資料科學 - 生命週期
什麼是資料科學生命週期?
資料科學生命週期是一種系統性的方法,用於尋找解決資料問題的方案,它展示了開發、交付/部署和維護資料科學專案所採取的步驟。我們可以假設一個一般的資料科學生命週期,其中包含一些最重要的常見步驟,如下面的圖所示,但一些步驟可能因專案而異,因為每個專案都不同,所以生命週期可能也不同,因為並非每個資料科學專案都是以相同的方式構建的。
標準的資料科學生命週期方法包括使用機器學習演算法和統計程式,從而產生更準確的預測模型。資料提取、準備、清洗、建模、評估等是資料科學中一些最重要的階段。這種技術在資料科學領域被稱為“跨行業資料探勘標準程式”。
資料科學生命週期有多少個階段?
資料科學生命週期主要有六個階段:

識別問題並理解業務
資料科學生命週期從“為什麼?”開始,就像任何其他業務生命週期一樣。資料科學過程中最重要的部分之一是弄清楚問題是什麼。這有助於找到一個明確的目標,圍繞這個目標可以規劃所有其他步驟。簡而言之,儘早瞭解業務目標非常重要,因為它將決定分析的最終目標。
此階段應評估業務趨勢,評估類似分析的案例研究,並研究行業的領域。小組將根據現有員工、裝置、時間和技術評估專案的可行性。當這些因素被發現和評估後,將制定初步假設以解決現有環境導致的業務問題。此階段應:
明確說明問題,為什麼必須立即解決這個問題並需要答案。
明確說明業務專案的潛在價值。
確定與專案相關的風險,包括倫理問題。
建立和傳達靈活、高度整合的專案計劃。
資料收集
資料科學生命週期的下一步是資料收集,這意味著從適當且可靠的來源獲取原始資料。收集的資料可以是有組織的,也可以是無組織的。資料可以從網站日誌、社交媒體資料、線上資料儲存庫,甚至是使用 API 從線上來源流式傳輸的資料中收集,也可以透過網路抓取或儲存在 Excel 或任何其他來源中的資料中收集。
從事這項工作的人應該瞭解不同可用資料集之間的區別以及組織如何投資其資料。專業人士發現很難跟蹤每條資料的來源以及它是否是最新的。在整個資料科學專案的生命週期中,跟蹤此資訊非常重要,因為它可以幫助檢驗假設或執行任何其他新實驗。
資訊可以透過調查收集,或者透過更普遍的自動化資料收集方法收集,例如網際網路 cookie,這是未經分析的資料的主要來源。
我們還可以使用二手資料,這是一個開源資料集。有很多網站可以收集資料,例如:
Kaggle (https://www.kaggle.com/datasets),
Google 公共資料集 (https://cloud.google.com/bigquery/public-data/)
Python 中有一些預定義的資料集。讓我們從 Python 中匯入 Iris 資料集,並使用它來定義資料科學的各個階段。
from sklearn.datasets import load_iris import pandas as pd # Load Data iris = load_iris() # Create a dataframe df = pd.DataFrame(iris.data, columns = iris.feature_names) df['target'] = iris.target X = iris.data
資料處理
從可靠的來源收集高質量資料後,下一步是處理它。資料處理的目的是確保獲取的資料是否存在任何問題,以便在進入下一階段之前可以解決這些問題。如果沒有這一步,我們可能會產生錯誤或不準確的發現。
獲取的資料可能存在若干問題。例如,資料在多行或多列中可能有多個缺失值。它可能包含多個異常值、不準確的數字、具有不同時區的 timestamps 等。資料可能存在日期範圍問題。在某些國家/地區,日期格式為 DD/MM/YYYY,而在其他國家/地區,則寫為 MM/DD/YYYY。在資料收集過程中,可能會出現許多問題,例如,如果資料是從多個溫度計收集的,並且任何一個溫度計都有缺陷,則可能需要丟棄或重新收集資料。
在此階段,必須解決資料中的各種問題。其中一些問題有多種解決方案,例如,如果資料包含缺失值,我們可以用零或列的平均值替換它們。但是,如果列缺少大量值,則最好完全刪除該列,因為它資料太少,無法在我們的資料科學生命週期方法中用於解決問題。
當時區全部混雜在一起時,我們無法使用這些列中的資料,可能必須刪除它們,直到我們可以定義提供的 timestamps 中使用的時區。如果我們知道收集每個 timestamp 的時區,我們可以將所有 timestamp 資料轉換為某個時區。這樣,有很多方法可以解決獲取的資料中可能存在的問題。
我們將訪問資料,然後使用 Python 將其儲存在資料框中。
from sklearn.datasets import load_iris import pandas as pd import numpy as np # Load Data iris = load_iris() # Create a dataframe df = pd.DataFrame(iris.data, columns = iris.feature_names) df['target'] = iris.target X = iris.data
所有資料都必須以數字表示形式用於機器學習模型。這意味著如果資料集包含分類資料,則必須將其轉換為數字值,然後才能執行模型。因此,我們將實現標籤編碼。
標籤編碼
species = []
for i in range(len(df['target'])):
if df['target'][i] == 0:
species.append("setosa")
elif df['target'][i] == 1:
species.append('versicolor')
else:
species.append('virginica')
df['species'] = species
labels = np.asarray(df.species)
df.sample(10)
labels = np.asarray(df.species)
