- Apache Tajo 教程
- Apache Tajo - 首頁
- Apache Tajo - 簡介
- Apache Tajo - 架構
- Apache Tajo - 安裝
- Apache Tajo - 配置設定
- Apache Tajo - Shell 命令
- Apache Tajo - 資料型別
- Apache Tajo - 運算子
- Apache Tajo - SQL 函式
- Apache Tajo - 數學函式
- Apache Tajo - 字串函式
- Apache Tajo - 日期時間函式
- Apache Tajo - JSON 函式
- Apache Tajo - 資料庫建立
- Apache Tajo - 表管理
- Apache Tajo - SQL 語句
- 聚合 & 視窗函式
- Apache Tajo - SQL 查詢
- Apache Tajo - 儲存外掛
- 與 HBase 整合
- Apache Tajo - 與 Hive 整合
- OpenStack Swift 整合
- Apache Tajo - JDBC 介面
- Apache Tajo - 自定義函式
- Apache Tajo 有用資源
- Apache Tajo - 快速指南
- Apache Tajo - 有用資源
- Apache Tajo - 討論
Apache Tajo - SQL 查詢
本章解釋以下重要的查詢。
- 謂詞
- 解釋
- 連線
讓我們繼續執行查詢。
謂詞
謂詞是一個用於評估真/假值和 UNKNOWN 的表示式。謂詞用於 WHERE 子句和 HAVING 子句的搜尋條件以及其他需要布林值的結構。
IN 謂詞
確定要測試的表示式的值是否與子查詢或列表中的任何值匹配。子查詢是一個普通的 SELECT 語句,它有一個包含一列和多行的結果集。此列或列表中的所有表示式必須與要測試的表示式的型別相同。
語法
IN::= <expression to test> [NOT] IN (<subquery>) | (<expression1>,...)
查詢
select id,name,address from mytable where id in(2,3,4);
結果
以上查詢將生成以下結果。
id, name, address ------------------------------- 2, Amit, 12 old street 3, Bob, 10 cross street 4, David, 15 express avenue
該查詢返回 **mytable** 中學生 ID 為 2、3 和 4 的記錄。
查詢
select id,name,address from mytable where id not in(2,3,4);
結果
以上查詢將生成以下結果。
id, name, address ------------------------------- 1, Adam, 23 new street 5, Esha, 20 garden street 6, Ganga, 25 north street 7, Jack, 2 park street 8, Leena, 24 south street 9, Mary, 5 west street 10, Peter, 16 park avenue
以上查詢返回 **mytable** 中學生 ID 不為 2、3 和 4 的記錄。
Like 謂詞
LIKE 謂詞將第一個表示式中指定的字串與第二個表示式中定義的模式進行比較,以計算字串值,該字串值被稱為要測試的值。
模式可以包含任何萬用字元組合,例如:
下劃線符號(_),可用於代替要測試值中的任何單個字元。
百分號(%),替換要測試值中零個或多個字元的任何字串。
語法
LIKE::= <expression for calculating the string value> [NOT] LIKE <expression for calculating the string value> [ESCAPE <symbol>]
查詢
select * from mytable where name like ‘A%';
結果
以上查詢將生成以下結果。
id, name, address, age, mark ------------------------------- 1, Adam, 23 new street, 12, 90 2, Amit, 12 old street, 13, 95
該查詢返回 mytable 中姓名以“A”開頭的學生的記錄。
查詢
select * from mytable where name like ‘_a%';
結果
以上查詢將生成以下結果。
id, name, address, age, mark ——————————————————————————————————————- 4, David, 15 express avenue, 12, 85 6, Ganga, 25 north street, 12, 55 7, Jack, 2 park street, 12, 60 9, Mary, 5 west street, 12, 75
