- PyBrain 教程
- PyBrain - 首頁
- PyBrain - 概述
- PyBrain - 環境設定
- PyBrain - PyBrain 網路簡介
- PyBrain - 使用網路
- PyBrain - 使用資料集
- PyBrain - 資料集型別
- PyBrain - 匯入資料集資料
- PyBrain - 在網路上訓練資料集
- PyBrain - 測試網路
- 使用前饋網路
- PyBrain - 使用迴圈網路
- 使用最佳化演算法訓練網路
- PyBrain - 層
- PyBrain - 連線
- PyBrain - 強化學習模組
- PyBrain - API 和工具
- PyBrain - 示例
- PyBrain 有用資源
- PyBrain 快速指南
- PyBrain - 有用資源
- PyBrain - 討論
PyBrain 快速指南
PyBrain - 概述
Pybrain 是一個使用 Python 實現的機器學習開源庫。該庫為您提供了一些易於使用的網路訓練演算法、資料集和訓練器來訓練和測試網路。
其官方文件中對 Pybrain 的定義如下:
PyBrain 是一個用於 Python 的模組化機器學習庫。其目標是為機器學習任務提供靈活、易用且功能強大的演算法,以及各種預定義的環境來測試和比較您的演算法。
PyBrain 是 Python-Based Reinforcement Learning, Artificial Intelligence, and Neural Network Library 的縮寫。事實上,我們首先想出了這個名字,後來才反向設計了這個相當具有描述性的“首字母縮略詞”。
Pybrain 的特性
以下是 Pybrain 的特性:
網路
網路由模組組成,它們透過連線連線起來。Pybrain 支援諸如前饋網路、迴圈網路等神經網路。
前饋網路是一種神經網路,其中節點之間資訊沿前向方向移動,永遠不會向後傳播。前饋網路是人工神經網路中第一個也是最簡單的網路。資訊從輸入節點傳遞到隱藏節點,然後傳遞到輸出節點。
資訊從輸入節點傳遞到隱藏節點,然後傳遞到輸出節點。
迴圈網路類似於前饋網路;唯一的區別是它必須記住每一步的資料。必須儲存每一步的歷史記錄。
資料集
資料集是用於在網路上進行測試、驗證和訓練的資料。要使用的資料集型別取決於我們將使用機器學習執行的任務。Pybrain 支援的最常用的資料集是SupervisedDataSet 和 ClassificationDataSet。
SupervisedDataSet - 它包含輸入和目標欄位。它是資料集最簡單的形式,主要用於監督學習任務。
ClassificationDataSet - 它主要用於處理分類問題。它接收輸入、目標欄位,以及一個名為“類”的額外欄位,該欄位是給定目標的自動備份。例如,輸出將是 1 或 0,或者輸出將根據給定的輸入將值分組在一起,即它將屬於一個特定的類。
訓練器
當我們建立一個網路(即神經網路)時,它將根據給定的訓練資料進行訓練。現在,網路是否訓練得當將取決於在該網路上測試的測試資料的預測。Pybrain 訓練中最重要的概念是使用 BackpropTrainer 和 TrainUntilConvergence。
BackpropTrainer - 它是一個訓練器,根據監督或分類資料集(可能是順序的)訓練模組的引數,方法是反向傳播誤差(透過時間)。
TrainUntilConvergence - 用於在資料集上訓練模組,直到它收斂。
工具
Pybrain 提供工具模組,可以幫助透過匯入包來構建網路:pybrain.tools.shortcuts.buildNetwork
視覺化
無法使用 pybrain 視覺化測試資料。但 Pybrain 可以與其他框架(如 Mathplotlib、pyplot)一起工作以視覺化資料。
Pybrain 的優勢
Pybrain 的優勢在於:
Pybrain 是一個學習機器學習的開源免費庫。對於任何對機器學習感興趣的新手來說,這是一個不錯的起點。
Pybrain 使用 Python 來實現它,這使得它在開發方面比 Java/C++ 等語言快。
Pybrain 可以輕鬆地與其他 Python 庫一起工作以視覺化資料。
Pybrain 支援流行的網路,如前饋網路、迴圈網路、神經網路等。
使用 .csv 載入資料集在 Pybrain 中非常容易。它還允許使用來自其他庫的資料集。
使用 Pybrain 訓練器進行資料訓練和測試很容易。
Pybrain 的侷限性
Pybrain 對遇到的任何問題提供的幫助較少。在stackoverflow和Google Group上有一些問題沒有得到解答。
Pybrain 的工作流程
根據 Pybrain 文件,機器學習的流程如下圖所示:

