題,該超平面使兩組資料點之間的距離最大。這條線稱為“決策邊界”,因為它將資料點組(例如,橙子和蘋果)劃分為平面兩側。
K近鄰 − KNN演算法,也稱為“k近鄰”演算法,根據資料點與其他資料點的接近程度和相關性對資料點進行分組。該演算法基於類似的資料點可以彼此靠近的思想。因此,它試圖找出資料點之間的距離,使用歐幾里得距離,然後根據最常見或平均類別分配類別。但是,隨著測試資料集大小的增加,處理時間也會增加,這使得它不太適合分類任務。
隨機森林 − 隨機森林是另一種靈活的監督機器學習演算法,可用於分類和迴歸。該“森林”是一組彼此不相關的決策樹。然後將這些樹組合起來以減少差異並做出更準確的資料預測。
無監督學習
無監督學習,也稱為無監督機器學習,使用機器學習演算法檢視未標記的資料集並將其分組。這些程式查詢隱藏的模式或資料組。它發現資訊中相似之處和差異的能力使其非常適合探索性資料分析、交叉銷售策略、客戶細分和影像識別。
常見的無監督學習方法
無監督學習模型用於三個主要任務:聚類、建立關聯和降維。下面,我們將描述學習方法和常用的演算法 -
聚類 − 聚類是一種資料探勘方法,它根據資料之間的相似性或差異來組織未標記的資料。聚類技術用於根據資料中的結構或模式將未分類、未處理的資料項組織成組。聚類演算法有很多型別,包括排他性、重疊、層次和機率性。
K均值聚類 是聚類方法的一個流行示例,其中資料點根據其到每個組質心的距離分配到K個組。最接近某個質心的資料點將被歸為同一類。較高的K值表示具有更多粒度的較小組,而較低的K值表示具有較少粒度的較大組。K均值聚類的常見應用包括市場細分、文件聚類、圖片分割和影像壓縮。
降維 − 雖然更多的資料通常會產生更準確的結果,但它也可能影響機器學習演算法的有效性(例如,過擬合)並使資料集難以視覺化。當資料集具有過多的特徵或維度時,降維是一種使用的策略。它將資料輸入的數量減少到可管理的水平,同時儘可能保持資料集的完整性。降維通常用於資料預處理階段,並且有多種方法,其中一種是 -
主成分分析 (PCA) − 它是一種降維方法,用於透過特徵提取來消除冗餘和壓縮資料集。此方法使用線性變換生成新的資料表示,從而產生一組“主成分”。第一個主成分是最大化資料集方差的方向。雖然第二個主成分也類似地找到資料中最大的方差,但它與第一個完全不相關,從而產生一個與第一個正交的方向。此過程根據維度的數量重複,下一個主成分是與先前成分變化最大的成分正交的方向。
強化學習
強化學習 (RL) 是一種機器學習型別,它允許代理透過反覆試驗在互動式環境中學習,利用其自身行動和經驗的反饋。
強化學習中的關鍵術語
一些重要的概念描述了 RL 問題的基本組成部分 -
環境 − 代理執行的物理環境
狀態 − 代理的當前情況
獎勵 − 基於環境的反饋
策略 − 代理狀態和動作之間的對映
價值 − 代理在給定狀態下執行某個動作將獲得的未來回報。
資料科學與機器學習
資料科學是對資料以及如何從中提取有意義的見解的研究,而機器學習是對使用資料來提高效能或提供預測資訊的模型的研究和開發。機器學習是人工智慧的一個子領域。
近年來,機器學習和人工智慧 (AI) 已主導資料科學的某些部分,在資料分析和商業智慧中發揮著至關重要的作用。機器學習使用模型和演算法自動執行資料分析並根據收集和分析有關特定人群的大量資料進行預測。資料科學和機器學習彼此相關,但並不相同。
資料科學是一個廣泛的領域,涵蓋從資料中提取見解和資訊的所有方面。它涉及收集、清理、分析和解釋大量資料以發現模式、趨勢和見解,這些見解可能指導業務決策。
機器學習是資料科學的一個子領域,專注於開發能夠從資料中學習並根據其獲得的知識進行預測或判斷的演算法。機器學習演算法旨在透過獲取新知識隨著時間的推移自動提高其效能。
換句話說,資料科學包含機器學習作為其眾多方法之一。機器學習是資料分析和預測的強大工具,但它只是整個資料科學的一個子領域。
下表是比較表,以便於理解。
| 資料科學 | 機器學習 |
|---|---|
資料科學是一個廣泛的領域,涉及使用各種技術(包括統計分析、機器學習和資料視覺化)從大型複雜資料集中提取見解和知識。 |
機器學習是資料科學的一個子集,涉及定義和開發演算法和模型,使機器能夠從資料中學習並進行預測或決策,而無需明確程式設計。 |
資料科學專注於理解資料、識別模式和趨勢以及提取見解以支援決策。 |
另一方面,機器學習專注於構建預測模型並根據學習到的模式做出決策。 |
資料科學包括各種技術,例如資料清理、資料整合、資料探索、統計分析、資料視覺化和機器學習。 |
另一方面,機器學習主要專注於使用迴歸、分類和聚類等演算法構建預測模型。 |
資料科學通常需要大型複雜的資料集,這些資料集需要大量的處理和清理才能得出見解。 |
另一方面,機器學習需要可用於訓練演算法和模型的標記資料。 |
資料科學需要統計學、程式設計和資料視覺化方面的技能,以及正在研究領域的領域知識。 |
機器學習需要對演算法、程式設計和數學有深入的瞭解,以及特定應用領域的知識。 |
資料科學技術可用於預測之外的各種目的,例如聚類、異常檢測和資料視覺化 |
機器學習演算法主要專注於根據資料進行預測或決策 |
資料科學通常依靠統計方法來分析資料, |
機器學習依靠演算法進行預測或決策。 |
資料科學 - 資料分析
什麼是資料科學中的資料分析?
資料分析是資料科學的關鍵組成部分之一。資料分析被描述為清理、轉換和建模資料的過程,以獲得可操作的商業智慧。它使用統計和計算方法從大量資料中獲取見解和提取資訊。資料分析的目的是從資料中提取相關資訊並根據這些知識做出決策。
雖然資料分析可能包含統計過程,但它通常是一個持續的迭代過程,其中資料不斷收集和分析。事實上,研究人員通常在整個資料收集過程中評估觀察結果以尋找趨勢。具體的定性方法(實地研究、人種志內容分析、口述歷史、傳記、非侵入性研究)和資料的性質決定了分析的結構。
更準確地說,資料分析將原始資料轉換為有意義的見解和有價值的資訊,這有助於在醫療保健、教育、商業等各個領域做出明智的決策。
為什麼資料分析很重要?
