- Python 網路爬取教程
- Python 網路爬取 - 首頁
- 介紹
- Python 入門
- 用於網路爬取的 Python 模組
- 網路爬取的合法性
- 資料提取
- 資料處理
- 處理影像和影片
- 處理文字
- 爬取動態網站
- 爬取基於表單的網站
- 處理驗證碼
- 使用爬蟲進行測試
- Python 網路爬取資源
- Python 網路爬取 - 快速指南
- Python 網路爬取 - 資源
- Python 網路爬取 - 討論
Python 網路爬取 - 快速指南
Python 網路爬取 - 介紹
網路爬取是從網路中自動提取資訊的過程。本章將深入介紹網路爬取,將其與網路爬蟲進行比較,並說明為什麼要選擇網路爬取。您還將瞭解網路爬蟲的元件和工作原理。
什麼是網路爬取?
“爬取”一詞的字典含義是指從網路獲取某些東西。這裡出現兩個問題:我們能從網路中獲取什麼以及如何獲取。
第一個問題的答案是“資料”。資料對於任何程式設計師來說都是不可或缺的,每個程式設計專案的首要需求都是大量有用的資料。
第二個問題的答案有點棘手,因為獲取資料的方法有很多。通常,我們可以從資料庫或資料檔案以及其他來源獲取資料。但是,如果我們需要大量線上可用的資料呢?獲取此類資料的一種方法是手動搜尋(在網頁瀏覽器中點選)並儲存(複製貼上到電子表格或檔案中)所需資料。這種方法非常繁瑣且耗時。另一種獲取此類資料的方法是使用網路爬取。
網路爬取,也稱為網路資料探勘或網路採集,是構建一個能夠自動提取、解析、下載和整理網路上有用資訊的代理的過程。換句話說,我們可以說,與其手動從網站儲存資料,不如讓網路爬取軟體根據我們的要求自動載入和提取來自多個網站的資料。
網路爬取的起源
網路爬取起源於螢幕抓取,用於整合非基於網路的應用程式或本機 Windows 應用程式。最初,螢幕抓取在全球資訊網 (WWW) 廣泛使用之前就被使用,但它無法擴充套件 WWW 的擴充套件。這使得自動化螢幕抓取方法成為必要,並出現了名為“網路爬取”的技術。
網路爬蟲與網路爬取
術語“網路爬蟲”和“網路爬取”通常可以互換使用,因為它們的根本概念都是提取資料。但是,它們彼此之間存在差異。我們可以從它們的定義中瞭解基本區別。
網路爬蟲基本上用於使用機器人(即爬蟲)索引頁面上的資訊。它也稱為索引。另一方面,網路爬取是使用機器人(即爬蟲)自動提取資訊的一種方式。它也稱為資料提取。
為了理解這兩個術語之間的區別,讓我們看一下下面給出的比較表:
| 網路爬蟲 | 網路爬取 |
|---|---|
| 指下載和儲存大量網站的內容。 | 指透過使用特定於站點的結構從網站提取單個數據元素。 |
| 主要在大規模進行。 | 可以在任何規模上實施。 |
| 產生通用資訊。 | 產生特定資訊。 |
| 由 Google、Bing、Yahoo 等主要搜尋引擎使用。Googlebot 是網路爬蟲的一個示例。 | 使用網路爬取提取的資訊可以用於複製到其他網站,也可以用於執行資料分析。例如,資料元素可以是姓名、地址、價格等。 |
網路爬取的用途
使用網路爬取的用途和原因與全球資訊網的用途一樣多。網路爬蟲可以執行任何操作,例如線上訂購食物、為您掃描線上購物網站以及在門票可用時立即購買比賽門票等,就像人類可以做的那樣。這裡討論了一些網路爬取的重要用途:
電子商務網站 - 網路爬蟲可以從各種電子商務網站收集與特定產品價格相關的資料,以便進行比較。
內容聚合器 - 網路爬取被新聞聚合器和工作聚合器等內容聚合器廣泛使用,以便為其使用者提供更新的資料。
營銷和銷售活動 - 網路爬蟲可以用於獲取電子郵件、電話號碼等資料,用於銷售和營銷活動。
搜尋引擎最佳化 (SEO) - 網路爬取被 SEMRush、Majestic 等 SEO 工具廣泛使用,以告知企業他們在對其重要的搜尋關鍵詞方面的排名。
機器學習專案的資料 - 機器學習專案的檢索資料依賴於網路爬取。
研究資料 - 研究人員可以透過此自動化流程節省時間,收集對其研究工作有用的資料。
網路爬蟲的元件
網路爬蟲包括以下元件:
網路爬蟲模組
網路爬蟲模組是網路爬蟲的一個非常必要的元件,用於透過向 URL 發出 HTTP 或 HTTPS 請求來導航目標網站。爬蟲下載非結構化資料(HTML 內容)並將其傳遞給提取器,即下一個模組。
提取器
提取器處理獲取的 HTML 內容並將資料提取為半結構化格式。這也被稱為解析器模組,並使用不同的解析技術(如正則表示式、HTML 解析、DOM 解析或人工智慧)來實現其功能。
資料轉換和清理模組
上面提取的資料不適合直接使用。它必須透過一些清理模組,以便我們可以使用它。字串操作或正則表示式等方法可用於此目的。請注意,提取和轉換也可以在一個步驟中完成。
儲存模組
提取資料後,我們需要根據我們的要求儲存它。儲存模組將以標準格式輸出資料,該格式可以儲存在資料庫或 JSON 或 CSV 格式中。
網路爬蟲的工作原理
網路爬蟲可以定義為用於下載多個網頁的內容並從中提取資料的軟體或指令碼。
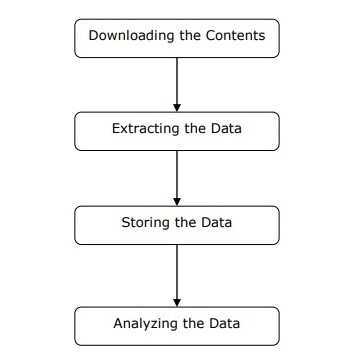
我們可以按照上面給出的圖中所示的簡單步驟來了解網路爬蟲的工作原理。
步驟 1:從網頁下載內容
在此步驟中,網路爬蟲將從多個網頁下載請求的內容。
步驟 2:提取資料
網站上的資料是 HTML,並且大部分是非結構化的。因此,在此步驟中,網路爬蟲將解析並從下載的內容中提取結構化資料。
步驟 3:儲存資料
在這裡,網路爬蟲將以 CSV、JSON 或資料庫等任何格式儲存和儲存提取的資料。
步驟 4:分析資料
在所有這些步驟成功完成後,網路爬蟲將分析獲得的資料。
Python 入門
在第一章中,我們學習了網路爬取的基本知識。在本章中,讓我們看看如何使用 Python 實現網路爬取。
為什麼選擇 Python 進行網路爬取?
Python 是實現網路爬取的常用工具。Python 程式語言還用於其他與網路安全、滲透測試以及數字取證應用程式相關的有用專案。使用 Python 的基礎程式設計,可以在不使用任何其他第三方工具的情況下執行網路爬取。
Python 程式語言正在迅速普及,以下是一些使 Python 非常適合網路爬取專案的原因:
語法簡單
與其他程式語言相比,Python 具有最簡單的結構。Python 的這一特性使測試更容易,開發人員可以更加專注於程式設計。
內建模組
使用 Python 進行網路爬取的另一個原因是它擁有內建的和外部的有用庫。我們可以使用 Python 作為程式設計基礎來執行許多與網路爬取相關的實現。
開源程式語言
由於 Python 是一種開源程式語言,因此它得到了社群的大力支援。
廣泛的應用範圍
Python 可用於各種程式設計任務,從小型 shell 指令碼到企業 Web 應用程式。
Python 的安裝
Python 發行版適用於 Windows、MAC 和 Unix/Linux 等平臺。我們只需要下載適用於我們平臺的二進位制程式碼即可安裝 Python。但是,如果我們的平臺沒有可用的二進位制程式碼,則我們必須擁有 C 編譯器,以便手動編譯原始碼。
我們可以在各種平臺上安裝 Python,如下所示:
在 Unix 和 Linux 上安裝 Python
您需要按照以下步驟在 Unix/Linux 機器上安裝 Python:
步驟 1 - 轉到連結 https://python.club.tw/downloads/
步驟 2 - 下載上面連結中提供的適用於 Unix/Linux 的壓縮原始碼。
步驟 3 - 將檔案解壓縮到您的計算機上。
步驟 4 - 使用以下命令完成安裝:
run ./configure script make make install
您可以在標準位置/usr/local/bin找到已安裝的 Python,並在/usr/local/lib/pythonXX找到其庫,其中 XX 是 Python 的版本。
在 Windows 上安裝 Python
您需要按照以下步驟在 Windows 機器上安裝 Python:
步驟 1 - 轉到連結 https://python.club.tw/downloads/
步驟 2 - 下載 Windows 安裝程式python-XYZ.msi檔案,其中 XYZ 是我們需要安裝的版本。
步驟 3 - 現在,將安裝程式檔案儲存到本地計算機並執行 MSI 檔案。
步驟 4 - 最後,執行下載的檔案以調出 Python 安裝嚮導。
在 Macintosh 上安裝 Python
我們必須使用Homebrew在 Mac OS X 上安裝 Python 3。Homebrew 易於安裝,是一個很棒的軟體包安裝程式。
也可以使用以下命令安裝 Homebrew:
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
要更新軟體包管理器,我們可以使用以下命令:
$ brew update
藉助以下命令,我們可以在 MAC 機器上安裝 Python3:
$ brew install python3
設定 PATH
您可以使用以下說明在各種環境中設定路徑:
在 Unix/Linux 上設定路徑
使用以下命令使用各種命令 shell 設定路徑:
對於 csh shell
setenv PATH "$PATH:/usr/local/bin/python".
對於 bash shell (Linux)
ATH="$PATH:/usr/local/bin/python".
