- Apache Spark 教程
- Apache Spark - 首頁
- Apache Spark - 簡介
- Apache Spark - RDD
- Apache Spark - 安裝
- Apache Spark - 核心程式設計
- Apache Spark - 部署
- 高階 Spark 程式設計
- Apache Spark 有用資源
- Apache Spark - 快速指南
- Apache Spark - 有用資源
- Apache Spark - 討論
Apache Spark - 核心程式設計
Spark Core 是整個專案的基石。它提供分散式任務排程、計劃和基本的 I/O 功能。Spark 使用一種稱為 RDD(彈性分散式資料集)的特殊基本資料結構,它是在機器之間分割槽的邏輯資料集合。RDD 可以透過兩種方式建立;一種是引用外部儲存系統中的資料集,另一種是在現有的 RDD 上應用轉換(例如 map、filter、reducer、join)。
RDD 抽象透過語言整合 API 公開。這簡化了程式設計複雜性,因為應用程式操作 RDD 的方式類似於操作本地資料集合。
Spark Shell
Spark 提供了一個互動式 shell——一個強大的工具,用於互動式地分析資料。它以 Scala 或 Python 語言提供。Spark 的主要抽象是稱為彈性分散式資料集 (RDD) 的專案的分散式集合。RDD 可以從 Hadoop 輸入格式(例如 HDFS 檔案)建立,也可以透過轉換其他 RDD 建立。
開啟 Spark Shell
以下命令用於開啟 Spark shell。
$ spark-shell
建立簡單的 RDD
讓我們從文字檔案建立一個簡單的 RDD。使用以下命令建立簡單的 RDD。
scala> val inputfile = sc.textFile(“input.txt”)
上述命令的輸出為
inputfile: org.apache.spark.rdd.RDD[String] = input.txt MappedRDD[1] at textFile at <console>:12
Spark RDD API 引入了一些**轉換**和一些**操作**來操作 RDD。
RDD 轉換
RDD 轉換返回指向新 RDD 的指標,並允許您在 RDD 之間建立依賴關係。依賴鏈(依賴關係字串)中的每個 RDD 都有一個計算其資料的函式,並有一個指向其父 RDD 的指標(依賴關係)。
Spark 是惰性的,因此除非您呼叫一些將觸發作業建立和執行的轉換或操作,否則不會執行任何操作。請檢視以下單詞計數示例程式碼片段。
因此,RDD 轉換不是一組資料,而是在程式中的一步(可能是唯一的一步),告訴 Spark 如何獲取資料以及如何處理它。
下面列出了 RDD 轉換。
| 序號 | 轉換及含義 |
|---|---|
| 1 |
map(func) 返回一個新的分散式資料集,該資料集透過函式**func**傳遞源的每個元素形成。 |
| 2 |
filter(func) 返回一個新的資料集,該資料集透過選擇**func**返回 true 的源的那些元素形成。 |
| 3 |
flatMap(func) 類似於 map,但每個輸入項可以對映到 0 個或多個輸出項(因此func應該返回 Seq 而不是單個項)。 |
| 4 |
mapPartitions(func) 類似於 map,但在 RDD 的每個分割槽(塊)上單獨執行,因此當在型別為 T 的 RDD 上執行時,**func**必須為 Iterator<T> ⇒ Iterator<U> 型別。 |
| 5 |
mapPartitionsWithIndex(func) 類似於 map Partitions,但還為**func**提供一個表示分割槽索引的整數值,因此當在型別為 T 的 RDD 上執行時,**func**必須為 (Int, Iterator<T>) ⇒ Iterator<U> 型別。 |
| 6 |
sample(withReplacement, fraction, seed) 使用給定的隨機數生成器種子對資料進行**fraction**取樣,可以替換或不替換。 |
| 7 |
union(otherDataset) 返回一個新的資料集,其中包含源資料集和引數中的元素的並集。 |
