- Scala 集合教程
- Scala 集合 - 首頁
- Scala 集合 - 概述
- Scala 集合 - 環境設定
- Scala 集合 - 陣列
- Scala 集合 - 陣列
- Scala 集合 - 多維陣列
- Scala 集合 - 使用 Range 建立陣列
- Scala 集合 - ArrayBuffer
- Scala 集合 - 列表
- Scala 集合 - 列表
- Scala 集合 - ListBuffer
- Scala 集合 - ListSet
- Scala 集合 - 向量
- Scala 集合 - 集合
- Scala 集合 - 集合
- Scala 集合 - BitSet
- Scala 集合 - HashSet
- Scala 集合 - TreeSet
- Scala 集合 - 對映
- Scala 集合 - 對映
- Scala 集合 - HashMap
- Scala 集合 - ListMap
- Scala 集合 - 其他
- Scala 集合 - 迭代器
- Scala 集合 - Option
- Scala 集合 - 佇列
- Scala 集合 - 元組
- Scala 集合 - Seq
- Scala 集合 - 堆疊
- Scala 集合 - 流
- Scala 集合組合器方法
- Scala 集合 - drop
- Scala 集合 - dropWhile
- Scala 集合 - filter
- Scala 集合 - find
- Scala 集合 - flatMap
- Scala 集合 - flatten
- Scala 集合 - fold
- Scala 集合 - foldLeft
- Scala 集合 - foldRight
- Scala 集合 - map
- Scala 集合 - partition
- Scala 集合 - reduce
- Scala 集合 - scan
- Scala 集合 - zip
- Scala 集合有用資源
- Scala 集合 - 快速指南
- Scala 集合 - 有用資源
- Scala 集合 - 討論
Scala 集合 - 快速指南
Scala 集合 - 概述
Scala 擁有豐富的集合庫。集合是事物的容器。這些容器可以是有序的,例如 List、Tuple、Option、Map 等線性專案集。集合可以包含任意數量的元素,也可以限制為零個或一個元素(例如,Option)。
集合可以是**嚴格的**或**惰性的**。惰性集合的元素可能不會在訪問之前佔用記憶體,例如**Ranges**。此外,集合可以是**可變的**(引用的內容可以更改)或**不可變的**(引用指向的事物永遠不會更改)。請注意,不可變集合可能包含可變項。
對於某些問題,可變集合效果更好,而對於其他問題,不可變集合效果更好。如有疑問,最好從不可變集合開始,如果需要可變集合,則稍後再更改。
本章闡述了最常用的集合型別和對這些集合最常用的操作。
| 序號 | 集合及描述 |
|---|---|
| 1 | Scala 列表 Scala 的 List[T] 是型別 T 的連結串列。 |
| 2 | Scala 集合 集合是相同型別元素的成對不同元素的集合。 |
| 3 |
Scala 對映 對映是鍵/值對的集合。任何值都可以根據其鍵檢索。 |
| 4 | Scala 元組 與陣列或列表不同,元組可以容納不同型別的物件。 |
| 5 | Scala Option Option[T] 為給定型別的零個或一個元素提供容器。 |
| 6 | Scala 迭代器 迭代器不是集合,而是一種逐一訪問集合元素的方法。 |
Scala 集合 - 環境設定
Scala 可以安裝在任何類 Unix 或基於 Windows 的系統上。在開始在您的計算機上安裝 Scala 之前,您必須在計算機上安裝 Java 1.8 或更高版本。
請按照以下步驟安裝 Scala。
步驟 1:驗證您的 Java 安裝
首先,您需要在系統上安裝 Java 軟體開發工具包 (SDK)。要驗證這一點,請根據您正在使用的平臺執行以下兩個命令中的任何一個。
如果 Java 安裝已正確完成,則它將顯示當前版本和 Java 安裝的規範。示例輸出在以下表格中給出。
| 平臺 | 命令 | 示例輸出 |
|---|---|---|
| Windows |
開啟命令控制檯並鍵入: >java -version |
Java 版本 "1.8.0_31" Java(TM) SE 執行時環境 (build 1.8.0_31-b31) Java Hotspot(TM) 64 位伺服器 VM (build 25.31-b07, mixed mode) |
| Linux |
開啟命令終端並鍵入: $java -version |
Java 版本 "1.8.0_31" Open JDK 執行時環境 (rhel-2.8.10.4.el6_4-x86_64) Open JDK 64 位伺服器 VM (build 25.31-b07, mixed mode) |
我們假設本教程的讀者在其系統上安裝了 Java SDK 版本 1.8.0_31。
如果您沒有 Java SDK,請從https://www.oracle.com/technetwork/java/javase/downloads/index.html下載其當前版本並安裝它。
步驟 2:設定您的 Java 環境
設定環境變數 JAVA_HOME 以指向 Java 安裝在您機器上的基本目錄位置。例如:
| 序號 | 平臺和描述 |
|---|---|
| 1 |
Windows 將 JAVA_HOME 設定為 C:\ProgramFiles\java\jdk1.8.0_31 |
| 2 |
Linux Export JAVA_HOME=/usr/local/java-current |
將 Java 編譯器位置的完整路徑附加到系統路徑。
| 序號 | 平臺和描述 |
|---|---|
| 1 |
Windows 將字串 "C:\Program Files\Java\jdk1.8.0_31\bin" 附加到系統變數 PATH 的末尾。 |
| 2 |
Linux Export PATH=$PATH:$JAVA_HOME/bin/ |
如上所述,從命令提示符執行命令**java -version**。
步驟 3:安裝 Scala
您可以從www.scala-lang.org/downloads下載 Scala。在撰寫本教程時,我下載了“scala-2.13.1-installer.jar”。確保您擁有管理員許可權才能繼續。現在,在命令提示符下執行以下命令:
| 平臺 | 命令和輸出 | 描述 |
|---|---|---|
| Windows | >java -jar scala-2.13.1-installer.jar> |
此命令將顯示安裝嚮導,該向導將指導您在 Windows 機器上安裝 Scala。在安裝過程中,它將詢問許可協議,只需接受它,然後它將詢問安裝 Scala 的路徑。我選擇了預設路徑 _“C:\Program Files\Scala”_,您可以根據自己的方便選擇合適的路徑。 |
| Linux |
**命令**: $java -jar scala-2.13.1-installer.jar **輸出**: 歡迎安裝 Scala 2.13.1! 按 1 繼續,按 2 退出,按 3 重新顯示 1................................................ [ 開始解壓 ] [ 處理軟體包:軟體包安裝 (1/1) ] [ 解壓完成 ] [ 控制檯安裝完成 ] |
在安裝過程中,它將詢問許可協議,要接受它,請輸入 1,它將詢問安裝 Scala 的路徑。我輸入了 _/usr/local/share_,您可以根據自己的方便選擇合適的路徑。 |
最後,開啟一個新的命令提示符並鍵入**Scala -version** 並按 Enter 鍵。您應該看到以下內容:
| 平臺 | 命令 | 輸出 |
|---|---|---|
| Windows | >scala -version |
Scala 程式碼執行器版本 2.13.1 -- 版權所有 2002-2019,LAMP/EPFL 和 Lightbend, Inc. |
| Linux | $scala -version |
Scala 程式碼執行器版本 2.13.1 -- 版權所有 2002-2019,LAMP/EPFL 和 Lightbend, Inc.tut |
Scala 集合 - 陣列
Scala 提供了一種資料結構**陣列**,它儲存相同型別元素的固定大小的順序集合。陣列用於儲存資料集合,但通常將陣列視為相同型別變數的集合更有用。
您可以宣告一個數組變數(例如 numbers),並使用 numbers[0]、numbers[1] 和 ... numbers[99] 來表示各個變數,而不是宣告單獨的變數,例如 number0、number1、... 和 number99。本教程介紹如何宣告陣列變數、建立陣列以及使用索引變數處理陣列。陣列第一個元素的索引為零,最後一個元素的索引為元素總數減一。
