- C++ 基礎
- C++ 首頁
- C++ 概述
- C++ 環境設定
- C++ 基本語法
- C++ 註釋
- C++ Hello World
- C++ 省略名稱空間
- C++ 常量/字面量
- C++ 關鍵字
- C++ 識別符號
- C++ 資料型別
- C++ 數值資料型別
- C++ 字元資料型別
- C++ 布林資料型別
- C++ 變數型別
- C++ 變數作用域
- C++ 多個變數
- C++ 基本輸入/輸出
- C++ 修飾符型別
- C++ 儲存類
- C++ 運算子
- C++ 數字
- C++ 列舉
- C++ 引用
- C++ 日期和時間
- C++ 控制語句
- C++ 決策
- C++ if 語句
- C++ if else 語句
- C++ 巢狀 if 語句
- C++ switch 語句
- C++ 巢狀 switch 語句
- C++ 迴圈型別
- C++ while 迴圈
- C++ for 迴圈
- C++ do while 迴圈
- C++ foreach 迴圈
- C++ 巢狀迴圈
- C++ break 語句
- C++ continue 語句
- C++ goto 語句
- C++ 建構函式
- C++ 建構函式和解構函式
- C++ 複製建構函式
- C++ 檔案處理
- C++ 檔案和流
- C++ 從檔案中讀取
C++ 快速指南
C++ 概述
C++ 是一種靜態型別的、編譯型的、通用的、區分大小寫的、自由格式的程式語言,支援程序式程式設計、面向物件程式設計和泛型程式設計。
C++ 被認為是一種中級語言,因為它結合了高階和低階語言的特性。
C++ 由 Bjarne Stroustrup 於 1979 年在位於新澤西州默裡山的貝爾實驗室開始開發,作為對 C 語言的增強,最初命名為“帶類的 C”,後來於 1983 年改名為 C++。
C++ 是 C 的超集,幾乎任何合法的 C 程式都是合法的 C++ 程式。
注意 − 當型別檢查在編譯時而不是執行時執行時,據說程式語言使用靜態型別。
面向物件程式設計
C++ 完全支援面向物件程式設計,包括面向物件開發的四個支柱:
- 封裝
- 資料隱藏
- 繼承
- 多型性
標準庫
標準 C++ 包含三個重要的部分:
核心語言,提供所有構建塊,包括變數、資料型別和字面量等。
C++ 標準庫,提供豐富的函式來操作檔案、字串等。
標準模板庫 (STL),提供豐富的用於操作資料結構的方法等。
ANSI 標準
ANSI 標準旨在確保 C++ 的可移植性;也就是說,你為 Microsoft 編譯器編寫的程式碼將在 Mac、UNIX、Windows 或 Alpha 上的編譯器上無需錯誤地進行編譯。
ANSI 標準已經穩定了一段時間,所有主要的 C++ 編譯器製造商都支援 ANSI 標準。
學習 C++
學習 C++ 最重要的事情是關注概念。
學習程式語言的目的是成為更好的程式設計師;也就是說,更有效地設計和實現新系統以及維護舊系統。
C++ 支援各種程式設計風格。你可以在任何語言中使用 Fortran、C、Smalltalk 等的風格進行編寫。每種風格都能有效地實現其目標,同時保持執行時和空間效率。
C++ 的用途
C++ 被數十萬程式設計師用於幾乎所有應用領域。
C++ 被廣泛用於編寫裝置驅動程式和其他依賴於在即時約束下直接操縱硬體的軟體。
C++ 廣泛用於教學和研究,因為它足夠清晰,可以成功地教授基本概念。
任何使用過 Apple Macintosh 或執行 Windows 的 PC 的人都間接地使用了 C++,因為這些系統的主要使用者介面是用 C++ 編寫的。
C++ 環境設定
本地環境設定
如果你仍然希望為 C++ 設定你的環境,你需要在你的計算機上安裝以下兩個軟體。
文字編輯器
這將用於鍵入你的程式。一些編輯器的例子包括 Windows 記事本、OS Edit 命令、Brief、Epsilon、EMACS 和 vim 或 vi。
文字編輯器的名稱和版本在不同的作業系統上可能會有所不同。例如,Windows 上將使用記事本,而 vim 或 vi 可以在 Windows、Linux 或 UNIX 上使用。
你用編輯器建立的檔案稱為原始檔,對於 C++,它們通常以 .cpp、.cp 或 .c 副檔名命名。
為了開始你的 C++ 程式設計,必須有一個文字編輯器。
C++ 編譯器
這是一個實際的 C++ 編譯器,它將用於將你的原始碼編譯成最終的可執行程式。
大多數 C++ 編譯器並不關心你給原始碼賦予什麼副檔名,但如果你沒有另外指定,許多編譯器預設使用 .cpp。
最常用且免費提供的編譯器是 GNU C/C++ 編譯器,或者如果你有相應的作業系統,你可以使用 HP 或 Solaris 的編譯器。
安裝 GNU C/C++ 編譯器
UNIX/Linux 安裝
如果你使用的是Linux 或 UNIX,請透過從命令列輸入以下命令來檢查你的系統上是否安裝了 GCC:
$ g++ -v
如果你安裝了 GCC,它應該列印類似以下的訊息:
Using built-in specs. Target: i386-redhat-linux Configured with: ../configure --prefix=/usr ....... Thread model: posix gcc version 4.1.2 20080704 (Red Hat 4.1.2-46)
如果未安裝 GCC,則需要使用https://gcc.gnu.org/install/提供的詳細說明自行安裝。
Mac OS X 安裝
如果你使用 Mac OS X,獲取 GCC 的最簡單方法是從 Apple 的網站下載 Xcode 開發環境,並按照簡單的安裝說明進行操作。
Xcode 目前可在developer.apple.com/technologies/tools/獲取。
Windows 安裝
要在 Windows 上安裝 GCC,你需要安裝 MinGW。要安裝 MinGW,請訪問 MinGW 主頁 www.mingw.org,然後點選連結進入 MinGW 下載頁面。下載最新版本的 MinGW 安裝程式,其名稱應為 MinGW-<version>.exe。
安裝 MinGW 時,至少必須安裝 gcc-core、gcc-g++、binutils 和 MinGW 執行時,但你可能希望安裝更多。
將 MinGW 安裝的 bin 子目錄新增到你的PATH環境變數中,以便你可以透過簡單的名稱在命令列中指定這些工具。
安裝完成後,你將能夠從 Windows 命令列執行 gcc、g++、ar、ranlib、dlltool 和其他幾個 GNU 工具。
C++ 基本語法
當我們考慮一個 C++ 程式時,它可以定義為透過呼叫彼此的方法進行通訊的物件的集合。現在讓我們簡要地瞭解一下類、物件、方法和例項變數的含義。
物件 − 物件具有狀態和行為。例如:一隻狗具有狀態——顏色、名字、品種以及行為——搖尾、吠叫、吃東西。物件是類的例項。
類 − 類可以定義為一個模板/藍圖,它描述了其型別物件支援的行為/狀態。
方法 − 方法基本上是一種行為。一個類可以包含許多方法。在方法中編寫邏輯、操作資料和執行所有操作。
例項變數 − 每個物件都有自己唯一的一組例項變數。物件的 state 是透過賦予這些例項變數的值來建立的。
C++ 程式結構
讓我們來看一個簡單的程式碼,它將列印單詞“Hello World”。
#include <iostream>
using namespace std;
// main() is where program execution begins.
int main() {
cout << "Hello World"; // prints Hello World
return 0;
}
讓我們看看上面程式的各個部分:
C++ 語言定義了幾個標頭檔案,其中包含對你的程式來說是必需的或有用的資訊。對於此程式,需要標頭檔案<iostream>。
using namespace std; 這行程式碼告訴編譯器使用 std 名稱空間。名稱空間是 C++ 中相對較新的新增。
下一行 '// main() is where program execution begins.' 是 C++ 中提供的單行註釋。單行註釋以 // 開頭,在行尾結束。
int main() 這行程式碼是主函式,程式執行從此處開始。
下一行cout << "Hello World"; 將訊息“Hello World”顯示在螢幕上。
下一行return 0; 終止 main() 函式並使其向呼叫程序返回值 0。
編譯和執行 C++ 程式
讓我們看看如何儲存檔案、編譯和執行程式。請按照以下步驟操作:
開啟文字編輯器並新增上述程式碼。
將檔案儲存為:hello.cpp
開啟命令提示符並轉到儲存檔案的目錄。
鍵入“g++ hello.cpp”並按 Enter 鍵編譯你的程式碼。如果你的程式碼中沒有錯誤,命令提示符將帶你到下一行,並生成 a.out 可執行檔案。
現在,鍵入“a.out”執行你的程式。
你將看到視窗上列印“Hello World”。
$ g++ hello.cpp $ ./a.out Hello World
確保 g++ 位於你的路徑中,並且你正在包含檔案 hello.cpp 的目錄中執行它。
你可以使用 makefile 編譯 C/C++ 程式。更多詳情,請檢視我們的“Makefile 教程”。
C++ 中的分號和塊
在 C++ 中,分號是語句終止符。也就是說,每個單獨的語句都必須以分號結尾。它表示一個邏輯實體的結束。
例如,以下是三個不同的語句:
x = y; y = y + 1; add(x, y);
塊是一組邏輯上連線的語句,它們被大括號包圍。例如:
{
cout << "Hello World"; // prints Hello World
return 0;
}
C++ 不識別行尾作為終止符。因此,你在一行中放置語句的位置無關緊要。例如:
x = y; y = y + 1; add(x, y);
與以下相同
x = y; y = y + 1; add(x, y);
C++ 識別符號
C++識別符號是用於標識變數、函式、類、模組或任何其他使用者定義項的名稱。識別符號以字母A到Z或a到z或下劃線(_)開頭,後跟零個或多個字母、下劃線和數字(0到9)。
C++不允許在識別符號中使用@、$和%等標點符號。C++是一種區分大小寫的程式語言。因此,Manpower和manpower在C++中是兩個不同的識別符號。
以下是一些可接受的識別符號示例:
mohd zara abc move_name a_123 myname50 _temp j a23b9 retVal
C++ 關鍵字
以下列表顯示了C++中的保留字。這些保留字不能用作常量或變數或任何其他識別符號名稱。
| asm | else | new | this |
| auto | enum | operator | throw |
| bool | explicit | private | true |
| break | export | protected | try |
| case | extern | public | typedef |
| catch | false | register | typeid |
| char | float | reinterpret_cast | typename |
| class | for | return | union |
| const | friend | short | unsigned |
| const_cast | goto | signed | using |
| continue | if | sizeof | virtual |
| default | inline | static | void |
| delete | int | static_cast | volatile |
| do | long | struct | wchar_t |
| double | mutable | switch | while |
| dynamic_cast | namespace | template |
三元組
一些字元具有另一種表示形式,稱為三元組序列。三元組是一個三字元序列,代表單個字元,該序列總是以兩個問號開頭。
三元組在其出現的任何位置都被擴充套件,包括字串文字和字元文字、註釋和預處理器指令中。
以下是最常用的三元組序列:
| 三元組 | 替換字元 |
|---|---|
| ??= | # |
| ??/ | \ |
| ??' | ^ |
| ??( | [ |
| ??) | ] |
| ??! | | |
| ??< | { |
| ??> | } |
| ??- | ~ |
並非所有編譯器都支援三元組,並且由於其混淆性,建議不要使用它們。
C++中的空白字元
僅包含空白字元(可能帶有註釋)的行稱為空行,C++編譯器會完全忽略它。
空白字元是C++中用來描述空格、製表符、換行符和註釋的術語。空白字元將語句的一個部分與另一個部分分開,並使編譯器能夠識別語句中一個元素(例如int)的結束位置和下一個元素的開始位置。
語句 1
int age;
在上述語句中,int和age之間必須至少有一個空白字元(通常是空格),才能使編譯器能夠區分它們。
語句 2
fruit = apples + oranges; // Get the total fruit
在上述語句2中,fruit和=之間,或=和apples之間不需要空白字元,儘管您可以根據可讀性需要包含一些空白字元。
C++中的註釋
程式註釋是可以包含在C++程式碼中的解釋性語句。這些註釋有助於任何閱讀原始碼的人。所有程式語言都允許某種形式的註釋。
C++支援單行和多行註釋。C++編譯器會忽略任何註釋中包含的所有字元。
C++註釋以/*開頭,以*/結尾。例如:
/* This is a comment */ /* C++ comments can also * span multiple lines */
註釋也可以以//開頭,一直延伸到行尾。例如:
#include <iostream>
using namespace std;
main() {
cout << "Hello World"; // prints Hello World
return 0;
}
編譯上述程式碼時,它將忽略// prints Hello World,最終的可執行檔案將產生以下結果:
Hello World
在/*和*/註釋中,//字元沒有任何特殊含義。在//註釋中,/*和*/沒有任何特殊含義。因此,您可以將一種註釋“巢狀”在另一種註釋中。例如:
/* Comment out printing of Hello World: cout << "Hello World"; // prints Hello World */
C++ 資料型別
在任何語言中編寫程式時,都需要使用各種變數來儲存各種資訊。變數只不過是保留的記憶體位置,用於儲存值。這意味著當您建立變數時,您會在記憶體中保留一些空間。
您可能希望儲存各種資料型別的資訊,例如字元、寬字元、整數、浮點數、雙精度浮點數、布林值等。根據變數的資料型別,作業系統分配記憶體並決定可以在保留的記憶體中儲存什麼。
基本內建型別
C++為程式設計師提供了豐富的內建和使用者定義資料型別。下表列出了七種基本C++資料型別:
| 型別 | 關鍵字 |
|---|---|
| 布林型 | bool |
| 字元型 | char |
| 整型 | int |
| 浮點型 | float |
| 雙精度浮點型 | double |
| 空值型 | void |
| 寬字元型 | wchar_t |
可以使用一個或多個型別修飾符修改幾種基本型別:
- signed
- unsigned
- short
- long
下表顯示了變數型別、儲存值所需的記憶體大小以及可以在此類變數中儲存的最大值和最小值。
| 型別 | 典型位寬 | 典型範圍 |
|---|---|---|
| char | 1位元組 | -127到127或0到255 |
| unsigned char | 1位元組 | 0到255 |
| signed char | 1位元組 | -127到127 |
| int | 4位元組 | -2147483648到2147483647 |
| unsigned int | 4位元組 | 0到4294967295 |
| signed int | 4位元組 | -2147483648到2147483647 |
| short int | 2位元組 | -32768到32767 |
| unsigned short int | 2位元組 | 0到65,535 |
| signed short int | 2位元組 | -32768到32767 |
| long int | 8位元組 | -2,147,483,648到2,147,483,647 |
| signed long int | 8位元組 | 與long int相同 |
| unsigned long int | 8位元組 | 0到4,294,967,295 |
| long long int | 8位元組 | -(2^63)到(2^63)-1 |
| unsigned long long int | 8位元組 | 0到18,446,744,073,709,551,615 |
| float | 4位元組 | |
| double | 8位元組 | |
| long double | 12位元組 | |
| wchar_t | 2或4位元組 | 1個寬字元 |
變數的大小可能與上表中顯示的大小不同,具體取決於您使用的編譯器和計算機。
以下是示例,它將生成您計算機上各種資料型別的正確大小。
#include <iostream>
using namespace std;
int main() {
cout << "Size of char : " << sizeof(char) << endl;
cout << "Size of int : " << sizeof(int) << endl;
cout << "Size of short int : " << sizeof(short int) << endl;
cout << "Size of long int : " << sizeof(long int) << endl;
cout << "Size of float : " << sizeof(float) << endl;
cout << "Size of double : " << sizeof(double) << endl;
cout << "Size of wchar_t : " << sizeof(wchar_t) << endl;
return 0;
}
此示例使用endl,它在每一行之後插入一個換行符,並使用<<運算子將多個值輸出到螢幕。我們還使用sizeof()運算子來獲取各種資料型別的大小。
編譯並執行上述程式碼後,將產生以下結果,該結果可能因機器而異:
Size of char : 1 Size of int : 4 Size of short int : 2 Size of long int : 4 Size of float : 4 Size of double : 8 Size of wchar_t : 4
typedef宣告
您可以使用typedef為現有型別建立一個新名稱。以下是使用typedef定義新型別的簡單語法:
typedef type newname;
例如,以下程式碼告訴編譯器feet是int的另一個名稱:
typedef int feet;
現在,以下宣告是完全合法的,並建立一個名為distance的整型變數:
feet distance;
列舉型別
列舉型別宣告一個可選的型別名稱和一組零個或多個可作為型別值的識別符號。每個列舉器都是一個常量,其型別為列舉。
建立列舉需要使用關鍵字enum。列舉型別的通用形式如下:
enum enum-name { list of names } var-list;
這裡,enum-name是列舉的型別名稱。名稱列表用逗號分隔。
例如,以下程式碼定義了一個名為colors的顏色的列舉和color型別的變數c。最後,將c賦值為“blue”。
enum color { red, green, blue } c;
c = blue;
預設情況下,第一個名稱的值為0,第二個名稱的值為1,第三個名稱的值為2,依此類推。但是,您可以透過新增初始化程式為名稱指定特定值。例如,在以下列舉中,green的值將為5。
enum color { red, green = 5, blue };
這裡,blue的值將為6,因為每個名稱都比其前面的名稱大1。
C++ 變數型別
變數為我們提供了程式可以操作的命名儲存。C++中的每個變數都有一個特定型別,該型別決定變數記憶體的大小和佈局;可以儲存在該記憶體中的值的範圍;以及可以應用於變數的操作集。
變數的名稱可以由字母、數字和下劃線組成。它必須以字母或下劃線開頭。大寫字母和小寫字母是不同的,因為C++區分大小寫:
C++中存在以下基本型別的變數,如上一章所述:
| 序號 | 型別和描述 |
|---|---|
| 1 | bool 儲存true或false值。 |
| 2 | char 通常是一個八位位元組(一個位元組)。這是一個整型。 |
| 3 | int 機器中最自然的整數大小。 |
| 4 | float 單精度浮點值。 |
| 5 | double 雙精度浮點值。 |
| 6 | void 表示型別的缺失。 |
| 7 | wchar_t 寬字元型別。 |
C++還允許定義各種其他型別的變數,我們將在後續章節中介紹,例如列舉、指標、陣列、引用、資料結構和類。
下一節將介紹如何定義、宣告和使用各種型別的變數。
C++中的變數定義
變數定義告訴編譯器在哪裡以及為變數建立多少儲存空間。變數定義指定資料型別,幷包含一個或多個該型別變數的列表,如下所示:
type variable_list;
這裡,type必須是有效的C++資料型別,包括char、w_char、int、float、double、bool或任何使用者定義的物件等,而variable_list可以包含一個或多個用逗號分隔的識別符號名稱。這裡顯示了一些有效的宣告:
int i, j, k; char c, ch; float f, salary; double d;
int i, j, k;這一行宣告並定義了變數i、j和k;它指示編譯器建立名為i、j和k的int型別變數。
可以在變數宣告中初始化(賦值初始值)變數。初始化程式由等號後跟一個常量表達式組成,如下所示:
type variable_name = value;
一些例子:
extern int d = 3, f = 5; // declaration of d and f. int d = 3, f = 5; // definition and initializing d and f. byte z = 22; // definition and initializes z. char x = 'x'; // the variable x has the value 'x'.
