- AWS Athena 教程
- AWS Athena - 首頁
- 什麼是 AWS Athena?
- AWS Athena - 入門
- AWS Athena 如何工作?
- AWS Athena - 編寫 SQL 查詢
- AWS Athena - 效能最佳化
- AWS Athena - 資料安全
- AWS Athena - 成本管理
- AWS Athena 資源
- AWS Athena 快速指南
- AWS Athena - 資源
- AWS Athena - 討論
AWS Athena 快速指南
AWS Athena 是一款無伺服器、互動式查詢服務,允許您使用標準 SQL 直接分析 Amazon Simple Storage Service (S3) 中的大型資料集。
- 與傳統資料庫相比,Athena 更好,因為它消除了配置、管理和擴充套件等管理任務的需求。
- Athena 為使用者提供了更大的靈活性,因為它可以自動處理跨分割槽的資料。將資料上傳到 Amazon S3 後,您可以立即開始查詢資料。
- Athena 即使在大型資料集上也能實現高效能查詢,因為它使用 Presto 分散式 SQL 引擎來執行查詢。
- AWS Athena 支援多種格式,包括 CSV、JSON、Parquet 和 ORC。
資料分析師、開發人員或任何想要執行查詢而無需資料倉庫的人員都可以使用 Athena。
為什麼選擇 AWS Athena 進行資料查詢?
在本節中,我們重點介紹了一系列充分的理由,說明您為什麼應該選擇 AWS Athena 而不是其他工具進行資料查詢:
1. 無伺服器架構
AWS Athena 最重要的優勢之一是它完全是無伺服器的。這意味著使用者無需管理伺服器、儲存,也不必擔心擴充套件基礎設施。Athena 只允許使用者進行資料查詢。
2. 按查詢付費模型
AWS Athena 遵循按查詢付費模型。這意味著使用者只需為查詢掃描的資料付費。此功能使其具有成本效益。
3. 支援各種資料格式
Athena 支援各種資料格式,包括結構化、半結構化和非結構化格式。它可以查詢儲存為 CSV、JSON、Apache Parquet、Apache ORC 甚至 Apache Web 日誌等日誌格式的資料。
4. 易於與 AWS 服務整合
AWS Athena 可以輕鬆連線到其他 AWS 工具,這使得建立完整的資料管道變得容易。
例如,AWS Athena 可以很好地與 AWS Glue(用於資料組織)、AWS Lambda(用於即時處理)和 Amazon QuickSight(用於視覺化資料和構建儀表板)配合使用。
5. Athena 提供安全的環境
AWS Athena 是安全的,因為它為您的資料提供了多層安全保護。它與 **AWS Identity and Access Management (IAM)** 整合,以控制對資料集的訪問。
Athena 確保只有授權使用者才能執行查詢。使用者還可以配置 **VPC 端點**,以確保所有資料查詢都在安全和私有網路內執行。
6. 可擴充套件性和速度
AWS Athena 旨在處理大量資料。它會自動擴充套件自身以適應更大的資料集,並確保快速執行查詢,而無論資料量如何。
Athena 即使對於複雜的查詢也能實現高速效能,因為它使用 Presto 分散式 SQL 引擎來執行查詢。
7. 易用性
AWS Athena 使用標準 SQL,因此對於熟悉 SQL 查詢的任何人來說都很容易使用。其使用者友好的介面使使用者只需點選幾下即可直接在其 S3 資料上執行 SQL 查詢。
Athena 還透過自動建立表和架構來自您的資料來簡化設定和執行查詢的過程。
AWS Athena - 入門
設定您的 AWS Athena 環境很簡單,並且對於有效地在儲存在 Amazon S3 中的資料上執行 SQL 查詢至關重要。
先決條件
在開始使用 AWS Athena 之前,以下是先決條件:
- 您必須擁有一個 **AWS 賬戶**才能使用 **AWS Athena**。
- 您應該擁有 **IAM 角色**,它允許 AWS Athena 訪問您來自 Amazon S3 的資料。