該查詢返回 **mytable** 中姓名第二個字元為“a”的學生的記錄。
在搜尋條件中使用 NULL 值
現在讓我們瞭解如何在搜尋條件中使用 NULL 值。
語法
Predicate IS [NOT] NULL
查詢
select name from mytable where name is not null;
結果
以上查詢將生成以下結果。
name ------------------------------- Adam Amit Bob David Esha Ganga Jack Leena Mary Peter (10 rows, 0.076 sec, 163 B selected)
此處,結果為真,因此它返回表中的所有名稱。
查詢
現在讓我們檢查帶有 NULL 條件的查詢。
default> select name from mytable where name is null;
結果
以上查詢將生成以下結果。
name ------------------------------- (0 rows, 0.068 sec, 0 B selected)
解釋
**Explain** 用於獲取查詢執行計劃。它顯示了語句的邏輯和全域性計劃執行。
邏輯計劃查詢
explain select * from mytable;
explain
-------------------------------
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
結果
以上查詢將生成以下結果。

查詢結果顯示了給定表的邏輯計劃格式。邏輯計劃返回以下三個結果:
- 目標列表
- 輸出模式
- 輸入模式
全域性計劃查詢
explain global select * from mytable;
explain
-------------------------------
-------------------------------------------------------------------------------
Execution Block Graph (TERMINAL - eb_0000000000000_0000_000002)
-------------------------------------------------------------------------------
|-eb_0000000000000_0000_000002
|-eb_0000000000000_0000_000001
-------------------------------------------------------------------------------
Order of Execution
-------------------------------------------------------------------------------
1: eb_0000000000000_0000_000001
2: eb_0000000000000_0000_000002
-------------------------------------------------------------------------------
=======================================================
Block Id: eb_0000000000000_0000_000001 [ROOT]
=======================================================
SCAN(0) on default.mytable
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT),default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=======================================================
Block Id: eb_0000000000000_0000_000002 [TERMINAL]
=======================================================
(24 rows, 0.065 sec, 0 B selected)
結果
以上查詢將生成以下結果。
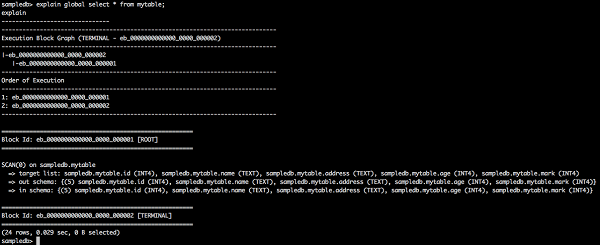
在這裡,全域性計劃顯示執行塊 ID、執行順序及其資訊。
連線
SQL 連線用於組合來自兩個或多個表的行。以下是不同型別的 SQL 連線:
- 內部連線
- { 左 | 右 | 全 } 外連線
- 交叉連線
- 自連線
- 自然連線
考慮以下兩個表以執行連線操作。
表 1 - 客戶
| ID | 姓名 | 地址 | 年齡 |
|---|---|---|---|
| 1 | 客戶 1 | 23 老街 | 21 |
| 2 | 客戶 2 | 12 新街 | 23 |
| 3 | 客戶 3 | 10 快車道 | 22 |