宣告陣列變數
要在程式中使用陣列,必須宣告一個變數來引用陣列,並且必須指定變數可以引用的陣列型別。
以下是宣告陣列變數的語法。
語法
var z:Array[String] = new Array[String](3) or var z = new Array[String](3)
這裡,z 被宣告為一個最多可以容納三個元素的字串陣列。可以使用以下命令為各個元素賦值或訪問各個元素:
命令
z(0) = "Zara"; z(1) = "Nuha"; z(4/2) = "Ayan"
這裡,最後一個示例表明,通常索引可以是任何產生整數的表示式。還有一種定義陣列的方法:
var z = Array("Zara", "Nuha", "Ayan")
下圖表示陣列**myList**。這裡,**myList** 包含十個雙精度值,索引從 0 到 9。
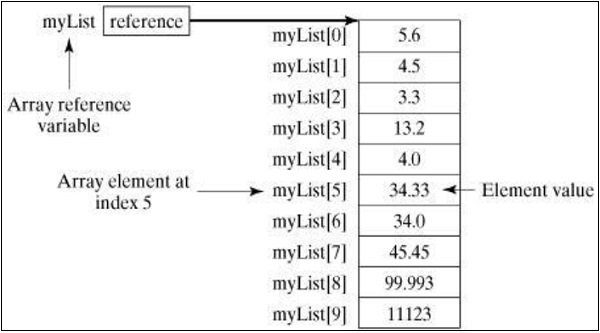
處理陣列
處理陣列元素時,我們經常使用迴圈控制結構,因為陣列中的所有元素都是相同型別,並且陣列的大小是已知的。
以下是一個示例程式,演示如何建立、初始化和處理陣列:
示例
object Demo {
def main(args: Array[String]) {
var myList = Array(1.9, 2.9, 3.4, 3.5)
// Print all the array elements
for ( x <- myList ) {
println( x )
}
// Summing all elements
var total = 0.0;
for ( i <- 0 to (myList.length - 1)) {
total += myList(i);
}
println("Total is " + total);
// Finding the largest element
var max = myList(0);
for ( i <- 1 to (myList.length - 1) ) {
if (myList(i) > max) max = myList(i);
}
println("Max is " + max);
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
1.9 2.9 3.4 3.5 Total is 11.7 Max is 3.5
Scala 不直接支援各種陣列操作,並提供各種方法來處理任何維度的陣列。如果要使用不同的方法,則需要匯入**Array._** 包。
Scala 集合 - 多維陣列
在許多情況下,您需要定義和使用多維陣列(即元素為陣列的陣列)。例如,矩陣和表是可以實現為二維陣列的結構示例。
以下是定義二維陣列的示例:
var myMatrix = ofDim[Int](3,3)
這是一個數組,它有三個元素,每個元素都是一個包含三個元素的整數陣列。
嘗試以下示例程式來處理多維陣列:
示例
import Array._
object Demo {
def main(args: Array[String]) {
var myMatrix = ofDim[Int](3,3)
// build a matrix
for (i <- 0 to 2) {
for ( j <- 0 to 2) {
myMatrix(i)(j) = j;
}
}
// Print two dimensional array
for (i <- 0 to 2) {
for ( j <- 0 to 2) {
print(" " + myMatrix(i)(j));
}
println();
}
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
0 1 2 0 1 2 0 1 2
Scala 集合 - 使用 Range 建立陣列
使用 range() 方法生成一個包含給定範圍內遞增整數序列的陣列。您可以使用最終引數作為步長來建立序列;如果您不使用最終引數,則步長將假定為 1。
讓我們以建立範圍 (10, 20, 2) 的陣列為例:這意味著建立一個包含 10 到 20 之間的元素且範圍差為 2 的陣列。陣列中的元素為 10、12、14、16 和 18。
另一個示例:range (10, 20)。這裡沒有給出範圍差,因此預設情況下它假定為 1 個元素。它建立一個包含 10 到 20 之間的元素且範圍差為 1 的陣列。陣列中的元素為 10、11、12、13、…和 19。
以下示例程式演示如何使用範圍建立陣列。
示例
import Array._
object Demo {
def main(args: Array[String]) {
var myList1 = range(10, 20, 2)
var myList2 = range(10,20)
// Print all the array elements
for ( x <- myList1 ) {
print( " " + x )
}
println()
for ( x <- myList2 ) {
print( " " + x )
}
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
10 12 14 16 18 10 11 12 13 14 15 16 17 18 19
Scala 集合 - ArrayBuffer
Scala 提供了一種資料結構**ArrayBuffer**,當初始大小不足時,它可以更改大小。由於陣列大小固定,無法在陣列中佔用更多元素,因此 ArrayBuffer 是陣列的替代方案,其大小是靈活的。
ArrayBuffer 在內部維護一個當前大小的陣列來儲存元素。新增新元素時,將檢查大小。如果底層陣列已滿,則將建立一個新的更大陣列,並將所有元素複製到更大的陣列。
宣告 ArrayBuffer 變數
以下是宣告 ArrayBuffer 變數的語法。
語法
var z = ArrayBuffer[String]()
這裡,z 被宣告為一個最初為空的字串陣列緩衝區。可以使用以下命令新增值:
命令
z += "Zara"; z += "Nuha"; z += "Ayan";
處理 ArrayBuffer
下面是一個關於如何建立、初始化和處理ArrayBuffer的示例程式。
示例
import scala.collection.mutable.ArrayBuffer
object Demo {
def main(args: Array[String]) = {
var myList = ArrayBuffer("Zara","Nuha","Ayan")
println(myList);
// Add an element
myList += "Welcome";
// Add two element
myList += ("To", "Tutorialspoint");
println(myList);
// Remove an element
myList -= "Welcome";
// print second element
println(myList(1));
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
ArrayBuffer(Zara, Nuha, Ayan) ArrayBuffer(Zara, Nuha, Ayan, Welcome, To, Tutorialspoint) Nuha
Scala 集合 - 列表
Scala列表與陣列非常相似,這意味著列表的所有元素都具有相同的型別,但是有兩個重要的區別。首先,列表是不可變的,這意味著列表的元素不能透過賦值來更改。其次,列表表示一個連結串列,而陣列是扁平的。
具有型別為T的元素的列表的型別寫為List[T]。
嘗試以下示例,這裡定義了幾個不同資料型別的列表。
// List of Strings
val fruit: List[String] = List("apples", "oranges", "pears")
// List of Integers
val nums: List[Int] = List(1, 2, 3, 4)
// Empty List.
val empty: List[Nothing] = List()
// Two dimensional list
val dim: List[List[Int]] = List(
List(1, 0, 0),
List(0, 1, 0),
List(0, 0, 1)
)
所有列表都可以使用兩個基本構建塊來定義:尾部Nil和::(發音為cons)。Nil也表示空列表。以上所有列表都可以如下定義。
// List of Strings
val fruit = "apples" :: ("oranges" :: ("pears" :: Nil))
// List of Integers
val nums = 1 :: (2 :: (3 :: (4 :: Nil)))
// Empty List.