以下是資料分析在當今至關重要的原因列表 -
準確的資料 − 我們需要資料分析來幫助企業獲取相關且準確的資訊,他們可以使用這些資訊來規劃業務戰略並做出與未來計劃相關的明智決策,以及重新調整公司的願景和目標。
更好的決策 − 資料分析有助於透過識別資料中的模式和趨勢並提供有價值的見解來做出明智的決策。這使企業和組織能夠做出資料驅動的決策,從而帶來更好的結果和更高的成功率。
提高效率 − 分析資料可以幫助識別業務運營中的低效率和改進領域,從而更好地分配資源並提高效率。
競爭優勢 − 透過分析資料,企業可以透過識別新的機會、開發新的產品或服務以及提高客戶滿意度來獲得競爭優勢。
風險管理 − 分析資料可以幫助識別企業可能面臨的潛在風險和威脅,從而能夠採取積極措施來降低這些風險。
客戶洞察 − 資料分析可以提供關於客戶行為和偏好的寶貴見解,使企業能夠調整其產品和服務以更好地滿足客戶需求。
資料分析過程
隨著企業可以訪問的資料的複雜性和數量的增加,資料分析的需求也隨之增加,以清理資料並提取企業可以用來做出明智決策的相關資訊。
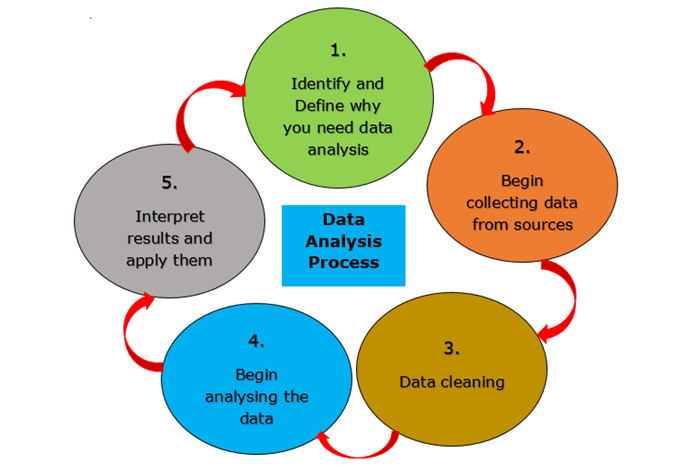
通常,資料分析過程涉及許多迭代輪次。讓我們更詳細地檢查每個輪次。
識別 − 確定要解決的業務問題。公司試圖解決什麼問題?必須測量什麼,以及如何測量?
收集 − 獲取解決指定查詢所需原始資料集。可以使用內部來源,例如客戶關係管理 (CRM) 軟體,或次要來源,例如政府記錄或社交媒體應用程式程式設計介面 (API) 來收集資料。
清理 − 透過清理資料來準備進行分析。這通常包括刪除重複和異常資料、解決不一致性、標準化資料結構和格式以及解決空格和其他語法問題。
分析資料 − 透過使用不同的資料分析方法和工具轉換資料,您可以開始識別模式、相關性、異常值和差異,這些模式、相關性、異常值和差異講述了一個故事。在此階段,您可以使用資料探勘來識別資料庫中的趨勢或使用資料視覺化工具將資料轉換為易於理解的圖形格式。
解讀 − 透過解讀分析結果來確定你的分析結果在多大程度上解決了你的初始問題。根據事實,有哪些可能的建議?你的結論有哪些限制?
資料分析型別
資料可以以多種方式被用來回答問題和輔助決策。為了選擇最佳的資料分析方法,你需要了解該領域廣泛使用的四種資料分析型別,這可能會有所幫助。
我們將在下面的章節中詳細討論每一種型別 −
描述性分析
描述性分析是檢視當前和過去資料以查詢模式和趨勢的過程。它有時被稱為檢視資料的最簡單方法,因為它顯示了趨勢和關係,而無需深入細節。
描述性分析易於使用,並且可能幾乎每個公司每天都在進行。簡單的統計軟體(如 Microsoft Excel)或資料視覺化工具(如 Google Charts 和 Tableau)可以幫助分離資料、查詢變數之間的趨勢和關係,並以視覺方式顯示資訊。
描述性分析是顯示事物如何隨時間變化的好方法。它還利用趨勢作為進一步分析的起點,以幫助做出決策。
這種型別的分析回答了“發生了什麼?”的問題。
描述性分析的一些示例包括財務報表分析、調查報告。
診斷分析
診斷分析是使用資料來找出變數之間趨勢和相關性發生原因的過程。它是繼使用描述性分析識別趨勢之後的下一步。你可以手動、使用演算法或使用統計軟體(如 Microsoft Excel)進行診斷分析。
在深入診斷分析之前,你應該瞭解如何檢驗假設、相關性和因果關係之間的區別以及診斷迴歸分析是什麼。
這種型別的分析回答了“為什麼會發生這種情況?”的問題。
診斷分析的一些示例包括檢查市場需求、解釋客戶行為。
預測分析
預測分析是使用資料來預測未來可能發生的事情的過程。它利用過去的資料來預測可能出現的未來情況,從而幫助做出戰略決策。
預測可能是針對近期或未來,例如預測裝置在當天晚些時候發生故障,或者針對更遙遠的未來,例如預測公司明年的現金流。
預測分析可以手動完成,也可以藉助機器學習演算法完成。無論哪種情況,都使用過去的資料來猜測或預測未來可能發生的事情。
迴歸分析是一種預測分析方法,它可以檢測兩個變數之間的關係(線性迴歸)或三個或更多變數之間的關係(多元迴歸)。變數之間的關係用數學方程表示,該方程可用於預測如果一個變數發生變化,結果會如何。
迴歸使我們能夠深入瞭解這種關係的結構,並提供資料與該關係擬合程度的度量。這些見解對於評估過去的模式和制定預測非常有用。預測可以幫助我們制定資料驅動的計劃並做出更明智的決策。
這種型別的分析回答了“未來可能發生什麼?”的問題。
預測分析的一些示例包括:營銷 - 行為定位,醫療保健 - 疾病或過敏反應的早期檢測。
規範性分析
規範性分析是使用資料來確定下一步最佳行動方案的過程。這種型別的分析考慮所有重要因素,並提出下一步行動建議。這使得規範性分析成為基於資料做出決策的有用工具。
在規範性分析中,機器學習演算法通常用於更快、更有效地篩選大量資料,通常比人工篩選更有效。使用“如果”和“否則”語句,演算法篩選資料並根據特定的一組要求提出建議。例如,如果資料集中至少 50% 的客戶表示對你的客戶服務團隊“非常不滿意”,則演算法可能會建議你的團隊需要更多培訓。
重要的是要記住,演算法可以根據資料提出建議,但不能取代人工判斷。規範性分析應該作為一個工具來使用,以幫助做出決策和制定策略。你的判斷力非常重要,需要為演算法提出的內容提供背景和限制。
這種型別的分析回答了“我們接下來應該做什麼?”的問題。
規範性分析的一些示例包括:投資決策,銷售:潛在客戶評分。
資料科學 - 熱門工具
資料科學工具用於深入挖掘原始和複雜的資料(非結構化或結構化資料),並透過使用不同的資料處理技術(如統計學、計算機科學、預測建模和分析以及深度學習)對其進行處理、提取和分析,以發現有價值的見解。
