- Apache Tajo 教程
- Apache Tajo - 首頁
- Apache Tajo - 簡介
- Apache Tajo - 架構
- Apache Tajo - 安裝
- Apache Tajo - 配置設定
- Apache Tajo - Shell 命令
- Apache Tajo - 資料型別
- Apache Tajo - 運算子
- Apache Tajo - SQL 函式
- Apache Tajo - 數學函式
- Apache Tajo - 字串函式
- Apache Tajo - 日期時間函式
- Apache Tajo - JSON 函式
- Apache Tajo - 資料庫建立
- Apache Tajo - 表管理
- Apache Tajo - SQL 語句
- 聚合與視窗函式
- Apache Tajo - SQL 查詢
- Apache Tajo - 儲存外掛
- 與 HBase 整合
- Apache Tajo - 與 Hive 整合
- OpenStack Swift 整合
- Apache Tajo - JDBC 介面
- Apache Tajo - 自定義函式
- Apache Tajo 有用資源
- Apache Tajo 快速指南
- Apache Tajo - 有用資源
- Apache Tajo - 討論
Apache Tajo 快速指南
Apache Tajo - 簡介
分散式資料倉庫系統
資料倉庫是一個關係型資料庫,其設計用於查詢和分析,而不是事務處理。它是一個面向主題的、整合的、隨時間變化的、非易失性的資料集合。這些資料幫助分析師在組織中做出明智的決策,但關係型資料的數量日益增加。
為了克服這些挑戰,分散式資料倉庫系統跨多個數據儲存庫共享資料,用於聯機分析處理 (OLAP)。每個資料倉庫可能屬於一個或多個組織。它執行負載平衡和可擴充套件性。元資料被複制和集中分發。
Apache Tajo 是一個分散式資料倉庫系統,它使用 Hadoop 分散式檔案系統 (HDFS) 作為儲存層,並擁有自己的查詢執行引擎,而不是 MapReduce 框架。
Hadoop 上 SQL 的概述
Hadoop 是一個開源框架,允許在分散式環境中儲存和處理大資料。它極其快速和強大。但是,Hadoop 的查詢能力有限,因此藉助 Hadoop 上的 SQL 可以使其效能得到進一步提升。這允許使用者透過簡單的 SQL 命令與 Hadoop 進行互動。
Hadoop 上 SQL 應用的一些示例包括 Hive、Impala、Drill、Presto、Spark、HAWQ 和 Apache Tajo。
什麼是 Apache Tajo
Apache Tajo 是一個關係型分散式資料處理框架。它旨在實現低延遲和可擴充套件的 ad-hoc 查詢分析。
Tajo 支援標準 SQL 和各種資料格式。大多數 Tajo 查詢無需任何修改即可執行。
Tajo 透過用於失敗任務的重啟機制和可擴充套件的查詢重寫引擎具有**容錯性**。
Tajo 執行必要的**ETL(提取、轉換和載入過程)**操作以彙總儲存在 HDFS 上的大型資料集。它是 Hive/Pig 的替代選擇。
最新版本的 Tajo 具有與 Java 程式和 Oracle 和 PostGreSQL 等第三方資料庫更好的連線性。
Apache Tajo 的特性
Apache Tajo 具有以下特性:
- 卓越的可擴充套件性和最佳化的效能
- 低延遲
- 使用者定義函式
- 行/列儲存處理框架。
- 與 HiveQL 和 Hive MetaStore 相容
- 簡單的資料流和易於維護。
Apache Tajo 的優勢
Apache Tajo 提供以下優勢:
- 易於使用
- 簡化的架構
- 基於成本的查詢最佳化
- 向量化查詢執行計劃
- 快速交付
- 簡單的 I/O 機制並支援各種型別的儲存。
- 容錯性
Apache Tajo 的用例
以下是 Apache Tajo 的一些用例:
資料倉庫和分析
韓國 SK 電訊公司針對 1.7 TB 的資料執行 Tajo,發現它可以比 Hive 或 Impala 更快地完成查詢。
資料發現
韓國音樂流媒體服務 Melon 使用 Tajo 進行分析處理。Tajo 執行 ETL(提取-轉換-載入過程)作業的速度比 Hive 快 1.5 到 10 倍。
日誌分析
韓國公司 Bluehole Studio 開發了 TERA——一款奇幻多人線上遊戲。該公司使用 Tajo 進行遊戲日誌分析,並查詢服務質量中斷的主要原因。
儲存和資料格式
Apache Tajo 支援以下資料格式:
- JSON
- 文字檔案 (CSV)
- Parquet
- Sequence File
- AVRO
- Protocol Buffer
- Apache Orc
Tajo 支援以下儲存格式:
- HDFS
- JDBC
- Amazon S3
- Apache HBase
- Elasticsearch
Apache Tajo - 架構
下圖描述了 Apache Tajo 的架構。
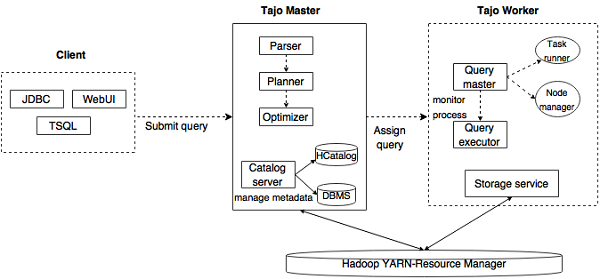
下表詳細描述了每個元件。
| 序號 | 元件與描述 |
|---|---|
| 1 | 客戶端 **客戶端**將 SQL 語句提交到 Tajo Master 以獲取結果。 |
| 2 | 主節點 (Master) 主節點是主守護程序。它負責查詢規劃,並且是工作節點的協調器。 |
| 3 | 目錄伺服器 維護表和索引描述。它嵌入在 Master 守護程序中。目錄伺服器使用 Apache Derby 作為儲存層,並透過 JDBC 客戶端連線。 |
| 4 | 工作節點 (Worker) 主節點將任務分配給工作節點。TajoWorker 處理資料。隨著 TajoWorker 數量的增加,處理能力也線性增加。 |
| 5 | 查詢主節點 (Query Master) Tajo 主節點將查詢分配給查詢主節點。查詢主節點負責控制分散式執行計劃。它啟動 TaskRunner 並將任務排程到 TaskRunner。查詢主節點的主要作用是監控正在執行的任務並將它們報告給主節點。 |
| 6 | 節點管理器 (Node Managers) 管理工作節點的資源。它決定將請求分配給哪個節點。 |
| 7 | 任務執行器 (TaskRunner) 充當本地查詢執行引擎。它用於執行和監控查詢過程。TaskRunner 一次處理一個任務。 它具有以下三個主要屬性:
|
| 8 | 查詢執行器 它用於執行查詢。 |
| 9 | 儲存服務 將底層資料儲存連線到 Tajo。 |
工作流程
Tajo 使用 Hadoop 分散式檔案系統 (HDFS) 作為儲存層,並擁有自己的查詢執行引擎,而不是 MapReduce 框架。Tajo 叢集由一個主節點和跨叢集節點的多個工作節點組成。
主節點主要負責查詢規劃和工作節點的協調。主節點將查詢劃分為小的任務並分配給工作節點。每個工作節點都有一個本地查詢引擎,用於執行物理運算子的有向無環圖。
此外,Tajo 可以比 MapReduce 更靈活地控制分散式資料流,並支援索引技術。
Tajo 的基於 Web 的介面具有以下功能:
- 查詢提交的查詢是如何規劃的選項
- 查詢查詢如何在節點之間分佈的選項
- 檢查叢集和節點狀態的選項
Apache Tajo - 安裝
要安裝 Apache Tajo,您的系統上必須安裝以下軟體:
- Hadoop 2.3 或更高版本
- Java 1.7 或更高版本
- Linux 或 Mac OS
現在讓我們繼續執行以下步驟來安裝 Tajo。
驗證 Java 安裝
希望您已經在機器上安裝了 Java 8 版本。現在,您只需透過驗證它來繼續。
要驗證,請使用以下命令:
$ java -version
如果 Java 已成功安裝在您的機器上,您可以看到已安裝 Java 的當前版本。如果 Java 未安裝,請按照以下步驟在您的機器上安裝 Java 8。
下載 JDK
訪問以下連結下載最新版本的 JDK,然後下載最新版本。
最新版本為**JDK 8u 92**,檔名為**“jdk-8u92-linux-x64.tar.gz”**。請將檔案下載到您的機器上。接下來,解壓檔案並將它們移動到特定目錄。現在,設定 Java 備選方案。最後,Java 已安裝在您的機器上。
驗證 Hadoop 安裝
您已在系統上安裝了**Hadoop**。現在,使用以下命令驗證它:
$ hadoop version
如果您的設定一切正常,那麼您可以看到 Hadoop 的版本。如果 Hadoop 未安裝,請訪問以下連結下載並安裝 Hadoop:https://www.apache.org
Apache Tajo 安裝
Apache Tajo 提供兩種執行模式——本地模式和完全分散式模式。驗證 Java 和 Hadoop 安裝後,請按照以下步驟在您的機器上安裝 Tajo 叢集。本地模式 Tajo 例項需要非常簡單的配置。
訪問以下連結下載最新版本的 Tajo:https://www.apache.org/dyn/closer.cgi/tajo
現在您可以從您的機器下載檔案**“tajo-0.11.3.tar.gz”**。
解壓 Tar 檔案
使用以下命令解壓 tar 檔案:
$ cd opt/ $ tar tajo-0.11.3.tar.gz $ cd tajo-0.11.3
設定環境變數
將以下更改新增到**“conf/tajo-env.sh”**檔案中
$ cd tajo-0.11.3 $ vi conf/tajo-env.sh # Hadoop home. Required export HADOOP_HOME = /Users/path/to/Hadoop/hadoop-2.6.2 # The java implementation to use. Required. export JAVA_HOME = /path/to/jdk1.8.0_92.jdk/
在這裡,您必須將 Hadoop 和 Java 路徑指定到**“tajo-env.sh”**檔案中。完成更改後,儲存檔案並退出終端。
啟動 Tajo 伺服器
要啟動 Tajo 伺服器,請執行以下命令:
$ bin/start-tajo.sh
您將收到類似於以下的響應:
Starting single TajoMaster starting master, logging to /Users/path/to/Tajo/tajo-0.11.3/bin/../ localhost: starting worker, logging to /Users/path/toe/Tajo/tajo-0.11.3/bin/../logs/ Tajo master web UI: http://local:26080 Tajo Client Service: local:26002
現在,輸入命令“jps”檢視正在執行的守護程序。
$ jps 1010 TajoWorker 1140 Jps 933 TajoMaster
啟動 Tajo Shell (Tsql)
要啟動 Tajo shell 客戶端,請使用以下命令:
$ bin/tsql
您將收到以下輸出:
welcome to _____ ___ _____ ___ /_ _/ _ |/_ _/ / / // /_| |_/ // / / /_//_/ /_/___/ \__/ 0.11.3 Try \? for help.