對於 sh 或 ksh shell
PATH="$PATH:/usr/local/bin/python".
在 Windows 上設定路徑
在Windows上設定路徑,可以在命令提示符下使用路徑%path%;C:\Python,然後按Enter鍵。
執行Python
我們可以透過以下三種方式之一啟動Python:
互動式直譯器
可以使用提供命令列直譯器或shell的作業系統(如UNIX和DOS)來啟動Python。
我們可以按照以下步驟在互動式直譯器中開始編碼:
步驟1 - 在命令列中輸入python。
步驟2 - 然後,我們可以在互動式直譯器中立即開始編碼。
$python # Unix/Linux or python% # Unix/Linux or C:> python # Windows/DOS
從命令列執行指令碼
我們可以透過呼叫直譯器在命令列中執行Python指令碼。可以理解為:
$python script.py # Unix/Linux or python% script.py # Unix/Linux or C: >python script.py # Windows/DOS
整合開發環境
如果系統具有支援Python的GUI應用程式,我們也可以從GUI環境中執行Python。以下是一些在各種平臺上支援Python的IDE:
UNIX的IDE - UNIX的Python IDE是IDLE。
Windows的IDE - Windows的Python IDE是PythonWin,它也具有GUI。
Macintosh的IDE - Macintosh的Python IDE是IDLE,可以從主網站下載MacBinary或BinHex'd檔案。
用於網路爬取的 Python 模組
在本章中,讓我們學習各種可用於網頁抓取的Python模組。
使用virtualenv的Python開發環境
Virtualenv是一個建立隔離的Python環境的工具。藉助virtualenv,我們可以建立一個包含所有必要可執行檔案的資料夾,以使用Python專案所需的包。它還允許我們新增和修改Python模組,而無需訪問全域性安裝。
可以使用以下命令安裝virtualenv:
(base) D:\ProgramData>pip install virtualenv Collecting virtualenv Downloading https://files.pythonhosted.org/packages/b6/30/96a02b2287098b23b875bc8c2f58071c3 5d2efe84f747b64d523721dc2b5/virtualenv-16.0.0-py2.py3-none-any.whl (1.9MB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 1.9MB 86kB/s Installing collected packages: virtualenv Successfully installed virtualenv-16.0.0
現在,我們需要使用以下命令建立一個目錄,該目錄將代表專案:
(base) D:\ProgramData>mkdir webscrap
現在,使用以下命令進入該目錄:
(base) D:\ProgramData>cd webscrap
現在,我們需要按照以下方式初始化我們選擇的虛擬環境資料夾:
(base) D:\ProgramData\webscrap>virtualenv websc Using base prefix 'd:\\programdata' New python executable in D:\ProgramData\webscrap\websc\Scripts\python.exe Installing setuptools, pip, wheel...done.
現在,使用以下命令啟用虛擬環境。啟用成功後,您將在左側括號中看到其名稱。
(base) D:\ProgramData\webscrap>websc\scripts\activate
我們可以按照以下方式在此環境中安裝任何模組:
(websc) (base) D:\ProgramData\webscrap>pip install requests Collecting requests Downloading https://files.pythonhosted.org/packages/65/47/7e02164a2a3db50ed6d8a6ab1d6d60b69 c4c3fdf57a284257925dfc12bda/requests-2.19.1-py2.py3-none-any.whl (9 1kB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 148kB/s Collecting chardet<3.1.0,>=3.0.2 (from requests) Downloading https://files.pythonhosted.org/packages/bc/a9/01ffebfb562e4274b6487b4bb1ddec7ca 55ec7510b22e4c51f14098443b8/chardet-3.0.4-py2.py3-none-any.whl (133 kB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 143kB 369kB/s Collecting certifi>=2017.4.17 (from requests) Downloading https://files.pythonhosted.org/packages/df/f7/04fee6ac349e915b82171f8e23cee6364 4d83663b34c539f7a09aed18f9e/certifi-2018.8.24-py2.py3-none-any.whl (147kB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 153kB 527kB/s Collecting urllib3<1.24,>=1.21.1 (from requests) Downloading https://files.pythonhosted.org/packages/bd/c9/6fdd990019071a4a32a5e7cb78a1d92c5 3851ef4f56f62a3486e6a7d8ffb/urllib3-1.23-py2.py3-none-any.whl (133k B) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 143kB 517kB/s Collecting idna<2.8,>=2.5 (from requests) Downloading https://files.pythonhosted.org/packages/4b/2a/0276479a4b3caeb8a8c1af2f8e4355746 a97fab05a372e4a2c6a6b876165/idna-2.7-py2.py3-none-any.whl (58kB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 61kB 339kB/s Installing collected packages: chardet, certifi, urllib3, idna, requests Successfully installed certifi-2018.8.24 chardet-3.0.4 idna-2.7 requests-2.19.1 urllib3-1.23
要停用虛擬環境,可以使用以下命令:
(websc) (base) D:\ProgramData\webscrap>deactivate (base) D:\ProgramData\webscrap>
您可以看到(websc)已停用。
用於網路爬取的 Python 模組
網頁抓取是構建一個代理的過程,該代理可以自動從網路中提取、解析、下載和組織有用的資訊。換句話說,網頁抓取軟體會根據我們的需求自動載入和提取來自多個網站的資料,而不是手動從網站儲存資料。
在本節中,我們將討論一些有用的Python庫,用於網頁抓取。
Requests
這是一個簡單的Python網頁抓取庫。它是一個高效的HTTP庫,用於訪問網頁。藉助Requests,我們可以獲取網頁的原始HTML,然後對其進行解析以檢索資料。在使用requests之前,讓我們瞭解其安裝。
安裝Requests
我們可以將其安裝在虛擬環境或全域性安裝中。藉助pip命令,我們可以輕鬆地按如下方式安裝它:
(base) D:\ProgramData> pip install requests Collecting requests Using cached https://files.pythonhosted.org/packages/65/47/7e02164a2a3db50ed6d8a6ab1d6d60b69 c4c3fdf57a284257925dfc12bda/requests-2.19.1-py2.py3-none-any.whl Requirement already satisfied: idna<2.8,>=2.5 in d:\programdata\lib\sitepackages (from requests) (2.6) Requirement already satisfied: urllib3<1.24,>=1.21.1 in d:\programdata\lib\site-packages (from requests) (1.22) Requirement already satisfied: certifi>=2017.4.17 in d:\programdata\lib\sitepackages (from requests) (2018.1.18) Requirement already satisfied: chardet<3.1.0,>=3.0.2 in d:\programdata\lib\site-packages (from requests) (3.0.4) Installing collected packages: requests Successfully installed requests-2.19.1
示例
在此示例中,我們正在對網頁發出GET HTTP請求。為此,我們需要首先匯入requests庫,如下所示:
In [1]: import requests
在以下程式碼行中,我們使用requests對URL:https://authoraditiagarwal.com/ 發出GET HTTP請求。
In [2]: r = requests.get('https://authoraditiagarwal.com/')
現在,我們可以使用.text屬性檢索內容,如下所示:
In [5]: r.text[:200]
請注意,在以下輸出中,我們獲得了前200個字元。
Out[5]: '<!DOCTYPE html>\n<html lang="en-US"\n\titemscope \n\titemtype="http://schema.org/WebSite" \n\tprefix="og: http://ogp.me/ns#" >\n<head>\n\t<meta charset ="UTF-8" />\n\t<meta http-equiv="X-UA-Compatible" content="IE'
Urllib3
它是另一個Python庫,可用於從URL檢索資料,類似於requests庫。您可以在其技術文件https://urllib3.readthedocs.io/en/latest/中瞭解更多資訊。
安裝Urllib3
使用pip命令,我們可以將urllib3安裝到虛擬環境或全域性安裝中。
(base) D:\ProgramData>pip install urllib3 Collecting urllib3 Using cached https://files.pythonhosted.org/packages/bd/c9/6fdd990019071a4a32a5e7cb78a1d92c5 3851ef4f56f62a3486e6a7d8ffb/urllib3-1.23-py2.py3-none-any.whl Installing collected packages: urllib3 Successfully installed urllib3-1.23
示例:使用Urllib3和BeautifulSoup進行抓取
在以下示例中,我們使用Urllib3和BeautifulSoup來抓取網頁。我們使用Urllib3代替requests庫從網頁獲取原始資料(HTML)。然後,我們使用BeautifulSoup解析該HTML資料。
import urllib3
from bs4 import BeautifulSoup
http = urllib3.PoolManager()
r = http.request('GET', 'https://authoraditiagarwal.com')
soup = BeautifulSoup(r.data, 'lxml')
print (soup.title)
print (soup.title.text)
這是執行此程式碼時將觀察到的輸出:
<title>Learn and Grow with Aditi Agarwal</title> Learn and Grow with Aditi Agarwal
Selenium
它是一個開源的Web應用程式自動化測試套件,適用於不同的瀏覽器和平臺。它不是單個工具,而是一套軟體。我們有適用於Python、Java、C#、Ruby和JavaScript的Selenium繫結。在這裡,我們將使用selenium及其Python繫結執行網頁抓取。您可以在連結Selenium上了解有關Selenium與Java的更多資訊。
Selenium Python繫結提供了一個方便的API來訪問Selenium WebDrivers,如Firefox、IE、Chrome、Remote等。當前支援的Python版本為2.7、3.5及以上。
安裝Selenium
使用pip命令,我們可以將urllib3安裝到虛擬環境或全域性安裝中。
pip install selenium
由於selenium需要一個驅動程式來與所選瀏覽器互動,因此我們需要下載它。下表顯示了不同的瀏覽器及其下載連結。
Chrome |
|
Edge |
|
Firefox |
|
Safari |
示例
此示例演示了使用selenium進行網頁抓取。它也可用於測試,稱為selenium測試。
下載特定瀏覽器指定版本的驅動程式後,我們需要用Python進行程式設計。
首先,需要從selenium匯入webdriver,如下所示:
from selenium import webdriver
現在,提供我們根據需要下載的Web驅動程式的路徑:
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver' browser = webdriver.Chrome(executable_path = path)
現在,提供我們希望在現在由Python指令碼控制的Web瀏覽器中開啟的URL。
browser.get('https://authoraditiagarwal.com/leadershipmanagement')
我們還可以透過提供lxml中提供的xpath來抓取特定元素。
browser.find_element_by_xpath('/html/body').click()
您可以檢查由Python指令碼控制的瀏覽器以獲取輸出。
Scrapy
Scrapy是一個用Python編寫的快速、開源的Web爬取框架,用於藉助基於XPath的選擇器從網頁中提取資料。Scrapy於2008年6月26日首次釋出,根據BSD許可,並在2015年6月釋出了1.0里程碑版本。它為我們提供了從網站提取、處理和構建資料所需的所有工具。
安裝Scrapy
使用pip命令,我們可以將urllib3安裝到虛擬環境或全域性安裝中。
pip install scrapy
有關Scrapy的更多詳細研究,您可以訪問連結Scrapy
網路爬取的合法性
使用Python,我們可以抓取任何網站或網頁的特定元素,但您是否知道這是否合法?在抓取任何網站之前,我們必須瞭解網頁抓取的合法性。本章將解釋與網頁抓取的合法性相關的概念。
介紹
通常,如果您要將抓取的資料用於個人用途,則可能不會有任何問題。但是,如果您要重新發布該資料,則在執行此操作之前,應向所有者發出下載請求或對相關政策以及您要抓取的資料進行一些背景調查。
抓取前所需的調查
如果您要針對某個網站進行資料抓取,我們需要了解其規模和結構。以下是在開始網頁抓取之前需要分析的一些檔案。
分析robots.txt
實際上,大多數釋出者允許程式設計師在一定程度上抓取其網站。換句話說,釋出者希望抓取網站的特定部分。為了定義這一點,網站必須制定一些規則來說明哪些部分可以抓取,哪些部分不能抓取。此類規則定義在一個名為robots.txt的檔案中。
robots.txt是一個人類可讀的檔案,用於識別爬蟲允許和不允許抓取的網站部分。robots.txt檔案沒有標準格式,網站釋出者可以根據需要進行修改。我們可以透過在網站URL後提供斜槓和robots.txt來檢查特定網站的robots.txt檔案。例如,如果要檢查Google.com,則需要鍵入https://www.google.com/robots.txt,我們將獲得如下內容:
User-agent: * Disallow: /search Allow: /search/about Allow: /search/static Allow: /search/howsearchworks Disallow: /sdch Disallow: /groups Disallow: /index.html? Disallow: /? Allow: /?hl= Disallow: /?hl=*& Allow: /?hl=*&gws_rd=ssl$ and so on……..