- 您應該將您的 **資料儲存在 Amazon S3 中**。
滿足這些先決條件後,請按照以下步驟設定您的 AWS Athena 環境:
步驟 1:登入 AWS 控制檯
首先,您需要登入 AWS 管理控制檯。然後導航到 Amazon Athena 服務。您也可以在搜尋欄中搜索 Athena。
步驟 2:建立 S3 儲存桶
在執行查詢之前,必須將您的資料儲存在 Amazon S3 中。這是因為 AWS Athena 直接從 S3 查詢資料。
如果您尚未建立儲存桶,則首先透過轉到 S3 服務並單擊 **“建立儲存桶”** 按鈕來建立它。
步驟 3:配置 AWS Glue 資料目錄
AWS Athena 需要一個數據目錄來定義資料集的結構。為此,建議配置 AWS Glue 資料目錄。
AWS Glue 可以自動與 Athena 整合,並幫助您將資料組織成表。在 AWS Glue 中,您需要建立一個爬蟲,它掃描您的 S3 資料並在 Athena 資料目錄中建立表架構。
步驟 4:設定 IAM 許可權
Aws Athena 需要許可權才能訪問 S3 和其他 AWS 服務。您需要建立或分配一個具有 Athena 訪問您的 S3 儲存桶和 Glue 資料目錄所需許可權的 IAM 角色。
在 AWS Athena 中建立您的第一個查詢
現在,您已經設定了 AWS Athena 環境,您可以準備在 Athena 中建立您的第一個查詢。在 AWS Athena 中建立查詢是一個非常簡單的過程。它允許您毫不費力地分析資料。
按照以下步驟在 Athena 中建立您的第一個查詢:
步驟 1:開啟 Athena 控制檯
首先,登入您的 AWS 管理控制檯並導航到 Athena 服務。
步驟 2:選擇您的資料庫
接下來,開啟 Athena 查詢編輯器。現在選擇儲存資料所在的資料庫。此資料庫應包含您的表。
檢視以下影像,其中我們選擇了名為 **“tutorialpoint”** 的資料庫:

步驟 3:編寫您的 SQL 查詢
現在,您可以開始編寫 SQL 查詢了。使用您已建立並儲存在所選資料庫中的表。
步驟 4:執行查詢
編寫查詢後,要執行它,請單擊 **“執行查詢”** 按鈕。AWS Athena 將執行您的 SQL 語句並從指定的表中檢索資料。
步驟 5:檢視結果
查詢執行完成後,它將在查詢編輯器下方顯示結果。您還可以將結果下載為各種格式,例如 CSV。
步驟 6:儲存您的查詢
您還可以儲存您的查詢,並在將來再次使用該查詢。
透過按照上述步驟,您可以輕鬆地在 AWS Athena 中建立和執行您的第一個查詢。
AWS Athena 如何工作?
以下流程圖說明了 Amazon Athena 的工作原理:
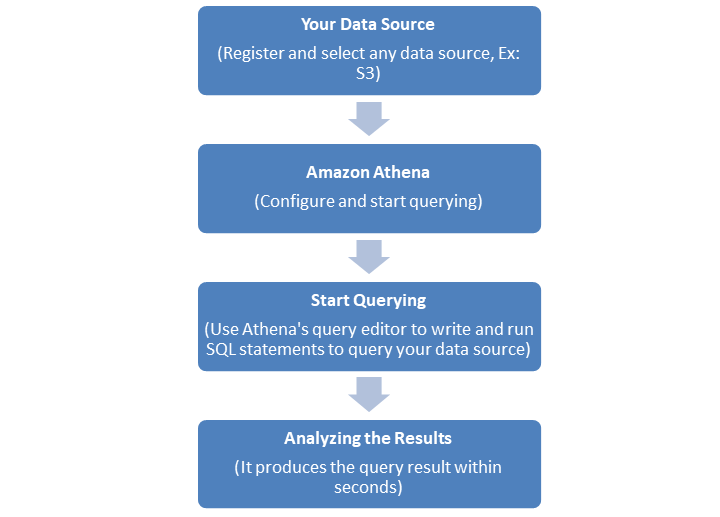
首先,您需要註冊並 **選擇您的資料來源**。例如,**Amazon S3** 是一個流行的 AWS 資料來源,您可以在其中儲存您的表。
接下來,此資料來源應與 Amazon Athena 整合。您首先需要配置 Athena。
配置並整合後,您可以使用 Athena 的查詢編輯器編寫和執行 SQL 語句來查詢您的資料來源。
Athena 將在幾秒鐘內提供查詢結果。獲取結果後,分析結果。您可以根據需要改進查詢。
與 AWS S3 和其他 AWS 服務整合
將 AWS Athena 與 AWS S3 和其他 AWS 服務整合可以增強資料分析的功能並簡化資料管道。
在本章的下一部分,我們提供了將 Athena 與 AWS S3 和其他 AWS 服務整合的分步指南。
將 AWS Athena 與 Amazon S3 整合
要將 AWS Athena 與 Amazon S3 整合,請按照以下步驟操作:
上傳資料
首先,將您的資料集儲存在 Amazon S3 中。Athena 可以直接從各種格式(如 CSV、JSON、Parquet、ORC 和 Avro)查詢資料。
資料夾結構
接下來,您需要使用資料夾結構(如 **s3://your-bucket/folder/subfolder/data.csv**)組織您的資料。這使得查詢更簡單。
在 S3 中建立表和執行查詢