資料科學家在資料科學生命週期的不同階段使用各種工具來處理每天產生的澤位元組和堯位元組的結構化和/或非結構化資料,並從中獲得有用的見解。這些工具最重要的方面是它們使人們能夠在不使用複雜程式語言的情況下執行資料科學任務。這是因為這些工具具有預先設定好的演算法、函式和圖形使用者介面(GUI)。
最佳資料科學工具
市場上有很多資料科學工具。因此,很難決定哪一個最適合你的學習之旅和職業發展。下圖根據需求展示了一些最佳的資料科學工具 −

SQL
資料科學是對資料的全面研究。為了訪問和處理資料,必須從資料庫中提取資料,為此需要 SQL。資料科學嚴重依賴關係型資料庫管理。使用 SQL 命令和查詢,資料科學家可以管理、定義、更改、建立和查詢資料庫。
一些現代行業已經將其產品資料管理配備了 NoSQL 技術,但 SQL 仍然是許多商業智慧工具和辦公室流程的最佳選擇。
DuckDB
DuckDB 是一個基於表的關系型資料庫管理系統,它還允許你使用 SQL 查詢進行分析。它是免費和開源的,並且具有許多功能,例如更快的分析查詢、更簡單的操作等等。
DuckDB 還與 Python、R、Java 等資料科學中使用的程式語言相容。你可以使用這些語言來建立、註冊和操作資料庫。
Beautiful Soup
Beautiful Soup 是一個 Python 庫,可以從 HTML 或 XML 檔案中提取或抓取資訊。它是一個易於使用的工具,允許你讀取網站的 HTML 內容以從中獲取資訊。
這個庫可以幫助資料科學家或資料工程師設定自動 Web 抓取,這是完全自動化資料管道的重要步驟。
它主要用於網路抓取。
Scrapy
Scrapy 是一個開源的 Python 網路爬蟲框架,用於抓取大量網頁。它是一個網路爬蟲,可以同時抓取和爬行網路。它為你提供了從網站快速獲取資料、按你想要的方式處理資料以及以你想要的結構和格式儲存資料所需的所有工具。
Selenium
Selenium 是一款免費的開源測試工具,用於在不同瀏覽器上測試 Web 應用程式。Selenium 只能測試 Web 應用程式,因此不能用於測試桌面或移動應用程式。Appium 和 HP 的 QTP 是其他兩種可用於測試軟體和移動應用程式的工具。
Python
Python 是資料科學家使用最多的程式語言,也是最受歡迎的程式語言之一。Python 在資料科學領域如此受歡迎的主要原因之一是它易於使用且語法簡單。這使得沒有工程背景的人也能夠輕鬆學習和使用它。此外,還有很多開源庫和線上指南可以將機器學習、深度學習、資料視覺化等資料科學任務付諸實踐。
Python 在資料科學中一些最常用的庫包括 −
- Numpy
- Pandas
- Matplotlib
- SciPy
- Plotly
R
R 是繼 Python 之後資料科學中使用第二多的程式語言。它最初是為了解決統計問題而建立的,但後來發展成為一個完整的資料科學生態系統。
大多數人使用 Dpylr 和 readr(這兩個是庫)來載入資料並對其進行更改和新增。ggplot2 允許你使用不同的方式在圖形上顯示資料。
Tableau
Tableau 是一款視覺化分析平臺,正在改變人們和組織使用資料解決問題的方式。它為個人和組織提供了充分利用其資料的工具。
在溝通方面,Tableau 至關重要。大多數情況下,資料科學家必須分解資訊,以便其團隊、同事、高管和客戶更好地理解。在這些情況下,資訊需要易於檢視和理解。
Tableau 幫助團隊更深入地挖掘資料,發現通常隱藏的見解,然後以既有吸引力又易於理解的方式呈現這些資料。Tableau 還幫助資料科學家快速瀏覽資料,在過程中新增和刪除內容,以便最終結果成為所有重要內容的互動式影像。
Tensorflow
TensorFlow 是一個開源的、免費使用的機器學習平臺,使用資料流圖。圖的節點是數學運算,邊是在它們之間流動的多維資料陣列(張量)。這種架構非常靈活;機器學習演算法可以被描述為協同工作的操作圖。它們可以在不同的平臺上(如行動式裝置、桌上型電腦和高階伺服器)的 GPU、CPU 和 TPU 上進行訓練和執行,而無需更改程式碼。這意味著來自各種背景的程式設計師可以使用相同的工具協同工作,從而極大地提高他們的生產力。Google Brain 團隊建立了該系統來研究機器學習和深度神經網路 (DNN)。然而,該系統足夠靈活,可以應用於其他廣泛的領域。
Scikit-learn
Scikit-learn 是一個流行的開源 Python 機器學習庫,易於使用。它包含各種監督和無監督學習演算法,以及用於模型選擇、評估和資料預處理的工具。Scikit-learn 在學術界和商業領域得到了廣泛的應用。它以快速、可靠和易用而聞名。
它還具有降維、特徵選擇、特徵提取、整合技術以及使用隨程式附帶的資料集的功能。我們將依次研究這些內容。
Keras
Google 的 Keras 是一個用於建立神經網路的高階深度學習 API。它用 Python 構建,用於簡化神經網路的構建。此外,它支援不同的後端神經網路計算。
由於它提供了一個高度抽象的 Python 介面和許多用於計算的後端,因此 Keras 相對容易理解和使用。這使得 Keras 比其他深度學習框架慢,但對於初學者來說非常友好。
Jupyter Notebook
Jupyter Notebook 是一款開源的線上應用程式,允許建立和共享包含即時程式碼、方程式、視覺化和敘述文字的文件。它在資料科學家和機器學習從業者中很受歡迎,因為它提供了一個互動式環境來進行資料探索和分析。
使用 Jupyter Notebook,您可以在 Web 瀏覽器中直接編寫和執行 Python 程式碼(以及其他程式語言編寫的程式碼)。結果將顯示在同一文件中。這使您可以將程式碼、資料和文字說明都放在一個地方,從而方便地共享和重現您的分析。
Dash
Dash 是資料科學中一項重要的工具,因為它允許您使用 Python 建立互動式 Web 應用程式。它使建立資料視覺化儀表板和應用程式變得簡單快捷,而無需瞭解 Web 開發方面的編碼知識。