網站robots.txt檔案中定義的一些最常見的規則如下:
User-agent: BadCrawler Disallow: /
以上規則表示robots.txt檔案要求具有BadCrawler使用者代理的爬蟲不要抓取其網站。
User-agent: * Crawl-delay: 5 Disallow: /trap
以上規則表示robots.txt檔案將所有使用者代理的下載請求之間的延遲設定為5秒,以避免伺服器過載。/trap連結將嘗試阻止遵循禁止連結的惡意爬蟲。釋出者可以根據其需求定義更多規則。其中一些在此處討論:
分析Sitemap檔案
如果您想抓取網站以獲取更新的資訊,應該怎麼做?您將抓取每個網頁以獲取該更新的資訊,但這會增加特定網站的伺服器流量。這就是為什麼網站提供sitemap檔案以幫助爬蟲定位更新內容,而無需抓取每個網頁。Sitemap標準定義在http://www.sitemaps.org/protocol.html。
Sitemap檔案的內容
以下是https://www.microsoft.com/robots.txt的sitemap檔案的內容,該檔案是在robot.txt檔案中發現的:
Sitemap: https://www.microsoft.com/en-us/explore/msft_sitemap_index.xml Sitemap: https://www.microsoft.com/learning/sitemap.xml Sitemap: https://www.microsoft.com/en-us/licensing/sitemap.xml Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8 Sitemap: https://www.microsoft.com/store/collections.xml Sitemap: https://www.microsoft.com/store/productdetailpages.index.xml Sitemap: https://www.microsoft.com/en-us/store/locations/store-locationssitemap.xml
以上內容表明sitemap列出了網站上的URL,並進一步允許網站管理員為每個URL指定一些其他資訊,例如上次更新日期、內容更改、與其他URL相關的URL重要性等。
網站的大小是多少?
網站的大小(即網站的網頁數量)是否會影響我們的抓取方式?當然是的。因為如果我們要抓取的網頁數量較少,那麼效率不會成為嚴重問題,但假設我們的網站有數百萬個網頁,例如Microsoft.com,那麼按順序下載每個網頁將需要幾個月的時間,然後效率就會成為嚴重問題。
檢查網站的大小
透過檢查Google爬蟲結果的大小,我們可以估計網站的大小。在進行Google搜尋時,可以使用關鍵字site過濾我們的結果。例如,下面給出了估計https://authoraditiagarwal.com/大小的方法:
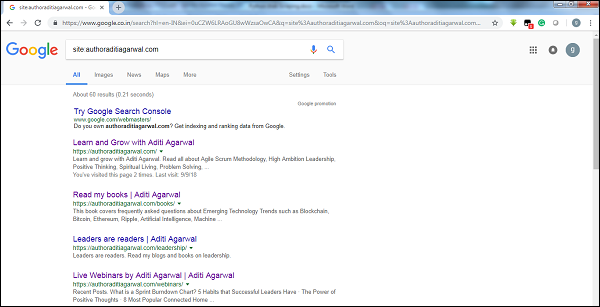
您可以看到大約有60個結果,這意味著它不是一個大型網站,抓取不會導致效率問題。
網站使用什麼技術?
另一個重要的問題是,網站使用的技術是否會影響我們的爬取方式?答案是會的。但是我們如何檢查網站使用的技術呢?有一個名為builtwith的Python庫可以幫助我們找出網站使用的技術。
示例
在這個例子中,我們將使用Python庫builtwith來檢查網站https://authoraditiagarwal.com使用的技術。但在使用此庫之前,我們需要按照以下步驟安裝它:
(base) D:\ProgramData>pip install builtwith Collecting builtwith Downloading https://files.pythonhosted.org/packages/9b/b8/4a320be83bb3c9c1b3ac3f9469a5d66e0 2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz Requirement already satisfied: six in d:\programdata\lib\site-packages (from builtwith) (1.10.0) Building wheels for collected packages: builtwith Running setup.py bdist_wheel for builtwith ... done Stored in directory: C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b f926764a924873e0304f10b2524 Successfully built builtwith Installing collected packages: builtwith Successfully installed builtwith-1.3.3
現在,藉助以下幾行簡單的程式碼,我們可以檢查特定網站使用的技術:
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}
網站的所有者是誰?
網站的所有者也很重要,因為如果所有者以阻止爬蟲而聞名,那麼爬蟲在從網站抓取資料時必須小心。有一個名為Whois的協議可以幫助我們找到網站的所有者。
示例
在這個例子中,我們將使用Whois來檢查網站microsoft.com的所有者。但在使用此庫之前,我們需要按照以下步驟安裝它:
(base) D:\ProgramData>pip install python-whois Collecting python-whois Downloading https://files.pythonhosted.org/packages/63/8a/8ed58b8b28b6200ce1cdfe4e4f3bbc8b8 5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s Requirement already satisfied: future in d:\programdata\lib\site-packages (from python-whois) (0.16.0) Building wheels for collected packages: python-whois Running setup.py bdist_wheel for python-whois ... done Stored in directory: C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b 4dcc81ab212a3d5e52ab32dc531 Successfully built python-whois Installing collected packages: python-whois Successfully installed python-whois-0.7.0
現在,藉助以下幾行簡單的程式碼,我們可以檢查特定網站使用的技術:
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"abusecomplaints@markmonitor.com",
"domains@microsoft.com",
"msnhst@microsoft.com",
"whoisrelay@markmonitor.com"
],
}
Python網頁抓取 - 資料提取
分析網頁意味著理解其結構。現在,問題出現了,為什麼這對網頁抓取很重要?在本章中,讓我們詳細瞭解一下。
網頁分析
網頁分析很重要,因為如果不進行分析,我們就無法知道在提取後,我們將以何種形式(結構化或非結構化)從該網頁接收資料。我們可以透過以下方式進行網頁分析:
檢視頁面原始碼
這是一種透過檢查頁面原始碼來了解網頁結構的方式。要實現這一點,我們需要右鍵單擊頁面,然後選擇“檢視頁面原始碼”選項。然後,我們將以HTML的形式從該網頁獲取我們感興趣的資料。但主要問題是關於空格和格式,這對於我們來說很難格式化。
透過單擊“檢查元素”選項檢查頁面原始碼
這是另一種分析網頁的方式。但不同之處在於,它將解決網頁原始碼中格式和空格的問題。您可以透過右鍵單擊,然後從選單中選擇“檢查”或“檢查元素”選項來實現此功能。它將提供有關該網頁特定區域或元素的資訊。
從網頁提取資料的不同方法
以下方法主要用於從網頁提取資料:
正則表示式
它們是嵌入在Python中的高度專業化的程式語言。我們可以透過Python的re模組使用它。它也稱為RE、regexes或regex模式。藉助正則表示式,我們可以為我們想要從資料中匹配的可能的字串集指定一些規則。
如果您想更全面地瞭解正則表示式,請訪問連結https://tutorialspoint.tw/automata_theory/regular_expressions.htm,如果您想了解更多關於re模組或Python中正則表示式的知識,您可以訪問連結https://tutorialspoint.tw/python/python_reg_expressions.htm。
示例
在下面的示例中,我們將使用正則表示式匹配<td>的內容,從http://example.webscraping.com 抓取有關印度的資料。
import re
import urllib.request
response =
urllib.request.urlopen('http://example.webscraping.com/places/default/view/India-102')
html = response.read()
text = html.decode()
re.findall('<td class="w2p_fw">(.*?)</td>',text)
輸出
相應的輸出將如下所示:
[
'<img src="/places/static/images/flags/in.png" />',
'3,287,590 square kilometres',
'1,173,108,018',
'IN',
'India',
'New Delhi',
'<a href="/places/default/continent/AS">AS</a>',
'.in',
'INR',
'Rupee',
'91',
'######',
'^(\\d{6})$',
'enIN,hi,bn,te,mr,ta,ur,gu,kn,ml,or,pa,as,bh,sat,ks,ne,sd,kok,doi,mni,sit,sa,fr,lus,inc',
'<div>
<a href="/places/default/iso/CN">CN </a>
<a href="/places/default/iso/NP">NP </a>
<a href="/places/default/iso/MM">MM </a>
<a href="/places/default/iso/BT">BT </a>
