- Beautiful Soup 教程
- Beautiful Soup - 首頁
- Beautiful Soup - 概述
- Beautiful Soup - 網頁抓取
- Beautiful Soup - 安裝
- Beautiful Soup - 解析頁面
- Beautiful Soup - 物件型別
- Beautiful Soup - 檢查資料來源
- Beautiful Soup - 抓取 HTML 內容
- Beautiful Soup - 透過標籤導航
- Beautiful Soup - 透過 ID 查詢元素
- Beautiful Soup - 透過 Class 查詢元素
- Beautiful Soup - 透過屬性查詢元素
- Beautiful Soup - 搜尋樹結構
- Beautiful Soup - 修改樹結構
- Beautiful Soup - 解析文件的一部分
- Beautiful Soup - 查詢元素的所有子元素
- Beautiful Soup - 使用 CSS 選擇器查詢元素
- Beautiful Soup - 查詢所有註釋
- Beautiful Soup - 從 HTML 中抓取列表
- Beautiful Soup - 從 HTML 中抓取段落
- BeautifulSoup - 從 HTML 中抓取連結
- Beautiful Soup - 獲取所有 HTML 標籤
- Beautiful Soup - 獲取標籤內的文字
- Beautiful Soup - 查詢所有標題
- Beautiful Soup - 提取標題標籤
- Beautiful Soup - 提取電子郵件 ID
- Beautiful Soup - 抓取巢狀標籤
- Beautiful Soup - 解析表格
- Beautiful Soup - 選擇第 n 個子元素
- Beautiful Soup - 透過標籤內的文字搜尋
- Beautiful Soup - 移除 HTML 標籤
- Beautiful Soup - 移除所有樣式
- Beautiful Soup - 移除所有指令碼
- Beautiful Soup - 移除空標籤
- Beautiful Soup - 移除子元素
- Beautiful Soup - find 與 find_all 的區別
- Beautiful Soup - 指定解析器
- Beautiful Soup - 比較物件
- Beautiful Soup - 複製物件
- Beautiful Soup - 獲取標籤位置
- Beautiful Soup - 編碼
- Beautiful Soup - 輸出格式化
- Beautiful Soup - 美化輸出
- Beautiful Soup - NavigableString 類
- Beautiful Soup - 將物件轉換為字串
- Beautiful Soup - 將 HTML 轉換為文字
- Beautiful Soup - 解析 XML
- Beautiful Soup - 錯誤處理
- Beautiful Soup - 故障排除
- Beautiful Soup - 移植舊程式碼
- Beautiful Soup - 函式參考
- Beautiful Soup - contents 屬性
- Beautiful Soup - children 屬性
- Beautiful Soup - string 屬性
- Beautiful Soup - strings 屬性
- Beautiful Soup - stripped_strings 屬性
- Beautiful Soup - descendants 屬性
- Beautiful Soup - parent 屬性
- Beautiful Soup - parents 屬性
- Beautiful Soup - next_sibling 屬性
- Beautiful Soup - previous_sibling 屬性
- Beautiful Soup - next_siblings 屬性
- Beautiful Soup - previous_siblings 屬性
- Beautiful Soup - next_element 屬性
- Beautiful Soup - previous_element 屬性
- Beautiful Soup - next_elements 屬性
- Beautiful Soup - previous_elements 屬性
- Beautiful Soup - find 方法
- Beautiful Soup - find_all 方法
- Beautiful Soup - find_parents 方法
- Beautiful Soup - find_parent 方法
- Beautiful Soup - find_next_siblings 方法
- Beautiful Soup - find_next_sibling 方法
- Beautiful Soup - find_previous_siblings 方法
- Beautiful Soup - find_previous_sibling 方法
- Beautiful Soup - find_all_next 方法
- Beautiful Soup - find_next 方法
- Beautiful Soup - find_all_previous 方法
- Beautiful Soup - find_previous 方法
- Beautiful Soup - select 方法
- Beautiful Soup - append 方法
- Beautiful Soup - extend 方法
- Beautiful Soup - NavigableString 方法
- Beautiful Soup - new_tag 方法
- Beautiful Soup - insert 方法
- Beautiful Soup - insert_before 方法
- Beautiful Soup - insert_after 方法
- Beautiful Soup - clear 方法
- Beautiful Soup - extract 方法
- Beautiful Soup - decompose 方法
- Beautiful Soup - replace_with 方法
- Beautiful Soup - wrap 方法
- Beautiful Soup - unwrap 方法
- Beautiful Soup - smooth 方法
- Beautiful Soup - prettify 方法
- Beautiful Soup - encode 方法
- Beautiful Soup - decode 方法
- Beautiful Soup - get_text 方法
- Beautiful Soup - diagnose 方法
- Beautiful Soup 有用資源
- Beautiful Soup 快速指南
- Beautiful Soup - 有用資源
- Beautiful Soup - 討論
Beautiful Soup 快速指南
Beautiful Soup - 概述
在當今世界,我們擁有大量非結構化資料/資訊(主要是網路資料)可供免費使用。有時這些免費資料易於閱讀,有時則不然。無論你的資料如何呈現,網頁抓取都是一個非常有用的工具,可以將非結構化資料轉換為更易於閱讀和分析的結構化資料。換句話說,網頁抓取是一種收集、整理和分析這些海量資料的方法。所以,讓我們首先了解什麼是網頁抓取。
Beautiful Soup 簡介
Beautiful Soup 是一個 Python 庫,其名稱來源於劉易斯·卡羅爾在《愛麗絲夢遊仙境》中同名的一首詩。Beautiful Soup 是一個 Python 包,顧名思義,它解析不需要的資料,並透過修復不良 HTML 並以易於遍歷的 XML 結構呈現給我們,從而幫助整理和格式化凌亂的網路資料。
簡而言之,Beautiful Soup 是一個 Python 包,它允許我們從 HTML 和 XML 文件中提取資料。
HTML 樹結構
在深入瞭解 Beautiful Soup 提供的功能之前,讓我們首先了解 HTML 樹結構。
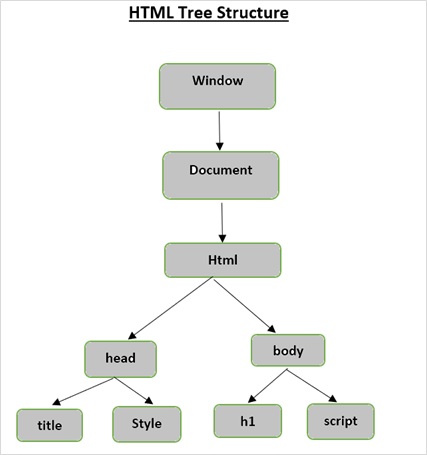
文件樹中的根元素是 html,它可以有父節點、子節點和兄弟節點,這由它在樹結構中的位置決定。要在 HTML 元素、屬性和文字之間移動,必須在樹結構中的節點之間移動。
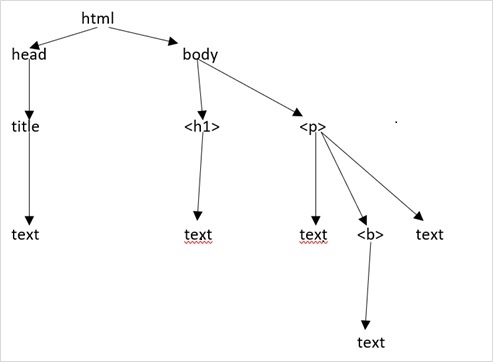
假設網頁如下所示:

它轉換為以下 HTML 文件:
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
</body>
</html>
這僅僅意味著,對於上面的 HTML 文件,我們有如下 HTML 樹結構:
Beautiful Soup - 網頁抓取
抓取僅僅是一個提取(從各種來源)、複製和篩選資料的過程。
當我們從網路(例如從網頁或網站)抓取或提取資料或 Feed 時,稱為網頁抓取。
因此,網頁抓取(也稱為網頁資料提取或網頁收集)是從網路中提取資料。簡而言之,網頁抓取為開發人員提供了一種從網際網路收集和分析資料的方法。
為什麼要進行網頁抓取?
網頁抓取提供了一種強大的工具來自動化人類在瀏覽時執行的大部分操作。企業以多種方式使用網頁抓取:
研究資料
智慧分析師(如研究人員或記者)使用網頁抓取器,而不是手動從網站收集和清理資料。
產品、價格和受歡迎程度比較
目前有一些服務使用網頁抓取器從眾多線上網站收集資料,並將其用於比較產品的受歡迎程度和價格。
SEO 監控
有許多 SEO 工具,如 Ahrefs、Seobility、SEMrush 等,用於競爭對手分析和從客戶網站提取資料。
搜尋引擎
一些大型 IT 公司的業務完全依賴於網頁抓取。
銷售和營銷
透過網頁抓取收集的資料可供營銷人員分析不同的細分市場和競爭對手,或供銷售專家用於銷售內容營銷或社交媒體推廣服務。
為什麼選擇 Python 進行網頁抓取?
Python 是最流行的網頁抓取語言之一,因為它可以非常輕鬆地處理大多數與網路爬取相關的任務。
以下是選擇 Python 進行網頁抓取的一些原因:
易用性
大多數開發人員都認為 Python 非常易於編碼。我們不必在任何地方使用花括號“{}”或分號“;” ,這使得它在開發網頁抓取器時更易於閱讀和使用。
強大的庫支援
Python 為不同的需求提供了大量的庫,因此它適用於網頁抓取以及資料視覺化、機器學習等。
易於理解的語法
Python 是一種非常易讀的程式語言,因為 Python 語法易於理解。Python 非常具有表現力,程式碼縮排幫助使用者區分程式碼中的不同塊或範圍。
動態型別語言
Python 是一種動態型別語言,這意味著分配給變數的資料會告訴我們它是什麼型別的變數。它節省了大量時間,並使工作更快。
龐大的社群
Python 社群非常龐大,無論你在編寫程式碼時遇到什麼問題,都可以獲得幫助。
Beautiful Soup - 安裝
Beautiful Soup 是一個庫,它簡化了從網頁抓取資訊的過程。它位於 HTML 或 XML 解析器的頂部,提供了 Python 風格的習慣用法來迭代、搜尋和修改解析樹。
BeautifulSoup 包不是 Python 標準庫的一部分,因此必須安裝它。在安裝最新版本之前,讓我們根據 Python 的推薦方法建立一個虛擬環境。
虛擬環境允許我們為特定專案建立 Python 的隔離工作副本,而不會影響外部設定。
我們將使用 Python 標準庫中的 venv 模組來建立虛擬環境。PIP 預設包含在 Python 3.4 或更高版本中。
使用以下命令在 Windows 上建立虛擬環境
C:\uses\user\>python -m venv myenv
在 Ubuntu Linux 上,在建立虛擬環境之前,如果需要,請更新 APT 儲存庫並安裝 venv
mvl@GNVBGL3:~ $ sudo apt update && sudo apt upgrade -y mvl@GNVBGL3:~ $ sudo apt install python3-venv
然後使用以下命令建立虛擬環境
mvl@GNVBGL3:~ $ sudo python3 -m venv myenv
你需要啟用虛擬環境。在 Windows 上使用以下命令
C:\uses\user\>cd myenv C:\uses\user\myenv>scripts\activate (myenv) C:\Users\users\user\myenv>
在 Ubuntu Linux 上,使用以下命令啟用虛擬環境
mvl@GNVBGL3:~$ cd myenv mvl@GNVBGL3:~/myenv$ source bin/activate (myenv) mvl@GNVBGL3:~/myenv$
虛擬環境的名稱顯示在括號中。現在它已啟用,我們可以在其中安裝 BeautifulSoup 了。
(myenv) mvl@GNVBGL3:~/myenv$ pip3 install beautifulsoup4
Collecting beautifulsoup4
Downloading beautifulsoup4-4.12.2-py3-none-any.whl (142 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
143.0/143.0 KB 325.2 kB/s eta 0:00:00
Collecting soupsieve>1.2
Downloading soupsieve-2.4.1-py3-none-any.whl (36 kB)
Installing collected packages: soupsieve, beautifulsoup4
Successfully installed beautifulsoup4-4.12.2 soupsieve-2.4.1
請注意,Beautifulsoup4 的最新版本是 4.12.2,需要 Python 3.8 或更高版本。
如果你沒有安裝 easy_install 或 pip,可以下載 Beautiful Soup 4 原始碼壓縮包並使用 setup.py 安裝它。
(myenv) mvl@GNVBGL3:~/myenv$ python setup.py install
要檢查 Beautifulsoup 是否已正確安裝,請在 Python 終端中輸入以下命令:
>>> import bs4 >>> bs4.__version__ '4.12.2'
如果安裝不成功,你將收到 ModuleNotFoundError 錯誤。
你還需要安裝 requests 庫。它是 Python 的 HTTP 庫。
pip3 install requests
安裝解析器
預設情況下,Beautiful Soup 支援 Python 標準庫中包含的 HTML 解析器,但它也支援許多外部第三方 Python 解析器,如 lxml 解析器或 html5lib 解析器。
要安裝 lxml 或 html5lib 解析器,請使用以下命令
pip3 install lxml pip3 install html5lib
這些解析器各有優缺點,如下所示:
解析器:Python 的 html.parser
用法 − BeautifulSoup(markup, "html.parser")
優點
- 內建
- 速度不錯
- 寬容(從 Python 3.2 開始)
缺點
- 速度不如 lxml,寬容度不如 html5lib。
解析器:lxml 的 HTML 解析器
用法 − BeautifulSoup(markup, "lxml")
優點
- 非常快
- 寬鬆的
缺點
-
外部 C 依賴
解析器:lxml 的 XML 解析器
用法 − BeautifulSoup(markup, "lxml-xml")
或 BeautifulSoup(markup, "xml")
優點
- 非常快
- 目前唯一支援的 XML 解析器
缺點
- 外部 C 依賴
解析器:html5lib
用法 − BeautifulSoup(markup, "html5lib")
優點
- 極其寬鬆
- 以與網路瀏覽器相同的方式解析頁面
- 建立有效的 HTML5
缺點
- 非常慢
- 外部 Python 依賴
Beautiful Soup - 解析頁面
現在是時候在一個 html 頁面中測試我們的 Beautiful Soup 包了(以網頁 - https://tutorialspoint.tw/index.htm 為例,您可以選擇任何其他網頁)並從中提取一些資訊。
在下面的程式碼中,我們嘗試從網頁中提取標題 -
示例
from bs4 import BeautifulSoup import requests url = "https://tutorialspoint.tw/index.htm" req = requests.get(url) soup = BeautifulSoup(req.content, "html.parser") print(soup.title)
輸出
<title>Online Courses and eBooks Library<title>
一個常見的任務是從網頁中提取所有 URL。為此,我們只需要新增下面的程式碼行 -
for link in soup.find_all('a'):
print(link.get('href'))
輸出
下面顯示了上述迴圈的部分輸出 -
https://tutorialspoint.tw/index.htm https://tutorialspoint.tw/codingground.htm https://tutorialspoint.tw/about/about_careers.htm https://tutorialspoint.tw/whiteboard.htm https://tutorialspoint.tw/online_dev_tools.htm https://tutorialspoint.tw/business/index.asp https://tutorialspoint.tw/market/teach_with_us.jsp https://#/tutorialspointindia https://www.instagram.com/tutorialspoint_/ https://twitter.com/tutorialspoint https://www.youtube.com/channel/UCVLbzhxVTiTLiVKeGV7WEBg https://tutorialspoint.tw/categories/development https://tutorialspoint.tw/categories/it_and_software https://tutorialspoint.tw/categories/data_science_and_ai_ml https://tutorialspoint.tw/categories/cyber_security https://tutorialspoint.tw/categories/marketing https://tutorialspoint.tw/categories/office_productivity https://tutorialspoint.tw/categories/business https://tutorialspoint.tw/categories/lifestyle https://tutorialspoint.tw/latest/prime-packs https://tutorialspoint.tw/market/index.asp https://tutorialspoint.tw/latest/ebooks … …
要解析本地當前工作目錄中儲存的網頁,請獲取指向 html 檔案的檔案物件,並將其用作 BeautifulSoup() 建構函式的引數。
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
print(soup)
輸出
<html> <head> <title>Hello World</title> </head> <body> <h1 style="text-align:center;">Hello World</h1> </body> </html>
您還可以使用包含 HTML 指令碼的字串作為建構函式的引數,如下所示 -
from bs4 import BeautifulSoup
html = '''
<html>
<head>
<title>Hello World</title>
</head>
<body>
<h1 style="text-align:center;">Hello World</h1>
</body>
</html>
'''
soup = BeautifulSoup(html, 'html.parser')
print(soup)
Beautiful Soup 使用最佳可用的解析器來解析文件。除非另有指定,否則它將使用 HTML 解析器。
Beautiful Soup - 物件型別
當我們將 html 文件或字串傳遞給 beautifulsoup 建構函式時,beautifulsoup 基本上將複雜的 html 頁面轉換為不同的 python 物件。下面我們將討論 bs4 包中定義的四種主要型別的物件。
- 標籤
- 可導航字串
- BeautifulSoup
- 註釋
標籤物件
HTML 標籤用於定義各種型別的內容。BeautifulSoup 中的標籤物件對應於實際頁面或文件中的 HTML 或 XML 標籤。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">TutorialsPoint</b>', 'lxml')
tag = soup.html
print (type(tag))
輸出
<class 'bs4.element.Tag'>
標籤包含許多屬性和方法,標籤的兩個重要特徵是其名稱和屬性。
名稱 (tag.name)
每個標籤都包含一個名稱,可以透過“.name”作為字尾來訪問。tag.name 將返回它所屬的標籤型別。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">TutorialsPoint</b>', 'lxml')
tag = soup.html
print (tag.name)
輸出
html
但是,如果我們更改標籤名稱,則 BeautifulSoup 生成的 HTML 標記中也會反映出來。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">TutorialsPoint</b>', 'lxml')
tag = soup.html
tag.name = "strong"
print (tag)
輸出
<strong><body><b class="boldest">TutorialsPoint</b></body></strong>
屬性 (tag.attrs)
一個標籤物件可以具有任意數量的屬性。在上面的示例中,標籤<b class="boldest">具有一個名為“class”的屬性,其值為“boldest”。任何不是標籤的東西,基本上都是一個屬性,並且必須包含一個值。“attrs”返回屬性及其值的字典。您也可以透過訪問鍵來訪問屬性。
在下面的示例中,Beautifulsoup() 建構函式的字串引數包含 HTML 輸入標籤。“attr”返回輸入標籤的屬性。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup('<input type="text" name="name" value="Raju">', 'lxml')
tag = soup.input
print (tag.attrs)
輸出
{'type': 'text', 'name': 'name', 'value': 'Raju'}
我們可以使用字典運算子或方法對標籤的屬性進行各種修改(新增/刪除/修改)。
在下面的示例中,更新了 value 標籤。更新後的 HTML 字串顯示了更改。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup('<input type="text" name="name" value="Raju">', 'lxml')
tag = soup.input
print (tag.attrs)
tag['value']='Ravi'
print (soup)
輸出
<html><body><input name="name" type="text" value="Ravi"/></body></html>
我們添加了一個新的 id 標籤,並刪除了 value 標籤。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup('<input type="text" name="name" value="Raju">', 'lxml')
tag = soup.input
tag['id']='nm'
del tag['value']
print (soup)
輸出
<html><body><input id="nm" name="name" type="text"/></body></html>
多值屬性
某些 HTML5 屬性可以具有多個值。最常用的是 class 屬性,它可以具有多個 CSS 值。其他包括“rel”、“rev”、“headers”、“accesskey”和“accept-charset”。Beautiful Soup 中的多值屬性顯示為列表。
示例
from bs4 import BeautifulSoup
css_soup = BeautifulSoup('<p class="body"></p>', 'lxml')
print ("css_soup.p['class']:", css_soup.p['class'])
css_soup = BeautifulSoup('<p class="body bold"></p>', 'lxml')
print ("css_soup.p['class']:", css_soup.p['class'])
輸出
css_soup.p['class']: ['body'] css_soup.p['class']: ['body', 'bold']
但是,如果任何屬性包含多個值,但它不是任何版本的 HTML 標準的多值屬性,則 Beautiful Soup 將保留該屬性 -
示例
from bs4 import BeautifulSoup
id_soup = BeautifulSoup('<p id="body bold"></p>', 'lxml')
print ("id_soup.p['id']:", id_soup.p['id'])
print ("type(id_soup.p['id']):", type(id_soup.p['id']))
輸出
id_soup.p['id']: body bold type(id_soup.p['id']): <class 'str'>
可導航字串物件
通常,某個字串放置在某種型別的開始和結束標籤中。瀏覽器的 HTML 引擎在呈現元素時會對字串應用預期的效果。例如,在<b>Hello World</b>中,您會在<b>和</b>標籤中間找到一個字串,以便以粗體顯示。
可導航字串物件表示標籤的內容。它是 bs4.element.NavigableString 類的物件。要訪問內容,請將標籤與“.string”一起使用。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>", 'html.parser')
print (soup.string)
print (type(soup.string))
輸出
Hello, Tutorialspoint! <class 'bs4.element.NavigableString'>
可導航字串物件類似於 Python Unicode 字串。它的一些功能支援遍歷樹和搜尋樹。可導航字串可以使用 str() 函式轉換為 Unicode 字串。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>",'html.parser')
tag = soup.h2
string = str(tag.string)
print (string)
輸出
Hello, Tutorialspoint!