對於沒有初始化器的定義:具有靜態儲存期的變數會隱式初始化為 NULL(所有位元組的值都為 0);所有其他變數的初始值未定義。
C++ 中的變數宣告
變數宣告向編譯器保證存在一個具有給定型別和名稱的變數,以便編譯器繼續進行編譯,而無需關於變數的完整細節。變數宣告只在編譯時有意義,編譯器在程式連結時需要實際的變數定義。
當您使用多個檔案並將變數定義在一個檔案中(該檔案將在程式連結時可用)時,變數宣告非常有用。您將使用extern關鍵字在任何地方宣告變數。儘管您可以在 C++ 程式中多次宣告變數,但它只能在一個檔案中、一個函式中或一段程式碼塊中定義一次。
示例
嘗試以下示例,其中變數已在頂部宣告,但已在 main 函式內定義:
#include <iostream>
using namespace std;
// Variable declaration:
extern int a, b;
extern int c;
extern float f;
int main () {
// Variable definition:
int a, b;
int c;
float f;
// actual initialization
a = 10;
b = 20;
c = a + b;
cout << c << endl ;
f = 70.0/3.0;
cout << f << endl ;
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
30 23.3333
相同的概念也適用於函式宣告,您在函式宣告時提供函式名稱,其實際定義可以在其他任何地方給出。例如:
// function declaration
int func();
int main() {
// function call
int i = func();
}
// function definition
int func() {
return 0;
}
左值和右值
C++ 中有兩種表示式:
左值 - 指向記憶體位置的表示式稱為“左值”表示式。左值可以作為賦值的左側或右側出現。
右值 - 右值指的是儲存在記憶體某個地址處的資料值。右值是一個不能為其賦值的表示式,這意味著右值可以出現在賦值的右側,但不能出現在左側。
變數是左值,因此可以出現在賦值的左側。數字字面值是右值,因此不能賦值,也不能出現在左側。以下是有效的語句:
int g = 20;
但以下語句無效,會產生編譯時錯誤:
10 = 20;
C++ 中的變數作用域
作用域是程式的一個區域,廣義地說,變數可以在三個地方宣告:
在函式或程式碼塊內,稱為區域性變數;
在函式引數定義中,稱為形式引數;
在所有函式之外,稱為全域性變數;
我們將在後續章節中學習什麼是函式及其引數。這裡讓我們解釋一下區域性變數和全域性變數。
區域性變數
在函式或程式碼塊內部宣告的變數是區域性變數。只有函式或程式碼塊內部的語句才能使用它們。外部函式不知道區域性變數。以下是使用區域性變數的示例:
#include <iostream>
using namespace std;
int main () {
// Local variable declaration:
int a, b;
int c;
// actual initialization
a = 10;
b = 20;
c = a + b;
cout << c;
return 0;
}
全域性變數
全域性變數定義在所有函式之外,通常位於程式頂部。全域性變數將在程式的整個生命週期內保持其值。
任何函式都可以訪問全域性變數。也就是說,全域性變數在其聲明後可在整個程式中使用。以下是使用全域性變數和區域性變數的示例:
#include <iostream>
using namespace std;
// Global variable declaration:
int g;
int main () {
// Local variable declaration:
int a, b;
// actual initialization
a = 10;
b = 20;
g = a + b;
cout << g;
return 0;
}
程式可以為區域性變數和全域性變數使用相同的名稱,但函式內部區域性變數的值將優先。例如:
#include <iostream>
using namespace std;
// Global variable declaration:
int g = 20;
int main () {
// Local variable declaration:
int g = 10;
cout << g;
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
10
區域性變數和全域性變數的初始化
定義區域性變數時,系統不會對其進行初始化,您必須自行初始化。全域性變數在您按如下方式定義它們時會由系統自動初始化:
| 資料型別 | 初始化器 |
|---|---|
| int | 0 |
| char | '\0' |
| float | 0 |
| double | 0 |
| 指標 | NULL |
正確初始化變數是一個良好的程式設計習慣,否則有時程式會產生意想不到的結果。
C++ 常量/字面量
常量是指程式可能不會更改的固定值,它們稱為字面量。
常量可以是任何基本資料型別,可以分為整數字面量、浮點字面量、字元、字串和布林值。
同樣,常量與普通變數一樣,只是它們的值在定義後不能修改。
整數字面量
整數字面量可以是十進位制、八進位制或十六進位制常量。字首指定基數或基:十六進位制為 0x 或 0X,八進位制為 0,十進位制為無。
整數字面量還可以帶字尾,該字尾是 U 和 L 的組合,分別表示無符號和長整型。字尾可以是大寫或小寫,並且可以按任意順序排列。
以下是一些整數字面量的示例:
212 // Legal 215u // Legal 0xFeeL // Legal 078 // Illegal: 8 is not an octal digit 032UU // Illegal: cannot repeat a suffix
以下是各種型別整數字面量的其他示例:
85 // decimal 0213 // octal 0x4b // hexadecimal 30 // int 30u // unsigned int 30l // long 30ul // unsigned long
浮點字面量
浮點字面量具有整數部分、小數點、小數部分和指數部分。您可以使用十進位制形式或指數形式表示浮點字面量。
使用十進位制形式表示時,必須包含小數點、指數或兩者兼有;使用指數形式表示時,必須包含整數部分、小數部分或兩者兼有。帶符號的指數由 e 或 E 引入。
以下是一些浮點字面量的示例:
3.14159 // Legal 314159E-5L // Legal 510E // Illegal: incomplete exponent 210f // Illegal: no decimal or exponent .e55 // Illegal: missing integer or fraction
布林字面量
有兩個布林字面量,它們是標準 C++ 關鍵字的一部分:
值為true表示真。
值為false表示假。
不應將 true 的值視為 1,將 false 的值視為 0。
字元字面量
字元字面量用單引號括起來。如果字面量以 L(僅大寫)開頭,則它是寬字元字面量(例如,L'x'),應儲存在wchar_t型別的變數中。否則,它是窄字元字面量(例如,'x'),可以儲存在char型別的簡單變數中。
字元字面量可以是普通字元(例如,'x')、轉義序列(例如,'\t')或通用字元(例如,'\u02C0')。
在 C++ 中,某些字元在前面加上反斜槓時具有特殊含義,它們用於表示換行符(\n)或製表符(\t)。這裡列出了一些這樣的轉義序列程式碼:
| 轉義序列 | 含義 |
|---|---|
| \\ | \ 字元 |
| \' | ' 字元 |
| \" | " 字元 |
| \? | ? 字元 |
| \a | 警告或鈴聲 |
| \b | 退格 |
| \f | 換頁 |
| \n | 換行 |
| \r | 回車 |
| \t | 水平製表符 |
| \v | 垂直製表符 |
| \ooo | 一位到三位八進位制數 |
| \xhh . . . | 一位或多位十六進位制數 |
以下示例顯示了一些轉義序列字元:
#include <iostream>
using namespace std;
int main() {
cout << "Hello\tWorld\n\n";
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Hello World
字串字面量
字串字面量用雙引號括起來。字串包含與字元字面量相似的字元:普通字元、轉義序列和通用字元。
您可以使用字串字面量將長行分成多行,並使用空格分隔它們。
以下是一些字串字面量的示例。所有三種形式都是相同的字串。
"hello, dear" "hello, \ dear" "hello, " "d" "ear"
定義常量
在 C++ 中定義常量有兩種簡單的方法:
使用#define預處理器。
使用const關鍵字。
#define 預處理器
以下是使用 #define 預處理器定義常量的形式:
#define identifier value
以下示例詳細解釋了它:
#include <iostream>
using namespace std;
#define LENGTH 10
#define WIDTH 5
#define NEWLINE '\n'
int main() {
int area;
area = LENGTH * WIDTH;
cout << area;
cout << NEWLINE;
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
50
const 關鍵字
您可以使用const字首以特定的型別宣告常量,如下所示:
const type variable = value;
以下示例詳細解釋了它:
#include <iostream>
using namespace std;
int main() {
const int LENGTH = 10;
const int WIDTH = 5;
const char NEWLINE = '\n';
int area;
area = LENGTH * WIDTH;
cout << area;
cout << NEWLINE;
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
50
請注意,良好的程式設計習慣是用大寫字母定義常量。
C++ 修飾符型別
C++ 允許char、int和double資料型別在其前面有修飾符。修飾符用於更改基本型別的含義,使其更精確地適應各種情況的需求。
資料型別修飾符列於此處:
- signed
- unsigned
- long
- short
修飾符signed、unsigned、long和short可以應用於整數基本型別。此外,signed和unsigned可以應用於 char,long可以應用於 double。
修飾符signed和unsigned也可以用作long或short修飾符的字首。例如,unsigned long int。
C++ 允許使用簡寫法宣告unsigned、short或long整數。您可以簡單地使用unsigned、short或long,而無需int。它會自動暗示int。例如,以下兩個語句都聲明瞭無符號整數變數。
unsigned x; unsigned int y;
要了解 C++ 解釋帶符號和無符號整數修飾符的方式之間的區別,您應該執行以下簡短程式:
#include <iostream>
using namespace std;
/* This program shows the difference between
* signed and unsigned integers.
*/
int main() {
short int i; // a signed short integer
short unsigned int j; // an unsigned short integer
j = 50000;
i = j;
cout << i << " " << j;
return 0;
}
執行此程式時,輸出如下:
-15536 50000
上述結果是由於表示 50,000 作為短無符號整數的位模式被 short 解釋為 -15,536。
C++ 中的型別限定符
型別限定符提供有關它們前面的變數的附加資訊。
| 序號 | 限定符和含義 |
|---|---|
| 1 | const 程式在執行期間無法更改const型別的物件。 |
| 2 | volatile 修飾符volatile告訴編譯器變數的值可能會以程式未明確指定的方式更改。 |
| 3 | restrict 由restrict限定的指標最初是訪問其指向的物件的唯一方法。只有 C99 添加了一個名為 restrict 的新型別限定符。 |
C++ 中的儲存類
儲存類定義 C++ 程式中變數和/或函式的作用域(可見性)和生命週期。這些說明符位於它們修改的型別之前。C++ 程式中可以使用以下儲存類
- auto
- register
- static
- extern
- mutable
auto 儲存類
auto儲存類是所有區域性變數的預設儲存類。
{
int mount;
auto int month;
}
上面的示例定義了兩個具有相同儲存類的變數,auto 只能在函式內使用,即區域性變數。
register 儲存類
register儲存類用於定義應儲存在暫存器而不是 RAM 中的區域性變數。這意味著變數的最大大小等於暫存器大小(通常是一個字),並且不能對其應用一元 '&' 運算子(因為它沒有記憶體位置)。
{
register int miles;
}
register 應該僅用於需要快速訪問的變數,例如計數器。還應注意,定義 'register' 並不意味著變數將儲存在暫存器中。這意味著它可能會儲存在暫存器中,具體取決於硬體和實現限制。
static 儲存類
static儲存類指示編譯器在程式的生命週期內保持區域性變數的存在,而不是在每次進入和退出作用域時建立和銷燬它。因此,使區域性變數靜態允許它們在函式呼叫之間保持其值。
static 修飾符也可以應用於全域性變數。當這樣做時,它會導致該變數的作用域限制在其宣告的檔案中。
在 C++ 中,當在類資料成員上使用 static 時,它只導致一個副本由其類的所有物件共享。
#include <iostream>
// Function declaration
void func(void);
static int count = 10; /* Global variable */
main() {
while(count--) {
func();
}
return 0;
}
// Function definition
void func( void ) {
static int i = 5; // local static variable
i++;
std::cout << "i is " << i ;
std::cout << " and count is " << count << std::endl;
}
編譯並執行上述程式碼時,會產生以下結果:
i is 6 and count is 9 i is 7 and count is 8 i is 8 and count is 7 i is 9 and count is 6 i is 10 and count is 5 i is 11 and count is 4 i is 12 and count is 3 i is 13 and count is 2 i is 14 and count is 1 i is 15 and count is 0
extern 儲存類
extern儲存類用於引用對所有程式檔案可見的全域性變數。當您使用 'extern' 時,不能初始化變數,因為它只是將變數名指向先前定義的儲存位置。
當您有多個檔案並定義了一個全域性變數或函式,而這些變數或函式也將在其他檔案中使用時,則需要在另一個檔案中使用extern來引用已定義的變數或函式。簡單來說,extern用於在另一個檔案中宣告全域性變數或函式。
正如以下解釋,當兩個或多個檔案共享相同的全域性變數或函式時,extern 修飾符最常用。
第一個檔案:main.cpp
#include <iostream>
int count ;
extern void write_extern();
main() {
count = 5;
write_extern();
}
第二個檔案:support.cpp
#include <iostream>
extern int count;
void write_extern(void) {
std::cout << "Count is " << count << std::endl;
}
這裡,extern關鍵字用於在另一個檔案中宣告count。現在編譯這兩個檔案,方法如下:
$g++ main.cpp support.cpp -o write
這將生成write可執行程式,嘗試執行write並檢查結果如下:
$./write 5
可變儲存類
mutable說明符僅適用於類物件(本教程稍後會討論)。它允許物件的成員覆蓋const成員函式。也就是說,const成員函式可以修改mutable成員。
C++中的運算子
運算子是一個符號,它告訴編譯器執行特定的數學或邏輯運算。C++ 擁有豐富的內建運算子,並提供以下型別的運算子:
- 算術運算子
- 關係運算符
- 邏輯運算子
- 位運算子
- 賦值運算子
- 其他運算子
本章將逐一考察算術、關係、邏輯、位、賦值和其他運算子。
算術運算子
C++語言支援以下算術運算子:
假設變數A的值為10,變數B的值為20,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| + | 將兩個運算元相加 | A + B 將得到 30 |
| - | 從第一個運算元中減去第二個運算元 | A - B 將得到 -10 |
| * | 將兩個運算元相乘 | A * B 將得到 200 |
| / | 將分子除以分母 | B / A 將得到 2 |
| % | 模運算子,返回整數除法後的餘數 | B % A 將得到 0 |
| ++ | 自增運算子,將整數值增加一 | A++ 將得到 11 |
| -- | 自減運算子,將整數值減少一 | A-- 將得到 9 |
關係運算符
C++語言支援以下關係運算符:
假設變數A的值為10,變數B的值為20,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| == | 檢查兩個運算元的值是否相等,如果相等則條件為真。 | (A == B) 為假。 |
| != | 檢查兩個運算元的值是否不相等,如果不相等則條件為真。 | (A != B) 為真。 |
| > | 檢查左運算元的值是否大於右運算元的值,如果是則條件為真。 | (A > B) 為假。 |
| < | 檢查左運算元的值是否小於右運算元的值,如果是則條件為真。 | (A < B) 為真。 |
| >= | 檢查左運算元的值是否大於或等於右運算元的值,如果是則條件為真。 | (A >= B) 為假。 |
| <= | 檢查左運算元的值是否小於或等於右運算元的值,如果是則條件為真。 | (A <= B) 為真。 |
邏輯運算子
C++語言支援以下邏輯運算子。
假設變數A的值為1,變數B的值為0,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| && | 稱為邏輯與運算子。如果兩個運算元都非零,則條件為真。 | (A && B) 為假。 |
| || | 稱為邏輯或運算子。如果兩個運算元中任何一個非零,則條件為真。 | (A || B) 為真。 |
| ! | 稱為邏輯非運算子。用於反轉其運算元的邏輯狀態。如果一個條件為真,則邏輯非運算子將使其為假。 | !(A && B) 為真。 |
位運算子
位運算子作用於位並執行逐位運算。&,| 和 ^ 的真值表如下:
| p | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
假設 A = 60;B = 13;現在它們的二進位制格式如下:
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A|B = 0011 1101
A^B = 0011 0001
~A = 1100 0011
C++語言支援的位運算子列在下面的表格中。假設變數A的值為60,變數B的值為13,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| & | 二進位制與運算子:如果位同時存在於兩個運算元中,則將其複製到結果中。 | (A & B) 將得到 12,即 0000 1100 |
| | | 二進位制或運算子:如果位存在於任一運算元中,則將其複製。 | (A | B) 將得到 61,即 0011 1101 |
| ^ | 二進位制異或運算子:如果位在一個運算元中設定,但在另一個運算元中未設定,則將其複製。 | (A ^ B) 將得到 49,即 0011 0001 |
| ~ | 二進位制反碼運算子:是一元運算子,其作用是“翻轉”位。 | (~A ) 將得到 -61,由於是帶符號二進位制數,因此以二進位制補碼形式表示為 1100 0011。 |
| << | 二進位制左移運算子:左運算元的值向左移動由右運算元指定的位數。 | A << 2 將得到 240,即 1111 0000 |
| >> | 二進位制右移運算子:左運算元的值向右移動由右運算元指定的位數。 | A >> 2 將得到 15,即 0000 1111 |
賦值運算子
C++語言支援以下賦值運算子:
| 運算子 | 描述 | 示例 |
|---|---|---|
| = | 簡單賦值運算子:將右運算元的值賦給左運算元。 | C = A + B 將 A + B 的值賦給 C |
| += | 加法賦值運算子:將右運算元加到左運算元上,並將結果賦給左運算元。 | C += A 等效於 C = C + A |
| -= | 減法賦值運算子:從左運算元中減去右運算元,並將結果賦給左運算元。 | C -= A 等效於 C = C - A |
| *= | 乘法賦值運算子:將右運算元乘以左運算元,並將結果賦給左運算元。 | C *= A 等效於 C = C * A |
| /= | 除法賦值運算子:將左運算元除以右運算元,並將結果賦給左運算元。 | C /= A 等效於 C = C / A |
| %= | 模賦值運算子:使用兩個運算元取模,並將結果賦給左運算元。 | C %= A 等效於 C = C % A |
| <<= | 左移賦值運算子。 | C <<= 2 與 C = C << 2 相同 |
| >>= | 右移賦值運算子。 | C >>= 2 與 C = C >> 2 相同 |
| &= | 位與賦值運算子。 | C &= 2 與 C = C & 2 相同 |
| ^= | 位異或賦值運算子。 | C ^= 2 與 C = C ^ 2 相同 |
| |= | 位或賦值運算子。 | C |= 2 與 C = C | 2 相同 |
其他運算子
下表列出了 C++ 支援的其他一些運算子。
| 序號 | 運算子 & 描述 |
|---|---|
| 1 | sizeof sizeof 運算子 返回變數的大小。例如,sizeof(a),其中 'a' 是整數,將返回 4。 |
| 2 | Condition ? X : Y 條件運算子 (?)。如果 Condition 為真,則返回 X 的值,否則返回 Y 的值。 |
| 3 | , 逗號運算子 導致執行一系列操作。整個逗號表示式的值是逗號分隔列表中最後一個表示式的值。 |
| 4 | .(點) 和 ->(箭頭) 成員運算子 用於引用類、結構體和聯合體的各個成員。 |
| 5 | 型別轉換 型別轉換運算子 將一種資料型別轉換為另一種資料型別。例如,int(2.2000) 將返回 2。 |
| 6 | & 地址運算子 & 返回變數的地址。例如 &a; 將給出變數的實際地址。 |
| 7 | * 指標運算子 * 指向一個變數。例如 *var; 將指向變數 var。 |
C++ 中的運算子優先順序
運算子優先順序決定了表示式中項的分組方式。這會影響表示式的計算方式。某些運算子的優先順序高於其他運算子;例如,乘法運算子的優先順序高於加法運算子:
例如 x = 7 + 3 * 2; 這裡,x 被賦值為 13,而不是 20,因為運算子 * 的優先順序高於 +,所以它首先與 3*2 相乘,然後加到 7 中。
這裡,優先順序最高的運算子出現在表的上方,優先順序最低的運算子出現在表的下方。在一個表示式中,優先順序較高的運算子將首先計算。
| 類別 | 運算子 | 結合性 |
|---|---|---|
| 字尾 | () [] -> . ++ -- | 從左到右 |
| 一元 | + - ! ~ ++ -- (type)* & sizeof | 從右到左 |
| 乘法 | * / % | 從左到右 |
| 加法 | + - | 從左到右 |
| 移位 | << >> | 從左到右 |
| 關係 | < <= > >= | 從左到右 |
| 相等 | == != | 從左到右 |
| 位與 | & | 從左到右 |
| 位異或 | ^ | 從左到右 |
| 位或 | | | 從左到右 |
| 邏輯與 | && | 從左到右 |
| 邏輯或 | || | 從左到右 |
| 條件 | ?: | 從右到左 |
| 賦值 | = += -= *= /= %= >>= <<= &= ^= |= | 從右到左 |
| 逗號 | , | 從左到右 |
C++ 迴圈型別
可能會有這樣的情況,您需要多次執行一段程式碼。通常情況下,語句是順序執行的:函式中的第一個語句首先執行,然後是第二個語句,依此類推。
程式語言提供各種控制結構,允許更復雜的執行路徑。
迴圈語句允許我們多次執行一條語句或一組語句,以下是大多數程式語言中迴圈語句的一般形式:
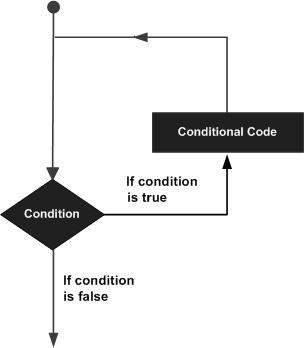
C++程式語言提供以下型別的迴圈來處理迴圈需求。
| 序號 | 迴圈型別 & 描述 |
|---|---|
| 1 | while迴圈
當給定條件為真時,重複執行一條語句或一組語句。它在執行迴圈體之前測試條件。 |
| 2 | for迴圈
多次執行一系列語句,並縮寫管理迴圈變數的程式碼。 |
| 3 | do...while迴圈
類似於‘while’語句,但它在迴圈體結束時測試條件。 |
| 4 | 巢狀迴圈
您可以在任何其他‘while’、‘for’或‘do..while’迴圈內使用一個或多個迴圈。 |
迴圈控制語句
迴圈控制語句改變其正常的執行順序。當執行離開一個作用域時,在該作用域中建立的所有自動物件都被銷燬。
C++支援以下控制語句。
| 序號 | 控制語句 & 描述 |
|---|---|
| 1 | break語句
終止迴圈或switch語句,並將執行轉移到緊跟在迴圈或switch之後的語句。 |
| 2 | continue語句
導致迴圈跳過其主體的其餘部分,並在重新迭代之前立即重新測試其條件。 |
| 3 | goto語句
將控制轉移到帶標籤的語句。雖然不建議在程式中使用goto語句。 |
無限迴圈
如果條件永遠不變成假,迴圈就會變成無限迴圈。傳統的for迴圈常用於此目的。“for”迴圈的三個表示式都不必非要存在,您可以透過將條件表示式留空來建立一個無限迴圈。
#include <iostream>
using namespace std;
int main () {
for( ; ; ) {
printf("This loop will run forever.\n");
}
return 0;
}
當條件表示式不存在時,它被認為是真。您可以有初始化和增量表達式,但是C++程式設計師更常用'for (;;)'結構來表示無限迴圈。
注意 −您可以透過按下Ctrl + C鍵來終止無限迴圈。
C++決策語句
決策結構要求程式設計師指定一個或多個條件,由程式進行評估或測試,以及如果條件被確定為真則要執行的語句,以及可選地,如果條件被確定為假則要執行的其他語句。
以下是大多數程式語言中常見的一種典型決策結構的通用形式:
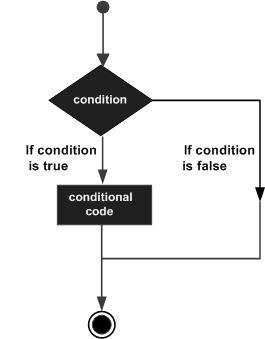
C++程式語言提供以下型別的決策語句。
| 序號 | 語句與描述 |
|---|---|
| 1 | if語句
一個“if”語句由一個布林表示式後跟一個或多個語句組成。 |
| 2 | if...else語句
一個“if”語句後面可以跟一個可選的“else”語句,當布林表示式為假時執行。 |
| 3 | switch語句
一個“switch”語句允許測試一個變數是否與值的列表相等。 |
| 4 | 巢狀if語句
您可以在另一個if或else if語句中使用一個if或else if語句。 |
| 5 | 巢狀switch語句
您可以在另一個switch語句中使用一個switch語句。 |
?: 運算子
我們在上一章中介紹了條件運算子“?:”,它可以用來替換if...else語句。它具有以下通用形式:
Exp1 ? Exp2 : Exp3;
Exp1、Exp2和Exp3是表示式。注意冒號的使用和位置。
“?”表示式的值是這樣的:Exp1被計算。如果為真,則計算Exp2,併成為整個“?”表示式的值。如果Exp1為假,則計算Exp3,其值成為表示式的值。
C++ 函式
函式是一組一起執行任務的語句。每個C++程式至少有一個函式,即main(),並且所有最簡單的程式都可以定義附加函式。
您可以將程式碼分成單獨的函式。您如何將程式碼劃分到不同的函式取決於您,但邏輯上劃分通常是這樣的:每個函式執行一項特定任務。
函式宣告告訴編譯器有關函式的名稱、返回型別和引數的資訊。函式定義提供了函式的實際主體。
C++標準庫提供了許多內建函式,您的程式可以呼叫這些函式。例如,函式strcat()用於連線兩個字串,函式memcpy()用於將一個記憶體位置複製到另一個位置,還有許多其他函式。
函式被稱為方法、子例程或過程等各種名稱。
定義函式
C++函式定義的通用形式如下:
return_type function_name( parameter list ) {
body of the function
}
C++函式定義由函式頭和函式體組成。以下是函式的所有部分:
返回型別 −函式可以返回值。return_type是函式返回的值的資料型別。有些函式執行所需的操作而不返回值。在這種情況下,return_type是關鍵字void。
函式名 −這是函式的實際名稱。函式名和引數列表一起構成函式簽名。
引數 −引數就像一個佔位符。當呼叫函式時,您將值傳遞給引數。這個值被稱為實際引數或實參。引數列表是指函式的引數的型別、順序和數量。引數是可選的;也就是說,函式可能不包含任何引數。
函式體 −函式體包含定義函式功能的一組語句。
示例
以下是名為max()函式的原始碼。此函式接受兩個引數num1和num2,並返回兩者中較大的一個:
// function returning the max between two numbers
int max(int num1, int num2) {
// local variable declaration
int result;
if (num1 > num2)
result = num1;
else
result = num2;
return result;
}
函式宣告
函式宣告告訴編譯器有關函式名稱以及如何呼叫函式的資訊。函式的實際主體可以單獨定義。
函式宣告具有以下部分:
return_type function_name( parameter list );
對於上面定義的函式max(),以下是函式宣告:
int max(int num1, int num2);
引數名稱在函式宣告中並不重要,只需要它們的型別,因此以下也是有效的宣告:
int max(int, int);
當您在一個原始檔中定義一個函式並在另一個檔案中呼叫該函式時,需要進行函式宣告。在這種情況下,您應該在呼叫函式的檔案頂部宣告該函式。
呼叫函式
在建立C++函式時,您會給出函式必須執行的操作的定義。要使用函式,您必須呼叫或呼叫該函式。
當程式呼叫函式時,程式控制權將轉移到被呼叫的函式。被呼叫的函式執行定義的任務,當執行其返回語句或到達其函式結束的閉合大括號時,它將程式控制權返回到主程式。
要呼叫函式,您只需傳遞所需的函式名稱以及引數,如果函式返回值,則可以儲存返回值。例如:
#include <iostream>
using namespace std;
// function declaration
int max(int num1, int num2);
int main () {
// local variable declaration:
int a = 100;
int b = 200;
int ret;
// calling a function to get max value.