val empty = Nil
// Two dimensional list
val dim = (1 :: (0 :: (0 :: Nil))) ::
(0 :: (1 :: (0 :: Nil))) ::
(0 :: (0 :: (1 :: Nil))) :: Nil
列表的基本操作
所有列表操作都可以用以下三種方法來表達。
| 序號 | 方法和描述 |
|---|---|
| 1 |
head 此方法返回列表的第一個元素。 |
| 2 |
tail 此方法返回一個列表,該列表包含除第一個元素之外的所有元素。 |
| 3 |
isEmpty 如果列表為空,此方法返回true,否則返回false。 |
以下示例演示瞭如何使用上述方法。
示例
object Demo {
def main(args: Array[String]) {
val fruit = "apples" :: ("oranges" :: ("pears" :: Nil))
val nums = Nil
println( "Head of fruit : " + fruit.head )
println( "Tail of fruit : " + fruit.tail )
println( "Check if fruit is empty : " + fruit.isEmpty )
println( "Check if nums is empty : " + nums.isEmpty )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Head of fruit : apples Tail of fruit : List(oranges, pears) Check if fruit is empty : false Check if nums is empty : true
連線列表
您可以使用:::運算子或List.:::()方法或List.concat()方法來新增兩個或多個列表。請參見下面的示例。
示例
object Demo {
def main(args: Array[String]) {
val fruit1 = "apples" :: ("oranges" :: ("pears" :: Nil))
val fruit2 = "mangoes" :: ("banana" :: Nil)
// use two or more lists with ::: operator
var fruit = fruit1 ::: fruit2
println( "fruit1 ::: fruit2 : " + fruit )
// use two lists with Set.:::() method
fruit = fruit1.:::(fruit2)
println( "fruit1.:::(fruit2) : " + fruit )
// pass two or more lists as arguments
fruit = List.concat(fruit1, fruit2)
println( "List.concat(fruit1, fruit2) : " + fruit )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
fruit1 ::: fruit2 : List(apples, oranges, pears, mangoes, banana) fruit1.:::(fruit2) : List(mangoes, banana, apples, oranges, pears) List.concat(fruit1, fruit2) : List(apples, oranges, pears, mangoes, banana)
建立統一列表
您可以使用List.fill()方法建立一個包含零個或多個相同元素副本的列表。嘗試以下示例程式。
示例
object Demo {
def main(args: Array[String]) {
val fruit = List.fill(3)("apples") // Repeats apples three times.
println( "fruit : " + fruit )
val num = List.fill(10)(2) // Repeats 2, 10 times.
println( "num : " + num )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
fruit : List(apples, apples, apples) num : List(2, 2, 2, 2, 2, 2, 2, 2, 2, 2)
製表函式
您可以將函式與List.tabulate()方法一起使用,以在製表列表之前將其應用於列表的所有元素。其引數與List.fill的引數類似:第一個引數列表給出要建立的列表的維度,第二個引數描述列表的元素。唯一的區別是,元素不是固定的,而是由函式計算的。
嘗試以下示例程式。
示例
object Demo {
def main(args: Array[String]) {
// Creates 5 elements using the given function.
val squares = List.tabulate(6)(n => n * n)
println( "squares : " + squares )
val mul = List.tabulate( 4,5 )( _ * _ )
println( "mul : " + mul )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
squares : List(0, 1, 4, 9, 16, 25) mul : List(List(0, 0, 0, 0, 0), List(0, 1, 2, 3, 4), List(0, 2, 4, 6, 8), List(0, 3, 6, 9, 12))
反轉列表順序
您可以使用List.reverse方法反轉列表的所有元素。以下示例演示了用法。
示例
object Demo {
def main(args: Array[String]) {
val fruit = "apples" :: ("oranges" :: ("pears" :: Nil))
println( "Before reverse fruit : " + fruit )
println( "After reverse fruit : " + fruit.reverse )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Before reverse fruit : List(apples, oranges, pears) After reverse fruit : List(pears, oranges, apples)
Scala 集合 - ListBuffer
Scala提供了一種資料結構ListBuffer,它在新增/刪除列表中的元素時比List更高效。它提供了在列表中新增元素的方法。
宣告ListBuffer變數
以下是宣告ListBuffer變數的語法。
語法
var z = ListBuffer[String]()
這裡,z宣告為一個最初為空的字串ListBuffer。可以使用以下命令新增值:
命令
z += "Zara"; z += "Nuha"; z += "Ayan";
處理ListBuffer
下面是一個關於如何建立、初始化和處理ListBuffer的示例程式。
示例
import scala.collection.mutable.ListBuffer
object Demo {
def main(args: Array[String]) = {
var myList = ListBuffer("Zara","Nuha","Ayan")
println(myList);
// Add an element
myList += "Welcome";
// Add two element
myList += ("To", "Tutorialspoint");
println(myList);
// Remove an element
myList -= "Welcome";
// print second element
println(myList(1));
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
ListBuffer(Zara, Nuha, Ayan) ListBuffer(Zara, Nuha, Ayan, Welcome, To, Tutorialspoint) Nuha
Scala 集合 - ListSet
Scala Set是一個包含相同型別成對不同元素的集合。換句話說,Set是一個不包含重複元素的集合。ListSet實現不可變集合並使用列表結構。儲存元素時會保留元素的插入順序。
宣告ListSet變數
以下是宣告ListSet變數的語法。
語法
var z : ListSet[String] = ListSet("Zara","Nuha","Ayan")
這裡,z宣告為一個包含三個成員的字串ListSet。可以使用以下命令新增值:
命令
var myList1: ListSet[String] = myList + "Naira";
處理ListSet
下面是一個關於如何建立、初始化和處理ListSet的示例程式。
示例
import scala.collection.immutable.ListSet
object Demo {
def main(args: Array[String]) = {
var myList: ListSet[String] = ListSet("Zara","Nuha","Ayan");
// Add an element
var myList1: ListSet[String] = myList + "Naira";
// Remove an element
var myList2: ListSet[String] = myList - "Nuha";
// Create empty set
var myList3: ListSet[String] = ListSet.empty[String];
println(myList);
println(myList1);
println(myList2);
println(myList3);
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
ListSet(Zara, Nuha, Ayan) ListSet(Zara, Nuha, Ayan, Naira) ListSet(Zara, Ayan) ListSet()
Scala 集合 - 向量
Scala Vector是一個通用的不可變資料結構,其中元素可以隨機訪問。它通常用於大型資料集合。
宣告Vector變數
以下是宣告Vector變數的語法。
語法
var z : Vector[String] = Vector("Zara","Nuha","Ayan")
這裡,z宣告為一個包含三個成員的字串Vector。可以使用以下命令新增值:
命令
var vector1: Vector[String] = z + "Naira";
處理Vector
下面是一個關於如何建立、初始化和處理Vector的示例程式。
示例
import scala.collection.immutable.Vector
object Demo {
def main(args: Array[String]) = {
var vector: Vector[String] = Vector("Zara","Nuha","Ayan");
// Add an element
var vector1: Vector[String] = vector :+ "Naira";
// Reverse an element
var vector2: Vector[String] = vector.reverse;
// sort a vector
var vector3: Vector[String] = vector1.sorted;
println(vector);
println(vector1);
println(vector2);
println(vector3);
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Vector(Zara, Nuha, Ayan) Vector(Zara, Nuha, Ayan, Naira) Vector(Ayan, Nuha, Zara) Vector(Ayan, Naira, Nuha, Zara)
