- Python 網頁抓取教程
- Python 網頁抓取 - 主頁
- 簡介
- Python 入門
- Python 網頁抓取模組
- 網頁抓取的合法性
- 資料提取
- 資料處理
- 圖片與影片處理
- 文字處理
- 動態網頁抓取
- 基於表單的網頁抓取
- 驗證碼處理
- 使用抓取工具進行測試
- Python 網頁抓取資源
- Python 網頁抓取 - 快速指南
- Python 網頁抓取 - 資源
- Python 網頁抓取 - 討論
Python 網頁抓取 - 文字處理
在上一章中,我們瞭解瞭如何處理我們透過網頁抓取的內容獲取的影片和圖片。在本章中,我們將使用 Python 庫來處理文字分析,並詳細瞭解這方面的內容。
簡介
你可以使用名為自然語言工具包 (NLTK) 的 Python 庫來執行文字分析。在深入瞭解 NLTK 的概念之前,讓我們瞭解文字分析和網頁抓取之間的關係。
分析文字中的單詞,可以讓我們瞭解哪些單詞很重要,哪些單詞不尋常以及單詞是如何分組的。這種分析可以簡化網頁抓取的任務。
NLTK 入門
自然語言工具包 (NLTK) 是一個 Python 庫的集合,專門設計用於識別和標記英語等自然語言文字中找到的詞性。
安裝 NLTK
你可以使用以下命令在 Python 中安裝 NLTK −
pip install nltk
如果你正在使用 Anaconda,那麼可以使用以下命令構建一個針對 NLTK 的 conda 包 −
conda install -c anaconda nltk
下載 NLTK 的資料
在安裝 NLTK 之後,我們必須下載預設的文字儲存庫。但在下載文字預設儲存庫之前,我們需要使用import命令幫助匯入 NLTK,如下所示 −
mport nltk
現在,可以在以下命令的幫助下下載 NLTK 資料 −
nltk.download()
安裝 NLTK 的所有可用包需要一些時間,但始終建議安裝所有包。
安裝其他必要的包
我們還需要一些其他 Python 包,如gensim和pattern,以便透過 NLTK 執行文字分析以及構建自然語言處理應用程式。
gensim − 一個強大的語義建模庫,對許多應用程式都很有用。它可以透過以下命令進行安裝 −
pip install gensim
pattern − 用於使gensim包正常工作。它可以透過以下命令進行安裝 −
pip install pattern
標記化
將給定文字分解為稱為標記的較小單元的過程稱為標記化。這些標記可以是單詞、數字或標點符號。它也稱為單詞分割。
示例

NLTK 模組提供了不同的包來進行標記化。我們可以根據自己的需要使用這些包。這裡描述了其中的一些包 −
sent_tokenize 包 − 此包會將輸入文字分成句子。你可以使用以下命令來匯入此包 −
from nltk.tokenize import sent_tokenize
word_tokenize 包 − 此包會將輸入文字分成單詞。你可以使用以下命令來匯入此包 −
from nltk.tokenize import word_tokenize
WordPunctTokenizer 包 – 此包將輸入文字及標點符號劃分為單詞。你可以使用以下命令來匯入該包 −
from nltk.tokenize import WordPuncttokenizer
詞幹分析
任何語言中都存在各種形式的單詞。一門語言會因語法原因而包含許多變體。例如,考慮單詞 democracy、democratic 和 democratization。對於機器學習以及網路抓取專案而言,機器理解這些不同的單詞具有相同的基元形式非常重要。因此我們可以說,在分析文字時,提取單詞的基元形式非常有用。
這可以透過詞幹分析來實現,它可以定義為透過切除單詞尾部來提取單詞基元形式的啟發式過程。
NLTK 模組為詞幹分析提供了不同的包。我們可以根據自己的要求使用這些包。以下對其中一些包進行了說明 −
PorterStemmer 包 – 此 Python 詞幹分析包使用 Porter 演算法來提取基元形式。你可以使用以下命令來匯入該包 −
from nltk.stem.porter import PorterStemmer
例如,將單詞 “writing” 作為輸入形式提供給此詞幹分析器時,詞幹分析後得到的輸出將是單詞 “write”。
LancasterStemmer 包 – 此 Python 詞幹分析包使用 Lancaster 演算法來提取基元形式。你可以使用以下命令來匯入該包 −
from nltk.stem.lancaster import LancasterStemmer
例如,將單詞 “writing” 作為輸入形式提供給此詞幹分析器時,詞幹分析後得到的輸出將是單詞 “writ”。
SnowballStemmer 包 – 此 Python 詞幹分析包使用 Snowball 演算法來提取基元形式。你可以使用以下命令來匯入該包 −
from nltk.stem.snowball import SnowballStemmer
例如,將單詞 “writing” 作為輸入形式提供給此詞幹分析器時,詞幹分析後得到的輸出將是單詞 “write”。
詞形還原
另一種提取單詞基元形式的方法是詞形還原,其通常旨在透過使用詞彙和形態分析來移除屈折詞尾。詞形還原後的任何單詞的基元形式都稱為詞幹。