SPSS
SPSS,代表“社會科學統計軟體包”,是資料科學中一項重要的工具,因為它為新手和經驗豐富的使用者提供了全套的統計和資料分析工具。
資料科學 - 職業
有幾種與資料科學家領域相關或重疊的職位。
與資料科學相關的職位列表 -
以下是與資料科學家相關的職位列表。
資料分析師
資料科學家
資料庫管理員
大資料工程師
資料探勘工程師
機器學習工程師
資料架構師
Hadoop 工程師
資料倉庫架構師
資料分析師
資料分析師分析資料集以識別與客戶相關問題的解決方案。資料分析師還會將這些資訊傳達給管理層和其他利益相關者。這些人工作在各種領域,包括商業、銀行、刑事司法、科學、醫療和政府。
資料分析師是指擁有專業知識和能力,能夠將原始資料轉換為可用於商業決策的資訊和見解的人。
資料科學家
資料科學家是一種專業人士,他們利用分析、統計和程式設計技能來獲取海量資料。他們的職責是利用資料建立針對組織特定需求的解決方案。
公司越來越依賴資料在其日常運營中發揮作用。資料科學家檢查原始資料並從中提取有意義的見解。然後,他們利用這些資料來識別趨勢並提供業務增長和競爭所需的解決方案。
資料庫管理員
資料庫管理員負責管理和維護企業的資料庫。資料庫管理員負責執行資料管理策略,並確保企業資料庫能夠正常執行並在出現記憶體丟失的情況下進行備份。
資料庫管理員(有時稱為資料庫管理者)管理企業資料庫,以確保資訊安全儲存且僅供授權人員訪問。資料庫管理員還必須確保這些人能夠在他們需要的時間以及他們需要的格式訪問他們需要的資訊。
大資料工程師
大資料工程師建立、測試和維護公司使用大資料的解決方案。他們的工作是從各種來源收集大量資料,並確保後續資料使用者能夠快速輕鬆地訪問這些資料。簡而言之,大資料工程師確保公司的數據管道具有可擴充套件性、安全性並能夠為多個使用者服務。
當今生成和使用的資料量似乎是無限的。問題是如何儲存、分析和呈現這些資訊。大資料工程師致力於解決這些問題的方案和技術。
資料探勘工程師
資料探勘是指對資訊進行分類以查詢企業可用於改進其系統和運營的答案的過程。如果資料沒有以正確的方式進行操作和呈現,那麼它就沒有多大用處。
資料探勘工程師建立和執行用於儲存和分析資料的系統。主要任務包括設定資料倉庫、組織資料以方便查詢以及安裝資料流通道。資料探勘工程師需要了解資料的來源、用途以及使用者。ETL(提取、轉換和載入)是資料探勘工程師的關鍵縮寫詞。
機器學習工程師
機器學習 (ML) 開發人員知道如何使用資料訓練模型。然後,這些模型用於自動化諸如將影像分組、語音識別和市場預測等任務。
機器學習可以承擔不同的角色。資料科學家和 AI(人工智慧)工程師的工作之間經常存在一些重疊,有時甚至會混淆這兩個職位。機器學習是 AI 的一個子領域,專注於檢查資料以發現輸入和預期輸出之間的關聯。
機器學習開發人員確保每個問題都有一個完美的解決方案。只有透過仔細處理資料併為特定情況選擇最佳演算法,才能獲得最佳結果。
資料架構師
資料架構師透過找到最佳的設定和結構方式來構建和管理公司的資料庫。他們與資料庫管理人員和分析師合作,確保公司資料易於訪問。任務包括建立資料庫解決方案、確定需要做什麼以及建立設計報告。
資料架構師是制定組織資料策略的專家,其中包括資料質量標準、資料在組織中的流動方式以及資料安全保障方式。這種資料管理專業人員的視角將業務需求轉化為技術需求。
作為業務和技術之間的關鍵紐帶,資料架構師的需求越來越大。
Hadoop 工程師
Hadoop 開發人員負責構建和編碼 Hadoop 應用程式。Hadoop 是一個開源框架,用於管理和儲存處理大量資料並在集群系統上執行的應用程式。基本上,Hadoop 開發人員構建應用程式以幫助公司管理和跟蹤其大資料。
Hadoop 開發人員負責編寫 Hadoop 應用程式的程式碼。這個職位類似於軟體開發人員。這兩個職位非常相似,但第一個職位屬於大資料領域。讓我們看看 Hadoop 開發人員的一些職責,以便更好地瞭解這個職位。
資料倉庫架構師
資料倉庫架構師負責提出資料倉庫的解決方案,並利用標準的資料倉庫技術來制定最有利於企業或組織的計劃。在設計特定架構時,資料倉庫架構師通常會考慮僱主目標或客戶需求。然後,員工可以維護此架構並利用它來實現目標。
因此,就像普通建築師設計建築物或海軍建築師設計船舶一樣,資料倉庫架構師設計和幫助啟動資料倉庫,並根據客戶的需求進行定製。
2022 年資料科學職位趨勢
到 2022 年,對資料科學家的需求將大幅增長。IBM 預計 2020 年將新增 364,000 至 2,720,000 個職位。這種需求將持續增長,很快將出現 700,000 個空缺職位。
Glassdoor 表示,其網站上排名第一的職位是資料科學家。未來,這個職位不會有任何變化。此外,還發現資料科學職位空缺的開放時間為 45 天。這比平均職位市場長 5 天。
IBM 將與學校和企業合作,為有抱負的資料科學家建立一種工學結合的環境。這將有助於彌合技能差距。
對資料科學家的需求正在以指數級速度增長。這是因為創造了新的工作和行業。不斷增長的資料量和資料型別加劇了這種狀況。
未來,資料科學家的職位和數量只會越來越多。資料科學家職位包括資料工程師、資料科學經理和大資料架構師。此外,金融和保險行業正在成為資料科學家的主要僱主之一。
隨著培訓資料科學家的機構數量的增加,越來越多的人可能會掌握資料技能。
資料科學 - 科學家
資料科學家是經過培訓的專業人士,負責分析和解讀資料。他們利用其資料科學知識幫助企業做出更好的決策並提高運營效率。大多數資料科學家都擁有豐富的數學、統計學和計算機科學經驗。他們利用這些知識來檢查大型資料集並發現趨勢或模式。資料科學家還可以開發新的資料收集和儲存方法。
如何成為一名資料科學家?