現在,您可以建立表並在儲存在 Amazon S3 中的資料上執行查詢。
將 AWS Athena 與 AWS Glue 整合
要將 AWS Athena 與 AWS Glue 整合,請按照以下步驟操作:
設定 Glue 資料目錄
首先,設定 AWS Glue 資料目錄。它可以自動發現和編目您在 Amazon S3 中的資料。Glue 目錄充當 Aws Athena 的集中式元資料儲存庫。
配置爬蟲
接下來,我們需要配置一個 Glue 爬蟲。為此,首先建立一個 Glue 爬蟲並指定您的 Amazon S3 儲存桶位置。Glue 爬蟲掃描資料並建立元資料表。
使用 Athena 查詢資料
Glue 編目您的資料後,表將自動顯示在 AWS Athena 查詢編輯器中。現在,您可以透過簡單地選擇表來查詢資料。例如,一個簡單的查詢如下所示:
SELECT * FROM glue_catalog_database.table_name WHERE condition;
轉換資料
AWS Glue 可用於 ETL 任務。您可以編寫 Glue 作業,這些作業處理 Amazon S3 中的原始資料並將清理後的資料儲存回 Amazon S3。
將 AWS Athena 與 AWS Lambda 整合
要將 AWS Athena 與 AWS Lambda 整合,請按照以下步驟操作:
建立 Lambda 函式
首先,編寫一個 Lambda 函式,該函式使用 AWS SDK 觸發 AWS Athena 查詢。例如,S3 事件(如新檔案上傳)。
示例
檢視以下示例:
import boto3
athena_client = boto3.client('athena')
def lambda_handler(event, context):
response = athena_client.start_query_execution(
QueryString='SELECT * FROM your_table LIMIT 10;',
QueryExecutionContext={
'Database': 'your_database'
},
ResultConfiguration={
'OutputLocation': 's3://your-output-bucket/'
}
)
return response
自動化事件驅動的查詢
您還可以配置 Lambda 函式以根據事件執行 Aws Athena 查詢。例如,事件可以是新資料上傳到 S3。此整合允許使用者進行即時或計劃的資料處理。
將 AWS Athena 與 Amazon CloudWatch 整合
要將 AWS Athena 與 Amazon CloudWatch 整合,請按照以下步驟操作:
設定 CloudWatch 日誌
首先,您需要設定 CloudWatch 日誌。為此,請轉到 Athena 設定並啟用 CloudWatch 日誌以監控查詢執行。
跟蹤查詢效能
啟用後,CloudWatch 允許您監控查詢效能、執行時間和故障。它可以幫助您隨著時間的推移最佳化成本和效能。
為查詢失敗設定警報
最後,您可以設定 CloudWatch 警報,當 Athena 查詢失敗或執行時間超過某個閾值時通知您。建立警報可確保可靠的資料處理。
AWS Athena - 編寫 SQL 查詢
在 AWS Athena 中執行任何查詢之前,您需要建立一個引用 Amazon S3 中資料的表。Athena 使用按需架構方法,這意味著您在查詢資料時定義資料結構,而不是在儲存資料時定義。
讓我們瞭解在 Athena 中建立表的步驟:
登入 AWS Athena 控制檯
首先,從您的 AWS 管理控制檯訪問 Athena。
定義表架構
編寫一個 SQL 查詢來定義表結構。例如:
CREATE EXTERNAL TABLE IF NOT EXISTS your_table_name ( column1 STRING, column2 INT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION 's3://your-bucket/folder/';