<a href="/places/default/iso/PK">PK </a>
<a href="/places/default/iso/BD">BD </a>
</div>'
]
觀察上面輸出,您可以看到使用正則表示式獲取的關於印度國家的資訊。
Beautiful Soup
假設我們想從網頁中收集所有超連結,那麼我們可以使用一個名為BeautifulSoup的解析器,可以在https://www.crummy.com/software/BeautifulSoup/bs4/doc/.中詳細瞭解。簡單來說,BeautifulSoup是一個用於從HTML和XML檔案中提取資料的Python庫。它可以與requests一起使用,因為它需要一個輸入(文件或URL)來建立soup物件,因為它本身無法獲取網頁。您可以使用以下Python指令碼收集網頁標題和超連結。
安裝Beautiful Soup
使用pip命令,我們可以在虛擬環境或全域性安裝中安裝beautifulsoup。
(base) D:\ProgramData>pip install bs4 Collecting bs4 Downloading https://files.pythonhosted.org/packages/10/ed/7e8b97591f6f456174139ec089c769f89 a94a1a4025fe967691de971f314/bs4-0.0.1.tar.gz Requirement already satisfied: beautifulsoup4 in d:\programdata\lib\sitepackages (from bs4) (4.6.0) Building wheels for collected packages: bs4 Running setup.py bdist_wheel for bs4 ... done Stored in directory: C:\Users\gaurav\AppData\Local\pip\Cache\wheels\a0\b0\b2\4f80b9456b87abedbc0bf2d 52235414c3467d8889be38dd472 Successfully built bs4 Installing collected packages: bs4 Successfully installed bs4-0.0.1
示例
請注意,在這個例子中,我們擴充套件了之前用requests python模組實現的例子。我們使用r.text來建立一個soup物件,該物件將進一步用於獲取網頁標題等詳細資訊。
首先,我們需要匯入必要的Python模組:
import requests from bs4 import BeautifulSoup
在以下程式碼行中,我們使用requests對URL:https://authoraditiagarwal.com/發出GET HTTP請求。
r = requests.get('https://authoraditiagarwal.com/')
現在我們需要建立一個Soup物件,如下所示:
soup = BeautifulSoup(r.text, 'lxml') print (soup.title) print (soup.title.text)
輸出
相應的輸出將如下所示:
<title>Learn and Grow with Aditi Agarwal</title> Learn and Grow with Aditi Agarwal
Lxml
我們將要討論的另一個用於網頁抓取的Python庫是lxml。它是一個高效能的HTML和XML解析庫。它相對快速且簡單。您可以在https://lxml.de/上了解更多資訊。
安裝lxml
使用pip命令,我們可以在虛擬環境或全域性安裝中安裝lxml。
(base) D:\ProgramData>pip install lxml Collecting lxml Downloading https://files.pythonhosted.org/packages/b9/55/bcc78c70e8ba30f51b5495eb0e 3e949aa06e4a2de55b3de53dc9fa9653fa/lxml-4.2.5-cp36-cp36m-win_amd64.whl (3. 6MB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 3.6MB 64kB/s Installing collected packages: lxml Successfully installed lxml-4.2.5
示例:使用lxml和requests提取資料
在以下示例中,我們使用lxml和requests從authoraditiagarwal.com抓取網頁的特定元素:
首先,我們需要匯入requests和來自lxml庫的html,如下所示:
import requests from lxml import html
現在我們需要提供要抓取的網頁的URL
url = https://authoraditiagarwal.com/leadershipmanagement/
現在我們需要提供到該網頁特定元素的路徑(Xpath):
path = '//*[@id="panel-836-0-0-1"]/div/div/p[1]' response = requests.get(url) byte_string = response.content source_code = html.fromstring(byte_string) tree = source_code.xpath(path) print(tree[0].text_content())
輸出
相應的輸出將如下所示:
The Sprint Burndown or the Iteration Burndown chart is a powerful tool to communicate daily progress to the stakeholders. It tracks the completion of work for a given sprint or an iteration. The horizontal axis represents the days within a Sprint. The vertical axis represents the hours remaining to complete the committed work.
Python網頁抓取 - 資料處理
在前面的章節中,我們學習瞭如何使用各種Python模組從網頁或網頁抓取資料。在本章中,讓我們深入瞭解處理已抓取資料的各種技術。
介紹
要處理已抓取的資料,我們必須以特定的格式(如電子表格(CSV)、JSON或有時是像MySQL這樣的資料庫)將資料儲存在本地機器上。
CSV和JSON資料處理
首先,我們將從網頁抓取的資訊寫入CSV檔案或電子表格。讓我們首先透過一個簡單的示例來理解,在這個示例中,我們將首先使用BeautifulSoup模組(如前所述)抓取資訊,然後使用Python CSV模組將文字資訊寫入CSV檔案。
首先,我們需要匯入必要的Python庫,如下所示:
import requests from bs4 import BeautifulSoup import csv
在以下程式碼行中,我們使用requests對URL:https://authoraditiagarwal.com/ 發出GET HTTP請求。
r = requests.get('https://authoraditiagarwal.com/')
現在,我們需要建立一個Soup物件,如下所示:
soup = BeautifulSoup(r.text, 'lxml')
現在,藉助以下幾行程式碼,我們將抓取的資料寫入名為dataprocessing.csv的CSV檔案。
f = csv.writer(open(' dataprocessing.csv ','w'))
f.writerow(['Title'])
f.writerow([soup.title.text])
執行此指令碼後,網頁的文字資訊或標題將儲存在您本地機器上上述CSV檔案中。
類似地,我們可以將收集到的資訊儲存在JSON檔案中。以下是易於理解的Python指令碼,用於執行相同的操作,其中我們將抓取與上一個Python指令碼中相同的資訊,但這次抓取的資訊使用JSON Python模組儲存在JSONfile.txt中。
import requests
from bs4 import BeautifulSoup
import csv
import json
r = requests.get('https://authoraditiagarwal.com/')
soup = BeautifulSoup(r.text, 'lxml')
y = json.dumps(soup.title.text)
with open('JSONFile.txt', 'wt') as outfile:
json.dump(y, outfile)
執行此指令碼後,抓取的資訊(即網頁標題)將儲存在您本地機器上上述文字檔案中。
使用AWS S3進行資料處理
有時我們可能希望將抓取的資料儲存在本地儲存中以供存檔。但是,如果我們需要大規模儲存和分析這些資料怎麼辦?答案是名為Amazon S3或AWS S3(簡單儲存服務)的雲端儲存服務。基本上,AWS S3是一個物件儲存,旨在從任何地方儲存和檢索任意數量的資料。
我們可以按照以下步驟將資料儲存在AWS S3中:
步驟1 - 首先,我們需要一個AWS賬戶,它將為我們在Python指令碼中儲存資料時提供金鑰。它將在其中我們可以儲存資料的S3儲存桶中建立。
步驟2 - 接下來,我們需要安裝boto3 Python庫來訪問S3儲存桶。可以使用以下命令安裝:
pip install boto3
步驟3 - 接下來,我們可以使用以下Python指令碼從網頁抓取資料並將其儲存到AWS S3儲存桶中。
首先,我們需要匯入用於抓取的Python庫,這裡我們使用requests,以及boto3將資料儲存到S3儲存桶中。
import requests import boto3
現在我們可以從我們的URL抓取資料。
data = requests.get("Enter the URL").text
現在為了將資料儲存到S3儲存桶,我們需要建立S3客戶端,如下所示:
s3 = boto3.client('s3')
bucket_name = "our-content"
下一行程式碼將建立S3儲存桶,如下所示:
s3.create_bucket(Bucket = bucket_name, ACL = 'public-read') s3.put_object(Bucket = bucket_name, Key = '', Body = data, ACL = "public-read")
現在您可以從您的AWS賬戶中檢查名為our-content的儲存桶。
使用MySQL進行資料處理
讓我們學習如何使用MySQL處理資料。如果您想了解MySQL,可以訪問連結https://tutorialspoint.tw/mysql/.