對能夠利用資料分析為公司提供競爭優勢的人才的需求很大。作為一名資料科學家,您將根據資料建立業務解決方案和分析。
成為資料科學家的途徑有很多,但由於它通常是一個高階職位,因此大多數資料科學家都擁有數學、統計學、計算機科學和其他相關領域的學位。
以下是成為資料科學家的幾個步驟 -
步驟 1 - 正確的資料技能
即使您沒有任何與資料相關的工作經驗,也可以成為一名資料科學家,但您需要獲得從事資料科學職業所需的必要基礎。
資料科學家是一個高階職位;在達到這種專業水平之前,您應該在相關領域打下紮實的基礎知識。這可能包括數學、工程學、統計學、資料分析、程式設計或資訊科技;一些資料科學家是從銀行或棒球球探開始其職業生涯的。
但無論您從哪個領域開始,都應該從 Python、SQL 和 Excel 開始。這些技能對於處理和組織原始資料至關重要。熟悉 Tableau 也很有幫助,這是一個您將經常使用來建立視覺化的工具。
步驟 2 - 學習資料科學基礎知識
資料科學訓練營可能是學習或提高資料科學原理的絕佳方法。您可以參考 資料科學訓練營,其中詳細介紹了每個主題。
學習資料科學基礎知識,例如如何收集和儲存資料、分析和建模資料以及使用資料科學工具箱中的所有工具(例如 Tableau 和 PowerBI 等)來顯示和呈現資料。
在培訓結束時,您應該能夠使用 Python 和 R 建立評估行為和預測未知數的模型,以及以使用者友好的格式重新打包資料。
許多資料科學職位列表將高階學位列為先決條件。有時,這是不可協商的,但當需求超過供應時,這一點越來越凸顯了真相。也就是說,必要的技能證明往往勝過單純的證書。
招聘經理最關心的是你如何展示自己對相關領域的瞭解程度,越來越多的人意識到,這並不一定要透過傳統的方式來實現。
資料科學基礎
收集和儲存資料。
分析和建模資料。
構建一個能夠使用給定資料進行預測的模型。
以使用者友好的形式視覺化和呈現資料。
步驟 3 - 學習資料科學的關鍵程式語言
資料科學家使用各種專門用於資料清洗、分析和建模的工具和程式。資料科學家需要掌握的不僅僅是 Excel。他們還需要了解像 Python、R 或 Hive 這樣的統計程式語言,以及像 SQL 這樣的查詢語言。
RStudio Server 是資料科學家最重要的工具之一,它提供了一個在伺服器上使用 R 進行開發的環境。另一個流行的軟體是開源的 Jupyter Notebook,它可以用於統計建模、資料視覺化、機器學習等。
機器學習在資料科學中得到了最廣泛的應用。它指的是利用人工智慧賦予系統學習和改進能力的工具,而無需進行專門的程式設計。
步驟 4 - 學習如何進行視覺化並進行練習
使用 Tableau、PowerBI、Bokeh、Plotly 或 Infogram 等程式練習從頭開始建立自己的視覺化。找到最佳方法讓資料自身“說話”。
Excel 通常用於此步驟。儘管電子表格的基本原理很簡單——透過關聯單元格中的資訊進行計算或繪圖——但 Excel 在 30 多年後的今天仍然非常有用,並且幾乎不可能在沒有它的情況下進行資料科學。
但製作精美的圖表僅僅是開始。作為一名資料科學家,你還需要能夠利用這些視覺化結果向現場觀眾展示你的發現。你可能已經具備了這些溝通技巧,如果沒有,也不用擔心。任何人都可以透過練習變得更好。如果需要,可以從小做起,先向一位朋友甚至你的寵物進行演示,然後再擴充套件到一個群體。
步驟 5 - 從事一些有助於提升你的實踐資料技能的資料科學專案
一旦你瞭解了資料科學家使用的程式語言和數字工具的基礎知識,就可以開始使用它們來練習和提升你的新技能。嘗試承擔需要廣泛技能的專案,例如使用 Excel 和 SQL 管理和查詢資料庫,以及使用 Python 和 R 透過統計方法分析資料,構建分析行為並提供新見解的模型,以及使用統計分析來預測未知的事物。
在練習過程中,嘗試涵蓋流程的不同部分。從研究一家公司或市場領域開始,然後為手頭的任務定義和收集正確的資料。最後,清理和測試這些資料,使其儘可能有用。
最後,你可以建立並使用自己的演算法來分析和建模資料。然後,你可以將結果放入易於閱讀的視覺化效果或儀表板中,使用者可以使用這些視覺化效果與你的資料進行互動並提出問題。你甚至可以嘗試向其他人展示你的發現,以提高溝通能力。
你還應該習慣於處理不同型別的資料,例如文字、結構化資料、影像、音訊,甚至影片。每個行業都有自己獨特的資料型別,幫助領導者做出更明智、更合理的決策。
作為一名工作中的資料科學家,你可能會在一個或兩個領域成為專家,但作為一個正在構建技能集的初學者,你需要學習儘可能多的型別資料的基礎知識。
承擔更復雜的專案將讓你有機會了解資料如何在不同的方式中被使用。一旦你瞭解瞭如何使用描述性分析來尋找資料中的模式,你將能夠更好地準備嘗試更復雜的統計方法,例如資料探勘、預測建模和機器學習,以預測未來的事件甚至提出建議。
步驟 6 - 建立一個展示你的資料科學技能的作品集
完成初步研究、接受培訓並透過完成一系列令人印象深刻的專案練習了你的新技能後,下一步就是透過建立精美的作品集來展示你的新技能,從而獲得你夢想的工作。
事實上,你的作品集可能是你求職過程中最重要的東西。如果你想成為一名資料科學家,你可能希望在 GitHub 上展示你的作品,而不是(或除了)你自己的網站。GitHub 使得輕鬆展示你的工作、流程和結果成為可能,同時也在公共網路中提升你的知名度。但不要止步於此。
將引人入勝的故事與你的資料結合起來,並展示你試圖解決的問題,以便僱主能夠了解你的能力。你可以在 GitHub 上以更宏觀的視角展示你的程式碼,而不僅僅是單獨展示程式碼,這使得你的貢獻更容易理解。
在申請特定職位時,不要列出你所有的工作。只需突出一些與你申請的職位最相關,並且最能展示你在整個資料科學流程中技能範圍的作品,從開始使用基本資料集到定義問題、清理資料、構建模型以及找到解決方案。
你的作品集是你展示自己不僅僅能夠處理數字,還能夠進行良好溝通的機會。
步驟 7 - 展示你的能力
你獨立完成的一個精心製作的專案可以成為展示你的技能和打動可能聘用你的招聘經理的絕佳方式。
選擇一些你真正感興趣的東西,提出一個關於它的問題,並嘗試用資料來回答這個問題。
記錄你的旅程,並透過以美觀的方式呈現你的發現並解釋你如何得出這些發現,來展示你的技術技能和創造力。你的資料應該伴隨著引人入勝的敘述,展示你解決的問題,突出你的過程和採取的創造性步驟,以便僱主能夠看到你的價值。
加入 Kaggle 等線上資料科學網路是另一種證明你參與社群、展示你作為一名有抱負的資料科學家的技能以及繼續提升你的專業知識和影響力的絕佳方式。
步驟 8 - 開始申請資料科學職位
資料科學領域有很多工作機會。學習基礎知識後,人們通常會繼續專注於不同的子領域,例如資料工程師、資料分析師或機器學習工程師等等。