就像 Python 字串是不可變的,可導航字串也不能就地修改。但是,使用 replace_with() 將標籤的內部字串替換為另一個字串。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>",'html.parser')
tag = soup.h2
tag.string.replace_with("OnLine Tutorials Library")
print (tag.string)
輸出
OnLine Tutorials Library
BeautifulSoup 物件
BeautifulSoup 物件表示整個已解析的物件。但是,可以認為它類似於 Tag 物件。當我們嘗試抓取 Web 資源時建立的物件。因為它類似於 Tag 物件,所以它支援解析和搜尋文件樹所需的功能。
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
print (soup)
print (soup.name)
print ('type:',type(soup))
輸出
<html> <head> <title>TutorialsPoint</title> </head> <body> <h2>Departmentwise Employees</h2> <ul> <li>Accounts</li> <ul> <li>Anand</li> <li>Mahesh</li> </ul> <li>HR</li> <ul> <li>Rani</li> <li>Ankita</li> </ul> </ul> </body> </html> [document] type: <class 'bs4.BeautifulSoup'>
BeautifulSoup 物件的 name 屬性始終返回 [document]。
如果將 BeautifulSoup 物件作為引數傳遞給某個函式(例如 replace_with()),則可以組合兩個已解析的文件。
示例
from bs4 import BeautifulSoup
obj1 = BeautifulSoup("<book><title>Python</title></book>", features="xml")
obj2 = BeautifulSoup("<b>Beautiful Soup parser</b>", "lxml")
obj2.find('b').replace_with(obj1)
print (obj2)
輸出
<html><body><book><title>Python</title></book></body></html>
註釋物件
HTML 和 XML 文件中<!-- 和 -->之間編寫的任何文字都被視為註釋。BeautifulSoup 可以將此類註釋文字檢測為 Comment 物件。
示例
from bs4 import BeautifulSoup markup = "<b><!--This is a comment text in HTML--></b>" soup = BeautifulSoup(markup, 'html.parser') comment = soup.b.string print (comment, type(comment))
輸出
This is a comment text in HTML <class 'bs4.element.Comment'>
Comment 物件是一種特殊型別的 NavigableString 物件。prettify() 方法以特殊格式顯示註釋文字 -
示例
print (soup.b.prettify())
輸出
<b> <!--This is a comment text in HTML--> </b>
Beautiful Soup - 檢查資料來源
為了使用 BeautifulSoup 和 Python 抓取網頁,任何 Web 抓取專案的第一步都應該是探索您想要抓取的網站。因此,首先訪問該網站以瞭解站點結構,然後開始提取與您相關的的資訊。
讓我們訪問 TutorialsPoint 的 Python 教程主頁。在瀏覽器中開啟https://tutorialspoint.tw/python3/index.htm。
使用開發者工具可以幫助您瞭解網站的結構。所有現代瀏覽器都安裝了開發者工具。
如果使用 Chrome 瀏覽器,請從右上角選單按鈕 (⋮) 開啟開發者工具,然後選擇更多工具 → 開發者工具。
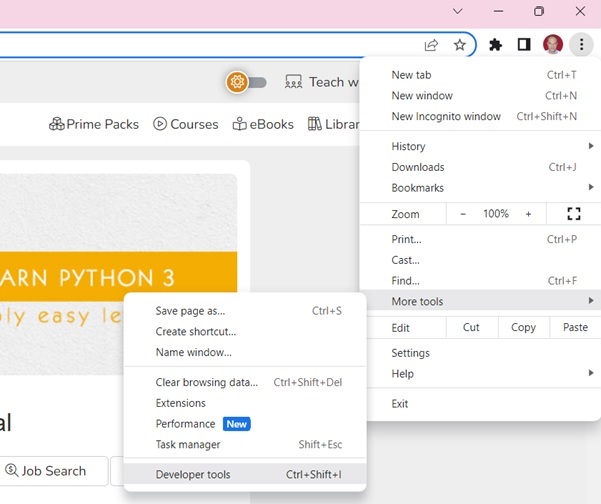
使用開發者工具,您可以瀏覽站點的文件物件模型 (DOM) 以更好地理解您的原始碼。在開發者工具中選擇“元素”選項卡。您將看到一個包含可點選 HTML 元素的結構。
教程頁面在左側邊欄中顯示了目錄。右鍵單擊任何章節,然後選擇“檢查”選項。
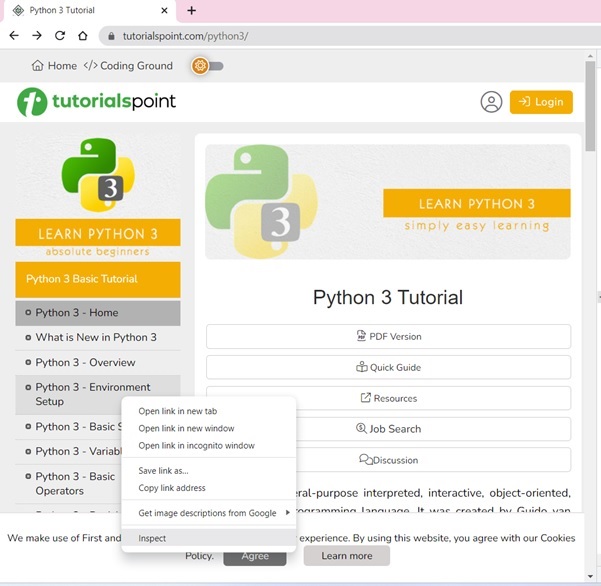
對於“元素”選項卡,找到對應於 TOC 列表的標籤,如下面的圖所示 -

右鍵單擊 HTML 元素,複製 HTML 元素,並將其貼上到任何編輯器中。

現在獲得了<ul>..</ul>元素的 HTML 指令碼。
<ul class="toc chapters"> <li class="heading">Python 3 Basic Tutorial</li> <li class="current-chapter"><a href="/python3/index.htm">Python 3 - Home</a></li> <li><a href="/python3/python3_whatisnew.htm">What is New in Python 3</a></li> <li><a href="/python3/python_overview.htm">Python 3 - Overview</a></li> <li><a href="/python3/python_environment.htm">Python 3 - Environment Setup</a></li> <li><a href="/python3/python_basic_syntax.htm">Python 3 - Basic Syntax</a></li> <li><a href="/python3/python_variable_types.htm">Python 3 - Variable Types</a></li> <li><a href="/python3/python_basic_operators.htm">Python 3 - Basic Operators</a></li> <li><a href="/python3/python_decision_making.htm">Python 3 - Decision Making</a></li> <li><a href="/python3/python_loops.htm">Python 3 - Loops</a></li> <li><a href="/python3/python_numbers.htm">Python 3 - Numbers</a></li> <li><a href="/python3/python_strings.htm">Python 3 - Strings</a></li> <li><a href="/python3/python_lists.htm">Python 3 - Lists</a></li> <li><a href="/python3/python_tuples.htm">Python 3 - Tuples</a></li> <li><a href="/python3/python_dictionary.htm">Python 3 - Dictionary</a></li> <li><a href="/python3/python_date_time.htm">Python 3 - Date & Time</a></li> <li><a href="/python3/python_functions.htm">Python 3 - Functions</a></li> <li><a href="/python3/python_modules.htm">Python 3 - Modules</a></li> <li><a href="/python3/python_files_io.htm">Python 3 - Files I/O</a></li> <li><a href="/python3/python_exceptions.htm">Python 3 - Exceptions</a></li> </ul>
我們現在可以將此指令碼載入到 BeautifulSoup 物件中以解析文件樹。
Beautiful Soup - 抓取 HTML 內容
從網站提取資料的過程稱為 Web 抓取。網頁可能包含 url、電子郵件地址、影像或任何其他內容,我們可以將其儲存在檔案或資料庫中。手動搜尋網站是一個繁瑣的過程。有不同的 Web 抓取工具可以自動化此過程。
有時,使用“robots.txt”檔案會禁止 Web 抓取。一些受歡迎的網站提供 API 以結構化的方式訪問其資料。不道德的 Web 抓取可能會導致您的 IP 被阻止。
Python 廣泛用於 Web 抓取。Python 標準庫具有 urllib 包,可用於從 HTML 頁面提取資料。由於 urllib 模組與標準庫捆綁在一起,因此無需安裝。
urllib 包是 Python 程式語言的 HTTP 客戶端。urllib.request 模組在我們想要開啟和讀取 URL 時很有用。urllib 包中的其他模組有 -
urllib.error 定義了 urllib.request 命令引發的異常和錯誤。
urllib.parse 用於解析 URL。
urllib.robotparser 用於解析 robots.txt 檔案。
使用 urllib 模組中的 urlopen() 函式從網站讀取網頁內容。
import urllib.request
response = urllib.request.urlopen('https://python.club.tw/')
html = response.read()
您也可以為此目的使用 requests 庫。您需要先安裝它才能使用。
pip3 install requests
在下面的程式碼中,抓取了https://tutorialspoint.tw的主頁 -
from bs4 import BeautifulSoup import requests url = "https://tutorialspoint.tw/index.htm" req = requests.get(url)
然後使用 Beautiful Soup 解析透過上述兩種方法中的任何一種獲得的內容。
Beautiful Soup - 透過標籤導航
任何 HTML 文件中重要的元素之一是標籤,它們可能包含其他標籤/字串(標籤的子元素)。Beautiful Soup 提供了不同的方法來導航和迭代標籤的子元素。
搜尋解析樹最簡單的方法是按名稱搜尋標籤。
soup.head
soup.head 函式返回放在 HTML 頁面<head> .. </head>元素內部的內容。
Consider the following HTML page to be scraped:
<html>
<head>
<title>TutorialsPoint</title>
<script>
document.write("Welcome to TutorialsPoint");
</script>
</head>
<body>
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
</body>
</html>
以下程式碼提取<head>元素的內容
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
print(soup.head)
輸出
<head>
<title>TutorialsPoint</title>
<script>
document.write("Welcome to TutorialsPoint");
</script>
</head>
soup.body
類似地,要返回 HTML 頁面的 body 部分的內容,請使用 soup.body
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
print (soup.body)
輸出
<body> <h1>Tutorialspoint Online Library</h1> <p><b>It's all Free</b></p> </body>
您還可以提取<body>標籤中的特定標籤(如第一個<h1>標籤)。
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
print(soup.body.h1)
輸出
<h1>Tutorialspoint Online Library</h1>
soup.p
我們的 HTML 檔案包含一個<p>標籤。我們可以提取此標籤的內容
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
print(soup.p)
輸出
<p><b>It's all Free</b></p>
Tag.contents
Tag 物件可能具有一個或多個 PageElements。Tag 物件的 contents 屬性返回其中包含的所有元素的列表。
讓我們在 index.html 檔案的<head>標籤中找到元素。
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.head
print (tag.contents)
輸出
['\n',
<title>TutorialsPoint</title>,
'\n',
<script>
document.write("Welcome to TutorialsPoint");
</script>,
'\n']
Tag.children
HTML 指令碼中標籤的結構是分層的。元素巢狀在另一個元素內部。例如,頂級<HTML>標籤包含<HEAD>和<BODY>標籤,每個標籤都可能包含其他標籤。
Tag 物件具有一個 children 屬性,該屬性返回一個列表迭代器物件,其中包含封閉的 PageElements。
為了演示 children 屬性,我們將使用以下 HTML 指令碼 (index.html)。在<body>部分,有兩個<ul>列表元素,一個巢狀在另一個內部。換句話說,body 標籤具有頂級列表元素,每個列表元素在其下方都有另一個列表。
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h2>Departmentwise Employees</h2>
<ul>
<li>Accounts</li>
<ul>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ul>
<li>Rani</li>
<li>Ankita</li>
</ul>
</ul>
</body>
</html>
以下 Python 程式碼給出了頂級<ul>標籤的所有子元素的列表。
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.ul
print (list(tag.children))
輸出
['\n', <li>Accounts</li>, '\n', <ul> <li>Anand</li> <li>Mahesh</li> </ul>, '\n', <li>HR</li>, '\n', <ul> <li>Rani</li> <li>Ankita</li> </ul>, '\n']
由於 .children 屬性返回一個列表迭代器,因此我們可以使用 for 迴圈來遍歷層次結構。
示例
for child in tag.children: print (child)
輸出
<li>Accounts</li> <ul> <li>Anand</li> <li>Mahesh</li> </ul> <li>HR</li> <ul> <li>Rani</li> <li>Ankita</li> </ul>
Tag.find_all()
此方法返回與提供的引數標籤匹配的所有標籤內容的結果集。
讓我們考慮以下 HTML 頁面 (index.html) -
<html>
<body>
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
<a class="prog" href="https://tutorialspoint.tw/java/java_overview.htm" id="link1">Java</a>
<a class="prog" href="https://tutorialspoint.tw/cprogramming/index.htm" id="link2">C</a>
<a class="prog" href="https://tutorialspoint.tw/python/index.htm" id="link3">Python</a>
<a class="prog" href="https://tutorialspoint.tw/javascript/javascript_overview.htm" id="link4">JavaScript</a>
<a class="prog" href="https://tutorialspoint.tw/ruby/index.htm" id="link5">C</a>
</body>
</html>
以下程式碼列出了所有具有<a>標籤的元素
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
result = soup.find_all("a")
print (result)
輸出
[ <a class="prog" href="https://tutorialspoint.tw/java/java_overview.htm" id="link1">Java</a>, <a class="prog" href="https://tutorialspoint.tw/cprogramming/index.htm" id="link2">C</a>, <a class="prog" href="https://tutorialspoint.tw/python/index.htm" id="link3">Python</a>, <a class="prog" href="https://tutorialspoint.tw/javascript/javascript_overview.htm" id="link4">JavaScript</a>, <a class="prog" href="https://tutorialspoint.tw/ruby/index.htm" id="link5">C</a> ]
Beautiful Soup - 透過 ID 查詢元素
在 HTML 文件中,通常每個元素都分配一個唯一的 ID。這使得可以透過前端程式碼(如 JavaScript 函式)提取元素的值。
使用 BeautifulSoup,您可以透過其 ID 找到給定元素的內容。可以透過兩種方法實現此目的 - find() 和 find_all(),以及 select()
使用 find() 方法
BeautifulSoup 物件的 find() 方法搜尋第一個滿足作為引數給定條件的元素。
讓我們為此目的使用以下 HTML 指令碼(作為 index.html)
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
以下 Python 程式碼查詢其 id 為 nm 的元素
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.find(id = 'nm')
print (obj)
輸出
<input id="nm" name="name" type="text"/>
使用 find_all()
find_all() 方法也接受一個 filter 引數。它返回具有給定 id 的所有元素的列表。在某些 HTML 文件中,通常只有一個具有特定 id 的元素。因此,使用 find() 而不是 find_all() 更適合搜尋給定的 id。
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.find_all(id = 'nm')
print (obj)
輸出
[<input id="nm" name="name" type="text"/>]
請注意,find_all() 方法返回一個列表。find_all() 方法還有一個 limit 引數。將 find_all() 的 limit 設定為 1 等效於 find()
obj = soup.find_all(id = 'nm', limit=1)
使用 select() 方法
BeautifulSoup 類中的 select() 方法接受 CSS 選擇器作為引數。# 符號是 id 的 CSS 選擇器。它後面跟著所需 id 的值傳遞給 select() 方法。它的作用與 find_all() 方法相同。
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.select("#nm")
print (obj)
輸出
[<input id="nm" name="name" type="text"/>]
使用 select_one()
與 find_all() 方法類似,select() 方法也返回一個列表。還有一個 select_one() 方法用於返回給定引數的第一個標籤。
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.select_one("#nm")
print (obj)
輸出
<input id="nm" name="name" type="text"/>
Beautiful Soup - 透過 Class 查詢元素
CSS(層疊樣式表)是用於設計 HTML 元素外觀的工具。CSS 規則控制 HTML 元素的不同方面,例如大小、顏色、對齊方式等。應用樣式比定義 HTML 元素屬性更有效。您可以將樣式規則應用於每個 HTML 元素。與其分別對每個元素應用樣式,不如使用 CSS 類將類似的樣式應用於 HTML 元素組,以實現統一的網頁外觀。在 BeautifulSoup 中,可以找到使用 CSS 類設定樣式的標籤。在本章中,我們將使用以下方法搜尋指定 CSS 類的元素:
- find_all() 和 find() 方法
- select() 和 select_one() 方法
CSS 中的類
CSS 中的類是指定與外觀相關的不同特徵(例如字型型別、大小和顏色、背景顏色、對齊方式等)的屬性的集合。宣告類時,類名字首為點(.)。
.class {
css declarations;
}
CSS 類可以內聯定義,也可以在需要包含在 HTML 指令碼中的單獨 css 檔案中定義。CSS 類的典型示例如下:
.blue-text {
color: blue;
font-weight: bold;
}
您可以藉助以下 BeautifulSoup 方法搜尋使用特定類樣式定義的 HTML 元素。
出於本章的目的,我們將使用以下 HTML 頁面:
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h2 class="heading">Departmentwise Employees</h2>
<ul>
<li class="mainmenu">Accounts</li>
<ul>
<li class="submenu">Anand</li>
<li class="submenu">Mahesh</li>
</ul>
<li class="mainmenu">HR</li>
<ul>
<li class="submenu">Rani</li>
<li class="submenu">Ankita</li>
</ul>
</ul>
</body>
</html>
使用 find() 和 find_all()
要搜尋標籤中使用的特定 CSS 類的元素,請使用 Tag 物件的attrs 屬性,如下所示:
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.find_all(attrs={"class": "mainmenu"})
print (obj)
輸出
[<li class="mainmenu">Accounts</li>, <li class="mainmenu">HR</li>]
結果是所有具有 mainmenu 類的元素的列表
要獲取 attrs 屬性中提到的任何 CSS 類的元素列表,請將 find_all() 語句更改為:
obj = soup.find_all(attrs={"class": ["mainmenu", "submenu"]})
這將生成一個包含上面使用的任何 CSS 類的所有元素的列表。
[ <li class="mainmenu">Accounts</li>, <li class="submenu">Anand</li>, <li class="submenu">Mahesh</li>, <li class="mainmenu">HR</li>, <li class="submenu">Rani</li>, <li class="submenu">Ankita</li> ]
使用 select() 和 select_one()
您還可以使用 select() 方法,並將 CSS 選擇器作為引數。點(.) 符號後跟類名用作 CSS 選擇器。
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.select(".heading")
print (obj)
輸出
[<h2 class="heading">Departmentwise Employees</h2>]
select_one() 方法返回使用給定類找到的第一個元素。
obj = soup.select_one(".submenu")
Beautiful Soup - 透過屬性查詢元素
find() 和 find_all() 方法都旨在根據傳遞給這些方法的引數查詢文件中一個或所有標籤。您可以將 attrs 引數傳遞給這些函式。attrs 的值必須是一個字典,其中包含一個或多個標籤屬性及其值。
為了檢查這些方法的行為,我們將使用以下 HTML 文件 (index.html)
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
使用 find_all()
以下程式返回所有具有 input type="text" 屬性的標籤的列表。
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.find_all(attrs={"type":'text'})
print (obj)
輸出
[<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>, <input id="marks" name="marks" type="text"/>]
使用 find()
find() 方法返回已解析文件中第一個具有給定屬性的標籤。
obj = soup.find(attrs={"name":'marks'})
使用 select()
select() 方法可以透過將要比較的屬性作為引數來呼叫。屬性必須放在列表物件中。它返回所有具有給定屬性的標籤的列表。
在以下程式碼中,select() 方法返回所有具有 type 屬性的標籤。
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.select("[type]")
print (obj)
輸出
[<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>, <input id="marks" name="marks" type="text"/>]
使用 select_one()
select_one() 方法與此類似,只是它返回滿足給定過濾器的第一個標籤。
obj = soup.select_one("[name='marks']")
輸出
<input id="marks" name="marks" type="text"/>
Beautiful Soup - 搜尋樹結構
在本章中,我們將討論 Beautiful Soup 中的不同方法,用於以不同方向遍歷 HTML 文件樹——向上和向下、左右以及來回。
我們將在本章的所有示例中使用以下 HTML 字串:
html = """
<html><head><title>TutorialsPoint</title></head>
<body>
<p class="title"><b>Online Tutorials Library</b></p>
<p class="story">TutorialsPoint has an excellent collection of tutorials on:
<a href="https://tutorialspoint.tw/Python" class="lang" id="link1">Python</a>,
<a href="https://tutorialspoint.tw/Java" class="lang" id="link2">Java</a> and
<a href="https://tutorialspoint.tw/PHP" class="lang" id="link3">PHP</a>;
Enhance your Programming skills.</p>
<p class="tutorial">...</p>
"""
所需標籤的名稱允許您導航解析樹。例如 soup.head 將為您獲取 <head> 元素:
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') print (soup.head.prettify())
輸出
<head>
<title>
TutorialsPoint
</title>
</head>
向下
一個標籤可能包含在其內封閉的字串或其他標籤。Tag 物件的 .contents 屬性返回屬於它的所有子元素的列表。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.head print (list(tag.children))
輸出
[<title>TutorialsPoint</title>]
返回的物件是一個列表,儘管在這種情況下,head 元素中只包含一個子標籤。
.children
.children 屬性也返回標籤中所有封閉元素的列表。下面,body 標籤中的所有元素都作為列表給出。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.body print (list(tag.children))
輸出
['\n', <p class="title"><b>Online Tutorials Library</b></p>, '\n', <p class="story">TutorialsPoint has an excellent collection of tutorials on: <a class="lang" href="https://tutorialspoint.tw/Python" id="link1">Python</a>, <a class="lang" href="https://tutorialspoint.tw/Java" id="link2">Java</a> and <a class="lang" href="https://tutorialspoint.tw/PHP" id="link3">PHP</a>; Enhance your Programming skills.</p>, '\n', <p class="tutorial">...</p>, '\n']
您可以使用 .children 生成器迭代標籤的子元素,而不是將它們作為列表獲取:
示例
tag = soup.body for child in tag.children: print (child)
輸出
<p class="title"><b>Online Tutorials Library</b></p> <p class="story">TutorialsPoint has an excellent collection of tutorials on: <a class="lang" href="https://tutorialspoint.tw/Python" id="link1">Python</a>, <a class="lang" href="https://tutorialspoint.tw/Java" id="link2">Java</a> and <a class="lang" href="https://tutorialspoint.tw/PHP" id="link3">PHP</a>; Enhance your Programming skills.</p> <p class="tutorial">...</p>
.descendents
.contents 和 .children 屬性僅考慮標籤的直接子元素。.descendants 屬性允許您遞迴地迭代標籤的所有子元素:它的直接子元素、其直接子元素的子元素,依此類推。
BeautifulSoup 物件位於所有標籤層次結構的頂部。因此,它的 .descendents 屬性包含 HTML 字串中的所有元素。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') print (soup.descendants)
.descendents 屬性返回一個生成器,可以使用 for 迴圈進行迭代。在這裡,我們列出 head 標籤的後代。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.head for element in tag.descendants: print (element)
輸出
<title>TutorialsPoint</title> TutorialsPoint
head 標籤包含一個 title 標籤,該標籤又包含一個 NavigableString 物件 TutorialsPoint。<head> 標籤只有一個子元素,但它有兩個後代:<title> 標籤和 <title> 標籤的子元素。但是 BeautifulSoup 物件只有一個直接子元素(<html> 標籤),但它有許多後代。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tags = list(soup.descendants) print (len(tags))
輸出
27
向上
就像您可以使用 children 和 descendents 屬性導航文件的下游一樣,BeautifulSoup 提供 .parent 和 .parent 屬性來導航標籤的上游
.parent
每個標籤和每個字串都有一個包含它的父標籤。您可以使用 parent 屬性訪問元素的父元素。在我們的示例中,<head> 標籤是 <title> 標籤的父元素。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.title print (tag.parent)
輸出
<head><title>TutorialsPoint</title></head>
由於 title 標籤包含一個字串(NavigableString),因此字串的父元素是 title 標籤本身。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.title string = tag.string print (string.parent)
輸出
<title>TutorialsPoint</title>
.parents
您可以使用 .parents 迭代元素的所有父元素。此示例使用 .parents 從文件深處隱藏的 <a> 標籤遍歷到文件的最頂部。在以下程式碼中,我們跟蹤示例 HTML 字串中第一個 <a> 標籤的父元素。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.a print (tag.string) for parent in tag.parents: print (parent.name)
輸出
Python p body html [document]
橫向
出現在相同縮排級別的 HTML 標籤稱為同級。考慮以下 HTML 程式碼段
<p>
<b>
Hello
</b>
<i>
Python
</i>
</p>
在外部 <p> 標籤中,我們在同一縮排級別上具有 <b> 和 <i> 標籤,因此它們被稱為同級。BeautifulSoup 使在同一級別的標籤之間導航成為可能。
.next_sibling 和 .previous_sibling
這些屬性分別返回同一級別上的下一個標籤和同一級別上的上一個標籤。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag1 = soup.b
print ("next:",tag1.next_sibling)
tag2 = soup.i
print ("previous:",tag2.previous_sibling)
輸出
next: <i>Python</i> previous: <b>Hello</b>
由於 <b> 標籤左側沒有同級,<i> 標籤右側也沒有同級,因此在這兩種情況下它都返回 Nobe。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag1 = soup.b
print ("next:",tag1.previous_sibling)
tag2 = soup.i
print ("previous:",tag2.next_sibling)
輸出
next: None previous: None
.next_siblings 和 .previous_siblings
如果標籤右側或左側有兩個或多個同級,則可以使用 .next_siblings 和 .previous_siblings 屬性分別導航它們。它們都返回生成器物件,以便可以使用 for 迴圈進行迭代。
讓我們為此目的使用以下 HTML 程式碼段:
<p>
<b>
Excellent
</b>
<i>
Python
</i>
<u>
Tutorial
</u>
</p>
使用以下程式碼遍歷下一個和上一個同級標籤。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.b
print ("next siblings:")
for tag in tag1.next_siblings:
print (tag)
print ("previous siblings:")
tag2 = soup.u
for tag in tag2.previous_siblings:
print (tag)
輸出
next siblings: <i>Python</i> <u>Tutorial</u> previous siblings: <i>Python</i> <b>Excellent</b>
來回
在 Beautiful Soup 中,next_element 屬性返回解析樹中的下一個字串或標籤。另一方面,previous_element 屬性返回解析樹中的上一個字串或標籤。有時,next_element 和 previous_element 屬性的返回值與 next_sibling 和 previous_sibling 屬性相似。
.next_element 和 .previous_element
示例
html = """
<html><head><title>TutorialsPoint</title></head>
<body>
<p class="title"><b>Online Tutorials Library</b></p>
<p class="story">TutorialsPoint has an excellent collection of tutorials on:
<a href="https://tutorialspoint.tw/Python" class="lang" id="link1">Python</a>,
<a href="https://tutorialspoint.tw/Java" class="lang" id="link2">Java</a> and
<a href="https://tutorialspoint.tw/PHP" class="lang" id="link3">PHP</a>;
Enhance your Programming skills.</p>
<p class="tutorial">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find("a", id="link3")
print (tag.next_element)
tag = soup.find("a", id="link1")
print (tag.previous_element)
輸出
PHP TutorialsPoint has an excellent collection of tutorials on:
id = "link3" 的 <a> 標籤之後的 next_element 是字串 PHP。類似地,previous_element 返回 id = "link1" 的 <a> 標籤之前的字串。
.next_elements 和 .previous_elements
Tag 物件的這些屬性分別返回其後和其前所有標籤和字串的生成器。
Next elements 示例
tag = soup.find("a", id="link1")
for element in tag.next_elements:
print (element)
輸出
Python , <a class="lang" href="https://tutorialspoint.tw/Java" id="link2">Java</a> Java and <a class="lang" href="https://tutorialspoint.tw/PHP" id="link3">PHP</a> PHP ; Enhance your Programming skills. <p class="tutorial">...</p> ...
Previous elements 示例
tag = soup.find("body")
for element in tag.previous_elements:
print (element)
輸出
<html><head><title>TutorialsPoint</title></head>
Beautiful Soup - 修改樹結構
Beautiful Soup 庫的一個強大功能是能夠操縱已解析的 HTML 或 XML 文件並修改其內容。
Beautiful Soup 庫具有執行以下操作的不同函式:
將內容或新標籤新增到文件的現有標籤中
在現有標籤或字串之前或之後插入內容
清除現有標籤的內容
修改標籤元素的內容
新增內容
您可以使用 Tag 物件上的append() 方法新增到現有標籤的內容中。它的工作原理類似於 Python 列表物件的 append() 方法。
在以下示例中,HTML 指令碼有一個 <p> 標籤。使用 append(),附加了其他文字。
示例
from bs4 import BeautifulSoup
markup = '<p>Hello</p>'
soup = BeautifulSoup(markup, 'html.parser')
print (soup)
tag = soup.p
tag.append(" World")
print (soup)
輸出
<p>Hello</p> <p>Hello World</p>
使用 append() 方法,您可以在現有標籤的末尾新增一個新標籤。首先使用new_tag() 方法建立一個新的 Tag 物件,然後將其傳遞給 append() 方法。
示例
from bs4 import BeautifulSoup, Tag
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag1 = soup.new_tag('i')
tag1.string = 'World'
tag.append(tag1)
print (soup.prettify())
輸出
<b>
Hello
<i>
World
</i>
</b>
如果必須將字串新增到文件中,則可以附加NavigableString 物件。
示例
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
new_string = NavigableString(" World")
tag.append(new_string)
print (soup.prettify())
輸出
<b> Hello World </b>
從 Beautiful Soup 4.7 版開始,extend() 方法已新增到 Tag 類中。它將列表中的所有元素新增到標籤中。
示例
from bs4 import BeautifulSoup markup = '<b>Hello</b>' soup = BeautifulSoup(markup, 'html.parser') tag = soup.b vals = ['World.', 'Welcome to ', 'TutorialsPoint'] tag.extend(vals) print (soup.prettify())
輸出
<b> Hello World. Welcome to TutorialsPoint </b>
插入內容
您可以使用insert() 方法在 Tag 元素的子元素列表中的給定位置新增元素,而不是在末尾新增新元素。Beautiful Soup 中的 insert() 方法的行為類似於 Python 列表物件上的 insert()。
在以下示例中,一個新字串在位置 1 新增到 <b> 標籤中。生成的已解析文件顯示了結果。
示例
from bs4 import BeautifulSoup, NavigableString markup = '<b>Excellent </b><u>from TutorialsPoint</u>' soup = BeautifulSoup(markup, 'html.parser') tag = soup.b tag.insert(1, "Tutorial ") print (soup.prettify())
輸出
<b> Excellent Tutorial </b> <u> from TutorialsPoint </u>
Beautiful Soup 還有insert_before() 和insert_after() 方法。它們各自的目的是在給定的 Tag 物件之前或之後插入標籤或字串。以下程式碼顯示字串“Python 教程”已新增到 <b> 標籤之後。
示例
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Excellent </b><u>from TutorialsPoint</u>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag.insert_after("Python Tutorial")
print (soup.prettify())
輸出
<b> Excellent </b> Python Tutorial <u> from TutorialsPoint </u>
另一方面,下面使用 insert_before() 方法,在 <b> 標籤之前新增“這是一個”文字。
tag.insert_before("Here is an ")
print (soup.prettify())
輸出
Here is an <b> Excellent </b> Python Tutorial <u> from TutorialsPoint </u>
清除內容
Beautiful Soup 提供了多種從文件樹中刪除元素內容的方法。每種方法都有其獨特的特點。
clear() 方法是最直接的方法。它只是簡單地刪除指定 Tag 元素的內容。以下示例顯示了它的用法。
示例
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Excellent </b><u>from TutorialsPoint</u>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.find('u')
tag.clear()
print (soup.prettify())
輸出
<b> Excellent </b> <u> </u>
可以看出,clear() 方法刪除了內容,但保留了標籤。
對於以下示例,我們解析以下 HTML 文件並在所有標籤上呼叫 clear() 方法。
<html>
<body>
<p> The quick, brown fox jumps over a lazy dog.</p>
<p> DJs flock by when MTV ax quiz prog.</p>
<p> Junk MTV quiz graced by fox whelps.</p>
<p> Bawds jog, flick quartz, vex nymphs./p>
</body>
</html>
這是使用 clear() 方法的 Python 程式碼
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
tags = soup.find_all()
for tag in tags:
tag.clear()
print (soup.prettify())
輸出
<html> </html>
extract() 方法從文件樹中刪除標籤或字串,並返回已刪除的物件。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
tags = soup.find_all()
for tag in tags:
obj = tag.extract()
print ("Extracted:",obj)
print (soup)
輸出
Extracted: <html> <body> <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs.</p> </body> </html> Extracted: <body> <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs.</p> </body> Extracted: <p> The quick, brown fox jumps over a lazy dog.</p> Extracted: <p> DJs flock by when MTV ax quiz prog.</p> Extracted: <p> Junk MTV quiz graced by fox whelps.</p> Extracted: <p> Bawds jog, flick quartz, vex nymphs.</p>
您可以提取標籤或字串。以下示例顯示了正在提取的 antag。
示例
html = '''
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
obj=soup.find('ol')
obj.find_next().extract()
print (soup)
輸出
<ol id="HR"> <li>Ankita</li> </ol>
更改 extract() 語句以刪除第一個 <li> 元素的內部文字。
示例
obj.find_next().string.extract()
輸出
<ol id="HR"> <li>Ankita</li> </ol>
還有另一個方法 decompose(),它從樹中刪除標籤,然後完全銷燬它及其內容:
示例
html = '''
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag1=soup.find('ol')
tag2 = soup.find('li')
tag2.decompose()
print (soup)
print (tag2.decomposed)
輸出
<ol id="HR"> <li>Ankita</li> </ol>
decomposed 屬性返回 True 或 False——元素是否已被分解。
修改內容
我們將看看replace_with() 方法,它允許替換標籤的內容。
就像 Python 字串是不可變的,可導航字串也不能就地修改。但是,使用 replace_with() 將標籤的內部字串替換為另一個字串。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>",'html.parser')
tag = soup.h2
tag.string.replace_with("OnLine Tutorials Library")
print (tag.string)
輸出
OnLine Tutorials Library
這是另一個顯示 replace_with() 用法的示例。如果您將 BeautifulSoup 物件作為引數傳遞給某個函式(例如 replace_with()),則可以組合兩個已解析的文件。2524
示例
from bs4 import BeautifulSoup
obj1 = BeautifulSoup("<book><title>Python</title></book>", features="xml")
obj2 = BeautifulSoup("<b>Beautiful Soup parser</b>", "lxml")
obj2.find('b').replace_with(obj1)
print (obj2)
輸出
<html><body><book><title>Python</title></book></body></html>
wrap() 方法將元素包裝在您指定的標籤中。它返回新的包裝器。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>Hello Python</p>", 'html.parser')
tag = soup.p
newtag = soup.new_tag('b')
tag.string.wrap(newtag)
print (soup)
輸出
<p><b>Hello Python</b></p>
另一方面,unwrap() 方法用標籤內的任何內容替換標籤。它非常適合去除標記。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>Hello <b>Python</b></p>", 'html.parser')
tag = soup.p
tag.b.unwrap()
print (soup)
輸出
<p>Hello Python</p>
Beautiful Soup - 解析文件的一部分
假設您想使用 Beautiful Soup 僅檢視文件的 <a> 標籤。通常,您會解析樹並使用 find_all() 方法,並將所需的標籤作為引數。
soup = BeautifulSoup(fp, "html.parser")
tags = soup.find_all('a')
但是,這也會非常耗時,並且會不必要地佔用更多記憶體。相反,您可以建立一個 SoupStrainer 類物件,並將其用作 BeautifulSoup 建構函式的 parse_only 引數的值。
SoupStrainer 告訴 BeautifulSoup 要提取哪些部分,並且解析樹僅包含這些元素。如果您將所需資訊縮小到 HTML 的特定部分,這將加快搜索結果的速度。
product = SoupStrainer('div',{'id': 'products_list'})
soup = BeautifulSoup(html,parse_only=product)
以上程式碼行將僅從產品網站解析標題,標題可能位於標籤欄位內。
類似地,就像上面一樣,我們可以使用其他 soupStrainer 物件從 HTML 標籤解析特定資訊。以下是一些示例 -
示例
from bs4 import BeautifulSoup, SoupStrainer
#Only "a" tags
only_a_tags = SoupStrainer("a")
#Will parse only the below mentioned "ids".