藉助以下步驟,我們可以將抓取的資料處理到MySQL表中:
步驟1 - 首先,使用MySQL我們需要建立一個數據庫和一個表,我們希望將抓取的資料儲存到其中。例如,我們使用以下查詢建立表:
CREATE TABLE Scrap_pages (id BIGINT(7) NOT NULL AUTO_INCREMENT, title VARCHAR(200), content VARCHAR(10000),PRIMARY KEY(id));
步驟2 - 接下來,我們需要處理Unicode。請注意,MySQL預設不處理Unicode。我們需要使用以下命令開啟此功能,這將更改資料庫、表和兩個列的預設字元集:
ALTER DATABASE scrap CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci; ALTER TABLE Scrap_pages CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; ALTER TABLE Scrap_pages CHANGE title title VARCHAR(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; ALTER TABLE pages CHANGE content content VARCHAR(10000) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
步驟3 - 現在,將MySQL與Python整合。為此,我們需要PyMySQL,它可以使用以下命令安裝
pip install PyMySQL
步驟4 - 現在,我們之前建立的名為Scrap的資料庫已準備好儲存從網頁抓取的資料,並將資料儲存到名為Scrap_pages的表中。在我們的示例中,我們將從維基百科抓取資料,並將資料儲存到我們的資料庫中。
首先,我們需要匯入所需的Python模組。
from urllib.request import urlopen from bs4 import BeautifulSoup import datetime import random import pymysql import re
現在,建立連線,也就是將其與Python整合。
conn = pymysql.connect(host='127.0.0.1',user='root', passwd = None, db = 'mysql',
charset = 'utf8')
cur = conn.cursor()
cur.execute("USE scrap")
random.seed(datetime.datetime.now())
def store(title, content):
cur.execute('INSERT INTO scrap_pages (title, content) VALUES ''("%s","%s")', (title, content))
cur.connection.commit()
現在,連線到維基百科並獲取資料。
def getLinks(articleUrl):
html = urlopen('http://en.wikipedia.org'+articleUrl)
bs = BeautifulSoup(html, 'html.parser')
title = bs.find('h1').get_text()
content = bs.find('div', {'id':'mw-content-text'}).find('p').get_text()
store(title, content)
return bs.find('div', {'id':'bodyContent'}).findAll('a',href=re.compile('^(/wiki/)((?!:).)*$'))
links = getLinks('/wiki/Kevin_Bacon')
try:
while len(links) > 0:
newArticle = links[random.randint(0, len(links)-1)].attrs['href']
print(newArticle)
links = getLinks(newArticle)
最後,我們需要關閉遊標和連線。
finally: cur.close() conn.close()
這將把從維基百科收集到的資料儲存到名為scrap_pages的表中。如果您熟悉MySQL和網頁抓取,那麼上述程式碼不難理解。
使用PostgreSQL進行資料處理
PostgreSQL 由全球志願者團隊開發,是一個開源的關係型資料庫管理系統 (RDMS)。使用 PostgreSQL 處理抓取資料的過程類似於 MySQL。會有兩個變化:首先,命令與 MySQL 不同;其次,這裡我們將使用psycopg2 Python 庫來執行它與 Python 的整合。
如果您不熟悉 PostgreSQL,可以在 https://tutorialspoint.tw/postgresql/. 學習。並且可以透過以下命令安裝 psycopg2 Python 庫:
pip install psycopg2
處理影像和影片
網頁抓取通常涉及下載、儲存和處理網頁媒體內容。在本章中,讓我們瞭解如何處理從網路下載的內容。
介紹
我們在抓取過程中獲得的網頁媒體內容可以是影像、音訊和影片檔案,也可以是非網頁頁面以及資料檔案。但是,我們能否信任下載的資料,特別是我們打算下載並存儲在計算機記憶體中的資料副檔名?這使得了解我們要本地儲存的資料型別變得至關重要。
從網頁獲取媒體內容
在本節中,我們將學習如何下載媒體內容,這些內容根據 Web 伺服器的資訊正確表示媒體型別。我們可以藉助 Python 的requests模組來實現,就像我們在上一章中所做的那樣。
首先,我們需要匯入必要的 Python 模組,如下所示:
import requests
現在,提供我們要下載並本地儲存的媒體內容的 URL。
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"
使用以下程式碼建立 HTTP 響應物件。
r = requests.get(url)
藉助以下程式碼行,我們可以將接收到的內容儲存為 .png 檔案。
with open("ThinkBig.png",'wb') as f:
f.write(r.content)
執行上述 Python 指令碼後,我們將獲得一個名為 ThinkBig.png 的檔案,其中包含下載的影像。
從 URL 中提取檔名
從網站下載內容後,我們還想將其儲存在一個檔案中,檔名在 URL 中找到。但我們也可以檢查 URL 中是否存在多個額外片段。為此,我們需要從 URL 中找到實際的檔名。
藉助以下 Python 指令碼,使用urlparse,我們可以從 URL 中提取檔名:
import urllib3 import os url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg" a = urlparse(url) a.path
您可以觀察到如下所示的輸出:
'/wp-content/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg' os.path.basename(a.path)
您可以觀察到如下所示的輸出:
'MetaSlider_ThinkBig-1080x180.jpg'
執行上述指令碼後,我們將從 URL 中獲取檔名。
關於 URL 內容型別的資訊
在透過 GET 請求從 Web 伺服器提取內容時,我們還可以檢查 Web 伺服器提供的資訊。藉助以下 Python 指令碼,我們可以確定 Web 伺服器對內容型別的含義:
首先,我們需要匯入必要的 Python 模組,如下所示:
import requests
現在,我們需要提供我們要下載並本地儲存的媒體內容的 URL。
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"
以下程式碼行將建立 HTTP 響應物件。
r = requests.get(url, allow_redirects=True)
現在,我們可以獲取 Web 伺服器可以提供的關於內容的哪種型別的資訊。
for headers in r.headers: print(headers)
您可以觀察到如下所示的輸出:
Date Server Upgrade Connection Last-Modified Accept-Ranges Content-Length Keep-Alive Content-Type
藉助以下程式碼行,我們可以獲取關於內容型別的特定資訊,例如 content-type:
print (r.headers.get('content-type'))
您可以觀察到如下所示的輸出:
image/jpeg
藉助以下程式碼行,我們可以獲取關於內容型別的特定資訊,例如 EType:
print (r.headers.get('ETag'))
您可以觀察到如下所示的輸出:
None
觀察以下命令:
print (r.headers.get('content-length'))
您可以觀察到如下所示的輸出:
12636
藉助以下程式碼行,我們可以獲取關於內容型別的特定資訊,例如 Server:
print (r.headers.get('Server'))
您可以觀察到如下所示的輸出:
Apache
為影像生成縮圖
縮圖是一個非常小的描述或表示。使用者可能只想儲存大型影像的縮圖,或者同時儲存影像和縮圖。在本節中,我們將為名為ThinkBig.png的影像建立縮圖,該影像在上一節“從網頁獲取媒體內容”中下載。
對於此 Python 指令碼,我們需要安裝名為 Pillow 的 Python 庫,它是 Python 影像庫的一個分支,具有用於處理影像的有用功能。它可以透過以下命令安裝:
pip install pillow
以下 Python 指令碼將建立影像的縮圖,並將其儲存到當前目錄,並在縮圖檔名前新增Th_字首。
import glob
from PIL import Image
for infile in glob.glob("ThinkBig.png"):
img = Image.open(infile)
img.thumbnail((128, 128), Image.ANTIALIAS)
if infile[0:2] != "Th_":
img.save("Th_" + infile, "png")
以上程式碼非常易於理解,您可以在當前目錄中檢查縮圖檔案。
網站截圖
在網頁抓取中,一個非常常見的任務是擷取網站的螢幕截圖。為了實現這一點,我們將使用 selenium 和 webdriver。以下 Python 指令碼將擷取網站的螢幕截圖,並將其儲存到當前目錄。
From selenium import webdriver
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
browser = webdriver.Chrome(executable_path = path)
browser.get('https://tutorialspoint.tw/')
screenshot = browser.save_screenshot('screenshot.png')
browser.quit
您可以觀察到如下所示的輸出:
DevTools listening on ws://127.0.0.1:1456/devtools/browser/488ed704-9f1b-44f0- a571-892dc4c90eb7 <bound method WebDriver.quit of <selenium.webdriver.chrome.webdriver.WebDriver (session="37e8e440e2f7807ef41ca7aa20ce7c97")>>
執行指令碼後,您可以在當前目錄中檢查screenshot.png檔案。
影片縮圖生成
假設我們從網站下載了影片,並希望為它們生成縮圖,以便可以根據其縮圖單擊特定的影片。為了生成影片的縮圖,我們需要一個名為ffmpeg的簡單工具,可以從www.ffmpeg.org下載。下載後,我們需要根據作業系統的規格進行安裝。
以下 Python 指令碼將生成影片的縮圖,並將其儲存到我們的本地目錄:
import subprocess video_MP4_file = “C:\Users\gaurav\desktop\solar.mp4 thumbnail_image_file = 'thumbnail_solar_video.jpg' subprocess.call(['ffmpeg', '-i', video_MP4_file, '-ss', '00:00:20.000', '- vframes', '1', thumbnail_image_file, "-y"])
執行上述指令碼後,我們將獲得名為thumbnail_solar_video.jpg的縮圖,並將其儲存在本地目錄中。
將 MP4 影片轉換為 MP3
假設您從網站下載了一些影片檔案,但您只需要其中的音訊來滿足您的目的,那麼可以使用 Python 庫moviepy在 Python 中完成此操作,該庫可以透過以下命令安裝:
pip install moviepy
現在,成功使用以下指令碼安裝 moviepy 後,我們可以將 MP4 轉換為 MP3。
import moviepy.editor as mp
clip = mp.VideoFileClip(r"C:\Users\gaurav\Desktop\1234.mp4")
clip.audio.write_audiofile("movie_audio.mp3")
您可以觀察到如下所示的輸出:
[MoviePy] Writing audio in movie_audio.mp3 100%|¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦ ¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 674/674 [00:01<00:00, 476.30it/s] [MoviePy] Done.
