- Apache Tajo 教程
- Apache Tajo - 首頁
- Apache Tajo - 簡介
- Apache Tajo - 架構
- Apache Tajo - 安裝
- Apache Tajo - 配置設定
- Apache Tajo - Shell 命令
- Apache Tajo - 資料型別
- Apache Tajo - 運算子
- Apache Tajo - SQL 函式
- Apache Tajo - 數學函式
- Apache Tajo - 字串函式
- Apache Tajo - 日期時間函式
- Apache Tajo - JSON 函式
- Apache Tajo - 資料庫建立
- Apache Tajo - 表管理
- Apache Tajo - SQL 語句
- 聚合與視窗函式
- Apache Tajo - SQL 查詢
- Apache Tajo - 儲存外掛
- 與 HBase 整合
- Apache Tajo - 與 Hive 整合
- OpenStack Swift 整合
- Apache Tajo - JDBC 介面
- Apache Tajo - 自定義函式
- Apache Tajo 有用資源
- Apache Tajo - 快速指南
- Apache Tajo - 有用資源
- Apache Tajo - 討論
Apache Tajo - 架構
下圖描述了 Apache Tajo 的架構。
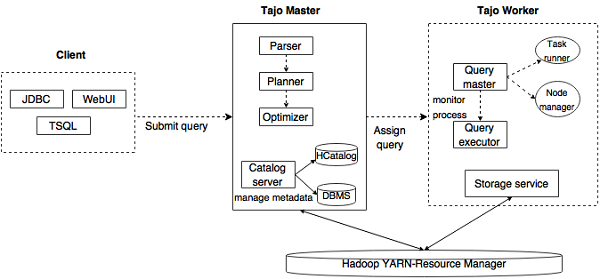
下表詳細描述了每個元件。
| 序號 | 元件及描述 |
|---|---|
| 1 | 客戶端 客戶端向 Tajo Master 提交 SQL 語句以獲取結果。 |
| 2 | Master Master 是主守護程序。它負責查詢規劃,並且是 worker 的協調器。 |
| 3 | 元資料伺服器 維護表和索引描述。它嵌入在 Master 守護程序中。元資料伺服器使用 Apache Derby 作為儲存層,並透過 JDBC 客戶端連線。 |
| 4 | Worker Master 節點將任務分配給 worker 節點。TajoWorker 處理資料。隨著 TajoWorker 數量的增加,處理能力也線性增加。 |
| 5 | 查詢 Master Tajo master 將查詢分配給 Query Master。Query Master 負責控制分散式執行計劃。它啟動 TaskRunner 並將任務排程到 TaskRunner。Query Master 的主要作用是監控正在執行的任務並將其報告給 Master 節點。 |
| 6 | 節點管理器 管理 worker 節點的資源。它決定如何將請求分配給節點。 |
| 7 | TaskRunner 充當本地查詢執行引擎。它用於執行和監控查詢程序。TaskRunner 一次處理一個任務。 它具有以下三個主要屬性:
|
| 8 | 查詢執行器 它用於執行查詢。 |
| 9 | 儲存服務 將底層資料儲存連線到 Tajo。 |
工作流程
Tajo 使用 Hadoop 分散式檔案系統 (HDFS) 作為儲存層,並擁有自己的查詢執行引擎,而不是 MapReduce 框架。Tajo 叢集由一個 master 節點和跨叢集節點的多個 worker 組成。
master 主要負責查詢規劃和 worker 的協調。master 將查詢劃分為小的任務並分配給 worker。每個 worker 都有一個本地查詢引擎,該引擎執行物理運算子的有向無環圖。
此外,Tajo 可以比 MapReduce 更靈活地控制分散式資料流,並支援索引技術。
Tajo 的基於 Web 的介面具有以下功能:
- 查詢提交的查詢如何規劃的選項
- 查詢查詢如何在節點之間分佈的選項
- 檢查叢集和節點狀態的選項