parse_only = SoupStrainer(id=["first", "third", "my_unique_id"])
soup = BeautifulSoup(my_document, "html.parser", parse_only=parse_only)
#parse only where string length is less than 10
def is_short_string(string):
return len(string) < 10
only_short_strings = SoupStrainer(string=is_short_string)
SoupStrainer 類接受與搜尋樹中的典型方法相同的引數:name、attrs、text 和 **kwargs。
請注意,如果您使用 html5lib 解析器,則此功能將不起作用,因為在這種情況下,無論如何都會解析整個文件。因此,您應該使用內建的 html.parser 或 lxml 解析器。
您還可以將 SoupStrainer 傳遞到“搜尋樹”中介紹的任何方法中。
from bs4 import SoupStrainer
a_tags = SoupStrainer("a")
soup = BeautifulSoup(html_doc, 'html.parser')
soup.find_all(a_tags)
Beautiful Soup - 查詢元素的所有子元素
HTML 指令碼中標籤的結構是分層的。元素巢狀在另一個元素內部。例如,頂級 <HTML> 標籤包含 <HEAD> 和 <BODY> 標籤,每個標籤都可能包含其他標籤。頂級元素稱為父元素。巢狀在父元素內部的元素是其子元素。藉助 Beautiful Soup,我們可以找到父元素的所有子元素。在本章中,我們將瞭解如何獲取 HTML 元素的子元素。
BeautifulSoup 類中有兩種方法可以獲取子元素。
- .children 屬性
- findChildren() 方法
本章中的示例使用以下 HTML 指令碼 (index.html)
<html> <head> <title>TutorialsPoint</title> </head> <body> <h2>Departmentwise Employees</h2> <ul id="dept"> <li>Accounts</li> <ul id='acc'> <li>Anand</li> <li>Mahesh</li> </ul> <li>HR</li> <ul id="HR"> <li>Rani</li> <li>Ankita</li> </ul> </ul> </body> </html>
使用 .children 屬性
Tag 物件的 .children 屬性以遞迴方式返回所有子元素的生成器。
以下 Python 程式碼給出了頂級 <ul> 標籤的所有子元素的列表。我們首先獲取與 <ul> 標籤對應的 Tag 元素,然後讀取其 .children 屬性。
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.ul
print (list(tag.children))
輸出
['\n', <li>Accounts</li>, '\n', <ul> <li>Anand</li> <li>Mahesh</li> </ul>, '\n', <li>HR</li>, '\n', <ul> <li>Rani</li> <li>Ankita</li> </ul>, '\n']
由於 .children 屬性返回一個列表迭代器,因此我們可以使用 for 迴圈來遍歷層次結構。
for child in tag.children: print (child)
輸出
<li>Accounts</li> <ul> <li>Anand</li> <li>Mahesh</li> </ul> <li>HR</li> <ul> <li>Rani</li> <li>Ankita</li> </ul>
使用 findChildren() 方法
findChildren() 方法提供了一種更全面的替代方案。它返回任何頂級標籤下的所有子元素。
在 index.html 文件中,我們有兩個巢狀的無序列表。頂級 <ul> 元素的 id 為 "dept",兩個包含的列表的 id 分別為 "acc" 和 "HR"。
在以下示例中,我們首先例項化一個指向頂級 <ul> 元素的 Tag 物件,並提取其下的子元素列表。
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find("ul", {"id": "dept"})
children = tag.findChildren()
for child in children:
print(child)
請注意,結果集以遞迴方式包含元素下的子元素。因此,在以下輸出中,您將找到整個內部列表,以及其中的各個元素。
<li>Accounts</li> <ul id="acc"> <li>Anand</li> <li>Mahesh</li> </ul> <li>Anand</li> <li>Mahesh</li> <li>HR</li> <ul id="HR"> <li>Rani</li> <li>Ankita</li> </ul> <li>Rani</li> <li>Ankita</li>
讓我們提取 id 為 'acc' 的內部 <ul> 元素下的子元素。程式碼如下 -
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find("ul", {"id": "acc"})
children = tag.findChildren()
for child in children:
print(child)
執行上述程式時,您將獲得 id 為 acc 的 <ul> 下的 <li> 元素。
輸出
<li>Anand</li> <li>Mahesh</li>
因此,BeautifulSoup 使解析任何頂級 HTML 元素下的子元素變得非常容易。
Beautiful Soup - 使用 CSS 選擇器查詢元素
在 Beautiful Soup 庫中,select() 方法是抓取 HTML/XML 文件的重要工具。與 find() 和其他 find_*() 方法類似,select() 方法也有助於定位滿足給定條件的元素。但是,find*() 方法根據標籤名稱及其屬性搜尋 PageElements,而 select() 方法根據給定的 CSS 選擇器搜尋文件樹。
Beautiful Soup 還有 select_one() 方法。select() 和 select_one() 的區別在於,select() 返回屬於 PageElement 並以 CSS 選擇器為特徵的所有元素的結果集;而 select_one() 返回滿足基於 CSS 選擇器選擇標準的元素的第一個出現。
在 Beautiful Soup 4.7 版本之前,select() 方法只能支援常見的 CSS 選擇器。隨著 4.7 版本的釋出,Beautiful Soup 集成了 Soup Sieve CSS 選擇器庫。因此,現在可以使用更多的選擇器。在 4.12 版本中,除了現有的便捷方法 select() 和 select_one() 之外,還添加了一個 .css 屬性。select() 方法的引數如下 -
select(selector, limit, **kwargs)
selector - 包含 CSS 選擇器的字串。
limit - 找到此數量的結果後,停止查詢。
kwargs - 要傳遞的關鍵字引數。
如果將 limit 引數設定為 1,則它等效於 select_one() 方法。select() 方法返回 Tag 物件的結果集,而 select_one() 方法返回單個 Tag 物件。
Soup Sieve 庫
Soup Sieve 是一個 CSS 選擇器庫。它已與 Beautiful Soup 4 整合,因此與 Beautiful Soup 包一起安裝。它提供了使用現代 CSS 選擇器選擇、匹配和過濾文件樹標籤的功能。Soup Sieve 目前實現了從 CSS 級別 1 規範到 CSS 級別 4 的大多數 CSS 選擇器,除了某些尚未實現的選擇器。
Soup Sieve 庫有不同型別的 CSS 選擇器。基本 CSS 選擇器為 -
型別選擇器
透過節點名稱匹配元素。例如 -
tags = soup.select('div')
示例
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tags = soup.select('div')
print (tags)
輸出
[<div id="Languages"> <p>Java</p> <p>Python</p> <p>C++</p> </div>]
通用選擇器 (*)
它匹配任何型別的元素。例如 -
tags = soup.select('*')
ID 選擇器
它根據元素的 id 屬性匹配元素。符號 # 表示 ID 選擇器。例如 -
tags = soup.select("#nm")
示例
from bs4 import BeautifulSoup
html = '''
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
'''
soup = BeautifulSoup(html, 'html.parser')
obj = soup.select("#nm")
print (obj)
輸出
[<input id="nm" name="name" type="text"/>]
類選擇器
它根據 class 屬性中包含的值匹配元素。字首為類名稱的 . 符號是 CSS 類選擇器。例如 -
tags = soup.select(".submenu")
示例
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tags = soup.select('div')
print (tags)
輸出
[<div id="Languages"> <p>Java</p> <p>Python</p> <p>C++</p> </div>]
屬性選擇器
屬性選擇器根據元素的屬性匹配元素。
soup.select('[attr]')
示例
from bs4 import BeautifulSoup
html = '''
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
<a class="prog" href="https://tutorialspoint.tw/java/java_overview.htm" id="link1">Java</a>
<a class="prog" href="https://tutorialspoint.tw/cprogramming/index.htm" id="link2">C</a>
'''
soup = BeautifulSoup(html, 'html5lib')
print(soup.select('[href]'))
輸出
[<a class="prog" href="https://tutorialspoint.tw/java/java_overview.htm" id="link1">Java</a>, <a class="prog" href="https://tutorialspoint.tw/cprogramming/index.htm" id="link2">C</a>]
偽類
CSS 規範定義了許多偽 CSS 類。偽類是新增到選擇器中的關鍵字,用於定義所選元素的特殊狀態。它為現有元素新增效果。例如,:link 選擇尚未訪問的連結(每個具有 href 屬性的 <a> 和 <area> 元素)。
偽類選擇器 nth-of-type 和 nth-child 非常廣泛使用。
:nth-of-type()
選擇器 :nth-of-type() 根據元素在兄弟元素組中的位置匹配給定型別的元素。關鍵字 even 和 odd 分別將從兄弟元素的子組中選擇元素。
在以下示例中,選擇了 <p> 型別的第二個元素。
示例
from bs4 import BeautifulSoup
html = '''
<p id="0"></p>
<p id="1"></p>
<span id="2"></span>
<span id="3"></span>
'''
soup = BeautifulSoup(html, 'html5lib')
print(soup.select('p:nth-of-type(2)'))
輸出
[<p id="1"></p>]
:nth-child()
此選擇器根據元素在一組兄弟元素中的位置匹配元素。關鍵字 even 和 odd 分別將選擇在一組兄弟元素中位置為偶數或奇數的元素。
用法
:nth-child(even) :nth-child(odd) :nth-child(2)
示例
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.div
child = tag.select_one(':nth-child(2)')
print (child)
輸出
<p>Python</p>
Beautiful Soup - 查詢所有註釋
在計算機程式碼中插入註釋被認為是一種良好的程式設計實踐。註釋有助於理解程式的邏輯。它們也用作文件。您可以在 HTML 和 XML 指令碼中添加註釋,就像在用 C、Java、Python 等編寫的程式中一樣。BeautifulSoup API 可以幫助識別 HTML 文件中的所有註釋。
在 HTML 和 XML 中,註釋文字寫在 <!-- 和 --> 標籤之間。
<!-- Comment Text -->
BeutifulSoup 包(其內部名稱為 bs4)將 Comment 定義為一個重要的物件。Comment 物件是一種特殊的 NavigableString 物件。因此,在 <!-- 和 --> 之間找到的任何 Tag 的 string 屬性都被識別為 Comment。
示例
from bs4 import BeautifulSoup markup = "<b><!--This is a comment text in HTML--></b>" soup = BeautifulSoup(markup, 'html.parser') comment = soup.b.string print (comment, type(comment))
輸出
This is a comment text in HTML <class 'bs4.element.Comment'>
要搜尋 HTML 文件中註釋的所有出現,我們將使用 find_all() 方法。如果沒有引數,find_all() 將返回解析後的 HTML 文件中的所有元素。您可以將關鍵字引數 'string' 傳遞給 find_all() 方法。我們將為其分配函式 iscomment() 的返回值。
comments = soup.find_all(string=iscomment)
iscomment() 函式使用 isinstance() 函式驗證標籤中的文字是否為註釋物件。
def iscomment(elem): return isinstance(elem, Comment)
comments 變數將儲存給定 HTML 文件中的所有註釋文字出現。我們將在示例程式碼中使用以下 index.html 檔案 -
<html>
<head>
<!-- Title of document -->
<title>TutorialsPoint</title>
</head>
<body>
<!-- Page heading -->
<h2>Departmentwise Employees</h2>
<!-- top level list-->
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<!-- first inner list -->
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ul id="HR">
<!-- second inner list -->
<li>Rani</li>
<li>Ankita</li>
</ul>
</ul>
</body>
</html>
以下 Python 程式抓取上述 HTML 文件,並查詢其中的所有註釋。
示例
from bs4 import BeautifulSoup, Comment
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
def iscomment(elem):
return isinstance(elem, Comment)
comments = soup.find_all(string=iscomment)
print (comments)
輸出
[' Title of document ', ' Page heading ', ' top level list', ' first inner list ', ' second inner list ']
以上輸出顯示了所有註釋的列表。我們還可以對註釋集合使用 for 迴圈。
示例
i=0 for comment in comments: i+=1 print (i,".",comment)
輸出
1 . Title of document 2 . Page heading 3 . top level list 4 . first inner list 5 . second inner list
在本章中,我們學習瞭如何提取 HTML 文件中的所有註釋字串。
Beautiful Soup - 從 HTML 中抓取列表
網頁通常以有序或無序列表的形式包含重要資料。使用 Beautiful Soup,我們可以輕鬆地提取 HTML 列表元素,將資料轉換為 Python 物件,並將其儲存在資料庫中以供進一步分析。在本章中,我們將使用 find() 和 select() 方法從 HTML 文件中抓取列表資料。
搜尋解析樹最簡單的方法是按其名稱搜尋標籤。soup.<tag> 獲取給定標籤的內容。
HTML 提供 <ol> 和 <ul> 標籤來組成有序和無序列表。與任何其他標籤一樣,我們可以獲取這些標籤的內容。
我們將使用以下 HTML 文件 -
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
按標籤抓取列表
在上面的 HTML 文件中,我們有一個頂級 <ul> 列表,其中包含另一個 <ul> 標籤和另一個 <ol> 標籤。我們首先在 soup 物件中解析文件,並在 soup.ul Tag 物件中檢索第一個 <ul> 的內容。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
lst=soup.ul
print (lst)
輸出
<ul id="dept"> <li>Accounts</li> <ul id="acc"> <li>Anand</li> <li>Mahesh</li> </ul> <li>HR</li> <ol id="HR"> <li>Rani</li> <li>Ankita</li> </ol> </ul>
更改 lst 的值以指向 <ol> 元素以獲取內部列表。
lst=soup.ol
輸出
<ol id="HR"> <li>Rani</li> <li>Ankita</li> </ol>
使用 select() 方法
select() 方法主要用於使用 CSS 選擇器獲取資料。但是,您也可以向其傳遞標籤。在這裡,我們可以將 ol 標籤傳遞給 select() 方法。select_one() 方法也可用。它獲取給定標籤的第一個出現。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
lst=soup.select("ol")
print (lst)
輸出
[<ol id="HR"> <li>Rani</li> <li>Ankita</li> </ol>]
使用 find_all() 方法
find() 和 fin_all() 方法更全面。您可以將各種型別的過濾器(如標籤、屬性或字串等)傳遞給這些方法。在這種情況下,我們想要獲取列表標籤的內容。
在以下程式碼中,find_all() 方法返回 <ul> 標籤中所有元素的列表。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
lst=soup.find_all("ul")
print (lst)
我們可以透過包含 attrs 引數來細化搜尋過濾器。在我們的 HTML 文件中,<ul> 和 <ol> 標籤,我們已經指定了它們各自的 id 屬性。因此,讓我們獲取具有 id="acc" 的 <ul> 元素的內容。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
lst=soup.find_all("ul", {"id":"acc"})
print (lst)
輸出
[<ul id="acc"> <li>Anand</li> <li>Mahesh</li> </ul>]
這是一個其他示例。我們收集所有帶有 <li> 標籤的元素,其內部文字以 'A' 開頭。find_all() 方法採用關鍵字引數 string。如果 startingwith() 函式返回 True,則它將獲取文字的值。
示例
from bs4 import BeautifulSoup
def startingwith(ch):
return ch.startswith('A')
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
lst=soup.find_all('li',string=startingwith)
print (lst)
輸出
[<li>Accounts</li>, <li>Anand</li>, <li>Ankita</li>]
Beautiful Soup - 從 HTML 中抓取段落
HTML 文件中經常出現的標籤之一是 <p> 標籤,它標記段落文字。使用 Beautiful Soup,您可以輕鬆地從解析的文件樹中提取段落。在本章中,我們將討論以下使用 BeautifulSoup 庫抓取段落的方法。
使用 <p> 標籤抓取 HTML 段落
使用 find_all() 方法抓取 HTML 段落
使用 select() 方法抓取 HTML 段落
我們將使用以下 HTML 文件進行這些練習 -
<html>
<head>
<title>BeautifulSoup - Scraping Paragraph</title>
</head>
<body>
<p id='para1'>The quick, brown fox jumps over a lazy dog.</p>
<h2>Hello</h2>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
按 <p> 標籤抓取
搜尋解析樹最簡單的方法是按其名稱搜尋標籤。因此,表示式 soup.p 指向抓取的文件中的第一個 <p> 標籤。
para = soup.p
要獲取所有後續的<p>標籤,可以執行一個迴圈,直到soup物件中所有的<p>標籤都被遍歷完。以下程式顯示了所有段落標籤的美化輸出。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
para = soup.p
print (para.prettify())
while True:
p = para.find_next('p')
if p is None:
break
print (p.prettify())
para=p
輸出
<p> The quick, brown fox jumps over a lazy dog. </p> <p> DJs flock by when MTV ax quiz prog. </p> <p> Junk MTV quiz graced by fox whelps. </p> <p> Bawds jog, flick quartz, vex nymphs. </p>
使用 find_all() 方法
find_all()方法更全面。您可以將各種型別的過濾器(例如標籤、屬性或字串等)傳遞給此方法。在本例中,我們想要獲取<p>標籤的內容。
在以下程式碼中,find_all()方法返回<p>標籤中所有元素的列表。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
paras = soup.find_all('p')
for para in paras:
print (para.prettify())
輸出
<p> The quick, brown fox jumps over a lazy dog. </p> <p> DJs flock by when MTV ax quiz prog. </p> <p> Junk MTV quiz graced by fox whelps. </p> <p> Bawds jog, flick quartz, vex nymphs. </p>
我們可以使用另一種方法來查詢所有<p>標籤。首先,使用find_all()獲取所有標籤的列表,並檢查每個標籤的Tag.name是否等於'p'。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
tags = soup.find_all()
paras = [tag.contents for tag in tags if tag.name=='p']
print (paras)
find_all()方法還有一個attrs引數。當您想要提取具有特定屬性的<p>標籤時,它非常有用。例如,在給定的文件中,第一個<p>元素具有id='para1'。要獲取它,我們需要修改標籤物件如下所示:
paras = soup.find_all('p', attrs={'id':'para1'})
使用 select() 方法
select()方法主要用於使用CSS選擇器獲取資料。但是,您也可以將標籤傳遞給它。在這裡,我們可以將<p>標籤傳遞給select()方法。select_one()方法也可用。它獲取<p>標籤的第一次出現。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
paras = soup.select('p')
print (paras)
輸出
[ <p>The quick, brown fox jumps over a lazy dog.</p>, <p>DJs flock by when MTV ax quiz prog.</p>, <p>Junk MTV quiz graced by fox whelps.</p>, <p>Bawds jog, flick quartz, vex nymphs.</p> ]
要過濾掉具有特定id的<p>標籤,請使用如下所示的for迴圈:
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
tags = soup.select('p')
for tag in tags:
if tag.has_attr('id') and tag['id']=='para1':
print (tag.contents)
輸出
['The quick, brown fox jumps over a lazy dog.']