退出 Tajo Shell
執行以下命令以退出 Tsql:
default> \q bye!
這裡,預設指的是 Tajo 中的目錄。
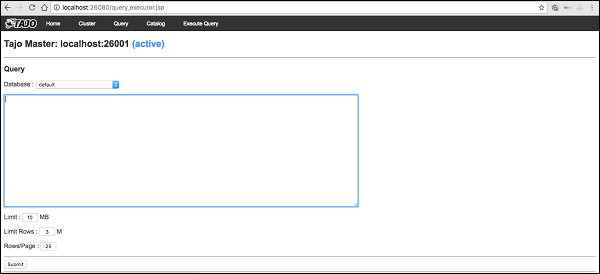
Web UI
輸入以下 URL 啟動 Tajo Web UI:https://:26080/
您現在將看到以下螢幕,它類似於 ExecuteQuery 選項。
停止 Tajo
要停止 Tajo 伺服器,請使用以下命令:
$ bin/stop-tajo.sh
您將收到以下響應:
localhost: stopping worker stopping master
Apache Tajo - 配置設定
Tajo 的配置基於 Hadoop 的配置系統。本章詳細解釋 Tajo 配置設定。
基本設定
Tajo 使用以下兩個配置檔案:
- catalog-site.xml - 目錄伺服器的配置。
- tajo-site.xml - 其他 Tajo 模組的配置。
分散式模式配置
分散式模式設定執行在 Hadoop 分散式檔案系統 (HDFS) 上。讓我們按照以下步驟配置 Tajo 分散式模式設定。
tajo-site.xml
此檔案位於 /path/to/tajo/conf 目錄下,充當其他 Tajo 模組的配置。要在分散式模式下訪問 Tajo,請對 “tajo-site.xml” 應用以下更改。
<property> <name>tajo.rootdir</name> <value>hdfs://hostname:port/tajo</value> </property> <property> <name>tajo.master.umbilical-rpc.address</name> <value>hostname:26001</value> </property> <property> <name>tajo.master.client-rpc.address</name> <value>hostname:26002</value> </property> <property> <name>tajo.catalog.client-rpc.address</name> <value>hostname:26005</value> </property>
主節點配置
Tajo 使用 HDFS 作為主要儲存型別。配置如下,應新增到 “tajo-site.xml” 中。
<property> <name>tajo.rootdir</name> <value>hdfs://namenode_hostname:port/path</value> </property>
目錄配置
如果要自定義目錄服務,請將 $path/to/Tajo/conf/catalogsite.xml.template 複製到 $path/to/Tajo/conf/catalog-site.xml 並根據需要新增以下任何配置。
例如,如果使用 “Hive 目錄儲存” 訪問 Tajo,則配置應如下所示:
<property> <name>tajo.catalog.store.class</name> <value>org.apache.tajo.catalog.store.HCatalogStore</value> </property>
如果需要儲存 MySQL 目錄,請應用以下更改:
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.MySQLStore</value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.id</name>
<value><mysql user name></value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.password</name>
<value><mysql user password></value>
</property>
<property>
<name>tajo.catalog.jdbc.uri</name>
<value>jdbc:mysql://<mysql host name>:<mysql port>/<database name for tajo>
?createDatabaseIfNotExist = true</value>
</property>
同樣,您可以註冊配置檔案中其他 Tajo 支援的目錄。
工作節點配置
預設情況下,TajoWorker 將臨時資料儲存在本地檔案系統中。它在“tajo-site.xml”檔案中定義如下:
<property> <name>tajo.worker.tmpdir.locations</name> <value>/disk1/tmpdir,/disk2/tmpdir,/disk3/tmpdir</value> </property>
要增加每個工作節點資源執行任務的容量,請選擇以下配置:
<property> <name>tajo.worker.resource.cpu-cores</name> <value>12</value> </property> <property> <name>tajo.task.resource.min.memory-mb</name> <value>2000</value> </property> <property> <name>tajo.worker.resource.disks</name> <value>4</value> </property>
要使 Tajo 工作節點在專用模式下執行,請選擇以下配置:
<property> <name>tajo.worker.resource.dedicated</name> <value>true</value> </property>
Apache Tajo - Shell 命令
本章將詳細瞭解 Tajo Shell 命令。
要執行 Tajo shell 命令,需要使用以下命令啟動 Tajo 伺服器和 Tajo shell:
啟動伺服器
$ bin/start-tajo.sh
啟動 Shell
$ bin/tsql
上述命令現在可以執行了。
元命令
現在讓我們討論一下 元命令。Tsql 元命令以反斜槓 (‘\’) 開頭。
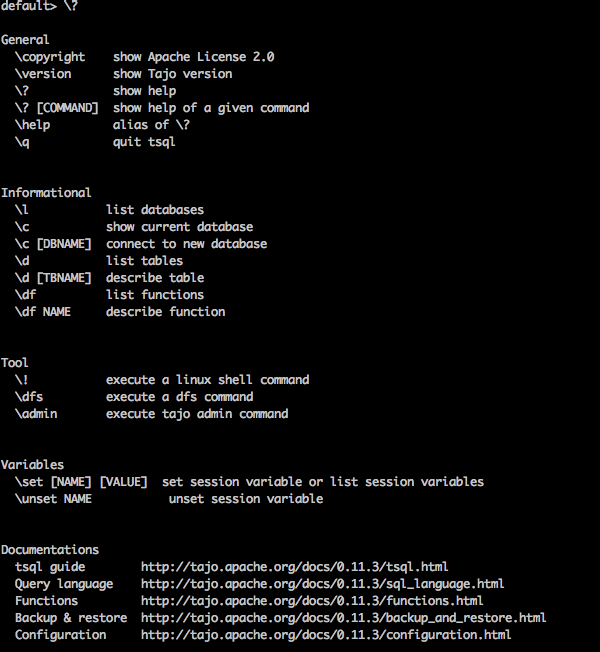
幫助命令
“\?” 命令用於顯示幫助選項。
查詢
default> \?