ret = max(a, b);
cout << "Max value is : " << ret << endl;
return 0;
}
// function returning the max between two numbers
int max(int num1, int num2) {
// local variable declaration
int result;
if (num1 > num2)
result = num1;
else
result = num2;
return result;
}
我將max()函式與main()函式一起保留,並編譯了原始碼。在執行最終的可執行檔案時,它將產生以下結果:
Max value is : 200
函式引數
如果函式要使用引數,則必須宣告接受引數值的變數。這些變數稱為函式的形式引數。
形式引數在函式內部的行為類似於其他區域性變數,並在進入函式時建立,並在退出函式時銷燬。
在呼叫函式時,引數可以透過兩種方式傳遞給函式:
| 序號 | 呼叫型別與描述 |
|---|---|
| 1 | 按值呼叫
此方法將引數的實際值複製到函式的形式引數中。在這種情況下,對函式內部引數所做的更改不會影響引數。 |
| 2 | 按指標呼叫
此方法將引數的地址複製到形式引數中。在函式內部,該地址用於訪問呼叫中使用的實際引數。這意味著對引數所做的更改會影響引數。 |
| 3 | 按引用呼叫
此方法將引數的引用複製到形式引數中。在函式內部,該引用用於訪問呼叫中使用的實際引數。這意味著對引數所做的更改會影響引數。 |
預設情況下,C++使用按值呼叫傳遞引數。一般來說,這意味著函式中的程式碼不能更改用於呼叫函式的引數,而上述示例在呼叫max()函式時使用了相同的方法。
引數的預設值
定義函式時,可以為每個最後一個引數指定預設值。如果在呼叫函式時對應的引數留空,則將使用此值。
這是透過使用賦值運算子並在函式定義中為引數賦值來完成的。如果在呼叫函式時未為該引數傳遞值,則使用給定的預設值,但如果指定了值,則忽略此預設值,並使用傳遞的值。考慮以下示例:
#include <iostream>
using namespace std;
int sum(int a, int b = 20) {
int result;
result = a + b;
return (result);
}
int main () {
// local variable declaration:
int a = 100;
int b = 200;
int result;
// calling a function to add the values.
result = sum(a, b);
cout << "Total value is :" << result << endl;
// calling a function again as follows.
result = sum(a);
cout << "Total value is :" << result << endl;
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Total value is :300 Total value is :120
C++中的數字
通常,當我們使用數字時,我們使用諸如int、short、long、float和double等原始資料型別。在討論C++資料型別時,已經解釋了數字資料型別、其可能值和數字範圍。
在C++中定義數字
您已經在前面章節中給出的各種示例中定義了數字。這是一個在C++中定義各種型別數字的另一個綜合示例:
#include <iostream>
using namespace std;
int main () {
// number definition:
short s;
int i;
long l;
float f;
double d;
// number assignments;
s = 10;
i = 1000;
l = 1000000;
f = 230.47;
d = 30949.374;
// number printing;
cout << "short s :" << s << endl;
cout << "int i :" << i << endl;
cout << "long l :" << l << endl;
cout << "float f :" << f << endl;
cout << "double d :" << d << endl;
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
short s :10 int i :1000 long l :1000000 float f :230.47 double d :30949.4
C++中的數學運算
除了您可以建立的各種函式外,C++還包含一些您可以使用的有用函式。這些函式可在標準C和C++庫中使用,稱為內建函式。這些是可以包含在您的程式中然後使用的函式。
C++有一套豐富的數學運算,可以對各種數字進行運算。下表列出了C++中可用的一些有用的內建數學函式。
要使用這些函式,您需要包含math標頭檔案<cmath>。
| 序號 | 函式與用途 |
|---|---|
| 1 | double cos(double); 此函式接受一個角度(作為double)並返回餘弦值。 |
| 2 | double sin(double); 此函式接受一個角度(作為double)並返回正弦值。 |
| 3 | double tan(double); 此函式接受一個角度(作為double)並返回正切值。 |
| 4 | double log(double); 此函式接受一個數字並返回該數字的自然對數。 |
| 5 | double pow(double, double); 第一個是您要提升的數字,第二個是您要提升它的冪。 |
| 6 | double hypot(double, double); 如果您將直角三角形的兩條邊的長度傳遞給此函式,它將返回斜邊的長度。 |
| 7 | double sqrt(double); 您將一個數字傳遞給此函式,它會給出平方根。 |
| 8 | int abs(int); 此函式返回傳遞給它的整數的絕對值。 |
| 9 | double fabs(double); 此函式返回傳遞給它的任何十進位制數的絕對值。 |
| 10 | double floor(double); 查詢小於或等於傳遞給它的引數的整數。 |
以下是一個簡單的示例,用於顯示一些數學運算:
#include <iostream>
#include <cmath>
using namespace std;
int main () {
// number definition:
short s = 10;
int i = -1000;
long l = 100000;
float f = 230.47;
double d = 200.374;
// mathematical operations;
cout << "sin(d) :" << sin(d) << endl;
cout << "abs(i) :" << abs(i) << endl;
cout << "floor(d) :" << floor(d) << endl;
cout << "sqrt(f) :" << sqrt(f) << endl;
cout << "pow( d, 2) :" << pow(d, 2) << endl;
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
sign(d) :-0.634939 abs(i) :1000 floor(d) :200 sqrt(f) :15.1812 pow( d, 2 ) :40149.7
C++中的隨機數
在許多情況下,您希望生成一個隨機數。實際上,您需要了解兩個關於隨機數生成的函式。第一個是rand(),此函式僅返回偽隨機數。解決此問題的方法是首先呼叫srand()函式。
以下是一個生成一些隨機數的簡單示例。此示例使用time()函式獲取系統時間的秒數,以隨機播種rand()函式:
#include <iostream>
#include <ctime>
#include <cstdlib>
using namespace std;
int main () {
int i,j;
// set the seed
srand( (unsigned)time( NULL ) );
/* generate 10 random numbers. */
for( i = 0; i < 10; i++ ) {
// generate actual random number
j = rand();
cout <<" Random Number : " << j << endl;
}
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Random Number : 1748144778 Random Number : 630873888 Random Number : 2134540646 Random Number : 219404170 Random Number : 902129458 Random Number : 920445370 Random Number : 1319072661 Random Number : 257938873 Random Number : 1256201101 Random Number : 580322989
C++ 陣列
C++提供了一種資料結構陣列,它儲存相同型別的元素的固定大小的順序集合。陣列用於儲存資料集合,但通常將陣列視為相同型別變數的集合更有用。
無需宣告單個變數,例如number0、number1、...和number99,您可以宣告一個數組變數,例如numbers,並使用numbers[0]、numbers[1]和...numbers[99]來表示單個變數。陣列中的特定元素透過索引訪問。
所有陣列都由連續的記憶體位置組成。最低地址對應於第一個元素,最高地址對應於最後一個元素。
宣告陣列
在 C++ 中宣告陣列,程式設計師需要指定元素的型別和陣列所需的元素數量,如下所示:
type arrayName [ arraySize ];
這被稱為一維陣列。arraySize 必須是一個大於零的整數常量,而 type 可以是任何有效的 C++ 資料型別。例如,要宣告一個名為 balance 的 10 個元素的雙精度浮點數型別陣列,可以使用以下語句:
double balance[10];
陣列初始化
您可以逐個初始化 C++ 陣列元素,也可以使用以下單一語句進行初始化:
double balance[5] = {1000.0, 2.0, 3.4, 17.0, 50.0};
大括號 { } 中的值的數量不能大於我們在方括號 [ ] 中為陣列宣告的元素數量。以下是一個為陣列的單個元素賦值的示例:
如果您省略陣列的大小,則會建立一個足夠大的陣列來容納初始化的值。因此,如果您編寫:
double balance[] = {1000.0, 2.0, 3.4, 17.0, 50.0};
您將建立與前一個示例中完全相同的陣列。
balance[4] = 50.0;
上述語句將陣列中第 5 個元素的值賦值為 50.0。由於所有陣列的第一個元素的索引都是 0(也稱為基索引),因此索引為 4 的元素將是第 5 個元素,即最後一個元素。以下是我們上面討論的相同陣列的圖示:

訪問陣列元素
透過索引陣列名稱來訪問元素。這是透過在陣列名稱之後方括號中放置元素的索引來完成的。例如:
double salary = balance[9];
上述語句將從陣列中取出第 10 個元素並將該值賦給 salary 變數。以下是一個示例,它將使用上述三個概念,即宣告、賦值和訪問陣列:
#include <iostream>
using namespace std;
#include <iomanip>
using std::setw;
int main () {
int n[ 10 ]; // n is an array of 10 integers
// initialize elements of array n to 0
for ( int i = 0; i < 10; i++ ) {
n[ i ] = i + 100; // set element at location i to i + 100
}
cout << "Element" << setw( 13 ) << "Value" << endl;
// output each array element's value
for ( int j = 0; j < 10; j++ ) {
cout << setw( 7 )<< j << setw( 13 ) << n[ j ] << endl;
}
return 0;
}
此程式使用 setw() 函式來格式化輸出。當以上程式碼編譯並執行時,它會產生以下結果:
Element Value
0 100
1 101
2 102
3 103
4 104
5 105
6 106
7 107
8 108
9 109
C++ 中的陣列
陣列對於 C++ 非常重要,需要更詳細的解釋。以下是一些 C++ 程式設計師應該瞭解的重要概念:
| 序號 | 概念和描述 |
|---|---|
| 1 | 多維陣列
C++ 支援多維陣列。多維陣列最簡單的形式是二維陣列。 |
| 2 | 指向陣列的指標
您可以透過簡單地指定陣列名(不帶任何索引)來生成指向陣列第一個元素的指標。 |
| 3 | 將陣列傳遞給函式
您可以透過指定陣列名(不帶索引)將指向陣列的指標傳遞給函式。 |
| 4 | 從函式返回陣列
C++ 允許函式返回一個數組。 |
C++ 字串
C++ 提供以下兩種型別的字串表示:
- C 風格的字元字串。
- 標準 C++ 引入的 string 類型別。
C 風格的字元字串
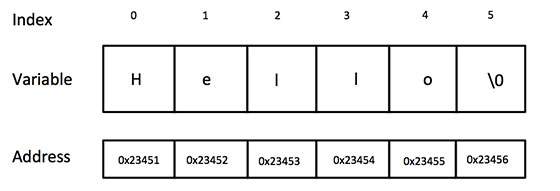
C 風格的字元字串起源於 C 語言,並在 C++ 中繼續得到支援。這個字串實際上是一個以空字元 '\0' 結尾的一維字元陣列。因此,一個空終止字串包含構成字串的字元,後跟一個空字元。
以下宣告和初始化建立一個包含單詞“Hello”的字串。為了在陣列末尾保留空字元,包含字串的字元陣列的大小比單詞“Hello”中的字元數多一個。
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'};
如果您遵循陣列初始化規則,則可以將上述語句編寫如下:
char greeting[] = "Hello";
以下是上述在 C/C++ 中定義的字串的記憶體表示:
實際上,您不必在字串常量的末尾放置空字元。C++ 編譯器在初始化陣列時會自動在字串末尾放置 '\0'。讓我們嘗試列印上述字串:
#include <iostream>
using namespace std;
int main () {
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'};
cout << "Greeting message: ";
cout << greeting << endl;
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Greeting message: Hello
C++ 支援廣泛的功能,這些功能可以操作以 null 結尾的字串:
| 序號 | 函式與用途 |
|---|---|
| 1 | strcpy(s1, s2); 將字串 s2 複製到字串 s1 中。 |
| 2 | strcat(s1, s2); 將字串 s2 連線到字串 s1 的末尾。 |
| 3 | strlen(s1); 返回字串 s1 的長度。 |
| 4 | strcmp(s1, s2); 如果 s1 和 s2 相同,則返回 0;如果 s1 |
| 5 | strchr(s1, ch); 返回指向字串 s1 中字元 ch 的第一次出現的指標。 |
| 6 | strstr(s1, s2); 返回指向字串 s1 中字串 s2 的第一次出現的指標。 |
以下示例使用了一些上述函式:
#include <iostream>
#include <cstring>
using namespace std;
int main () {
char str1[10] = "Hello";
char str2[10] = "World";
char str3[10];
int len ;
// copy str1 into str3
strcpy( str3, str1);
cout << "strcpy( str3, str1) : " << str3 << endl;
// concatenates str1 and str2
strcat( str1, str2);
cout << "strcat( str1, str2): " << str1 << endl;
// total lenghth of str1 after concatenation
len = strlen(str1);
cout << "strlen(str1) : " << len << endl;
return 0;
}
當以上程式碼編譯並執行時,會產生類似以下的結果:
strcpy( str3, str1) : Hello strcat( str1, str2): HelloWorld strlen(str1) : 10
C++ 中的字串類
標準 C++ 庫提供了一個string 類型別,它支援上述所有操作,以及更多功能。讓我們檢查以下示例:
#include <iostream>
#include <string>
using namespace std;
int main () {
string str1 = "Hello";
string str2 = "World";
string str3;
int len ;
// copy str1 into str3
str3 = str1;
cout << "str3 : " << str3 << endl;
// concatenates str1 and str2
str3 = str1 + str2;
cout << "str1 + str2 : " << str3 << endl;
// total length of str3 after concatenation
len = str3.size();
cout << "str3.size() : " << len << endl;
return 0;
}
當以上程式碼編譯並執行時,會產生類似以下的結果:
str3 : Hello str1 + str2 : HelloWorld str3.size() : 10
C++ 指標
C++ 指標易於學習且很有趣。一些 C++ 任務使用指標更容易完成,而其他 C++ 任務(例如動態記憶體分配)則無法在沒有指標的情況下完成。
如您所知,每個變數都是一個記憶體位置,每個記憶體位置都有其定義的地址,可以使用表示記憶體地址的地址運算子 & 來訪問。考慮以下內容,它將列印定義的變數的地址:
#include <iostream>
using namespace std;
int main () {
int var1;
char var2[10];
cout << "Address of var1 variable: ";
cout << &var1 << endl;
cout << "Address of var2 variable: ";
cout << &var2 << endl;
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Address of var1 variable: 0xbfebd5c0 Address of var2 variable: 0xbfebd5b6
什麼是指標?
