
 資料結構
資料結構 網路
網路 關係型資料庫管理系統
關係型資料庫管理系統 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP在 Python 中理解邏輯迴歸?
邏輯迴歸是一種用於預測二元結果的統計技術。它並不是什麼新鮮事物,因為它目前已被應用於從金融到醫學,再到犯罪學和其他社會科學等各個領域。
在本節中,我們將使用 Python 開發邏輯迴歸,儘管您也可以使用其他語言(如 R)來實現相同的目的。
安裝
我們將在示例程式中使用以下庫:
Numpy:用於定義數值陣列和矩陣
Pandas:用於處理和操作資料
Statsmodels:用於處理引數估計和統計檢驗
Pylab:用於生成繪圖
您可以使用 pip 透過在 CLI 中執行以下命令來安裝以上庫。
>pip install numpy pandas statsmodels
邏輯迴歸的示例用例
為了測試我們在 Python 中的邏輯迴歸,我們將使用 UCLA(數字研究與教育研究所)提供的 logit 迴歸資料。您可以從以下連結以 csv 格式訪問資料:https://stats.idre.ucla.edu/stat/data/binary.csv
我已經將此 csv 檔案儲存在我的本地機器上,並將從那裡讀取資料,您可以選擇任一方式。使用此 csv 檔案,我們將識別可能影響研究生院錄取的各種因素。
匯入所需的庫並載入資料集
我們將使用 pandas 庫 (pandas.read_csv) 讀取資料
import pandas as pd
import statsmodels.api as sm
import pylab as pl
import numpy as np
df = pd.read_csv('binary.csv')
#We can read the data directly from the link \
# df = pd.read_csv(‘https://stats.idre.ucla.edu/stat/data/binary.csv’)
print(df.head())輸出
admit gre gpa rank 0 0 380 3.61 3 1 1 660 3.67 3 2 1 800 4.00 1 3 1 640 3.19 4 4 0 520 2.93 4
從上面的輸出可以看出,有一列名稱為“rank”,這可能會造成問題,因為“rank”也是 pandas 資料框中方法的名稱。為了避免任何衝突,我將 rank 列的名稱更改為“prestige”。所以讓我們更改資料集的列名
df.columns = ["admit", "gre", "gpa", "prestige"] print(df.columns)
輸出
Index(['admit', 'gre', 'gpa', 'prestige'], dtype='object') In [ ]:
現在一切看起來都正常了,我們現在可以更深入地瞭解我們的資料集包含的內容。
#總結資料
使用 pandas 函式 describe,我們將獲得所有內容的彙總檢視。
print(df.describe())
輸出
admit gre gpa prestige count 400.000000 400.000000 400.000000 400.00000 mean 0.317500 587.700000 3.389900 2.48500 std 0.466087 115.516536 0.380567 0.94446 min 0.000000 220.000000 2.260000 1.00000 25% 0.000000 520.000000 3.130000 2.00000 50% 0.000000 580.000000 3.395000 2.00000 75% 1.000000 660.000000 3.670000 3.00000 max 1.000000 800.000000 4.000000 4.00000
我們可以獲取資料的每一列的標準差,以及按聲望和是否被錄取來劃分的頻數表。
# take a look at the standard deviation of each column print(df.std())
輸出
admit 0.466087 gre 115.516536 gpa 0.380567 prestige 0.944460 dtype: float64
示例
# frequency table cutting presitge and whether or not someone was admitted print(pd.crosstab(df['admit'], df['prestige'], rownames = ['admit']))
輸出
prestige 1 2 3 4 admit 0 28 97 93 55 1 33 54 28 12
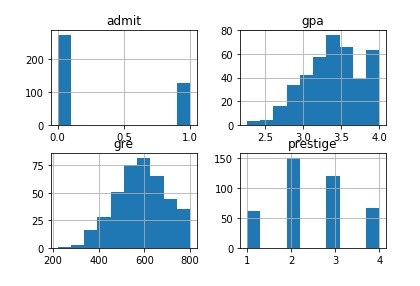
讓我們繪製資料集的所有列。
# plot all of the columns df.hist() pl.show()
輸出
虛擬變數
Python pandas 庫在表示分類變數的方式上提供了極大的靈活性。
# dummify rank dummy_ranks = pd.get_dummies(df['prestige'], prefix='prestige') print(dummy_ranks.head())
輸出
prestige_1 prestige_2 prestige_3 prestige_4 0 0 0 1 0 1 0 0 1 0 2 1 0 0 0 3 0 0 0 1 4 0 0 0 1
示例
# create a clean data frame for the regression cols_to_keep = ['admit', 'gre', 'gpa'] data = df[cols_to_keep].join(dummy_ranks.ix[:, 'prestige_2':])
輸出
admit gre gpa prestige_2 prestige_3 prestige_4 0 0 380 3.61 0 1 0 1 1 660 3.67 0 1 0 2 1 800 4.00 0 0 0 3 1 640 3.19 0 0 1 4 0 520 2.93 0 0 1 In [ ]:
執行迴歸
現在我們將進行邏輯迴歸,這非常簡單。我們只需指定包含我們要預測的變數的列,然後指定模型應使用哪些列進行預測。
現在我們根據 gre、gpa 和聲望虛擬變數 prestige_2、prestige_3 和 prestige_4 來預測 admit 列。
train_cols = data.columns[1:] # Index([gre, gpa, prestige_2, prestige_3, prestige_4], dtype=object) logit = sm.Logit(data['admit'], data[train_cols]) # fit the model result = logit.fit()
輸出
Optimization terminated successfully. Current function value: 0.573147 Iterations 6
解釋結果
讓我們使用 statsmodels 生成彙總輸出。
print(result.summary2())
輸出
Results: Logit =============================================================== Model: Logit No. Iterations: 6.0000 Dependent Variable: admit Pseudo R-squared: 0.083 Date: 2019-03-03 14:16 AIC: 470.5175 No. Observations: 400 BIC: 494.4663 Df Model: 5 Log-Likelihood: -229.26 Df Residuals: 394 LL-Null: -249.99 Converged: 1.0000 Scale: 1.0000 ---------------------------------------------------------------- Coef. Std.Err. z P>|z| [0.025 0.975] ---------------------------------------------------------------- gre 0.0023 0.0011 2.0699 0.0385 0.0001 0.0044 gpa 0.8040 0.3318 2.4231 0.0154 0.1537 1.4544 prestige_2 -0.6754 0.3165 -2.1342 0.0328 -1.2958 -0.0551 prestige_3 -1.3402 0.3453 -3.8812 0.0001 -2.0170 -0.6634 prestige_4 -1.5515 0.4178 -3.7131 0.0002 -2.3704 -0.7325 intercept -3.9900 1.1400 -3.5001 0.0005 -6.2242 -1.7557 ==============================================================
上述結果物件還允許我們分離並檢查模型輸出的各個部分。
#look at the confidence interval of each coeffecient print(result.conf_int())
輸出
0 1 gre 0.000120 0.004409 gpa 0.153684 1.454391 prestige_2 -1.295751 -0.055135 prestige_3 -2.016992 -0.663416 prestige_4 -2.370399 -0.732529 intercept -6.224242 -1.755716
從上面的輸出可以看出,被錄取的機率與候選人本科學校的聲望之間存在反比關係。
因此,對於就讀於排名靠前的本科院校(prestige_1=True)的學生,被研究生項目錄取的機率高於就讀於排名較低的學校(prestige_3 或 prestige_4)的學生。

297 次瀏覽