執行查詢
現在,在 Athena 查詢編輯器中執行此查詢以建立表。這將允許您引用指定 S3 儲存桶中的資料。
在 Athena 中執行基本 SQL 查詢
建立表後,您可以開始執行 SQL 查詢來分析您的資料。Athena 支援標準 SQL,這使得熟悉 SQL 的使用者可以輕鬆地編寫查詢。下面是一個簡單查詢示例:
SELECT * FROM your_table_name LIMIT 10;
此查詢將從指定的表中獲取前 10 行。您還可以像在任何基於 SQL 的資料庫中一樣過濾資料、連線多個表和使用聚合函式。
示例
讓我們藉助一個示例來理解它。在這裡,我們在 Athena 查詢編輯器中建立了一個數據庫、一個表,然後對該表運行了一個查詢:

AWS Athena - 效能最佳化
AWS Athena 是一種無伺服器查詢服務,允許您使用標準 SQL 分析儲存在 Amazon S3 中的資料。但是,當我們處理大型資料集時,最佳化查詢效能變得非常重要,以確保更快的執行時間並降低成本。
在本章中,我們重點介紹了一些提高 AWS Athena 中查詢效能的最佳實踐。
對您的資料進行分割槽
分割槽是最佳化 AWS Athena 中查詢效能最有效的方法之一。您可以根據日期、區域或產品類別等列將資料劃分為子集。它的好處是 AWS Athena 只掃描相關的分割槽,而不是整個資料集,這可以大大減少查詢時間和掃描的資料量。
如何對資料進行分割槽?
您可以在建立表時使用 PARTITIONED BY 子句。
示例
檢視以下示例:
CREATE EXTERNAL TABLE IF NOT EXISTS your_table_name ( column1 STRING, column2 INT ) PARTITIONED BY (year STRING, month STRING) LOCATION 's3://your-bucket/folder/';
建立表後,使用 MSCK REPAIR TABLE 命令載入分割槽,如下所示:
MSCK REPAIR TABLE your_table_name;
最佳化檔案大小和格式
為了最佳化查詢,您應該選擇正確的檔案大小和資料格式。讓我們看看在查詢時關於檔案大小和檔案格式的一些重要事項:
關於檔案大小的重要事項
- Aws Athena 處理多個小檔案的效率低下,因此小檔案會導致更高的成本。因此,檔案不應該太小。
- 另一方面,非常大的檔案可能會降低效能,因為它們需要更長的時間來讀取和處理。
- 建議將檔案大小保持在128 MB 到 1 GB 之間,以在效率和效能之間取得平衡。
關於檔案格式的重要事項
列式格式(如 Parquet 和 ORC)非常適合 AWS Athena。這些格式按列而不是按行儲存資料,這意味著 Athena 只讀取您查詢的列。
例如,如果您只查詢包含 10 列的資料集中 3 列,則列式格式將只掃描所需的 3 列。這使得查詢更快並減少了掃描的資料量。
Parquet 和ORC 等格式還支援資料壓縮,這可以進一步提高效能。
使用壓縮
您應該在將資料儲存到 Amazon S3 之前對其進行壓縮,因為它可以提高 AWS Athena 中的查詢效能。眾所周知,壓縮減少了資料的大小,這意味著 Athena 在執行查詢時需要掃描的資料更少。
Gzip、Snappy 和Zlib 是 Athena 中支援的一些壓縮格式。
使用選擇性查詢限制資料掃描
如果您想最佳化效能並降低查詢成本,請嘗試不要使用 Athena 中的SELECT* 查詢掃描整個表。相反,始終只選擇分析所需的特定列。您掃描的資料越多,Athena 處理查詢所需的時間和資源就越多,這將增加執行時間和成本。
例如,使用如下查詢代替SELECT*:
SELECT column1, column2 FROM your_table WHERE condition;
對重複查詢使用快取
AWS Athena 為我們提供了結果快取功能,該功能可以儲存查詢結果長達 45 天。如果您在 45 天內執行相同的查詢,Athena 將立即返回快取的結果,而無需重新處理資料,這意味著它不需要掃描新資料。