指標是一個變數,其值是另一個變數的地址。與任何變數或常量一樣,您必須在使用指標之前宣告它。指標變數宣告的一般形式是:
type *var-name;
這裡,type 是指標的基型別;它必須是有效的 C++ 型別,而 var-name 是指標變數的名稱。用於宣告指標的星號與用於乘法的星號相同。但是,在此語句中,星號用於將變數指定為指標。以下是有效的指標宣告:
int *ip; // pointer to an integer double *dp; // pointer to a double float *fp; // pointer to a float char *ch // pointer to character
所有指標的實際資料型別(無論是整數、浮點數、字元還是其他型別)都是相同的,都是表示記憶體地址的長十六進位制數。不同資料型別指標之間的唯一區別在於指標指向的變數或常量的型別。
在 C++ 中使用指標
有一些重要的操作,我們將非常頻繁地對指標進行這些操作。(a) 我們定義一個指標變數。(b) 將變數的地址賦給指標。(c) 最後訪問指標變數中可用地址處的值。這是透過使用一元運算子 * 來完成的,它返回位於其運算元指定的地址處的變數的值。以下示例使用了這些操作:
#include <iostream>
using namespace std;
int main () {
int var = 20; // actual variable declaration.
int *ip; // pointer variable
ip = &var; // store address of var in pointer variable
cout << "Value of var variable: ";
cout << var << endl;
// print the address stored in ip pointer variable
cout << "Address stored in ip variable: ";
cout << ip << endl;
// access the value at the address available in pointer
cout << "Value of *ip variable: ";
cout << *ip << endl;
return 0;
}
當以上程式碼編譯並執行時,會產生類似以下的結果:
Value of var variable: 20 Address stored in ip variable: 0xbfc601ac Value of *ip variable: 20
C++ 中的指標
指標有很多但很容易理解的概念,它們對於 C++ 程式設計非常重要。以下是一些 C++ 程式設計師應該瞭解的重要指標概念:
| 序號 | 概念和描述 |
|---|---|
| 1 | 空指標
C++ 支援空指標,它是一個值為零的常量,在幾個標準庫中定義。 |
| 2 | 指標運算
有四個算術運算子可以用於指標:++、--、+、- |
| 3 | 指標與陣列
指標和陣列之間存在密切關係。 |
| 4 | 指標陣列
您可以定義陣列來儲存多個指標。 |
| 5 | 指向指標的指標
C++ 允許您對指標進行指標操作,以此類推。 |
| 6 | 將指標傳遞給函式
透過引用或透過地址傳遞引數都可以使被呼叫函式在呼叫函式中更改傳遞的引數。 |
| 7 | 從函式返回指標
C++ 允許函式返回指向區域性變數、靜態變數和動態分配記憶體的指標。 |
C++ 引用
引用變數是別名,即已存在變數的另一個名稱。一旦引用用變數初始化,就可以使用變數名或引用名來引用該變數。
引用與指標
引用經常與指標混淆,但引用和指標之間有三個主要區別:
您不能有空引用。您必須始終能夠假設引用已連線到合法的儲存空間。
一旦引用被初始化為一個物件,就不能將其更改為引用另一個物件。指標可以隨時指向另一個物件。
建立引用時必須對其進行初始化。指標可以隨時初始化。
在 C++ 中建立引用
將變數名視為附加到變數在記憶體中的位置的標籤。然後,您可以將引用視為附加到該記憶體位置的第二個標籤。因此,您可以透過原始變數名或引用來訪問變數的內容。例如,假設我們有以下示例:
int i = 17;
我們可以為 i 宣告引用變數,如下所示。
int& r = i;
將這些宣告中的 & 讀作引用。因此,將第一個宣告讀作“r 是一個初始化為 i 的整數引用”,並將第二個宣告讀作“s 是一個初始化為 d 的雙精度浮點數引用”。以下示例使用了 int 和 double 的引用:
#include <iostream>
using namespace std;
int main () {
// declare simple variables
int i;
double d;
// declare reference variables
int& r = i;
double& s = d;
i = 5;
cout << "Value of i : " << i << endl;
cout << "Value of i reference : " << r << endl;
d = 11.7;
cout << "Value of d : " << d << endl;
cout << "Value of d reference : " << s << endl;
return 0;
}
當上述程式碼編譯並執行時,它會產生以下結果:
Value of i : 5 Value of i reference : 5 Value of d : 11.7 Value of d reference : 11.7
引用通常用於函式引數列表和函式返回值。因此,以下與 C++ 引用相關的兩個重要主題應該對 C++ 程式設計師清晰:
C++ 日期和時間
C++ 標準庫沒有提供合適的日期型別。C++ 從 C 繼承了用於日期和時間操作的結構和函式。要訪問與日期和時間相關的函式和結構,您需要在 C++ 程式中包含
有四種與時間相關的型別:clock_t、time_t、size_t 和 tm。clock_t、size_t 和 time_t 型別能夠將系統時間和日期表示為某種整數。
結構型別 tm 以 C 結構的形式儲存日期和時間,該結構具有以下元素:
struct tm {
int tm_sec; // seconds of minutes from 0 to 61
int tm_min; // minutes of hour from 0 to 59
int tm_hour; // hours of day from 0 to 24
int tm_mday; // day of month from 1 to 31
int tm_mon; // month of year from 0 to 11
int tm_year; // year since 1900
int tm_wday; // days since sunday
int tm_yday; // days since January 1st
int tm_isdst; // hours of daylight savings time
}
以下是在 C 或 C++ 中使用日期和時間時使用的重要函式。所有這些函式都是標準 C 和 C++ 庫的一部分,您可以使用下面給出的 C++ 標準庫參考來檢查它們的詳細資訊。
| 序號 | 函式與用途 |
|---|---|
| 1 | time_t time(time_t *time); 這將返回系統當前日曆時間,單位為自 1970 年 1 月 1 日以來經過的秒數。如果系統沒有時間,則返回 .1。 |
| 2 | char *ctime(const time_t *time); 這將返回一個指向以下形式字串的指標:day month year hours:minutes:seconds year\n\0。 |
| 3 | struct tm *localtime(const time_t *time); 這將返回一個指向表示本地時間的 tm 結構的指標。 |
| 4 | clock_t clock(void); 這將返回一個近似表示呼叫程式執行時間的數值。如果時間不可用,則返回 .1。 |
| 5 | char * asctime ( const struct tm * time ); 這將返回一個指向包含 time 指向的結構中儲存的資訊的字串的指標,該資訊已轉換為以下形式:day month date hours:minutes:seconds year\n\0 |
| 6 | struct tm *gmtime(const time_t *time); 此函式返回一個指向 tm 結構體型別的指標,該結構體表示時間。時間以協調世界時 (UTC) 表示,它本質上與格林威治標準時間 (GMT) 相同。 |
| 7 | time_t mktime(struct tm *time); 此函式返回 time 指標指向的結構體中時間對應的日曆時間。 |
| 8 | double difftime ( time_t time2, time_t time1 ); 此函式計算 time1 和 time2 之間的秒數差。 |
| 9 | size_t strftime(); 此函式可用於以特定格式格式化日期和時間。 |
當前日期和時間
假設您想檢索當前系統日期和時間,無論是本地時間還是協調世界時 (UTC)。以下是實現此目的的示例:
#include <iostream>
#include <ctime>
using namespace std;
int main() {
// current date/time based on current system
time_t now = time(0);
// convert now to string form
char* dt = ctime(&now);
cout << "The local date and time is: " << dt << endl;
// convert now to tm struct for UTC
tm *gmtm = gmtime(&now);
dt = asctime(gmtm);
cout << "The UTC date and time is:"<< dt << endl;
}
編譯並執行上述程式碼時,會產生以下結果:
The local date and time is: Sat Jan 8 20:07:41 2011 The UTC date and time is:Sun Jan 9 03:07:41 2011
使用 struct tm 格式化時間
在 C 或 C++ 中處理日期和時間時,tm 結構體非常重要。此結構體以 C 結構體的形式儲存日期和時間,如上所述。大多數與時間相關的函式都使用 tm 結構體。以下是一個使用各種日期和時間相關函式和 tm 結構體的示例:
在本節中使用結構體時,我假設您已經基本瞭解 C 結構體以及如何使用箭頭 -> 運算子訪問結構體成員。
#include <iostream>
#include <ctime>
using namespace std;
int main() {
// current date/time based on current system
time_t now = time(0);
cout << "Number of sec since January 1,1970 is:: " << now << endl;
tm *ltm = localtime(&now);
// print various components of tm structure.
cout << "Year:" << 1900 + ltm->tm_year<<endl;
cout << "Month: "<< 1 + ltm->tm_mon<< endl;
cout << "Day: "<< ltm->tm_mday << endl;
cout << "Time: "<< 5+ltm->tm_hour << ":";
cout << 30+ltm->tm_min << ":";
cout << ltm->tm_sec << endl;
}
編譯並執行上述程式碼時,會產生以下結果:
Number of sec since January 1,1970 is:: 1588485717 Year:2020 Month: 5 Day: 3 Time: 11:31:57
C++ 基本輸入/輸出
C++ 標準庫提供了一套廣泛的輸入/輸出功能,我們將在後續章節中介紹。本章將討論 C++ 程式設計所需的最基本和最常見的 I/O 操作。
C++ 的 I/O 發生在流中,流是位元組序列。如果位元組從鍵盤、磁碟驅動器或網路連線等裝置流向主記憶體,則稱為輸入操作;如果位元組從主記憶體流向顯示屏、印表機、磁碟驅動器或網路連線等裝置,則稱為輸出操作。
I/O 庫標頭檔案
以下標頭檔案對於 C++ 程式很重要:
| 序號 | 標頭檔案 & 函式及說明 |
|---|---|
| 1 | <iostream> 此檔案定義了cin、cout、cerr 和 clog 物件,它們分別對應於標準輸入流、標準輸出流、無緩衝的標準錯誤流和帶緩衝的標準錯誤流。 |
| 2 | <iomanip> 此檔案聲明瞭用於使用所謂的引數化流運算子(例如setw 和 setprecision)執行格式化 I/O 的服務。 |
| 3 | <fstream> 此檔案聲明瞭用於使用者控制的檔案處理的服務。我們將在檔案和流相關的章節中詳細討論。 |
標準輸出流 (cout)
預定義物件cout 是ostream 類的例項。cout 物件被稱為“連線到”標準輸出裝置,通常是顯示屏。cout 與流插入運算子一起使用,該運算子寫為 <<,即兩個小於號,如下例所示。
#include <iostream>
using namespace std;
int main() {
char str[] = "Hello C++";
cout << "Value of str is : " << str << endl;
}
編譯並執行上述程式碼時,會產生以下結果:
Value of str is : Hello C++
C++ 編譯器還會確定要輸出的變數的資料型別,並選擇適當的流插入運算子來顯示值。<< 運算子被過載以輸出內建型別整數、浮點數、雙精度浮點數、字串和指標值的資料項。
插入運算子 << 可以在單個語句中使用多次,如上所示,endl 用於在行尾新增換行符。
標準輸入流 (cin)
預定義物件cin 是istream 類的例項。cin 物件被稱為連線到標準輸入裝置,通常是鍵盤。cin 與流提取運算子一起使用,該運算子寫為 >>,即兩個大於號,如下例所示。
#include <iostream>
using namespace std;
int main() {
char name[50];
cout << "Please enter your name: ";
cin >> name;
cout << "Your name is: " << name << endl;
}
當編譯並執行上述程式碼時,它將提示您輸入名稱。您輸入一個值,然後按 Enter 鍵檢視以下結果:
Please enter your name: cplusplus Your name is: cplusplus
C++ 編譯器還會確定輸入值的型別,並選擇適當的流提取運算子來提取值並將其儲存到給定的變數中。
流提取運算子 >> 可以在單個語句中使用多次。要請求多個數據,可以使用以下方法:
cin >> name >> age;
這將等效於以下兩個語句:
cin >> name; cin >> age;
標準錯誤流 (cerr)
預定義物件cerr 是ostream 類的例項。cerr 物件被稱為連線到標準錯誤裝置,這也是顯示屏,但是cerr 物件是無緩衝的,每次向 cerr 進行流插入都會立即顯示其輸出。
cerr 也與流插入運算子一起使用,如下例所示。
#include <iostream>
using namespace std;
int main() {
char str[] = "Unable to read....";
cerr << "Error message : " << str << endl;
}
編譯並執行上述程式碼時,會產生以下結果:
Error message : Unable to read....
標準日誌流 (clog)
預定義物件clog 是ostream 類的例項。clog 物件被稱為連線到標準錯誤裝置,這也是顯示屏,但是clog 物件是有緩衝的。這意味著每次向 clog 進行插入都可能導致其輸出儲存在緩衝區中,直到緩衝區填滿或緩衝區被重新整理。
clog 也與流插入運算子一起使用,如下例所示。
#include <iostream>
using namespace std;
int main() {
char str[] = "Unable to read....";
clog << "Error message : " << str << endl;
}
編譯並執行上述程式碼時,會產生以下結果:
Error message : Unable to read....
透過這些小的例子,您可能無法看到 cout、cerr 和 clog 之間的任何區別,但在編寫和執行大型程式時,差異就會變得明顯。因此,最好使用 cerr 流顯示錯誤訊息,而顯示其他日誌訊息時則應使用 clog。
C++ 資料結構
C/C++ 陣列允許您定義組合幾種相同型別的資料項的變數,但結構體是另一種使用者定義的資料型別,它允許您組合不同型別的資料項。
結構體用於表示記錄,假設您想跟蹤圖書館中書籍的資訊。您可能希望跟蹤每本書的以下屬性:
- 書名
- 作者
- 主題
- 圖書 ID
定義結構體
要定義結構體,必須使用 struct 語句。struct 語句為程式定義了一種新的資料型別,它包含多個成員。struct 語句的格式如下:
struct [structure tag] {
member definition;
member definition;
...
member definition;
} [one or more structure variables];
結構體標籤是可選的,每個成員定義都是正常的變數定義,例如 int i; 或 float f; 或任何其他有效的變數定義。在結構體定義的末尾,在最後一個分號之前,您可以指定一個或多個結構體變數,但這是可選的。以下是宣告 Book 結構體的方式:
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
} book;
訪問結構體成員
要訪問結構體的任何成員,我們使用成員訪問運算子 (.)。成員訪問運算子被編碼為結構體變數名和我們希望訪問的結構體成員之間的句點。您將使用struct 關鍵字定義結構體型別的變數。以下示例解釋了結構體的用法:
#include <iostream>
#include <cstring>
using namespace std;
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main() {
struct Books Book1; // Declare Book1 of type Book
struct Books Book2; // Declare Book2 of type Book
// book 1 specification
strcpy( Book1.title, "Learn C++ Programming");
strcpy( Book1.author, "Chand Miyan");
strcpy( Book1.subject, "C++ Programming");
Book1.book_id = 6495407;
// book 2 specification
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Yakit Singha");
strcpy( Book2.subject, "Telecom");
Book2.book_id = 6495700;
// Print Book1 info
cout << "Book 1 title : " << Book1.title <<endl;
cout << "Book 1 author : " << Book1.author <<endl;
cout << "Book 1 subject : " << Book1.subject <<endl;
cout << "Book 1 id : " << Book1.book_id <<endl;
// Print Book2 info
cout << "Book 2 title : " << Book2.title <<endl;
cout << "Book 2 author : " << Book2.author <<endl;
cout << "Book 2 subject : " << Book2.subject <<endl;
cout << "Book 2 id : " << Book2.book_id <<endl;
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Book 1 title : Learn C++ Programming Book 1 author : Chand Miyan Book 1 subject : C++ Programming Book 1 id : 6495407 Book 2 title : Telecom Billing Book 2 author : Yakit Singha Book 2 subject : Telecom Book 2 id : 6495700
結構體作為函式引數
您可以像傳遞任何其他變數或指標一樣傳遞結構體作為函式引數。您將像在上述示例中一樣訪問結構體變數:
#include <iostream>
#include <cstring>
using namespace std;
void printBook( struct Books book );
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main() {
struct Books Book1; // Declare Book1 of type Book
struct Books Book2; // Declare Book2 of type Book
// book 1 specification
strcpy( Book1.title, "Learn C++ Programming");
strcpy( Book1.author, "Chand Miyan");
strcpy( Book1.subject, "C++ Programming");
Book1.book_id = 6495407;
// book 2 specification
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Yakit Singha");
strcpy( Book2.subject, "Telecom");
Book2.book_id = 6495700;
// Print Book1 info
printBook( Book1 );
// Print Book2 info
printBook( Book2 );
return 0;
}
void printBook( struct Books book ) {
cout << "Book title : " << book.title <<endl;
cout << "Book author : " << book.author <<endl;
cout << "Book subject : " << book.subject <<endl;
cout << "Book id : " << book.book_id <<endl;
}
編譯並執行上述程式碼時,會產生以下結果:
Book title : Learn C++ Programming Book author : Chand Miyan Book subject : C++ Programming Book id : 6495407 Book title : Telecom Billing Book author : Yakit Singha Book subject : Telecom Book id : 6495700
指向結構體的指標
您可以像定義指向任何其他變數的指標一樣定義指向結構體的指標,如下所示:
struct Books *struct_pointer;
現在,您可以將結構體變數的地址儲存在上述定義的指標變數中。要查詢結構體變數的地址,請在結構體名稱前放置 & 運算子,如下所示:
struct_pointer = &Book1;
要使用指向該結構體的指標訪問結構體的成員,必須使用 -> 運算子,如下所示:
struct_pointer->title;
讓我們使用結構體指標重寫上述示例,希望這將更容易理解這個概念:
#include <iostream>
#include <cstring>
using namespace std;
void printBook( struct Books *book );
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main() {
struct Books Book1; // Declare Book1 of type Book
struct Books Book2; // Declare Book2 of type Book
// Book 1 specification
strcpy( Book1.title, "Learn C++ Programming");
strcpy( Book1.author, "Chand Miyan");
strcpy( Book1.subject, "C++ Programming");
Book1.book_id = 6495407;
// Book 2 specification
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Yakit Singha");
strcpy( Book2.subject, "Telecom");
Book2.book_id = 6495700;
// Print Book1 info, passing address of structure
printBook( &Book1 );
// Print Book1 info, passing address of structure
printBook( &Book2 );
return 0;
}
// This function accept pointer to structure as parameter.
