- CatBoost 教程
- CatBoost - 首頁
- CatBoost - 概述
- CatBoost - 架構
- CatBoost - 安裝
- CatBoost - 特性
- CatBoost - 決策樹
- CatBoost - Boosting 過程
- CatBoost - 核心引數
- CatBoost - 資料預處理
- CatBoost - 處理類別特徵
- CatBoost - 處理缺失值
- CatBoost - 分類器
- CatBoost - 迴歸器
- CatBoost - 排序器
- CatBoost - 模型訓練
- CatBoost - 模型評估指標
- CatBoost - 分類指標
- CatBoost - 過擬合檢測
- CatBoost 與其他 Boosting 演算法的比較
- CatBoost 有用資源
- CatBoost - 有用資源
- CatBoost - 討論
CatBoost - 架構
CatBoost 是一種機器學習程式,可以生成資料驅動的預測。 “CatBoost”這個名稱來自兩個詞:“categorical”(類別)和“boosting”(提升)。
- 類別資料是可以分成不同類別的的資料,例如顏色(紅色、藍色、綠色)或動物型別(貓、狗、鳥)。
- 提升是一種機器學習技術,它結合多個簡單的模型來生成更強大、更準確的模型。
CatBoost 的架構
CatBoost 架構指的是 CatBoost 工具生成資料驅動預測的能力。CatBoost 基於一種稱為決策樹的機器學習系統。
決策樹的工作原理類似於流程圖,根據接收到的資訊做出決策。樹的每個“分支”代表一個決策,每個“葉子”表示結果。
CatBoost 使用一種稱為“提升”的獨特方法,將多個小的決策樹組合成一個強大的模型。每棵新樹都會糾正之前樹的錯誤,隨著時間的推移提高模型的準確性。
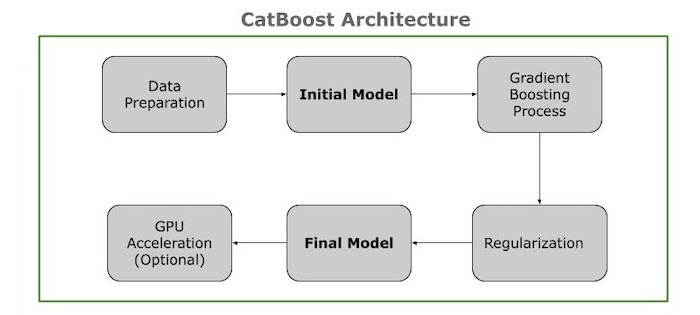
關鍵元件
CatBoost 架構展示了其主要元件和互連關係。以下是架構元件的概述:
資料準備 包含類別和數值特徵,以及目標值。處理缺失值、資料標準化等。將類別特徵轉換為基於目標的編碼。
初始模型 然後,您需要計算一個初始預測,這通常是目標值的平均值。
梯度提升過程 接下來,您需要計算實際值和預測值之間的差異。並僅使用過去的資料(有序提升)進行訓練以生成一致的劃分(對稱樹)。然後將樹插入模型,調整殘差,並重復此過程,直到效能穩定或達到樹的數量。
正則化 在此過程中,您需要新增懲罰以防止過擬合併降低模型複雜度。
最終模型 在此階段,您需要將所有決策樹組合起來形成最終模型。並使用完成的模型來預測新資料的效應。
GPU 加速 使用 GPU 加速計算,尤其是在大型資料集上。
數學表示
CatBoost 需要一個函式 F(x) 來預測給定 N 個樣本和 M 個特徵的訓練資料集的目標變數 y。每個樣本表示為 (xi, yi),其中 xi 是 M 個特徵的向量,yi 是相應的目標變數。
CatBoost 生成各種決策樹。每棵樹都會生成一個預測,並且將估計值合併以提高準確性。
F(x) = F0(x) + ∑Mm=1 fm(x)
這裡:
F(x) 是最終預測。
F0(x) 是初始猜測。
∑Mm=1 fm(x) 是每棵樹的預測之和。
樹 fm(x) 預測資料集中的所有樣本。例如,單個樹可能知道一個人購買產品的可能性。
總結
總而言之,CatBoost 是一款功能強大且使用者友好的梯度提升工具包,非常適合各種應用。無論您是初學者尋找一種簡單的機器學習方法,還是經驗豐富的從業者尋求最佳效能,CatBoost 都是您工具箱中一個寶貴的工具。但與任何工具一樣,其成功取決於具體問題和資料集,因此始終建議進行實驗並將其與其他方法進行比較。