語音識別
語音識別生物識別模式是生理模式和行為模式的結合。語音識別只不過是聲音識別。它依賴於受以下因素影響的特徵:
生理成分 - 人的聲帶、嘴唇、牙齒、舌頭和口腔的物理形狀、大小和健康狀況。
行為成分 - 人說話時的情緒狀態、口音、語調、音調、說話速度、含糊不清等。
語音識別系統
語音識別也稱為說話人識別。在註冊時,使用者需要對著麥克風說一個單詞或短語。這對於獲取候選人的語音樣本是必要的。
來自麥克風的電訊號透過模數轉換器 (ADC) 轉換為數字訊號。它以數字化樣本的形式記錄到計算機記憶體中。然後,計算機比較並嘗試將候選人的輸入語音與儲存的數字化語音樣本進行匹配,並識別候選人。
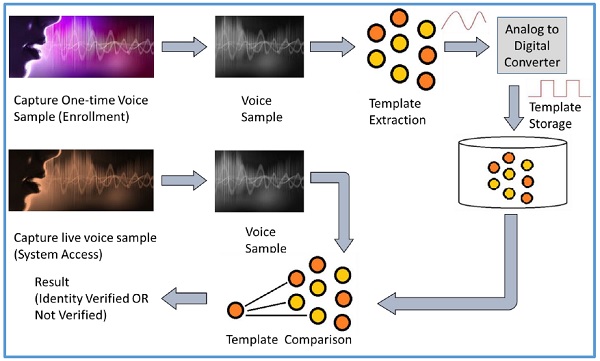
語音識別模式
語音識別有兩種變體:說話人依賴和說話人獨立。
說話人依賴語音識別依賴於候選人特定語音特徵的知識。該系統透過語音訓練(或註冊)學習這些特徵。
在使用該系統識別所說內容之前,需要針對使用者對其進行訓練,使其適應特定的口音和語調。
如果只有一個使用者將使用該系統,這是一個不錯的選擇。
說話人獨立系統能夠透過限制語音的上下文(例如單詞和短語)來識別不同使用者的語音。這些系統用於自動電話介面。
它們不需要針對每個單獨的使用者對系統進行訓練。
它們是不同個人使用的不錯選擇,在這種情況下不需要識別每個候選人的語音特徵。
語音識別和語音識別之間的區別
說話人識別和語音識別被錯誤地認為是相同的;但它們是不同的技術。讓我們看看,如何 -
| 說話人識別(語音識別) | 語音識別 |
|---|---|
| 語音識別的目標是識別“誰”在說話。 | 語音識別旨在理解和理解“說了什麼”。 |
| 它用於透過分析其音調、語音音調和口音來識別一個人。 | 它用於擴音計算、地圖或選單導航。 |
語音識別的優點
- 易於實施。
語音識別的缺點
- 它容易受到麥克風質量和噪音的影響。
無法控制影響輸入系統的因素會顯著降低效能。
某些說話人驗證系統也容易受到通過錄制語音進行的欺騙攻擊。
語音識別的應用
- 執行電話和網際網路交易。
使用基於互動式語音響應 (IRV) 的銀行和醫療保健系統。
- 將音訊簽名應用於數字文件。
- 在娛樂和緊急服務中。
- 在線上教育系統中。
廣告