void printBook( struct Books *book ) {
cout << "Book title : " << book->title <<endl;
cout << "Book author : " << book->author <<endl;
cout << "Book subject : " << book->subject <<endl;
cout << "Book id : " << book->book_id <<endl;
}
編譯並執行上述程式碼時,會產生以下結果:
Book title : Learn C++ Programming Book author : Chand Miyan Book subject : C++ Programming Book id : 6495407 Book title : Telecom Billing Book author : Yakit Singha Book subject : Telecom Book id : 6495700
typedef 關鍵字
有一種更簡單的方法來定義結構體,或者您可以為建立的型別建立“別名”。例如:
typedef struct {
char title[50];
char author[50];
char subject[100];
int book_id;
} Books;
現在,您可以直接使用Books 來定義Books 型別的變數,而無需使用 struct 關鍵字。以下是一個示例:
Books Book1, Book2;
您也可以對非結構體使用typedef 關鍵字,如下所示:
typedef long int *pint32; pint32 x, y, z;
x、y 和 z 都是指向長整型的指標。
C++ 類和物件
C++ 程式設計的主要目的是為 C 程式語言新增面向物件特性,類是支援面向物件程式設計的 C++ 的核心特性,通常稱為使用者定義型別。
類用於指定物件的結構,它將資料表示和操作該資料的方法組合到一個整潔的包中。類中的資料和函式稱為類的成員。
C++ 類定義
定義類時,定義了資料型別的藍圖。這實際上並沒有定義任何資料,但它確實定義了類名的含義,也就是說,類的物件將包含什麼以及可以對這樣的物件執行什麼操作。
類定義以關鍵字class 後跟類名開頭;以及用一對花括號括起來的類體。類定義後面必須跟一個分號或一個宣告列表。例如,我們使用關鍵字class 定義了 Box 資料型別,如下所示:
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
關鍵字public 確定其後類成員的訪問屬性。公共成員可以在類的作用域內的任何地方從類外部訪問。您還可以將類的成員指定為private 或protected,我們將在小節中討論。
定義 C++ 物件
類為物件提供了藍圖,因此基本上物件是由類建立的。我們用與宣告基本型別的變數完全相同的宣告來宣告類的物件。以下語句聲明瞭兩個 Box 類的物件:
Box Box1; // Declare Box1 of type Box Box Box2; // Declare Box2 of type Box
Box1 和 Box2 兩個物件都將擁有自己的資料成員副本。
訪問資料成員
可以使用直接成員訪問運算子 (.) 訪問類物件的公共資料成員。讓我們嘗試以下示例來使事情更清晰:
#include <iostream>
using namespace std;
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
int main() {
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
Box1.height = 5.0;
Box1.length = 6.0;
Box1.breadth = 7.0;
// box 2 specification
Box2.height = 10.0;
Box2.length = 12.0;
Box2.breadth = 13.0;
// volume of box 1
volume = Box1.height * Box1.length * Box1.breadth;
cout << "Volume of Box1 : " << volume <<endl;
// volume of box 2
volume = Box2.height * Box2.length * Box2.breadth;
cout << "Volume of Box2 : " << volume <<endl;
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Volume of Box1 : 210 Volume of Box2 : 1560
需要注意的是,不能使用直接成員訪問運算子 (.) 直接訪問私有和受保護成員。我們將學習如何訪問私有和受保護成員。
詳細介紹類和物件
到目前為止,您已經對 C++ 類和物件有了非常基本的瞭解。還有更多關於 C++ 類和物件的有趣概念,我們將在下面列出的各個小節中討論:
| 序號 | 概念和描述 |
|---|---|
| 1 | 類成員函式
類的成員函式是一個函式,其定義或原型與任何其他變數一樣,都位於類定義內。 |
| 2 | 類訪問修飾符
類成員可以定義為公有的(public)、私有的(private)或受保護的(protected)。預設情況下,成員被認為是私有的。 |
| 3 | 建構函式和解構函式
類的建構函式是類中的一種特殊函式,在建立類的新的物件時被呼叫。解構函式也是一種特殊函式,在建立的物件被刪除時被呼叫。 |
| 4 | 複製建構函式
複製建構函式是一種建構函式,它透過使用之前建立的同一類的物件來初始化物件從而建立一個物件。 |
| 5 | 友元函式
友元函式被允許完全訪問類的私有和受保護成員。 |
| 6 | 行內函數
對於行內函數,編譯器嘗試將函式體中的程式碼擴充套件到函式呼叫的位置。 |
| 7 | this 指標
每個物件都有一個特殊的指標this,它指向物件本身。 |
| 8 | 指向C++類的指標
指向類的指標與指向結構的指標完全相同。實際上,類只是一個包含函式的結構。 |
| 9 | 類的靜態成員
類的成員資料和成員函式都可以宣告為靜態的。 |
C++ 繼承
面向物件程式設計中最重要概念之一是繼承。繼承允許我們根據另一個類來定義類,這使得建立和維護應用程式更加容易。這也提供了重用程式碼功能和加快實現時間的機會。
建立類時,程式設計師可以指定新類應該繼承現有類的成員,而不是編寫全新的成員資料和成員函式。這個現有的類稱為基類,新類稱為派生類。
繼承的概念實現了is a關係。例如,哺乳動物是動物,狗是哺乳動物,因此狗也是動物,等等。
基類和派生類
一個類可以從多個類派生,這意味著它可以繼承多個基類的成員資料和函式。為了定義派生類,我們使用類派生列表來指定基類。
class derived-class: access-specifier base-class
其中,訪問說明符是public、protected或private之一,基類是先前定義的類的名稱。如果未使用訪問說明符,則預設為private。
考慮一個基類Shape及其派生類Rectangle:
#include <iostream>
using namespace std;
// Base class
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
};
// Derived class
class Rectangle: public Shape {
public:
int getArea() {
return (width * height);
}
};
int main(void) {
Rectangle Rect;
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
cout << "Total area: " << Rect.getArea() << endl;
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Total area: 35
訪問控制和繼承
派生類可以訪問其基類的所有非私有成員。因此,基類中不應該被派生類的成員函式訪問的成員應該在基類中宣告為私有的。
我們可以按照以下方式總結不同訪問型別:
| 訪問許可權 | public | protected | private |
|---|---|---|---|
| 同一類 | 是 | 是 | 是 |
| 派生類 | 是 | 是 | 否 |
| 外部類 | 是 | 否 | 否 |
派生類繼承所有基類方法,但以下情況除外:
- 基類的建構函式、解構函式和複製建構函式。
- 基類的過載運算子。
- 基類的友元函式。
繼承型別
從基類派生類時,基類可以透過public、protected或private繼承方式繼承。繼承型別由訪問說明符指定,如上所述。
我們幾乎不使用protected或private繼承,但public繼承是常用的。使用不同型別的繼承時,應用以下規則:
公有繼承 - 從公有基類派生類時,基類的公有成員成為派生類的公有成員,基類的受保護成員成為派生類的受保護成員。基類的私有成員永遠無法直接從派生類訪問,但可以透過呼叫基類的公有和受保護成員來訪問。
受保護繼承 - 從受保護基類派生時,基類的公有和受保護成員成為派生類的受保護成員。
私有繼承 - 從私有基類派生時,基類的公有和受保護成員成為派生類的私有成員。
多重繼承
C++類可以繼承多個類的成員,以下是擴充套件語法:
class derived-class: access baseA, access baseB....
其中,access是public、protected或private之一,每個基類都會給出,它們將用逗號分隔,如上所示。
#include <iostream>
using namespace std;
// Base class Shape
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
};
// Base class PaintCost
class PaintCost {
public:
int getCost(int area) {
return area * 70;
}
};
// Derived class
class Rectangle: public Shape, public PaintCost {
public:
int getArea() {
return (width * height);
}
};
int main(void) {
Rectangle Rect;
int area;
Rect.setWidth(5);
Rect.setHeight(7);
area = Rect.getArea();
// Print the area of the object.
cout << "Total area: " << Rect.getArea() << endl;
// Print the total cost of painting
cout << "Total paint cost: $" << Rect.getCost(area) << endl;
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Total area: 35 Total paint cost: $2450
C++過載(運算子和函式)
C++允許你在同一作用域內為函式名或運算子指定多個定義,這分別稱為函式過載和運算子過載。
過載宣告是在同一作用域中宣告與先前宣告的宣告具有相同名稱的宣告,但兩者具有不同的引數,並且顯然具有不同的定義(實現)。
呼叫過載的函式或運算子時,編譯器會透過將你用於呼叫函式或運算子的引數型別與定義中指定的引數型別進行比較,來確定最合適的定義。選擇最合適的過載函式或運算子的過程稱為過載解析。
C++中的函式過載
你可以在同一作用域中為同一函式名提供多個定義。函式的定義必須透過引數列表中引數的型別和/或數量來區分。你不能過載僅返回值型別不同的函式宣告。
以下示例演示瞭如何使用相同的函式print()列印不同的資料型別:
#include <iostream>
using namespace std;
class printData {
public:
void print(int i) {
cout << "Printing int: " << i << endl;
}
void print(double f) {
cout << "Printing float: " << f << endl;
}
void print(char* c) {
cout << "Printing character: " << c << endl;
}
};
int main(void) {
printData pd;
// Call print to print integer
pd.print(5);
// Call print to print float
pd.print(500.263);
// Call print to print character
pd.print("Hello C++");
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Printing int: 5 Printing float: 500.263 Printing character: Hello C++
C++中的運算子過載
你可以重新定義或過載C++中大多數可用的內建運算子。因此,程式設計師也可以將運算子與使用者定義的型別一起使用。
過載運算子是具有特殊名稱的函式:關鍵字“operator”後跟被定義運算子的符號。與任何其他函式一樣,過載運算子具有返回型別和引數列表。
Box operator+(const Box&);
聲明瞭可以用來加兩個Box物件的加法運算子,並返回最終的Box物件。大多數過載運算子可以定義為普通的非成員函式或類成員函式。如果我們將上述函式定義為類的非成員函式,則必須為每個運算元傳遞兩個引數,如下所示:
Box operator+(const Box&, const Box&);
以下示例演示了使用成員函式進行運算子過載的概念。這裡將一個物件作為引數傳遞,其屬性將使用此物件訪問,呼叫此運算子的物件可以使用this運算子訪問,如下所示:
#include <iostream>
using namespace std;
class Box {
public:
double getVolume(void) {
return length * breadth * height;
}
void setLength( double len ) {
length = len;
}
void setBreadth( double bre ) {
breadth = bre;
}
void setHeight( double hei ) {
height = hei;
}
// Overload + operator to add two Box objects.
Box operator+(const Box& b) {
Box box;
box.length = this->length + b.length;
box.breadth = this->breadth + b.breadth;
box.height = this->height + b.height;
return box;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
// Main function for the program
int main() {
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type Box
Box Box3; // Declare Box3 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
Box1.setLength(6.0);
Box1.setBreadth(7.0);
Box1.setHeight(5.0);
// box 2 specification
Box2.setLength(12.0);
Box2.setBreadth(13.0);
Box2.setHeight(10.0);
// volume of box 1
volume = Box1.getVolume();
cout << "Volume of Box1 : " << volume <<endl;
// volume of box 2
volume = Box2.getVolume();
cout << "Volume of Box2 : " << volume <<endl;
// Add two object as follows:
Box3 = Box1 + Box2;
// volume of box 3
volume = Box3.getVolume();
cout << "Volume of Box3 : " << volume <<endl;
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Volume of Box1 : 210 Volume of Box2 : 1560 Volume of Box3 : 5400
可過載/不可過載運算子
以下是可過載的運算子列表:
| + | - | * | / | % | ^ |
| & | | | ~ | ! | , | = |
| < | > | <= | >= | ++ | -- |
| << | >> | == | != | && | || |
| += | -= | /= | %= | ^= | &= |
| |= | *= | <<= | >>= | [] | () |
| -> | ->* | new | new [] | delete | delete [] |
以下是不可過載的運算子列表:
| :: | .* | . | ?: |
運算子過載示例
以下是一些運算子過載示例,以幫助你理解這個概念。
| 序號 | 運算子和示例 |
|---|---|
| 1 | 一元運算子過載 |
| 2 | 二元運算子過載 |
| 3 | 關係運算符過載 |
| 4 | 輸入/輸出運算子過載 |
| 5 | ++和--運算子過載 |
| 6 | 賦值運算子過載 |
| 7 | 函式呼叫()運算子過載 |
| 8 | 下標[]運算子過載 |
| 9 | 類成員訪問運算子->過載 |
C++中的多型性
多型性一詞意為具有多種形式。通常,當存在類層次結構且它們透過繼承相關時,就會發生多型性。
C++多型性意味著對成員函式的呼叫將導致執行不同的函式,這取決於呼叫該函式的物件的型別。
考慮以下示例,其中一個基類已被其他兩個類派生:
#include <iostream>
using namespace std;
class Shape {
protected:
int width, height;
public:
Shape( int a = 0, int b = 0){
width = a;
height = b;
}
int area() {
cout << "Parent class area :" <<endl;
return 0;
}
};
class Rectangle: public Shape {
public:
Rectangle( int a = 0, int b = 0):Shape(a, b) { }
int area () {
cout << "Rectangle class area :" <<endl;
return (width * height);
}
};
class Triangle: public Shape {
public:
Triangle( int a = 0, int b = 0):Shape(a, b) { }
int area () {
cout << "Triangle class area :" <<endl;
return (width * height / 2);
}
};
// Main function for the program
int main() {
Shape *shape;
Rectangle rec(10,7);
Triangle tri(10,5);
// store the address of Rectangle
shape = &rec;
// call rectangle area.
shape->area();
// store the address of Triangle
shape = &tri;
// call triangle area.
shape->area();
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Parent class area : Parent class area :
輸出不正確的原因是,對函式area()的呼叫由編譯器一次設定為基類中定義的版本。這稱為函式呼叫的靜態解析,或靜態連結——函式呼叫在程式執行之前就已固定。這有時也稱為早期繫結,因為area()函式是在程式編譯期間設定的。
但是現在,讓我們對程式進行一些修改,並在Shape類中area()的宣告前加上關鍵字virtual,使其看起來像這樣:
class Shape {
protected:
int width, height;
public:
Shape( int a = 0, int b = 0) {
width = a;
height = b;
}
virtual int area() {
cout << "Parent class area :" <<endl;
return 0;
}
};
經過此細微修改後,當編譯並執行前面的示例程式碼時,它會產生以下結果:
Rectangle class area Triangle class area
這次,編譯器檢視指標的內容而不是它的型別。因此,由於tri和rec類的物件的地址儲存在*shape中,因此呼叫相應的area()函式。
正如你所看到的,每個子類都有一個單獨的area()函式實現。這就是多型性的通常使用方法。你擁有具有相同名稱的函式的不同類,甚至具有相同的引數,但具有不同的實現。
虛擬函式
虛擬函式是基類中使用關鍵字virtual宣告的函式。在基類中定義一個虛擬函式,並在派生類中定義另一個版本,這會向編譯器發出訊號,表明我們不希望此函式進行靜態連結。
我們想要的是在程式的任何給定點上,要呼叫的函式的選擇基於為其呼叫的物件的型別。這種操作稱為動態連結或後期繫結。
純虛擬函式
你可能希望在基類中包含一個虛擬函式,以便可以在派生類中重新定義它以適應該類的物件,但是對於基類中的函式,你沒有可以提供的有意義的定義。
我們可以將基類中的虛擬函式area()更改為以下內容:
class Shape {
protected:
int width, height;
public:
Shape(int a = 0, int b = 0) {
width = a;
height = b;
}
// pure virtual function
virtual int area() = 0;
};
= 0告訴編譯器該函式沒有主體,上面的虛擬函式將被稱為純虛擬函式。
C++中的資料抽象
資料抽象是指只向外界提供必要資訊,而隱藏其背景細節,即在程式中表示所需資訊而不呈現細節。
資料抽象是一種程式設計(和設計)技術,它依賴於介面和實現的分離。
讓我們以電視機為例,你可以開啟和關閉它,換臺,調節音量,並新增外部元件,例如揚聲器、錄影機和 DVD 播放器,但是你不知道它的內部細節,也就是說,你不知道它如何接收無線或有線訊號,如何轉換這些訊號,以及最終如何在螢幕上顯示它們。
因此,我們可以說電視機清楚地將它的內部實現與其外部介面分隔開來,你可以操作它的介面,例如電源按鈕、換臺按鈕和音量控制,而無需瞭解其內部結構。
在 C++ 中,類提供了高級別的**資料抽象**。它們向外部世界提供足夠的公共方法來使用物件的函式並操作物件資料,即狀態,而無需實際瞭解類的內部實現方式。
例如,你的程式可以呼叫**sort()**函式,而無需知道該函式實際使用什麼演算法來對給定值進行排序。事實上,排序功能的底層實現可能會在庫的不同版本之間發生變化,只要介面保持不變,你的函式呼叫仍然有效。
在 C++ 中,我們使用**類**來定義我們自己的抽象資料型別 (ADT)。你可以使用**ostream**類的**cout**物件將資料流式傳輸到標準輸出,如下所示:
#include <iostream>
using namespace std;
int main() {
cout << "Hello C++" <<endl;
return 0;
}
在這裡,你不需要了解**cout**如何將文字顯示在使用者的螢幕上。你只需要知道公共介面,而‘cout’的底層實現可以隨意更改。
訪問標籤強制執行抽象
在 C++ 中,我們使用訪問標籤來定義類的抽象介面。一個類可以包含零個或多個訪問標籤:
使用公共標籤定義的成員可以被程式的所有部分訪問。型別的抽象資料檢視由其公共成員定義。
使用私有標籤定義的成員無法被使用該類的程式碼訪問。私有部分隱藏了使用該型別的程式碼的實現。
訪問標籤出現的頻率沒有限制。每個訪問標籤都指定後續成員定義的訪問級別。指定的訪問級別一直有效,直到遇到下一個訪問標籤或類的主體右括號。
資料抽象的優點
資料抽象提供了兩個重要的優點:
類內部受到保護,免受無意的使用者級錯誤的影響,這些錯誤可能會破壞物件的狀態。
類實現可以隨著時間的推移而發展,以響應不斷變化的需求或錯誤報告,而無需更改使用者級程式碼。
透過僅在類的私有部分定義資料成員,類作者可以自由地更改資料。如果實現發生更改,只需要檢查類程式碼即可檢視更改可能產生的影響。如果資料是公共的,那麼任何直接訪問舊錶示的資料成員的函式都可能被破壞。
資料抽象示例
任何在其中實現具有公共和私有成員的類的 C++ 程式都是資料抽象的示例。考慮以下示例:
#include <iostream>
using namespace std;
class Adder {
public:
// constructor
Adder(int i = 0) {
total = i;
}
// interface to outside world
void addNum(int number) {
total += number;
}
// interface to outside world
int getTotal() {
return total;
};
private:
// hidden data from outside world
int total;
};
int main() {
Adder a;
a.addNum(10);
a.addNum(20);
a.addNum(30);
cout << "Total " << a.getTotal() <<endl;
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Total 60
上面的類將數字加在一起,並返回總和。公共成員 - **addNum** 和 **getTotal** 是面向外部世界的介面,使用者需要知道它們才能使用該類。私有成員 **total** 是使用者不需要了解的內容,但它是類正常執行所必需的。
設計策略
抽象將程式碼分為介面和實現。因此,在設計元件時,必須保持介面與實現的獨立性,以便如果更改底層實現,介面將保持不變。
在這種情況下,無論使用這些介面的程式是什麼,它們都不會受到影響,只需要使用最新的實現重新編譯即可。
C++ 中的資料封裝
所有 C++ 程式都由以下兩個基本元素組成:
**程式語句(程式碼)** - 這是程式執行操作的部分,它們被稱為函式。
**程式資料** - 資料是程式的資訊,受程式函式的影響。
封裝是一個面向物件程式設計的概念,它將資料和操作資料的函式繫結在一起,並使兩者都免受外部干擾和誤用的影響。資料封裝導致了重要的面向物件程式設計概念 **資料隱藏**。
**資料封裝**是一種將資料及其使用的函式捆綁在一起的機制,而**資料抽象**是一種僅公開介面並向用戶隱藏實現細節的機制。
C++ 透過建立稱為**類**的使用者定義型別來支援封裝和資料隱藏的特性。我們已經學習過一個類可以包含**私有、保護**和**公共**成員。預設情況下,在類中定義的所有專案都是私有的。例如:
class Box {
public:
double getVolume(void) {
return length * breadth * height;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
變數 length、breadth 和 height 是**私有的**。這意味著它們只能被 Box 類的其他成員訪問,而不能被程式的任何其他部分訪問。這是實現封裝的一種方式。
要使類的部分成員成為**公共的**(即,可被程式的其他部分訪問),必須在**public**關鍵字之後宣告它們。在 public 說明符之後定義的所有變數或函式都可以被程式中的所有其他函式訪問。
使一個類成為另一個類的 friend 會暴露實現細節並降低封裝性。理想的做法是儘可能隱藏每個類的細節,使其不被其他任何類訪問。
資料封裝示例
任何在其中實現具有公共和私有成員的類的 C++ 程式都是資料封裝和資料抽象的示例。考慮以下示例:
#include <iostream>
using namespace std;
class Adder {
public:
// constructor
Adder(int i = 0) {
total = i;
}
// interface to outside world
void addNum(int number) {
total += number;
}
// interface to outside world
int getTotal() {
return total;
};
private:
// hidden data from outside world
int total;
};
int main() {
Adder a;
a.addNum(10);
a.addNum(20);
a.addNum(30);
cout << "Total " << a.getTotal() <<endl;
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Total 60
上面的類將數字加在一起,並返回總和。公共成員 **addNum** 和 **getTotal** 是面向外部世界的介面,使用者需要知道它們才能使用該類。私有成員 **total** 是對外部世界隱藏的內容,但它是類正常執行所必需的。
設計策略
我們大多數人都學會了預設情況下將類成員設為私有,除非我們確實需要公開它們。這只是良好的**封裝**。
這最常應用於資料成員,但也同樣適用於所有成員,包括虛擬函式。
C++ 中的介面(抽象類)
介面描述了 C++ 類的行為或功能,而無需採用該類的特定實現。
C++ 介面是使用**抽象類**實現的,這些抽象類不應與資料抽象混淆,資料抽象是將實現細節與相關資料分開的概念。
透過至少宣告其一個函式為**純虛擬函式**來使類成為抽象類。純虛擬函式透過在其宣告中放置“= 0”來指定,如下所示:
class Box {
public:
// pure virtual function
virtual double getVolume() = 0;
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
**抽象類**(通常稱為 ABC) 的目的是提供一個合適的基類,其他類可以從中繼承。抽象類不能用於例項化物件,僅用作**介面**。嘗試例項化抽象類的物件會導致編譯錯誤。
因此,如果 ABC 的子類需要被例項化,它必須實現每個虛擬函式,這意味著它支援 ABC 宣告的介面。如果在派生類中沒有重寫純虛擬函式,則嘗試例項化該類的物件將導致編譯錯誤。
可以用來例項化物件的類稱為**具體類**。
抽象類示例
考慮以下示例,其中父類提供了一個介面,供基類實現名為 **getArea()** 的函式:
#include <iostream>
using namespace std;
// Base class
class Shape {
public:
// pure virtual function providing interface framework.