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(labels)
labels = le.transform(labels)
df_selected1 = df.drop(['sepal length (cm)', 'sepal width (cm)', "species"], axis=1)
資料分析
資料分析探索性資料分析 (EDA) 是一組用於分析資料的視覺化技術。使用此方法,我們可以獲取有關資料統計摘要的具體詳細資訊。此外,我們將能夠處理重複數字、異常值並識別集合中的趨勢或模式。
在此階段,我們試圖更好地理解獲取和處理的資料。我們應用統計和分析技術來對資料得出結論,並確定資料集中多列之間的關係。使用圖片、圖表、曲線圖、繪圖等,我們可以使用視覺化來更好地理解和描述資料。
專業人員使用資料的統計技術(例如平均值和中位數)來更好地理解資料。他們還使用直方圖、頻譜分析和總體分佈來視覺化資料並評估其分佈模式。將根據問題分析資料。
示例
以下程式碼用於檢查資料集中是否存在任何空值:
df.isnull().sum()
輸出
sepal length (cm) 0 sepal width (cm) 0 petal length (cm) 0 petal width (cm) 0 target 0 species 0 dtype: int64
從以上輸出中,我們可以得出結論,資料集中沒有空值,因為列中所有空值的總和為 0。
我們將使用 shape 引數來檢查資料集的形狀(行、列):
示例
df.shape
輸出
(150, 5)
現在我們將使用 info() 來檢查列及其資料型別:
示例
df.info()
輸出
<class 'pandas.core.frame.DataFrame'> RangeIndex: 150 entries, 0 to 149 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sepal length (cm) 150 non-null float64 1 sepal width (cm) 150 non-null float64 2 petal length (cm) 150 non-null float64 3 petal width (cm) 150 non-null float64 4 target 150 non-null int64 dtypes: float64(4), int64(1) memory usage: 6.0 KB
只有一列包含類別資料,而其他列包含非空數值。
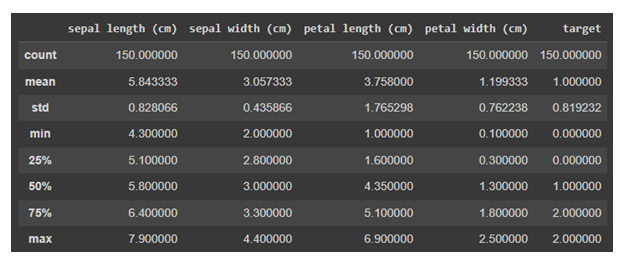
現在我們將對資料使用 describe()。describe() 方法對資料集執行基本統計計算,例如極值、資料點數、標準差等。任何缺失值或 NaN 值都會立即被忽略。describe() 方法準確地描述了資料的分佈。
示例
df.describe()
輸出
資料視覺化
目標列 - 我們的目標列將是 Species 列,因為我們最終只需要基於物種的結果。
Matplotlib 和 seaborn 庫將用於資料視覺化。
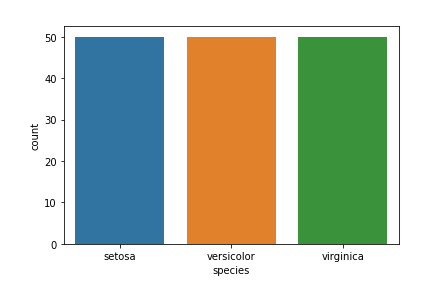
以下是物種計數圖:
示例
import seaborn as sns import matplotlib.pyplot as plt sns.countplot(x='species', data=df, ) plt.show()
輸出
資料科學中還有許多其他視覺化圖表。要了解更多資訊,請參考 https://tutorialspoint.tw/machine_learning_with_python
資料建模
資料建模是資料科學最重要的方面之一,有時也被稱為資料分析的核心。模型的預期輸出應源自準備和分析的資料。在實現指定標準之前,將選擇和構建執行資料模型所需的的環境。
在此階段,我們開發資料集以訓練和測試用於生產相關任務的模型。它還涉及選擇正確的模式型別並確定問題是否涉及分類、迴歸或聚類。分析模型型別後,我們必須選擇合適的實現演算法。必須謹慎執行此操作,因為它對於從提供的資料中提取相關見解至關重要。
這裡機器學習就派上用場了。機器學習基本上分為分類、迴歸或聚類模型,每個模型都有一些應用於資料集以獲取相關資訊的演算法。此階段使用這些模型。我們將在機器學習章節中詳細討論這些模型。
模型部署
我們已經到達資料科學生命週期的最後階段。在詳細的審查過程後,該模型終於可以以所需的格式和選擇的渠道部署。請注意,除非機器學習模型部署到生產環境中,否則它沒有任何用處。一般來說,這些模型與產品和應用程式相關聯並整合在一起。
模型部署包含建立必要的交付方法,以將模型部署到市場消費者或其他系統。機器學習模型也正在裝置上實施,並正在獲得認可和吸引力。根據專案的複雜程度,此階段可能從 Tableau 儀表板上的基本模型輸出到擁有數百萬使用者的複雜雲端部署。
誰參與資料科學生命週期?
從個人層面到組織層面,大量的資料正在生成、收集和儲存在海量的伺服器和資料倉庫中。但是,您將如何訪問這個龐大的資料儲存庫?這就是資料科學家發揮作用的地方,因為他是或她是一位從非結構化文字和統計資料中提取見解和模式的專家。
下面,我們介紹參與資料科學生命週期的多個數據科學團隊的職位簡介。
| 序號 | 職位和角色 |
|---|---|
| 1 | 業務分析師
瞭解業務需求並找到合適的目標客戶。 |
| 2 | 資料分析師
格式化和清理原始資料,解釋和視覺化它們以執行分析並提供相同的技術摘要。 |
| 3 | 資料科學家
提高機器學習模型的質量。 |
| 4 | 資料工程師
他們負責從社交網路、網站、部落格和其他內部和外部網路來源收集資料,以便進行進一步分析。 |
| 5 | 資料架構師
連線、集中、保護和維護組織的資料來源。 |
| 6 | 機器學習工程師
設計和實現與機器學習相關的演算法和應用。 |