| 4 | 客戶 4 | 15 快車道 | 22 |
| 5 | 客戶 5 | 20 花園街 | 33 |
| 6 | 客戶 6 | 21 北街 | 25 |
表 2 - 客戶訂單
| ID | 訂單 ID | 員工 ID |
|---|---|---|
| 1 | 1 | 101 |
| 2 | 2 | 102 |
| 3 | 3 | 103 |
| 4 | 4 | 104 |
| 5 | 5 | 105 |
現在讓我們繼續在以上兩個表上執行 SQL 連線操作。
內部連線
內部連線在兩個表中的列之間存在匹配時,選擇兩個表中的所有行。
語法
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
查詢
default> select c.age,c1.empid from customers c inner join customer_order c1 on c.id = c1.id;
結果
以上查詢將生成以下結果。
age, empid ------------------------------- 21, 101 23, 102 22, 103 22, 104 33, 105
該查詢匹配兩個表中的五行。因此,它返回第一個表中匹配的行年齡。
左外連線
左外連線保留“左”表的所有行,無論“右”表中是否存在匹配的行。
查詢
select c.name,c1.empid from customers c left outer join customer_order c1 on c.id = c1.id;
結果
以上查詢將生成以下結果。
name, empid ------------------------------- customer1, 101 customer2, 102 customer3, 103 customer4, 104 customer5, 105 customer6,
在這裡,左外連線返回來自客戶(左)表的姓名列行,以及來自客戶訂單(右)表中匹配的員工 ID 列行。
右外連線
右外連線保留“右”表的所有行,無論“左”表中是否存在匹配的行。
查詢
select c.name,c1.empid from customers c right outer join customer_order c1 on c.id = c1.id;
結果
以上查詢將生成以下結果。
name, empid ------------------------------- customer1, 101 customer2, 102 customer3, 103 customer4, 104 customer5, 105
在這裡,右外連線返回來自客戶訂單(右)表的員工 ID 行,以及來自客戶表的匹配的姓名列行。
全外連線
全外連線保留來自左表和右表的所有行。
查詢
select * from customers c full outer join customer_order c1 on c.id = c1.id;
結果
以上查詢將生成以下結果。
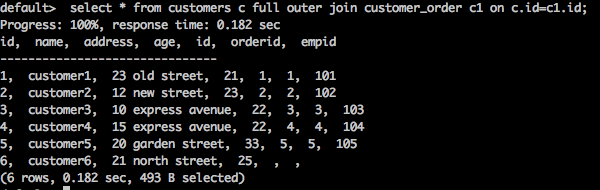
該查詢返回客戶表和客戶訂單表中所有匹配和不匹配的行。
交叉連線
這將返回來自兩個或多個連線表的記錄集的笛卡爾積。
語法
SELECT * FROM table1 CROSS JOIN table2;
查詢
select orderid,name,address from customers,customer_order;
結果
以上查詢將生成以下結果。
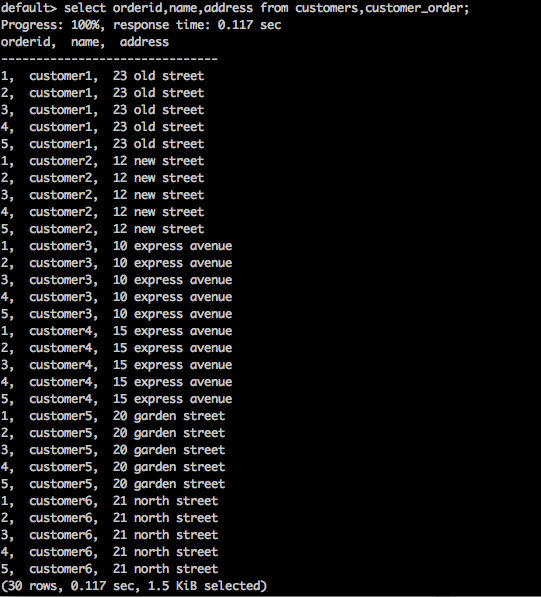
以上查詢返回表的笛卡爾積。
自然連線
自然連線不使用任何比較運算子。它不像笛卡爾積那樣連線。只有當兩個關係之間存在至少一個公共屬性時,我們才能執行自然連線。
語法
SELECT * FROM table1 NATURAL JOIN table2;
查詢
select * from customers natural join customer_order;
結果
以上查詢將生成以下結果。
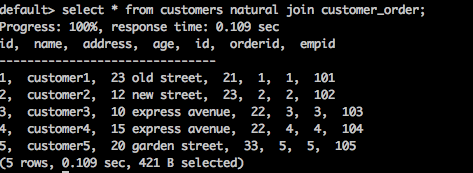
這裡,兩個表之間存在一個公共列 ID。使用該公共列,**自然連線**連線兩個表。
自連線
SQL 自連線用於將表連線到自身,就好像表是兩個表一樣,在 SQL 語句中臨時重新命名至少一個表。
語法
SELECT a.column_name, b.column_name... FROM table1 a, table1 b WHERE a.common_filed = b.common_field
查詢
default> select c.id,c1.name from customers c, customers c1 where c.id = c1.id;
結果
以上查詢將生成以下結果。
id, name ------------------------------- 1, customer1 2, customer2 3, customer3 4, customer4 5, customer5 6, customer6
該查詢將客戶表連線到自身。