結果
上述 \? 命令列出了 Tajo 中所有基本使用方法選項。您將收到以下輸出:
列出資料庫
要列出 Tajo 中的所有資料庫,請使用以下命令:
查詢
default> \l
結果
您將收到以下輸出:
information_schema default
目前,我們還沒有建立任何資料庫,因此它顯示了兩個內建的 Tajo 資料庫。
當前資料庫
\c 選項用於顯示當前資料庫名稱。
查詢
default> \c
結果
您現在已以使用者“username”連線到資料庫“default”。
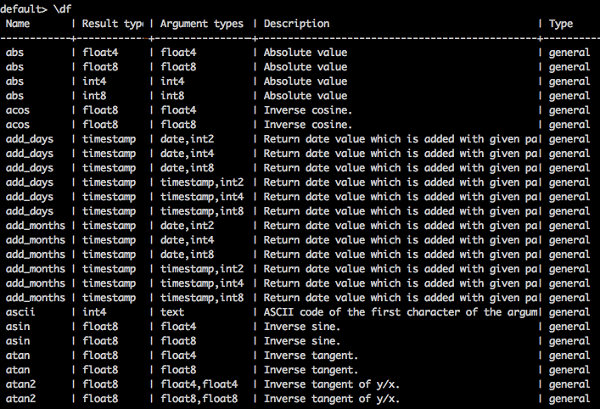
列出內建函式
要列出所有內建函式,請鍵入如下查詢:
查詢
default> \df
結果
您將收到以下輸出:
描述函式
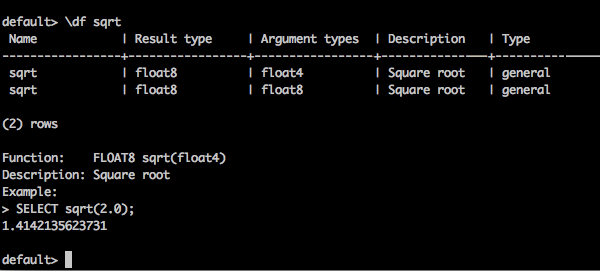
\df 函式名 - 此查詢返回給定函式的完整描述。
查詢
default> \df sqrt
結果
您將收到以下輸出:
退出終端
要退出終端,請鍵入以下查詢:
查詢
default> \q
結果
您將收到以下輸出:
bye!
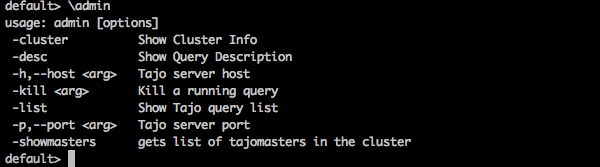
管理員命令
Tajo shell 提供 \admin 選項以列出所有管理員功能。
查詢
default> \admin
結果
您將收到以下輸出:
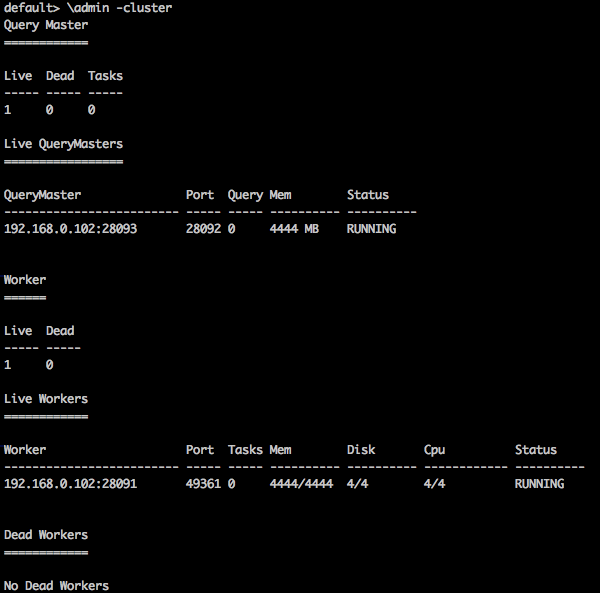
叢集資訊
要顯示 Tajo 中的叢集資訊,請使用以下查詢
查詢
default> \admin -cluster
結果
您將收到以下輸出:
顯示主節點
以下查詢顯示當前主節點資訊。
查詢
default> \admin -showmasters
結果
localhost
同樣,您可以嘗試其他管理員命令。
會話變數
Tajo 客戶端透過唯一的會話 ID 連線到主節點。會話在客戶端斷開連線或過期之前一直處於活動狀態。
以下命令用於列出所有會話變數。
查詢
default> \set
結果
'SESSION_LAST_ACCESS_TIME' = '1470206387146' 'CURRENT_DATABASE' = 'default' ‘USERNAME’ = 'user' 'SESSION_ID' = 'c60c9b20-dfba-404a-822f-182bc95d6c7c' 'TIMEZONE' = 'Asia/Kolkata' 'FETCH_ROWNUM' = '200' ‘COMPRESSED_RESULT_TRANSFER' = 'false'
\set key val 將使用值 val 設定名為 key 的會話變數。例如,
查詢
default> \set ‘current_database’='default'
結果
usage: \set [[NAME] VALUE]
在這裡,您可以在 \set 命令中分配鍵和值。如果需要恢復更改,請使用 \unset 命令。
Apache Tajo - 資料型別
要在 Tajo shell 中執行查詢,請開啟終端並移動到已安裝 Tajo 的目錄,然後鍵入以下命令:
$ bin/tsql
您現在將看到如下程式所示的響應:
default>
您現在可以執行您的查詢。或者,您可以透過 Web 控制檯應用程式執行您的查詢,訪問以下 URL:https://:26080/
基本資料型別
Apache Tajo 支援以下基本資料型別列表:
| 序號 | 資料型別 & 描述 |
|---|---|
| 1 | integer 用於儲存整數,佔用 4 個位元組。 |
| 2 | tinyint 微型整數,佔用 1 個位元組。 |
| 3 | smallint 用於儲存小型整數,佔用 2 個位元組。 |
| 4 | bigint 大範圍整數,佔用 8 個位元組。 |
| 5 | boolean 返回 true/false。 |
| 6 | real 用於儲存實數,大小為 4 個位元組。 |
| 7 | float 浮點精度值,佔用 4 或 8 個位元組儲存空間。 |
| 8 | double 雙精度值,儲存在 8 個位元組中。 |
| 9 | char[(n)] 字元值。 |
| 10 | varchar[(n)] 可變長度非 Unicode 資料。 |
| 11 | number 十進位制值。 |
| 12 | binary 二進位制值。 |
| 13 | date 日曆日期(年、月、日)。 示例 - DATE '2016-08-22' |
| 14 | time 一天中的時間(小時、分鐘、秒、毫秒),沒有時區。此型別的值在會話時區中進行解析和呈現。 |
| 15 | timezone 一天中的時間(小時、分鐘、秒、毫秒),帶有時區。此型別的值使用值中的時區進行呈現。 示例 - TIME '01:02:03.456 Asia/kolkata' |
| 16 | timestamp 包含日期和時間(沒有時區)的瞬間時間。 示例 - TIMESTAMP '2016-08-22 03:04:05.321' |
| 17 | text 可變長度 Unicode 文字。 |
Apache Tajo - 運算子
以下運算子用於在 Tajo 中執行所需的運算。
| 序號 | 運算子 & 描述 |
|---|---|
| 1 | 算術運算子
Presto 支援算術運算子,例如 +、-、*、/、%。 |
| 2 | 關係運算符
<, >, <=, >=, =, <> |
| 3 | 邏輯運算子
AND、OR、NOT |
| 4 | 字串運算子
‘||’ 運算子執行字串連線。 |
| 5 | 範圍運算子
範圍運算子用於測試特定範圍內的值。Tajo 支援 BETWEEN、IS NULL、IS NOT NULL 運算子。 |
Apache Tajo - SQL 函式
目前,您已經瞭解如何在 Tajo 上執行簡單的基本查詢。在接下來的幾章中,我們將討論以下 SQL 函式:
Apache Tajo - 數學函式
數學函式對數學公式進行運算。下表詳細描述了函式列表。
| 序號 | 函式 & 描述 |
|---|---|
| 1 | abs(x)
返回 x 的絕對值。 |
| 2 | cbrt(x)
返回 x 的立方根。 |
| 3 | ceil(x)
返回向上舍入到最接近整數的 x 值。 |
| 4 | floor(x)
返回向下舍入到最接近整數的 x 值。 |
| 5 | pi()
返回 pi 值。結果將作為雙精度值返回。 |
| 6 | radians(x)
將角度 x 從度轉換為弧度。 |
| 7 | degrees(x)
返回 x 的度數值。 |
| 8 | pow(x,p)
返回值 ‘p’ 的 x 次冪。 |
| 9 | div(x,y)
返回給定的兩個整數 x,y 的除法結果。 |
| 10 | exp(x)
返回尤拉數 e 的 x 次冪。 |
| 11 | sqrt(x)
返回 x 的平方根。 |
| 12 | sign(x)
返回 x 的符號函式,即:
|
| 13 | mod(n,m)
返回 n 除以 m 的模(餘數)。 |
| 14 | round(x)
返回 x 的四捨五入值。 |
| 15 | cos(x)
返回餘弦值(x)。 |
| 16 | asin(x)
返回反正弦值(x)。 |
| 17 | acos(x)
返回反餘弦值(x)。 |
| 18 | atan(x)
返回反正切值(x)。 |
| 19 | atan2(y,x)
返回反正切值(y/x)。 |
資料型別函式
下表列出了 Apache Tajo 中可用的資料型別函式。
| 序號 | 函式 & 描述 |
|---|---|
| 1 | to_bin(x)
返回整數的二進位制表示。 |
| 2 | to_char(int,text)
將整數轉換為字串。 |
| 3 | to_hex(x)
將 x 值轉換為十六進位制。 |
Apache Tajo - 字串函式
下表列出了 Tajo 中的字串函式。
| 序號 | 函式 & 描述 |
|---|---|
| 1 | concat(string1, ..., stringN)
連線給定的字串。 |
| 2 | length(string)
返回給定字串的長度。 |
| 3 | lower(string)
返回字串的小寫格式。 |
| 4 | upper(string)
返回給定字串的大寫格式。 |
| 5 | ascii(string text)
返回文字第一個字元的 ASCII 碼。 |
| 6 | bit_length(string text)
返回字串中的位數。 |
| 7 | char_length(string text)
返回字串中的字元數。 |
| 8 | octet_length(string text)
返回字串中的位元組數。 |
| 9 | digest(input text, method text)
計算字串的 Digest 雜湊值。這裡,第二個引數 method 指的是雜湊方法。 |
| 10 | initcap(string text)
將每個單詞的第一個字母轉換為大寫。 |
| 11 | md5(string text)
計算字串的 MD5 雜湊值。 |
| 12 | left(string text, int size)
返回字串中的前 n 個字元。 |
| 13 | right(string text, int size)
返回字串中的最後 n 個字元。 |
| 14 | locate(source text, target text, start_index)
返回指定子字串的位置。 |
| 15 | strposb(source text, target text)
返回指定子字串的二進位制位置。 |
| 16 | substr(source text, start index, length)
返回指定長度的子字串。 |
| 17 | trim(string text[, characters text])
刪除字串開頭/結尾/兩端 的字元(預設為空格)。 |