此出色的功能不僅提高了效能,還降低了查詢成本。
AWS Athena - 資料安全
當您使用 AWS Athena 等雲服務時,資料安全成為重中之重。在本章中,我們重點介紹了 AWS Athena 中資料安全的一些關鍵方面:
管理訪問控制和許可權
AWS Athena 與 AWS Identity and Access Management (IAM) 整合,使您可以控制誰可以訪問您的資料以及他們可以執行哪些操作。
正確配置“訪問控制和許可權”可確保只有授權使用者才能查詢或管理 Athena 中的資料。
使用 AWS IAM 進行訪問控制
IAM 是管理對 AWS 資源訪問的主要工具之一。使用 IAM,您可以建立使用者帳戶、分配角色並根據工作職能定義許可權。
讓我們看看如何使用 IAM 管理“訪問控制”:
建立 IAM 角色和使用者
AWS Athena 允許您為具有特定許可權的不同使用者建立 IAM 角色。例如,資料分析師只需要訪問查詢資料許可權,而資料工程師則需要建立和修改表的完全訪問許可權。
使用細粒度許可權
在 AWS Athena 中,您還可以設定細粒度許可權以限制對特定操作的訪問,例如查詢資料或更改表結構。
例如,IAM 策略可以授予執行 SQL 查詢的許可權,但阻止使用者修改表。
限制對 Amazon S3 的訪問
您可以應用儲存桶策略,允許特定的 IAM 使用者或角色僅訪問某些資料集或資料夾。
資料加密
AWS Athena 中資料安全的另一個重要組成部分是加密。它確保您的資料在靜態和傳輸過程中都受到保護。
Athena 提供多種加密選項,可幫助您保護敏感資料並滿足監管合規性要求。
加密靜態資料
下面是您可以用來加密儲存在 Amazon S3 中的資料的兩種方法:
- S3 託管加密 (SSE-S3)
- AWS Key Management Service (KMS)
加密傳輸中的資料
除了靜態加密外,AWS Athena 還可以使用安全套接字層 (SSL) 加密來加密傳輸中的資料。
SSL 確保在 Athena 和其他服務(例如 Amazon S3)之間傳輸的任何資料都已加密。
AWS Athena 中的合規性功能
為了滿足合規性要求,AWS Athena 還與各種 AWS 服務整合:
AWS CloudTrail
AWS CloudTrail 記錄在 Athena 中執行的所有操作。這些日誌提供了詳細的審計跟蹤,可幫助您跟蹤使用者活動並檢測未經授權的訪問或可疑行為。
AWS Config
AWS Config 可幫助您監控 Athena 配置中的任何更改。它確保符合組織策略。
AWS Athena - 成本管理
AWS Athena 採用按使用付費定價模式,為使用者提供了極大的靈活性。在本章中,我們將簡要解釋 Athena 如何向您收費以及您可以遵循的策略以最大程度地降低 AWS Athena 的成本。
瞭解 Athena 定價和查詢成本
AWS Athena 根據查詢掃描的資料量收費。它掃描的資料越多,成本就越高。您需要按掃描的資料量(TB)付費。目前,掃描 1 TB 資料的成本約為5 美元,但這可能因區域而異。
例如,假設您查詢 500 GB 的資料集,並且 Athena 需要掃描整個資料集,則成本將為2.50 美元。
Athena 定價如何運作?
Athena 定價主要取決於以下三個因素:
掃描的資料
每次執行查詢時,Athena 都需要從 Amazon S3 掃描相關資料。總成本將基於查詢期間掃描了多少資料。
未壓縮資料
未壓縮資料佔用更多空間。這意味著當您對非結構化資料執行查詢時,Athena 將需要掃描更多資料。這會增加成本。
儲存在 S3 中的結果
執行查詢時,查詢結果將儲存到 S3。您需要支付標準的 S3 儲存成本。
最大程度地降低 AWS Athena 成本的策略
以下是一些您可以實施的策略,以最大程度地降低 AWS Athena 的成本:
- 使用壓縮來減小資料大小
- 對您的資料進行分割槽
- 僅選擇所需的列
- 最佳化檔案大小
- 使用快取限制查詢結果
- 監控查詢使用情況和成本
瞭解 Athena 成本的計算方式並應用策略來最大程度地降低這些成本對於有效的成本管理至關重要。