virtual int getArea() = 0;
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
};
// Derived classes
class Rectangle: public Shape {
public:
int getArea() {
return (width * height);
}
};
class Triangle: public Shape {
public:
int getArea() {
return (width * height)/2;
}
};
int main(void) {
Rectangle Rect;
Triangle Tri;
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
cout << "Total Rectangle area: " << Rect.getArea() << endl;
Tri.setWidth(5);
Tri.setHeight(7);
// Print the area of the object.
cout << "Total Triangle area: " << Tri.getArea() << endl;
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Total Rectangle area: 35 Total Triangle area: 17
您可以看到抽象類如何根據 getArea() 定義介面,以及其他兩個類如何實現相同的函式,但使用不同的演算法來計算特定形狀的面積。
設計策略
面向物件的系統可以使用抽象基類來提供適合所有外部應用程式的通用且標準化的介面。然後,透過從該抽象基類繼承,形成操作方式相似的派生類。
外部應用程式提供的功能(即公共函式)在抽象基類中作為純虛擬函式提供。這些純虛擬函式的實現在對應於應用程式特定型別的派生類中提供。
這種架構還允許輕鬆地將新應用程式新增到系統中,即使在定義系統之後也是如此。
C++ 檔案和流
到目前為止,我們一直在使用 **iostream** 標準庫,該庫提供 **cin** 和 **cout** 方法,分別用於從標準輸入讀取和寫入標準輸出。
本教程將教你如何從檔案讀取和寫入。這需要另一個名為 **fstream** 的標準 C++ 庫,它定義了三個新的資料型別:
| 序號 | 資料型別和描述 |
|---|---|
| 1 | ofstream 此資料型別表示輸出檔案流,用於建立檔案並將資訊寫入檔案。 |
| 2 | ifstream 此資料型別表示輸入檔案流,用於從檔案讀取資訊。 |
| 3 | fstream 此資料型別通常表示檔案流,並且具有 ofstream 和 ifstream 的功能,這意味著它可以建立檔案、將資訊寫入檔案和從檔案讀取資訊。 |
要在 C++ 中執行檔案處理,必須在 C++ 原始檔中包含標頭檔案 <iostream> 和 <fstream>。
開啟檔案
在讀取或寫入檔案之前,必須先開啟檔案。可以使用 **ofstream** 或 **fstream** 物件開啟要寫入的檔案。而 ifstream 物件僅用於開啟要讀取的檔案。
以下是 open() 函式的標準語法,它是 fstream、ifstream 和 ofstream 物件的成員。
void open(const char *filename, ios::openmode mode);
這裡,第一個引數指定要開啟的檔案的名稱和位置,**open()** 成員函式的第二個引數定義應以何種模式開啟檔案。
| 序號 | 模式標誌和描述 |
|---|---|
| 1 | ios::app 追加模式。所有寫入該檔案的內容都將追加到檔案的末尾。 |
| 2 | ios::ate 開啟一個用於輸出的檔案,並將讀/寫控制移動到檔案的末尾。 |
| 3 | ios::in 開啟一個用於讀取的檔案。 |
| 4 | ios::out 開啟一個用於寫入的檔案。 |
| 5 | ios::trunc 如果檔案已存在,則在開啟檔案之前將截斷其內容。 |
可以透過將它們**OR**在一起來組合兩個或多個這些值。例如,如果要以寫入模式開啟檔案,並且如果檔案已存在,則要截斷它,則語法如下:
ofstream outfile;
outfile.open("file.dat", ios::out | ios::trunc );
類似地,可以開啟一個用於讀取和寫入的檔案,如下所示:
fstream afile;
afile.open("file.dat", ios::out | ios::in );
關閉檔案
當 C++ 程式終止時,它會自動重新整理所有流,釋放所有已分配的記憶體並關閉所有開啟的檔案。但程式設計師在程式終止前關閉所有開啟的檔案始終是一個好習慣。
以下是 close() 函式的標準語法,它是 fstream、ifstream 和 ofstream 物件的成員。
void close();
寫入檔案
在進行 C++ 程式設計時,您可以使用流插入運算子(<<)將資訊從程式寫入檔案,就像使用該運算子將資訊輸出到螢幕一樣。唯一的區別在於您使用的是ofstream 或 fstream 物件而不是 cout 物件。
從檔案讀取
您可以使用流提取運算子(>>)將資訊從檔案讀取到程式中,就像使用該運算子從鍵盤輸入資訊一樣。唯一的區別在於您使用的是ifstream 或 fstream 物件而不是 cin 物件。
讀寫示例
以下是 C++ 程式,它以讀寫模式開啟檔案。該程式將使用者輸入的資訊寫入名為 afile.dat 的檔案後,會從檔案中讀取資訊並將其輸出到螢幕上:
#include <fstream>
#include <iostream>
using namespace std;
int main () {
char data[100];
// open a file in write mode.
ofstream outfile;
outfile.open("afile.dat");
cout << "Writing to the file" << endl;
cout << "Enter your name: ";
cin.getline(data, 100);
// write inputted data into the file.
outfile << data << endl;
cout << "Enter your age: ";
cin >> data;
cin.ignore();
// again write inputted data into the file.
outfile << data << endl;
// close the opened file.
outfile.close();
// open a file in read mode.
ifstream infile;
infile.open("afile.dat");
cout << "Reading from the file" << endl;
infile >> data;
// write the data at the screen.
cout << data << endl;
// again read the data from the file and display it.
infile >> data;
cout << data << endl;
// close the opened file.
infile.close();
return 0;
}
編譯並執行上述程式碼後,會生成以下示例輸入和輸出:
$./a.out Writing to the file Enter your name: Zara Enter your age: 9 Reading from the file Zara 9
上述示例使用了 cin 物件的附加函式,例如 getline() 函式從外部讀取行,以及 ignore() 函式忽略先前讀取語句留下的額外字元。
檔案位置指標
istream 和 ostream 都提供用於重新定位檔案位置指標的成員函式。這些成員函式是 seekg(“seek get”)用於 istream,seekp(“seek put”)用於 ostream。
seekg 和 seekp 的引數通常是長整數。可以指定第二個引數來指示搜尋方向。搜尋方向可以是ios::beg(預設值),用於相對於流的開頭定位;ios::cur,用於相對於流中的當前位置定位;或ios::end,用於相對於流的末尾定位。
檔案位置指標是一個整數值,它指定檔案中距檔案起始位置的位元組數位置。一些定位“get”檔案位置指標的示例如下:
// position to the nth byte of fileObject (assumes ios::beg) fileObject.seekg( n ); // position n bytes forward in fileObject fileObject.seekg( n, ios::cur ); // position n bytes back from end of fileObject fileObject.seekg( n, ios::end ); // position at end of fileObject fileObject.seekg( 0, ios::end );
C++ 異常處理
異常是在程式執行期間出現的錯誤。C++ 異常是對程式執行時出現的異常情況的響應,例如嘗試除以零。
異常提供了一種將控制從程式的某個部分轉移到另一個部分的方法。C++ 異常處理基於三個關鍵字:try、catch 和 throw。
throw − 當出現問題時,程式會丟擲異常。這是使用throw關鍵字完成的。
catch − 程式在程式中要處理問題的某個位置使用異常處理程式捕獲異常。catch關鍵字表示捕獲異常。
try − try 塊標識將為其啟用特定異常的程式碼塊。它後面跟有一個或多個 catch 塊。
假設一個塊會引發異常,則一個方法使用try和catch關鍵字的組合來捕獲異常。try/catch 塊放置在可能生成異常的程式碼周圍。try/catch 塊中的程式碼稱為受保護程式碼,使用 try/catch 的語法如下:
try {
// protected code
} catch( ExceptionName e1 ) {
// catch block
} catch( ExceptionName e2 ) {
// catch block
} catch( ExceptionName eN ) {
// catch block
}
您可以列出多個catch語句來捕獲不同型別的異常,以防您的try塊在不同情況下引發多個異常。
丟擲異常
可以使用throw語句在程式碼塊中的任何位置丟擲異常。throw 語句的運算元確定異常的型別,可以是任何表示式,表示式的結果型別決定了丟擲的異常型別。
以下是在發生除以零條件時丟擲異常的示例:
double division(int a, int b) {
if( b == 0 ) {
throw "Division by zero condition!";
}
return (a/b);
}
捕獲異常
try塊後面的catch塊捕獲任何異常。您可以指定要捕獲的異常型別,這由出現在 catch 關鍵字後面的括號中的異常宣告決定。
try {
// protected code
} catch( ExceptionName e ) {
// code to handle ExceptionName exception
}
上面的程式碼將捕獲ExceptionName型別的異常。如果要指定 catch 塊應處理 try 塊中丟擲的任何型別的異常,則必須在包含異常宣告的括號之間放置省略號 ...,如下所示:
try {
// protected code
} catch(...) {
// code to handle any exception
}
以下是一個示例,它丟擲除以零異常,我們在 catch 塊中捕獲它。
#include <iostream>
using namespace std;
double division(int a, int b) {
if( b == 0 ) {
throw "Division by zero condition!";
}
return (a/b);
}
int main () {
int x = 50;
int y = 0;
double z = 0;
try {
z = division(x, y);
cout << z << endl;
} catch (const char* msg) {
cerr << msg << endl;
}
return 0;
}
因為我們丟擲的異常型別是const char*,所以在捕獲此異常時,我們必須在 catch 塊中使用 const char*。如果我們編譯並執行上面的程式碼,則會產生以下結果:
Division by zero condition!
C++ 標準異常
C++ 提供了在<exception>中定義的標準異常列表,我們可以在程式中使用。這些異常按如下所示的父子類層次結構排列:
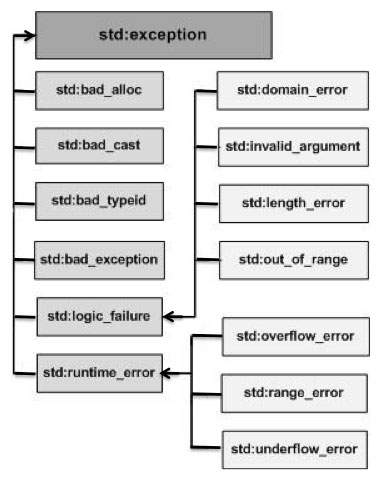
以下是上述層次結構中每個異常的簡短描述:
| 序號 | 異常和描述 |
|---|---|
| 1 | std::exception 一個異常,也是所有標準 C++ 異常的父類。 |
| 2 | std::bad_alloc 這可能由new丟擲。 |
| 3 | std::bad_cast 這可能由dynamic_cast丟擲。 |
| 4 | std::bad_exception 這是一個有用的工具,用於處理 C++ 程式中的意外異常。 |
| 5 | std::bad_typeid 這可能由typeid丟擲。 |
| 6 | std::logic_error 理論上可以透過閱讀程式碼檢測到的異常。 |
| 7 | std::domain_error 當使用數學上無效的域時丟擲的異常。 |
| 8 | std::invalid_argument 由於引數無效而丟擲。 |
| 9 | std::length_error 建立太大的 std::string 時丟擲。 |
| 10 | std::out_of_range 例如,這可能由'at'方法(例如 std::vector 和 std::bitset<>::operator[]())丟擲。 |
| 11 | std::runtime_error 理論上無法透過閱讀程式碼檢測到的異常。 |
| 12 | std::overflow_error 如果發生數學溢位,則會丟擲此異常。 |
| 13 | std::range_error 當您嘗試儲存超出範圍的值時發生。 |
| 14 | std::underflow_error 如果發生數學下溢,則會丟擲此異常。 |
定義新的異常
您可以透過繼承和重寫exception類的功能來定義自己的異常。以下是一個示例,它展示瞭如何使用 std::exception 類以標準方式實現您自己的異常:
#include <iostream>
#include <exception>
using namespace std;
struct MyException : public exception {
const char * what () const throw () {
return "C++ Exception";
}
};
int main() {
try {
throw MyException();
} catch(MyException& e) {
std::cout << "MyException caught" << std::endl;
std::cout << e.what() << std::endl;
} catch(std::exception& e) {
//Other errors
}
}
這將產生以下結果:
MyException caught C++ Exception
這裡,what() 是 exception 類提供的公共方法,並且所有子異常類都已重寫它。這返回異常的原因。
C++ 動態記憶體
充分了解 C++ 中動態記憶體的實際工作方式對於成為優秀的 C++ 程式設計師至關重要。C++ 程式中的記憶體分為兩部分:
棧 − 在函式內部宣告的所有變數都將佔用來自棧的記憶體。
堆 − 這是程式的未用記憶體,可以在程式執行時動態分配記憶體。
很多時候,您事先並不知道需要多少記憶體來儲存定義變數中的特定資訊,並且所需記憶體的大小可以在執行時確定。
您可以使用 C++ 中的特殊運算子為給定型別的變數在堆中執行時分配記憶體,該運算子返回已分配空間的地址。此運算子稱為new運算子。
如果您不再需要動態分配的記憶體,則可以使用delete運算子,該運算子將取消先前由 new 運算子分配的記憶體。
new 和 delete 運算子
以下是用new運算子動態分配任何資料型別記憶體的通用語法。
new data-type;
這裡,資料型別可以是任何內建資料型別,包括陣列或任何使用者定義的資料型別,包括類或結構。讓我們從內建資料型別開始。例如,我們可以定義一個指向 double 型別的指標,然後請求在執行時分配記憶體。我們可以使用new運算子和以下語句來執行此操作:
double* pvalue = NULL; // Pointer initialized with null pvalue = new double; // Request memory for the variable
如果空閒儲存已用完,則可能無法成功分配記憶體。因此,最好檢查 new 運算子是否返回 NULL 指標並採取適當的措施,如下所示:
double* pvalue = NULL;
if( !(pvalue = new double )) {
cout << "Error: out of memory." <<endl;
exit(1);
}
來自 C 的malloc()函式仍然存在於 C++ 中,但建議避免使用 malloc() 函式。new 相對於 malloc() 的主要優點是 new 不僅僅分配記憶體,它還構造物件,這是 C++ 的主要目的。
在任何時候,當您覺得不再需要動態分配的變數時,您可以使用“delete”運算子釋放它在空閒儲存中佔用的記憶體,如下所示:
delete pvalue; // Release memory pointed to by pvalue
讓我們將上述概念組合起來,形成以下示例以顯示“new”和“delete”的工作方式:
#include <iostream>
using namespace std;
int main () {
double* pvalue = NULL; // Pointer initialized with null
pvalue = new double; // Request memory for the variable
*pvalue = 29494.99; // Store value at allocated address
cout << "Value of pvalue : " << *pvalue << endl;
delete pvalue; // free up the memory.
return 0;
}
如果我們編譯並執行上面的程式碼,這將產生以下結果:
Value of pvalue : 29495
陣列的動態記憶體分配
假設您想為字元陣列(即 20 個字元的字串)分配記憶體。使用我們上面使用的相同語法,我們可以動態分配記憶體,如下所示。
char* pvalue = NULL; // Pointer initialized with null pvalue = new char[20]; // Request memory for the variable
要刪除我們剛剛建立的陣列,語句將如下所示:
delete [] pvalue; // Delete array pointed to by pvalue
按照 new 運算子的類似通用語法,您可以為多維陣列分配記憶體,如下所示:
double** pvalue = NULL; // Pointer initialized with null pvalue = new double [3][4]; // Allocate memory for a 3x4 array
但是,釋放多維陣列記憶體的語法仍然與上面相同:
delete [] pvalue; // Delete array pointed to by pvalue
物件的動態記憶體分配
物件與簡單資料型別沒有什麼不同。例如,考慮以下程式碼,我們將使用物件陣列來闡明這個概念:
#include <iostream>
using namespace std;
class Box {
public:
Box() {
cout << "Constructor called!" <<endl;
}
~Box() {
cout << "Destructor called!" <<endl;
}
};
int main() {
Box* myBoxArray = new Box[4];
delete [] myBoxArray; // Delete array
return 0;
}
如果您要分配四個 Box 物件的陣列,則 Simple 建構函式將被呼叫四次,同樣,在刪除這些物件時,解構函式也將被呼叫相同次數。
如果我們編譯並執行上面的程式碼,這將產生以下結果:
Constructor called! Constructor called! Constructor called! Constructor called! Destructor called! Destructor called! Destructor called! Destructor called!
C++ 中的名稱空間
考慮這種情況,當我們有兩個同名的人,Zara,在同一個班級。每當我們需要區分他們時,我們肯定必須使用一些附加資訊以及他們的姓名,例如他們居住的地區(如果他們居住在不同地區)或他們母親或父親的姓名等。
同樣的情況也可能出現在您的 C++ 應用程式中。例如,您可能正在編寫一些包含名為 xyz() 的函式的程式碼,並且還有一個也包含相同函式 xyz() 的可用庫。現在,編譯器無法知道您在程式碼中引用的是哪個版本的 xyz() 函式。
名稱空間旨在克服這種困難,並用作附加資訊來區分在不同庫中可用的名稱相同的類似函式、類、變數等。使用名稱空間,您可以定義定義名稱的上下文。本質上,名稱空間定義了一個範圍。
定義名稱空間
名稱空間定義以關鍵字namespace開頭,後跟名稱空間名稱,如下所示:
namespace namespace_name {
// code declarations
}
要呼叫函式或變數的啟用名稱空間的版本,請在前面新增 (::) 名稱空間名稱,如下所示:
name::code; // code could be variable or function.
讓我們看看名稱空間如何作用域實體,包括變數和函式:
#include <iostream>
using namespace std;
// first name space
namespace first_space {
void func() {
cout << "Inside first_space" << endl;
}
}
// second name space
namespace second_space {
void func() {
cout << "Inside second_space" << endl;
}
}
int main () {
// Calls function from first name space.
first_space::func();
// Calls function from second name space.
second_space::func();
return 0;
}
如果我們編譯並執行上面的程式碼,這將產生以下結果:
Inside first_space Inside second_space
using 指令
您也可以使用 `using namespace` 指令避免名稱空間的字首。此指令告訴編譯器後續程式碼正在使用指定名稱空間中的名稱。因此,名稱空間將隱式應用於以下程式碼。
#include <iostream>
using namespace std;
// first name space
namespace first_space {
void func() {
cout << "Inside first_space" << endl;
}
}
// second name space
namespace second_space {
void func() {
cout << "Inside second_space" << endl;
}
}
using namespace first_space;
int main () {
// This calls function from first name space.
func();
return 0;
}
如果我們編譯並執行上面的程式碼,這將產生以下結果:
Inside first_space
`using` 指令還可以用於引用名稱空間中的特定專案。例如,如果您打算使用的 `std` 名稱空間的唯一部分是 `cout`,您可以按如下方式引用它:
using std::cout;
後續程式碼可以引用 `cout` 而無需新增名稱空間字首,但 `std` 名稱空間中的其他專案仍需要顯式說明,如下所示:
#include <iostream>
using std::cout;
int main () {
cout << "std::endl is used with std!" << std::endl;
return 0;
}
如果我們編譯並執行上面的程式碼,這將產生以下結果:
std::endl is used with std!