| 18 | split_part(string text, delimiter text, field int)
按分隔符分割字串,並返回給定的欄位(從 1 開始計數)。 |
| 19 | regexp_replace(string text, pattern text, replacement text)
替換與給定正則表示式模式匹配的子字串。 |
| 20 | reverse(string)
對字串執行反轉操作。 |
Apache Tajo - 日期時間函式
Apache Tajo 支援以下日期時間函式。
Apache Tajo - JSON 函式
JSON 函式列在下面的表格中:
| 序號 | 函式 & 描述 |
|---|---|
| 1 | json_extract_path_text(json text, json_path text)
根據指定的 json 路徑從 JSON 字串中提取 JSON 字串。 |
| 2 | json_array_get(json_array text, index int4)
返回 JSON 陣列中指定索引處的元素。 |
| 3 | json_array_contains(json_array text, value any)
確定給定值是否存在於 JSON 陣列中。 |
| 4 | json_array_length(json_array text)
返回 JSON 陣列的長度。 |
Apache Tajo - 資料庫建立
本節解釋 Tajo DDL 命令。Tajo 有一個名為 **default** 的內建資料庫。
建立資料庫語句
**建立資料庫** 用於在 Tajo 中建立資料庫。此語句的語法如下:
CREATE DATABASE [IF NOT EXISTS] <database_name>
查詢
default> default> create database if not exists test;
結果
上述查詢將生成以下結果。
OK
資料庫是 Tajo 中的名稱空間。一個數據庫可以包含多個具有唯一名稱的表。
顯示當前資料庫
要檢查當前資料庫名稱,請發出以下命令:
查詢
default> \c
結果
上述查詢將生成以下結果。
You are now connected to database "default" as user “user1". default>
連線到資料庫
目前,您已經建立了一個名為“test”的資料庫。以下語法用於連線“test”資料庫。
\c <database name>
查詢
default> \c test
結果
上述查詢將生成以下結果。
You are now connected to database "test" as user “user1”. test>
您現在可以看到提示符從 default 資料庫更改為 test 資料庫。
刪除資料庫
要刪除資料庫,請使用以下語法:
DROP DATABASE <database-name>
查詢
test> \c default You are now connected to database "default" as user “user1". default> drop database test;
結果
上述查詢將生成以下結果。
OK
Apache Tajo - 表管理
表是一個數據源的邏輯檢視。它包含邏輯模式、分割槽、URL 和各種屬性。Tajo 表可以是 HDFS 中的目錄、單個檔案、一個 HBase 表或一個 RDBMS 表。
Tajo 支援以下兩種型別的表:
- 外部表
- 內部表
外部表
建立外部表時需要 location 屬性。例如,如果您的資料已經存在為 Text/JSON 檔案或 HBase 表,您可以將其註冊為 Tajo 外部表。
以下查詢是外部表建立的示例。
create external table sample(col1 int,col2 text,col3 int) location ‘hdfs://path/to/table';
這裡,
**External 關鍵字** - 用於建立外部表。這有助於在指定位置建立表。
Sample 指的是表名。
**Location** - 它是 HDFS、Amazon S3、HBase 或本地檔案系統的目錄。要為目錄分配 location 屬性,請使用以下 URI 示例:
**HDFS** - hdfs://:port/path/to/table
**Amazon S3** - s3://bucket-name/table
**本地檔案系統** - file:///path/to/table
**Openstack Swift** - swift://bucket-name/table
表屬性
外部表具有以下屬性:
**TimeZone** - 使用者可以指定讀取或寫入表的時區。
**壓縮格式** - 用於使資料大小更緊湊。例如,text/json 檔案使用 **compression.codec** 屬性。
內部表
內部表也稱為 **託管表**。它是在稱為表空間的預定義物理位置建立的。
語法
create table table1(col1 int,col2 text);
預設情況下,Tajo 使用位於“conf/tajo-site.xml”中的“tajo.warehouse.directory”。要為表分配新位置,可以使用表空間配置。
表空間
表空間用於定義儲存系統中的位置。僅內部表支援它。您可以透過表空間名稱訪問表空間。每個表空間可以使用不同的儲存型別。如果您沒有指定表空間,則 Tajo 使用根目錄中的預設表空間。
表空間配置
您在 Tajo 中有 **“conf/tajo-site.xml.template”**。複製該檔案並將其重新命名為 **“storagesite.json”**。此檔案將充當表空間的配置。Tajo 資料格式使用以下配置:
HDFS 配置
$ vi conf/storage-site.json {
"spaces": {
"${tablespace_name}": {
"uri": “hdfs://:9000/path/to/Tajo"
}
}
}
HBase 配置
$ vi conf/storage-site.json {
"spaces": {
"${tablespace_name}": {
"uri": “hbase:zk://quorum1:port,quorum2:port/"
}
}
}
文字檔案配置
$ vi conf/storage-site.json {
"spaces": {
"${tablespace_name}": {
“uri”: “hdfs://:9000/path/to/Tajo”
}
}
}
表空間建立
Tajo 的內部表記錄只能從另一個表訪問。您可以使用表空間對其進行配置。
語法
CREATE TABLE [IF NOT EXISTS] <table_name> [(column_list)] [TABLESPACE tablespace_name] [using <storage_type> [with (<key> = <value>, ...)]] [AS <select_statement>]
這裡,
**IF NOT EXISTS** - 如果尚未建立相同的表,則可以避免錯誤。
**TABLESPACE** - 此子句用於分配表空間名稱。
**儲存型別** - Tajo 資料支援 text、JSON、HBase、Parquet、Sequencefile 和 ORC 等格式。
**AS select 語句** - 從另一個表中選擇記錄。
配置表空間
啟動您的 Hadoop 服務並開啟檔案 **“conf/storage-site.json”**,然後新增以下更改:
$ vi conf/storage-site.json {
"spaces": {
“space1”: {
"uri": “hdfs://:9000/path/to/Tajo"
}
}
}
在這裡,Tajo 將引用來自 HDFS 位置的資料,並且 **space1** 是表空間名稱。如果您沒有啟動 Hadoop 服務,則無法登錄檔空間。
查詢
default> create table table1(num1 int,num2 text,num3 float) tablespace space1;
上述查詢建立一個名為“table1”的表,而“space1”指的是表空間名稱。
資料格式
Tajo 支援資料格式。讓我們逐一詳細瞭解每種格式。
文字
字元分隔值純文字檔案表示由行和列組成的表格資料集。每一行都是一個純文字行。
建立表
default> create external table customer(id int,name text,address text,age int)
using text with('text.delimiter'=',') location ‘file:/Users/workspace/Tajo/customers.csv’;
這裡,**“customers.csv”** 檔案指的是位於 Tajo 安裝目錄中的逗號分隔值檔案。
要使用文字格式建立內部表,請使用以下查詢:
default> create table customer(id int,name text,address text,age int) using text;
在上述查詢中,您沒有分配任何表空間,因此它將採用 Tajo 的預設表空間。
屬性
文字檔案格式具有以下屬性:
**text.delimiter** - 這是一個分隔符字元。預設為 '|'。
**compression.codec** - 這是一個壓縮格式。預設情況下,它是停用的。您可以使用指定的演算法更改設定。
**timezone** - 用於讀取或寫入的表。
**text.error-tolerance.max-num** - 最大容錯級別數。
**text.skip.headerlines** - 每行跳過的標題行數。
**text.serde** - 這是序列化屬性。
JSON
Apache Tajo 支援 JSON 格式用於查詢資料。Tajo 將 JSON 物件視為 SQL 記錄。一個物件等於 Tajo 表中的一行。讓我們考慮如下所示的“array.json”:
$ hdfs dfs -cat /json/array.json {
"num1" : 10,
"num2" : "simple json array",
"num3" : 50.5
}
建立此檔案後,切換到 Tajo shell 並鍵入以下查詢以使用 JSON 格式建立表。
查詢
default> create external table sample (num1 int,num2 text,num3 float) using json location ‘json/array.json’;
請始終記住,檔案資料必須與表模式匹配。否則,您可以省略列名並使用 *,它不需要列列表。
要建立內部表,請使用以下查詢:
default> create table sample (num1 int,num2 text,num3 float) using json;
Parquet
Parquet 是一種列式儲存格式。Tajo 使用 Parquet 格式來實現輕鬆、快速和高效的訪問。
表建立
以下查詢是表建立的示例:
CREATE TABLE parquet (num1 int,num2 text,num3 float) USING PARQUET;
Parquet 檔案格式具有以下屬性:
**parquet.block.size** - 緩衝在記憶體中的行組的大小。
**parquet.page.size** - 頁面大小用於壓縮。
**parquet.compression** - 用於壓縮頁面的壓縮演算法。
**parquet.enable.dictionary** - 布林值用於啟用/停用字典編碼。
RCFile
RCFile 是記錄列式檔案。它由二進位制鍵/值對組成。
表建立
以下查詢是表建立的示例:
CREATE TABLE Record(num1 int,num2 text,num3 float) USING RCFILE;
RCFile 具有以下屬性:
**rcfile.serde** - 自定義反序列化類。
**compression.codec** - 壓縮演算法。
**rcfile.null** - NULL 字元。
SequenceFile
SequenceFile 是 Hadoop 中的一種基本檔案格式,它由鍵/值對組成。
表建立
以下查詢是表建立的示例:
CREATE TABLE seq(num1 int,num2 text,num3 float) USING sequencefile;
此序列檔案具有 Hive 相容性。這可以在 Hive 中編寫為:
CREATE TABLE table1 (id int, name string, score float, type string) STORED AS sequencefile;
ORC
ORC(Optimized Row Columnar)是來自 Hive 的列式儲存格式。
表建立
以下查詢是表建立的示例:
CREATE TABLE optimized(num1 int,num2 text,num3 float) USING ORC;
ORC 格式具有以下屬性:
**orc.max.merge.distance** - 讀取 ORC 檔案時,當距離較低時會合並。
**orc.stripe.size** - 這是每個條帶的大小。
**orc.buffer.size** - 預設值為 256KB。
**orc.rowindex.stride** - 這是 ORC 索引跨度(以行數表示)。
Apache Tajo - SQL 語句
在上一章中,您瞭解瞭如何在 Tajo 中建立表。本章解釋 Tajo 中的 SQL 語句。
建立表語句
在建立表之前,請在 Tajo 安裝目錄路徑中建立一個名為“students.csv”的文字檔案,如下所示:
students.csv
| Id | 姓名 | 地址 | 年齡 | 分數 |
|---|---|---|---|---|
| 1 | Adam | 23 New Street | 21 | 90 |
| 2 | Amit | 12 Old Street | 13 | 95 |
| 3 | Bob | 10 Cross Street | 12 | 80 |
| 4 | David | 15 Express Avenue | 12 | 85 |
| 5 | Esha | 20 Garden Street | 13 | 50 |
| 6 | Ganga | 25 North Street | 12 | 55 |
| 7 | Jack | 2 Park Street | 12 | 60 |
| 8 | Leena | 24 South Street | 12 | 70 |
| 9 | Mary | 5 West Street | 12 | 75 |
| 10 | Peter | 16 Park Avenue | 12 | 95 |
檔案建立後,移動到終端並逐一啟動 Tajo 伺服器和 shell。
建立資料庫
使用以下命令建立一個新資料庫:
查詢
default> create database sampledb; OK
連線到現在已建立的資料庫“sampledb”。
default> \c sampledb You are now connected to database "sampledb" as user “user1”.
然後,在“sampledb”中建立一個表,如下所示:
查詢
sampledb> create external table mytable(id int,name text,address text,age int,mark int)
using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;
結果
上述查詢將生成以下結果。
OK
這裡,建立了外部表。現在,您只需輸入檔案位置即可。如果您必須從 hdfs 分配表,請使用 hdfs 而不是 file。
接下來,**“students.csv”** 檔案包含逗號分隔的值。**text.delimiter** 欄位分配了 ','。
您現在已在“sampledb”中成功建立了“mytable”。
顯示錶
要在 Tajo 中顯示錶,請使用以下查詢。
查詢
sampledb> \d mytable sampledb> \d mytable
結果
上述查詢將生成以下結果。
table name: sampledb.mytable table uri: file:/Users/workspace/Tajo/students.csv store type: TEXT number of rows: unknown volume: 261 B Options: 'timezone' = 'Asia/Kolkata' 'text.null' = '\\N' 'text.delimiter' = ',' schema: id INT4 name TEXT address TEXT age INT4 mark INT4
列出表
要獲取表中的所有記錄,請鍵入以下查詢:
查詢
sampledb> select * from mytable;
結果
上述查詢將生成以下結果。

插入表語句
Tajo 使用以下語法將記錄插入表中。
語法
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;
Tajo 的 insert 語句類似於 SQL 的 **INSERT INTO SELECT** 語句。
查詢
讓我們建立一個表來覆蓋現有表的表資料。
sampledb> create table test(sno int,name text,addr text,age int,mark int); OK sampledb> \d
結果
上述查詢將生成以下結果。
mytable test
插入記錄
要將記錄插入“test”表,請鍵入以下查詢。
查詢
sampledb> insert overwrite into test select * from mytable;
結果
上述查詢將生成以下結果。
Progress: 100%, response time: 0.518 sec
這裡,“mytable”記錄覆蓋了“test”表。如果您不想建立“test”表,則可以直接分配物理路徑位置,如插入查詢的替代選項中所述。
提取記錄
使用以下查詢列出“test”表中的所有記錄:
查詢
sampledb> select * from test;
結果
上述查詢將生成以下結果。

此語句用於新增、刪除或修改現有表的列。
要重命名錶,請使用以下語法:
Alter table table1 RENAME TO table2;
查詢
sampledb> alter table test rename to students;
結果
上述查詢將生成以下結果。
OK
要檢查更改後的表名,請使用以下查詢。
sampledb> \d mytable students
現在表“test”已更改為“students”表。
新增列
要在“students”表中插入新列,請鍵入以下語法:
Alter table <table_name> ADD COLUMN <column_name> <data_type>
查詢
sampledb> alter table students add column grade text;
結果
上述查詢將生成以下結果。
OK
設定屬性
此屬性用於更改表的屬性。
查詢
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD', 'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ; OK
這裡,分配了壓縮型別和編解碼器屬性。
要更改文字分隔符屬性,請使用以下命令:
查詢
ALTER TABLE students SET PROPERTY ‘text.delimiter'=','; OK
結果
上述查詢將生成以下結果。