瞭解一家公司重視什麼以及他們在做什麼,並確保它符合你的技能、目標以及你未來的職業規劃。並且不要只關注矽谷。像波士頓、芝加哥和紐約這樣的城市也面臨著技術人才短缺的問題,因此也存在大量機會。
資料科學家 - 薪資
隨著數字化在全球範圍內的普及,資料科學已成為世界上薪酬最高的職業之一。在印度,資料科學家的年薪在 1.8 萬盧比到 100 萬盧比之間,具體取決於他們的資格、技能和經驗。
決定資料科學家薪資的主要因素
一些因素會影響資料科學家的薪資。當然,經驗是最重要的因素,但印度資料科學家的薪資也取決於他們的技能、職位、就職公司以及居住地。
基於技能的薪資
印度的資料科學薪資也取決於你在該領域的技能水平。你在該領域掌握的技能越多,獲得更高薪資的可能性就越大。即使是印度資料科學家的起薪,對於擁有不同 IT 技能的人來說也更高。如果你簡歷中突出顯示的技能足夠獨特,招聘人員會更加關注你。如果你具備機器學習、Python、統計分析和大資料分析等技能,你可能能夠獲得更高的薪資。
基於經驗的薪資
在印度的資料科學職位薪資方面,經驗是一個主要因素。PayScale 表示,印度工作經驗少於一年的初級資料科學家的平均薪資約為 577,893 盧比。工作經驗為 1-4 年的員工平均薪資為 809,952 盧比。工作經驗為 5-9 年的職業中期資料科學家每年可以賺取高達 1,448,144 盧比。而在印度,工作經驗為 1-19 年的員工平均年薪可達 1,944,566 盧比。
基於地點的薪資
地點是影響你在印度獲得的資料科學職位薪資的另一個因素。印度有許多招聘資料科學家的主要城市,但不同城市的薪資待遇有所不同。
基於公司的薪資
許多公司定期招聘資料科學家,但大多數情況下,他們承擔不同的職位或角色。如果你在這些公司工作,你的薪資將取決於你獲得的職位。印度的其他公司也每年向資料科學家支付不同的薪資。在接受工作邀請之前,你始終可以瞭解其他公司印度資料科學家的月薪或年薪。
印度資料科學家薪資
下表顯示了印度不同資料科學職位型別的平均薪資:
| 序號 | 職位名稱 | 印度平均年基本薪資 |
|---|---|---|
| 1 | 資料科學家 |
₹ 10.0 LPA |
| 2 | 資料架構師 |
₹ 24.7 LPA |
| 3 | 資料工程師 |
₹ 8.0 LPA |
| 4 | 資料分析師 | ₹ 4.2 LPA |
| 5 | 資料庫管理員 |
₹ 10.0 LPA |
| 6 | 機器學習工程師 |
₹ 6.5 LPA |
以上資料來自 Ambition Box。
美國資料科學家薪資
下表顯示了美國不同資料科學職位型別的平均薪資:
| 序號 | 職位名稱 | 美國平均年基本薪資 |
|---|---|---|
| 1 | 資料科學家 |
$123,829 |
| 2 | 資料架構師 | $1,28,205 |
| 3 | 資料工程師 |
$126,443 |
| 4 | 資料分析師 | $71,047 |
| 5 | 資料庫管理員 |
$90,078 |
| 6 | 機器學習工程師 |
$146,799 |
以上資料來自 Indeed。
美國的資料科學家平均薪資最高,其次是澳大利亞、加拿大和德國。
根據 Payscale 的資料,基於 498 份薪資資料,工作經驗少於 1 年的初級資料科學家預計可以獲得平均總薪酬(包括小費、獎金和加班工資)為 ₹589,126。基於 2,250 份薪資資料,職業早期(工作經驗 1-4 年)的資料科學家平均總薪酬為 ₹830,781。基於 879 份薪資資料,職業中期(工作經驗 5-9 年)的資料科學家平均總薪酬為 ₹1,477,290。基於 218 份薪資資料,經驗豐富的資料科學家(工作經驗 10-19 年)平均總薪酬為 ₹1,924,803。在職業後期(20 年及以上),員工的平均總薪酬為 ₹1,350,000。
近年來,技術的進步使得資料科學在許多不同的工作領域變得越來越重要。資料科學的應用不僅僅侷限於資料收集和分析。它現在已成為一個多學科領域,包含許多不同的角色。隨著高薪和職業發展前景的保證,越來越多的人每天都加入資料科學領域。
資料科學 - 資源
本文列出了 2023 年你可以參加的最佳資料科學課程和專案,以提升你的技能並獲得最佳的資料科學家職位之一。你應該參加這些面向資料科學家的線上課程和認證之一,踏上掌握資料科學的正確道路。
頂級資料科學課程
在本節中,我們將討論一些可以在網際網路上找到的流行的資料科學課程。
在製作 2023 年頂級資料科學課程列表時,我們考慮了多種因素/方面,包括:
課程內容 - 該列表在考慮課程大綱廣度的同時,也考慮了課程針對不同經驗水平的有效性。
課程特色與成果 − 我們還討論了課程成果和其他方面,例如查詢解決、動手專案等,這些將幫助學生獲得有市場價值的技能。
課程時長 − 我們已計算出每門課程的時長。
所需技能 − 我們已說明了申請者必須具備的參與課程所需的技能。
課程費用 − 每門課程都根據其特色和價格進行分級,以確保您物有所值。
掌握資料科學與機器學習的 A 到 Z課程亮點
涵蓋資料科學的所有領域,從程式設計基礎(二進位制、迴圈、數制等)開始,到中級程式設計主題(陣列、OOPs、排序、遞迴等)和機器學習工程(NLP、強化學習、TensorFlow、Keras 等)。
終身訪問。
30 天退款保證。
完成課程後頒發證書。
課程時長:94 小時。
檢視課程詳情 此處
課程亮點
無論您是否具備基本的 Python 技能,本課程都將幫助您建立資料科學基礎。程式碼隨堂講解和精心設計的練習將使您從一開始就對 Python 語法感到舒適。在本短課程結束時,您將熟練掌握 Python 程式設計在資料科學和資料分析中的基礎知識。
在本真正循序漸進的課程中,每個新的教程影片都建立在您已學到的內容之上。目的是一次讓您向前邁進一步,然後,您會收到一個小型任務,該任務將在下一個影片的開頭立即解決。也就是說,您首先從理解新概念的理論部分開始。然後,您透過使用 Python 將所有內容付諸實踐來掌握這個概念。
透過報名參加本課程,成為 Python 開發人員和資料科學家。即使您是 Python 和資料科學的新手,您也會發現本說明性課程資訊豐富、實用且有幫助。如果您不是 Python 和資料科學的新手,您仍然會發現本課程中的動手專案非常有幫助。
課程時長:14 小時
檢視課程詳情 此處。
課程描述
本課程首先演示了 R 語言的重要性及其優勢,然後介紹了 R 資料型別、變數賦值、算術運算、向量、矩陣、因子、資料框和列表等主題。此外,還包括運算子、條件語句、迴圈、函式和包等主題。它還涵蓋正則表示式、獲取和清理資料、繪圖以及使用 dplyr 包進行資料操作。
終身訪問。
30 天退款保證。
完成課程後頒發證書。
課程時長:6 小時
檢視課程詳情 此處。
在本課程中,您將學習 -
資料科學專案的生命週期。
資料科學中廣泛使用的 Pandas 和 Numpy 等 Python 庫。
用於資料視覺化的 Matplotlib 和 Seaborn。