在 `using` 指令中引入的名稱遵循正常的範圍規則。該名稱從 `using` 指令的位置到找到該指令的範圍的末尾都是可見的。在外層作用域中定義的同名實體將被隱藏。
不連續名稱空間
名稱空間可以分為幾個部分,因此名稱空間由其各個單獨定義的部分的總和構成。名稱空間的各個部分可以分佈在多個檔案中。
因此,如果名稱空間的一部分需要在另一個檔案中定義的名稱,則該名稱仍然必須宣告。編寫以下名稱空間定義,要麼定義一個新的名稱空間,要麼向現有名稱空間新增新元素:
namespace namespace_name {
// code declarations
}
巢狀名稱空間
名稱空間可以巢狀,您可以按如下方式在一個名稱空間內定義另一個名稱空間:
namespace namespace_name1 {
// code declarations
namespace namespace_name2 {
// code declarations
}
}
您可以使用解析運算子訪問巢狀名稱空間的成員,如下所示:
// to access members of namespace_name2 using namespace namespace_name1::namespace_name2; // to access members of namespace:name1 using namespace namespace_name1;
在上例中,如果您使用 `namespace_name1`,它將使 `namespace_name2` 的元素在作用域中可用,如下所示:
#include <iostream>
using namespace std;
// first name space
namespace first_space {
void func() {
cout << "Inside first_space" << endl;
}
// second name space
namespace second_space {
void func() {
cout << "Inside second_space" << endl;
}
}
}
using namespace first_space::second_space;
int main () {
// This calls function from second name space.
func();
return 0;
}
如果我們編譯並執行上面的程式碼,這將產生以下結果:
Inside second_space
C++ 模板
模板是泛型程式設計的基礎,泛型程式設計涉及以獨立於任何特定型別的方式編寫程式碼。
模板是建立泛型類或函式的藍圖或公式。像迭代器和演算法這樣的庫容器是泛型程式設計的示例,並且是使用模板概念開發的。
每個容器(例如 `vector`)只有一個定義,但我們可以定義許多不同型別的向量,例如 `vector <int>` 或 `vector <string>`。
您可以使用模板定義函式和類,讓我們看看它們是如何工作的:
函式模板
此處顯示模板函式定義的一般形式:
template <class type> ret-type func-name(parameter list) {
// body of function
}
這裡,`type` 是函式使用的資料型別的佔位符名稱。此名稱可以在函式定義中使用。
以下是一個返回兩個值最大值的函式模板示例:
#include <iostream>
#include <string>
using namespace std;
template <typename T>
inline T const& Max (T const& a, T const& b) {
return a < b ? b:a;
}
int main () {
int i = 39;
int j = 20;
cout << "Max(i, j): " << Max(i, j) << endl;
double f1 = 13.5;
double f2 = 20.7;
cout << "Max(f1, f2): " << Max(f1, f2) << endl;
string s1 = "Hello";
string s2 = "World";
cout << "Max(s1, s2): " << Max(s1, s2) << endl;
return 0;
}
如果我們編譯並執行上面的程式碼,這將產生以下結果:
Max(i, j): 39 Max(f1, f2): 20.7 Max(s1, s2): World
類模板
就像我們可以定義函式模板一樣,我們也可以定義類模板。此處顯示泛型類宣告的一般形式:
template <class type> class class-name {
.
.
.
}
這裡,`type` 是佔位符型別名稱,在例項化類時將指定它。您可以使用逗號分隔的列表定義多個泛型資料型別。
以下是如何定義類 `Stack<>` 並實現泛型方法來壓入和彈出棧中元素的示例:
#include <iostream>
#include <vector>
#include <cstdlib>
#include <string>
#include <stdexcept>
using namespace std;
template <class T>
class Stack {
private:
vector<T> elems; // elements
public:
void push(T const&); // push element
void pop(); // pop element
T top() const; // return top element
bool empty() const { // return true if empty.
return elems.empty();
}
};
template <class T>
void Stack<T>::push (T const& elem) {
// append copy of passed element
elems.push_back(elem);
}
template <class T>
void Stack<T>::pop () {
if (elems.empty()) {
throw out_of_range("Stack<>::pop(): empty stack");
}
// remove last element
elems.pop_back();
}
template <class T>
T Stack<T>::top () const {
if (elems.empty()) {
throw out_of_range("Stack<>::top(): empty stack");
}
// return copy of last element
return elems.back();
}
int main() {
try {
Stack<int> intStack; // stack of ints
Stack<string> stringStack; // stack of strings
// manipulate int stack
intStack.push(7);
cout << intStack.top() <<endl;
// manipulate string stack
stringStack.push("hello");
cout << stringStack.top() << std::endl;
stringStack.pop();
stringStack.pop();
} catch (exception const& ex) {
cerr << "Exception: " << ex.what() <<endl;
return -1;
}
}
如果我們編譯並執行上面的程式碼,這將產生以下結果:
7 hello Exception: Stack<>::pop(): empty stack
C++ 預處理器
預處理器是指令,它們指示編譯器在實際編譯開始之前預處理資訊。
所有預處理器指令都以 `#` 開頭,一行預處理器指令之前只能出現空格字元。預處理器指令不是 C++ 語句,因此它們不以分號 (;) 結尾。
您已經在所有示例中都看到了 `#include` 指令。此宏用於將標頭檔案包含到原始檔中。
C++ 支援許多預處理器指令,例如 `#include`、`#define`、`#if`、`#else`、`#line` 等。讓我們看看重要的指令:
#define 預處理器
`#define` 預處理器指令建立符號常量。符號常量稱為 `宏`,該指令的一般形式為:
#define macro-name replacement-text
當這一行出現在檔案中時,該檔案中宏的所有後續出現都將在程式編譯之前替換為 `replacement-text`。例如:
#include <iostream>
using namespace std;
#define PI 3.14159
int main () {
cout << "Value of PI :" << PI << endl;
return 0;
}
現在,讓我們對這段程式碼進行預處理以檢視結果,假設我們有原始碼檔案。因此,讓我們使用 `-E` 選項編譯它並將結果重定向到 `test.p`。現在,如果您檢查 `test.p`,它將包含大量資訊,並且在底部,您會發現值已替換為:
$gcc -E test.cpp > test.p
...
int main () {
cout << "Value of PI :" << 3.14159 << endl;
return 0;
}
類函式宏
您可以使用 `#define` 來定義一個將接受引數的宏,如下所示:
#include <iostream>
using namespace std;
#define MIN(a,b) (((a)<(b)) ? a : b)
int main () {
int i, j;
i = 100;
j = 30;
cout <<"The minimum is " << MIN(i, j) << endl;
return 0;
}
如果我們編譯並執行上面的程式碼,這將產生以下結果:
The minimum is 30
條件編譯
有幾個指令可以用於編譯程式原始碼的某些部分。此過程稱為條件編譯。
條件預處理器結構很像 `if` 選擇結構。考慮以下預處理器程式碼:
#ifndef NULL #define NULL 0 #endif
您可以編譯程式以進行除錯。您還可以使用單個宏開啟或關閉除錯,如下所示:
#ifdef DEBUG cerr <<"Variable x = " << x << endl; #endif
如果在 `#ifdef DEBUG` 指令之前已定義符號常量 `DEBUG`,則這會導致 `cerr` 語句在程式中編譯。您可以使用 `#if 0` 語句註釋掉程式的一部分,如下所示:
#if 0 code prevented from compiling #endif
讓我們嘗試以下示例:
#include <iostream>
using namespace std;
#define DEBUG
#define MIN(a,b) (((a)<(b)) ? a : b)
int main () {
int i, j;
i = 100;
j = 30;
#ifdef DEBUG
cerr <<"Trace: Inside main function" << endl;
#endif
#if 0
/* This is commented part */
cout << MKSTR(HELLO C++) << endl;
#endif
cout <<"The minimum is " << MIN(i, j) << endl;
#ifdef DEBUG
cerr <<"Trace: Coming out of main function" << endl;
#endif
return 0;
}
如果我們編譯並執行上面的程式碼,這將產生以下結果:
The minimum is 30 Trace: Inside main function Trace: Coming out of main function
`#` 和 `##` 運算子
`#` 和 `##` 預處理器運算子在 C++ 和 ANSI/ISO C 中可用。 `#` 運算子會導致將替換文字標記轉換為用引號括起來的字串。
考慮以下宏定義:
#include <iostream>
using namespace std;
#define MKSTR( x ) #x
int main () {
cout << MKSTR(HELLO C++) << endl;
return 0;
}
如果我們編譯並執行上面的程式碼,這將產生以下結果:
HELLO C++
讓我們看看它是如何工作的。很容易理解,C++ 預處理器將以下行:
cout << MKSTR(HELLO C++) << endl;
轉換為以下行:
cout << "HELLO C++" << endl;
`##` 運算子用於連線兩個標記。這是一個例子:
#define CONCAT( x, y ) x ## y
當 `CONCAT` 出現在程式中時,它的引數將被連線起來並用於替換宏。例如,`CONCAT(HELLO, C++)` 在程式中將替換為 `"HELLO C++"`,如下所示。
#include <iostream>
using namespace std;
#define concat(a, b) a ## b
int main() {
int xy = 100;
cout << concat(x, y);
return 0;
}
如果我們編譯並執行上面的程式碼,這將產生以下結果:
100
讓我們看看它是如何工作的。很容易理解,C++ 預處理器將以下行:
cout << concat(x, y);
轉換為以下行:
cout << xy;
預定義的 C++ 宏
C++ 提供了許多下面提到的預定義宏:
| 序號 | 宏 & 說明 |
|---|---|
| 1 | __LINE__ 這包含程式在編譯時的當前行號。 |
| 2 | __FILE__ 這包含程式在編譯時的當前檔名。 |
| 3 | __DATE__ 這包含一個格式為月/日/年的字串,它是原始檔轉換為目的碼的日期。 |
| 4 | __TIME__ 這包含一個格式為時:分:秒的字串,它是編譯程式的時間。 |
讓我們看看所有上述宏的一個例子:
#include <iostream>
using namespace std;
int main () {
cout << "Value of __LINE__ : " << __LINE__ << endl;
cout << "Value of __FILE__ : " << __FILE__ << endl;
cout << "Value of __DATE__ : " << __DATE__ << endl;
cout << "Value of __TIME__ : " << __TIME__ << endl;
return 0;
}
如果我們編譯並執行上面的程式碼,這將產生以下結果:
Value of __LINE__ : 6 Value of __FILE__ : test.cpp Value of __DATE__ : Feb 28 2011 Value of __TIME__ : 18:52:48
C++ 訊號處理
訊號是由作業系統傳遞給程序的中斷,它可以過早地終止程式。您可以透過在 UNIX、LINUX、Mac OS X 或 Windows 系統上按 Ctrl+C 來生成中斷。
有一些訊號程式無法捕獲,但有一份列表列出了您可以在程式中捕獲的訊號,並且可以根據訊號採取適當的操作。這些訊號在 C++ 標頭檔案 `
| 序號 | 訊號 & 說明 |
|---|---|
| 1 | SIGABRT 程式異常終止,例如呼叫 `abort`。 |
| 2 | SIGFPE 錯誤的算術運算,例如被零除或導致溢位的運算。 |
| 3 | SIGILL 檢測到非法指令。 |
| 4 | SIGINT 收到互動式注意訊號。 |
| 5 | SIGSEGV 無效的儲存器訪問。 |
| 6 | SIGTERM 傳送到程式的終止請求。 |
signal() 函式
C++ 訊號處理庫提供 `signal` 函式來捕獲意外事件。以下是 `signal()` 函式的語法:
void (*signal (int sig, void (*func)(int)))(int);
簡而言之,此函式接收兩個引數:第一個引數是一個整數,表示訊號編號;第二個引數是指向訊號處理函式的指標。
讓我們編寫一個簡單的 C++ 程式,我們將在其中使用 `signal()` 函式捕獲 `SIGINT` 訊號。您要在程式中捕獲任何訊號,都必須使用 `signal` 函式註冊該訊號並將其與訊號處理程式關聯。檢查以下示例:
#include <iostream>
#include <csignal>
using namespace std;
void signalHandler( int signum ) {
cout << "Interrupt signal (" << signum << ") received.\n";
// cleanup and close up stuff here
// terminate program
exit(signum);
}
int main () {
// register signal SIGINT and signal handler
signal(SIGINT, signalHandler);
while(1) {
cout << "Going to sleep...." << endl;
sleep(1);
}
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Going to sleep.... Going to sleep.... Going to sleep....
現在,按 Ctrl+c 中斷程式,您將看到您的程式將捕獲訊號並透過列印如下內容退出:
Going to sleep.... Going to sleep.... Going to sleep.... Interrupt signal (2) received.
raise() 函式
您可以透過 `raise()` 函式生成訊號,該函式以整數訊號編號作為引數,並具有以下語法。
int raise (signal sig);
這裡,`sig` 是要傳送的訊號編號,可以是以下任何訊號:`SIGINT`、`SIGABRT`、`SIGFPE`、`SIGILL`、`SIGSEGV`、`SIGTERM`、`SIGHUP`。以下是一個使用 `raise()` 函式在內部引發訊號的示例:
#include <iostream>
#include <csignal>
using namespace std;
void signalHandler( int signum ) {
cout << "Interrupt signal (" << signum << ") received.\n";
// cleanup and close up stuff here
// terminate program
exit(signum);
}
int main () {
int i = 0;
// register signal SIGINT and signal handler
signal(SIGINT, signalHandler);
while(++i) {
cout << "Going to sleep...." << endl;
if( i == 3 ) {
raise( SIGINT);
}
sleep(1);
}
return 0;
}
編譯並執行上述程式碼時,它會產生以下結果並自動退出:
Going to sleep.... Going to sleep.... Going to sleep.... Interrupt signal (2) received.
C++ 多執行緒
多執行緒是多工處理的一種特殊形式,多工處理允許您的計算機同時執行兩個或多個程式。一般來說,多工處理有兩種型別:基於程序的和基於執行緒的。
基於程序的多工處理處理程式的併發執行。基於執行緒的多工處理處理同一程式的各個部分的併發執行。
多執行緒程式包含兩個或多個可以併發執行的部分。此類程式的每一部分稱為一個執行緒,每個執行緒定義一個單獨的執行路徑。
在 C++ 11 之前,沒有對多執行緒應用程式的內建支援。相反,它完全依賴於作業系統來提供此功能。
本教程假設您正在 Linux 作業系統上工作,我們將使用 POSIX 編寫多執行緒 C++ 程式。POSIX 執行緒或 Pthreads 提供了可在許多類 Unix POSIX 系統(如 FreeBSD、NetBSD、GNU/Linux、Mac OS X 和 Solaris)上使用的 API。
建立執行緒
以下例程用於建立 POSIX 執行緒:
#include <pthread.h> pthread_create (thread, attr, start_routine, arg)
此處,pthread_create 建立一個新執行緒並使其可執行。此例程可以從程式碼中的任何位置呼叫任意多次。以下是引數的描述:
| 序號 | 引數及描述 |
|---|---|
| 1 | thread 子例程返回的新的執行緒的不透明、唯一識別符號。 |
| 2 | attr 一個不透明的屬性物件,可用於設定執行緒屬性。您可以指定一個執行緒屬性物件,或者使用 NULL 表示預設值。 |
| 3 | start_routine 執行緒建立後將執行的 C++ 例程。 |
| 4 | arg 可以傳遞給 start_routine 的單個引數。它必須透過引用作為 void 型別指標的強制轉換來傳遞。如果不需要傳遞引數,可以使用 NULL。 |
程序可以建立的執行緒最大數量取決於實現。建立後,執行緒是同等地位的,可以建立其他執行緒。執行緒之間沒有隱含的層次結構或依賴關係。
終止執行緒
我們使用以下例程來終止 POSIX 執行緒:
#include <pthread.h> pthread_exit (status)
這裡pthread_exit 用於顯式退出執行緒。通常,線上程完成其工作並且不再需要存在後,會呼叫 pthread_exit() 例程。
如果 main() 在其建立的執行緒之前完成並使用 pthread_exit() 退出,則其他執行緒將繼續執行。否則,當 main() 完成時,它們將自動終止。
示例
此簡單的示例程式碼使用 pthread_create() 例程建立 5 個執行緒。每個執行緒列印一條“Hello World!”訊息,然後透過呼叫 pthread_exit() 終止。
#include <iostream>
#include <cstdlib>
#include <pthread.h>
using namespace std;
#define NUM_THREADS 5
void *PrintHello(void *threadid) {
long tid;
tid = (long)threadid;
cout << "Hello World! Thread ID, " << tid << endl;
pthread_exit(NULL);
}
int main () {
pthread_t threads[NUM_THREADS];
int rc;
int i;
for( i = 0; i < NUM_THREADS; i++ ) {
cout << "main() : creating thread, " << i << endl;
rc = pthread_create(&threads[i], NULL, PrintHello, (void *)i);
if (rc) {
cout << "Error:unable to create thread," << rc << endl;
exit(-1);
}
}
pthread_exit(NULL);
}
使用 -lpthread 庫編譯以下程式,方法如下:
$gcc test.cpp -lpthread
現在,執行您的程式,它將給出以下輸出:
main() : creating thread, 0 main() : creating thread, 1 main() : creating thread, 2 main() : creating thread, 3 main() : creating thread, 4 Hello World! Thread ID, 0 Hello World! Thread ID, 1 Hello World! Thread ID, 2 Hello World! Thread ID, 3 Hello World! Thread ID, 4
向執行緒傳遞引數
此示例演示如何透過結構傳遞多個引數。您可以將任何資料型別傳遞給執行緒回撥,因為它指向 void,如下例所示:
#include <iostream>
#include <cstdlib>
#include <pthread.h>
using namespace std;
#define NUM_THREADS 5
struct thread_data {
int thread_id;
char *message;
};
void *PrintHello(void *threadarg) {
struct thread_data *my_data;
my_data = (struct thread_data *) threadarg;
cout << "Thread ID : " << my_data->thread_id ;
cout << " Message : " << my_data->message << endl;
pthread_exit(NULL);
}
int main () {
pthread_t threads[NUM_THREADS];
struct thread_data td[NUM_THREADS];
int rc;
int i;
for( i = 0; i < NUM_THREADS; i++ ) {
cout <<"main() : creating thread, " << i << endl;
td[i].thread_id = i;
td[i].message = "This is message";
rc = pthread_create(&threads[i], NULL, PrintHello, (void *)&td[i]);
if (rc) {
cout << "Error:unable to create thread," << rc << endl;
exit(-1);
}
}
pthread_exit(NULL);
}
編譯並執行上述程式碼時,會產生以下結果:
main() : creating thread, 0 main() : creating thread, 1 main() : creating thread, 2 main() : creating thread, 3 main() : creating thread, 4 Thread ID : 3 Message : This is message Thread ID : 2 Message : This is message Thread ID : 0 Message : This is message Thread ID : 1 Message : This is message Thread ID : 4 Message : This is message
連線和分離執行緒
我們可以使用以下兩個例程來連線或分離執行緒:
pthread_join (threadid, status) pthread_detach (threadid)
pthread_join() 子例程會阻塞呼叫執行緒,直到指定的 'threadid' 執行緒終止。建立執行緒時,其屬性之一定義它是可連線的還是已分離的。只有建立為可連線的執行緒才能連線。如果執行緒建立為已分離的,則永遠無法連線它。
此示例演示如何使用 Pthread join 例程等待執行緒完成。
#include <iostream>
#include <cstdlib>
#include <pthread.h>
#include <unistd.h>
using namespace std;
#define NUM_THREADS 5
void *wait(void *t) {
int i;
long tid;
tid = (long)t;
sleep(1);
cout << "Sleeping in thread " << endl;
cout << "Thread with id : " << tid << " ...exiting " << endl;
pthread_exit(NULL);
}
int main () {
int rc;
int i;
pthread_t threads[NUM_THREADS];
pthread_attr_t attr;
void *status;
// Initialize and set thread joinable
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
for( i = 0; i < NUM_THREADS; i++ ) {
cout << "main() : creating thread, " << i << endl;
rc = pthread_create(&threads[i], &attr, wait, (void *)i );
if (rc) {
cout << "Error:unable to create thread," << rc << endl;
exit(-1);
}
}
// free attribute and wait for the other threads
pthread_attr_destroy(&attr);
for( i = 0; i < NUM_THREADS; i++ ) {
rc = pthread_join(threads[i], &status);
if (rc) {
cout << "Error:unable to join," << rc << endl;
exit(-1);
}
cout << "Main: completed thread id :" << i ;
cout << " exiting with status :" << status << endl;
}
cout << "Main: program exiting." << endl;
pthread_exit(NULL);
}
編譯並執行上述程式碼時,會產生以下結果:
main() : creating thread, 0 main() : creating thread, 1 main() : creating thread, 2 main() : creating thread, 3 main() : creating thread, 4 Sleeping in thread Thread with id : 0 .... exiting Sleeping in thread Thread with id : 1 .... exiting Sleeping in thread Thread with id : 2 .... exiting Sleeping in thread Thread with id : 3 .... exiting Sleeping in thread Thread with id : 4 .... exiting Main: completed thread id :0 exiting with status :0 Main: completed thread id :1 exiting with status :0 Main: completed thread id :2 exiting with status :0 Main: completed thread id :3 exiting with status :0 Main: completed thread id :4 exiting with status :0 Main: program exiting.
C++ Web程式設計
什麼是 CGI?