在開始時,我們有原始資料,經過預處理後可用於 Pybrain。
Pybrain 的流程從資料集開始,資料集被分成訓練資料和測試資料。
建立網路,並將資料集和網路提供給訓練器。
訓練器在網路上訓練資料,並將輸出分類為訓練誤差和驗證誤差,這些誤差可以視覺化。
可以驗證測試資料,以檢視輸出是否與訓練資料匹配。
術語
在使用 Pybrain 進行機器學習時,需要考慮一些重要的術語。它們如下:
總誤差 - 它指的是網路訓練後顯示的誤差。如果誤差在每次迭代中不斷變化,則表示它仍然需要時間來穩定,直到它開始顯示迭代之間的恆定誤差。一旦它開始顯示恆定的誤差數字,就表示網路已收斂,並且無論應用任何額外的訓練,它都將保持不變。
訓練資料 - 用於訓練 Pybrain 網路的資料。
測試資料 - 用於測試經過訓練的 Pybrain 網路的資料。
訓練器 - 當我們建立一個網路(即神經網路)時,它將根據給定的訓練資料進行訓練。現在,網路是否訓練得當將取決於在該網路上測試的測試資料的預測。Pybrain 訓練中最重要的概念是使用 BackpropTrainer 和 TrainUntilConvergence。
BackpropTrainer - 它是一個訓練器,根據監督或分類資料集(可能是順序的)訓練模組的引數,方法是反向傳播誤差(透過時間)。
TrainUntilConvergence - 用於在資料集上訓練模組,直到它收斂。
層 - 層基本上是在網路的隱藏層上使用的一組函式。
連線 - 連線的工作方式類似於層;唯一的區別是它將資料從網路中的一個節點轉移到另一個節點。
模組 - 模組是包含輸入和輸出緩衝區的網路。
監督學習 - 在這種情況下,我們有輸入和輸出,我們可以使用演算法將輸入與輸出對映起來。該演算法被設計為在給定的訓練資料上學習並對其進行迭代,並且當演算法預測正確資料時,迭代過程停止。
無監督學習 - 在這種情況下,我們有輸入,但不知道輸出。無監督學習的作用是儘可能多地利用給定的資料進行訓練。
PyBrain - 環境設定
在本章中,我們將介紹 PyBrain 的安裝。要開始使用 PyBrain,我們需要首先安裝 Python。因此,我們將執行以下操作:
- 安裝 Python
- 安裝 PyBrain
安裝 Python
要安裝 Python,請訪問 Python 官方網站:www.python.org/downloads(如下所示),然後點選適用於 Windows、Linux/Unix 和 macOS 的最新版本。根據您可用的 64 位或 32 位作業系統下載 Python。
下載完成後,點選.exe檔案,然後按照步驟在您的系統上安裝 python。

python 包管理器(即 pip)也將與上述安裝一起預設安裝。為了使其在您的系統上全域性執行,請直接將 python 的位置新增到 PATH 變數中,在安裝開始時會顯示相同的內容,請記住選中“新增到 PATH”複選框。如果您忘記選中它,請按照以下步驟新增到 PATH。
新增到 PATH
要新增到 PATH,請按照以下步驟操作:
右鍵單擊“計算機”圖示,然後單擊“屬性”->“高階系統設定”。
它將顯示如下螢幕

單擊上面顯示的“環境變數”。它將顯示如下螢幕
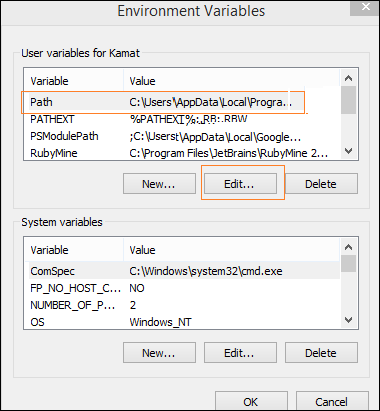
選擇 Path 並單擊“編輯”按鈕,將 python 的位置路徑新增到末尾。現在讓我們檢查 python 版本。
檢查 Python 版本
以下程式碼幫助我們檢查 Python 的版本:
E:\pybrain>python --version Python 3.7.3
安裝 PyBrain
現在我們已經安裝了 Python,我們將安裝 Pybrain。克隆 pybrain 儲存庫,如下所示:
git clone git://github.com/pybrain/pybrain.git
C:\pybrain>git clone git://github.com/pybrain/pybrain.git Cloning into 'pybrain'... remote: Enumerating objects: 2, done. remote: Counting objects: 100% (2/2), done. remote: Compressing objects: 100% (2/2), done. remote: Total 12177 (delta 0), reused 0 (delta 0), pack-reused 12175 Receiving objects: 100% (12177/12177), 13.29 MiB | 510.00 KiB/s, done. Resolving deltas: 100% (8506/8506), done.