資料預處理步驟,如特徵編碼、特徵縮放等…
機器學習基礎和不同的演算法
機器學習的雲計算
深度學習
5 個專案,如糖尿病預測、股票價格預測等…
課程時長:7 小時
檢視課程詳情 此處。
課程描述
本 Pandas 課程全面概述了這個強大的工具,用於實現資料分析、資料清理、資料轉換、不同的資料格式、文字操作、正則表示式、資料 I/O、資料統計、資料視覺化、時間序列等。
本課程是一個實踐課程,包含許多示例,因為學習最簡單的方法就是練習!然後,我們將整合我們所學到的所有知識,在一個 Capstone 專案中開發初步分析、清理、過濾、轉換和視覺化資料,使用著名的 IMDB 資料集。
課程時長:6 小時
檢視課程詳情 此處。
本課程面向希望成為 Python 程式設計概念和資料科學庫(用於分析、機器學習模型等)專家的初學者和中級學習者。
他們可以是學生、專業人士、資料科學家、商業分析師、資料工程師、機器學習工程師、專案經理、領導者、業務報告員等。
課程分為 6 個部分 - 章節、測驗、課堂動手練習、家庭作業動手練習、案例研究和專案。
透過課堂、家庭作業、案例研究和專案練習和實踐概念
本課程非常適合任何開始資料科學之旅並將來構建機器學習模型和分析的人。
本課程涵蓋了在學術界和企業行業取得成功所需的所有重要的 Python 基礎知識和資料科學概念。
有機會在 3 個真實世界的案例研究和 2 個真實世界的專案中應用資料科學概念。
這 3 個案例研究分別關於貸款風險分析、客戶流失預測和客戶細分。
這兩個專案分別關於泰坦尼克號資料集和紐約市計程車行程時長。
課程時長:8.5 小時
檢視課程詳情 此處。
課程描述
學生將獲得關於統計學基礎知識。
他們將清楚地瞭解不同型別的資料及其示例,這對於理解資料分析非常重要。
學生將能夠分析、解釋和解讀資料。
他們將透過學習皮爾遜相關係數、散點圖和變數之間的線性迴歸分析來理解關係和依賴性,並能夠知道如何進行預測。
學生將瞭解不同的資料分析方法,例如集中趨勢的度量(均值、中位數、眾數)、離散度的度量(方差、標準差、變異係數)、如何計算四分位數、偏度和箱線圖。
在學習了偏度和箱線圖之後,他們將清楚地瞭解資料的形狀,這是資料分析的重要組成部分。
學生將對機率有一個基本的瞭解,以及如何用最簡單的例子解釋和理解貝葉斯定理。
課程時長:7 小時
檢視課程詳情 此處。
頂級資料科學電子書
在本節中,我們將討論一些可在網際網路上獲取的流行資料科學電子書。
資料科學入門課程
在這本書中,您將找到開始學習資料科學並熟練掌握其方法和工具所需的一切。在當今快節奏的世界中,瞭解資料科學及其如何幫助預測至關重要。本書的目的是提供資料科學及其方法論的高階概述。資料科學起源於統計學。但是,要在這個領域取得成功,需要具備程式設計、業務和統計學方面的專業知識。學習的最佳方法是詳細瞭解每個主題。
在資料集中查詢趨勢和見解是一門古老的藝術。古埃及人使用人口普查資訊來更好地徵稅。尼羅河洪水的預測也使用資料分析來進行。在資料集中找到模式或令人興奮的資訊片段需要回顧之前的資料。公司將能夠利用這些資訊做出更好的選擇。資料科學家的需求不再隱藏;如果您喜歡分析數字資訊,那麼這就是您的領域。資料科學是一個不斷發展的領域,如果您決定在其中接受教育,那麼您應該抓住機會盡快在這個領域工作。
檢視電子書 此處。
使用 Anaconda 構建資料科學解決方案
在這本書中,您將學習如何使用 Anaconda 作為輕鬆按鈕,可以全面瞭解 conda 等工具的功能,包括如何指定新的通道以引入任何所需的包,以及發現可供您使用的新的開源工具。您還將清楚地瞭解如何評估要訓練的模型,以及如何識別模型由於漂移而變得不可用。最後,您將瞭解可以用來解釋模型工作原理的強大而簡單的技術。
在閱讀完本書後,您將充滿信心使用 conda 和 Anaconda Navigator 管理依賴項,並深入瞭解端到端的資料科學工作流程。
檢視電子書 此處。
使用 Python 進行實踐資料科學
本書首先概述了基本的 Python 技能,然後介紹了資料科學的基礎技術,接著詳細解釋了執行這些技術所需的 Python 程式碼。您將透過學習示例來理解程式碼。程式碼已分解成小塊(一次幾行或一個函式),以便進行徹底的討論。
隨著您的學習進度,您將學習如何在探索關鍵資料科學 Python 包(包括 pandas、SciPy 和 scikit-learn)的功能的同時執行資料分析。最後,本書涵蓋了資料科學中的倫理和隱私問題,並建議了提高資料科學技能的資源,以及瞭解資料科學新發展的方法。
在閱讀完本書後,您應該能夠舒適地使用 Python 完成基本的資料科學專案,並且應該具備在任何資料來源上執行資料科學流程的技能。
檢視電子書 此處。
清理資料以進行有效的資料科學
本書深入探討了資料攝取、異常檢測、值插補和特徵工程所需的工具和技術的實際應用。它還在每一章的末尾提供了長篇練習,以練習所獲得的技能。
您將從檢視 JSON、CSV、SQL RDBMS、HDF5、NoSQL 資料庫、影像格式檔案和二進位制序列化資料結構等資料格式的資料攝取開始。此外,本書提供了大量示例資料集和資料檔案,可供下載和獨立探索。
從格式開始,您將插補缺失值、檢測不可靠資料和統計異常,並生成成功的資料分析和視覺化目標所需的合成特徵。
在閱讀完本書後,您將對執行真實世界資料科學和機器學習任務所需的資料清理過程有一個堅實的理解。
檢視電子書 此處。
資料科學與分析基礎
本書結合了資料科學和分析的關鍵概念,幫助您對這些領域有實用的瞭解。本書的四個不同部分分為各個章節,解釋了資料科學的核心內容。鑑於人們對資料科學的興趣日益濃厚,本書適逢其時且內容豐富。
檢視電子書 此處。
資料科學 - 面試問題
以下是面試中一些最常見的問題。
Q1. 什麼是資料科學,它與其他與資料相關的領域有什麼區別?
資料科學是一個研究領域,它利用計算和統計方法從資料中獲取知識和見解。它利用數學、統計學、計算機科學和領域特定知識的技術來分析大型資料集,從資料中發現趨勢和模式,並對未來進行預測。
資料科學與其他資料相關領域的不同之處在於,它不僅僅是收集和組織資料。資料科學過程包括分析、建模、視覺化和評估資料集。資料科學使用機器學習演算法、資料視覺化工具和統計模型等工具來分析資料,做出預測並發現資料中的模式和趨勢。
其他與資料相關的領域,如機器學習、資料工程和資料分析,更專注於某一特定方面,例如機器學習工程師的目標是設計和建立能夠從資料中學習並做出預測的演算法,資料工程的目標是設計和管理資料管道、基礎設施和資料庫。資料分析就是探索和分析資料以發現模式和趨勢。而資料科學則涉及建模、探索、收集、視覺化、預測和模型部署。
總的來說,資料科學是一種更全面的資料分析方法,因為它涵蓋了從資料準備到預測的整個過程。其他處理資料的領域則擁有更具體的專業領域。
Q2. 資料科學過程是什麼,其中涉及的關鍵步驟有哪些?
