- spaCy 教程
- spaCy - 首頁
- spaCy - 簡介
- spaCy - 入門
- spaCy - 模型和語言
- spaCy - 架構
- spaCy - 命令列助手
- spaCy - 頂級函式
- spaCy - 視覺化函式
- spaCy - 實用函式
- spaCy - 相容性函式
- spaCy - 容器
- Doc 類上下文管理器和屬性
- spaCy - 容器 Token 類
- spaCy - Token 屬性
- spaCy - 容器 Span 類
- spaCy - Span 類屬性
- spaCy - 容器 Lexeme 類
- 訓練神經網路模型
- 更新神經網路模型
- spaCy 有用資源
- spaCy - 快速指南
- spaCy - 有用資源
- spaCy - 討論
spaCy - 訓練神經網路模型
在本章中,讓我們學習如何在 spaCy 中訓練神經網路模型。
在這裡,我們將瞭解如何更新 spaCy 的統計模型以根據我們的用例對其進行定製。例如,預測線上評論中的新實體型別。要進行自定義,我們首先需要訓練自己的模型。
訓練步驟
讓我們瞭解在 spaCy 中訓練神經網路模型的步驟。
步驟 1 - **初始化** - 如果您不使用預訓練模型,那麼首先,我們需要使用 **nlp.begin_training** 隨機初始化模型權重。
步驟 2 - **預測** - 接下來,我們需要使用當前權重預測一些示例。可以透過呼叫 **nlp.updates** 來完成。
步驟 3 - **比較** - 現在,模型將檢查預測結果與真實標籤是否一致。
步驟 4 - **計算** - 比較之後,在這裡,我們將決定如何更改權重以便下次進行更好的預測。
步驟 5 - **更新** - 最後,對當前權重進行微小更改,並選擇下一批示例。繼續對您獲取的每一批示例呼叫 **nlp.updates**。
現在讓我們藉助下圖瞭解這些步驟 -
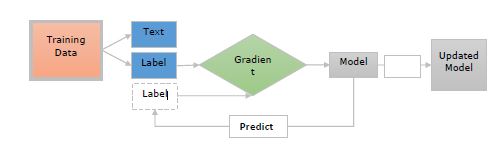
這裡 -
**訓練資料** - 訓練資料是示例及其註釋。這些是我們想要更新模型的示例。
**文字** - 它表示模型應該預測其標籤的輸入文字。它可以是句子、段落或更長的文件。
**標籤** - 標籤實際上是我們希望模型預測的內容。例如,它可以是文字類別。
**梯度** - 梯度是指我們應該如何更改權重以減少誤差。在將預測標籤與真實標籤進行比較後,將計算梯度。
訓練實體識別器
首先,實體識別器將獲取文件並預測短語及其標籤。
這意味著訓練資料需要包含以下內容 -
文字。
它們包含的實體。
實體標籤。
每個標記只能是某個實體的一部分。因此,實體不能重疊。
我們還應該在實體及其周圍上下文中對其進行訓練,因為實體識別器會在上下文中預測實體。
這可以透過向模型顯示文字和字元偏移列表來完成。
例如,在下面給出的程式碼中,phone 是一個從字元 0 開始到字元 8 結束的小工具。
("Phone is coming", {"entities": [(0, 8, "GADGET")]})
在這裡,模型還應該學習除實體之外的其他單詞。
考慮另一個訓練實體識別器的示例,如下所示 -
("I need a new phone! Any suggestions?", {"entities": []})
主要目標應該是教會我們的實體識別器模型,即使在訓練資料中不存在,也能在類似上下文中識別新的實體。
spaCy 的訓練迴圈
一些庫為我們提供了負責模型訓練的方法,但另一方面,spaCy 為我們提供了對訓練迴圈的完全控制。
訓練迴圈可以定義為一系列步驟,這些步驟用於更新和訓練模型。
訓練迴圈步驟
讓我們看看訓練迴圈的步驟,如下所示 -
**步驟 1** - **迴圈** - 第一步是迴圈,我們通常需要執行多次,以便模型從中學習。例如,如果您想訓練模型 20 次迭代,則需要迴圈 20 次。
**步驟 2** - **隨機洗牌** - 第二步是隨機洗牌訓練資料。我們需要對每次迭代的資料進行隨機洗牌。這有助於防止模型陷入次優解。
**步驟 3** - **劃分** – 然後將資料分成批次。在這裡,我們將訓練資料分成小批次。這有助於提高梯度估計的可讀性。
**步驟 4** - **更新** - 下一步是更新每個步驟的模型。現在,我們需要更新模型並重新開始迴圈,直到達到最後一次迭代。
**步驟 5** - **儲存** - 最後,我們可以儲存此訓練後的模型並在 spaCy 中使用它。
示例
以下是 spaCy 的訓練迴圈示例 -
DATA = [
("How to order the Phone X", {"entities": [(20, 28, "GADGET")]})
]
# Step1: Loop for 10 iterations
for i in range(10):
# Step2: Shuffling the training data
random.shuffle(DATA)
# Step3: Creating batches and iterating over them
for batch in spacy.util.minibatch(DATA):
# Step4: Splitting the batch in texts and annotations
texts = [text for text, annotation in batch]
annotations = [annotation for text, annotation in batch]
# Step5: Updating the model
nlp.update(texts, annotations)
# Step6: Saving the model
nlp.to_disk(path_to_model)