BeautifulSoup - 從 HTML 中抓取連結
在從具有網站的資源中抓取和分析內容時,您通常需要提取某個頁面包含的所有連結。在本章中,我們將瞭解如何從HTML文件中提取連結。
HTML使用錨標籤<a>來插入超連結。錨標籤的href屬性允許您建立連結。它使用以下語法:
<a href=="web page URL">hypertext</a>
使用find_all()方法,我們可以收集文件中的所有錨標籤,然後列印每個錨標籤的href屬性的值。
在下面的示例中,我們提取了Google主頁上找到的所有連結。我們使用requests庫來收集https://google.com的HTML內容,將其解析為soup物件,然後收集所有<a>標籤。最後,我們列印href屬性。
示例
from bs4 import BeautifulSoup
import requests
url = "https://www.google.com/"
req = requests.get(url)
soup = BeautifulSoup(req.content, "html.parser")
tags = soup.find_all('a')
links = [tag['href'] for tag in tags]
for link in links:
print (link)
以下是執行上述程式時部分輸出:
輸出
https://www.google.co.in/imghp?hl=en&tab=wi https://maps.google.co.in/maps?hl=en&tab=wl https://play.google.com/?hl=en&tab=w8 https://www.youtube.com/?tab=w1 https://news.google.com/?tab=wn https://mail.google.com/mail/?tab=wm https://drive.google.com/?tab=wo https://www.google.co.in/intl/en/about/products?tab=wh http://www.google.co.in/history/optout?hl=en /preferences?hl=en https://#/ServiceLogin?hl=en&passive=true&continue=https://www.google.com/&ec=GAZAAQ /advanced_search?hl=en-IN&authuser=0 https://www.google.com/url?q=https://io.google/2023/%3Futm_source%3Dgoogle-hpp%26utm_medium%3Dembedded_marketing%26utm_campaign%3Dhpp_watch_live%26utm_content%3D&source=hpp&id=19035434&ct=3&usg=AOvVaw0qzqTkP5AEv87NM-MUDd_u&sa=X&ved=0ahUKEwiPzpjku-z-AhU1qJUCHVmqDJoQ8IcBCAU
但是,HTML文件可能具有不同協議方案的超連結,例如用於連結到電子郵件ID的mailto:協議,用於連結到電話號碼的tel:方案,或用於連結到具有file:// URL方案的本地檔案的連結。在這種情況下,如果我們有興趣提取具有https://方案的連結,我們可以透過以下示例來實現。我們有一個包含不同型別超連結的HTML文件,其中僅提取了具有https://字首的超連結。
html = '''
<p><a href="https://tutorialspoint.tw">Web page link </a></p>
<p><a href="https://www.example.com">Web page link </a></p>
<p><a href="mailto:nowhere@mozilla.org">Email link</a></p>
<p><a href="tel:+4733378901">Telephone link</a></p>
'''
from bs4 import BeautifulSoup
import requests
soup = BeautifulSoup(html, "html.parser")
tags = soup.find_all('a')
links = [tag['href'] for tag in tags]
for link in links:
if link.startswith("https"):
print (link)
輸出
https://tutorialspoint.tw https://www.example.com
Beautiful Soup - 獲取所有 HTML 標籤
HTML中的標籤就像Python或Java等傳統程式語言中的關鍵字。標籤具有預定義的行為,瀏覽器根據該行為呈現其內容。使用Beautiful Soup,可以收集給定HTML文件中的所有標籤。
獲取標籤列表的最簡單方法是將網頁解析為soup物件,然後呼叫不帶任何引數的find_all()方法。它返回一個列表生成器,為我們提供所有標籤的列表。
讓我們提取Google主頁中所有標籤的列表。
示例
from bs4 import BeautifulSoup import requests url = "https://www.google.com/" req = requests.get(url) soup = BeautifulSoup(req.content, "html.parser") tags = soup.find_all() print ([tag.name for tag in tags])
輸出
['html', 'head', 'meta', 'meta', 'title', 'script', 'style', 'style', 'script', 'body', 'script', 'div', 'div', 'nobr', 'b', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'u', 'div', 'nobr', 'span', 'span', 'span', 'a', 'a', 'a', 'div', 'div', 'center', 'br', 'div', 'img', 'br', 'br', 'form', 'table', 'tr', 'td', 'td', 'input', 'input', 'input', 'input', 'input', 'div', 'input', 'br', 'span', 'span', 'input', 'span', 'span', 'input', 'script', 'input', 'td', 'a', 'input', 'script', 'div', 'div', 'br', 'div', 'style', 'div', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'span', 'div', 'div', 'a', 'a', 'a', 'a', 'p', 'a', 'a', 'script', 'script', 'script']
當然,您可能會得到這樣一個列表,其中某個特定標籤可能會出現多次。要獲得唯一的標籤列表(避免重複),請從標籤物件列表中構造一個集合。
將上面程式碼中的print語句更改為
示例
print ({tag.name for tag in tags})
輸出
{'body', 'head', 'p', 'a', 'meta', 'tr', 'nobr', 'script', 'br', 'img', 'b', 'form', 'center', 'span', 'div', 'input', 'u', 'title', 'style', 'td', 'table', 'html'}
要獲取與某些文字關聯的標籤,請檢查字串屬性,如果它不是None,則列印。
tags = soup.find_all()
for tag in tags:
if tag.string is not None:
print (tag.name, tag.string)
可能有一些不帶文字但帶有一個或多個屬性的單例標籤,例如<img>標籤。以下迴圈構建了此類標籤的列表。
在以下程式碼中,HTML字串不是完整的HTML文件,因為它沒有給出<html>和<body>標籤。但是,html5lib和lxml解析器在解析文件樹時會自行新增這些標籤。因此,當我們提取標籤列表時,也會看到額外的標籤。
示例
html = '''
<h1 style="color:blue;text-align:center;">This is a heading</h1>
<p style="color:red;">This is a paragraph.</p>
<p>This is another paragraph</p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html5lib")
tags = soup.find_all()
print ({tag.name for tag in tags} )
輸出
{'head', 'html', 'p', 'h1', 'body'}
Beautiful Soup - 獲取標籤內的文字
HTML中有兩種型別的標籤。許多標籤成對出現,分別是開始標籤和結束標籤。頂級<html>標籤具有相應的結束</html>標籤,這是一個主要示例。其他的有<body>和</body>、<p>和</p>、<h1>和</h1>等等。其他標籤是自閉合標籤,例如<img>和<a>。自閉合標籤沒有文字,就像大多數帶有開始和結束符號的標籤(例如<b>Hello</b>)一樣。在本章中,我們將瞭解如何藉助Beautiful Soup庫獲取此類標籤內部的文字部分。
Beautiful Soup中有多種方法/屬性可用於獲取與標籤物件關聯的文字。
| 序號 | 方法及描述 |
|---|---|
| 1 | text屬性 獲取PageElement的所有子字串,如果指定則使用分隔符連線。 |
| 2 | string屬性 方便地從子元素獲取字串。 |
| 3 | strings屬性 從當前PageElement下的所有子物件生成字串部分。 |
| 4 | stripped_strings屬性 與strings屬性相同,但刪除了換行符和空格。 |
| 5 | get_text()方法 返回此PageElement的所有子字串,如果指定則使用分隔符連線。 |
考慮以下HTML文件:
<div id="outer">
<div id="inner">
<p>Hello<b>World</b></p>
<img src='logo.jpg'>
</div>
</div>
如果我們檢索解析的文件樹中每個標籤的stripped_string屬性,我們會發現兩個div標籤和p標籤有兩個NavigableString物件,分別是Hello和World。<b>標籤包含world字串,而<img>沒有文字部分。
以下示例從給定HTML文件中的每個標籤中獲取文字:
示例
html = """
<div id="outer">
<div id="inner">
<p>Hello<b>World</b></p>
<img src='logo.jpg'>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
for tag in soup.find_all():
print ("Tag: {} attributes: {} ".format(tag.name, tag.attrs))
for txt in tag.stripped_strings:
print (txt)
print()
輸出
Tag: div attributes: {'id': 'outer'}
Hello
World
Tag: div attributes: {'id': 'inner'}
Hello
World
Tag: p attributes: {}
Hello
World
Tag: b attributes: {}
World
Tag: img attributes: {'src': 'logo.jpg'}
Beautiful Soup - 查詢所有標題
在本章中,我們將探討如何使用BeautifulSoup在HTML文件中查詢所有標題元素。HTML定義了從H1到H6的六種標題樣式,每種標題樣式的字型大小都逐漸減小。不同的頁面部分使用合適的標籤,例如主標題、章節標題、主題等。讓我們以兩種不同的方式使用find_all()方法來提取HTML文件中的所有標題元素。
我們將在本章的程式碼示例中使用以下HTML指令碼(儲存為index.html):
<html>
<head>
<title>BeautifulSoup - Scraping Headings</title>
</head>
<body>
<h2>Scraping Headings</h2>
<b>The quick, brown fox jumps over a lazy dog.</b>
<h3>Paragraph Heading</h3>
<p>DJs flock by when MTV ax quiz prog.</p>
<h3>List heading</h3>
<ul>
<li>Junk MTV quiz graced by fox whelps.</li>
<li>Bawds jog, flick quartz, vex nymphs.</li>
</ul>
</body>
</html>
示例1
在這種方法中,我們收集解析樹中的所有標籤,並檢查每個標籤的名稱是否在所有標題標籤的列表中找到。
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
headings = ['h1','h2','h3', 'h4', 'h5', 'h6']
tags = soup.find_all()
heads = [(tag.name, tag.contents[0]) for tag in tags if tag.name in headings]
print (heads)
這裡,headings是所有標題樣式h1到h6的列表。如果標籤的名稱是其中的任何一個,則該標籤及其內容將被收集到名為heads的列表中。
輸出
[('h2', 'Scraping Headings'), ('h3', 'Paragraph Heading'), ('h3', 'List heading')]
示例2
您可以將正則表示式傳遞給find_all()方法。請檢視以下正則表示式。
re.compile('^h[1-6]$')
此正則表示式查詢以h開頭,h後面有一個數字,然後在數字後結束的所有標籤。讓我們在下面的程式碼中將其用作find_all()方法的引數:
from bs4 import BeautifulSoup
import re
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
tags = soup.find_all(re.compile('^h[1-6]$'))
print (tags)
輸出
[<h2>Scraping Headings</h2>, <h3>Paragraph Heading</h3>, <h3>List heading</h3>]
Beautiful Soup - 提取標題標籤
<title>標籤用於為頁面提供出現在瀏覽器標題欄中的文字標題。它不是網頁主要內容的一部分。title標籤始終位於<head>標籤內。
我們可以透過Beautiful Soup提取title標籤的內容。我們解析HTML樹並獲取title標籤物件。
示例
html = '''
<html>
<head>
<Title>Python Libraries</title>
</head>
<body>
<p Hello World</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html5lib")
title = soup.title
print (title)
輸出
<title>Python Libraries</title>
在HTML中,我們可以將title屬性與所有標籤一起使用。title屬性提供有關元素的附加資訊。當滑鼠懸停在元素上時,該資訊作為工具提示文字顯示。
我們可以使用以下程式碼片段提取每個標籤的title屬性的文字:
示例
html = '''
<html>
<body>
<p title='parsing HTML and XML'>Beautiful Soup</p>
<p title='HTTP library'>requests</p>
<p title='URL handling'>urllib</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html5lib")
tags = soup.find_all()
for tag in tags:
if tag.has_attr('title'):
print (tag.attrs['title'])
輸出
parsing HTML and XML HTTP library URL handling
Beautiful Soup - 提取電子郵件 ID
從網頁中提取電子郵件地址是BeautifulSoup等網路抓取庫的重要應用。在任何網頁中,電子郵件ID通常出現在錨<a>標籤的href屬性中。電子郵件ID使用mailto URL方案編寫。很多時候,電子郵件地址可能作為普通文字出現在頁面內容中(沒有任何超連結)。在本章中,我們將使用BeautifulSoup庫透過簡單的技術從HTML頁面獲取電子郵件ID。
href屬性中電子郵件ID的典型用法如下所示:
<a href = "mailto:xyz@abc.com">test link</a>
在第一個示例中,我們將考慮以下HTML文件,以從中提取超連結中的電子郵件ID:
<html>
<head>
<title>BeautifulSoup - Scraping Email IDs</title>
</head>
<body>
<h2>Contact Us</h2>
<ul>
<li><a href = "mailto:sales@company.com">Sales Enquiries</a></li>
<li><a href = "mailto:careers@company.com">Careers</a></li>
<li><a href = "mailto:partner@company.com">Partner with us</a></li>
</ul>
</body>
</html>
以下是查詢電子郵件ID的Python程式碼。我們收集文件中的所有<a>標籤,並檢查該標籤是否具有href屬性。如果是,則其值從第6個字元開始的部分就是電子郵件ID。
from bs4 import BeautifulSoup
import re
fp = open("contact.html")
soup = BeautifulSoup(fp, "html.parser")
tags = soup.find_all("a")
for tag in tags:
if tag.has_attr("href") and tag['href'][:7]=='mailto:':
print (tag['href'][7:])
對於給定的HTML文件,電子郵件ID將按如下方式提取:
sales@company.com careers@company.com partner@company.com
在第二個示例中,我們假設電子郵件ID出現在文字中的任何位置。要提取它們,我們使用正則表示式搜尋機制。正則表示式是一種複雜的字元模式。Python的re模組有助於處理正則表示式模式。以下正則表示式模式用於搜尋電子郵件地址:
pat = r'[\w.+-]+@[\w-]+\.[\w.-]+'
對於此練習,我們將使用以下HTML文件,其中<li>標籤包含電子郵件ID。
<html>
<head>
<title>BeautifulSoup - Scraping Email IDs</title>
</head>
<body>
<h2>Contact Us</h2>
<ul>
<li>Sales Enquiries: sales@company.com</a></li>
<li>Careers: careers@company.com</a></li>
<li>Partner with us: partner@company.com</a></li>
</ul>
</body>
</html>
使用電子郵件正則表示式,我們將查詢模式在每個<li>標籤字串中的出現情況。以下是Python程式碼:
示例
from bs4 import BeautifulSoup
import re
def isemail(s):
pat = r'[\w.+-]+@[\w-]+\.[\w.-]+'
grp=re.findall(pat,s)
return (grp)
fp = open("contact.html")
soup = BeautifulSoup(fp, "html.parser")
tags = soup.find_all('li')
for tag in tags:
emails = isemail(tag.string)
if emails:
print (emails)
輸出
['sales@company.com'] ['careers@company.com'] ['partner@company.com']
使用上面描述的簡單技術,我們可以使用BeautifulSoup從網頁中提取電子郵件ID。
Beautiful Soup - 抓取巢狀標籤
HTML文件中標籤或元素的排列具有層次結構的性質。標籤可以巢狀到多個級別。例如,<head>和<body>標籤巢狀在<html>標籤內。類似地,一個或多個<li>標籤可能位於<ul>標籤內。在本章中,我們將瞭解如何抓取具有一個或多個巢狀在其中的子標籤的標籤。
讓我們考慮以下HTML文件:
<div id="outer">
<div id="inner">
<p>Hello<b>World</b></p>
<img src='logo.jpg'>
</div>
</div>
在這種情況下,兩個<div>標籤和一個<p>標籤有一個或多個巢狀在其中的子元素。而<img>和<b>標籤沒有任何子標籤。
findChildren()方法返回標籤下所有子元素的ResultSet。因此,如果標籤沒有任何子元素,則ResultSet將是一個空列表,例如[]。
以此為線索,以下程式碼查詢文件樹中每個標籤下的標籤並顯示列表。
示例
html = """
<div id="outer">
<div id="inner">
<p>Hello<b>World</b></p>
<img src='logo.jpg'>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
for tag in soup.find_all():
print ("Tag: {} attributes: {}".format(tag.name, tag.attrs))
print ("Child tags: ", tag.findChildren())
print()
輸出
Tag: div attributes: {'id': 'outer'}
Child tags: [<div id="inner">
<p>Hello<b>World</b></p>
<img src="logo.jpg"/>
</div>, <p>Hello<b>World</b></p>, <b>World</b>, <img src="logo.jpg"/>]
Tag: div attributes: {'id': 'inner'}
Child tags: [<p>Hello<b>World</b></p>, <b>World</b>, <img src="logo.jpg"/>]
Tag: p attributes: {}
Child tags: [<b>World</b>]
Tag: b attributes: {}
Child tags: []
Tag: img attributes: {'src': 'logo.jpg'}
Child tags: []
Beautiful Soup - 解析表格
除了文字內容之外,HTML文件還可以以HTML表格的形式包含結構化資料。使用Beautiful Soup,我們可以將表格資料提取到Python物件(例如列表或字典)中,如果需要,可以將其儲存在資料庫或電子表格中,並執行處理。在本章中,我們將使用Beautiful Soup解析HTML表格。
儘管Beautiful Soup沒有用於提取表格資料的任何特殊函式或方法,但我們可以透過簡單的抓取技術來實現它。就像任何表格(例如SQL或電子表格中的表格)一樣,HTML表格由行和列組成。
HTML使用<table>標籤來構建表格結構。有一個或多個巢狀的<tr>標籤,每個標籤代表一行。每一行都包含<td>標籤,用於儲存該行每個單元格中的資料。第一行通常用於列標題,標題放在<th>標籤而不是<td>標籤中。
以下HTML指令碼在瀏覽器視窗中呈現一個簡單的表格:
<html>
<body>
<h2>Beautiful Soup - Parse Table</h2>
<table border="1">
<tr>
<th>Name</th>
<th>Age</th>
<th>Marks</th>
</tr>
<tr class='data'>
<td>Ravi</td>
<td>23</td>
<td>67</td>
</tr>
<tr class='data'>
<td>Anil</td>
<td>27</td>
<td>84</td>
</tr>
</table>
</body>
</html>
請注意,資料行的外觀使用CSS類data進行了自定義,以便將其與標題行區分開來。
現在我們將瞭解如何解析表格資料。首先,我們在 BeautifulSoup 物件中獲取文件樹。然後將所有列標題收集到一個列表中。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup, "html.parser")
tbltag = soup.find('table')
headers = []
headings = tbltag.find_all('th')
for h in headings: headers.append(h.string)
然後獲取在標題行之後具有 class='data' 屬性的資料行標籤。形成一個字典物件,其中列標題作為鍵,每個單元格中的對應值作為值,並將該字典物件追加到一個字典物件列表中。
rows = tbltag.find_all_next('tr', {'class':'data'})
trows=[]
for i in rows:
row = {}
data = i.find_all('td')
n=0
for j in data:
row[headers[n]] = j.string
n+=1
trows.append(row)
一個字典物件列表被收集到 trows 中。然後可以將其用於不同的目的,例如儲存在 SQL 表中、儲存為 JSON 或 pandas DataFrame 物件。
完整的程式碼如下所示:
markup = """
<html>
<body>
<p>Beautiful Soup - Parse Table</p>
<table>
<tr>
<th>Name</th>
<th>Age</th>
<th>Marks</th>
</tr>
<tr class='data'>
<td>Ravi</td>
<td>23</td>
<td>67</td>
</tr>
<tr class='data'>
<td>Anil</td>
<td>27</td>
<td>84</td>
</tr>
</table>
</body>
</html>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup, "html.parser")
tbltag = soup.find('table')
headers = []
headings = tbltag.find_all('th')
for h in headings: headers.append(h.string)
print (headers)
rows = tbltag.find_all_next('tr', {'class':'data'})
trows=[]
for i in rows:
row = {}
data = i.find_all('td')
n=0
for j in data:
row[headers[n]] = j.string
n+=1
trows.append(row)
print (trows)
輸出
[{'Name': 'Ravi', 'Age': '23', 'Marks': '67'}, {'Name': 'Anil', 'Age': '27', 'Marks': '84'}]
Beautiful Soup - 選擇第 n 個子元素
HTML 的特點是標籤的層次順序。例如,<html> 標籤包含 <body> 標籤,在 <body> 標籤內部可能存在 <div> 標籤,並且 <div> 標籤可能進一步巢狀 <ul> 和 <li> 元素。findChildren() 方法和 .children 屬性都返回一個 ResultSet(列表),其中包含元素下所有直接子標籤。透過遍歷列表,可以獲取位於所需位置(第 n 個子元素)的子元素。
下面的程式碼使用 HTML 文件中 <div> 標籤的 children 屬性。由於 children 屬性的返回型別是列表迭代器,因此我們將從中檢索一個 Python 列表。我們還需要從迭代器中刪除空格和換行符。完成後,我們可以獲取所需的子元素。這裡顯示了 <div> 標籤索引為 1 的子元素。
示例
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.div
children = tag.children
childlist = [child for child in children if child not in ['\n', ' ']]
print (childlist[1])
輸出
<p>Python</p>
要使用 findChildren() 方法而不是 children 屬性,請將語句更改為
children = tag.findChildren()
輸出不會有任何變化。
定位第 n 個子元素的更有效方法是使用 select() 方法。select() 方法使用 CSS 選擇器從當前元素獲取所需的 PageElements。
Soup 和 Tag 物件透過其 .css 屬性支援 CSS 選擇器,該屬性是 CSS 選擇器 API 的介面。選擇器實現由 Soup Sieve 包處理,該包與 bs4 包一起安裝。
Soup Sieve 包定義了不同型別的 CSS 選擇器,即簡單、複合和複雜 CSS 選擇器,它們由一個或多個型別選擇器、ID 選擇器、類選擇器組成。這些選擇器在 CSS 語言中定義。
Soup Sieve 中也有偽類選擇器。CSS 偽類是新增到選擇器中的一個關鍵字,用於指定所選元素的特殊狀態。在本例中,我們將使用 :nth-child 偽類選擇器。由於我們需要從 <div> 標籤的第 2 個位置選擇一個子元素,因此我們將 :nthchild(2) 傳遞給 select_one() 方法。
示例
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.div
child = tag.select_one(':nth-child(2)')
print (child)
輸出
<p>Python</p>
我們得到了與 findChildren() 方法相同的結果。請注意,子元素編號從 1 開始,而不是像 Python 列表那樣從 0 開始。
Beautiful Soup - 透過標籤內的文字搜尋
Beautiful Soup 提供了不同的方法來搜尋給定 HTML 文件中的特定文字。在這裡,我們為此目的使用 find() 方法的字串引數。
在下面的示例中,我們使用 find() 方法搜尋單詞“by”。
示例
html = '''
<p> The quick, brown fox jumps over a lazy dog.</p>
<p> DJs flock by when MTV ax quiz prog.</p>
<p> Junk MTV quiz graced by fox whelps.</p>
<p> Bawds jog, flick quartz, vex nymphs./p>
'''
from bs4 import BeautifulSoup, NavigableString
def search(tag):
if 'by' in tag.text:
return True
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('p', string=search)
print (tag)
輸出
<p> DJs flock by when MTV ax quiz prog.</p>
You can find all occurrences of the word with find_all() method
tag = soup.find_all('p', string=search)
print (tag)
輸出
[<p> DJs flock by when MTV ax quiz prog.</p>, <p> Junk MTV quiz graced by fox whelps.</p>]
可能存在所需文字位於文件樹內部某個子標籤中的情況。我們需要首先找到一個沒有其他元素的標籤,然後檢查所需文字是否在其中。
示例
html = ''' <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs./p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tags = soup.find_all(lambda tag: len(tag.find_all()) == 0 and "by" in tag.text) for tag in tags: print (tag)
輸出
<p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p>
Beautiful Soup - 移除 HTML 標籤
在本章中,我們將瞭解如何從 HTML 文件中刪除所有標籤。HTML 是一種標記語言,由預定義的標籤組成。標籤標記與其關聯的特定文字,以便瀏覽器根據其預定義的含義呈現它。例如,用 <b> 標籤標記的單詞 Hello(例如 <b>Hello</b>),由瀏覽器以粗體顯示。
如果我們想過濾掉 HTML 文件中不同標籤之間的原始文字,我們可以使用 Beautiful Soup 庫中的兩種方法中的任何一種 - get_text() 或 extract()。
get_text() 方法收集文件中的所有原始文字部分並返回一個字串。但是,原始文件樹不會改變。
在下面的示例中,get_text() 方法刪除了所有 HTML 標籤。
示例
html = '''
<html>
<body>
<p> The quick, brown fox jumps over a lazy dog.</p>
<p> DJs flock by when MTV ax quiz prog.</p>
<p> Junk MTV quiz graced by fox whelps.</p>
<p> Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
text = soup.get_text()
print(text)
輸出
The quick, brown fox jumps over a lazy dog. DJs flock by when MTV ax quiz prog. Junk MTV quiz graced by fox whelps. Bawds jog, flick quartz, vex nymphs.
請注意,上面示例中的 soup 物件仍然包含 HTML 文件的解析樹。
另一種方法是在從 soup 物件中提取之前收集包含在 Tag 物件中的字串。在 HTML 中,某些標籤沒有字串屬性(我們可以說對於某些標籤,例如 <html> 或 <body>,tag.string 為 None)。因此,我們將來自所有其他標籤的字串連線起來,以從 HTML 文件中獲取純文字。
以下程式演示了這種方法。
示例
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tags = soup.find_all()
string=''
for tag in tags:
#print (tag.name, tag.string)
if tag.string != None:
string=string+tag.string+'\n'
tag.extract()
print ("Document text after removing tags:")
print (string)
print ("Document:")
print (soup)
輸出
Document text after removing tags: The quick, brown fox jumps over a lazy dog. DJs flock by when MTV ax quiz prog. Junk MTV quiz graced by fox whelps. Bawds jog, flick quartz, vex nymphs. Document:
clear() 方法刪除標籤物件的內部字串,但不會返回它。類似地,decompose() 方法會銷燬標籤及其所有子元素。因此,這些方法不適合從 HTML 文件中檢索純文字。
Beautiful Soup - 移除所有樣式
本章介紹如何從 HTML 文件中刪除所有樣式。級聯樣式表 (CSS) 用於控制 HTML 文件不同方面的外觀。它包括使用特定字型、顏色、對齊方式、間距等樣式化文字的呈現。CSS 以不同的方式應用於 HTML 標籤。
一種是在 CSS 檔案中定義不同的樣式,並在 HTML 指令碼中使用文件 <head> 部分中的 <link> 標籤包含它。例如,
示例
<html>
<head>
<link rel="stylesheet" href="style.css">
</head>
<body>
. . .
. . .
</body>
</html>
HTML 指令碼正文部分中的不同標籤將使用 mystyle.css 檔案中的定義。
另一種方法是在 HTML 文件本身的 <head> 部分中定義樣式配置。正文部分中的標籤將使用內部提供的定義進行呈現。
內部樣式的示例:
<html>
<head>
<style>
p {
text-align: center;
color: red;
}
</style>
</head>
<body>
<p>para1.</p>
<p id="para1">para2</p>
<p>para3</p>
</body>
</html>
在任何一種情況下,要以程式設計方式刪除樣式,只需從 soup 物件中刪除 head 標籤。
from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") soup.head.extract()
第三種方法是透過在標籤本身中包含 style 屬性來內聯定義樣式。style 屬性可以包含一個或多個樣式屬性定義,例如顏色、大小等。例如
<body> <h1 style="color:blue;text-align:center;">This is a heading</h1> <p style="color:red;">This is a paragraph.</p> </body>
要從 HTML 文件中刪除此類內聯樣式,您需要檢查標籤物件的 attrs 字典中是否定義了 style 鍵,如果已定義,則刪除它。
tags=soup.find_all()
for tag in tags:
if tag.has_attr('style'):
del tag.attrs['style']
print (soup)
以下程式碼刪除內聯樣式並刪除 head 標籤本身,以便生成的 HTML 樹中不再有任何樣式。
html = '''
<html>
<head>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1 style="color:blue;text-align:center;">This is a heading</h1>
<p style="color:red;">This is a paragraph.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
soup.head.extract()
tags=soup.find_all()
for tag in tags:
if tag.has_attr('style'):
del tag.attrs['style']
print (soup.prettify())
輸出
<html> <body> <h1> This is a heading </h1> <p> This is a paragraph. </p> </body> </html>
Beautiful Soup - 移除所有指令碼
HTML 中經常使用的標籤之一是 <script> 標籤。它有助於在 HTML 中嵌入客戶端指令碼,例如 JavaScript 程式碼。在本章中,我們將使用 BeautifulSoup 從 HTML 文件中刪除指令碼標籤。
<script> 標籤有一個對應的 </script> 標籤。在這兩個標籤之間,您可以包含對外部 JavaScript 檔案的引用,或在 HTML 指令碼本身中內聯包含 JavaScript 程式碼。
要包含外部 Javascript 檔案,使用的語法為:
<head> <script src="javascript.js"></script> </head>
然後,您可以從 HTML 內部呼叫在此檔案中定義的函式。
您可以將 JavaScipt 程式碼放在 HTML 中的 <script> 和 </script> 程式碼之間,而不是引用外部檔案。如果將其放在 HTML 文件的 <head> 部分,則該功能在整個文件樹中可用。另一方面,如果將其放在 <body> 部分的任何位置,則 JavaScript 函式從該點開始可用。
<body>
<p>Hello World</p>
<script>
alert("Hello World")
</script>
</body>
使用 Beautiful 刪除所有指令碼標籤很容易。您必須從解析樹中收集所有指令碼標籤的列表,然後逐個提取它們。
示例
html = '''
<html>
<head>
<script src="javascript.js"></scrript>
</head>
<body>
<p>Hello World</p>
<script>
alert("Hello World")
</script>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
for tag in soup.find_all('script'):
tag.extract()
print (soup)
輸出
<html> <head> </head> </html>
您也可以使用 decompose() 方法而不是 extract(),區別在於後者返回已刪除的內容,而前者只是銷燬它。為了使程式碼更簡潔,您還可以使用列表推導式語法來實現刪除了指令碼標籤的 soup 物件,如下所示:
[tag.decompose() for tag in soup.find_all('script')]
Beautiful Soup - 移除空標籤
在 HTML 中,許多標籤都有開始標籤和結束標籤。此類標籤主要用於定義格式屬性,例如 <b> 和 </b>、<h1> 和 </h1> 等。還有一些自閉合標籤沒有結束標籤,也沒有文字部分。例如 <img>、<br>、<input> 等。但是,在編寫 HTML 時,可能會無意中插入諸如 <p></p> 之類的沒有文字的標籤。我們需要藉助 Beautiful Soup 庫函式刪除此類空標籤。
刪除開始和結束符號之間沒有任何文字的文字標籤很容易。如果標籤的內部文字長度為 0,則可以在標籤上呼叫 extract() 方法。
for tag in tags:
if (len(tag.get_text(strip=True)) == 0):
tag.extract()
但是,這會刪除 <hr>、<img> 和 <input> 等標籤。這些都是自閉合或單例標籤。即使與標籤沒有關聯的文字,您也不希望關閉具有一個或多個屬性的標籤。因此,您必須檢查標籤是否具有任何屬性以及 get_text() 是否返回 None。
在下面的示例中,HTML 字串中同時存在空文字標籤和一些單例標籤的情況。該程式碼保留了具有屬性的標籤,但刪除了沒有任何嵌入文字的標籤。
示例
html ='''
<html>
<body>
<p>Paragraph</p>
<embed type="image/jpg" src="Python logo.jpg" width="300" height="200">
<hr>
<b></b>
<p>
<a href="#">Link</a>
<ul>
<li>One</li>
</ul>
<input type="text" id="fname" name="fname">
<img src="img_orange_flowers.jpg" alt="Flowers">
</body>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tags =soup.find_all()
for tag in tags:
if (len(tag.get_text(strip=True)) == 0):
if len(tag.attrs)==0:
tag.extract()
print (soup)
輸出
<html> <body> <p>Paragraph</p> <embed height="200" src="Python logo.jpg" type="image/jpg" width="300"/> <p> <a href="#">Link</a> <ul> <li>One</li> </ul> <input id="fname" name="fname" type="text"/> <img alt="Flowers" src="img_orange_flowers.jpg"/> </p> </body> </html>
請注意,原始 html 程式碼有一個沒有其結束 </p> 的 <p> 標籤。解析器會自動插入結束標籤。如果您將解析器更改為 lxml 或 html5lib,結束標籤的位置可能會更改。
Beautiful Soup - 移除子元素
HTML 文件是不同標籤的層次結構排列,其中一個標籤可能在多個級別巢狀一個或多個標籤。我們如何刪除某個標籤的子元素?使用 BeautifulSoup,這很容易做到。
