- Apache Spark 教程
- Apache Spark - 首頁
- Apache Spark 簡介
- Apache Spark - RDD
- Apache Spark - 安裝
- Apache Spark - 核心程式設計
- Apache Spark - 部署
- 高階 Spark 程式設計
- Apache Spark 有用資源
- Apache Spark - 快速指南
- Apache Spark - 有用資源
- Apache Spark - 討論
Apache Spark 簡介
許多行業廣泛使用 Hadoop 來分析其資料集。原因在於 Hadoop 框架基於簡單的程式設計模型(MapReduce),它能夠提供可擴充套件、靈活、容錯且經濟高效的計算解決方案。這裡,主要關注的是在處理大型資料集時保持速度,包括查詢之間的等待時間和程式執行的等待時間。
Apache 軟體基金會推出了 Spark,以加快 Hadoop 計算軟體的處理速度。
與普遍的看法相反,Spark 不是 Hadoop 的修改版本,實際上也不依賴於 Hadoop,因為它有自己的叢集管理。Hadoop 只是實現 Spark 的一種方式。
Spark 以兩種方式使用 Hadoop——一種是儲存,另一種是處理。由於 Spark 擁有自己的叢集管理計算,因此它僅將 Hadoop 用於儲存目的。
Apache Spark
Apache Spark 是一種閃電般快速的叢集計算技術,旨在進行快速計算。它基於 Hadoop MapReduce,並擴充套件了 MapReduce 模型,使其能夠高效地用於更多型別的計算,包括互動式查詢和流處理。Spark 的主要特點是其記憶體叢集計算,這提高了應用程式的處理速度。
Spark 旨在涵蓋各種工作負載,例如批處理應用程式、迭代演算法、互動式查詢和流處理。除了在各個系統中支援所有這些工作負載外,它還減少了維護單獨工具的管理負擔。
Apache Spark 的發展歷程
Spark 是 Hadoop 的一個子專案,於 2009 年由 Matei Zaharia 在加州大學伯克利分校的 AMPLab 開發。它於 2010 年在 BSD 許可證下開源。它於 2013 年捐贈給 Apache 軟體基金會,現在 Apache Spark 已成為從 2014 年 2 月開始的頂級 Apache 專案。
Apache Spark 的特性
Apache Spark 具有以下特性。
速度 - Spark 有助於在 Hadoop 叢集中執行應用程式,在記憶體中速度提高可達 100 倍,在磁碟上執行時速度提高 10 倍。這是透過減少對磁碟的讀/寫操作來實現的。它將中間處理資料儲存在記憶體中。
支援多種語言 - Spark 提供了 Java、Scala 或 Python 的內建 API。因此,您可以使用不同的語言編寫應用程式。Spark 提供了 80 多個高階運算子用於互動式查詢。
高階分析 - Spark 不僅支援“Map”和“reduce”,還支援 SQL 查詢、流資料、機器學習 (ML) 和圖演算法。
Spark 基於 Hadoop
下圖顯示了 Spark 如何與 Hadoop 元件結合使用的三種方式。
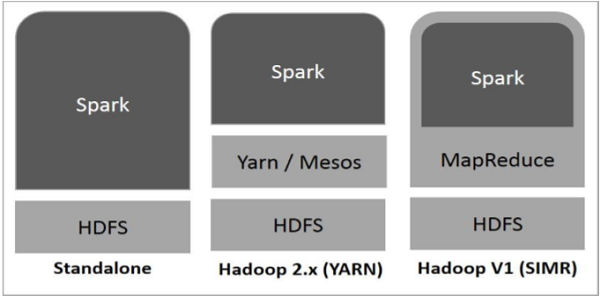
如下所述,Spark 有三種部署方式。
獨立模式 - Spark 獨立模式部署意味著 Spark 位於 HDFS(Hadoop 分散式檔案系統)之上,併為 HDFS 顯式分配空間。在這裡,Spark 和 MapReduce 將並排執行以覆蓋叢集上的所有 Spark 作業。
Hadoop Yarn - Hadoop Yarn 部署意味著 Spark 執行在 Yarn 上,無需任何預安裝或 root 訪問許可權。它有助於將 Spark 整合到 Hadoop 生態系統或 Hadoop 堆疊中。它允許其他元件在堆疊頂部執行。
MapReduce 中的 Spark (SIMR) - MapReduce 中的 Spark 用於除了獨立模式部署之外啟動 Spark 作業。使用 SIMR,使用者可以啟動 Spark 並使用其 shell,而無需任何管理許可權。
Spark 的元件
下圖描述了 Spark 的不同元件。
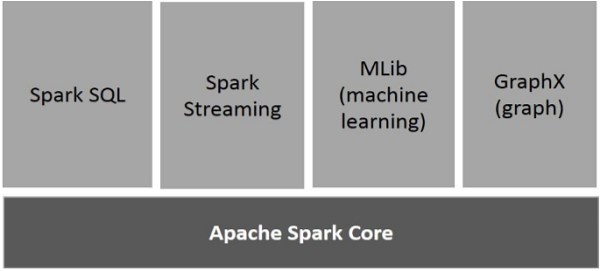
Apache Spark Core
Spark Core 是 Spark 平臺的基礎通用執行引擎,所有其他功能都是在此基礎上構建的。它提供記憶體計算和引用外部儲存系統中的資料集。
Spark SQL
Spark SQL 是 Spark Core 之上的一個元件,它引入了一種新的資料抽象,稱為 SchemaRDD,它支援結構化和半結構化資料。
Spark Streaming
Spark Streaming 利用 Spark Core 的快速排程功能來執行流分析。它以小批次方式提取資料,並在這些資料小批次上執行 RDD(彈性分散式資料集)轉換。
MLlib(機器學習庫)
MLlib 是 Spark 之上的一個分散式機器學習框架,因為它基於分散式記憶體的 Spark 架構。據基準測試(由 MLlib 開發人員針對交替最小二乘法 (ALS) 實現進行),Spark MLlib 比 Hadoop 基於磁碟的Apache Mahout版本快九倍(在 Mahout 獲得 Spark 介面之前)。
GraphX
GraphX 是 Spark 之上的一個分散式圖處理框架。它提供了一個 API 用於表達圖計算,可以使用 Pregel 抽象 API 對使用者定義的圖進行建模。它還為此抽象提供了一個最佳化的執行時。