- Beautiful Soup 教程
- Beautiful Soup - 首頁
- Beautiful Soup - 概述
- Beautiful Soup - 網頁抓取
- Beautiful Soup - 安裝
- Beautiful Soup - 解析頁面
- Beautiful Soup - 物件型別
- Beautiful Soup - 檢查資料來源
- Beautiful Soup - 抓取HTML內容
- Beautiful Soup - 透過標籤導航
- Beautiful Soup - 透過ID查詢元素
- Beautiful Soup - 透過類查詢元素
- Beautiful Soup - 透過屬性查詢元素
- Beautiful Soup - 搜尋樹結構
- Beautiful Soup - 修改樹結構
- Beautiful Soup - 解析文件的一部分
- Beautiful Soup - 查詢元素的所有子元素
- Beautiful Soup - 使用CSS選擇器查詢元素
- Beautiful Soup - 查詢所有註釋
- Beautiful Soup - 從HTML中抓取列表
- Beautiful Soup - 從HTML中抓取段落
- BeautifulSoup - 從HTML中抓取連結
- Beautiful Soup - 獲取所有HTML標籤
- Beautiful Soup - 獲取標籤內的文字
- Beautiful Soup - 查詢所有標題
- Beautiful Soup - 提取標題標籤
- Beautiful Soup - 提取郵箱ID
- Beautiful Soup - 抓取巢狀標籤
- Beautiful Soup - 解析表格
- Beautiful Soup - 選擇第n個子元素
- Beautiful Soup - 透過標籤內的文字搜尋
- Beautiful Soup - 刪除HTML標籤
- Beautiful Soup - 刪除所有樣式
- Beautiful Soup - 刪除所有指令碼
- Beautiful Soup - 刪除空標籤
- Beautiful Soup - 刪除子元素
- Beautiful Soup - find vs find_all
- Beautiful Soup - 指定解析器
- Beautiful Soup - 比較物件
- Beautiful Soup - 複製物件
- Beautiful Soup - 獲取標籤位置
- Beautiful Soup - 編碼
- Beautiful Soup - 輸出格式
- Beautiful Soup - 美化輸出
- Beautiful Soup - NavigableString 類
- Beautiful Soup - 將物件轉換為字串
- Beautiful Soup - 將HTML轉換為文字
- Beautiful Soup - 解析XML
- Beautiful Soup - 錯誤處理
- Beautiful Soup - 故障排除
- Beautiful Soup - 移植舊程式碼
- Beautiful Soup - 函式參考
- Beautiful Soup - contents 屬性
- Beautiful Soup - children 屬性
- Beautiful Soup - string 屬性
- Beautiful Soup - strings 屬性
- Beautiful Soup - stripped_strings 屬性
- Beautiful Soup - descendants 屬性
- Beautiful Soup - parent 屬性
- Beautiful Soup - parents 屬性
- Beautiful Soup - next_sibling 屬性
- Beautiful Soup - previous_sibling 屬性
- Beautiful Soup - next_siblings 屬性
- Beautiful Soup - previous_siblings 屬性
- Beautiful Soup - next_element 屬性
- Beautiful Soup - previous_element 屬性
- Beautiful Soup - next_elements 屬性
- Beautiful Soup - previous_elements 屬性
- Beautiful Soup - find 方法
- Beautiful Soup - find_all 方法
- Beautiful Soup - find_parents 方法
- Beautiful Soup - find_parent 方法
- Beautiful Soup - find_next_siblings 方法
- Beautiful Soup - find_next_sibling 方法
- Beautiful Soup - find_previous_siblings 方法
- Beautiful Soup - find_previous_sibling 方法
- Beautiful Soup - find_all_next 方法
- Beautiful Soup - find_next 方法
- Beautiful Soup - find_all_previous 方法
- Beautiful Soup - find_previous 方法
- Beautiful Soup - select 方法
- Beautiful Soup - append 方法
- Beautiful Soup - extend 方法
- Beautiful Soup - NavigableString 方法
- Beautiful Soup - new_tag 方法
- Beautiful Soup - insert 方法
- Beautiful Soup - insert_before 方法
- Beautiful Soup - insert_after 方法
- Beautiful Soup - clear 方法
- Beautiful Soup - extract 方法
- Beautiful Soup - decompose 方法
- Beautiful Soup - replace_with 方法
- Beautiful Soup - wrap 方法
- Beautiful Soup - unwrap 方法
- Beautiful Soup - smooth 方法
- Beautiful Soup - prettify 方法
- Beautiful Soup - encode 方法
- Beautiful Soup - decode 方法
- Beautiful Soup - get_text 方法
- Beautiful Soup - diagnose 方法
- Beautiful Soup 有用資源
- Beautiful Soup - 快速指南
- Beautiful Soup - 有用資源
- Beautiful Soup - 討論
Beautiful Soup - 概述
在當今世界,我們擁有大量的非結構化資料/資訊(主要是網頁資料)可免費獲取。有時這些免費資料易於閱讀,有時則不然。無論您的資料如何呈現,網頁抓取都是將非結構化資料轉換為易於閱讀和分析的結構化資料非常有用的工具。換句話說,網頁抓取是一種收集、組織和分析海量資料的方法。那麼,讓我們首先了解什麼是網頁抓取。
Beautiful Soup 簡介
Beautiful Soup 是一個 Python 庫,其名稱源於劉易斯·卡羅爾在《愛麗絲夢遊仙境》中同名詩歌。Beautiful Soup 是一個 Python 包,顧名思義,它解析不需要的資料,並透過修復錯誤的 HTML 並以易於遍歷的 XML 結構呈現給我們,從而幫助組織和格式化混亂的網頁資料。
簡而言之,Beautiful Soup 是一個 Python 包,允許我們從 HTML 和 XML 文件中提取資料。
HTML 樹結構
在深入瞭解 Beautiful Soup 提供的功能之前,讓我們首先了解 HTML 樹結構。
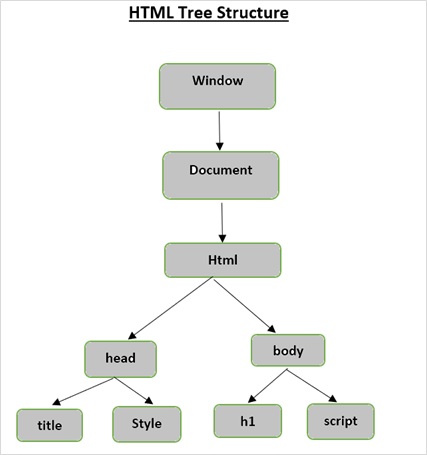
文件樹中的根元素是 html,它可以有父節點、子節點和兄弟節點,這由它在樹結構中的位置決定。要在 HTML 元素、屬性和文字之間移動,您必須在樹結構中的節點之間移動。
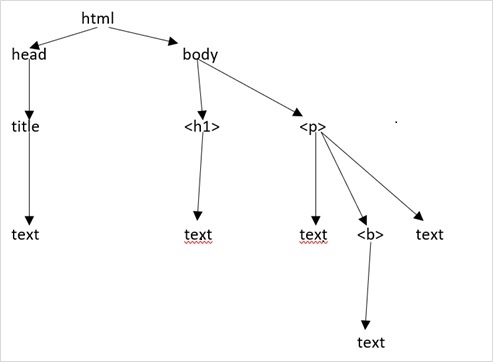
讓我們假設網頁如下所示:

這轉換為如下所示的 html 文件:
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
</body>
</html>
這僅僅意味著,對於上面的 html 文件,我們有如下所示的 html 樹結構:
廣告