sampledb> \d students table name: sampledb.students table uri: file:/tmp/tajo-user1/warehouse/sampledb/students store type: TEXT number of rows: 10 volume: 228 B Options: 'compression.type' = 'RECORD' 'timezone' = 'Asia/Kolkata' 'text.null' = '\\N' 'compression.codec' = 'org.apache.hadoop.io.compress.SnappyCodec' 'text.delimiter' = ',' schema: id INT4 name TEXT addr TEXT age INT4 mark INT4 grade TEXT
上述結果顯示使用“SET”屬性更改了表的屬性。
選擇語句
SELECT 語句用於從資料庫中選擇資料。
Select 語句的語法如下:
SELECT [distinct [all]] * | <expression> [[AS] <alias>] [, ...] [FROM <table reference> [[AS] <table alias name>] [, ...]] [WHERE <condition>] [GROUP BY <expression> [, ...]] [HAVING <condition>] [ORDER BY <expression> [ASC|DESC] [NULLS (FIRST|LAST)] [, …]]
Where 子句
Where 子句用於從表中篩選記錄。
查詢
sampledb> select * from mytable where id > 5;
結果
上述查詢將生成以下結果。

查詢返回 id 大於 5 的學生的記錄。
查詢
sampledb> select * from mytable where name = ‘Peter’;
結果
上述查詢將生成以下結果。
Progress: 100%, response time: 0.117 sec id, name, address, age ------------------------------- 10, Peter, 16 park avenue , 12
結果僅篩選 Peter 的記錄。
Distinct 子句
表列可能包含重複值。“DISTINCT”關鍵字可以用來只返回不同的值。
語法
SELECT DISTINCT column1,column2 FROM table_name;
查詢
sampledb> select distinct age from mytable;
結果
上述查詢將生成以下結果。
Progress: 100%, response time: 0.216 sec age ------------------------------- 13 12
查詢返回來自**mytable**表中學生年齡的唯一值。
GROUP BY 子句
GROUP BY 子句與 SELECT 語句一起使用,用於將相同的資料整理成組。
語法
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2;
查詢
select age,sum(mark) as sumofmarks from mytable group by age;
結果
上述查詢將生成以下結果。
age, sumofmarks ------------------------------- 13, 145 12, 610
這裡,“mytable”列包含兩種年齡——12歲和13歲。現在,查詢按年齡對記錄進行分組,並計算對應年齡學生的成績總和。
HAVING 子句
HAVING 子句允許您指定條件,以過濾最終結果中顯示的組結果。WHERE 子句對選定的列施加條件,而 HAVING 子句對 GROUP BY 子句建立的組施加條件。
語法
SELECT column1, column2 FROM table1 GROUP BY column HAVING [ conditions ]
查詢
sampledb> select age from mytable group by age having sum(mark) > 200;
結果
上述查詢將生成以下結果。
age ------------------------------- 12
查詢按年齡對記錄分組,並在滿足條件sum(mark) > 200時返回年齡。
ORDER BY 子句
ORDER BY 子句用於根據一個或多個列對資料進行升序或降序排序。Tajo 資料庫預設按升序排序查詢結果。
語法
SELECT column-list FROM table_name [WHERE condition] [ORDER BY column1, column2, .. columnN] [ASC | DESC];
查詢
sampledb> select * from mytable where mark > 60 order by name desc;
結果
上述查詢將生成以下結果。

查詢按降序返回成績大於 60 的學生的姓名。
建立索引語句
CREATE INDEX 語句用於在表中建立索引。索引用於快速檢索資料。當前版本僅支援對儲存在 HDFS 上的純文字格式進行索引。
語法
CREATE INDEX [ name ] ON table_name ( { column_name | ( expression ) }
查詢
create index student_index on mytable(id);
結果
上述查詢將生成以下結果。
id ———————————————
要檢視為列分配的索引,請鍵入以下查詢。
default> \d mytable table name: default.mytable table uri: file:/Users/deiva/workspace/Tajo/students.csv store type: TEXT number of rows: unknown volume: 307 B Options: 'timezone' = 'Asia/Kolkata' 'text.null' = '\\N' 'text.delimiter' = ',' schema: id INT4 name TEXT address TEXT age INT4 mark INT4 Indexes: "student_index" TWO_LEVEL_BIN_TREE (id ASC NULLS LAST )
這裡,Tajo 預設使用 TWO_LEVEL_BIN_TREE 方法。
刪除表語句
刪除表語句用於從資料庫中刪除表。
語法
drop table table name;
查詢
sampledb> drop table mytable;
要檢查表是否已從表中刪除,請鍵入以下查詢。
sampledb> \d mytable;
結果
上述查詢將生成以下結果。
ERROR: relation 'mytable' does not exist
您也可以使用“\d”命令檢查查詢,列出可用的 Tajo 表。
聚合與視窗函式
本章詳細解釋了聚合函式和視窗函式。
聚合函式
聚合函式根據一組輸入值生成單個結果。下表詳細描述了聚合函式的列表。
| 序號 | 函式 & 描述 |
|---|---|
| 1 | AVG(exp)
計算資料來源中所有記錄的列的平均值。 |
| 2 | CORR(expression1, expression2)
返回一組數字對之間的相關係數。 |
| 3 | COUNT()
返回行數。 |
| 4 | MAX(expression)
返回所選列的最大值。 |
| 5 | MIN(expression)
返回所選列的最小值。 |
| 6 | SUM(expression)
返回給定列的總和。 |
| 7 | LAST_VALUE(expression)
返回給定列的最後一個值。 |
視窗函式
視窗函式作用於一組行,併為查詢中的每一行返回單個值。“視窗”一詞表示函式的行集。
在查詢中,視窗函式使用 OVER() 子句定義視窗。
**OVER()** 子句具有以下功能:
- 定義視窗分割槽以形成行組。(PARTITION BY 子句)
- 對分割槽內的行進行排序。(ORDER BY 子句)
下表詳細描述了視窗函式。
| 函式 | 返回型別 | 描述 |
|---|---|---|
| rank() | int | 返回當前行的排名,帶有間隙。 |
| row_num() | int | 返回當前行在其分割槽中的排名,從 1 開始計數。 |
| lead(value[, offset integer[, default any]]) | 與輸入型別相同 | 返回在分割槽內當前行之後偏移行數處計算的值。如果沒有這樣的行,則返回預設值。 |
| lag(value[, offset integer[, default any]]) | 與輸入型別相同 | 返回在分割槽內當前行之前偏移行數處計算的值。 |
| first_value(value) | 與輸入型別相同 | 返回輸入行的第一個值。 |
| last_value(value) | 與輸入型別相同 | 返回輸入行的最後一個值。 |
Apache Tajo - SQL 查詢
本章解釋了以下重要的查詢。
- 謂詞
- 解釋
- 連線
讓我們繼續執行查詢。
謂詞
謂詞是一個表示式,用於評估真/假值和 UNKNOWN。謂詞用於 WHERE 子句和 HAVING 子句以及其他需要布林值的結構的搜尋條件中。
IN 謂詞
確定要測試的表示式的值是否與子查詢或列表中的任何值匹配。子查詢是一個普通的 SELECT 語句,它有一個包含一列和多行的結果集。此列或列表中的所有表示式必須與要測試的表示式具有相同的資料型別。
語法
IN::= <expression to test> [NOT] IN (<subquery>) | (<expression1>,...)