Scala 集合 - 集合
Scala Set是一個包含相同型別成對不同元素的集合。換句話說,Set是一個不包含重複元素的集合。Set有兩種型別:**不可變**和**可變**。可變物件和不可變物件的區別在於,當一個物件是不可變的時,物件本身不能被改變。
預設情況下,Scala使用不可變Set。如果要使用可變Set,則必須顯式匯入scala.collection.mutable.Set類。如果要在同一個集合中同時使用可變和不可變集合,則可以繼續將不可變Set稱為Set,但可變Set可以稱為mutable.Set。
以下是如何宣告不可變Set:
語法
// Empty set of integer type var s : Set[Int] = Set() // Set of integer type var s : Set[Int] = Set(1,3,5,7) or var s = Set(1,3,5,7)
定義空集合時,型別註釋是必要的,因為系統需要為變數分配具體的型別。
集合的基本操作
所有集合操作都可以用以下三種方法來表達:
| 序號 | 方法和描述 |
|---|---|
| 1 |
head 此方法返回集合的第一個元素。 |
| 2 |
tail 此方法返回一個集合,該集合包含除第一個元素之外的所有元素。 |
| 3 |
isEmpty 此方法如果集合為空則返回true,否則返回false。 |
嘗試以下示例,該示例顯示了基本操作方法的用法:
示例
object Demo {
def main(args: Array[String]) {
val fruit = Set("apples", "oranges", "pears")
val nums: Set[Int] = Set()
println( "Head of fruit : " + fruit.head )
println( "Tail of fruit : " + fruit.tail )
println( "Check if fruit is empty : " + fruit.isEmpty )
println( "Check if nums is empty : " + nums.isEmpty )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Head of fruit : apples Tail of fruit : Set(oranges, pears) Check if fruit is empty : false Check if nums is empty : true
連線集合
您可以使用++運算子或Set.++()方法連線兩個或多個集合,但在新增集合時,它會刪除重複的元素。
以下是連線兩個集合的示例。
示例
object Demo {
def main(args: Array[String]) {
val fruit1 = Set("apples", "oranges", "pears")
val fruit2 = Set("mangoes", "banana")
// use two or more sets with ++ as operator
var fruit = fruit1 ++ fruit2
println( "fruit1 ++ fruit2 : " + fruit )
// use two sets with ++ as method
fruit = fruit1.++(fruit2)
println( "fruit1.++(fruit2) : " + fruit )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
fruit1 ++ fruit2 : Set(banana, apples, mangoes, pears, oranges) fruit1.++(fruit2) : Set(banana, apples, mangoes, pears, oranges)
查詢集合中的最大值和最小值元素
您可以使用Set.min方法找出集合中可用的元素的最小值,並使用Set.max方法找出最大值。以下是顯示程式的示例。
示例
object Demo {
def main(args: Array[String]) {
val num = Set(5,6,9,20,30,45)
// find min and max of the elements
println( "Min element in Set(5,6,9,20,30,45) : " + num.min )
println( "Max element in Set(5,6,9,20,30,45) : " + num.max )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Min element in Set(5,6,9,20,30,45) : 5 Max element in Set(5,6,9,20,30,45) : 45
查詢集合中的公共值
您可以使用Set.&方法或Set.intersect方法找出兩個集合之間的公共值。嘗試以下示例以顯示用法。
示例
object Demo {
def main(args: Array[String]) {
val num1 = Set(5,6,9,20,30,45)
val num2 = Set(50,60,9,20,35,55)
// find common elements between two sets
println( "num1.&(num2) : " + num1.&(num2) )
println( "num1.intersect(num2) : " + num1.intersect(num2) )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
num1.&(num2) : Set(20, 9) num1.intersect(num2) : Set(20, 9)
Scala 集合 - BitSet
Bitset是可變和不可變位集的公共基類。位集是非負整數的集合,表示為打包到64位字中的可變大小的位陣列。位集的記憶體佔用量由其中儲存的最大數字表示。
宣告BitSet變數
以下是宣告BitSet變數的語法。
語法
var z : BitSet = BitSet(0,1,2)
這裡,z宣告為一個包含三個成員的非負整數位集。可以使用以下命令新增值:
命令
var myList1: BitSet = myList + 3;
處理BitSet
下面是一個關於如何建立、初始化和處理BitSet的示例程式。
示例
import scala.collection.immutable.BitSet
object Demo {
def main(args: Array[String]) = {
var mySet: BitSet = BitSet(0, 1, 2);
// Add an element
var mySet1: BitSet = mySet + 3;
// Remove an element
var mySet2: BitSet = mySet - 2;
var mySet3: BitSet = BitSet(4, 5);
// Adding sets
var mySet4: BitSet = mySet1 ++ mySet3;
println(mySet);
println(mySet1);
println(mySet2);
println(mySet4);
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
BitSet(0, 1, 2) BitSet(0, 1, 2, 3) BitSet(0, 1) BitSet(0, 1, 2, 3, 4, 5)
Scala 集合 - HashSet
Scala Set是一個包含相同型別成對不同元素的集合。換句話說,Set是一個不包含重複元素的集合。HashSet實現不可變集合並使用雜湊表。不保留元素的插入順序。
宣告HashSet變數
以下是宣告HashSet變數的語法。
語法
var z : HashSet[String] = HashSet("Zara","Nuha","Ayan")
這裡,z宣告為一個包含三個成員的字串HashSet。可以使用以下命令新增值:
命令
var myList1: HashSet[String] = myList + "Naira";
處理HashSet
下面是一個關於如何建立、初始化和處理HashSet的示例程式。
示例
import scala.collection.immutable.HashSet
object Demo {
def main(args: Array[String]) = {
var mySet: HashSet[String] = HashSet("Zara","Nuha","Ayan");
// Add an element
var mySet1: HashSet[String] = mySet + "Naira";
// Remove an element
var mySet2: HashSet[String] = mySet - "Nuha";
// Create empty set
var mySet3: HashSet[String] = HashSet.empty[String];
println(mySet);
println(mySet1);
println(mySet2);
println(mySet3);
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
HashSet(Zara, Nuha, Ayan) HashSet(Zara, Nuha, Ayan, Naira) HashSet(Zara, Ayan) HashSet()
Scala 集合 - TreeSet
Scala Set是一個包含相同型別成對不同元素的集合。換句話說,Set是一個不包含重複元素的集合。TreeSet實現不可變集合並按排序順序儲存元素。
宣告TreeSet變數
以下是宣告TreeSet變數的語法。
語法
var z : TreeSet[String] = TreeSet("Zara","Nuha","Ayan")
這裡,z宣告為一個包含三個成員的字串TreeSet。可以使用以下命令新增值:
命令
var myList1: TreeSet[String] = myList + "Naira";
處理TreeSet
下面是一個關於如何建立、初始化和處理TreeSet的示例程式。
示例
import scala.collection.immutable.TreeSet
object Demo {
def main(args: Array[String]) = {
var mySet: TreeSet[String] = TreeSet("Zara","Nuha","Ayan");
// Add an element
var mySet1: TreeSet[String] = mySet + "Naira";
// Remove an element
var mySet2: TreeSet[String] = mySet - "Nuha";
// Create empty set
var mySet3: TreeSet[String] = TreeSet.empty[String];
println(mySet);
println(mySet1);
println(mySet2);
println(mySet3);
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
TreeSet(Ayan, Nuha, Zara) TreeSet(Ayan, Naira, Nuha, Zara) TreeSet(Ayan, Zara) TreeSet()
Scala 集合 - 對映
Scala Map是鍵/值對的集合。任何值都可以根據其鍵檢索。Map中的鍵是唯一的,但值不必唯一。Map也稱為雜湊表。Map有兩種型別:**不可變**和**可變**。可變物件和不可變物件的區別在於,當一個物件是不可變的時,物件本身不能被改變。
預設情況下,Scala使用不可變Map。如果要使用可變Map,則必須顯式匯入scala.collection.mutable.Map類。如果要在同一個集合中同時使用可變和不可變Map,則可以繼續將不可變Map稱為Map,但可變Map可以稱為mutable.Map。
以下是宣告不可變Map的示例語句:
// Empty hash table whose keys are strings and values are integers:
var A:Map[Char,Int] = Map()
// A map with keys and values.