| 8 |
intersection(otherDataset) 返回一個新的 RDD,其中包含源資料集和引數中元素的交集。 |
| 9 |
distinct([numTasks]) 返回一個新的資料集,其中包含源資料集的唯一元素。 |
| 10 |
groupByKey([numTasks]) 在 (K, V) 對的資料集上呼叫時,返回 (K, Iterable<V>) 對的資料集。 注意 - 如果您為了對每個鍵執行聚合(例如總和或平均值)而進行分組,則使用 reduceByKey 或 aggregateByKey 將產生更好的效能。 |
| 11 |
reduceByKey(func, [numTasks]) 在 (K, V) 對的資料集上呼叫時,返回 (K, V) 對的資料集,其中每個鍵的值使用給定的歸約函式func聚合,該函式必須為 (V, V) ⇒ V 型別。與 groupByKey 一樣,歸約任務的數量可以透過可選的第二個引數進行配置。 |
| 12 |
aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) 在 (K, V) 對的資料集上呼叫時,返回 (K, U) 對的資料集,其中每個鍵的值使用給定的組合函式和中性“零”值聚合。允許與輸入值型別不同的聚合值型別,同時避免不必要的分配。與 groupByKey 一樣,歸約任務的數量可以透過可選的第二個引數進行配置。 |
| 13 |
sortByKey([ascending], [numTasks]) 在 (K, V) 對的資料集上呼叫時,其中 K 實現 Ordered,返回 (K, V) 對的資料集,這些對按鍵升序或降序排序,如布林型 ascending 引數中指定的那樣。 |
| 14 |
join(otherDataset, [numTasks]) 在型別為 (K, V) 和 (K, W) 的資料集上呼叫時,返回 (K, (V, W)) 對的資料集,其中包含每個鍵的所有元素對。透過 leftOuterJoin、rightOuterJoin 和 fullOuterJoin 支援外部聯接。 |
| 15 |
cogroup(otherDataset, [numTasks]) 在型別為 (K, V) 和 (K, W) 的資料集上呼叫時,返回 (K, (Iterable<V>, Iterable<W>)) 元組的資料集。此操作也稱為 group With。 |
| 16 |
cartesian(otherDataset) 在型別為 T 和 U 的資料集上呼叫時,返回 (T, U) 對的資料集(所有元素對)。 |
| 17 |
pipe(command, [envVars]) 透過 shell 命令(例如 Perl 或 bash 指令碼)將 RDD 的每個分割槽傳遞到管道中。RDD 元素寫入程序的 stdin,輸出到其 stdout 的行作為字串的 RDD 返回。 |
| 18 |
coalesce(numPartitions) 將 RDD 中的分割槽數量減少到 numPartitions。在篩選大型資料集後更有效地執行操作很有用。 |
| 19 |
repartition(numPartitions) 隨機重新整理 RDD 中的資料以建立更多或更少的分割槽,並在它們之間進行平衡。這始終透過網路混洗所有資料。 |
| 20 |
repartitionAndSortWithinPartitions(partitioner) 根據給定的分割槽器重新分割槽 RDD,並在每個結果分割槽中按其鍵對記錄排序。這比呼叫 repartition 然後在每個分割槽中排序更有效,因為它可以將排序推送到混洗機制中。 |
操作
下表列出了返回值的**操作**。
| 序號 | 操作及含義 |
|---|---|
| 1 |
reduce(func) 使用函式**func**聚合資料集的元素(該函式接受兩個引數並返回一個)。該函式應該是可交換的和關聯的,以便能夠在並行中正確計算。 |
| 2 |
collect() 將資料集的所有元素作為驅動程式程式中的陣列返回。這通常在篩選或其他返回足夠小的資料子集的操作之後很有用。 |
| 3 |
count() 返回資料集中元素的數量。 |
| 4 |
first() 返回資料集的第一個元素(類似於 take (1))。 |
