- Teradata 教程
- Teradata - 首頁
- Teradata 基礎
- Teradata - 簡介
- Teradata - 安裝
- Teradata - 架構
- Teradata - 關係型概念
- Teradata - 資料型別
- Teradata - 表
- Teradata - 資料操作
- Teradata - SELECT 語句
- 邏輯與條件運算子
- Teradata - 集合運算子
- Teradata - 字串操作
- Teradata - 日期/時間函式
- Teradata - 內建函式
- Teradata - 聚合函式
- Teradata - CASE 與 COALESCE
- Teradata - 主索引
- Teradata - 連線
- Teradata - 子查詢
- Teradata 高階
- Teradata - 表型別
- Teradata - 空間概念
- Teradata - 二級索引
- Teradata - 統計
- Teradata - 壓縮
- Teradata - EXPLAIN
- Teradata - 雜湊演算法
- Teradata - 連線索引
- Teradata - 檢視
- Teradata - 宏
- Teradata - 儲存過程
- Teradata - 連線策略
- Teradata - 分割槽主索引
- Teradata - OLAP 函式
- Teradata - 資料保護
- Teradata - 使用者管理
- Teradata - 效能調優
- Teradata - FastLoad
- Teradata - MultiLoad
- Teradata - FastExport
- Teradata - BTEQ
- Teradata 有用資源
- Teradata - 問答
- Teradata - 快速指南
- Teradata - 有用資源
- Teradata - 討論
Teradata - 雜湊演算法
根據主鍵值,一行資料被分配到特定的 AMP。Teradata 使用雜湊演算法來確定哪個 AMP 獲取該行資料。
以下是關於雜湊演算法的高階圖表。
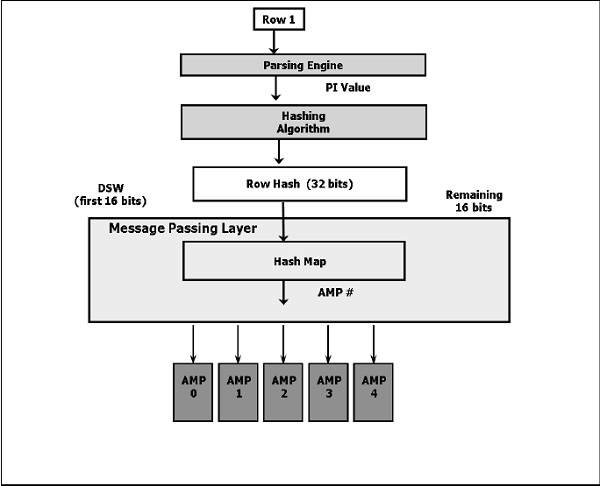
以下是插入資料的步驟。
客戶端提交查詢。
解析器接收查詢並將記錄的主鍵值傳遞給雜湊演算法。
雜湊演算法對主鍵值進行雜湊運算並返回一個 32 位數字,稱為行雜湊值。
行雜湊值的高位位元(前 16 位)用於標識雜湊對映條目。雜湊對映包含一個 AMP 號。雜湊對映是一個桶陣列,包含特定的 AMP 號。
BYNET 將資料傳送到已識別的 AMP。
AMP 使用 32 位行雜湊值在其磁碟中定位該行。
如果存在任何具有相同行雜湊值的記錄,則它會遞增唯一性 ID(一個 32 位數字)。對於新的行雜湊值,唯一性 ID 被賦值為 1,並在每次插入具有相同行雜湊值的記錄時遞增。
行雜湊值和唯一性 ID 的組合稱為行 ID。
行 ID 作為字首儲存在磁碟中的每條記錄之前。
AMP 中的每個錶行按其行 ID 邏輯排序。
表的儲存方式
表按其行 ID(行雜湊值 + 唯一性 ID)排序,然後儲存在 AMP 中。行 ID 與每個資料行一起儲存。
| 行雜湊值 | 唯一性 ID | 員工編號 | 名字 | 姓氏 |
|---|---|---|---|---|
| 2A01 2611 | 0000 0001 | 101 | Mike | James |
| 2A01 2612 | 0000 0001 | 104 | Alex | Stuart |
| 2A01 2613 | 0000 0001 | 102 | Robert | Williams |
| 2A01 2614 | 0000 0001 | 105 | Robert | James |
| 2A01 2615 | 0000 0001 | 103 | Peter | Paul |
廣告