val colors = Map("red" -> "#FF0000", "azure" -> "#F0FFFF")
定義空Map時,型別註釋是必要的,因為系統需要為變數分配具體的型別。如果要向Map新增鍵值對,可以使用+運算子,如下所示。
A + = ('I' -> 1)
A + = ('J' -> 5)
A + = ('K' -> 10)
A + = ('L' -> 100)
MAP的基本操作
所有Map操作都可以用以下三種方法來表達。
| 序號 | 方法和描述 |
|---|---|
| 1 |
keys 此方法返回一個包含Map中每個鍵的可迭代物件。 |
| 2 |
values 此方法返回一個包含Map中每個值的可迭代物件。 |
| 3 |
isEmpty 此方法如果Map為空則返回true,否則返回false。 |
嘗試以下示例程式,該程式顯示了Map方法的用法。
示例
object Demo {
def main(args: Array[String]) {
val colors = Map(
"red" -> "#FF0000", "azure" -> "#F0FFFF", "peru" -> "#CD853F"
)
val nums: Map[Int, Int] = Map()
println( "Keys in colors : " + colors.keys )
println( "Values in colors : " + colors.values )
println( "Check if colors is empty : " + colors.isEmpty )
println( "Check if nums is empty : " + nums.isEmpty )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Keys in colors : Set(red, azure, peru) Values in colors : MapLike(#FF0000, #F0FFFF, #CD853F) Check if colors is empty : false Check if nums is empty : true
連線Map
您可以使用++運算子或Map.++()方法連線兩個或多個Map,但在新增Map時,它會刪除重複的鍵。
嘗試以下示例程式來連線兩個Map。
示例
object Demo {
def main(args: Array[String]) {
val colors1 = Map(
"red" -> "#FF0000", "azure" -> "#F0FFFF", "peru" -> "#CD853F"
)
val colors2 = Map(
"blue" -> "#0033FF", "yellow" -> "#FFFF00", "red" -> "#FF0000"
)
// use two or more Maps with ++ as operator
var colors = colors1 ++ colors2
println( "colors1 ++ colors2 : " + colors )
// use two maps with ++ as method
colors = colors1.++(colors2)
println( "colors1.++(colors2)) : " + colors )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
colors1 ++ colors2 : Map(blue -> #0033FF, azure -> #F0FFFF, peru -> #CD853F, yellow -> #FFFF00, red -> #FF0000) colors1.++(colors2)) : Map(blue -> #0033FF, azure -> #F0FFFF, peru -> #CD853F, yellow -> #FFFF00, red -> #FF0000)
列印Map中的鍵和值
您可以使用“foreach”迴圈遍歷Map的鍵和值。在這裡,我們使用了與迭代器關聯的foreach方法來遍歷鍵。以下是一個示例程式。
示例
object Demo {
def main(args: Array[String]) {
val colors = Map("red" -> "#FF0000", "azure" -> "#F0FFFF","peru" -> "#CD853F")
colors.keys.foreach{
i =>
print( "Key = " + i )
println(" Value = " + colors(i) )
}
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Key = red Value = #FF0000 Key = azure Value = #F0FFFF Key = peru Value = #CD853F
檢查Map中的鍵
您可以使用Map.contains方法來測試給定的鍵是否存在於Map中。嘗試以下示例程式進行鍵檢查。
示例
object Demo {
def main(args: Array[String]) {
val colors = Map(
"red" -> "#FF0000", "azure" -> "#F0FFFF", "peru" -> "#CD853F"
)
if( colors.contains( "red" )) {
println("Red key exists with value :" + colors("red"))
} else {
println("Red key does not exist")
}
if( colors.contains( "maroon" )) {
println("Maroon key exists with value :" + colors("maroon"))
} else {
println("Maroon key does not exist")
}
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Red key exists with value :#FF0000 Maroon key does not exist
Scala 集合 - HashMap
Scala Map是鍵/值對的集合。任何值都可以根據其鍵檢索。Map中的鍵是唯一的,但值不必唯一。HashMap實現不可變Map並使用雜湊表來實現相同的功能。
宣告HashMap變數
以下是宣告HashMap變數的語法。
語法
val colors = HashMap("red" -> "#FF0000", "azure" -> "#F0FFFF", "peru" -> "#CD853F")
這裡,colors宣告為一個包含三個鍵值對的字串、Int HashMap。可以使用以下命令新增值:
命令
var myMap1: HashMap[Char, Int] = colors + ("black" -> "#000000");
處理HashMap
下面是一個關於如何建立、初始化和處理HashMap的示例程式。
示例
import scala.collection.immutable.HashMap
object Demo {
def main(args: Array[String]) = {
var myMap: HashMap[String,String] = HashMap(
"red" -> "#FF0000", "azure" -> "#F0FFFF", "peru" -> "#CD853F"
);
// Add an element
var myMap1: HashMap[String,String] = myMap + ("white" -> "#FFFFFF");
// Print key values
myMap.keys.foreach{
i =>
print( "Key = " + i )
println(" Value = " + myMap(i) )
}
if( myMap.contains( "red" )) {
println("Red key exists with value :" + myMap("red"))
} else {
println("Red key does not exist")
}
if( myMap.contains( "maroon" )) {
println("Maroon key exists with value :" + myMap("maroon"))
} else {
println("Maroon key does not exist")
}
//removing element
var myMap2: HashMap[String,String] = myMap - ("white");
// Create empty map
var myMap3: HashMap[String,String] = HashMap.empty[String, String];
println(myMap1);
println(myMap2);
println(myMap3);
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Key = azure Value = #F0FFFF Key = peru Value = #CD853F Key = red Value = #FF0000 Red key exists with value :#FF0000 Maroon key does not exist HashMap(azure -> #F0FFFF, peru -> #CD853F, white -> #FFFFFF, red -> #FF0000) HashMap(azure -> #F0FFFF, peru -> #CD853F, red -> #FF0000) HashMap()
Scala 集合 - ListMap
Scala Map是鍵/值對的集合。任何值都可以根據其鍵檢索。Map中的鍵是唯一的,但值不必唯一。ListMap實現不可變Map並使用列表來實現相同的功能。它用於少量元素。
宣告ListMap變數
以下是宣告 ListMap 變數的語法。
語法
val colors = ListMap("red" -> "#FF0000", "azure" -> "#F0FFFF", "peru" -> "#CD853F")
這裡,colors宣告為一個包含三個鍵值對的字串、Int HashMap。可以使用以下命令新增值:
命令
var myMap1: ListMap[Char, Int] = colors + ("black" -> "#000000");
處理 ListMap
下面是一個示例程式,演示如何建立、初始化和處理 ListMap:
示例
import scala.collection.immutable.ListMap
object Demo {
def main(args: Array[String]) = {
var myMap: ListMap[String,String] = ListMap(
"red" -> "#FF0000", "azure" -> "#F0FFFF", "peru" -> "#CD853F"
);
// Add an element
var myMap1: ListMap[String,String] = myMap + ("white" -> "#FFFFFF");
// Print key values
myMap.keys.foreach{
i =>
print( "Key = " + i )
println(" Value = " + myMap(i) )
}
if( myMap.contains( "red" )) {
println("Red key exists with value :" + myMap("red"))
} else {
println("Red key does not exist")
}
if( myMap.contains( "maroon" )) {
println("Maroon key exists with value :" + myMap("maroon"))