| 5 |
take(n) 返回一個數組,其中包含資料集的前**n**個元素。 |
| 6 |
takeSample (withReplacement,num, [seed]) 返回一個數組,其中包含資料集的**num**個元素的隨機樣本,可以替換或不替換,可以選擇預先指定隨機數生成器種子。 |
| 7 |
takeOrdered(n, [ordering]) 使用其自然順序或自定義比較器返回 RDD 的前**n**個元素。 |
| 8 |
saveAsTextFile(path) 將資料集的元素作為文字檔案(或一組文字檔案)寫入本地檔案系統、HDFS 或任何其他 Hadoop 支援的檔案系統中的給定目錄中。Spark 對每個元素呼叫 toString 以將其轉換為檔案中的文字行。 |
| 9 |
saveAsSequenceFile(path) (Java 和 Scala) 將資料集的元素作為 Hadoop SequenceFile 寫入本地檔案系統、HDFS 或任何其他 Hadoop 支援的檔案系統中的給定路徑中。這在實現 Hadoop 的 Writable 介面的鍵值對的 RDD 上可用。在 Scala 中,它也可用於隱式可轉換為 Writable 的型別(Spark 包含基本型別(如 Int、Double、String 等)的轉換)。 |
| 10 |
saveAsObjectFile(path) (Java 和 Scala) 使用 Java 序列化以簡單的格式寫入資料集的元素,然後可以使用 SparkContext.objectFile() 載入。 |
| 11 |
countByKey() 僅在型別為 (K, V) 的 RDD 上可用。返回 (K, Int) 對的雜湊對映,其中包含每個鍵的計數。 |
| 12 |
foreach(func) 在資料集的每個元素上執行函式**func**。這通常是為了副作用,例如更新累加器或與外部儲存系統互動。 注意 - 修改 foreach() 外部累加器以外的變數可能會導致未定義的行為。有關更多詳細資訊,請參閱理解閉包。 |
使用 RDD 進行程式設計
讓我們透過示例瞭解 RDD 程式設計中一些 RDD 轉換和操作的實現。
示例
考慮一個單詞計數示例——它計算文件中出現的每個單詞。將以下文字作為輸入,並將其另存為主目錄中的input.txt檔案。
input.txt - 輸入檔案。
people are not as beautiful as they look, as they walk or as they talk. they are only as beautiful as they love, as they care as they share.
按照以下步驟執行給定的示例。
開啟 Spark-Shell
以下命令用於開啟 spark shell。通常,spark 使用 Scala 構建。因此,Spark 程式在 Scala 環境中執行。
$ spark-shell
如果 Spark shell 成功開啟,您將找到以下輸出。檢視輸出的最後一行“Spark context available as sc”表示 Spark 容器自動建立名為sc的 spark context 物件。在開始程式的第一步之前,應建立 SparkContext 物件。
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>
建立 RDD
首先,我們必須使用 Spark-Scala API 讀取輸入檔案並建立 RDD。
以下命令用於從給定位置讀取檔案。此處,使用輸入檔名建立新的 RDD。作為 textFile("") 方法中引數給出的字串是輸入檔名的絕對路徑。但是,如果只給出檔名,則表示輸入檔案位於當前位置。
scala> val inputfile = sc.textFile("input.txt")
執行單詞計數轉換
我們的目標是計算檔案中的單詞。建立一個 flat map 以將每一行拆分為單詞(flatMap(line ⇒ line.split(" ")))。
接下來,使用 map 函式(map(word ⇒ (word, 1))將每個單詞作為鍵讀取,值為‘1’(<key, value> = <word,1>)。