Beautiful Soup 庫中有兩種主要方法可以刪除某個標籤。decompose() 方法和 extract() 方法,區別在於後者返回已刪除的內容,而前者只是銷燬它。
因此,要刪除子元素,請為給定的 Tag 物件呼叫 findChildren() 方法,然後對每個子元素呼叫 extract() 或 decompose()。
考慮以下程式碼段:
soup = BeautifulSoup(fp, "html.parser") soup.decompose() print (soup)
這將銷燬整個 soup 物件本身,它是文件的解析樹。顯然,我們不想這樣做。
現在以下程式碼:
soup = BeautifulSoup(fp, "html.parser")
tags = soup.find_all()
for tag in tags:
for t in tag.findChildren():
t.extract()
在文件樹中,<html> 是第一個標籤,所有其他標籤都是它的子元素,因此它將在迴圈的第一次迭代中刪除除 <html> 和 </html> 之外的所有標籤。
如果我們想要刪除特定標籤的子元素,可以更有效地使用它。例如,您可能希望刪除 HTML 表格的標題行。
以下 HTML 指令碼有一個表格,其中第一個 <tr> 元素的標題由 <th> 標籤標記。
<html>
<body>
<h2>Beautiful Soup - Remove Child Elements</h2>
<table border="1">
<tr class='header'>
<th>Name</th>
<th>Age</th>
<th>Marks</th>
</tr>
<tr>
<td>Ravi</td>
<td>23</td>
<td>67</td>
</tr>
<tr>
<td>Anil</td>
<td>27</td>
<td>84</td>
</tr>
</table>
</body>
</html>
我們可以使用以下 Python 程式碼刪除 <tr> 標籤的所有子元素,包括 <th> 單元格。
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, "html.parser")
tags = soup.find_all('tr', {'class':'header'})
for tag in tags:
for t in tag.findChildren():
t.extract()
print (soup)
輸出
<html> <body> <h2>Beautiful Soup - Parse Table</h2> <table border="1"> <tr class="header"> </tr> <tr> <td>Ravi</td> <td>23</td> <td>67</td> </tr> <tr> <td>Anil</td> <td>27</td> <td>84</td> </tr> </table> </body> </html>
可以看出,<th> 元素已從解析樹中刪除。
Beautiful Soup - find 與 find_all 的區別
Beautiful Soup 庫包含 find() 和 find_all() 方法。這兩種方法是解析 HTML 或 XML 文件時最常用的方法之一。從特定的文件樹中,您經常需要定位特定標籤型別、具有特定屬性或具有特定 CSS 樣式等的 PageElement。這些條件作為引數傳遞給 find() 和 find_all() 方法。這兩個方法的主要區別在於,find() 定位滿足條件的第一個子元素,而 find_all() 方法搜尋滿足條件的所有子元素。
find() 方法的語法定義如下:
語法
find(name, attrs, recursive, string, **kwargs)
name 引數指定對標籤名稱的過濾。使用 attrs,可以設定對標籤屬性值的過濾。如果 recursive 引數為 True,則強制進行遞迴搜尋。您可以將變數 kwargs 作為屬性值過濾器字典傳遞。
soup.find(id = 'nm')
soup.find(attrs={"name":'marks'})
find_all() 方法接受 find() 方法的所有引數,此外還有一個 limit 引數。它是一個整數,將搜尋限制為給定篩選條件出現的指定次數。如果未設定,find_all() 會在所述 PageElement 下的所有子元素中搜索條件。
soup.find_all('input')
lst=soup.find_all('li', limit =2)
如果 find_all() 方法的 limit 引數設定為 1,則它實際上充當 find() 方法。
兩種方法的返回型別不同。find() 方法返回第一個找到的 Tag 物件或 NavigableString 物件。find_all() 方法返回一個 ResultSet,其中包含滿足篩選條件的所有 PageElement。
以下示例演示了 find 和 find_all 方法之間的區別。
示例
from bs4 import BeautifulSoup
markup =open("index.html")
soup = BeautifulSoup(markup, 'html.parser')
ret1 = soup.find('input')
ret2 = soup.find_all ('input')
print (ret1, 'Return type of find:', type(ret1))
print (ret2)
print ('Return tyoe find_all:', type(ret2))
#set limit =1
ret3 = soup.find_all ('input', limit=1)
print ('find:', ret1)
print ('find_all:', ret3)
輸出
<input id="nm" name="name" type="text"/> Return type of find: <class 'bs4.element.Tag'> [<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>, <input id="marks" name="marks" type="text"/>] Return tyoe find_all: <class 'bs4.element.ResultSet'> find: <input id="nm" name="name" type="text"/> find_all: [<input id="nm" name="name" type="text"/>]
Beautiful Soup - 指定解析器
HTML 文件樹被解析到 BeautifulSoup 類的物件中。此類的建構函式需要 HTML 字串或指向 html 檔案的檔案物件作為必填引數。建構函式具有所有其他可選引數,其中重要的是 features。
BeautifulSoup(markup, features)
這裡 markup 是一個 HTML 字串或檔案物件。features 引數指定要使用的解析器。它可以是特定的解析器,例如“lxml”、“lxml-xml”、“html.parser”或“html5lib”;或要使用的標記型別(“html”、“html5”、“xml”)。
如果未提供 features 引數,則 BeautifulSoup 會選擇安裝的最佳 HTML 解析器。Beautiful Soup 將 lxml 的解析器評為最佳,然後是 html5lib 的解析器,最後是 Python 的內建解析器。
您可以指定以下之一:
您要解析的標記型別。Beautiful Soup 當前支援“html”、“xml”和“html5”。
要使用的解析器庫的名稱。當前支援的選項為“lxml”、“html5lib”和“html.parser”(Python 的內建 HTML 解析器)。
要安裝 lxml 或 html5lib 解析器,請使用以下命令:
pip3 install lxml pip3 install html5lib
這些解析器各有優缺點,如下所示:
解析器:Python 的 html.parser
用法 − BeautifulSoup(markup, "html.parser")
優點
- 內建
- 速度不錯
- 寬容(從 Python 3.2 開始)
缺點
- 速度不如 lxml,寬容度不如 html5lib。
解析器:lxml 的 HTML 解析器
用法 − BeautifulSoup(markup, "lxml")
優點
- 非常快
- 寬鬆的
缺點
- 外部 C 依賴
解析器:lxml 的 XML 解析器
用法 − BeautifulSoup(markup, "lxml-xml")
或 BeautifulSoup(markup, "xml")
優點
- 非常快
- 目前唯一支援的 XML 解析器
缺點
- 外部 C 依賴
解析器:html5lib
用法 − BeautifulSoup(markup, "html5lib")
優點
- 極其寬鬆
- 以與網路瀏覽器相同的方式解析頁面
- 建立有效的 HTML5
缺點
- 非常慢
- 外部 Python 依賴
不同的解析器將從同一文件建立不同的解析樹。HTML 解析器和 XML 解析器之間存在最大的差異。這是一個簡短的文件,作為 HTML 解析:
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<a><b /></a>", "html.parser")
print (soup)
輸出
<a><b></b></a>
空的 <b /> 標籤不是有效的 HTML。因此,解析器將其轉換為 <b></b> 標籤對。
現在將同一文件作為 XML 解析。請注意,空的 <b /> 標籤保持不變,並且該文件被賦予 XML 宣告而不是放入 <html> 標籤中。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<a><b /></a>", "xml")
print (soup)
輸出
<?xml version="1.0" encoding="utf-8"?> <a><b/></a>
對於格式良好的 HTML 文件,所有 HTML 解析器都會產生類似的解析樹,儘管一個解析器會比另一個解析器更快。
但是,如果 HTML 文件不完美,則不同型別的解析器會產生不同的結果。請參閱當“<a></p>” 使用不同的解析器解析時結果有何不同:
lxml 解析器
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<a></p>", "lxml")
print (soup)
輸出
<html><body><a></a></body></html>
請注意,懸掛的 </p> 標籤被簡單地忽略了。
html5lib 解析器
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<a></p>", "html5lib")
print (soup)
輸出
<html><head></head><body><a><p></p></a></body></html>
html5lib 將其與一個起始 <p> 標籤配對。此解析器還向文件添加了一個空的 <head> 標籤。
內建 html 解析器
示例
Built in from bs4 import BeautifulSoup
soup = BeautifulSoup("<a></p>", "html.parser")
print (soup)
輸出
<a></a>
此解析器也會忽略結束 </p> 標籤。但是,此解析器不會嘗試透過新增 <body> 標籤來建立格式良好的 HTML 文件,甚至不費心新增 <html> 標籤。
html5lib 解析器使用 HTML5 標準中包含的技術,因此它對成為“正確”方法擁有最佳主張。
Beautiful Soup - 比較物件
根據 beautiful soup,如果兩個可導航字串或標籤物件表示相同的 HTML/XML 標記,則它們相等。
現在讓我們看看下面的示例,其中兩個 <b> 標籤被視為相等,即使它們位於物件樹的不同部分,因為它們都看起來像“<b>Java</b>”。
示例
from bs4 import BeautifulSoup
markup = "<p>Learn <i>Python</i>, <b>Java</b>, advanced <i>Python</i> and advanced <b>Java</b>! from Tutorialspoint</p>"
soup = BeautifulSoup(markup, "html.parser")
b1 = soup.find('b')
b2 = b1.find_next('b')
print(b1== b2)
print(b1 is b2)
輸出
True False
在以下示例中,比較了兩個 NavigableString 物件。
示例
from bs4 import BeautifulSoup
markup = "<p>Learn <i>Python</i>, <b>Java</b>, advanced <i>Python</i> and advanced <b>Java</b>! from Tutorialspoint</p>"
soup = BeautifulSoup(markup, "html.parser")
i1 = soup.find('i')
i2 = i1.find_next('i')
print(i1.string== i2.string)
print(i1.string is i2.string)
輸出
True False
Beautiful Soup - 複製物件
要建立任何標籤或 NavigableString 的副本,請使用 Python 標準庫中 copy 模組的 copy() 函式。
示例
from bs4 import BeautifulSoup
import copy
markup = "<p>Learn <b>Python, Java</b>, <i>advanced Python and advanced Java</i>! from Tutorialspoint</p>"
soup = BeautifulSoup(markup, "html.parser")
i1 = soup.find('i')
icopy = copy.copy(i1)
print (icopy)
輸出
<i>advanced Python and advanced Java</i>
儘管兩個副本(原始副本和複製副本)包含相同的標記,但是這兩個副本不表示相同的物件。
print (i1 == icopy) print (i1 is icopy)
輸出
True False
複製的物件完全與原始 Beautiful Soup 物件樹分離,就像在它上面呼叫了 extract() 一樣。
print (icopy.parent)
輸出
None
Beautiful Soup - 獲取標籤位置
Beautiful Soup 中的 Tag 物件擁有兩個有用的屬性,它們提供了有關其在 HTML 文件中的位置的資訊。它們是:
sourceline - 找到標籤的行號
sourcepos - 找到標籤所在行的標籤的起始索引。
這些屬性受 Python 的內建解析器 html.parser 和 html5lib 解析器支援。當您使用 lmxl 解析器時,它們不可用。
在以下示例中,HTML 字串使用 html.parser 進行解析,我們找到 HTML 字串中 <p> 標籤的行號和位置。
示例
html = '''
<html>
<body>
<p>Web frameworks</p>
<ul>
<li>Django</li>
<li>Flask</li>
</ul>
<p>GUI frameworks</p>
<ol>
<li>Tkinter</li>
<li>PyQt</li>
</ol>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
p_tags = soup.find_all('p')
for p in p_tags:
print (p.sourceline, p.sourcepos, p.string)
輸出
4 0 Web frameworks 9 0 GUI frameworks
對於 html.parser,這些數字表示初始小於號的位置,在本例中為 0。當使用 html5lib 解析器時,它略有不同。
示例
html = '''
<html>
<body>
<p>Web frameworks</p>
<ul>
<li>Django</li>
<li>Flask</li>
</ul>
<p>GUI frameworks</p>
<ol>
<li>Tkinter</li>
<li>PyQt</li>
</ol>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html5lib')
li_tags = soup.find_all('li')
for l in li_tags:
print (l.sourceline, l.sourcepos, l.string)
輸出
6 3 Django 7 3 Flask 11 3 Tkinter 12 3 PyQt
當使用 html5lib 時,sourcepos 屬性返回最終大於號的位置。
Beautiful Soup - 編碼
所有 HTML 或 XML 文件都以某種特定的編碼(如 ASCII 或 UTF-8)編寫。但是,當您將該 HTML/XML 文件載入到 BeautifulSoup 中時,它已轉換為 Unicode。
示例
from bs4 import BeautifulSoup markup = "<p>I will display £</p>" soup = BeautifulSoup(markup, "html.parser") print (soup.p) print (soup.p.string)
輸出
<p>I will display £</p> I will display £
上述行為是因為 BeautifulSoup 在內部使用名為 Unicode、Dammit 的子庫來檢測文件的編碼,然後將其轉換為 Unicode。
但是,並非總是如此,Unicode、Dammit 的猜測都是正確的。由於逐位元組搜尋文件以猜測編碼,因此需要花費大量時間。如果您已經知道編碼,則可以透過將其作為 from_encoding 傳遞給 BeautifulSoup 建構函式來節省一些時間並避免錯誤。
以下是一個示例,其中 BeautifulSoup 將 ISO-8859-8 文件錯誤識別為 ISO-8859-7:
示例
from bs4 import BeautifulSoup markup = b"<h1>\xed\xe5\xec\xf9</h1>" soup = BeautifulSoup(markup, 'html.parser') print (soup.h1) print (soup.original_encoding)
輸出
<h1>翴檛</h1> ISO-8859-7
要解決上述問題,請使用 from_encoding 將其傳遞給 BeautifulSoup:
示例
from bs4 import BeautifulSoup markup = b"<h1>\xed\xe5\xec\xf9</h1>" soup = BeautifulSoup(markup, "html.parser", from_encoding="iso-8859-8") print (soup.h1) print (soup.original_encoding)
輸出
<h1>םולש</h1> iso-8859-8
從 BeautifulSoup 4.4.0 開始新增的另一個新功能是 exclude_encoding。當您不知道正確的編碼,但確定 Unicode、Dammit 顯示錯誤結果時,可以使用它。
soup = BeautifulSoup(markup, exclude_encodings=["ISO-8859-7"])
輸出編碼
無論輸入到 BeautifulSoup 的文件是什麼,來自 BeautifulSoup 的輸出都是 UTF-8 文件。以下是一個文件,其中波蘭字元以 ISO-8859-2 格式存在。
示例
markup = """
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<HTML>
<HEAD>
<META HTTP-EQUIV="content-type" CONTENT="text/html; charset=iso-8859-2">
</HEAD>
<BODY>
ą ć ę ł ń ó ś ź ż Ą Ć Ę Ł Ń Ó Ś Ź Ż
</BODY>
</HTML>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup, "html.parser", from_encoding="iso-8859-8")
print (soup.prettify())
輸出
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<meta content="text/html; charset=utf-8" http-equiv="content-type"/>
</head>
<body>
ą ć ę ł ń ó ś ź ż Ą Ć Ę Ł Ń Ó Ś Ź Ż
</body>
</html>
在上面的示例中,如果您注意到了,<meta> 標籤已被重寫以反映從 BeautifulSoup 生成的文件現在採用 UTF-8 格式。
如果您不希望生成的輸出為 UTF-8,則可以在 prettify() 中分配所需的編碼。
print(soup.prettify("latin-1"))
輸出
b'<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">\n<html>\n <head>\n <meta content="text/html; charset=latin-1" http-equiv="content-type"/>\n </head>\n <body>\n ą ć ę ł ń \xf3 ś ź ż Ą Ć Ę Ł Ń \xd3 Ś Ź Ż\n </body>\n</html>\n'
在上面的示例中,我們對整個文件進行了編碼,但是您可以對 soup 中的任何特定元素進行編碼,就像它們是 python 字串一樣:
soup.p.encode("latin-1")
soup.h1.encode("latin-1")
輸出
b'<p>My first paragraph.</p>' b'<h1>My First Heading</h1>'
任何無法在您選擇的編碼中表示的字元都將轉換為數字 XML 實體引用。以下是一個這樣的示例:
markup = u"<b>\N{SNOWMAN}</b>"
snowman_soup = BeautifulSoup(markup)
tag = snowman_soup.b
print(tag.encode("utf-8"))
輸出
b'<b>\xe2\x98\x83</b>'
如果您嘗試在“latin-1”或“ascii”中對其進行編碼,它將生成“☃”,表示沒有該字元的表示形式。
print (tag.encode("latin-1"))
print (tag.encode("ascii"))
輸出
b'<b>☃</b>' b'<b>☃</b>'
Unicode、Dammit
Unicode、Dammit 主要用於傳入文件格式未知(主要是外語)且我們希望以某種已知格式(Unicode)進行編碼,並且我們不需要 Beautifulsoup 執行所有這些操作的情況。
Beautiful Soup - 輸出格式化
如果傳遞給 BeautifulSoup 建構函式的 HTML 字串包含任何 HTML 實體,它們將轉換為 Unicode 字元。
HTML 實體是以 & 開頭並以 ; 結尾的字串。它們用於顯示保留字元(否則將被解釋為 HTML 程式碼)。一些 HTML 實體示例如下:
| < | 小於 | < | < |
| > | 大於 | > | > |
| & | 和號 | & | & |
| " | 雙引號 | " | " |
| ' | 單引號 | ' | ' |
| " | 左雙引號 | “ | “ |
| " | 右雙引號 | ” | ” |
| £ | 英鎊 | £ | £ |
| ¥ | 日元 | ¥ | ¥ |
| € | 歐元 | € | € |
| © | 版權 | © | © |
預設情況下,輸出時唯一轉義的字元是裸和號和尖括號。它們將轉換為“&”、“<”和“>”。
對於其他字元,它們將轉換為 Unicode 字元。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("Hello “World!”", 'html.parser')
print (str(soup))
輸出
Hello "World!"
如果您隨後將文件轉換為位元組字串,則 Unicode 字元將編碼為 UTF-8。您將無法取回 HTML 實體:
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("Hello “World!”", 'html.parser')
print (soup.encode())
輸出
b'Hello \xe2\x80\x9cWorld!\xe2\x80\x9d'
要更改此行為,請為 prettify() 方法的 formatter 引數提供一個值。formatter 有以下可能的值。
formatter="minimal" - 這是預設值。字串將僅被處理到足以確保 Beautiful Soup 生成有效的 HTML/XML。
formatter="html" - Beautiful Soup 將盡可能地將 Unicode 字元轉換為 HTML 實體。
formatter="html5" - 它類似於 formatter="html",但 Beautiful Soup 將省略 HTML 空標籤(如“br”)中的結束斜槓。
formatter=None - Beautiful Soup 根本不會修改輸出的字串。這是最快的選項,但可能導致 Beautiful Soup 生成無效的 HTML/XML。
示例
from bs4 import BeautifulSoup
french = "<p>Il a dit <<Sacré bleu!>></p>"
soup = BeautifulSoup(french, 'html.parser')
print ("minimal: ")
print(soup.prettify(formatter="minimal"))
print ("html: ")
print(soup.prettify(formatter="html"))
print ("None: ")
print(soup.prettify(formatter=None))
輸出
minimal: <p> Il a dit <<Sacré bleu!>> </p> html: <p> Il a dit <<Sacré bleu!>> </p> None: <p> Il a dit <<Sacré bleu!>> </p>
此外,Beautiful Soup 庫還提供了 formatter 類。您可以將任何這些類的物件作為引數傳遞給 prettify() 方法。
HTMLFormatter 類 - 用於自定義 HTML 文件的格式規則。
XMLFormatter 類 - 用於自定義 XML 文件的格式規則。
Beautiful Soup - 美化輸出
要顯示 HTML 文件的整個解析樹或特定標籤的內容,您可以使用 print() 函式或呼叫 str() 函式。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<h1>Hello World</h1>", "lxml")
print ("Tree:",soup)
print ("h1 tag:",str(soup.h1))
輸出
Tree: <html><body><h1>Hello World</h1></body></html> h1 tag: <h1>Hello World</h1>
str() 函式返回一個以 UTF-8 編碼的字串。
要獲得格式良好的 Unicode 字串,請使用 Beautiful Soup 的 prettify() 方法。它格式化 Beautiful Soup 解析樹,以便每個標籤都位於自己的單獨行並帶有縮排。它允許您輕鬆地視覺化 Beautiful Soup 解析樹的結構。
考慮以下 HTML 字串。
<p>The quick, <b>brown fox</b> jumps over a lazy dog.</p>
使用 prettify() 方法,我們可以更好地理解其結構:
html = ''' <p>The quick, <b>brown fox</b> jumps over a lazy dog.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "lxml") print (soup.prettify())
輸出
<html>
<body>
<p>
The quick,
<b>
brown fox
</b>
jumps over a lazy dog.
</p>
</body>
</html>
您可以在文件中的任何 Tag 物件上呼叫 prettify()。
print (soup.b.prettify())
輸出
<b> brown fox </b>
prettify() 方法用於理解文件的結構。但是,它不應用於重新格式化它,因為它添加了空格(以換行符的形式),並更改了 HTML 文件的含義。
He prettify() 方法可以選擇提供 formatter 引數來指定要使用的格式。
Beautiful Soup - NavigableString 類
Beautiful Soup API 中一個主要的常用物件是 NavigableString 類物件。它表示大多數 HTML 標籤的開始和結束標記之間的字串或文字。例如,如果 <b>Hello</b> 是要解析的標記,則 Hello 就是 NavigableString。
NavigableString 類是 bs4 包中 PageElement 類的子類,同時也是 Python 內建的 str 類的子類。因此,它繼承了 PageElement 方法,如 find_*()、insert、append、wrap、unwrap 方法,以及 str 類的方法,如 upper、lower、find、isalpha 等。
此類的建構函式接受一個引數,一個 str 物件。
示例
from bs4 import NavigableString
new_str = NavigableString('world')
現在可以使用此 NavigableString 物件對解析後的樹執行各種操作,例如 append、insert、find 等。
在下面的示例中,我們將新建立的 NavigableString 物件追加到現有的 Tab 物件。
示例
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
new_str = NavigableString('world')
tag.append(new_str)
print (soup)
輸出
<b>Helloworld</b>
請注意,NavigableString 是一個 PageElement,因此它也可以追加到 Soup 物件。檢查如果這樣做會有什麼區別。
示例
new_str = NavigableString('world')
soup.append(new_str)
print (soup)
輸出
<b>Hello</b>world
如我們所見,字串出現在 <b> 標籤之後。
Beautiful Soup 提供了一個 new_string() 方法。建立一個與此 BeautifulSoup 物件關聯的新 NavigableString。
讓我們使用 new_string() 方法建立一個 NavigableString 物件,並將其新增到 PageElements 中。
示例
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
ns=soup.new_string(' World')
tag.append(ns)
print (tag)
soup.append(ns)
print (soup)
輸出
<b>Hello World</b> <b>Hello</b> World
我們在這裡發現了一個有趣的行為。NavigableString 物件被新增到樹中的一個標籤中,以及 Soup 物件本身。雖然標籤顯示了追加的字串,但在 Soup 物件中,文字 World 被追加,但它沒有顯示在標籤中。這是因為 new_string() 方法建立了一個與 Soup 物件關聯的 NavigableString。
Beautiful Soup - 將物件轉換為字串
Beautiful Soup API 有三種主要型別的物件:Soup 物件、Tag 物件和 NavigableString 物件。讓我們找出如何將這些物件中的每一個轉換為字串。在 Python 中,字串是 str 物件。
假設我們有以下 HTML 文件
html = ''' <p>Hello <b>World</b></p> '''
讓我們將此字串作為 BeautifulSoup 建構函式的引數。然後,Soup 物件使用 Python 的內建 str() 函式轉換為字串物件。
此 HTML 字串的解析樹將根據您使用的解析器構建。內建的 html 解析器不會新增 <html> 和 <body> 標籤。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') print (str(soup))
輸出
<p>Hello <b>World</b></p>
另一方面,html5lib 解析器在插入正式標籤(如 <html> 和 <body>)後構建樹。
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html5lib') print (str(soup))
輸出
<html><head></head><body><p>Hello <b>World</b></p> </body></html>
Tag 物件有一個字串屬性,它返回一個 NavigableString 物件。
tag = soup.find('b')
obj = (tag.string)
print (type(obj),obj)
輸出
string <class 'bs4.element.NavigableString'> World
Tag 物件還定義了一個 Text 屬性。它返回標籤中包含的文字,剝離所有內部標籤和屬性。
如果 HTML 字串為 -
html = ''' <p>Hello <div id='id'>World</div></p> '''
我們嘗試獲取 <p> 標籤的 text 屬性
tag = soup.find('p')
obj = (tag.text)
print ( type(obj), obj)
輸出
<class 'str'> Hello World
您還可以使用 get_text() 方法,該方法返回表示標籤內文字的字串。該函式實際上是 text 屬性的包裝器,因為它也去除了內部標籤和屬性,並返回一個字串
obj = tag.get_text() print (type(obj),obj)
輸出
<class 'str'> Hello World
Beautiful Soup - 將 HTML 轉換為文字
像 Beautiful Soup 庫這樣的 Web 爬蟲的一個重要且經常需要的應用是從 HTML 指令碼中提取文字。您可能需要丟棄所有標籤以及與每個標籤關聯的屬性(如果有),並分離出文件中的原始文字。Beautiful Soup 中的 get_text() 方法適合此目的。
這是一個演示 get_text() 方法用法的基本示例。透過刪除所有 HTML 標籤,您可以獲取 HTML 文件中的所有文字。
示例
html = '''
<html>
<body>
<p> The quick, brown fox jumps over a lazy dog.</p>
<p> DJs flock by when MTV ax quiz prog.</p>
<p> Junk MTV quiz graced by fox whelps.</p>
<p> Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
text = soup.get_text()
print(text)
輸出
The quick, brown fox jumps over a lazy dog. DJs flock by when MTV ax quiz prog. Junk MTV quiz graced by fox whelps. Bawds jog, flick quartz, vex nymphs.
get_text() 方法有一個可選的分隔符引數。在下面的示例中,我們將 get_text() 方法的分隔符引數指定為 '#'。
html = ''' <p>The quick, brown fox jumps over a lazy dog.</p> <p>DJs flock by when MTV ax quiz prog.</p> <p>Junk MTV quiz graced by fox whelps.</p> <p>Bawds jog, flick quartz, vex nymphs.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") text = soup.get_text(separator='#') print(text)
輸出
#The quick, brown fox jumps over a lazy dog.# #DJs flock by when MTV ax quiz prog.# #Junk MTV quiz graced by fox whelps.# #Bawds jog, flick quartz, vex nymphs.#
get_text() 方法還有另一個引數 strip,它可以是 True 或 False。讓我們檢查當 strip 引數設定為 True 時產生的效果。預設情況下它為 False。
html = ''' <p>The quick, brown fox jumps over a lazy dog.</p> <p>DJs flock by when MTV ax quiz prog.</p> <p>Junk MTV quiz graced by fox whelps.</p> <p>Bawds jog, flick quartz, vex nymphs.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") text = soup.get_text(strip=True) print(text)
輸出
The quick, brown fox jumps over a lazy dog.DJs flock by when MTV ax quiz prog.Junk MTV quiz graced by fox whelps.Bawds jog, flick quartz, vex nymphs.
Beautiful Soup - 解析 XML
BeautifulSoup 還可以解析 XML 文件。您需要將 fatures='xml' 引數傳遞給 Beautiful() 建構函式。
假設我們在當前工作目錄中有以下 books.xml -
示例
<?xml version="1.0" ?>
<books>
<book>
<title>Python</title>
<author>TutorialsPoint</author>
<price>400</price>
</book>
</books>
以下程式碼解析給定的 XML 檔案 -
from bs4 import BeautifulSoup
fp = open("books.xml")
soup = BeautifulSoup(fp, features="xml")
print (soup)
print ('type:', type(soup))
執行上述程式碼後,您應該得到以下結果 -
<?xml version="1.0" encoding="utf-8"?> <books> <book> <title>Python</title> <author>TutorialsPoint</author> <price>400</price> </book> </books> type: <class 'bs4.BeautifulSoup'>
XML 解析器錯誤
預設情況下,BeautifulSoup 包將文件解析為 HTML,但是,它非常易於使用,並且可以使用 beautifulsoup4 以非常優雅的方式處理格式錯誤的 XML。
要將文件解析為 XML,您需要安裝 lxml 解析器,只需將“xml”作為第二個引數傳遞給 Beautifulsoup 建構函式 -
soup = BeautifulSoup(markup, "lxml-xml")
或
soup = BeautifulSoup(markup, "xml")
一個常見的 XML 解析錯誤是 -
AttributeError: 'NoneType' object has no attribute 'attrib'
這可能發生在使用 find() 或 findall() 函式時缺少或未定義某些元素的情況下。
Beautiful Soup - 錯誤處理
在嘗試使用 Beautiful Soup 解析 HTML/XML 文件時,您可能會遇到錯誤,這些錯誤不是來自您的指令碼,而是來自程式碼段的結構,因為 BeautifulSoup API 會丟擲錯誤。
預設情況下,BeautifulSoup 包將文件解析為 HTML,但是,它非常易於使用,並且可以使用 beautifulsoup4 以非常優雅的方式處理格式錯誤的 XML。
要將文件解析為 XML,您需要安裝 lxml 解析器,只需將“xml”作為第二個引數傳遞給 Beautifulsoup 建構函式 -
soup = BeautifulSoup(markup, "lxml-xml")
或
soup = BeautifulSoup(markup, "xml")
一個常見的 XML 解析錯誤是 -
AttributeError: 'NoneType' object has no attribute 'attrib'
這可能發生在使用 find() 或 findall() 函式時缺少或未定義某些元素的情況下。
除了上述解析錯誤之外,您可能會遇到其他解析問題,例如環境問題,您的指令碼可能在一個作業系統中工作,但在另一個作業系統中不工作,或者可能在一個虛擬環境中工作,但在另一個虛擬環境中不工作,或者可能在虛擬環境外部不工作。所有這些問題可能是因為這兩個環境具有不同的解析器庫可用。
建議瞭解或檢查您當前工作環境中的預設解析器。您可以檢查當前工作環境中可用的當前預設解析器,或者顯式地將所需的解析器庫作為第二個引數傳遞給 BeautifulSoup 建構函式。
由於 HTML 標籤和屬性不區分大小寫,因此所有三個 HTML 解析器都將標籤和屬性名稱轉換為小寫。但是,如果您想保留混合大小寫或大寫標籤和屬性,那麼最好將文件解析為 XML。
UnicodeEncodeError
讓我們看一下下面的程式碼段 -
示例
soup = BeautifulSoup(response, "html.parser") print (soup)
輸出
UnicodeEncodeError: 'charmap' codec can't encode character '\u011f'
上述問題可能是由於兩種主要情況造成的。您可能正在嘗試列印控制檯不知道如何顯示的 Unicode 字元。其次,您正在嘗試寫入檔案,並且傳遞了一個預設編碼不支援的 Unicode 字元。
解決上述問題的一種方法是在將響應文字/字元轉換為 Soup 之前對其進行編碼以獲得所需的結果,如下所示 -
responseTxt = response.text.encode('UTF-8')
KeyError: [attr]
當您訪問 tag['attr'] 時,而所討論的標籤未定義 attr 屬性時,就會發生這種情況。最常見的錯誤是:“KeyError: 'href'”和“KeyError: 'class'”。如果您不確定是否定義了 attr,請使用 tag.get('attr')。
for item in soup.fetch('a'):
try:
if (item['href'].startswith('/') or "tutorialspoint" in item['href']):
(...)
except KeyError:
pass # or some other fallback action
AttributeError
您可能會遇到如下 AttributeError -
AttributeError: 'list' object has no attribute 'find_all'
上述錯誤主要發生是因為您期望 find_all() 返回單個標籤或字串。但是,soup.find_all 返回一個 Python 元素列表。
您需要做的就是遍歷列表並從這些元素中捕獲資料。
為了避免在解析結果時出現上述錯誤,將繞過該結果以確保格式錯誤的程式碼段不會插入資料庫中 -
except(AttributeError, KeyError) as er: pass
Beautiful Soup - 故障排除
如果您在嘗試解析 HTML/XML 文件時遇到問題,則更有可能是因為所使用的解析器如何解釋文件。為了幫助您找到並糾正問題,Beautiful Soup API 提供了一個 diagnose() 實用程式。
Beautiful Soup 中的 diagnose() 方法是用於隔離常見問題的診斷套件。如果您難以理解 Beautiful Soup 對文件做了什麼,請將文件作為引數傳遞給 diagnose() 函式。一個報告將向您展示不同的解析器如何處理文件,並告訴您是否缺少解析器。
diagnose() 方法在 bs4.diagnose 模組中定義。它的輸出以如下訊息開頭 -
示例
diagnose(markup)
輸出
Diagnostic running on Beautiful Soup 4.12.2 Python version 3.11.2 (tags/v3.11.2:878ead1, Feb 7 2023, 16:38:35) [MSC v.1934 64 bit (AMD64)] Found lxml version 4.9.2.0 Found html5lib version 1.1 Trying to parse your markup with html.parser Here's what html.parser did with the markup:
如果它找不到任何這些解析器,也會出現相應的提示。
I noticed that html5lib is not installed. Installing it may help.