} else {
println("Maroon key does not exist")
}
//removing element
var myMap2: ListMap[String,String] = myMap - ("white");
// Create empty map
var myMap3: ListMap[String,String] = ListMap.empty[String, String];
println(myMap1);
println(myMap2);
println(myMap3);
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Key = red Value = #FF0000 Key = azure Value = #F0FFFF Key = peru Value = #CD853F Red key exists with value :#FF0000 Maroon key does not exist ListMap(red -> #FF0000, azure -> #F0FFFF, peru -> #CD853F, white -> #FFFFFF) ListMap(red -> #FF0000, azure -> #F0FFFF, peru -> #CD853F) ListMap()
Scala 集合 - 迭代器
迭代器不是集合,而是一種逐一訪問集合元素的方法。迭代器 it 的兩個基本操作是next 和 hasNext。呼叫it.next() 將返回迭代器的下一個元素並推進迭代器的狀態。您可以使用迭代器的it.hasNext 方法來確定是否還有更多元素可以返回。
遍歷迭代器返回的所有元素最直接的方法是使用 while 迴圈。讓我們來看下面的示例程式。
示例
object Demo {
def main(args: Array[String]) {
val it = Iterator("a", "number", "of", "words")
while (it.hasNext){
println(it.next())
}
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
a number of words
查詢最小和最大值元素
您可以使用it.min 和it.max 方法來查詢迭代器中的最小和最大值元素。這裡,我們使用ita 和itb 執行兩個不同的操作,因為迭代器只能遍歷一次。下面是示例程式。
示例
object Demo {
def main(args: Array[String]) {
val ita = Iterator(20,40,2,50,69, 90)
val itb = Iterator(20,40,2,50,69, 90)
println("Maximum valued element " + ita.max )
println("Minimum valued element " + itb.min )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Maximum valued element 90 Minimum valued element 2
查詢迭代器的長度
您可以使用it.size 或it.length 方法來查詢迭代器中可用元素的數量。這裡,我們使用 ita 和 itb 執行兩個不同的操作,因為迭代器只能遍歷一次。下面是示例程式。
示例
object Demo {
def main(args: Array[String]) {
val ita = Iterator(20,40,2,50,69, 90)
val itb = Iterator(20,40,2,50,69, 90)
println("Value of ita.size : " + ita.size )
println("Value of itb.length : " + itb.length )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Value of ita.size : 6 Value of itb.length : 6
Scala 集合 - Option
Scala Option[T] 是一個容器,包含給定型別的一個或零個元素。Option[T] 可以是Some[T] 或None 物件,後者表示缺失的值。例如,Scala 的 Map 的 get 方法如果找到與給定鍵對應的值,則會產生 Some(value),如果給定鍵在 Map 中未定義,則會產生None。
Option 型別在 Scala 程式中經常使用,您可以將其與 Java 中的null 值進行比較,後者表示沒有值。例如,java.util.HashMap 的 get 方法要麼返回儲存在 HashMap 中的值,要麼如果未找到值則返回 null。
假設我們有一個方法,它根據主鍵從資料庫中檢索記錄。
def findPerson(key: Int): Option[Person]
如果找到記錄,該方法將返回 Some[Person],如果未找到記錄,則返回 None。讓我們來看下面的程式。
示例
object Demo {
def main(args: Array[String]) {
val capitals = Map("France" -> "Paris", "Japan" -> "Tokyo")
println("capitals.get( \"France\" ) : " + capitals.get( "France" ))
println("capitals.get( \"India\" ) : " + capitals.get( "India" ))
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
capitals.get( "France" ) : Some(Paris) capitals.get( "India" ) : None
分解可選值最常用的方法是模式匹配。例如,嘗試以下程式。
示例
object Demo {
def main(args: Array[String]) {
val capitals = Map("France" -> "Paris", "Japan" -> "Tokyo")
println("show(capitals.get( \"Japan\")) : " + show(capitals.get( "Japan")) )
println("show(capitals.get( \"India\")) : " + show(capitals.get( "India")) )
}
def show(x: Option[String]) = x match {
case Some(s) => s
case None => "?"
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
show(capitals.get( "Japan")) : Tokyo show(capitals.get( "India")) : ?
使用 getOrElse() 方法
以下示例程式演示如何使用 getOrElse() 方法訪問值或在沒有值時使用預設值。
示例
object Demo {
def main(args: Array[String]) {
val a:Option[Int] = Some(5)
val b:Option[Int] = None
println("a.getOrElse(0): " + a.getOrElse(0) )
println("b.getOrElse(10): " + b.getOrElse(10) )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
a.getOrElse(0): 5 b.getOrElse(10): 10
使用 isEmpty() 方法
以下示例程式演示如何使用 isEmpty() 方法檢查選項是否為 None。
示例
object Demo {
def main(args: Array[String]) {
val a:Option[Int] = Some(5)
val b:Option[Int] = None
println("a.isEmpty: " + a.isEmpty )
println("b.isEmpty: " + b.isEmpty )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
示例
a.isEmpty: false b.isEmpty: true
Scala 集合 - 佇列
佇列是先進先出 (FIFO) 資料結構,允許以 FIFO 方式插入和檢索元素。
宣告佇列變數
以下是宣告佇列變數的語法。
語法
val queue = Queue(1, 2, 3, 4, 5)
這裡,queue 被宣告為一個數字佇列。可以使用以下命令在隊首新增值:
命令
queue.enqueue(6)
可以使用以下命令從隊首檢索值:
命令
queue.dequeue()
處理佇列
下面是一個示例程式,演示如何建立、初始化和處理佇列:
示例
import scala.collection.mutable.Queue
object Demo {
def main(args: Array[String]) = {
var queue = Queue(1, 2, 3, 4, 5);
// Print queue elements
queue.foreach{(element:Int) => print(element + " ")}
println();
// Print first element
println("First Element: " + queue.front)
// Add an element
queue.enqueue(6);
// Print queue elements
queue.foreach{(element:Int) => print(element+ " ")}
println();
// Remove an element
var dq = queue.dequeue;
// Print dequeued element
println("Dequeued Element: " + dq)
// Print queue elements
queue.foreach{(element:Int) => print(element+ " ")}
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
1 2 3 4 5 First Element: 1 1 2 3 4 5 6 Dequeued Element: 1 2 3 4 5 6
Scala 集合 - 元組
Scala 元組將固定數量的項組合在一起,以便可以將其作為一個整體傳遞。與陣列或列表不同,元組可以儲存不同型別的物件,但它們也是不可變的。
以下是一個包含整數、字串和控制檯的元組示例。
val t = (1, "hello", Console)
這是以下內容的語法糖(快捷方式):
val t = new Tuple3(1, "hello", Console)
元組的實際型別取決於它包含的元素數量和這些元素的型別。因此,(99, "Luftballons") 的型別是 Tuple2[Int, String]。('u', 'r', "the", 1, 4, "me") 的型別是 Tuple6[Char, Char, String, Int, Int, String]
元組的型別為 Tuple1、Tuple2、Tuple3 等。Scala 中目前上限為 22,如果您需要更多,則可以使用集合,而不是元組。對於每個 TupleN 型別(其中 1 <= N <= 22),Scala 定義了許多元素訪問方法。給定以下定義:
val t = (4,3,2,1)
要訪問元組 t 的元素,可以使用方法 t._1 訪問第一個元素,t._2 訪問第二個元素,依此類推。例如,以下表達式計算 t 所有元素的總和。
val sum = t._1 + t._2 + t._3 + t._4