最後,透過新增相似鍵的值來減少這些鍵(reduceByKey(_+_))。
以下命令用於執行單詞計數邏輯。執行此操作後,您將找不到任何輸出,因為這不是操作,這是一個轉換;指向新的 RDD 或告訴 spark 如何處理給定的資料)
scala> val counts = inputfile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_);
當前 RDD
在使用RDD時,如果想了解當前RDD的資訊,可以使用以下命令。它會顯示有關當前RDD及其依賴項的描述,以便進行除錯。
scala> counts.toDebugString
快取轉換
可以使用RDD上的`persist()`或`cache()`方法將其標記為持久化。第一次在action中計算它時,它將儲存在節點的記憶體中。使用以下命令將中間轉換儲存在記憶體中。
scala> counts.cache()
應用Action
應用一個action,例如將所有轉換儲存到文字檔案。`saveAsTextFile(“ ”)`方法的字串引數是輸出資料夾的絕對路徑。嘗試以下命令將輸出儲存到文字檔案中。在以下示例中,'output'資料夾位於當前位置。
scala> counts.saveAsTextFile("output")
檢查輸出
開啟另一個終端,轉到主目錄(Spark在另一個終端中執行的地方)。使用以下命令檢查輸出目錄。
[hadoop@localhost ~]$ cd output/ [hadoop@localhost output]$ ls -1 part-00000 part-00001 _SUCCESS
以下命令用於檢視來自Part-00000檔案的輸出。
[hadoop@localhost output]$ cat part-00000
輸出
(people,1) (are,2) (not,1) (as,8) (beautiful,2) (they, 7) (look,1)
以下命令用於檢視來自Part-00001檔案的輸出。
[hadoop@localhost output]$ cat part-00001
輸出
(walk, 1) (or, 1) (talk, 1) (only, 1) (love, 1) (care, 1) (share, 1)
取消持久化儲存
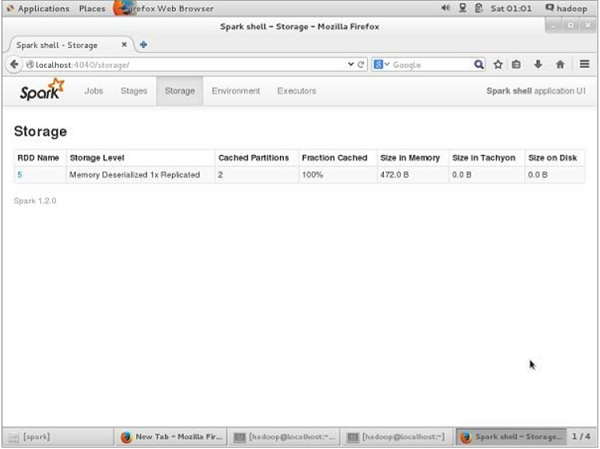
在取消持久化之前,如果想檢視此應用程式使用的儲存空間,請在瀏覽器中使用以下URL。
https://:4040
您將看到以下螢幕,其中顯示了應用程式使用的儲存空間,這些應用程式正在Spark shell上執行。
如果要取消持久化特定RDD的儲存空間,請使用以下命令。
Scala> counts.unpersist()
您將看到如下輸出:
15/06/27 00:57:33 INFO ShuffledRDD: Removing RDD 9 from persistence list 15/06/27 00:57:33 INFO BlockManager: Removing RDD 9 15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_1 15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_1 of size 480 dropped from memory (free 280061810) 15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_0 15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_0 of size 296 dropped from memory (free 280062106) res7: cou.type = ShuffledRDD[9] at reduceByKey at <console>:14
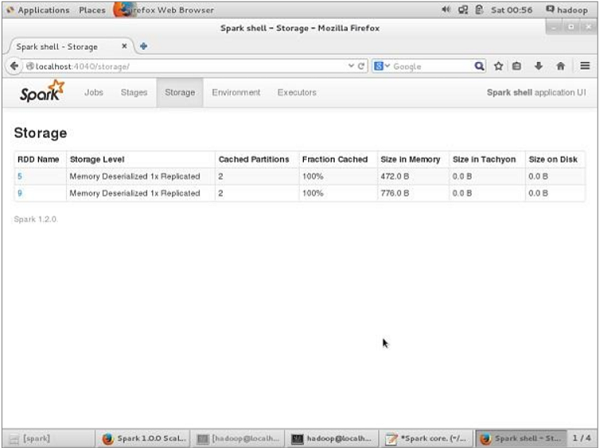
要驗證瀏覽器中的儲存空間,請使用以下URL。
https://:4040/
您將看到以下螢幕。它顯示了應用程式使用的儲存空間,這些應用程式正在Spark shell上執行。