資料科學過程,也稱為資料科學生命週期,是一種系統的方法來找到資料問題的解決方案,它展示了開發、交付和維護資料科學專案所採取的步驟。
標準的資料科學生命週期方法包括使用機器學習演算法和統計程式,從而產生更準確的預測模型。資料提取、準備、清洗、建模、評估等是資料科學中一些最重要的階段。資料科學過程中涉及的關鍵步驟包括:
識別問題並瞭解業務
就像任何其他業務生命週期一樣,資料科學生命週期從“為什麼”開始。資料科學過程中最重要的部分之一是確定問題是什麼。這有助於找到一個明確的目標,所有其他步驟都圍繞它展開。簡而言之,儘早瞭解業務目標非常重要,因為它將決定分析的最終目標。
資料收集
資料科學生命週期的下一步是資料收集,這意味著從適當且可靠的來源獲取原始資料。收集的資料可以是有組織的或無組織的。資料可以從網站日誌、社交媒體資料、線上資料儲存庫以及甚至使用 API 從線上源流式傳輸的資料中收集,還可以透過網路抓取或儲存在 Excel 或任何其他來源中的資料。
資料處理
在從可靠來源收集高質量資料後,下一步是處理它。資料處理的目的是確保在進入下一階段之前,已解決獲取資料中的任何問題。如果沒有這一步,我們可能會產生錯誤或不準確的發現。
資料分析
資料分析探索性資料分析 (EDA) 是一組用於分析資料的視覺化技術。使用此方法,我們可以獲取有關資料統計摘要的特定詳細資訊。此外,我們將能夠處理重複數字、異常值並識別集合中的趨勢或模式。
資料視覺化
資料視覺化是將資訊和資料在圖表上展示的過程。資料視覺化工具透過使用圖表、圖形和地圖等視覺元素,使理解資料中的趨勢、異常值和模式變得容易。對於員工或企業主來說,它也是一種向不熟悉技術的人展示資料的好方法,而不會讓他們感到困惑。
資料建模
資料建模是資料科學中最重要的方面之一,有時也被稱為資料分析的核心。模型的預期輸出應源自已準備和分析的資料。
在此階段,我們開發用於訓練和測試模型以執行生產相關任務的資料集。它還涉及選擇正確的模型型別並確定問題是否涉及分類、迴歸或聚類。在分析模型型別後,我們必須選擇合適的實現演算法。必須謹慎執行此操作,因為它對於從提供的資料中提取相關見解至關重要。
模型部署
模型部署包含建立必要的交付方法,以便將模型部署到市場消費者或其他系統。機器學習模型也正在裝置上實施,並獲得認可和吸引力。根據專案的複雜程度,此階段可能從Tableau Dashboard上的基本模型輸出到擁有數百萬使用者的複雜雲端部署。
Q3. 監督學習和無監督學習有什麼區別?
監督學習 - 監督學習是一種機器學習和人工智慧型別。它也稱為“監督式機器學習”。它的定義特徵是使用標記資料集來訓練演算法如何正確地對資料進行分類或預測結果。隨著資料輸入模型,其權重會發生變化,直到模型正確擬合。這是交叉驗證過程的一部分。監督學習幫助組織為各種現實世界問題找到大規模的解決方案,例如將垃圾郵件分類到與收件箱分開的資料夾中,就像在Gmail中,我們有一個垃圾郵件資料夾。
監督學習演算法 - 樸素貝葉斯、線性迴歸、邏輯迴歸。
無監督學習 - 無監督學習,也稱為無監督機器學習,使用機器學習演算法檢視未標記的資料集並將它們組合在一起。這些程式發現隱藏的模式或資料組。它能夠發現資訊中的相似點和差異,使其非常適合探索性資料分析、交叉銷售策略、客戶細分和影像識別。
無監督學習演算法 - K均值聚類
Q4. 什麼是正則化,它如何幫助避免過擬合?
正則化是一種向模型新增資訊以阻止其過擬合的方法。它是一種試圖使係數估計儘可能接近零的迴歸型別,從而使模型更小。在這種情況下,去除額外的權重就是降低模型容量的含義。
正則化從選定的特徵中去除任何額外的權重,並重新分配權重,使它們都相同。這意味著正則化使得學習一個既靈活又具有大量可移動部件的模型變得更加困難。一個非常靈活的模型是可以擬合儘可能多的資料點的模型。
Q5. 什麼是交叉驗證,為什麼它在機器學習中很重要?
交叉驗證是一種透過在可用輸入資料的不同子集上訓練機器學習模型,然後在另一個子集上測試它們來測試機器學習模型的技術。我們可以使用交叉驗證來檢測過擬合,即未能概括模式。
對於交叉驗證,我們可以使用k折交叉驗證方法。在k折交叉驗證中,我們將開始時的資料分成k組(也稱為折)。我們在除一個(k-1)之外的所有子集上訓練機器學習模型,然後在未用於訓練的子集上測試該模型。此過程執行k次,並且每次都將不同的子集留出用於評估(並且不用於訓練)。
Q6. 機器學習中的分類和迴歸有什麼區別?
迴歸和分類之間的主要區別在於,迴歸有助於預測連續量,而分類有助於預測離散類標籤。這兩種機器學習演算法的一些組成部分也是相同的。
迴歸演算法可以對離散值(即整數)做出預測。
如果該值以類標籤機率的形式,則分類演算法可以預測此型別的資料。
Q7. 什麼是聚類,一些流行的聚類演算法有哪些?
聚類是一種資料探勘方法,它根據資料之間的相似性或差異對其進行組織。聚類技術用於根據資料中的結構或模式,將未分類、未處理的資料項組織成組。聚類演算法有很多型別,包括排斥性、重疊性、層次性和機率性。
K均值聚類是聚類方法的一個流行示例,其中資料點根據其到每個組的質心的距離分配到K個組。最接近某個質心的資料點將被分組到同一類別中。較高的K值表示具有更多粒度的較小組,而較低的K值表示具有較少粒度的較大組。K均值聚類的常見應用包括市場細分、文件聚類、圖片分割和影像壓縮。
Q8. 什麼是梯度下降,它如何在機器學習中工作?
梯度下降是一種最佳化演算法,通常用於訓練神經網路和機器學習模型。訓練資料幫助這些模型隨著時間的推移學習,並且梯度下降中的成本函式充當衡量其在每次引數更新迭代中的準確性的晴雨表。模型將不斷更改其引數以使誤差儘可能小,直到函式接近或等於0。一旦機器學習模型被調整到儘可能準確,它們就可以以強大的方式用於人工智慧(AI)和計算機科學中。
Q9. 什麼是A/B測試,它如何在資料科學中使用?
A/B測試是一種常見的隨機對照實驗形式。這是一種確定在受控環境中兩個變數的哪個版本表現更好的方法。A/B測試是資料科學和整個科技行業中最重要的概念之一,因為它是最有效的方法之一,可以得出關於任何假設的結論。您必須瞭解什麼是A/B測試以及它通常如何工作。A/B測試是評估產品的常用方法,並且在資料分析領域正在獲得發展勢頭。在測試增量更改(例如使用者體驗修改、新功能、排名和頁面載入速度)時,A/B 測試更有效。
Q10. 你能解釋一下過擬合和欠擬合,以及如何緩解它們嗎?
過擬合是當函式過度擬合到有限數量的資料點時出現的建模錯誤。它是模型具有過多的訓練點和過高複雜度的結果。
欠擬合是當函式沒有正確擬合數據點時出現的建模錯誤。這是模型過於簡單且訓練點不足的結果。
機器學習研究人員可以透過多種方法避免過擬合。這些方法包括:交叉驗證、正則化、剪枝、Dropout。
機器學習研究人員可以透過多種方法避免欠擬合。這些方法包括:
獲取更多訓練資料。
新增更多引數或增加引數的大小。
使模型更復雜。
增加訓練時間,直到成本函式達到最低。
透過這些方法,您應該能夠改進您的模型並解決任何過擬合或欠擬合問題。