您可以使用元組編寫一個方法,該方法接受 List[Double] 並返回一個包含三個元素的元組 Tuple3[Int, Double, Double] 中的計數、總和以及平方和。它們也可用於在併發程式設計中將資料值列表作為訊息傳遞給參與者之間。
嘗試以下示例程式。它演示瞭如何使用元組。
示例
object Demo {
def main(args: Array[String]) {
val t = (4,3,2,1)
val sum = t._1 + t._2 + t._3 + t._4
println( "Sum of elements: " + sum )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Sum of elements: 10
迭代元組
您可以使用Tuple.productIterator() 方法迭代元組的所有元素。
嘗試以下示例程式來迭代元組。
示例
object Demo {
def main(args: Array[String]) {
val t = (4,3,2,1)
t.productIterator.foreach{ i =>println("Value = " + i )}
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Value = 4 Value = 3 Value = 2 Value = 1
轉換為字串
您可以使用Tuple.toString() 方法將元組的所有元素連線成一個字串。嘗試以下示例程式以轉換為字串。
示例
object Demo {
def main(args: Array[String]) {
val t = new Tuple3(1, "hello", Console)
println("Concatenated String: " + t.toString() )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Concatenated String: (1,hello,scala.Console$@281acd47)
交換元素
您可以使用Tuple.swap 方法交換 Tuple2 的元素。
嘗試以下示例程式來交換元素。
示例
object Demo {
def main(args: Array[String]) {
val t = new Tuple2("Scala", "hello")
println("Swapped Tuple: " + t.swap )
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Swapped tuple: (hello,Scala)
Scala 集合 - Seq
Scala Seq 是一個代表不可變序列的特徵。此結構提供基於索引的訪問以及各種實用程式方法來查詢元素、它們的出現和子序列。Seq 保持插入順序。
宣告 Seq 變數
以下是宣告 Seq 變數的語法。
語法
val seq: Seq[Int] = Seq(1, 2, 3, 4, 5)
這裡,seq 被宣告為一個數字 Seq。Seq 提供以下命令:
命令
val isPresent = seq.contains(4); val contains = seq.endsWith(Seq(4,5)); var lastIndexOf = seq.lasIndexOf(5);
處理 Seq
下面是一個示例程式,演示如何建立、初始化和處理 Seq:
示例
import scala.collection.immutable.Seq
object Demo {
def main(args: Array[String]) = {
var seq = Seq(1, 2, 3, 4, 5, 3)
// Print seq elements
seq.foreach{(element:Int) => print(element + " ")}
println()
println("Seq ends with (5,3): " + seq.endsWith(Seq(5, 3)))
println("Seq contains 4: " + seq.contains(4))
println("Last index of 3: " + seq.lastIndexOf(3))
println("Reversed Seq" + seq.reverse)
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
1 2 3 4 5 3 Seq ends with (5,3): true Seq contains 4: true Last index of 3: 5 Reversed SeqList(3, 5, 4, 3, 2, 1)
Scala 集合 - 堆疊
棧是後進先出 (LIFO) 資料結構,允許以 LIFO 方式在頂部插入和檢索元素。
宣告棧變數
以下是宣告棧變數的語法。
語法
val stack = Stack(1, 2, 3, 4, 5)
這裡,stack 被宣告為一個數字棧。可以使用以下命令在頂部新增值:
命令
stack.push(6)
可以使用以下命令從頂部檢索值:
命令
stack.top
可以使用以下命令從頂部移除值:
命令
stack.pop
處理棧
下面是一個示例程式,演示如何建立、初始化和處理棧:
示例
import scala.collection.mutable.Stack
object Demo {
def main(args: Array[String]) = {
var stack: Stack[Int] = Stack();
// Add elements
stack.push(1);
stack.push(2);
// Print element at top
println("Top Element: " + stack.top)
// Print element
println("Removed Element: " + stack.pop())
// Print element
println("Top Element: " + stack.top)
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Top Element: 2 Removed Element: 2 Top Element: 1
Scala 集合 - 流
Scala Stream 是一個具有惰性求值功能的特殊列表。在 Scala Stream 中,只有在需要時才求值元素。Stream 支援惰性計算,並且效能出色。
宣告 Stream 變數
以下是宣告 Stream 變數的語法。
語法
val stream = 1 #:: 2 #:: 3 #:: Stream.empty
這裡,stream 被宣告為一個數字流。這裡 1 是流的頭部,2、3 是流的尾部。Stream.empty 標記流的結尾。可以使用 take 命令檢索值,如下所示:
命令
stream.take(2)
處理 Stream
下面是一個示例程式,演示如何建立、初始化和處理 Stream:
示例
import scala.collection.immutable.Stream
object Demo {
def main(args: Array[String]) = {
val stream = 1 #:: 2 #:: 3 #:: Stream.empty
// print stream
println(stream)
// Print first two elements
stream.take(2).print
println()
// Create an empty stream
val stream1: Stream[Int] = Stream.empty[Int]
// Print element
println(s"Stream: $stream1")
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Stream(1, <not computed>) 1, 2 Stream: Stream()
Scala 集合 - Drop 方法
drop() 方法是 List 使用的方法,用於選擇列表中除前 n 個元素之外的所有元素。
語法
以下是 drop 方法的語法。
def drop(n: Int): List[A]
這裡,n 是要從列表中刪除的元素數。此方法返回列表中除前 n 個元素之外的所有元素。
用法
下面是一個示例程式,演示如何使用 drop 方法:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3, 4, 5)
// print list
println(list)
//apply operation
val result = list.drop(3)
//print result
println(result)
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
List(1, 2, 3, 4, 5) List(4, 5)
Scala 集合 - DropWhile 方法
dropWhile() 方法是 List 使用的方法,用於刪除滿足給定條件的所有元素。
語法
以下是 dropWhile 方法的語法。
def dropWhile(p: (A) => Boolean): List[A]
這裡,p: (A) => Boolean 是要應用於列表中每個元素的謂詞或條件。此方法返回列表中除已刪除元素之外的所有元素。
用法
下面是一個示例程式,演示如何使用 dropWhile 方法:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(3, 6, 9, 4, 2)
// print list
println(list)
//apply operation
val result = list.dropWhile(x=>{x % 3 == 0})
//print result
println(result)
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
List(3, 6, 9, 4, 2) List(4, 2)
Scala 集合 - Filter 方法
filter() 方法是 List 使用的方法,用於選擇滿足給定謂詞的所有元素。
語法
以下是 filter 方法的語法。
def filter(p: (A) => Boolean): List[A]
這裡,p: (A) => Boolean 是要應用於列表中每個元素的謂詞或條件。此方法返回滿足給定條件的列表中的所有元素。
用法
下面是一個示例程式,演示如何使用 filter 方法:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(3, 6, 9, 4, 2)
// print list
println(list)
//apply operation
val result = list.filter(x=>{x % 3 == 0})
//print result
println(result)
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
List(3, 6, 9, 4, 2) List(3, 6, 9)
Scala 集合 - Find 方法
find() 方法是迭代器使用的方法,用於查詢滿足給定謂詞的元素。
語法
以下是 find 方法的語法。
def find(p: (A) => Boolean): Option[A]
這裡,p: (A) => Boolean 是要應用於迭代器中每個元素的謂詞或條件。此方法返回包含滿足給定條件的迭代器的匹配元素的 Option 元素。
用法
下面是一個示例程式,演示如何使用 find 方法:
示例
object Demo {
def main(args: Array[String]) = {
val iterator = Iterator(3, 6, 9, 4, 2)
//apply operation
val result = iterator.find(x=>{x % 3 == 0})
//print result