如果提供給 diagnose() 方法的 HTML 文件格式正確,則任何解析器解析的樹都將相同。但是,如果格式不正確,則不同的解析器會進行不同的解釋。如果您沒有獲得預期的樹,則更改解析器可能會有所幫助。
有時,您可能為 XML 文件選擇了 HTML 解析器。HTML 解析器在錯誤地解析文件時會新增所有 HTML 標籤。檢視輸出,您將意識到錯誤並可以幫助糾正。
如果 Beautiful Soup 丟擲 HTMLParser.HTMLParseError,請嘗試更改解析器。
解析錯誤 HTMLParser.HTMLParseError: malformed start tag 和 HTMLParser.HTMLParseError: bad end tag 均由 Python 的內建 HTML 解析器庫生成,解決方法是安裝 lxml 或 html5lib。
如果您遇到 SyntaxError: Invalid syntax (在 ROOT_TAG_NAME = '[document]' 行上),這是因為在 Python 3 下執行舊版 Python 2 的 Beautiful Soup,而沒有轉換程式碼。
帶有訊息 No module named HTMLParser 的 ImportError 是因為在 Python 3 下執行舊版 Python 2 的 Beautiful Soup。
而 ImportError: No module named html.parser - 是因為在 Python 2 下執行 Python 3 版的 Beautiful Soup 造成的。
如果您收到 ImportError: No module named BeautifulSoup - 通常情況下,這是因為在未安裝 BS3 的系統上執行 Beautiful Soup 3 程式碼。或者,在編寫 Beautiful Soup 4 程式碼時不知道包名稱已更改為 bs4。
最後,ImportError: No module named bs4 - 是因為您嘗試在未安裝 BS4 的系統上執行 Beautiful Soup 4 程式碼。
Beautiful Soup - 移植舊程式碼
您可以透過在 import 語句中進行以下更改,使早期版本的 Beautiful Soup 中的程式碼與最新版本相容 -
示例
from BeautifulSoup import BeautifulSoup #becomes this: from bs4 import BeautifulSoup
如果您收到 ImportError“No module named BeautifulSoup”,則表示您正在嘗試執行 Beautiful Soup 3 程式碼,但您只安裝了 Beautiful Soup 4。類似地,如果您收到 ImportError“No module named bs4”,因為您正在嘗試執行 Beautiful Soup 4 程式碼,但您只安裝了 Beautiful Soup 3。
Beautiful Soup 3 使用 Python 的 SGMLParser,這是一個已在 Python 3.0 中刪除的模組。Beautiful Soup 4 預設使用 html.parser,但您也可以使用 lxml 或 html5lib。
儘管 BS4 與 BS3 大致向後相容,但其大多數方法已被棄用,併為符合 PEP 8 標準而改用了新名稱。
以下是一些示例 -
replaceWith -> replace_with findAll -> find_all findNext -> find_next findParent -> find_parent findParents -> find_parents findPrevious -> find_previous getText -> get_text nextSibling -> next_sibling previousSibling -> previous_sibling
Beautiful Soup - contents 屬性
方法描述
contents 屬性可用於 Soup 物件和 Tag 物件。它返回物件內部的所有內容,所有直接子元素和文字節點(即 Navigable String)的列表。
語法
Tag.contents
返回值
contents 屬性返回 Tag/Soup 物件中子元素和字串的列表。
示例1
標籤物件的內容 -
from bs4 import BeautifulSoup
markup = '''
<div id="Languages">
<p>Java</p>
<p>Python</p>
<p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.div
print (tag.contents)
輸出
['\n', <p>Java</p>, '\n', <p>Python</p>, '\n', <p>C++</p>, '\n']
示例2
整個文件的內容 -
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
print (soup.contents)
輸出
['\n', <div id="Languages"> <p>Java</p> <p>Python</p> <p>C++</p> </div>, '\n']
示例 3
請注意,NavigableString 物件沒有 contents 屬性。如果嘗試訪問它,會引發 AttributeError。
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.p
s=tag.contents[0]
print (s.contents)
輸出
Traceback (most recent call last):
File "C:\Users\user\BeautifulSoup\2.py", line 11, in <module>
print (s.contents)
^^^^^^^^^^
File "C:\Users\user\BeautifulSoup\Lib\site-packages\bs4\element.py", line 984, in __getattr__
raise AttributeError(
AttributeError: 'NavigableString' object has no attribute 'contents'
Beautiful Soup - children 屬性
方法描述
Beautiful Soup 庫中的 Tag 物件具有 children 屬性。它返回一個生成器,用於迭代直接子元素和文字節點(即 Navigable String)。
語法
Tag.children
返回值
該屬性返回一個生成器,您可以使用它來迭代 PageElement 的直接子元素。
示例1
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.div
children = tag.children
for child in children:
print (child)
輸出
<p>Java</p> <p>Python</p> <p>C++</p>
示例2
soup 物件也具有 children 屬性。
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
children = soup.children
for child in children:
print (child)
輸出
<div id="Languages"> <p>Java</p> <p>Python</p> <p>C++</p> </div>
示例 3
在以下示例中,我們將 NavigableString 物件追加到 <p> 標籤並獲取子元素列表。
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
soup.p.extend(['and', 'JavaScript'])
children = soup.p.children
for child in children:
print (child)
輸出
Java and JavaScript
Beautiful Soup - string 屬性
方法描述
在 Beautiful Soup 中,soup 和 Tag 物件有一個便捷屬性 - string 屬性。它返回 PageElement、Soup 或 Tag 中的單個字串。如果此元素只有一個字串子元素,則返回相應的 NavigableString。如果此元素有一個子標籤,則返回值是子標籤的 'string' 屬性,如果元素本身是一個字串(沒有子元素),則 string 屬性返回 None。
語法
Tag.string
示例1
以下程式碼包含一個 HTML 字串,其中包含一個 <div> 標籤,該標籤包含三個 <p> 元素。我們找到第一個 <p> 標籤的 string 屬性。
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.p
navstr = tag.string
print (navstr, type(navstr))
nav_str = str(navstr)
print (nav_str, type(nav_str))
輸出
Java <class 'bs4.element.NavigableString'> Java <class 'str'>
string 屬性返回一個 NavigableString。可以使用 str() 函式將其轉換為常規的 Python 字串。
示例2
包含子元素的元素的 string 屬性返回 None。使用 <div> 標籤進行檢查。
tag = soup.div navstr = tag.string print (navstr)
輸出
None
Beautiful Soup - strings 屬性
方法描述
對於任何具有多個子元素的 PageElement,可以使用 strings 屬性獲取每個子元素的內部文字。與 string 屬性不同,strings 處理元素包含多個子元素的情況。strings 屬性返回一個生成器物件。它會產生一系列與每個子元素對應的 NavigableStrings。
語法
Tag.strings
示例1
您可以檢索 soup 以及標籤物件的 strings 屬性的值。在以下示例中,檢查了 soup 物件的 stings 屬性。
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
print ([string for string in soup.strings])
輸出
['\n', '\n', 'Java', ' ', 'Python', ' ', 'C++', '\n', '\n']
請注意列表中的換行符和空格。我們可以使用 stripped_strings 屬性將其刪除。
示例2
現在,我們獲得 <div> 標籤的 strings 屬性返回的生成器物件。使用迴圈列印字串。
tag = soup.div navstrs = tag.strings for navstr in navstrs: print (navstr)
輸出
Java Python C++
請注意,輸出中出現了換行符和空格,可以使用 stripped_strings 屬性將其刪除。
Beautiful Soup - stripped_strings 屬性
方法描述
Tag/Soup 物件的 stripped_strings 屬性返回的結果與 strings 屬性類似,只是額外換行符和空格被刪除了。因此,可以說 stripped_strings 屬性導致生成一系列屬於正在使用物件的內部元素的 NavigableString 物件。
語法
Tag.stripped_strings
示例1
在下面的示例中,在應用剝離後,顯示了在 BeautifulSoup 物件中解析的文件樹中所有元素的字串。
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
print ([string for string in soup.stripped_strings])
輸出
['Java', 'Python', 'C++']
與 strings 屬性的輸出相比,您可以看到換行符和空格被刪除了。
示例2
在這裡,我們提取 <div> 標籤下每個子元素的 NavigableStrings。
tag = soup.div navstrs = tag.stripped_strings for navstr in navstrs: print (navstr)
輸出
Java Python C++
Beautiful Soup - descendants 屬性
方法描述
使用 Beautiful Soup API 中 PageElement 物件的 descendants 屬性,您可以遍歷其下所有子元素的列表。此屬性返回一個生成器物件,可以使用它以廣度優先的順序檢索子元素。
在搜尋樹結構時,廣度優先遍歷從樹根開始,在移至下一深度級別的節點之前,先探索當前深度處的全部節點。
語法
tag.descendants
返回值
descendants 屬性返回一個生成器物件。
示例1
在下面的程式碼中,我們有一個 HTML 文件,其中嵌套了無序列表標籤。我們以廣度優先的方式遍歷解析的子元素。
html = '''
<ul id='outer'>
<li class="mainmenu">Accounts</li>
<ul>
<li class="submenu">Anand</li>
<li class="submenu">Mahesh</li>
</ul>
<li class="mainmenu">HR</li>
<ul>
<li class="submenu">Anil</li>
<li class="submenu">Milind</li>
</ul>
</ul>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('ul', {'id': 'outer'})
tags = soup.descendants
for desc in tags:
print (desc)
輸出
<ul id="outer"> <li class="mainmenu">Accounts</li> <ul> <li class="submenu">Anand</li> <li class="submenu">Mahesh</li> </ul> <li class="mainmenu">HR</li> <ul> <li class="submenu">Anil</li> <li class="submenu">Milind</li> </ul> </ul> <li class="mainmenu">Accounts</li> Accounts <ul> <li class="submenu">Anand</li> <li class="submenu">Mahesh</li> </ul> <li class="submenu">Anand</li> Anand <li class="submenu">Mahesh</li> Mahesh <li class="mainmenu">HR</li> HR <ul> <li class="submenu">Anil</li> <li class="submenu">Milind</li> </ul> <li class="submenu">Anil</li> Anil <li class="submenu">Milind</li> Milind
示例2
在以下示例中,我們列出 <head> 標籤的後代。
html = """ <html><head><title>TutorialsPoint</title></head> <body> <p>Hello World</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.head for element in tag.descendants: print (element)
輸出
<title>TutorialsPoint</title> TutorialsPoint
Beautiful Soup - parent 屬性
方法描述
Beautiful Soup 庫中的 parent 屬性返回所述 PegeElement 的直接父元素。parents 屬性返回值的型別是 Tag 物件。對於 BeautifulSoup 物件,其父元素是文件物件。
語法
Element.parent
返回值
parent 屬性返回一個 Tag 物件。對於 Soup 物件,它返回文件物件。
示例1
此示例使用 .parent 屬性查詢示例 HTML 字串中第一個 <p> 標籤的直接父元素。
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<p>Hello World</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.p
print (tag.parent.name)
輸出
body
示例2
在以下示例中,我們看到 <title> 標籤包含在 <head> 標籤內。因此,<title> 標籤的 parent 屬性返回 <head> 標籤。
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<p>Hello World</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.title
print (tag.parent)
輸出
<head><title>TutorialsPoint</title></head>
示例 3
Python 內建的 HTML 解析器的行為與 html5lib 和 lxml 解析器略有不同。內建解析器不會嘗試根據提供的字串構建完美的文件。如果字串中不存在 body 或 html 等其他父標籤,它不會新增這些標籤。另一方面,html5lib 和 lxml 解析器會新增這些標籤以使文件成為完美的 HTML 文件。
html = """ <p><b>Hello World</b></p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') print (soup.p.parent.name) soup = BeautifulSoup(html, 'html5lib') print (soup.p.parent.name)
輸出
[document] Body
由於 HTML 解析器不會新增其他標籤,因此解析後的 soup 的父元素是文件物件。但是,當我們使用 html5lib 時,父標籤的 name 屬性是 Body。
Beautiful Soup - parents 屬性
方法描述
Beautiful Soup 庫中的 parents 屬性以遞迴方式檢索所述 PegeElement 的所有父元素。parents 屬性返回值的型別是生成器,藉助它我們可以自下而上地列出父元素。
語法
Element.parents
返回值
parents 屬性返回一個生成器物件。
示例1
此示例使用 .parents 從文件深處巢狀的 <a> 標籤遍歷到文件的最頂部。在以下程式碼中,我們跟蹤示例 HTML 字串中第一個 <p> 標籤的父元素。
html = """ <html><head><title>TutorialsPoint</title></head> <body> <p>Hello World</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.p for element in tag.parents: print (element.name)
輸出
body html [document]
請注意,BeautifulSoup 物件的父元素是 [document]。
示例2
在以下示例中,我們看到 <b> 標籤包含在 <p> 標籤內。上面的兩個 div 標籤具有 id 屬性。我們嘗試僅列印具有 id 屬性的元素。has_attr() 方法用於此目的。
html = """
<div id="outer">
<div id="inner">
<p>Hello<b>World</b></p>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.b
for parent in tag.parents:
if parent.has_attr("id"):
print(parent["id"])
輸出
inner outer
Beautiful Soup - next_sibling 屬性
方法描述
出現在相同縮排級別的 HTML 標籤稱為同級元素。PageElement 的 next_sibling 屬性返回同一級別或同一父元素下的下一個標籤。
語法
element.next_sibling
返回值型別
next_sibling 屬性返回一個 PageElement、一個 Tag 或一個 NavigableString 物件。
示例1
index.html 薪資頁面包含一個 HTML 表單,其中包含三個輸入元素,每個元素都有一個 name 屬性。在以下示例中,找到 name 屬性為 nm 的輸入標籤的下一個同級元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'name':'age'})
print (tag.find_previous())
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'id':'nm'})
sib = tag.next_sibling
print (sib)
輸出
<input id="nm" name="name" type="text"/>
示例2
在下一個示例中,我們有一個 HTML 文件,其中包含幾個標籤位於 <p> 標籤內。next_sibling 屬性返回其 <b> 標籤旁邊的標籤。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag1 = soup.b
print ("next:",tag1.next_sibling)
輸出
next: <i>Python</i>
示例 3
考慮以下文件中的 HTML 字串。它在同一級別有兩個 <p> 標籤。第一個 <p> 的 next_sibling 應該給出第二個 <p> 標籤的內容。
html = '''
<p><b>Hello</b><i>Python</i></p>
<p>TutorialsPoint</p>
'''
soup = BeautifulSoup(html, 'html.parser')
tag1 = soup.p
print ("next:",tag1.next_sibling)
輸出
next:
next: 這個詞後面的空行是意外的。但這是因為第一個 <p> 標籤後面有 \n 字元。將列印語句更改為如下所示,以獲取 next_sibling 的內容。
tag1 = soup.p
print ("next:",tag1.next_sibling.next_sibling)
輸出
next: <p>TutorialsPoint</p>
Beautiful Soup - previous_sibling 屬性
方法描述
出現在相同縮排級別的 HTML 標籤稱為同級元素。PageElement 的 previous_sibling 屬性返回同一級別或同一父元素下之前的一個標籤(出現在當前標籤之前的標籤)。此屬性封裝了 find_previous_sibling() 方法。
語法
element.previous_sibling
返回值型別
previous_sibling 屬性返回一個 PageElement、一個 Tag 或一個 NavigableString 物件。
示例1
在以下程式碼中,HTML 字串包含 <p> 標籤內的兩個相鄰標籤。它顯示了其前面出現的 <b> 標籤的同級標籤。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag = soup.i
sibling = tag.previous_sibling
print (sibling)
輸出
<b>Hello</b>
示例2
我們正在使用 index.html 檔案進行解析。該頁面包含一個 HTML 表單,其中包含三個輸入元素。哪個元素是 id 屬性為 age 的輸入元素的前一個同級元素?以下程式碼顯示了它 -
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'id':'age'})
sib = tag.previous_sibling.previous_sibling
print (sib)
輸出
<input id="nm" name="name" type="text"/>
示例 3
首先,我們找到包含字串“Tutorial”的 <p> 標籤,然後找到其之前的標籤。
html = '''
<p>Excellent</p><p>Python</p><p>Tutorial</p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('p', string='Tutorial')
print (tag.previous_sibling)
輸出
<p>Python</p>
Beautiful Soup - next_siblings 屬性
方法描述
出現在相同縮排級別的 HTML 標籤稱為同級元素。Beautiful Soup 中的 next_siblings 屬性返回一個生成器物件,用於迭代同一父元素下所有後續標籤和字串。
語法
element.next_siblings
返回值型別
next_siblings 屬性返回一個同級 PageElement 的生成器。
示例1
在 index.html 中的 HTML 表單程式碼包含三個輸入元素。以下指令碼使用 next_siblings 屬性收集 id 屬性為 nm 的輸入元素的下一個同級元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'id':'nm'})
siblings = tag.next_siblings
print (list(siblings))
輸出
['\n', <input id="age" name="age" type="text"/>, '\n', <input id="marks" name="marks" type="text"/>, '\n']
示例2
讓我們為此目的使用以下 HTML 程式碼段:
使用以下程式碼遍歷下一個同級標籤。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.b
print ("next siblings:")
for tag in tag1.next_siblings:
print (tag)
輸出
next siblings: <i>Python</i> <u>Tutorial</u>
示例 3
下一個示例顯示 <head> 標籤只有一個以 body 標籤形式出現的下一個同級元素。
html = '''
<html>
<head>
<title>Hello</title>
</head>
<body>
<p>Excellent</p><p>Python</p><p>Tutorial</p>
</body>
</head>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tags = soup.head.next_siblings
print ("next siblings:")
for tag in tags:
print (tag)
輸出
next siblings: <body> <p>Excellent</p><p>Python</p><p>Tutorial</p> </body>
這些額外的行是由於生成器中的換行符造成的。
Beautiful Soup - previous_siblings 屬性
方法描述
出現在相同縮排級別的 HTML 標籤稱為同級元素。Beautiful Soup 中的 previous_siblings 屬性返回一個生成器物件,用於迭代同一父元素下當前標籤之前的所有標籤和字串。這會提供與 find_previous_siblings() 方法類似的輸出。
語法
element.previous_siblings
返回值型別
previous_siblings 屬性返回一個同級 PageElement 的生成器。
示例1
以下示例解析給定的 HTML 字串,該字串在外部 <p> 標籤內嵌入了幾個標籤。<u> 標籤的前一個同級元素藉助 previous_siblings 屬性獲取。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.u
print ("previous siblings:")
for tag in tag1.previous_siblings:
print (tag)
輸出
previous siblings: <i>Python</i> <b>Excellent</b>
示例2
在以下示例中使用的 index.html 檔案中,HTML 表單中有三個輸入元素。我們找出在 <form> 標籤下,id 設定為 marks 的元素之前有哪些同級標籤。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'id':'marks'})
sibs = tag.previous_siblings
print ("previous siblings:")
for sib in sibs:
print (sib)
輸出
previous siblings: <input id="age" name="age" type="text"/> <input id="nm" name="name" type="text"/>
示例 3
頂級 <html> 標籤始終有兩個同級標籤 - head 和 body。因此,<body> 標籤只有一個前一個同級元素,即 head,如下面的程式碼所示 -
html = '''
<html>
<head>
<title>Hello</title>
</head>
<body>
<p>Excellent</p><p>Python</p><p>Tutorial</p>
</body>
</head>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tags = soup.body.previous_siblings
print ("previous siblings:")
for tag in tags:
print (tag)
輸出
previous siblings: <head> <title>Hello</title> </head>
Beautiful Soup - next_element 屬性
方法描述
在 Beautiful Soup 庫中,next_element 屬性返回緊接在當前 PageElement 後面的 Tag 或 NavigableString,即使它位於父樹之外。還有一個 next 屬性具有類似的行為。
語法
Element.next_element
返回值
next_element 和 next 屬性返回緊接在當前標籤後面的標籤或 NavigableString。
示例1
在從給定 HTML 字串解析的文件樹中,我們找到 <b> 標籤的 next_element。
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
tag = soup.b
print (tag)
nxt = tag.next_element
print ("Next:",nxt)
nxt = tag.next_element.next_element
print ("Next:",nxt)
輸出
<b>Excellent</b> Next: Excellent Next: <p>Python</p>
輸出有點奇怪,因為 <b>Excellent</b> 的下一個元素顯示為“Excellent”,這是因為內部字串被註冊為下一個元素。為了獲得所需的結果(<p>Python</p>)作為下一個元素,獲取內部 NavigableString 物件的 next_element 屬性。
示例2
Beautiful Soup PageElements 也支援 next 屬性,該屬性類似於 next_element 屬性。
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
tag = soup.b
print (tag)
nxt = tag.next
print ("Next:",nxt)
nxt = tag.next.next
print ("Next:",nxt)
輸出
<b>Excellent</b> Next: Excellent Next: <p>Python</p>
示例 3
在下一個示例中,我們嘗試確定 <body> 標籤後面的元素。由於它後面跟著一個換行符 (\n),我們需要找到 body 標籤後面元素的下一個元素。它恰好是 <h1> 標籤。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('body')
nxt = tag.next_element.next
print ("Next:",nxt)
輸出
Next: <h1>TutorialsPoint</h1>
Beautiful Soup - previous_element 屬性
方法描述
在 Beautiful Soup 庫中,previous_element 屬性返回緊接在當前 PageElement 之前的 Tag 或 NavigableString,即使它位於父樹之外。還有一個 previous 屬性具有類似的行為。
語法
Element.previous_element
返回值
previous_element 和 previous 屬性返回緊接在當前標籤之前的標籤或 NavigableString。
示例1
在從給定 HTML 字串解析的文件樹中,我們找到 <p id='id1'> 標籤的 previous_element。
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
tag = soup.find('p', id='id1')
print (tag)
pre = tag.previous_element
print ("Previous:",pre)
pre = tag.previous_element.previous_element
print ("Previous:",pre)
輸出
<p id="id1">Tutorial</p> Previous: Python Previous: <p>Python</p>
輸出有點奇怪,因為顯示的前一個元素為“Python”,這是因為內部字串被註冊為前一個元素。為了獲得所需的結果(<p>Python</p>)作為前一個元素,獲取內部 NavigableString 物件的 previous_element 屬性。
示例2
Beautiful Soup PageElements 也支援 previous 屬性,該屬性類似於 previous_element 屬性。
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
tag = soup.find('p', id='id1')
print (tag)
pre = tag.previous
print ("Previous:",pre)
pre = tag.previous.previous
print ("Previous:",pre)
輸出
<p id="id1">Tutorial</p> Previous: Python Previous: <p>Python</p>
示例 3
在下一個示例中,我們嘗試確定 id 屬性為“age”的 <input> 標籤後面的元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html5lib')
tag = soup.find('input', id='age')
pre = tag.previous_element.previous
print ("Previous:",pre)
輸出
Previous: <input id="nm" name="name" type="text"/>
Beautiful Soup - next_elements 屬性
方法描述
在 Beautiful Soup 庫中,next_elements 屬性返回一個生成器物件,其中包含解析樹中後續的字串或標籤。
語法
Element.next_elements
返回值
next_elements 屬性返回一個生成器。
示例1
next_elements 屬性返回以下文件字串中 <b> 標籤後面的標籤和 NavibaleStrings -
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('b')
nexts = tag.next_elements
print ("Next elements:")
for next in nexts:
print (next)
輸出
Next elements: ExcellentPython
Python <p id="id1">Tutorial</p> Tutorial
示例2
下面列出了 <p> 標籤後面的所有元素 -
from bs4 import BeautifulSoup
html = '''
<p>
<b>Excellent</b><i>Python</i>
</p>
<u>Tutorial</u>
'''
soup = BeautifulSoup(html, 'html.parser')
tag1 = soup.find('p')
print ("Next elements:")
print (list(tag1.next_elements))
輸出
Next elements: ['\n', <b>Excellent</b>, 'Excellent', <i>Python</i>, 'Python', '\n', '\n', <u>Tutorial</u>, 'Tutorial', '\n']
示例 3
下面列出了 index.html 的 HTML 表單中輸入標籤後面的元素 -
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html5lib')
tag = soup.find('input')
nexts = soup.previous_elements
print ("Next elements:")
for next in nexts:
print (next)
輸出
Next elements: <input id="age" name="age" type="text"/> <input id="marks" name="marks" type="text"/>
Beautiful Soup - previous_elements 屬性
方法描述
在 Beautiful Soup 庫中,previous_elements 屬性返回一個生成器物件,其中包含解析樹中之前的字串或標籤。
語法
Element.previous_elements
返回值
previous_elements 屬性返回一個生成器。
示例1
previous_elements 屬性返回在以下文件字串中 <p> 標籤之前出現的標籤和 NavigableStrings。
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('p', id='id1')
pres = tag.previous_elements
print ("Previous elements:")
for pre in pres:
print (pre)
輸出
Previous elements: Python <p>Python</p> Excellent <b>Excellent</b> <p><b>Excellent</b><p>Python</p><p id="id1">Tutorial</p></p>
示例2
下面列出了 <u> 標籤之前出現的所有元素。
from bs4 import BeautifulSoup
html = '''
<p>
<b>Excellent</b><i>Python</i>
</p>
<u>Tutorial</u>
'''
soup = BeautifulSoup(html, 'html.parser')
tag1 = soup.find('u')
print ("previous elements:")
print (list(tag1.previous_elements))
輸出
previous elements: ['\n', '\n', 'Python', <i>Python</i>, 'Excellent', <b>Excellent</b>, '\n', <p> <b>Excellent</b><i>Python</i> </p>, '\n']
示例 3
BeautifulSoup 物件本身沒有任何前置元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html5lib')
tag = soup.find('input', id='marks')
pres = soup.previous_elements
print ("Previous elements:")
for pre in pres:
print (pre.name)
輸出
Previous elements:
Beautiful Soup - find() 方法
方法描述
Beautiful Soup 中的 find() 方法在該 PageElement 的子元素中查詢與給定條件匹配的第一個元素並返回它。
語法
Soup.find(name, attrs, recursive, string, **kwargs)
引數
name - 標籤名稱的過濾器。
attrs - 屬性值的過濾器字典。
recursive - 如果為 True,則 find() 將執行遞迴搜尋。否則,只考慮直接子元素。
limit - 在找到指定數量的匹配項後停止查詢。
kwargs - 屬性值的過濾器字典。
返回值
find() 方法返回 Tag 物件或 NavigableString 物件。
示例1
讓我們為此目的使用以下 HTML 指令碼(作為 index.html)
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
以下 Python 程式碼查詢其 id 為 nm 的元素
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.find(id = 'nm')
print (obj)
輸出
<input id="nm" name="name" type="text"/>
示例2
find() 方法返回已解析文件中第一個具有給定屬性的標籤。
obj = soup.find(attrs={"name":'marks'})
輸出
<input id="marks" name="marks" type="text"/>
示例 3
如果 find() 找不到任何內容,則返回 None。
obj = soup.find('dummy')
print (obj)
輸出
None
Beautiful Soup - find_all() 方法
方法描述
Beautiful Soup 中的 find_all() 方法在該 PageElement 的子元素中查詢與給定條件匹配的元素,並返回所有元素的列表。
