- CatBoost 教程
- CatBoost - 首頁
- CatBoost - 概述
- CatBoost - 架構
- CatBoost - 安裝
- CatBoost - 特性
- CatBoost - 決策樹
- CatBoost - Boosting 過程
- CatBoost - 核心引數
- CatBoost - 資料預處理
- CatBoost - 處理類別特徵
- CatBoost - 處理缺失值
- CatBoost - 分類器
- CatBoost - 迴歸器
- CatBoost - 排序器
- CatBoost - 模型訓練
- CatBoost - 模型評估指標
- CatBoost - 分類指標
- CatBoost - 過擬合檢測
- CatBoost 與其他 Boosting 演算法的比較
- CatBoost 有用資源
- CatBoost - 有用資源
- CatBoost - 討論
CatBoost - 過擬合檢測
過擬合是指模型在訓練資料上表現良好,但在未知資料上表現較差的現象。CatBoost 提供了評估過擬合的指標。
以下是一些常見的 CatBoost 指標,用於解釋過擬合防護:
交叉驗證
交叉驗證是尋找和降低過擬合的最重要的機器學習方法之一。透過比較訓練和驗證效能,交叉驗證有助於檢測過擬合。
此方法使用交叉驗證分析 CatBoostClassifier 模型在 Iris 資料集上的效能。使用交叉驗證是一種常見的避免過擬合的方法,過擬合是指模型由於過度調整到訓練資料而無法在新資料上良好執行的情況。此外,交叉驗證提高了我們對模型真實效能的理解。為了確定模型的效能水平,它確定了許多指標。
# Import required libraries
import numpy as np
from catboost import CatBoostClassifier, Pool, cv
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load the required dataset
iris = load_iris()
X, y = iris.data, iris.target
# Generate a CatBoost Pool object
data_pool = Pool(X, label=y)
# Defining the CatBoostClassifier parameters
params = {
'iterations': 100,
'learning_rate': 0.1,
'depth': 6,
'loss_function': 'MultiClass',
'verbose': 0
}
# Do cross-validation
cv_results = cv(pool=data_pool,
params=params,
fold_count=5,
shuffle=True,
partition_random_seed=42,
verbose_eval=False)
# Print the results
for metric_name in cv_results.columns:
if 'test-' in metric_name:
mean_score = cv_results[metric_name].iloc[-1]
print(f'{metric_name}: {mean_score:.4f}')
輸出
這將產生以下結果:
Training on fold [0/5] bestTest = 0.1226007055 bestIteration = 72 Training on fold [1/5] bestTest = 0.09388296402 bestIteration = 99 Training on fold [2/5] bestTest = 0.05707644554 bestIteration = 99 Training on fold [3/5] bestTest = 0.1341533772 bestIteration = 93 Training on fold [4/5] bestTest = 0.19934632 bestIteration = 94 test-MultiClass-mean: 0.1221 test-MultiClass-std: 0.0531
