- Apache Spark 教程
- Apache Spark - 首頁
- Apache Spark - 簡介
- Apache Spark - RDD
- Apache Spark - 安裝
- Apache Spark - 核心程式設計
- Apache Spark - 部署
- 高階 Spark 程式設計
- Apache Spark 有用資源
- Apache Spark - 快速指南
- Apache Spark - 有用資源
- Apache Spark - 討論
Apache Spark - RDD
彈性分散式資料集
彈性分散式資料集 (RDD) 是 Spark 的一種基本資料結構。它是一個不可變的分散式物件集合。RDD 中的每個資料集都劃分為邏輯分割槽,這些分割槽可以在叢集的不同節點上計算。RDD 可以包含任何型別的 Python、Java 或 Scala 物件,包括使用者定義的類。
正式地講,RDD 是一個只讀的、分割槽的記錄集合。RDD 可以透過對穩定儲存上的資料或其他 RDD 進行確定性操作來建立。RDD 是一個容錯的元素集合,可以並行操作。
建立 RDD 有兩種方法:**並行化**驅動程式中的現有集合,或**引用**外部儲存系統中的資料集,例如共享檔案系統、HDFS、HBase 或任何提供 Hadoop 輸入格式的資料來源。
Spark 利用 RDD 的概念來實現更快、更高效的 MapReduce 操作。讓我們首先討論 MapReduce 操作是如何進行的以及為什麼它們效率不高。
MapReduce 中的資料共享速度慢
MapReduce 被廣泛應用於使用叢集上的並行分散式演算法處理和生成大型資料集。它允許使用者使用一組高階運算子編寫平行計算,而無需擔心工作分配和容錯。
不幸的是,在大多數當前框架中,在計算之間(例如,兩個 MapReduce 作業之間)重用資料的唯一方法是將其寫入外部穩定儲存系統(例如,HDFS)。雖然此框架提供了許多用於訪問叢集計算資源的抽象,但使用者仍然想要更多。
**迭代**和**互動式**應用程式都需要在並行作業之間進行更快的資料共享。由於**複製、序列化**和**磁碟 I/O**,MapReduce 中的資料共享速度很慢。關於儲存系統,大多數 Hadoop 應用程式花費超過 90% 的時間進行 HDFS 讀寫操作。
MapReduce 上的迭代操作
在多階段應用程式中跨多個計算重用中間結果。下圖說明了當前框架在 MapReduce 上執行迭代操作時的工作方式。由於資料複製、磁碟 I/O 和序列化,這會產生大量的開銷,從而使系統變慢。
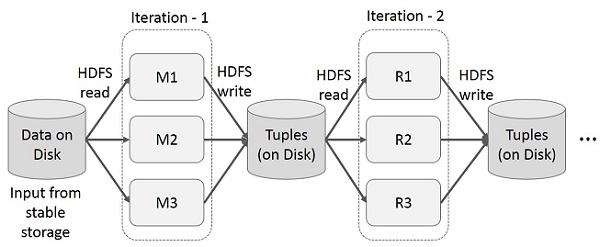
MapReduce 上的互動式操作
使用者對同一資料集的子集執行臨時查詢。每個查詢都會對穩定儲存執行磁碟 I/O,這可能會佔據應用程式執行時間的很大一部分。
下圖說明了當前框架在 MapReduce 上執行互動式查詢時的工作方式。
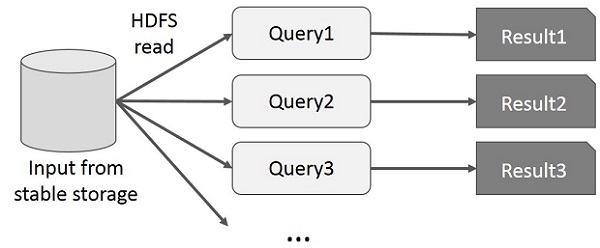
使用 Spark RDD 進行資料共享
由於**複製、序列化**和**磁碟 I/O**,MapReduce 中的資料共享速度很慢。大多數 Hadoop 應用程式花費超過 90% 的時間進行 HDFS 讀寫操作。
認識到這個問題,研究人員開發了一個專門的框架,稱為 Apache Spark。Spark 的核心思想是**彈性分散式資料集 (RDD)**;它支援記憶體中處理計算。這意味著,它將記憶體狀態作為作業間的一個物件儲存,並且該物件可以在這些作業之間共享。記憶體中的資料共享速度比網路和磁碟快 10 到 100 倍。
現在讓我們嘗試找出 Spark RDD 中迭代和互動式操作是如何進行的。
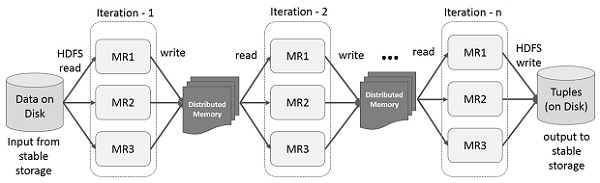
Spark RDD 上的迭代操作
下圖顯示了 Spark RDD 上的迭代操作。它將中間結果儲存在分散式記憶體中,而不是穩定儲存(磁碟),從而使系統更快。
**注意** - 如果分散式記憶體 (RAM) 不足以儲存中間結果(作業狀態),則會將這些結果儲存在磁碟上。
Spark RDD 上的互動式操作
此圖顯示了 Spark RDD 上的互動式操作。如果對同一組資料重複執行不同的查詢,則可以將此特定資料儲存在記憶體中以獲得更好的執行時間。
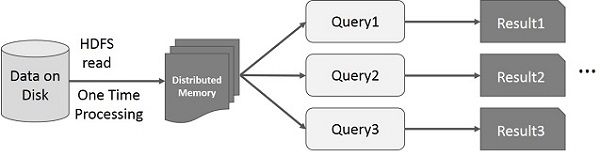
預設情況下,每次在轉換後的 RDD 上執行操作時,可能會重新計算每個轉換後的 RDD。但是,您也可以將 RDD **持久化**到記憶體中,在這種情況下,Spark 會將元素保留在叢集中,以便下次查詢時可以更快地訪問。還支援將 RDD 持久化到磁碟上或複製到多個節點上。