NLTK 模組為詞形還原提供了以下包 −
WordNetLemmatizer 包 – 它會提取單詞的基元形式,具體取決於該單詞是作為名詞還是動詞使用。你可以使用以下命令來匯入該包 −
from nltk.stem import WordNetLemmatizer
塊分析
塊分析是指將資料劃分為小塊,這是自然語言處理中用於識別詞性和短語(例如名詞短語)的重要過程之一。塊分析是要對標記進行標記。藉助塊分析過程,我們能夠獲取句子的結構。
示例
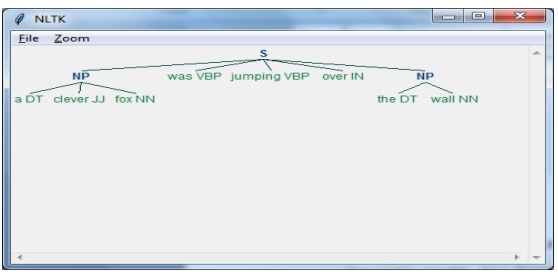
在此示例中,我們將使用 NLTK Python 模組實現名詞短語塊分析。名詞短語塊分析是一種塊分析分類,它將在句子中查詢名詞短語塊。
實現名詞短語塊分析的步驟
我們需要按照以下步驟來實現名詞短語塊分析 −
第 1 步 − 塊語法定義
在第一步中,我們將定義塊語法。它將包括我們需要遵循的規則。
第 2 步 − 塊解析器建立
現在,我們將建立一個塊解析器。它將解析語法並給輸出。
第 3 步 − 輸出
在最後一步中,輸出將以樹的形式生成。
首先,我們需要如下匯入 NLTK 包 −
import nltk
接下來,我們需要定義句子。在此,DT:限定詞,VBP:動詞,JJ:形容詞,IN:介詞,NN:名詞。
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]
接下來,我們要以正則表示式的形式提供語法。
grammar = "NP:{<DT>?<JJ>*<NN>}"
現在,下一行程式碼將定義用於分析語法的分析器。
parser_chunking = nltk.RegexpParser(grammar)
現在,分析器將分析句子。
parser_chunking.parse(sentence)
接下來,我們將輸出放入變數中。
Output = parser_chunking.parse(sentence)
藉助以下程式碼,我們可以繪製輸出,形式如下所示的樹形結構。
output.draw()
單詞袋模型 (BoW) 提取文字並將其轉換為數字形式
單詞袋 (BoW) 在自然語言處理中是一個有用的模型,基本上用於從文字中提取特徵。從文字中提取特徵之後,它可用於機器學習演算法建模,因為原始資料無法用於 ML 應用程式。
BoW 模型的工作原理
最初,模型從文件中的所有單詞中提取詞彙表。然後,使用文件術語矩陣,它會建立模型。透過這種方式,BoW 模型將文件表示為一個僅僅由單片語成的詞袋,而順序或結構則被捨棄。
示例
假設我們有以下兩個句子 -
句子 1 - 這是一個單詞袋模型示例。
句子 2 - 我們可以使用單詞袋模型提取特徵。
現在,透過考慮這兩個句子,我們得到了以下 14 個不同的單詞 -
- 這
- 是
- 一個
- 示例
- 詞袋
- 的
- 單詞
- 模型
- 我們
- 可以
- 提取
- 特徵
- 透過
- 使用
在 NLTK 中構建單詞袋模型
讓我們看一下以下 Python 指令碼,它將在 NLTK 中構建 BoW 模型。
首先,匯入以下包 -
from sklearn.feature_extraction.text import CountVectorizer
接下來,定義句子集合 -
Sentences=['This is an example of Bag of Words model.', ' We can extract features by using Bag of Words model.'] vector_count = CountVectorizer() features_text = vector_count.fit_transform(Sentences).todense() print(vector_count.vocabulary_)
輸出
它表明,在上述兩個句子中有 14 個不同的單詞 -
{
'this': 10, 'is': 7, 'an': 0, 'example': 4, 'of': 9,
'bag': 1, 'words': 13, 'model': 8, 'we': 12, 'can': 3,
'extract': 5, 'features': 6, 'by': 2, 'using':11
}
主題建模:在文字資料中識別模式
通常情況下,文件會被分組為主題,而主題建模就是一種識別與特定主題相對應的文字中模式的技術。換句話說,主題建模用於揭示給定文件集中的抽象主題或隱藏結構。
你可以在以下場景中使用主題建模 -
文字分類
主題建模可以改善分類,因為它將相似的單詞組合在一起,而不是將每個單詞單獨用作特徵。
推薦系統
我們可以利用相似度測量構建推薦系統。
主題建模演算法
我們可以透過以下演算法實現主題建模 -
潛在狄利克雷分配(LDA) - 這是最流行的演算法之一,它使用機率圖模型來實現主題建模。
潛在語義分析 (LDA) 或潛在語義索引 (LSI) - 它基於線性代數,並在文件術語矩陣上使用 SVD(奇異值分解)的概念。
非負矩陣分解 (NMF) - 它也基於線性代數,與 LDA 類似。
上述演算法將具有以下元素 -
- 主題數量:引數
- 文件-單詞矩陣:輸入
- WTM(單詞主題矩陣)和 TDM(主題文件矩陣):輸出