特徵重要性
CatBoost 還提供特徵重要性評分。它可以用於確定特徵的重要性及其效用,以及它們如何影響模型做出的預測。透過突出顯示影響模型預測的變數,可以使用特徵重要性來檢測過擬合。如果某個特徵對模型的預測沒有影響,它就可能過度擬合到模型中。
生成的條形圖將突出顯示每個特徵在模型預測中的重要性。藉助此資料,可以識別對分類過程最重要的特徵,從而對工程或特徵選擇工作進行排序。
import numpy as np
import matplotlib.pyplot as plt
from catboost import CatBoostClassifier, Pool
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load the Iris dataset
iris_dataset = load_iris()
X_data, y_labels = iris_dataset.data, iris_dataset.target
# Split the data into training and testing sets
X_train_data, X_test_data, y_train_labels, y_test_labels = train_test_split(X_data, y_labels, test_size=0.2, random_state=42)
# Create a CatBoostClassifier
catboost_model = CatBoostClassifier(iterations=100, learning_rate=0.1, depth=6, loss_function='MultiClass', verbose=0)
# Train the model
catboost_model.fit(X_train_data, y_train_labels)
# Create a Pool object for the testing data
test_data_pool = Pool(X_test_data)
# Get feature importance scores
feature_importance_scores = catboost_model.get_feature_importance(test_data_pool)
# Get feature names
feature_labels = iris_dataset.feature_names
# Plot feature importance with changed color
plt.figure(figsize=(10, 6))
plt.barh(range(len(feature_importance_scores)), feature_importance_scores, color='skyblue', tick_label=feature_labels)
plt.xlabel('Feature Importance Score')
plt.ylabel('Features')
plt.title('Feature Importance for CatBoost Classifier')
plt.show()
輸出
以下是使用上述程式碼生成的結果:
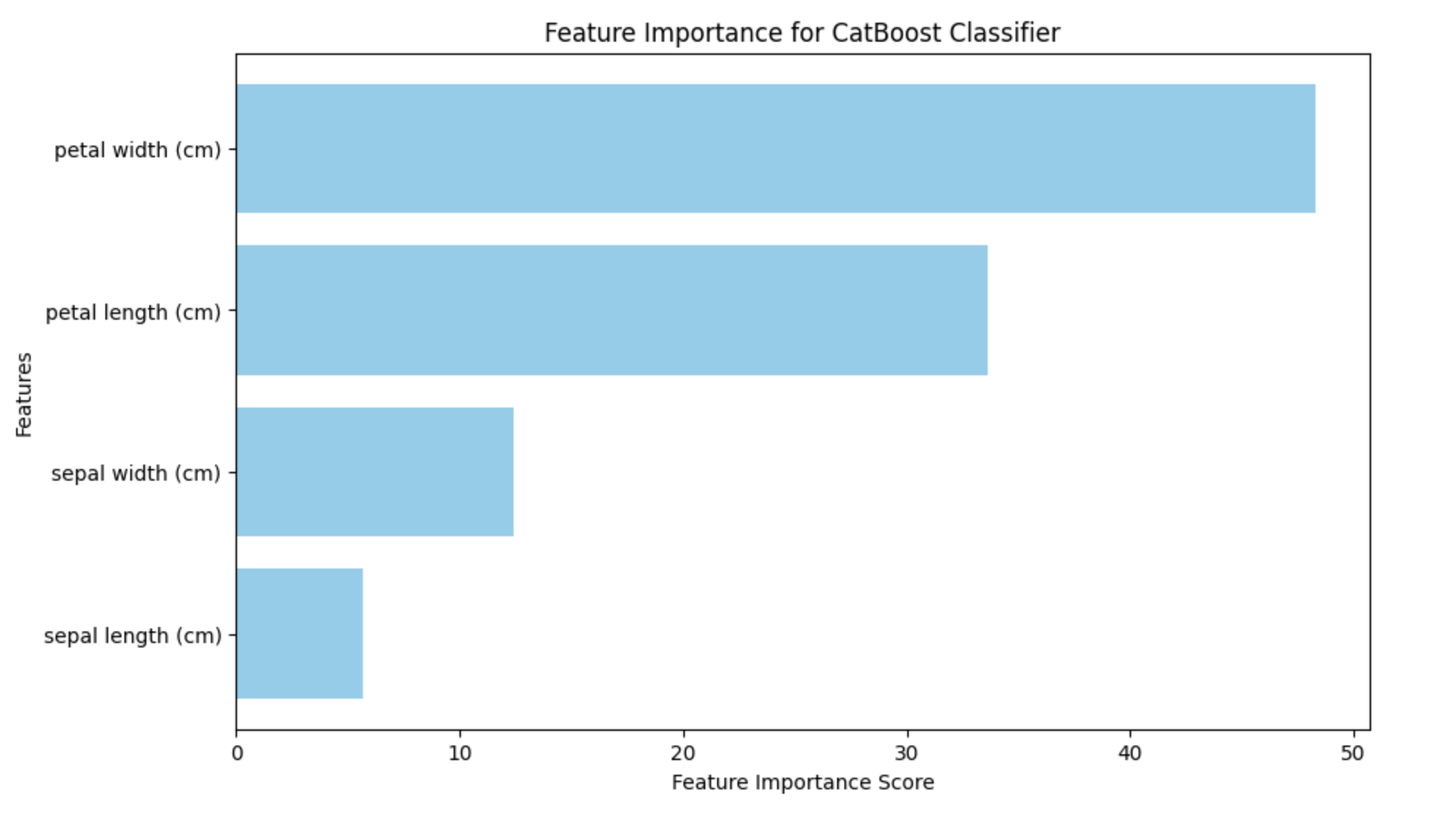
識別過擬合很大程度上也取決於學習曲線。CatBoost 中沒有不同的學習曲線繪圖技術。但是,可以使用其他 Python 程式(如 matplotlib)進行繪製。
廣告