查詢
select id,name,address from mytable where id in(2,3,4);
結果
上述查詢將生成以下結果。
id, name, address ------------------------------- 2, Amit, 12 old street 3, Bob, 10 cross street 4, David, 15 express avenue
查詢返回**mytable**表中學生 ID 為 2、3 和 4 的記錄。
查詢
select id,name,address from mytable where id not in(2,3,4);
結果
上述查詢將生成以下結果。
id, name, address ------------------------------- 1, Adam, 23 new street 5, Esha, 20 garden street 6, Ganga, 25 north street 7, Jack, 2 park street 8, Leena, 24 south street 9, Mary, 5 west street 10, Peter, 16 park avenue
上述查詢返回**mytable**表中studentId 不在 2、3 和 4 中的記錄。
LIKE 謂詞
LIKE 謂詞比較第一個表示式中指定的字串(作為要測試的值)與第二個表示式中定義的模式。
模式可以包含任何萬用字元組合,例如:
下劃線符號 (_) ,可以代替要測試值中的任何單個字元。
百分號 (%) ,可以代替要測試值中零個或多個字元的任何字串。
語法
LIKE::= <expression for calculating the string value> [NOT] LIKE <expression for calculating the string value> [ESCAPE <symbol>]
查詢
select * from mytable where name like ‘A%';
結果
上述查詢將生成以下結果。
id, name, address, age, mark ------------------------------- 1, Adam, 23 new street, 12, 90 2, Amit, 12 old street, 13, 95
查詢返回mytable表中姓名以“A”開頭的學生的記錄。
查詢
select * from mytable where name like ‘_a%';
結果
上述查詢將生成以下結果。
id, name, address, age, mark ——————————————————————————————————————- 4, David, 15 express avenue, 12, 85 6, Ganga, 25 north street, 12, 55 7, Jack, 2 park street, 12, 60 9, Mary, 5 west street, 12, 75
查詢返回**mytable**表中姓名第二個字元為“a”的學生的記錄。
在搜尋條件中使用 NULL 值
現在讓我們瞭解如何在搜尋條件中使用 NULL 值。
語法
Predicate IS [NOT] NULL
查詢
select name from mytable where name is not null;
結果
上述查詢將生成以下結果。
name ------------------------------- Adam Amit Bob David Esha Ganga Jack Leena Mary Peter (10 rows, 0.076 sec, 163 B selected)
這裡,結果為真,因此它返回表中的所有名稱。
查詢
現在讓我們檢查帶有 NULL 條件的查詢。
default> select name from mytable where name is null;
結果
上述查詢將生成以下結果。
name ------------------------------- (0 rows, 0.068 sec, 0 B selected)
解釋
**EXPLAIN** 用於獲取查詢執行計劃。它顯示語句的邏輯和全域性計劃執行。
邏輯計劃查詢
explain select * from mytable;
explain
-------------------------------
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
結果
上述查詢將生成以下結果。

查詢結果顯示給定表的邏輯計劃格式。邏輯計劃返回以下三個結果:
- 目標列表
- 輸出模式
- 輸入模式
全域性計劃查詢
explain global select * from mytable;
explain
-------------------------------
-------------------------------------------------------------------------------
Execution Block Graph (TERMINAL - eb_0000000000000_0000_000002)
-------------------------------------------------------------------------------
|-eb_0000000000000_0000_000002
|-eb_0000000000000_0000_000001
-------------------------------------------------------------------------------
Order of Execution
-------------------------------------------------------------------------------
1: eb_0000000000000_0000_000001
2: eb_0000000000000_0000_000002
-------------------------------------------------------------------------------
=======================================================
Block Id: eb_0000000000000_0000_000001 [ROOT]
=======================================================
SCAN(0) on default.mytable
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT),default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=======================================================
Block Id: eb_0000000000000_0000_000002 [TERMINAL]
=======================================================
(24 rows, 0.065 sec, 0 B selected)
結果
上述查詢將生成以下結果。
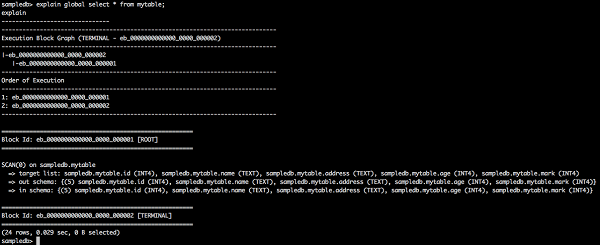
這裡,全域性計劃顯示執行塊 ID、執行順序及其資訊。
連線
SQL 連線用於組合來自兩個或多個表的行。以下是不同型別的 SQL 連線:
- 內連線
- { LEFT | RIGHT | FULL } OUTER JOIN
- 交叉連線
- 自連線
- 自然連線
考慮以下兩個表來執行連線操作。
表1 - 客戶
| Id | 姓名 | 地址 | 年齡 |
|---|---|---|---|
| 1 | 客戶1 | 23 老街 | 21 |
| 2 | 客戶2 | 12 新街 | 23 |
| 3 | 客戶3 | 10 快車大道 | 22 |
| 4 | 客戶4 | 15 Express Avenue | 22 |
| 5 | 客戶5 | 20 Garden Street | 33 |
| 6 | 客戶6 | 21 北街 | 25 |
表2 - 客戶訂單
| Id | 訂單 ID | 員工 ID |
|---|---|---|
| 1 | 1 | 101 |
| 2 | 2 | 102 |
| 3 | 3 | 103 |
| 4 | 4 | 104 |
| 5 | 5 | 105 |
讓我們繼續在上述兩個表上執行 SQL 連線操作。
內連線
內連線在兩個表中的列之間匹配時,選擇兩個表中的所有行。
語法
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
查詢
default> select c.age,c1.empid from customers c inner join customer_order c1 on c.id = c1.id;
結果
上述查詢將生成以下結果。
age, empid ------------------------------- 21, 101 23, 102 22, 103 22, 104 33, 105
查詢匹配來自兩個表的五行。因此,它返回來自第一個表匹配行的年齡。
左外連線
左外連線保留“左”表的所有行,無論是否有與“右”表匹配的行。
查詢
select c.name,c1.empid from customers c left outer join customer_order c1 on c.id = c1.id;
結果
上述查詢將生成以下結果。
name, empid ------------------------------- customer1, 101 customer2, 102 customer3, 103 customer4, 104 customer5, 105 customer6,
這裡,左外連線返回來自客戶(左)表的 name 列行和來自客戶訂單(右)表匹配的 empid 列行。
右外連線
右外連線保留“右”表的所有行,無論是否有與“左”表匹配的行。
查詢
select c.name,c1.empid from customers c right outer join customer_order c1 on c.id = c1.id;
結果
上述查詢將生成以下結果。
name, empid ------------------------------- customer1, 101 customer2, 102 customer3, 103 customer4, 104 customer5, 105
這裡,右外連線返回來自客戶訂單(右)表的 empid 行和來自客戶表的 name 列匹配行。
全外連線
全外連線保留左表和右表的所有行。
查詢
select * from customers c full outer join customer_order c1 on c.id = c1.id;
結果
上述查詢將生成以下結果。
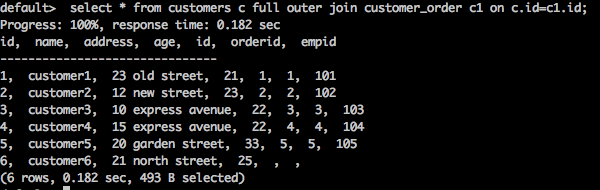
查詢返回客戶表和客戶訂單表中的所有匹配行和不匹配行。
交叉連線
這返回來自兩個或多個連線表的記錄集的笛卡爾積。
語法
SELECT * FROM table1 CROSS JOIN table2;
查詢
select orderid,name,address from customers,customer_order;
結果
上述查詢將生成以下結果。
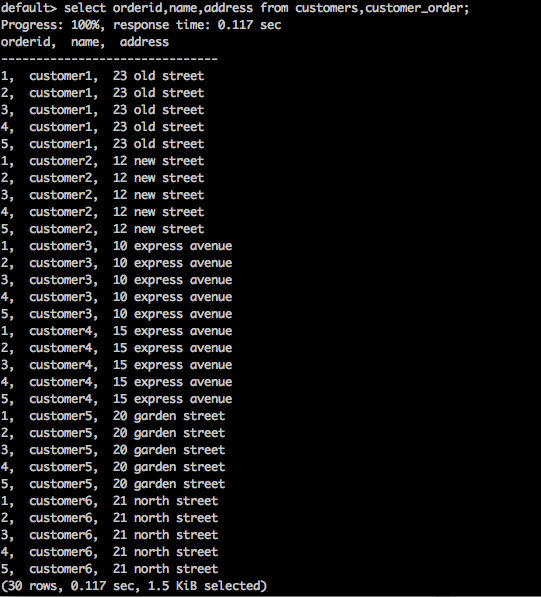
上述查詢返回表的笛卡爾積。
自然連線
自然連線不使用任何比較運算子。它不會像笛卡爾積那樣進行連線。只有當兩個關係之間存在至少一個公共屬性時,我們才能執行自然連線。
語法
SELECT * FROM table1 NATURAL JOIN table2;
查詢
select * from customers natural join customer_order;
結果
上述查詢將生成以下結果。
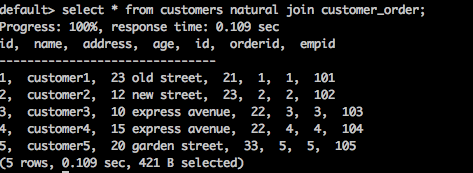
這裡,兩個表之間存在一個公共列 id。使用該公共列,**自然連線**連線這兩個表。
自連線
SQL 自連線用於將表本身連線起來,就好像表是兩個表一樣,在 SQL 語句中臨時重新命名至少一個表。
語法
SELECT a.column_name, b.column_name... FROM table1 a, table1 b WHERE a.common_filed = b.common_field
查詢
default> select c.id,c1.name from customers c, customers c1 where c.id = c1.id;
結果
上述查詢將生成以下結果。
id, name ------------------------------- 1, customer1 2, customer2 3, customer3 4, customer4 5, customer5 6, customer6
查詢將客戶表本身連線起來。
Apache Tajo - 儲存外掛
Tajo 支援各種儲存格式。要註冊儲存外掛配置,應將更改新增到配置檔案“storage-site.json”。
storage-site.json
結構定義如下:
{
"storages": {
“storage plugin name“: {
"handler": "${class name}”, "default-format": “plugin name"
}
}
}
每個儲存例項都由 URI 標識。
PostgreSQL 儲存處理程式
Tajo 支援 PostgreSQL 儲存處理程式。它使使用者查詢能夠訪問 PostgreSQL 中的資料庫物件。它是 Tajo 中的預設儲存處理程式,因此您可以輕鬆配置它。
配置
{
"spaces": {
"postgre": {
"uri": "jdbc:postgresql://hostname:port/database1"
"configs": {
"mapped_database": “sampledb”
"connection_properties": {
"user":“tajo", "password": "pwd"
}
}
}
}
}
這裡,**“database1”** 指的是對映到 Tajo 中資料庫 **“sampledb”** 的 **postgreSQL** 資料庫。
Apache Tajo - 與 HBase 整合
Apache Tajo 支援 HBase 整合。這使我們能夠在 Tajo 中訪問 HBase 表。HBase 是一個構建在 Hadoop 檔案系統之上的分散式列式資料庫。它是 Hadoop 生態系統的一部分,它為 Hadoop 檔案系統中的資料提供隨機的即時讀/寫訪問。配置 HBase 整合需要執行以下步驟。
設定環境變數
將以下更改新增到“conf/tajo-env.sh”檔案。
$ vi conf/tajo-env.sh # HBase home directory. It is opitional but is required mandatorily to use HBase. # export HBASE_HOME = path/to/HBase
包含HBase路徑後,Tajo會將HBase庫檔案設定到classpath。
建立外部表
使用以下語法建立外部表:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] <table_name> [(<column_name> <data_type>, ... )]
USING hbase WITH ('table' = '<hbase_table_name>'
, 'columns' = ':key,<column_family_name>:<qualifier_name>, ...'