語法
Soup.find_all(name, attrs, recursive, string, **kwargs)
引數
name - 標籤名稱的過濾器。
attrs - 屬性值的過濾器字典。
recursive - 如果為 True,則 find() 將執行遞迴搜尋。否則,只考慮直接子元素。
limit - 在找到指定數量的匹配項後停止查詢。
kwargs - 屬性值的過濾器字典。
返回值型別
find_all() 方法返回一個 ResultSet 物件,它是一個列表生成器。
示例1
當我們可以為 name 傳入一個值時,Beautiful Soup 只考慮具有特定名稱的標籤。文字字串將被忽略,名稱不匹配的標籤也將被忽略。在這個例子中,我們將 title 傳遞給 find_all() 方法。
from bs4 import BeautifulSoup
html = open('index.html')
soup = BeautifulSoup(html, 'html.parser')
obj = soup.find_all('input')
print (obj)
輸出
[<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>, <input id="marks" name="marks" type="text"/>]
示例2
我們將在本例中使用以下 HTML 指令碼。
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
我們可以將字串傳遞給 find_all() 方法的 name 引數。使用字串,您可以搜尋字串而不是標籤。您可以傳入字串、正則表示式、列表、函式或值 True。
在本例中,一個函式被傳遞給 name 引數。所有以 'A' 開頭的名稱都由 find_all() 方法返回。
from bs4 import BeautifulSoup
def startingwith(ch):
return ch.startswith('A')
soup = BeautifulSoup(html, 'html.parser')
lst=soup.find_all(string=startingwith)
print (lst)
輸出
['Accounts', 'Anand', 'Ankita']
示例 3
在本例中,我們將 limit=2 引數傳遞給 find_all() 方法。該方法返回 <li> 標籤的前兩個出現。
soup = BeautifulSoup(html, 'html.parser')
lst=soup.find_all('li', limit =2)
print (lst)
輸出
[<li>Accounts</li>, <li>Anand</li>]
Beautiful Soup - find_parents() 方法
方法描述
BeautifulSoup 包中的 find_parent() 方法查詢與給定條件匹配的該元素的所有父元素。
語法
find_parents( name, attrs, limit, **kwargs)
引數
name - 標籤名稱的過濾器。
attrs - 屬性值的過濾器字典。
limit - 在找到指定數量的匹配項後停止查詢。
kwargs - 屬性值的過濾器字典。
返回值型別
find_parents() 方法返回一個 ResultSet,其中包含所有父元素,並以相反的順序排列。
示例1
我們將在本例中使用以下 HTML 指令碼。
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
輸出
ul body html [document]
請注意,BeautifulSoup 物件的 name 屬性始終返回 [document]。
示例2
在本例中,limit 引數被傳遞給 find_parents() 方法,以將父級搜尋限制在向上兩級。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
obj=soup.find('li')
parents=obj.find_parents(limit=2)
for parent in parents:
print (parent.name)
輸出
ul body
Beautiful Soup - find_parent() 方法
方法描述
BeautifulSoup 包中的 find_parent() 方法查詢與給定條件匹配的該 PageElement 的最近父元素。
語法
find_parent( name, attrs, **kwargs)
引數
name - 標籤名稱的過濾器。
attrs - 屬性值的過濾器字典。
kwargs - 屬性值的過濾器字典。
返回值型別
find_parent() 方法返回 Tag 物件或 NavigableString 物件。
示例1
我們將在本例中使用以下 HTML 指令碼。
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
在下面的示例中,我們查詢作為字串 'HR' 父級的標籤的名稱。
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') obj=soup.find(string='HR') print (obj.find_parent().name)
輸出
li
示例2
<body> 標籤始終包含在頂級 <html> 標籤中。在下面的示例中,我們使用 find_parent() 方法確認此事實。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
obj=soup.find('body')
print (obj.find_parent().name)
輸出
html
Beautiful Soup - find_next_siblings() 方法
方法描述
find_next_siblings() 方法類似於 next_sibling 屬性。它查詢與給定條件匹配並在文件中隨後出現的該 PageElement 相同級別的所有同級元素。
語法
find_fnext_siblings(name, attrs, string, limit, **kwargs)
引數
name - 標籤名稱的過濾器。
attrs - 屬性值的過濾器字典。
string - 要搜尋的字串(而不是標籤)。
limit - 在找到指定數量的匹配項後停止查詢。
kwargs - 屬性值的過濾器字典。
返回值型別
find_next_siblings() 方法返回 Tag 物件或 NavigableString 物件的列表。
示例1
讓我們為此目的使用以下 HTML 程式碼段:
<p>
<b>
Excellent
</b>
<i>
Python
</i>
<u>
Tutorial
</u>
</p>
在下面的程式碼中,我們嘗試查詢 <b> 標籤的所有同級元素。在用於抓取的 HTML 字串中,同一級別還有兩個標籤。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.find('b')
print ("next siblings:")
for tag in tag1.find_next_siblings():
print (tag)
輸出
find_next_siblings() 的 ResultSet 正在藉助 for 迴圈進行迭代。
next siblings: <i>Python</i> <u>Tutorial</u>
示例2
如果在標籤之後沒有要找到的同級元素,則此方法將返回一個空列表。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.find('u')
print ("next siblings:")
print (tag1.find_next_siblings())
輸出
next siblings: []
Beautiful Soup - find_next_sibling() 方法
方法描述
Beautiful Soup 中的 find_next_sibling() 方法查詢與給定條件匹配並在文件中隨後出現的該 PageElement 相同級別的最近同級元素。此方法類似於 next_sibling 屬性。
語法
find_fnext_sibling(name, attrs, string, **kwargs)
引數
name - 標籤名稱的過濾器。
attrs - 屬性值的過濾器字典。
string - 要搜尋的字串(而不是標籤)。
kwargs - 屬性值的過濾器字典。
返回值型別
find_next_sibling() 方法返回 Tag 物件或 NavigableString 物件。
示例1
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag1 = soup.find('b')
print ("next:",tag1.find_next_sibling())
輸出
next: <i>Python</i>
示例2
如果下一個節點不存在,則該方法返回 None。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag1 = soup.find('i')
print ("next:",tag1.find_next_sibling())
輸出
next: None
Beautiful Soup - find_previous_siblings() 方法
方法描述
Beautiful Soup 包中的 find_previous_siblings() 方法返回所有在文件中出現在該 PAgeElement 之前並與給定條件匹配的同級元素。
語法
find_previous_siblings(name, attrs, string, limit, **kwargs)
引數
name - 標籤名稱的過濾器。
attrs - 屬性值的過濾器字典。
string - 具有特定文字的 NavigableString 的過濾器。
limit - 在找到這麼多結果後停止查詢。
kwargs - 屬性值的過濾器字典。
返回值
find_previous_siblings() 方法返回一個 PageElements 的 ResultSet。
示例1
讓我們為此目的使用以下 HTML 程式碼段:
<p>
<b>
Excellent
</b>
<i>
Python
</i>
<u>
Tutorial
</u>
</p>
在下面的程式碼中,我們嘗試查詢 <> 標籤的所有同級元素。在用於抓取的 HTML 字串中,同一級別還有兩個標籤。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.find('u')
print ("previous siblings:")
for tag in tag1.find_previous_siblings():
print (tag)
輸出
<i>Python</i> <b>Excellent</b>
示例2
網頁 (index.html) 有一個包含三個輸入元素的 HTML 表單。我們找到一個 id 屬性為 marks 的元素,然後找到它的前置同級元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'id':'marks'})
sibs = tag.find_previous_sibling()
print (sibs)
輸出
[<input id="age" name="age" type="text"/>, <input id="nm" name="name" type="text"/>]
示例 3
HTML 字串有兩個 <p> 標籤。我們找出 id1 作為其 id 屬性的標籤之前的同級元素。
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('p', id='id1')
ptags = tag.find_previous_siblings()
for ptag in ptags:
print ("Tag: {}, Text: {}".format(ptag.name, ptag.text))
輸出
Tag: p, Text: Python Tag: b, Text: Excellent
Beautiful Soup - find_previous_sibling() 方法
方法描述
Beautiful Soup 中的 find_previous_sibling() 方法返回與給定條件匹配並在文件中較早出現的該 PageElement 的最近同級元素。
語法
find_previous_sibling(name, attrs, string, **kwargs)
引數
name - 標籤名稱的過濾器。
attrs - 屬性值的過濾器字典。
string - 具有特定文字的 NavigableString 的過濾器。
kwargs - 屬性值的過濾器字典。
返回值
find_previous_sibling() 方法返回一個 PageElement,它可以是 Tag 或 NavigableString。
示例1
從以下示例中使用的 HTML 字串中,我們找出 <i> 標籤的前置同級元素,其標籤名稱為 'u'。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup("<p><u>Excellent</u><b>Hello</b><i>Python</i></p>", 'html.parser')
tag = soup.i
sibling = tag.find_previous_sibling('u')
print (sibling)
輸出
<u>Excellent</u>
示例2
網頁 (index.html) 有一個包含三個輸入元素的 HTML 表單。我們找到一個 id 屬性為 marks 的元素,然後找到其前置同級元素,該元素的 id 設定為 nm。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'id':'marks'})
sib = tag.find_previous_sibling(id='nm')
print (sib)
輸出
<input id="nm" name="name" type="text"/>
示例 3
在下面的程式碼中,HTML 字串有兩個 <p> 元素和外部 <p> 標籤內的字串。我們使用 find_previous_string() 方法搜尋 <p>Tutorial</p> 標籤的 NavigableString 物件同級元素。
html = '''
<p>Excellent<p>Python</p><p>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('p', string='Tutorial')
ptag = tag.find_previous_sibling(string='Excellent')
print (ptag, type(ptag))
輸出
Excellent <class 'bs4.element.NavigableString'>
Beautiful Soup - find_all_next() 方法
方法描述
Beautiful Soup 中的 find_all_next() 方法查詢與給定條件匹配並在文件中出現在此元素之後的 PageElements。此方法返回標籤或 NavigableString 物件,並且該方法接受與 find_all() 完全相同的引數。
語法
find_all_next(name, attrs, string, limit, **kwargs)
引數
name - 標籤名稱的過濾器。
attrs - 屬性值的過濾器字典。
recursive - 如果為 True,則 find() 將執行遞迴搜尋。否則,只考慮直接子元素。
limit - 在找到指定數量的匹配項後停止查詢。
kwargs - 屬性值的過濾器字典。
返回值
此方法返回一個包含 PageElements(標籤或 NavigableString 物件)的 ResultSet。
示例1
使用 index.html 作為本例的 HTML 文件,我們首先找到 <form> 標籤,然後使用 find_all_next() 方法收集其後的所有元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.form
tags = tag.find_all_next()
print (tags)
輸出
[<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>, <input id="marks" name="marks" type="text"/>]
示例2
在這裡,我們對 find_all_next() 方法應用一個過濾器,以收集所有在 <form> 之後的標籤,其 id 為 nm 或 age。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.form
tags = tag.find_all_next(id=['nm', 'age'])
print (tags)
輸出
[<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>]
示例 3
如果我們檢查 body 標籤後面的標籤,它包括一個 <h1> 標籤以及 <form> 標籤,其中包含三個輸入元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.body
tags = tag.find_all_next()
print (tags)
輸出
<h1>TutorialsPoint</h1> <form> <input id="nm" name="name" type="text"/> <input id="age" name="age" type="text"/> <input id="marks" name="marks" type="text"/> </form> <input id="nm" name="name" type="text"/> <input id="age" name="age" type="text"/> <input id="marks" name="marks" type="text"/>
Beautiful Soup - find_next() 方法
方法描述
Beautiful Soup 中的 find_next() 方法查詢與給定條件匹配並在文件中隨後出現的第一個 PageElement。返回文件中當前標籤後面出現的第一個標籤或 NavigableString。與所有其他 find 方法一樣,此方法具有以下語法。
語法
find_next(name, attrs, string, **kwargs)
引數
name - 標籤名稱的過濾器。
attrs - 屬性值的過濾器字典。
string - 具有特定文字的 NavigableString 的過濾器。
kwargs - 屬性值的過濾器字典。
返回值
此 find_next() 方法返回一個 Tag 或 NavigableString。
示例1
本例使用了以下指令碼的網頁 index.html。
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>TutorialsPoint</h1>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
我們首先找到 <form> 標籤,然後找到它旁邊的標籤。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.h1
print (tag.find_next())
輸出
<form> <input id="nm" name="name" type="text"/> <input id="age" name="age" type="text"/> <input id="marks" name="marks" type="text"/> </form>
示例2
在本例中,我們首先找到 <input> 標籤,其 name='age',並獲取其下一個標籤。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'name':'age'})
print (tag.find_next())
輸出
<input id="marks" name="marks" type="text"/>
示例 3
<head> 標籤旁邊的標籤恰好是 <title> 標籤。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.head
print (tag.find_next())
輸出
<title>TutorialsPoint</title>
Beautiful Soup - find_all_previous() 方法
方法描述
Beautiful Soup 中的 find_all_previous() 方法從該 PageElement 向文件中反向查詢,並查詢與給定條件匹配並在當前元素之前出現的 PageElements。它返回文件中當前標籤之前出現的 PageElements 的 ResultsSet。與所有其他 find 方法一樣,此方法具有以下語法。
語法
find_previous(name, attrs, string, limit, **kwargs)
引數
name - 標籤名稱的過濾器。
attrs - 屬性值的過濾器字典。
string - 具有特定文字的 NavigableString 的過濾器。
limit - 在找到這麼多結果後停止查詢。
kwargs - 屬性值的過濾器字典。
返回值
find_all_previous() 方法返回 Tag 或 NavigableString 物件的 ResultSet。如果 limit 引數為 1,則該方法等效於 find_previous() 方法。
示例1
在本例中,顯示了第一個輸入標籤之前出現的每個物件的 name 屬性。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input')
for t in tag.find_all_previous():
print (t.name)
輸出
form h1 body title head html
示例2
在正在考慮的 HTML 文件 (index.html) 中,有三個輸入元素。使用以下程式碼,我們列印 <input> 標籤(其 nm 屬性為 marks)之前所有前置標籤的標籤名稱。為了區分它之前的兩個輸入標籤,我們還列印 attrs 屬性。請注意,其他標籤沒有任何屬性。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'name':'marks'})
pretags = tag.find_all_previous()
for pretag in pretags:
print (pretag.name, pretag.attrs)
輸出
input {'type': 'text', 'id': 'age', 'name': 'age'}
input {'type': 'text', 'id': 'nm', 'name': 'name'}
form {}
h1 {}
body {}
title {}
head {}
html {}
示例 3
BeautifulSoup 物件儲存整個文件的樹。它沒有任何前置元素,如下面的示例所示。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tags = soup.find_all_previous()
print (tags)
輸出
[]
Beautiful Soup - find_previous() 方法
方法描述
Beautiful Soup 中的 find_previous() 方法從該 PageElement 向文件中反向查詢,並查詢與給定條件匹配的第一個 PageElement。它返回文件中當前標籤之前出現的第一個標籤或 NavigableString。與所有其他 find 方法一樣,此方法具有以下語法。
語法
find_previous(name, attrs, string, **kwargs)
引數
name - 標籤名稱的過濾器。
attrs - 屬性值的過濾器字典。
string - 具有特定文字的 NavigableString 的過濾器。
kwargs - 屬性值的過濾器字典。
返回值
find_previous() 方法返回一個 Tag 或 NavigableString 物件。
示例1
在下面的示例中,我們嘗試查詢 <body> 標籤之前的物件是哪個。它恰好是 <title> 元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.body
print (tag.find_previous())
輸出
<title>TutorialsPoint</title>
示例2
在本例中使用的 HTML 文件中有三個輸入元素。以下程式碼找到 name 屬性為 age 的輸入元素,並查詢其前置元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'name':'age'})
print (tag.find_previous())
輸出
<input id="nm" name="name" type="text"/>
示例 3
<title> 之前的元素恰好是 <head> 元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('title')
print (tag.find_previous())
輸出
<head> <title>TutorialsPoint</title> </head>
Beautiful Soup - select() 方法
方法描述
在 Beautiful Soup 庫中,select() 方法是抓取 HTML/XML 文件的重要工具。與 find() 和 find_() 方法類似,select() 方法也有助於定位滿足給定條件的元素。文件樹中元素的選擇是根據作為引數傳遞給它的 CSS 選擇器完成的。
Beautiful Soup 還有 select_one() 方法。select() 和 select_one() 的區別在於,select() 返回屬於 PageElement 並以 CSS 選擇器為特徵的所有元素的結果集;而 select_one() 返回滿足基於 CSS 選擇器選擇標準的元素的第一個出現。
在 Beautiful Soup 4.7 版之前,select() 方法只能支援常見的 CSS 選擇器。在 4.7 版中,Beautiful Soup 與 Soup Sieve CSS 選擇器庫整合。因此,現在可以使用更多的選擇器。在 4.12 版中,除了現有的便捷方法 select() 和 select_one() 之外,還添加了一個 .css 屬性。
語法
select(selector, limit, **kwargs)
引數
selector - 包含 CSS 選擇器的字串。
limit - 找到此數量的結果後,停止查詢。
kwargs - 要傳遞的關鍵字引數。
如果 limit 引數設定為 1,則它將等效於 select_one() 方法。
返回值
select() 方法返回一個 Tag 物件的 ResultSet。select_one() 方法返回一個單獨的 Tag 物件。
Soup Sieve 庫有不同型別的 CSS 選擇器。基本 CSS 選擇器為 -
型別選擇器根據節點名稱匹配元素。例如。
tags = soup.select('div')
通用選擇器 (*) 匹配任何型別的元素。示例。
tags = soup.select('*')
ID 選擇器根據元素的 id 屬性匹配元素。符號 # 表示 ID 選擇器。示例。
tags = soup.select("#nm")
類選擇器根據 class 屬性中包含的值匹配元素。以 . 為字首的類名稱是 CSS 類選擇器。示例。
tags = soup.select(".submenu")
示例:型別選擇器
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tags = soup.select('div')
print (tags)
輸出
[<div id="Languages"> <p>Java</p> <p>Python</p> <p>C++</p> </div>]
示例:ID 選擇器
from bs4 import BeautifulSoup
html = '''
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
'''
soup = BeautifulSoup(html, 'html.parser')
obj = soup.select("#nm")
print (obj)
輸出
[<input id="nm" name="name" type="text"/>]
示例:類選擇器
html = '''
<ul>
<li class="mainmenu">Accounts</li>
<ul>
<li class="submenu">Anand</li>
<li class="submenu">Mahesh</li>
</ul>
<li class="mainmenu">HR</li>
<ul>
<li class="submenu">Rani</li>
<li class="submenu">Ankita</li>
</ul>
</ul>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tags = soup.select(".mainmenu")
print (tags)
輸出
[<li class="mainmenu">Accounts</li>, <li class="mainmenu">HR</li>]
Beautiful Soup - append() 方法
方法描述
Beautiful Soup 中的 `append()` 方法將給定的字串或另一個標籤新增到當前 Tag 物件內容的末尾。`append()` 方法的工作方式類似於 Python 列表物件的 `append()` 方法。
語法
append(obj)
引數
obj − 任何 PageElement,可以是字串、NavigableString 物件或 Tag 物件。
返回值型別
`append()` 方法不會返回新物件。
示例1
在以下示例中,HTML 指令碼包含一個 <p> 標籤。使用 `append()`,附加了額外的文字。在以下示例中,HTML 指令碼包含一個 <p> 標籤。使用 `append()`,附加了額外的文字。
from bs4 import BeautifulSoup
markup = '<p>Hello</p>'
soup = BeautifulSoup(markup, 'html.parser')
print (soup)
tag = soup.p
tag.append(" World")
print (soup)
輸出
<p>Hello</p> <p>Hello World</p>
示例2
使用 `append()` 方法,可以在現有標籤的末尾新增一個新標籤。首先使用 `new_tag()` 方法建立一個新的 Tag 物件,然後將其傳遞給 `append()` 方法。
from bs4 import BeautifulSoup, Tag
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag1 = soup.new_tag('i')
tag1.string = 'World'
tag.append(tag1)
print (soup.prettify())
輸出
<b>
Hello
<i>
World
</i>
</b>
示例 3
如果需要向文件中新增字串,可以附加一個 NavigableString 物件。
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
new_string = NavigableString(" World")
tag.append(new_string)
print (soup.prettify())
輸出
<b> Hello World </b>
Beautiful Soup - extend() 方法
方法描述
Beautiful Soup 中的 `extend()` 方法從 4.7 版開始新增到 Tag 類中。它將列表中的所有元素新增到標籤中。此方法類似於標準 Python 列表的 `extend()` 方法 - 它接收一個字串陣列,將其附加到標籤的內容中。
語法
extend(tags)
引數
tags − 要附加的字串或 NavigableString 物件列表。
返回值型別
`extend()` 方法不會返回任何新物件。
示例
from bs4 import BeautifulSoup markup = '<b>Hello</b>' soup = BeautifulSoup(markup, 'html.parser') tag = soup.b vals = ['World.', 'Welcome to ', 'TutorialsPoint'] tag.extend(vals) print (soup.prettify())
輸出
<b> Hello World. Welcome to TutorialsPoint </b>
Beautiful Soup - NavigableString() 方法
方法描述
bs4 包中的 `NavigableString()` 方法是 NavigableString 類的構造方法。NavigableString 表示已解析文件的最內層子元素。此方法將常規 Python 字串轉換為 NavigableString。相反,內建的 `str()` 方法將 NavigableString 物件轉換為 Unicode 字串。
語法
NavigableString(string)
引數
string − Python 的 `str` 類的物件。
返回值
`NavigableString()` 方法返回一個 NavigableString 物件。
示例1
在下面的程式碼中,HTML 字串包含一個空的 <b> 標籤。我們在其中添加了一個 NavigableString 物件。
html = """
<p><b></b></p>
"""
from bs4 import BeautifulSoup, NavigableString
soup = BeautifulSoup(html, 'html.parser')
navstr = NavigableString("Hello World")
soup.b.append(navstr)
print (soup)
輸出
<p><b>Hello World</b></p>
示例2
在此示例中,我們看到兩個 NavigableString 物件被附加到一個空的 <b> 標籤。該標籤響應 `strings` 屬性而不是 `string` 屬性。它是一個 NavigableString 物件的生成器。
html = """
<p><b></b></p>
"""
from bs4 import BeautifulSoup, NavigableString
soup = BeautifulSoup(html, 'html.parser')
navstr = NavigableString("Hello")
soup.b.append(navstr)
navstr = NavigableString("World")
soup.b.append(navstr)
for s in soup.b.strings:
print (s, type(s))
輸出
Hello <class 'bs4.element.NavigableString'> World <class 'bs4.element.NavigableString'>
示例 3
如果訪問 <b> 標籤物件的 `stripped_strings` 屬性而不是 `strings` 屬性,我們將獲得一個 Unicode 字串(即 `str` 物件)的生成器。
html = """
<p><b></b></p>
"""
from bs4 import BeautifulSoup, NavigableString
soup = BeautifulSoup(html, 'html.parser')
navstr = NavigableString("Hello")
soup.b.append(navstr)
navstr = NavigableString("World")
soup.b.append(navstr)
for s in soup.b.stripped_strings:
print (s, type(s))
輸出
Hello <class 'str'> World <class 'str'>
Beautiful Soup - new_tag() 方法
Beautiful Soup 庫中的 `new_tag()` 方法建立一個新的 Tag 物件,該物件與現有的 BeautifulSoup 物件關聯。可以使用此工廠方法將新標籤附加或插入到文件樹中。
語法
new_tag(name, namespace, nsprefix, attrs, sourceline, sourcepos, **kwattrs)
引數
name − 新標籤的名稱。
namespace − 新標籤的 XML 名稱空間的 URI,可選。
prefix − 新標籤的 XML 名稱空間的字首,可選。
attrs − 此標籤的屬性值的字典。
sourceline − 在源文件中找到此標籤的行號。
sourcepos − 在 `sourceline` 中找到此標籤的字元位置。
kwattrs − 新標籤的屬性值的關鍵字引數。
返回值
此方法返回一個新的 Tag 物件。
示例1
以下示例顯示了 `new_tag()` 方法的使用。一個用於 <a> 元素的新標籤。標籤物件使用 `href` 和 `string` 屬性進行初始化,然後插入到文件樹中。
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>Welcome to <b>online Tutorial library</b></p>', 'html.parser')
tag = soup.new_tag('a')
tag.attrs['href'] = "www.tutorialspoint.com"
tag.string = "Tutorialspoint"
soup.b.insert_before(tag)
print (soup)
輸出
<p>Welcome to <a href="www.tutorialspoint.com">Tutorialspoint</a><b>online Tutorial library</b></p>
示例2
在以下示例中,我們有一個包含兩個輸入元素的 HTML 表單。我們建立一個新的輸入標籤並將其附加到表單標籤。
html = '''
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
</form>'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.form
newtag=soup.new_tag('input', attrs={'type':'text', 'id':'marks', 'name':'marks'})
tag.append(newtag)
print (soup)
輸出
<form> <input id="nm" name="name" type="text"/> <input id="age" name="age" type="text"/> <input id="marks" name="marks" type="text"/></form>
示例 3
這裡我們在 HTML 字串中有一個空的 <p> 標籤。一個新的標籤被插入到其中。
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p></p>', 'html.parser')
tag = soup.new_tag('b')
tag.string = "Hello World"
soup.p.insert(0,tag)
print (soup)
輸出
<p><b>Hello World</b></p>
Beautiful Soup - insert() 方法
方法描述
Beautiful Soup 中的 `insert()` 方法在 Tag 元素的子元素列表中的給定位置新增一個元素。Beautiful Soup 中的 `insert()` 方法的行為類似於 Python 列表物件上的 `insert()`。
語法
insert(position, child)
引數
position − 應插入新 PageElement 的位置。
child − 要插入的 PageElement。
返回值型別
`insert()` 方法不會返回任何新物件。
示例1
在以下示例中,一個新字串在位置 1 新增到 <b> 標籤中。生成的已解析文件顯示了結果。
from bs4 import BeautifulSoup, NavigableString markup = '<b>Excellent </b><u>from TutorialsPoint</u>' soup = BeautifulSoup(markup, 'html.parser') tag = soup.b tag.insert(1, "Tutorial ") print (soup.prettify())
輸出
<b> Excellent Tutorial </b> <u> from TutorialsPoint </u>
示例2
在以下示例中,`insert()` 方法用於將列表中的字串依次插入 HTML 標記中的 <p> 標籤。
from bs4 import BeautifulSoup, NavigableString
markup = '<p>Excellent Tutorials from TutorialsPoint</p>'
soup = BeautifulSoup(markup, 'html.parser')
langs = ['Python', 'Java', 'C']
i=0
for lang in langs:
i+=1
tag = soup.new_tag('p')
tag.string = lang
soup.p.insert(i, tag)
print (soup.prettify())
輸出
<p>
Excellent Tutorials from TutorialsPoint
<p>
Python
</p>
<p>
Java
</p>
<p>
C
</p>
</p>
Beautiful Soup - insert_before() 方法
方法描述
Beautiful Soup 中的 `insert_before()` 方法在解析樹中的其他內容之前立即插入標籤或字串。插入的元素成為此元素的直接前驅。插入的元素可以是標籤或字串。
語法
insert_before(*args)
引數
args − 一個或多個元素,可以是標籤或字串。
返回值
此 `insert_before()` 方法不會返回任何新物件。
示例1
以下示例在給定的 HTML 標記字串中的 "Excellent" 之前插入文字 "Here is an"。