以上指令碼將音訊 MP3 檔案儲存到本地目錄。
Python 網頁抓取 - 處理文字
在上一章中,我們已經瞭解瞭如何處理作為網頁抓取內容一部分獲得的影片和影像。在本章中,我們將使用 Python 庫處理文字分析,並將詳細瞭解這一點。
介紹
您可以使用名為自然語言工具包 (NLTK) 的 Python 庫進行文字分析。在深入瞭解 NLTK 的概念之前,讓我們瞭解文字分析和網頁抓取之間的關係。
分析文字中的單詞可以讓我們瞭解哪些單詞很重要,哪些單詞不尋常,單詞是如何分組的。這種分析簡化了網頁抓取的任務。
開始使用 NLTK
自然語言工具包 (NLTK) 是 Python 庫的集合,專門用於識別和標記自然語言(如英語)文字中發現的詞性。
安裝 NLTK
您可以使用以下命令在 Python 中安裝 NLTK:
pip install nltk
如果您使用的是 Anaconda,則可以使用以下命令構建 NLTK 的 conda 包:
conda install -c anaconda nltk
下載 NLTK 的資料
安裝 NLTK 後,我們必須下載預設的文字儲存庫。但在下載文字預設儲存庫之前,我們需要使用import命令匯入 NLTK,如下所示:
mport nltk
現在,藉助以下命令可以下載 NLTK 資料:
nltk.download()
安裝所有可用的 NLTK 包將需要一些時間,但始終建議安裝所有包。
安裝其他必要的包
我們還需要一些其他 Python 包,如gensim和pattern,用於進行文字分析以及使用 NLTK 構建自然語言處理應用程式。
gensim - 一個強大的語義建模庫,對許多應用程式很有用。它可以透過以下命令安裝:
pip install gensim
pattern - 用於使gensim包正常工作。它可以透過以下命令安裝:
pip install pattern
分詞
將給定的文字分解成稱為標記的較小單元的過程稱為分詞。這些標記可以是單詞、數字或標點符號。它也稱為詞語切分。
示例

NLTK 模組提供了不同的分詞包。我們可以根據需要使用這些包。這裡描述了一些包:
sent_tokenize 包 - 此包將輸入文字劃分為句子。您可以使用以下命令匯入此包:
from nltk.tokenize import sent_tokenize
word_tokenize 包 - 此包將輸入文字劃分為單詞。您可以使用以下命令匯入此包:
from nltk.tokenize import word_tokenize
WordPunctTokenizer 包 - 此包將輸入文字以及標點符號劃分為單詞。您可以使用以下命令匯入此包:
from nltk.tokenize import WordPuncttokenizer
詞幹提取
在任何語言中,單詞都有不同的形式。由於語法原因,語言包含大量變化。例如,考慮單詞democracy、democratic和democratization。對於機器學習以及網頁抓取專案,機器理解這些不同單詞具有相同的詞幹形式非常重要。因此,我們可以說在分析文字時提取單詞的詞幹形式可能很有用。
這可以透過詞幹提取來實現,詞幹提取可以定義為透過去除單詞末尾來提取單詞詞幹形式的啟發式過程。
NLTK 模組提供了不同的詞幹提取包。我們可以根據需要使用這些包。這裡描述了其中一些包:
PorterStemmer 包 - 此 Python 詞幹提取包使用 Porter 演算法來提取詞幹形式。您可以使用以下命令匯入此包:
from nltk.stem.porter import PorterStemmer
例如,在將單詞‘writing’作為輸入提供給此詞幹提取器後,詞幹提取後的輸出將是單詞‘write’。
LancasterStemmer 包 - 此 Python 詞幹提取包使用 Lancaster 演算法來提取詞幹形式。您可以使用以下命令匯入此包:
from nltk.stem.lancaster import LancasterStemmer
例如,如果將單詞“writing”作為輸入提供給這個詞幹提取器,那麼詞幹提取後的輸出將是單詞“writ”。
SnowballStemmer 包 - 這個 Python 詞幹提取包使用 Snowball 演算法來提取詞的基本形式。可以使用以下命令匯入此包:
from nltk.stem.snowball import SnowballStemmer
例如,如果將單詞“writing”作為輸入提供給這個詞幹提取器,那麼詞幹提取後的輸出將是單詞“write”。
詞形還原
另一種提取單詞基本形式的方法是詞形還原,通常旨在透過使用詞彙和形態分析來去除詞尾變化。任何單詞詞形還原後的基本形式稱為詞形。
NLTK 模組提供以下用於詞形還原的包:
WordNetLemmatizer 包 - 它將根據單詞是用作名詞還是動詞來提取單詞的基本形式。可以使用以下命令匯入此包:
from nltk.stem import WordNetLemmatizer
分塊
分塊,即把資料分成小塊,是自然語言處理中一個重要的過程,用於識別詞性並識別名詞短語等短語。分塊是對標記進行標註。藉助分塊過程,我們可以得到句子的結構。
示例
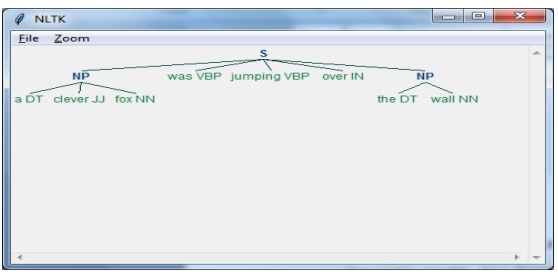
在這個例子中,我們將使用 NLTK Python 模組來實現名詞短語分塊。NP 分塊是一種分塊類別,它將在句子中查詢名詞短語塊。
實現名詞短語分塊的步驟
要實現名詞短語分塊,需要按照以下步驟操作:
步驟 1 - 分塊語法定義
在第一步中,我們將定義分塊的語法。它將包含我們需要遵循的規則。
步驟 2 - 分塊解析器建立
現在,我們將建立一個分塊解析器。它將解析語法並給出輸出。
步驟 3 - 輸出
在最後一步中,輸出將以樹狀格式生成。
首先,我們需要匯入 NLTK 包,如下所示:
import nltk
接下來,我們需要定義句子。這裡 DT:限定詞,VBP:動詞,JJ:形容詞,IN:介詞,NN:名詞。
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]
接下來,我們以正則表示式的形式給出語法。
grammar = "NP:{<DT>?<JJ>*<NN>}"
現在,下一行程式碼將定義一個用於解析語法的解析器。
parser_chunking = nltk.RegexpParser(grammar)
現在,解析器將解析句子。
parser_chunking.parse(sentence)
接下來,我們將輸出儲存在變數中。
Output = parser_chunking.parse(sentence)
藉助以下程式碼,我們可以將輸出繪製成樹狀圖,如下所示。
output.draw()
詞袋 (BoW) 模型 提取和將文字轉換為數值形式
詞袋 (BoW) 是自然語言處理中一個有用的模型,主要用於從文字中提取特徵。從文字中提取特徵後,可以將其用於機器學習演算法中的建模,因為原始資料不能用於 ML 應用。
BoW 模型的工作原理
最初,模型從文件中的所有單詞中提取詞彙表。之後,使用文件詞矩陣構建模型。這樣,BoW 模型僅將文件表示為詞袋,而丟棄了順序或結構。
示例
假設我們有以下兩個句子:
句子 1 - 這是一個詞袋模型的例子。
句子 2 - 我們可以使用詞袋模型提取特徵。
現在,考慮到這兩個句子,我們有以下 14 個不同的單詞:
- This
- is
- an
- example
- bag
- of
- words
- model
- we
- can
- extract
- features
- by
- using
在 NLTK 中構建詞袋模型
讓我們看看以下 Python 指令碼,它將在 NLTK 中構建一個 BoW 模型。
首先,匯入以下包:
from sklearn.feature_extraction.text import CountVectorizer
接下來,定義句子集:
Sentences=['This is an example of Bag of Words model.', ' We can extract features by using Bag of Words model.'] vector_count = CountVectorizer() features_text = vector_count.fit_transform(Sentences).todense() print(vector_count.vocabulary_)
輸出
它表明以上兩個句子中共有 14 個不同的單詞。
{
'this': 10, 'is': 7, 'an': 0, 'example': 4, 'of': 9,
'bag': 1, 'words': 13, 'model': 8, 'we': 12, 'can': 3,
'extract': 5, 'features': 6, 'by': 2, 'using':11
}
主題建模:識別文字資料中的模式
通常將文件分組到主題中,主題建模是一種識別文字中與特定主題相對應的模式的技術。換句話說,主題建模用於揭示給定文件集中抽象的主題或隱藏的結構。
可以在以下場景中使用主題建模:
文字分類
主題建模可以改進分類,因為它將相似的單詞組合在一起,而不是將每個單詞單獨用作特徵。
推薦系統
我們可以使用相似性度量來構建推薦系統。
主題建模演算法
可以使用以下演算法實現主題建模:
潛在狄利克雷分配 (LDA) - 它是使用機率圖模型實現主題建模的最流行演算法之一。
潛在語義分析 (LDA) 或潛在語義索引 (LSI) - 它基於線性代數,並在文件詞矩陣上使用 SVD (奇異值分解) 的概念。
非負矩陣分解 (NMF) - 它也像 LDA 一樣基於線性代數。
上述演算法將具有以下元素:
- 主題數量:引數
- 文件詞矩陣:輸入
- WTM(詞主題矩陣)和 TDM(主題文件矩陣):輸出
Python 網頁抓取 - 動態網站
介紹
網頁抓取是一項複雜的任務,如果網站是動態的,複雜性就會成倍增加。根據聯合國全球網頁無障礙審計,超過 70% 的網站本質上是動態的,它們依賴 JavaScript 來實現其功能。
動態網站示例
讓我們來看一個動態網站的例子,並瞭解為什麼它很難抓取。這裡我們將以從名為 http://example.webscraping.com/places/default/search 的網站搜尋為例。但是我們如何說這個網站是動態的呢?可以透過以下 Python 指令碼的輸出判斷,該指令碼將嘗試從上述網頁抓取資料:
import re
import urllib.request
response = urllib.request.urlopen('http://example.webscraping.com/places/default/search')
html = response.read()
text = html.decode()
re.findall('(.*?)',text)
輸出
[ ]
上述輸出表明,示例抓取器未能提取資訊,因為我們嘗試查詢的 <div> 元素為空。
從動態網站抓取資料的方法
我們已經看到,抓取器無法從動態網站抓取資訊,因為資料是使用 JavaScript 動態載入的。在這種情況下,我們可以使用以下兩種技術從依賴於動態 JavaScript 的網站抓取資料:
- 反向工程 JavaScript
- 渲染 JavaScript
反向工程 JavaScript
稱為反向工程的過程將非常有用,並讓我們瞭解網頁如何動態載入資料。
為此,我們需要為指定的 URL 單擊檢查元素選項卡。接下來,我們將單擊網路選項卡以查詢為此網頁發出的所有請求,包括路徑為/ajax 的 search.json。除了透過瀏覽器或透過網路選項卡訪問 AJAX 資料之外,我們也可以藉助以下 Python 指令碼實現:
import requests
url=requests.get('http://example.webscraping.com/ajax/search.json?page=0&page_size=10&search_term=a')
url.json()
示例
上述指令碼允許我們使用 Python json 方法訪問 JSON 響應。類似地,我們可以下載原始字串響應,並使用 python 的 json.loads 方法載入它。我們藉助以下 Python 指令碼執行此操作。它基本上將透過搜尋字母“a”來抓取所有國家/地區,然後迭代 JSON 響應的結果頁面。
import requests
import string
PAGE_SIZE = 15
url = 'http://example.webscraping.com/ajax/' + 'search.json?page={}&page_size={}&search_term=a'
countries = set()
for letter in string.ascii_lowercase:
print('Searching with %s' % letter)
page = 0
while True:
response = requests.get(url.format(page, PAGE_SIZE, letter))
data = response.json()
print('adding %d records from the page %d' %(len(data.get('records')),page))
for record in data.get('records'):countries.add(record['country'])
page += 1
if page >= data['num_pages']:
break
with open('countries.txt', 'w') as countries_file:
countries_file.write('n'.join(sorted(countries)))
執行上述指令碼後,我們將獲得以下輸出,並且記錄將儲存在名為 countries.txt 的檔案中。
輸出
Searching with a adding 15 records from the page 0 adding 15 records from the page 1 ...