, 'hbase.zookeeper.quorum' = '<zookeeper_address>'
, 'hbase.zookeeper.property.clientPort' = '<zookeeper_client_port>')
[LOCATION 'hbase:zk://<hostname>:<port>/'] ;
要訪問HBase表,必須配置表空間位置。
這裡,
表 (Table) − 設定HBase原始表名。如果要建立外部表,則該表必須存在於HBase中。
列 (Columns) − Key 指的是HBase行鍵。列的個數必須等於Tajo表列的個數。
hbase.zookeeper.quorum − 設定ZooKeeper叢集地址。
hbase.zookeeper.property.clientPort − 設定ZooKeeper客戶端埠。
查詢
CREATE EXTERNAL TABLE students (rowkey text,id int,name text)
USING hbase WITH ('table' = 'students', 'columns' = ':key,info:id,content:name')
LOCATION 'hbase:zk://<hostname>:<port>/';
此處,“位置路徑”欄位設定ZooKeeper客戶端埠ID。如果未設定埠,Tajo將引用hbase-site.xml檔案的屬性。
在HBase中建立表
可以使用“hbase shell”命令啟動HBase互動式shell,如下所示。
查詢
/bin/hbase shell
結果
上述查詢將生成以下結果。
hbase(main):001:0>
查詢HBase的步驟
要查詢HBase,應完成以下步驟:
步驟1 − 將以下命令管道傳輸到HBase shell以建立“tutorial”表。
查詢
hbase(main):001:0> create ‘students’,{NAME => ’info’},{NAME => ’content’}
put 'students', ‘row-01', 'content:name', 'Adam'
put 'students', ‘row-01', 'info:id', '001'
put 'students', ‘row-02', 'content:name', 'Amit'
put 'students', ‘row-02', 'info:id', '002'
put 'students', ‘row-03', 'content:name', 'Bob'
put 'students', ‘row-03', 'info:id', ‘003'
步驟2 − 現在,在hbase shell中發出以下命令以將資料載入到表中。
main):001:0> cat ../hbase/hbase-students.txt | bin/hbase shell
步驟3 − 現在,返回到Tajo shell並執行以下命令以查看錶的元資料:
default> \d students; table name: default.students table path: store type: HBASE number of rows: unknown volume: 0 B Options: 'columns' = ':key,info:id,content:name' 'table' = 'students' schema: rowkey TEXT id INT4 name TEXT
步驟4 − 要從表中獲取結果,請使用以下查詢:
查詢
default> select * from students
結果
以上查詢將獲取以下結果:
rowkey, id, name ------------------------------- row-01, 001, Adam row-02, 002, Amit row-03 003, Bob
Apache Tajo - 與 Hive 整合
Tajo支援HiveCatalogStore來與Apache Hive整合。此整合允許Tajo訪問Apache Hive中的表。
設定環境變數
將以下更改新增到“conf/tajo-env.sh”檔案。
$ vi conf/tajo-env.sh export HIVE_HOME = /path/to/hive
包含Hive路徑後,Tajo會將Hive庫檔案設定到classpath。
目錄配置
在“conf/catalog-site.xml”檔案中新增以下更改。
$ vi conf/catalog-site.xml <property> <name>tajo.catalog.store.class</name> <value>org.apache.tajo.catalog.store.HiveCatalogStore</value> </property>
配置HiveCatalogStore後,就可以在Tajo中訪問Hive的表了。
Apache Tajo - OpenStack Swift整合
Swift是一個分散式且一致的物件/Blob儲存。Swift提供雲端儲存軟體,以便您可以使用簡單的API儲存和檢索大量資料。Tajo支援Swift整合。
以下是Swift整合的先決條件:
- Swift
- Hadoop
core-site.xml
在Hadoop的“core-site.xml”檔案中新增以下更改:
<property> <name>fs.swift.impl</name> <value>org.apache.hadoop.fs.swift.snative.SwiftNativeFileSystem</value> <description>File system implementation for Swift</description> </property> <property> <name>fs.swift.blocksize</name> <value>131072</value> <description>Split size in KB</description> </property>
這將用於Hadoop訪問Swift物件。完成所有更改後,移動到Tajo目錄以設定Swift環境變數。
conf/tajo-env.sh
開啟Tajo配置檔案並新增設定環境變數,如下所示:
$ vi conf/tajo-env.h export TAJO_CLASSPATH = $HADOOP_HOME/share/hadoop/tools/lib/hadoop-openstack-x.x.x.jar
現在,Tajo將能夠使用Swift查詢資料。
建立表
讓我們建立一個外部表來訪問Tajo中的Swift物件,如下所示:
default> create external table swift(num1 int, num2 text, num3 float)
using text with ('text.delimiter' = '|') location 'swift://bucket-name/table1';
建立表後,您可以執行SQL查詢。
Apache Tajo - JDBC 介面
Apache Tajo提供JDBC介面來連線和執行查詢。我們可以使用相同的JDBC介面從基於Java的應用程式連線Tajo。在本節中,讓我們瞭解如何使用JDBC介面在本示例Java應用程式中連線Tajo並執行命令。
下載JDBC驅動程式
訪問以下連結下載JDBC驅動程式:http://apache.org/dyn/closer.cgi/tajo/tajo-0.11.3/tajo-jdbc-0.11.3.jar。
現在,“tajo-jdbc-0.11.3.jar”檔案已下載到您的計算機上。
設定類路徑
要在程式中使用JDBC驅動程式,請按如下方式設定類路徑:
CLASSPATH = path/to/tajo-jdbc-0.11.3.jar:$CLASSPATH
連線到Tajo
Apache Tajo提供JDBC驅動程式作為一個jar檔案,它位於@ /path/to/tajo/share/jdbc-dist/tajo-jdbc-0.11.3.jar。
連線Apache Tajo的連線字串格式如下:
jdbc:tajo://host/ jdbc:tajo://host/database jdbc:tajo://host:port/ jdbc:tajo://host:port/database
這裡,
host − TajoMaster的主機名。
port − 伺服器偵聽的埠號。預設埠號為26002。
database − 資料庫名稱。預設資料庫名稱為default。
Java應用程式
讓我們瞭解一下Java應用程式。
編碼
import java.sql.*;
import org.apache.tajo.jdbc.TajoDriver;
public class TajoJdbcSample {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
try {
Class.forName("org.apache.tajo.jdbc.TajoDriver");
connection = DriverManager.getConnection(“jdbc:tajo:///default");
statement = connection.createStatement();
String sql;
sql = "select * from mytable”;
// fetch records from mytable.
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.print("ID: " + id + ";\nName: " + name + "\n");
}
resultSet.close();
statement.close();
connection.close();
}catch(SQLException sqlException){
sqlException.printStackTrace();
}catch(Exception exception){
exception.printStackTrace();
}
}
}
可以使用以下命令編譯和執行應用程式。
編譯
javac -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSample.java
執行
java -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSample
結果
以上命令將生成以下結果:
ID: 1; Name: Adam ID: 2; Name: Amit ID: 3; Name: Bob ID: 4; Name: David ID: 5; Name: Esha ID: 6; Name: Ganga ID: 7; Name: Jack ID: 8; Name: Leena ID: 9; Name: Mary ID: 10; Name: Peter
Apache Tajo - 自定義函式
Apache Tajo支援自定義/使用者定義函式 (UDF)。自定義函式可以在Python中建立。
自定義函式只是帶有裝飾器“@output_type(<tajo sql datatype>)”的普通Python函式,如下所示:
@ouput_type(“integer”) def sum_py(a, b): return a + b;
可以透過在“tajosite.xml”中新增以下配置來註冊包含UDF的Python指令碼。
<property> <name>tajo.function.python.code-dir</name> <value>file:///path/to/script1.py,file:///path/to/script2.py</value> </property>
註冊指令碼後,重新啟動叢集,UDF將在SQL查詢中可用,如下所示:
select sum_py(10, 10) as pyfn;
Apache Tajo也支援使用者定義的聚合函式,但不支援使用者定義的視窗函式。