公共閘道器介面 (CGI) 是一組標準,定義瞭如何在 Web 伺服器和自定義指令碼之間交換資訊。
CGI 規範目前由 NCSA 維護,NCSA 對 CGI 的定義如下:
公共閘道器介面 (CGI) 是外部閘道器程式與資訊伺服器(例如 HTTP 伺服器)互動的標準。
當前版本為 CGI/1.1,CGI/1.2 正在開發中。
Web 瀏覽
為了理解 CGI 的概念,讓我們看看當我們點選超連結瀏覽特定網頁或 URL 時會發生什麼。
您的瀏覽器聯絡 HTTP Web 伺服器並請求 URL,即檔名。
Web 伺服器將解析 URL 並查詢檔名。如果找到請求的檔案,則 Web 伺服器將該檔案傳送回瀏覽器,否則傳送錯誤訊息,指示您請求的檔案錯誤。
Web 瀏覽器接收來自 Web 伺服器的響應,並根據接收到的響應顯示接收到的檔案或錯誤訊息。
但是,可以以這樣一種方式設定 HTTP 伺服器:每當請求某個目錄中的檔案時,該檔案不會被髮送回來;而是作為程式執行,程式生成的輸出被髮送回您的瀏覽器以顯示。
公共閘道器介面 (CGI) 是一種標準協議,用於啟用應用程式(稱為 CGI 程式或 CGI 指令碼)與 Web 伺服器和客戶端互動。這些 CGI 程式可以用 Python、PERL、Shell、C 或 C++ 等編寫。
CGI 架構圖
以下簡單程式顯示了 CGI 的簡單架構:
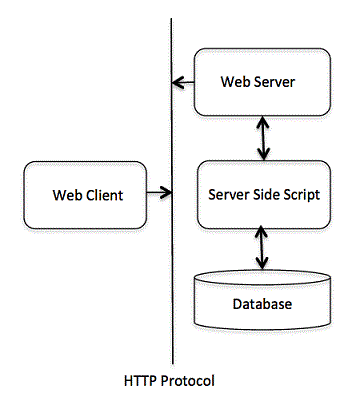
Web 伺服器配置
在繼續進行 CGI 程式設計之前,請確保您的 Web 伺服器支援 CGI 並已配置為處理 CGI 程式。所有要由 HTTP 伺服器執行的 CGI 程式都儲存在預配置的目錄中。此目錄稱為 CGI 目錄,按照慣例,其名稱為 /var/www/cgi-bin。按照慣例,CGI 檔案的副檔名為 .cgi,儘管它們是 C++ 可執行檔案。
預設情況下,Apache Web 伺服器配置為在 /var/www/cgi-bin 中執行 CGI 程式。如果要指定其他目錄來執行 CGI 指令碼,可以修改 httpd.conf 檔案中的以下部分:
<Directory "/var/www/cgi-bin"> AllowOverride None Options ExecCGI Order allow,deny Allow from all </Directory> <Directory "/var/www/cgi-bin"> Options All </Directory>
這裡,我假設您的 Web 伺服器已成功啟動並執行,並且您可以執行其他 CGI 程式,例如 Perl 或 Shell 等。
第一個 CGI 程式
考慮以下 C++ 程式內容:
#include <iostream>
using namespace std;
int main () {
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Hello World - First CGI Program</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "<h2>Hello World! This is my first CGI program</h2>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}
編譯上述程式碼並將可執行檔案命名為 cplusplus.cgi。此檔案儲存在 /var/www/cgi-bin 目錄中,其內容如下。在執行 CGI 程式之前,請確保已使用 chmod 755 cplusplus.cgi UNIX 命令更改檔案的模式以使其可執行。
我的第一個 CGI 程式
上述 C++ 程式是一個簡單的程式,它將其輸出寫入 STDOUT 檔案,即螢幕。還有一個重要的附加功能,即第一行列印 Content-type:text/html\r\n\r\n。此行被髮送回瀏覽器,並指定要在瀏覽器螢幕上顯示的內容型別。現在您必須已經理解了 CGI 的基本概念,並且可以使用 Python 編寫許多複雜的 CGI 程式。C++ CGI 程式可以與任何其他外部系統(例如 RDBMS)互動以交換資訊。
HTTP 頭
Content-type:text/html\r\n\r\n 行是 HTTP 頭的一部分,它被髮送到瀏覽器以理解內容。所有 HTTP 頭都將採用以下形式:
HTTP Field Name: Field Content For Example Content-type: text/html\r\n\r\n
還有一些其他重要的 HTTP 頭,您將在 CGI 程式設計中經常使用。
| 序號 | 頭及描述 |
|---|---|
| 1 | Content-type 定義返回檔案的格式的 MIME 字串。例如 Content-type:text/html。 |
| 2 | Expires: Date 資訊失效的日期。瀏覽器應使用此日期來決定何時需要重新整理頁面。有效的日期字串應採用 01 Jan 1998 12:00:00 GMT 格式。 |
| 3 | Location: URL 應返回的 URL,而不是請求的 URL。您可以使用此欄位將請求重定向到任何檔案。 |
| 4 | Last-modified: Date 資源上次修改的日期。 |
| 5 | Content-length: N 返回資料的長度(以位元組為單位)。瀏覽器使用此值來報告檔案的估計下載時間。 |
| 6 | Set-Cookie: String 設定透過 string 傳遞的 Cookie。 |
CGI 環境變數
所有 CGI 程式都可以訪問以下環境變數。這些變數在編寫任何 CGI 程式時都起著重要的作用。
| 序號 | 變數名稱及描述 |
|---|---|
| 1 | CONTENT_TYPE 內容的資料型別,在客戶端向伺服器傳送附加內容時使用。例如檔案上傳等。 |
| 2 | CONTENT_LENGTH 只有 POST 請求才可用的查詢資訊長度。 |
| 3 | HTTP_COOKIE 以鍵值對的形式返回設定的 Cookie。 |
| 4 | HTTP_USER_AGENT User-Agent 請求頭欄位包含有關發起請求的使用者代理的資訊。它是 Web 瀏覽器的名稱。 |
| 5 | PATH_INFO CGI 指令碼的路徑。 |
| 6 | QUERY_STRING 使用 GET 方法請求傳送的 URL 編碼資訊。 |
| 7 | REMOTE_ADDR 發出請求的遠端主機的 IP 地址。這對於日誌記錄或身份驗證非常有用。 |
| 8 | REMOTE_HOST 發出請求的主機的完全限定名稱。如果此資訊不可用,則可以使用 REMOTE_ADDR 獲取 IR 地址。 |
| 9 | REQUEST_METHOD 用於發出請求的方法。最常用的方法是 GET 和 POST。 |
| 10 | SCRIPT_FILENAME CGI 指令碼的完整路徑。 |
| 11 | SCRIPT_NAME CGI 指令碼的名稱。 |
| 12 | SERVER_NAME 伺服器的主機名或 IP 地址。 |
| 13 | SERVER_SOFTWARE 伺服器正在執行的軟體的名稱和版本。 |
這是一個小的 CGI 程式,用於列出所有 CGI 變數。
#include <iostream>
#include <stdlib.h>
using namespace std;
const string ENV[ 24 ] = {
"COMSPEC", "DOCUMENT_ROOT", "GATEWAY_INTERFACE",
"HTTP_ACCEPT", "HTTP_ACCEPT_ENCODING",
"HTTP_ACCEPT_LANGUAGE", "HTTP_CONNECTION",
"HTTP_HOST", "HTTP_USER_AGENT", "PATH",
"QUERY_STRING", "REMOTE_ADDR", "REMOTE_PORT",
"REQUEST_METHOD", "REQUEST_URI", "SCRIPT_FILENAME",
"SCRIPT_NAME", "SERVER_ADDR", "SERVER_ADMIN",
"SERVER_NAME","SERVER_PORT","SERVER_PROTOCOL",
"SERVER_SIGNATURE","SERVER_SOFTWARE" };
int main () {
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>CGI Environment Variables</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "<table border = \"0\" cellspacing = \"2\">";
for ( int i = 0; i < 24; i++ ) {
cout << "<tr><td>" << ENV[ i ] << "</td><td>";
// attempt to retrieve value of environment variable
char *value = getenv( ENV[ i ].c_str() );
if ( value != 0 ) {
cout << value;
} else {
cout << "Environment variable does not exist.";
}
cout << "</td></tr>\n";
}
cout << "</table><\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}
C++ CGI 庫
對於實際示例,您需要透過 CGI 程式執行許多操作。有一個為 C++ 程式編寫的 CGI 庫,您可以從 ftp://ftp.gnu.org/gnu/cgicc/ 下載,並按照步驟安裝該庫:
$tar xzf cgicc-X.X.X.tar.gz $cd cgicc-X.X.X/ $./configure --prefix=/usr $make $make install
您可以檢視在 ‘C++ CGI 庫文件’ 中提供的相關文件。
GET 和 POST 方法
您肯定遇到過許多需要將某些資訊從瀏覽器傳遞到 Web 伺服器,最終傳遞到 CGI 程式的情況。瀏覽器最常使用兩種方法將此資訊傳遞到 Web 伺服器。這些方法是 GET 方法和 POST 方法。
使用 GET 方法傳遞資訊
GET 方法傳送附加到頁面請求的編碼使用者資訊。頁面和編碼資訊由 ? 字元分隔,如下所示:
http://www.test.com/cgi-bin/cpp.cgi?key1=value1&key2=value2
GET 方法是將資訊從瀏覽器傳遞到 Web 伺服器的預設方法,它會生成一個長字串,該字串顯示在瀏覽器的 Location: 框中。如果要將密碼或其他敏感資訊傳遞到伺服器,切勿使用 GET 方法。GET 方法有大小限制,您最多可以在請求字串中傳遞 1024 個字元。
使用 GET 方法時,資訊使用 QUERY_STRING http 頭傳遞,並且可以透過 QUERY_STRING 環境變數在 CGI 程式中訪問。
您可以透過簡單地連線鍵值對以及任何URL來傳遞資訊,也可以使用HTML <FORM>標籤使用GET方法傳遞資訊。
簡單的URL示例:GET方法
這是一個簡單的URL,它將使用GET方法將兩個值傳遞給hello_get.py程式。
/cgi-bin/cpp_get.cgi?first_name=ZARA&last_name=ALI下面是一個程式,用於生成cpp_get.cgi CGI程式來處理Web瀏覽器提供的輸入。我們將使用C++ CGI庫,這使得訪問傳遞的資訊非常容易。
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Using GET and POST Methods</title>\n";
cout << "</head>\n";
cout << "<body>\n";
form_iterator fi = formData.getElement("first_name");
if( !fi->isEmpty() && fi != (*formData).end()) {
cout << "First name: " << **fi << endl;
} else {
cout << "No text entered for first name" << endl;
}
cout << "<br/>\n";
fi = formData.getElement("last_name");
if( !fi->isEmpty() &&fi != (*formData).end()) {
cout << "Last name: " << **fi << endl;
} else {
cout << "No text entered for last name" << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}
現在,按如下方式編譯上述程式:
$g++ -o cpp_get.cgi cpp_get.cpp -lcgicc
生成cpp_get.cgi並將其放入您的CGI目錄中,然後嘗試使用以下連結訪問:
/cgi-bin/cpp_get.cgi?first_name=ZARA&last_name=ALI這將生成以下結果:
First name: ZARA Last name: ALI
簡單的表單示例:GET方法
這是一個簡單的示例,它使用HTML表單和提交按鈕傳遞兩個值。我們將使用相同的CGI指令碼cpp_get.cgi來處理此輸入。
<form action = "/cgi-bin/cpp_get.cgi" method = "get"> First Name: <input type = "text" name = "first_name"> <br /> Last Name: <input type = "text" name = "last_name" /> <input type = "submit" value = "Submit" /> </form>
這是上面表單的實際輸出。您輸入名字和姓氏,然後單擊提交按鈕檢視結果。
使用POST方法傳遞資訊
將資訊傳遞給CGI程式的一種通常更可靠的方法是POST方法。此方法以與GET方法完全相同的方式打包資訊,但不是將其作為文字字串傳送到URL中的?之後,而是將其作為單獨的訊息傳送。此訊息以標準輸入的形式進入CGI指令碼。
相同的cpp_get.cgi程式也將處理POST方法。讓我們採用與上述相同的示例,它使用HTML表單和提交按鈕傳遞兩個值,但這次使用POST方法,如下所示:
<form action = "/cgi-bin/cpp_get.cgi" method = "post"> First Name: <input type = "text" name = "first_name"><br /> Last Name: <input type = "text" name = "last_name" /> <input type = "submit" value = "Submit" /> </form>
這是上面表單的實際輸出。您輸入名字和姓氏,然後單擊提交按鈕檢視結果。
將複選框資料傳遞給CGI程式
當需要選擇多個選項時,使用複選框。
這是一個帶有兩個複選框的表單的HTML程式碼示例:
<form action = "/cgi-bin/cpp_checkbox.cgi" method = "POST" target = "_blank"> <input type = "checkbox" name = "maths" value = "on" /> Maths <input type = "checkbox" name = "physics" value = "on" /> Physics <input type = "submit" value = "Select Subject" /> </form>
此程式碼的結果是以下表單:
下面是C++程式,它將生成cpp_checkbox.cgi指令碼以處理Web瀏覽器透過複選框按鈕提供的輸入。
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
bool maths_flag, physics_flag;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Checkbox Data to CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
maths_flag = formData.queryCheckbox("maths");
if( maths_flag ) {
cout << "Maths Flag: ON " << endl;
} else {
cout << "Maths Flag: OFF " << endl;
}
cout << "<br/>\n";
physics_flag = formData.queryCheckbox("physics");
if( physics_flag ) {
cout << "Physics Flag: ON " << endl;
} else {
cout << "Physics Flag: OFF " << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}
將單選按鈕資料傳遞給CGI程式
單選按鈕僅用於選擇一個選項。
這是一個帶有兩個單選按鈕的表單的HTML程式碼示例:
<form action = "/cgi-bin/cpp_radiobutton.cgi" method = "post" target = "_blank"> <input type = "radio" name = "subject" value = "maths" checked = "checked"/> Maths <input type = "radio" name = "subject" value = "physics" /> Physics <input type = "submit" value = "Select Subject" /> </form>
此程式碼的結果是以下表單:
下面是C++程式,它將生成cpp_radiobutton.cgi指令碼以處理Web瀏覽器透過單選按鈕提供的輸入。
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Radio Button Data to CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
form_iterator fi = formData.getElement("subject");
if( !fi->isEmpty() && fi != (*formData).end()) {
cout << "Radio box selected: " << **fi << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}
將文字區域資料傳遞給CGI程式
當必須將多行文字傳遞給CGI程式時,使用TEXTAREA元素。
這是一個帶有文字區域框的表單的HTML程式碼示例:
<form action = "/cgi-bin/cpp_textarea.cgi" method = "post" target = "_blank">
<textarea name = "textcontent" cols = "40" rows = "4">
Type your text here...
</textarea>
<input type = "submit" value = "Submit" />
</form>
此程式碼的結果是以下表單:
下面是C++程式,它將生成cpp_textarea.cgi指令碼以處理Web瀏覽器透過文字區域提供的輸入。
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Text Area Data to CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
form_iterator fi = formData.getElement("textcontent");
if( !fi->isEmpty() && fi != (*formData).end()) {
cout << "Text Content: " << **fi << endl;
} else {
cout << "No text entered" << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}
將下拉框資料傳遞給CGI程式
當有很多選項可用,但只選擇一兩個時,使用下拉框。
這是一個帶有下拉框的表單的HTML程式碼示例:
<form action = "/cgi-bin/cpp_dropdown.cgi" method = "post" target = "_blank">
<select name = "dropdown">
<option value = "Maths" selected>Maths</option>
<option value = "Physics">Physics</option>
</select>
<input type = "submit" value = "Submit"/>
</form>
此程式碼的結果是以下表單:
下面是C++程式,它將生成cpp_dropdown.cgi指令碼以處理Web瀏覽器透過下拉框提供的輸入。
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Drop Down Box Data to CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
form_iterator fi = formData.getElement("dropdown");
if( !fi->isEmpty() && fi != (*formData).end()) {
cout << "Value Selected: " << **fi << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}
在CGI中使用Cookie
HTTP協議是一種無狀態協議。但是對於商業網站來說,需要在不同的頁面之間維護會話資訊。例如,一個使用者註冊在完成許多頁面後結束。但是如何跨所有網頁維護使用者的會話資訊呢?
在許多情況下,使用cookie是記住和跟蹤偏好、購買、佣金以及其他改善訪問者體驗或網站統計資訊所需資訊的最高效方法。
工作原理
您的伺服器以cookie的形式向訪問者的瀏覽器傳送一些資料。瀏覽器可能會接受cookie。如果接受,則將其作為純文字記錄儲存在訪問者的硬碟驅動器上。現在,當訪問者到達您網站上的另一個頁面時,cookie即可供檢索。檢索後,您的伺服器就知道/記得儲存了什麼。
cookie是5個變長欄位的純文字資料記錄:
過期時間 - 這顯示cookie將過期的日期。如果為空,則cookie將在訪問者退出瀏覽器時過期。
域 - 這顯示您網站的域名。
路徑 - 這顯示設定cookie的目錄或網頁的路徑。如果您想從任何目錄或頁面檢索cookie,這可以為空。
安全 - 如果此欄位包含單詞“安全”,則cookie只能使用安全伺服器檢索。如果此欄位為空,則不存在此類限制。
名稱=值 - cookie以鍵值對的形式設定和檢索。
設定Cookie
向瀏覽器傳送cookie非常容易。這些cookie將在“Content-type”欄位之前的HTTP標頭中傳送。假設您想將UserID和Password設定為cookie。因此,cookie設定將按如下方式完成
#include <iostream>
using namespace std;
int main () {
cout << "Set-Cookie:UserID = XYZ;\r\n";
cout << "Set-Cookie:Password = XYZ123;\r\n";
cout << "Set-Cookie:Domain = www.tutorialspoint.com;\r\n";
cout << "Set-Cookie:Path = /perl;\n";
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Cookies in CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "Setting cookies" << endl;
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}
透過此示例,您必須瞭解如何設定cookie。我們使用Set-Cookie HTTP標頭來設定cookie。
在這裡,可以選擇設定cookie屬性,如過期時間、域和路徑。值得注意的是,cookie是在傳送神奇行“Content-type:text/html\r\n\r\n”之前設定的。
編譯上述程式以生成setcookies.cgi,並嘗試使用以下連結設定cookie。它將在您的計算機上設定四個cookie:
檢索Cookie
檢索所有已設定的cookie很容易。cookie儲存在CGI環境變數HTTP_COOKIE中,它們將具有以下形式。
key1 = value1; key2 = value2; key3 = value3....
這是一個檢索cookie的示例。
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc cgi;
const_cookie_iterator cci;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Cookies in CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "<table border = \"0\" cellspacing = \"2\">";
// get environment variables
const CgiEnvironment& env = cgi.getEnvironment();
for( cci = env.getCookieList().begin();
cci != env.getCookieList().end();
++cci ) {
cout << "<tr><td>" << cci->getName() << "</td><td>";
cout << cci->getValue();
cout << "</td></tr>\n";
}
cout << "</table><\n";
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}
現在,編譯上述程式以生成getcookies.cgi,並嘗試獲取計算機上所有可用cookie的列表:
這將生成上一節中設定的全部四個cookie以及您計算機上設定的所有其他cookie的列表:
UserID XYZ Password XYZ123 Domain www.tutorialspoint.com Path /perl
檔案上傳示例
要上傳檔案,HTML表單必須將enctype屬性設定為multipart/form-data。帶有檔案型別的input標籤將建立一個“瀏覽”按鈕。
<html>
<body>
<form enctype = "multipart/form-data" action = "/cgi-bin/cpp_uploadfile.cgi"
method = "post">
<p>File: <input type = "file" name = "userfile" /></p>
<p><input type = "submit" value = "Upload" /></p>
</form>
</body>
</html>
此程式碼的結果是以下表單:
注意 - 上述示例已被故意停用,以阻止人們將檔案上傳到我們的伺服器。但是您可以嘗試使用您的伺服器上的上述程式碼。
這是處理檔案上傳的指令碼cpp_uploadfile.cpp:
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc cgi;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>File Upload in CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
// get list of files to be uploaded
const_file_iterator file = cgi.getFile("userfile");
if(file != cgi.getFiles().end()) {
// send data type at cout.
cout << HTTPContentHeader(file->getDataType());
// write content at cout.
file->writeToStream(cout);
}
cout << "<File uploaded successfully>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}
上面的示例用於在cout流中寫入內容,但是您可以開啟檔案流並將上傳檔案的內容儲存到所需位置的檔案中。
希望您喜歡本教程。如果喜歡,請給我們傳送您的反饋。