println(result)
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
Some(3)
Scala 集合 - FlatMap 方法
flatMap() 方法是 TraversableLike 特徵的方法,它接受一個謂詞,將其應用於集合的每個元素,並返回謂詞返回的新元素集合。
語法
以下是 flatMap 方法的語法。
def flatMap[B](f: (A) ? GenTraversableOnce[B]): TraversableOnce[B]
這裡,f: (A) => GenTraversableOnce[B] 是要應用於集合中每個元素的謂詞或條件。此方法返回包含滿足給定條件的迭代器的匹配元素的 Option 元素。
用法
下面是一個示例程式,演示如何使用 flatMap 方法:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 5, 10)
//apply operation
val result = list.flatMap{x => List(x,x+1)}
//print result
println(result)
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
List(1, 2, 5, 6, 10, 11)
Scala 集合 - Flatten 方法
flatten() 方法是 GenericTraversableTemplate 特徵的成員,它透過合併子集合來返回單個元素集合。
語法
以下是 flatten 方法的語法。
def flatten[B]: Traversable[B]
這裡,f: (A) => GenTraversableOnce[B] 是要應用於集合中每個元素的謂詞或條件。此方法返回包含滿足給定條件的迭代器的匹配元素的 Option 元素。
用法
下面是一個示例程式,演示如何使用 flatten 方法:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(List(1,2), List(3,4))
//apply operation
val result = list.flatten
//print result
println(result)
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
List(1, 2, 3, 4)
Scala 集合 - Fold 方法
fold() 方法是 TraversableOnce 特徵的成員,它用於摺疊集合的元素。
語法
以下是 fold 方法的語法。
def fold[A1 >: A](z: A1)(op: (A1, A1) ? A1): A1
這裡,fold 方法將關聯二元運算子函式作為引數。此方法將結果作為值返回。它將第一個輸入視為初始值,將第二個輸入視為函式(它將累積值和當前項作為輸入)。
用法
下面是一個示例程式,演示如何使用 fold 方法:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3 ,4)
//apply operation to get sum of all elements of the list
val result = list.fold(0)(_ + _)
//print result
println(result)
}
}
這裡,我們將 0 作為初始值傳遞給 fold 函式,然後新增所有值。將上面的程式儲存在Demo.scala中。以下命令用於編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
10
Scala 集合 - FoldLeft 方法
foldLeft() 方法是 TraversableOnce 特性(trait)的成員,用於摺疊集合中的元素。它從左到右遍歷元素。主要用於遞迴函式,可以防止堆疊溢位異常。
語法
以下是 fold 方法的語法。
def foldLeft[B](z: B)(op: (B, A) ? B): B
這裡,foldLeft 方法接受一個關聯二元運算子函式作為引數。此方法返回結果值。
用法
下面是一個演示如何使用 foldLeft 方法的示例程式:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3 ,4)
//apply operation to get sum of all elements of the list
val result = list.foldLeft(0)(_ + _)
//print result
println(result)
}
}
這裡,我們將 0 作為初始值傳遞給 fold 函式,然後新增所有值。將上面的程式儲存在Demo.scala中。以下命令用於編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
10
Scala 集合 - foldRight 方法
foldRight() 方法是 TraversableOnce 特性的成員,用於摺疊集合中的元素。它從右到左遍歷元素。
語法
以下是 foldRight 方法的語法。
def foldRight[B](z: B)(op: (B, A) ? B): B
這裡,fold 方法接受一個關聯二元運算子函式作為引數。此方法返回結果值。
用法
下面是一個演示如何使用 foldRight 方法的示例程式:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3 ,4)
//apply operation to get sum of all elements of the list
val result = list.foldRight(0)(_ + _)
//print result
println(result)
}
}
這裡我們將 0 作為初始值傳遞給 foldRight 函式,然後將所有值相加。將上述程式儲存為 **Demo.scala** 檔案。使用以下命令編譯並執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
10
Scala 集合 - map 方法
map() 方法是 TraversableLike 特性的成員,用於對集合的每個元素執行一個謂詞方法。它返回一個新的集合。
語法
以下是 map 方法的語法。
def map[B](f: (A) ? B): Traversable[B]
這裡,map 方法接受一個謂詞函式作為引數。此方法返回更新後的集合。
用法
下面是一個演示如何使用 map 方法的示例程式:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3 ,4)
//apply operation to get twice of each element.
val result = list.map(_ * 2)
//print result
println(result)
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
List(2, 4, 6, 8)
Scala 集合 - partition 方法
partition() 方法是 TraversableLike 特性的成員,用於對集合的每個元素執行一個謂詞方法。它返回兩個集合,一個集合包含滿足給定謂詞函式的元素,另一個集合包含不滿足給定謂詞函式的元素。
語法
以下是 map 方法的語法。
def partition(p: (A) ? Boolean): (Repr, Repr)
這裡,partition 方法接受一個謂詞函式作為引數。此方法返回這些集合。
用法
下面是一個演示如何使用 partition 方法的示例程式:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3, 4, 5, 6, 7)
//apply operation to get twice of each element.
val (result1, result2) = list.partition(x=>{x % 3 == 0})
//print result
println(result1)
println(result2)
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
List(3, 6) List(1, 2, 4, 5, 7)
Scala 集合 - reduce 方法
reduce() 方法是 TraversableOnce 特性的成員,用於摺疊集合中的元素。它類似於 fold 方法,但它不接受初始值。
語法
以下是 reduce 方法的語法。
def reduce[A1 >: A](op: (A1, A1) ? A1): A1
這裡,reduce 方法接受一個關聯二元運算子函式作為引數。此方法返回結果值。
用法
下面是一個示例程式,演示如何使用 fold 方法:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3 ,4)
//apply operation to get sum of all elements of the list
val result = list.reduce(_ + _)
//print result
println(result)
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
10
Scala 集合 - scan 方法
scan() 方法是 TraversableLike 特性的成員,類似於 fold 方法,但用於對集合的每個元素應用一個操作並返回一個集合。
語法
以下是 fold 方法的語法。
def scan[B >: A, That](z: B)(op: (B, B) ? B)(implicit cbf: CanBuildFrom[Repr, B, That]): That
這裡,scan 方法接受一個關聯二元運算子函式作為引數。此方法返回更新後的集合作為結果。它將第一個輸入作為初始值,第二個輸入作為函式。
用法
下面是一個演示如何使用 scan 方法的示例程式:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3 ,4)
//apply operation to create a running total of all elements of the list
val list1 = list.scan(0)(_ + _)
//print list
println(list1)
}
}
這裡我們將 0 作為初始值傳遞給 scan 函式,然後將所有值相加。將上述程式儲存為 **Demo.scala** 檔案。使用以下命令編譯並執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
List(0, 1, 3, 6, 10)
Scala 集合 - zip 方法
zip() 方法是 IterableLike 特性的成員,用於將一個集合與當前集合合併,結果是一個包含來自兩個集合的成對元組元素的集合。
語法
以下是 zip 方法的語法。
def zip[B](that: GenIterable[B]): Iterable[(A, B)]
這裡,zip 方法接受一個集合作為引數。此方法返回更新後的成對集合作為結果。
用法
下面是一個演示如何使用 zip 方法的示例程式:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3 ,4)
val list1 = List("A", "B", "C", "D")
//apply operation to create a zip of list
val list2 = list zip list1
//print list
println(list2)
}
}
將上述程式儲存為**Demo.scala**。使用以下命令編譯和執行此程式。
命令
\>scalac Demo.scala \>scala Demo
輸出
List((1,A), (2,B), (3,C), (4,D))