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Excellent</b> Python Tutorial <u>from TutorialsPoint</u>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag.insert_before("Here is an ")
print (soup.prettify())
輸出
Here is an <b> Excellent </b> Python Tutorial <u> from TutorialsPoint </u>
示例2
您還可以在一個標籤之前插入一個標籤。看看這個例子。
from bs4 import BeautifulSoup, NavigableString
markup = '<P>Excellent <b>Tutorial</b> from TutorialsPoint</u>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag1 = soup.new_tag('b')
tag1.string = "Python "
tag.insert_before(tag1)
print (soup.prettify())
輸出
<p>
Excellent
<b>
Python
</b>
<b>
Tutorial
</b>
from TutorialsPoint
</p>
示例 3
以下程式碼傳遞多個要插入到 <b> 標籤之前的字串。
from bs4 import BeautifulSoup
markup = '<p>There are <b>Tutorials</b> <u>from TutorialsPoint</u></p>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag.insert_before("many ", 'excellent ')
print (soup.prettify())
輸出
<p>
There are
many
excellent
<b>
Tutorials
</b>
<u>
from TutorialsPoint
</u>
</p>
Beautiful Soup - insert_after() 方法
方法描述
Beautiful Soup 中的 `insert_after()` 方法在解析樹中的其他內容之後立即插入標籤或字串。插入的元素成為此元素的直接後繼。插入的元素可以是標籤或字串。
語法
insert_after(*args)
引數
args − 一個或多個元素,可以是標籤或字串。
返回值
此 `insert_after()` 方法不會返回任何新物件。
示例1
以下程式碼在第一個 <b> 標籤之後插入字串 "Python"。
from bs4 import BeautifulSoup
markup = '<p>An <b>Excellent</b> Tutorial <u>from TutorialsPoint</u>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag.insert_after("Python ")
print (soup.prettify())
輸出
<p>
An
<b>
Excellent
</b>
Python
Tutorial
<u>
from TutorialsPoint
</u>
</p>
示例2
您還可以在一個標籤之前插入一個標籤。看看這個例子。
from bs4 import BeautifulSoup, NavigableString
markup = '<P>Excellent <b>Tutorial</b> from TutorialsPoint</p>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag1 = soup.new_tag('b')
tag1.string = "on Python "
tag.insert_after(tag1)
print (soup.prettify())
輸出
<p>
Excellent
<b>
Tutorial
</b>
<b>
on Python
</b>
from TutorialsPoint
</p>
示例 3
可以在某些標籤之後插入多個標籤或字串。
from bs4 import BeautifulSoup, NavigableString
markup = '<P>Excellent <b>Tutorials</b> from TutorialsPoint</p>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.p
tag1 = soup.new_tag('i')
tag1.string = 'and Java'
tag.insert_after("on Python", tag1)
print (soup.prettify())
輸出
<p>
Excellent
<b>
Tutorials
</b>
from TutorialsPoint
</p>
on Python
<i>
and Java
</i>
Beautiful Soup - clear() 方法
方法描述
Beautiful Soup 庫中的 `clear()` 方法刪除標籤的內部內容,同時保持標籤完整。如果存在任何子元素,則會對它們呼叫 `extract()` 方法。如果 `decompose` 引數設定為 True,則會呼叫 `decompose()` 方法而不是 `extract()`。
語法
clear(decompose=False)
引數
decompose − 如果為 True,則將呼叫 `decompose()`(一種更具破壞性的方法)而不是 `extract()`。
返回值
`clear()` 方法不會返回任何物件。
示例1
由於 `clear()` 方法是在表示整個文件的 soup 物件上呼叫的,因此所有內容都將被刪除,使文件為空白。
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
soup.clear()
print(soup)
輸出
示例2
在以下示例中,我們找到所有 <p> 標籤並在每個標籤上呼叫 `clear()` 方法。
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tags = soup.find_all('p')
for tag in tags:
tag.clear()
print(soup)
輸出
每個 <p> .. </p> 的內容將被刪除,標籤將被保留。
<html> <body> <p></p> <p></p> <p></p> <p></p> </body> </html>
示例 3
這裡我們清除 <body> 標籤的內容,並將 `decompose` 引數設定為 Tue。
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tags = soup.find('body')
ret = tags.clear(decompose=True)
print(soup)
輸出
<html> <body></body> </html>
Beautiful Soup - extract() 方法
方法描述
Beautiful Soup 庫中的 `extract()` 方法用於從文件樹中刪除標籤或字串。`extract()` 方法返回已刪除的物件。它類似於 Python 列表中 `pop()` 方法的工作方式。
語法
extract(index)
引數
Index − 要刪除的元素的位置。預設為 None。
返回值型別
`extract()` 方法返回已從文件樹中刪除的元素。
示例1
html = '''
<div>
<p>Hello Python</p>
</div>
'''
from bs4 import BeautifulSoup
soup=BeautifulSoup(html, 'html.parser')
tag1 = soup.find("div")
tag2 = tag1.find("p")
ret = tag2.extract()
print ('Extracted:',ret)
print ('original:',soup)
輸出
Extracted: <p>Hello Python</p> original: <div> </div>
示例2
考慮以下 HTML 標記 -
<html>
<body>
<p> The quick, brown fox jumps over a lazy dog.</p>
<p> DJs flock by when MTV ax quiz prog.</p>
<p> Junk MTV quiz graced by fox whelps.</p>
<p> Bawds jog, flick quartz, vex nymphs./p>
</body>
</html>
這是程式碼 -
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
tags = soup.find_all()
for tag in tags:
obj = tag.extract()
print ("Extracted:",obj)
print (soup)
輸出
Extracted: <html> <body> <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs.</p> </body> </html> Extracted: <body> <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs.</p> </body> Extracted: <p> The quick, brown fox jumps over a lazy dog.</p> Extracted: <p> DJs flock by when MTV ax quiz prog.</p> Extracted: <p> Junk MTV quiz graced by fox whelps.</p> Extracted: <p> Bawds jog, flick quartz, vex nymphs.</p>
示例 3
您還可以將 `extract()` 方法與 `find_next()`、`find_previous()` 方法以及 `next_element`、`previous_element` 屬性一起使用。
html = '''
<div>
<p><b>Hello</b><b>Python</b></p>
</div>
'''
from bs4 import BeautifulSoup
soup=BeautifulSoup(html, 'html.parser')
tag1 = soup.find("b")
ret = tag1.next_element.extract()
print ('Extracted:',ret)
print ('original:',soup)
輸出
Extracted: Hello original: <div> <p><b></b><b>Python</b></p> </div>
Beautiful Soup - decompose() 方法
方法描述
`decompose()` 方法會銷燬當前元素及其子元素,因此該元素將從樹中刪除,將其及下面的所有內容都清除。可以透過 `decomposed` 屬性檢查元素是否已被分解。如果已銷燬,則返回 True,否則返回 false。
語法
decompose()
引數
此方法未定義任何引數。
返回值型別
該方法不會返回任何物件。
示例1
當我們在 BeautifulSoup 物件本身呼叫 `descompose()` 方法時,整個內容將被銷燬。
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
soup.decompose()
print ("decomposed:",soup.decomposed)
print (soup)
輸出
decomposed: True
document: Traceback (most recent call last):
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^~~~~~~~~~~
TypeError: can only concatenate str (not "NoneType") to str
由於 soup 物件已被分解,因此它返回 True,但是,您會得到如上所示的 TypeError。
示例2
以下程式碼使用 `decompose()` 方法刪除在使用的 HTML 字串中所有 <p> 標籤的出現。
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
p_all = soup.find_all('p')
[p.decompose() for p in p_all]
print ("document:",soup)
輸出
刪除所有 <p> 標籤後的其餘 HTML 文件將被列印。
document: <html> <body> </body> </html>
示例 3
這裡,我們從 HTML 文件樹中找到 <body> 標籤,並分解其前面的元素,該元素恰好是 <title> 標籤。生成的文件樹省略了 <title> 標籤。
html = '''
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
Hello World
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag = soup.body
tag.find_previous().decompose()
print ("document:",soup)
輸出
document: <html> <head> </head> <body> Hello World </body> </html>
Beautiful Soup - replace_with() 方法
方法描述
Beautiful Soup 的 `replace_with()` 方法用提供的標籤或字串替換元素中的標籤或字串。
語法
replace_with(tag/string)
引數
該方法接受標籤物件或字串作為引數。
返回值型別
`replace_method` 不會返回新物件。
示例1
在此示例中,<p> 標籤使用 `replace_with()` 方法替換為 <b>。
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('p')
txt = tag1.string
tag2 = soup.new_tag('b')
tag2.string = txt
tag1.replace_with(tag2)
print (soup)
輸出
<html> <body> <b>The quick, brown fox jumps over a lazy dog.</b> </body> </html>
示例2
您可以簡單地透過在 `tag.string` 物件上呼叫 `replace_with()` 方法來用另一個字串替換標籤的內部文字。
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('p')
tag1.string.replace_with("DJs flock by when MTV ax quiz prog.")
print (soup)
輸出
<html> <body> <p>DJs flock by when MTV ax quiz prog.</p> </body> </html>
示例 3
用於替換的標籤物件可以透過任何 `find()` 方法獲得。這裡,我們替換 <p> 標籤旁邊的標籤的文字。
html = '''
<html>
<body>
<p>The quick, <b>brown</b> fox jumps over a lazy dog.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('p')
tag1.find_next('b').string.replace_with('black')
print (soup)
輸出
<html> <body> <p>The quick, <b>black</b> fox jumps over a lazy dog.</p> </body> </html>
Beautiful Soup - wrap() 方法
方法描述
Beautiful Soup 中的 `wrap()` 方法將元素包含在另一個元素內。您可以將現有的標籤元素用另一個元素包裝,或者將標籤的字串用標籤包裝。
語法
wrap(tag)
引數
要包裝的標籤。
返回值型別
該方法返回一個帶有給定標籤的新包裝器。
示例1
在此示例中,<b> 標籤被包裝在 <div> 標籤中。
html = '''
<html>
<body>
<p>The quick, <b>brown</b> fox jumps over a lazy dog.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('b')
newtag = soup.new_tag('div')
tag1.wrap(newtag)
print (soup)
輸出
<html> <body> <p>The quick, <div><b>brown</b></div> fox jumps over a lazy dog.</p> </body> </html>
示例2
我們將 <p> 標籤內的字串用包裝標籤包裝。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>tutorialspoint.com</p>", 'html.parser')
soup.p.string.wrap(soup.new_tag("b"))
print (soup)
輸出
<p><b>tutorialspoint.com</b></p>
Beautiful Soup - unwrap() 方法
方法描述
`unwrap()` 方法與 `wrap()` 方法相反。它用標籤內的任何內容替換標籤。它從元素中刪除標籤並將其返回。
語法
unwrap()
引數
該方法不需要任何引數。
返回值型別
`unwrap()` 方法返回已刪除的標籤。
示例1
在以下示例中,刪除了 html 字串中的 <b> 標籤。
html = '''
<p>The quick, <b>brown</b> fox jumps over a lazy dog.</p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('b')
newtag = tag1.unwrap()
print (soup)
輸出
<p>The quick, brown fox jumps over a lazy dog.</p>
示例2
以下程式碼列印 `unwrap()` 方法的返回值。
html = '''
<p>The quick, <b>brown</b> fox jumps over a lazy dog.</p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('b')
newtag = tag1.unwrap()
print (newtag)
輸出
<b></b>
示例 3
`unwrap()` 方法對於去除標記很有用,如下面的程式碼所示 -
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
#print (soup.unwrap())
for tag in soup.find_all():
tag.unwrap()
print (soup)
輸出
The quick, brown fox jumps over a lazy dog. DJs flock by when MTV ax quiz prog. Junk MTV quiz graced by fox whelps. Bawds jog, flick quartz, vex nymphs.
Beautiful Soup - smooth() 方法
方法描述
在呼叫大量修改解析樹的方法後,您最終可能會得到兩個或多個彼此相鄰的 NavigableString 物件。`smooth()` 方法透過合併連續的字串來平滑此元素的子元素。這使得在大量修改樹的操作之後,格式化輸出看起來更自然。
語法
smooth()
引數
此方法沒有引數。
返回值型別
此方法在平滑後返回給定的標籤。
示例1
html ='''<html>
<head>
<title>TutorislsPoint/title>
</head>
<body>
Some Text
<div></div>
<p></p>
<div>Some more text</div>
<b></b>
<i></i> # COMMENT
</body>
</html>'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
soup.find('body').sm
for item in soup.find_all():
if not item.get_text(strip=True):
p = item.parent
item.replace_with('')
p.smooth()
print (soup.prettify())
輸出
<html>
<head>
<title>
TutorislsPoint/title>
</title>
</head>
<body>
Some Text
<div>
Some more text
</div>
# COMMENT
</body>
</html>
示例2
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>Hello</p>", 'html.parser')
soup.p.append(", World")
soup.smooth()
print (soup.p.contents)
print(soup.p.prettify())
輸出
['Hello, World'] <p> Hello, World </p>
Beautiful Soup - prettify() 方法
方法描述
要獲得格式良好的 Unicode 字串,請使用 Beautiful Soup 的 prettify() 方法。它格式化 Beautiful Soup 解析樹,以便每個標籤都位於自己的單獨行並帶有縮排。它允許您輕鬆地視覺化 Beautiful Soup 解析樹的結構。
語法
prettify(encoding, formatter)
引數
encoding − 字串的最終編碼。如果為 None,則將返回 Unicode 字串。
一個 Formatter 物件,或一個命名標準格式化程式之一的字串。
返回值型別
`prettify()` 方法返回一個 Unicode 字串(如果 `encoding==None`)或一個位元組字串(否則)。
示例1
考慮以下 HTML 字串。
<p>The quick, <b>brown fox</b> jumps over a lazy dog.</p>
使用 prettify() 方法,我們可以更好地理解其結構:
html = ''' <p>The quick, <b>brown fox</b> jumps over a lazy dog.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "lxml") print (soup.prettify())
輸出
<html>
<body>
<p>
The quick,
<b>
brown fox
</b>
jumps over a lazy dog.
</p>
</body>
</html>
示例2
您可以在文件中的任何 Tag 物件上呼叫 prettify()。
print (soup.b.prettify())
輸出
<b> brown fox </b>
prettify() 方法用於理解文件的結構。但是,它不應用於重新格式化它,因為它添加了空格(以換行符的形式),並更改了 HTML 文件的含義。
He prettify() 方法可以選擇提供 formatter 引數來指定要使用的格式。
格式化程式有以下可能的值。
formatter="minimal" − 這是預設值。字串將僅被處理到足以確保 Beautiful Soup 生成有效的 HTML/XML。
formatter="html" - Beautiful Soup 將盡可能地將 Unicode 字元轉換為 HTML 實體。
formatter="html5" − 它類似於 `formatter="html"`,但 Beautiful Soup 將省略 HTML 空標籤(如 "br")中的結束斜槓。
formatter=None − Beautiful Soup 根本不會修改輸出中的字串。這是最快的選項,但它可能導致 Beautiful Soup 生成無效的 HTML/XML。
示例 3
from bs4 import BeautifulSoup
french = "<p>Il a dit <<Sacré bleu!>></p>"
soup = BeautifulSoup(french, 'html.parser')
print ("minimal: ")
print(soup.prettify(formatter="minimal"))
print ("html: ")
print(soup.prettify(formatter="html"))
print ("None: ")
print(soup.prettify(formatter=None))
輸出
minimal: <p> Il a dit < <sacré bleu!=""> > </sacré> </p> html: <p> Il a dit < <sacré bleu!=""> > </sacré> </p> None: <p> Il a dit < <sacré bleu!=""> > </sacré> </p>
Beautiful Soup - encode() 方法
方法描述
Beautiful Soup 中的 `encode()` 方法呈現給定 PageElement 及其內容的位元組字串表示形式。
`prettify()` 方法允許您輕鬆視覺化 Beautiful Soup 解析樹的結構,它具有 `encoding` 引數。`encode()` 方法的作用與 `prettify()` 方法中的 `encoding` 引數相同。
語法
encode(encoding, indent_level, formatter, errors)
引數
encoding − 目標編碼。
indent_level − 渲染的每一行將
縮排這麼多級。在漂亮列印時,在遞迴呼叫中內部使用。
formatter − 一個 Formatter 物件,或一個命名標準格式化程式之一的字串。
errors − 錯誤處理策略。
返回值
`encode()` 方法返回標籤及其內容的位元組字串表示形式。
示例1
`encoding` 引數預設為 utf-8。以下程式碼顯示了 soup 物件的編碼位元組字串表示形式。
from bs4 import BeautifulSoup
soup = BeautifulSoup("Hello “World!”", 'html.parser')
print (soup.encode('utf-8'))
輸出
b'Hello \xe2\x80\x9cWorld!\xe2\x80\x9d'
示例2
格式化程式物件具有以下預定義值 -
formatter="minimal" − 這是預設值。字串將僅被處理到足以確保 Beautiful Soup 生成有效的 HTML/XML。
formatter="html" - Beautiful Soup 將盡可能地將 Unicode 字元轉換為 HTML 實體。
formatter="html5" − 它類似於 `formatter="html"`,但 Beautiful Soup 將省略 HTML 空標籤(如 "br")中的結束斜槓。
formatter=None − Beautiful Soup 根本不會修改輸出中的字串。這是最快的選項,但它可能導致 Beautiful Soup 生成無效的 HTML/XML。
在以下示例中,不同的格式化程式值用作 `encode()` 方法的引數。
from bs4 import BeautifulSoup
french = "<p>Il a dit <<Sacré bleu!>></p>"
soup = BeautifulSoup(french, 'html.parser')
print ("minimal: ")
print(soup.p.encode(formatter="minimal"))
print ("html: ")
print(soup.p.encode(formatter="html"))
print ("None: ")
print(soup.p.encode(formatter=None))
輸出
minimal: b'<p>Il a dit <<Sacr\xc3\xa9 bleu!>></p>' html: b'<p>Il a dit <<Sacré bleu!>></p>' None: b'<p>Il a dit <<Sacr\xc3\xa9 bleu!>></p>'
示例 3
以下示例使用 Latin-1 作為 `encoding` 引數。
markup = '''
<html>
<head>
<meta content="text/html; charset=ISO-Latin-1" http-equiv="Content-type" />
</head>
<body>
<p>Sacr`e bleu!</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup, 'lxml')
print(soup.p.encode("latin-1"))
輸出
b'<p>Sacr`e bleu!</p>'
Beautiful Soup - decode() 方法
方法描述
Beautiful Soup 中的 `decode()` 方法將解析樹作為 HTML 或 XML 文件返回字串或 Unicode 表示形式。該方法使用為編碼註冊的編解碼器解碼位元組。其功能與 `encode()` 方法相反。呼叫 `encode()` 獲取位元組字串,呼叫 `decode()` 獲取 Unicode。讓我們透過一些示例來學習 `decode()` 方法。
語法
decode(pretty_print, encoding, formatter, errors)
引數
pretty_print − 如果此值為 True,則將使用縮排使文件更易讀。
encoding − 最終文件的編碼。如果此值為 None,則文件將為 Unicode 字串。
formatter − 一個 Formatter 物件,或一個命名標準格式化程式之一的字串。
errors − 用於處理解碼錯誤的錯誤處理方案。值為 'strict'、'ignore' 和 'replace'。
返回值
decode() 方法返回一個 Unicode 字串。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("Hello “World!”", 'html.parser')
enc = soup.encode('utf-8')
print (enc)
dec = enc.decode()
print (dec)
輸出
b'Hello \xe2\x80\x9cWorld!\xe2\x80\x9d' Hello "World!"
Beautiful Soup - get_text() 方法
方法描述
get_text() 方法僅返回整個 HTML 文件或給定標籤中的人類可讀文字。所有子字串都由給定的分隔符連線,預設情況下為 null 字串。
語法
get_text(separator, strip)
引數
separator − 子字串將使用此引數連線。預設值為 ""。
strip − 在連線之前,字串將被去除空格。
返回值型別
get_Text() 方法返回一個字串。
示例1
在下面的示例中,get_text() 方法刪除了所有 HTML 標籤。
html = ''' <html> <body> <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs.</p> </body> </html> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") text = soup.get_text() print(text)
輸出
The quick, brown fox jumps over a lazy dog. DJs flock by when MTV ax quiz prog. Junk MTV quiz graced by fox whelps. Bawds jog, flick quartz, vex nymphs.
示例2
在以下示例中,我們將 get_text() 方法的分隔符引數指定為 '#'。
html = ''' <p>The quick, brown fox jumps over a lazy dog.</p> <p>DJs flock by when MTV ax quiz prog.</p> <p>Junk MTV quiz graced by fox whelps.</p> <p>Bawds jog, flick quartz, vex nymphs.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") text = soup.get_text(separator='#') print(text)
輸出
#The quick, brown fox jumps over a lazy dog.# #DJs flock by when MTV ax quiz prog.# #Junk MTV quiz graced by fox whelps.# #Bawds jog, flick quartz, vex nymphs.#
示例 3
讓我們檢查當 strip 引數設定為 True 時產生的效果。預設值為 False。
html = ''' <p>The quick, brown fox jumps over a lazy dog.</p> <p>DJs flock by when MTV ax quiz prog.</p> <p>Junk MTV quiz graced by fox whelps.</p> <p>Bawds jog, flick quartz, vex nymphs.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") text = soup.get_text(strip=True) print(text)
輸出
The quick, brown fox jumps over a lazy dog.DJs flock by when MTV ax quiz prog.Junk MTV quiz graced by fox whelps.Bawds jog, flick quartz, vex nymphs.
Beautiful Soup - diagnose() 方法
方法描述
Beautiful Soup 中的 diagnose() 方法是用於隔離常見問題的診斷套件。如果您難以理解 Beautiful Soup 對文件做了什麼,請將文件作為引數傳遞給 diagnose() 函式。一個報告將向您展示不同的解析器如何處理文件,並告訴您是否缺少解析器。
語法
diagnose(data)
引數
data − 文件字串。
返回值
diagnose() 方法根據所有可用的解析器列印解析給定文件的結果。
示例
讓我們以這個簡單的文件作為我們的練習示例 -
<h1>Hello World <b>Welcome</b> <P><b>Beautiful Soup</a> <i>Tutorial</i><p>
以下程式碼對上述 HTML 指令碼執行診斷 -
markup = ''' <h1>Hello World <b>Welcome</b> <P><b>Beautiful Soup</a> <i>Tutorial</i><p> ''' from bs4.diagnose import diagnose diagnose(markup)
diagnose() 的輸出以一條訊息開頭,顯示所有可用的解析器 -
Diagnostic running on Beautiful Soup 4.12.2 Python version 3.11.2 (tags/v3.11.2:878ead1, Feb 7 2023, 16:38:35) [MSC v.1934 64 bit (AMD64)] Found lxml version 4.9.2.0 Found html5lib version 1.1
如果要診斷的文件是一個完美的 HTML 文件,則所有解析器的結果幾乎相同。但是,在我們的示例中,有很多錯誤。
首先,內建的 html.parser 被使用。報告如下 -
Trying to parse your markup with html.parser
Here's what html.parser did with the markup:
<h1>
Hello World
<b>
Welcome
</b>
<p>
<b>
Beautiful Soup
<i>
Tutorial
</i>
<p>
</p>
</b>
</p>
</h1>
您可以看到 Python 的內建解析器不會插入 <html> 和 <body> 標籤。未關閉的 <h1> 標籤在末尾用匹配的 <h1> 提供。
html5lib 和 lxml 解析器都透過將其包裝在 <html>、<head> 和 <body> 標籤中來完成文件。
Trying to parse your markup with html5lib
Here's what html5lib did with the markup:
<html>
<head>
</head>
<body>
<h1>
Hello World
<b>
Welcome
</b>
<p>
<b>
Beautiful Soup
<i>
Tutorial
</i>
</b>
</p>
<p>
<b>
</b>
</p>
</h1>
</body>
</html>
使用 lxml 解析器,請注意插入 </h1> 的位置。此外,不完整的 <b> 標籤已糾正,並且懸掛的 </a> 已刪除。
Trying to parse your markup with lxml
Here's what lxml did with the markup:
<html>
<body>
<h1>
Hello World
<b>
Welcome
</b>
</h1>
<p>
<b>
Beautiful Soup
<i>
Tutorial
</i>
</b>
</p>
<p>
</p>
</body>
</html>
diagnose() 方法也以 XML 文件的形式解析文件,這在我們的例子中可能多餘。
Trying to parse your markup with lxml-xml
Here's what lxml-xml did with the markup:
<?xml version="1.0" encoding="utf-8"?>
<h1>
Hello World
<b>
Welcome
</b>
<P>
<b>
Beautiful Soup
</b>
<i>
Tutorial
</i>
<p/>
</P>
</h1>
讓我們為 diagnose() 方法提供一個 XML 文件而不是 HTML 文件。
<?xml version="1.0" ?>
<books>
<book>
<title>Python</title>
<author>TutorialsPoint</author>
<price>400</price>
</book>
</books>
現在,如果我們執行診斷,即使它是一個 XML,也會應用 html 解析器。
Trying to parse your markup with html.parser
Warning (from warnings module):
File "C:\Users\mlath\OneDrive\Documents\Feb23 onwards\BeautifulSoup\Lib\site-packages\bs4\builder\__init__.py", line 545
warnings.warn(
XMLParsedAsHTMLWarning: It looks like you're parsing an XML document using an HTML parser. If this really is an HTML document (maybe it's XHTML?), you can ignore or filter this warning. If it's XML, you should know that using an XML parser will be more reliable. To parse this document as XML, make sure you have the lxml package installed, and pass the keyword argument `features="xml"` into the BeautifulSoup constructor.
對於 html.parser,會顯示一條警告訊息。對於 html5lib,包含 XML 版本資訊的第 1 行被註釋掉,其餘的文件被解析為 HTML 文件。
Trying to parse your markup with html5lib
Here's what html5lib did with the markup:
<!--?xml version="1.0" ?-->
<html>
<head>
</head>
<body>
<books>
<book>
<title>
Python
</title>
<author>
TutorialsPoint
</author>
<price>
400
</price>
</book>
</books>
</body>
</html>
lxml html 解析器不會插入註釋,而是將其解析為 HTML。
Trying to parse your markup with lxml
Here's what lxml did with the markup:
<?xml version="1.0" ?>
<html>
<body>
<books>
<book>
<title>
Python
</title>
<author>
TutorialsPoint
</author>
<price>
400
</price>
</book>
</books>
</body>
</html>
lxml-xml 解析器將文件解析為 XML。
Trying to parse your markup with lxml-xml
Here's what lxml-xml did with the markup:
<?xml version="1.0" encoding="utf-8"?>
<?xml version="1.0" ?>
<books>
<book>
<title>
Python
</title>
<author>
TutorialsPoint
</author>
<price>
400
</price>
</book>
</books>
診斷報告可能有助於發現 HTML/XML 文件中的錯誤。