渲染 JavaScript
在上一節中,我們對網頁進行了反向工程,瞭解了 API 的工作原理以及如何使用它在一個請求中檢索結果。但是,在進行反向工程時,可能會遇到以下困難:
有時網站可能非常複雜。例如,如果網站是使用高階瀏覽器工具(如 Google Web Toolkit (GWT))製作的,那麼生成的 JS 程式碼將是機器生成的,難以理解和反向工程。
一些更高級別的框架(如React.js)可以透過抽象已經很複雜的 JavaScript 邏輯來使反向工程變得困難。
解決上述困難的辦法是使用瀏覽器渲染引擎,該引擎解析 HTML、應用 CSS 格式並執行 JavaScript 以顯示網頁。
示例
在這個例子中,為了渲染 Java Script,我們將使用一個熟悉的 Python 模組 Selenium。以下 Python 程式碼將藉助 Selenium 渲染網頁:
首先,我們需要從 selenium 匯入 webdriver,如下所示:
from selenium import webdriver
現在,提供我們根據需要下載的Web驅動程式的路徑:
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver' driver = webdriver.Chrome(executable_path = path)
現在,提供我們希望在現在由Python指令碼控制的Web瀏覽器中開啟的URL。
driver.get('http://example.webscraping.com/search')
現在,我們可以使用搜索工具箱的 ID 來設定要選擇的元素。
driver.find_element_by_id('search_term').send_keys('.')
接下來,我們可以使用 java 指令碼將選擇框內容設定為如下所示:
js = "document.getElementById('page_size').options[1].text = '100';"
driver.execute_script(js)
以下程式碼行顯示搜尋已準備好在網頁上單擊:
driver.find_element_by_id('search').click()
下一行程式碼顯示它將等待 45 秒以完成 AJAX 請求。
driver.implicitly_wait(45)
現在,要選擇國家/地區連結,我們可以使用 CSS 選擇器,如下所示:
links = driver.find_elements_by_css_selector('#results a')
現在可以提取每個連結的文字以建立國家/地區列表:
countries = [link.text for link in links] print(countries) driver.close()
Python 網頁抓取 - 基於表單的網站
在上一章中,我們學習了抓取動態網站。在本章中,讓我們瞭解一下基於使用者輸入的網站,即基於表單的網站的抓取。
介紹
如今,全球資訊網 (WWW) 正朝著社交媒體以及使用者生成內容的方向發展。因此,問題就出現了,我們如何訪問登入螢幕之外的此類資訊?為此,我們需要處理表單和登入。
在前面的章節中,我們使用了 HTTP GET 方法來請求資訊,但在本章中,我們將使用 HTTP POST 方法將資訊推送到 Web 伺服器以進行儲存和分析。
與登入表單互動
在使用網際網路時,您一定多次與登入表單互動過。它們可能非常簡單,例如僅包含很少的 HTML 欄位、一個提交按鈕和一個操作頁面,或者它們可能很複雜,並且具有一些其他欄位,例如電子郵件、留言以及出於安全原因的驗證碼。
在本節中,我們將藉助 Python requests 庫處理一個簡單的提交表單。
首先,我們需要匯入 requests 庫,如下所示:
import requests
現在,我們需要為登入表單的欄位提供資訊。
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}
在下一行程式碼中,我們需要提供表單操作將發生到的 URL。
r = requests.post(“enter the URL”, data = parameters) print(r.text)
執行指令碼後,它將返回操作發生到的頁面的內容。
假設您想使用表單提交任何影像,那麼使用 requests.post() 非常簡單。您可以透過以下 Python 指令碼瞭解它:
import requests
file = {‘Uploadfile’: open(’C:\Usres\desktop\123.png’,‘rb’)}
r = requests.post(“enter the URL”, files = file)
print(r.text)
從 Web 伺服器載入 Cookie
Cookie,有時稱為 Web Cookie 或 Internet Cookie,是從網站傳送的一小段資料,我們的計算機將其儲存在位於 Web 瀏覽器內部的檔案中。
在處理登入表單的上下文中,Cookie 可以分為兩種型別。一種是我們在上節中處理的,它允許我們向網站提交資訊;另一種允許我們在整個訪問網站期間保持永久“登入”狀態。對於第二種表單,網站使用 Cookie 來跟蹤誰已登入以及誰未登入。
Cookie 的作用是什麼?
如今,大多數網站都使用 Cookie 進行跟蹤。我們可以透過以下步驟瞭解 Cookie 的工作原理:
步驟 1 - 首先,網站將驗證我們的登入憑據並將其儲存在瀏覽器的 Cookie 中。此 Cookie 通常包含伺服器生成的令牌、超時和跟蹤資訊。
步驟 2 - 接下來,網站將使用 Cookie 作為身份驗證的證明。每次訪問網站時,都會始終顯示此身份驗證。
Cookie 對 Web 爬蟲來說非常麻煩,因為如果 Web 爬蟲不跟蹤 Cookie,提交的表單會被髮送回,並在下一頁顯示它們從未登入。藉助 Python 的 **requests** 庫,跟蹤 Cookie 非常容易,如下所示:
import requests
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}
r = requests.post(“enter the URL”, data = parameters)
在上面的程式碼行中,URL 將是充當登入表單處理程式的頁面。
print(‘The cookie is:’) print(r.cookies.get_dict()) print(r.text)
執行上述指令碼後,我們將從上次請求的結果中檢索 Cookie。
Cookie 還存在另一個問題,即有時網站會在沒有警告的情況下頻繁修改 Cookie。這種情況可以使用 **requests.Session()** 處理,如下所示:
import requests
session = requests.Session()
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}
r = session.post(“enter the URL”, data = parameters)
在上面的程式碼行中,URL 將是充當登入表單處理程式的頁面。
print(‘The cookie is:’) print(r.cookies.get_dict()) print(r.text)
可以很容易地理解使用 Session 和不使用 Session 的指令碼之間的區別。
使用 Python 自動化表單
在本節中,我們將使用名為 Mechanize 的 Python 模組來簡化我們的工作並自動化表單填寫過程。
Mechanize 模組
Mechanize 模組為我們提供了一個與表單互動的高階介面。在開始使用它之前,我們需要使用以下命令安裝它:
pip install mechanize
請注意,它僅在 Python 2.x 中有效。
示例
在這個例子中,我們將自動化填寫一個包含兩個欄位(電子郵件和密碼)的登入表單的過程:
import mechanize brwsr = mechanize.Browser() brwsr.open(Enter the URL of login) brwsr.select_form(nr = 0) brwsr['email'] = ‘Enter email’ brwsr['password'] = ‘Enter password’ response = brwsr.submit() brwsr.submit()
上述程式碼非常容易理解。首先,我們匯入了 mechanize 模組。然後建立了一個 Mechanize 瀏覽器物件。然後,我們導航到登入 URL 並選擇了表單。之後,名稱和值直接傳遞給瀏覽器物件。
Python Web 爬蟲 - 處理驗證碼
在本章中,讓我們瞭解如何執行 Web 爬蟲和處理驗證碼,驗證碼用於測試使用者是人類還是機器人。
什麼是驗證碼?
CAPTCHA 的全稱是 **Completely Automated Public Turing test to tell Computers and Humans Apart**,它清楚地表明這是一個確定使用者是否為人類的測試。
驗證碼是一張扭曲的影像,通常不容易被計算機程式檢測到,但人類可以設法理解它。大多數網站使用驗證碼來防止機器人進行互動。
使用 Python 載入驗證碼
假設我們想在一個網站上進行註冊,並且有一個包含驗證碼的表單,那麼在載入驗證碼影像之前,我們需要了解表單所需的特定資訊。藉助以下 Python 指令碼,我們可以瞭解名為 http://example.webscrapping.com 網站上登錄檔單的表單要求。
import lxml.html
import urllib.request as urllib2
import pprint
import http.cookiejar as cookielib
def form_parsing(html):
tree = lxml.html.fromstring(html)
data = {}
for e in tree.cssselect('form input'):
if e.get('name'):
data[e.get('name')] = e.get('value')
return data
REGISTER_URL = '<a target="_blank" rel="nofollow"
href="http://example.webscraping.com/user/register">http://example.webscraping.com/user/register'</a>
ckj = cookielib.CookieJar()
browser = urllib2.build_opener(urllib2.HTTPCookieProcessor(ckj))
html = browser.open(
'<a target="_blank" rel="nofollow"
href="http://example.webscraping.com/places/default/user/register?_next">
http://example.webscraping.com/places/default/user/register?_next</a> = /places/default/index'
).read()
form = form_parsing(html)
pprint.pprint(form)
在上面的 Python 指令碼中,我們首先定義了一個函式,該函式將使用 lxml Python 模組解析表單,然後打印表單要求,如下所示:
{
'_formkey': '5e306d73-5774-4146-a94e-3541f22c95ab',
'_formname': 'register',
'_next': '/places/default/index',
'email': '',
'first_name': '',
'last_name': '',
'password': '',
'password_two': '',
'recaptcha_response_field': None
}
從上面的輸出中可以看出,除了 **recpatcha_response_field** 之外,所有資訊都易於理解和直接。現在問題出現了,我們如何處理這些複雜資訊並下載驗證碼?這可以透過 Pillow Python 庫來實現,如下所示:
Pillow Python 包
Pillow 是 Python 影像庫的一個分支,具有用於操作影像的有用函式。可以使用以下命令安裝它:
pip install pillow
在下一個示例中,我們將使用它來載入驗證碼:
from io import BytesIO
import lxml.html
from PIL import Image
def load_captcha(html):
tree = lxml.html.fromstring(html)
img_data = tree.cssselect('div#recaptcha img')[0].get('src')
img_data = img_data.partition(',')[-1]
binary_img_data = img_data.decode('base64')
file_like = BytesIO(binary_img_data)
img = Image.open(file_like)
return img
上面的 Python 指令碼使用了 **pillow** Python 包並定義了一個載入驗證碼影像的函式。它必須與前面指令碼中定義的名為 **form_parser()** 的函式一起使用,以獲取有關注冊表單的資訊。此指令碼將以有用的格式儲存驗證碼影像,該影像可以進一步提取為字串。
OCR:使用 Python 從影像中提取文字
以有用的格式載入驗證碼後,我們可以藉助光學字元識別 (OCR) 來提取它,OCR 是從影像中提取文字的過程。為此,我們將使用開源的 Tesseract OCR 引擎。可以使用以下命令安裝它:
pip install pytesseract
示例
這裡我們將擴充套件上面使用 Pillow Python 包載入驗證碼的 Python 指令碼,如下所示:
import pytesseract
img = get_captcha(html)
img.save('captcha_original.png')
gray = img.convert('L')
gray.save('captcha_gray.png')
bw = gray.point(lambda x: 0 if x < 1 else 255, '1')
bw.save('captcha_thresholded.png')
上面的 Python 指令碼將以黑白模式讀取驗證碼,這將更加清晰易於傳遞給 tesseract,如下所示:
pytesseract.image_to_string(bw)
執行上述指令碼後,我們將獲得登錄檔單的驗證碼作為輸出。
Python Web 爬蟲 - 使用爬蟲進行測試
本章介紹如何在 Python 中使用 Web 爬蟲進行測試。
介紹
在大型 Web 專案中,會定期對網站的後端進行自動化測試,但前端測試卻經常被跳過。其主要原因是網站的程式設計就像一個由各種標記語言和程式語言組成的網路。我們可以為一種語言編寫單元測試,但如果互動是在另一種語言中進行的,那麼就會變得具有挑戰性。因此,我們必須有一套測試來確保我們的程式碼按照我們的預期執行。
使用 Python 進行測試
當我們談論測試時,指的是單元測試。在深入探討 Python 測試之前,我們必須瞭解單元測試。以下是單元測試的一些特點:
每個單元測試都將測試元件功能的至少一個方面。
每個單元測試都是獨立的,也可以獨立執行。
單元測試不會干擾任何其他測試的成功或失敗。
單元測試可以以任何順序執行,並且必須包含至少一個斷言。
Unittest - Python 模組
名為 Unittest 的 Python 單元測試模組隨所有標準 Python 安裝一起提供。我們只需要匯入它,其餘工作由 unittest.TestCase 類完成,它將執行以下操作:
unittest.TestCase 類提供了 setUp 和 tearDown 函式。這些函式可以在每個單元測試之前和之後執行。
它還提供了 assert 語句,以允許測試透過或失敗。
它執行所有以 test_ 開頭的函式作為單元測試。
示例
在這個例子中,我們將 Web 爬蟲與 **unittest** 結合起來。我們將測試維基百科頁面以搜尋字串“Python”。它基本上將執行兩個測試,第一個測試是標題頁面是否與搜尋字串即“Python”相同,第二個測試確保頁面具有內容 div。
首先,我們將匯入所需的 Python 模組。我們使用 BeautifulSoup 進行 Web 爬蟲,當然也使用 unittest 進行測試。
from urllib.request import urlopen from bs4 import BeautifulSoup import unittest
現在我們需要定義一個類,該類將擴充套件 unittest.TestCase。全域性物件 bs 將在所有測試之間共享。一個 unittest 指定的函式 setUpClass 將實現這一點。在這裡,我們將定義兩個函式,一個用於測試標題頁面,另一個用於測試頁面內容。
class Test(unittest.TestCase):
bs = None
def setUpClass():
url = '<a target="_blank" rel="nofollow" href="https://en.wikipedia.org/wiki/Python">https://en.wikipedia.org/wiki/Python'</a>
Test.bs = BeautifulSoup(urlopen(url), 'html.parser')
def test_titleText(self):
pageTitle = Test.bs.find('h1').get_text()
self.assertEqual('Python', pageTitle);
def test_contentExists(self):
content = Test.bs.find('div',{'id':'mw-content-text'})
self.assertIsNotNone(content)
if __name__ == '__main__':
unittest.main()
執行上述指令碼後,我們將獲得以下輸出:
----------------------------------------------------------------------
Ran 2 tests in 2.773s
OK
An exception has occurred, use %tb to see the full traceback.
SystemExit: False
D:\ProgramData\lib\site-packages\IPython\core\interactiveshell.py:2870:
UserWarning: To exit: use 'exit', 'quit', or Ctrl-D.
warn("To exit: use 'exit', 'quit', or Ctrl-D.", stacklevel=1)
使用 Selenium 進行測試
讓我們討論如何使用 Python Selenium 進行測試。它也稱為 Selenium 測試。Python **unittest** 和 **Selenium** 之間並沒有太多共同點。我們知道 Selenium 將標準 Python 命令傳送到不同的瀏覽器,儘管它們的瀏覽器設計存在差異。回想一下,我們已經在前面的章節中安裝並使用了 Selenium。在這裡,我們將建立 Selenium 中的測試指令碼並將其用於自動化。
示例
藉助以下 Python 指令碼,我們正在為 Facebook 登入頁面的自動化建立測試指令碼。您可以修改此示例以自動化您選擇的其他表單和登入,但概念將相同。
首先,為了連線到 Web 瀏覽器,我們將從 selenium 模組匯入 webdriver:
from selenium import webdriver
現在,我們需要從 selenium 模組匯入 Keys。
from selenium.webdriver.common.keys import Keys
接下來,我們需要提供使用者名稱和密碼才能登入我們的 Facebook 帳戶
user = "gauravleekha@gmail.com" pwd = ""
接下來,提供 Chrome 的 Web 驅動程式的路徑。
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
driver = webdriver.Chrome(executable_path=path)
driver.get("https://#")
現在,我們將使用 assert 關鍵字驗證條件。
assert "Facebook" in driver.title
藉助以下程式碼行,我們將值傳送到電子郵件部分。在這裡,我們透過其 ID 搜尋它,但可以透過名稱搜尋它,例如 **driver.find_element_by_name("email")**。
element = driver.find_element_by_id("email")
element.send_keys(user)
藉助以下程式碼行,我們將值傳送到密碼部分。在這裡,我們透過其 ID 搜尋它,但可以透過名稱搜尋它,例如 **driver.find_element_by_name("pass")**。
element = driver.find_element_by_id("pass")
element.send_keys(pwd)
下一行程式碼用於在電子郵件和密碼欄位中插入值後按 Enter/登入。
element.send_keys(Keys.RETURN)
現在我們將關閉瀏覽器。
driver.close()
執行上述指令碼後,Chrome Web 瀏覽器將開啟,您可以看到電子郵件和密碼正在插入並單擊登入按鈕。
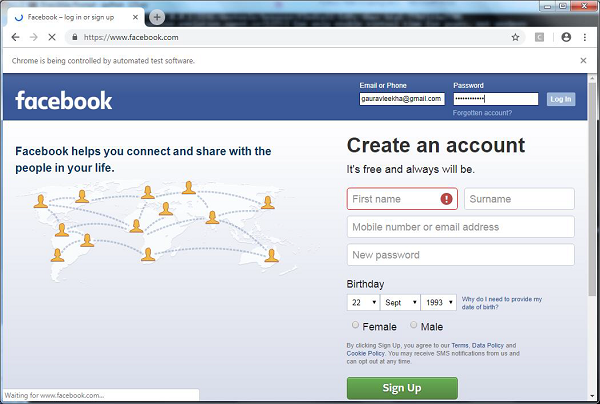
比較:unittest 或 Selenium
unittest 和 selenium 的比較比較困難,因為如果您想使用大型測試套件,則需要 unites 的語法嚴格性。另一方面,如果您要測試網站的靈活性,那麼 Selenium 測試將是我們的首選。但是,如果我們可以將兩者結合起來呢?我們可以將 selenium 匯入到 Python unittest 中,並獲得兩者的優勢。Selenium 可用於獲取有關網站的資訊,而 unittest 可以評估這些資訊是否滿足透過測試的標準。
例如,我們正在重寫上面的 Python 指令碼以透過將兩者結合起來來自動化 Facebook 登入,如下所示:
import unittest
from selenium import webdriver
class InputFormsCheck(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome(r'C:\Users\gaurav\Desktop\chromedriver')
def test_singleInputField(self):
user = "gauravleekha@gmail.com"
pwd = ""
pageUrl = "https://#"
driver=self.driver
driver.maximize_window()
driver.get(pageUrl)
assert "Facebook" in driver.title
elem = driver.find_element_by_id("email")
elem.send_keys(user)
elem = driver.find_element_by_id("pass")
elem.send_keys(pwd)
elem.send_keys(Keys.RETURN)
def tearDown(self):
self.driver.close()
if __name__ == "__main__":
unittest.main()