現在執行cd pybrain並執行以下命令:
python setup.py install
此命令將在您的系統上安裝 pybrain。
完成後,要檢查 pybrain 是否已安裝,請開啟命令列提示符並啟動 python 直譯器,如下所示:
C:\pybrain\pybrain>python Python 3.7.3 (v3.7.3:ef4ec6ed12, Mar 25 2019, 22:22:05) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>>
我們可以使用以下程式碼新增 import pybrain:
>>> import pybrain >>>
如果 import pybrain 沒有任何錯誤地工作,則表示 pybrain 已成功安裝。您現在可以編寫程式碼以開始使用 pybrain。
PyBrain - PyBrain 網路簡介
PyBrain 是一個使用 Python 開發的機器學習庫。機器學習中有一些重要的概念,其中之一是網路。網路由模組組成,它們透過連線連線起來。
簡單神經網路的佈局如下:
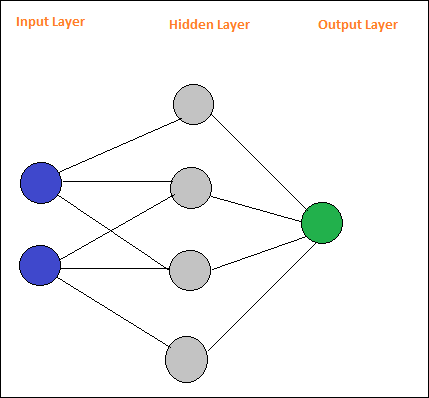
Pybrain 支援神經網路,如前饋網路、迴圈網路等。
前饋網路是一種神經網路,其中節點之間資訊沿前向方向移動,永遠不會向後傳播。前饋網路是人工神經網路中第一個也是最簡單的網路。資訊從輸入節點傳遞到隱藏節點,然後傳遞到輸出節點。
這是一個簡單的前饋網路佈局。

圓圈被稱為模組,帶箭頭的線是到模組的連線。
節點A、B、C和D是輸入節點
H1、H2、H3、H4是隱藏節點,O 是輸出。
在上述網路中,我們有 4 個輸入節點、4 個隱藏層和 1 個輸出。圖中顯示的線條數表示模型中在訓練期間調整的權重引數。
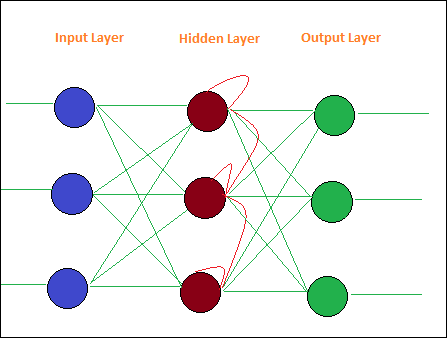
迴圈網路類似於前饋網路,唯一的區別是它必須記住每一步的資料。必須儲存每一步的歷史記錄。
這是一個簡單的迴圈網路佈局:
PyBrain - 使用網路
網路由模組組成,它們透過連線連線起來。在本章中,我們將學習:
- 建立網路
- 分析網路
建立網路
我們將使用 python 直譯器來執行我們的程式碼。要在 pybrain 中建立網路,我們必須使用buildNetwork api,如下所示:
C:\pybrain\pybrain>python Python 3.7.3 (v3.7.3:ef4ec6ed12, Mar 25 2019, 22:22:05) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> >>> >>> from pybrain.tools.shortcuts import buildNetwork >>> network = buildNetwork(2, 3, 1) >>>
我們使用 buildNetwork() 建立了一個網路,引數為 2、3、1,這意味著該網路由 2 個輸入、3 個隱藏和 1 個輸出組成。
以下是網路的詳細資訊,即模組和連線:
C:\pybrain\pybrain>python Python 3.7.3 (v3.7.3:ef4ec6ed12, Mar 25 2019, 22:22:05) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> from pybrain.tools.shortcuts import buildNetwork >>> network = buildNetwork(2,3,1) >>> print(network) FeedForwardNetwork-8 Modules: [<BiasUnit 'bias'>, <LinearLayer 'in'>, <SigmoidLayer 'hidden0'>, <LinearLay er 'out'>] Connections: [<FullConnection 'FullConnection-4': 'hidden0' -> 'out'>, <FullConnection 'F ullConnection-5': 'in' -> 'hidden0'>, <FullConnection 'FullConnection-6': 'bias' -< 'out'>, <FullConnection 'FullConnection-7': 'bias' -> 'hidden0'>] >>>
模組由層組成,連線由 FullConnection 物件構成。因此,每個模組和連線都像上面顯示的那樣命名。
網路分析
您可以透過以下方式引用模組層和連線的名稱來單獨訪問它們:
>>> network['bias'] <BiasUnit 'bias'> >>> network['in'] <LinearLayer 'in'>
PyBrain - 使用資料集
資料集是提供給測試、驗證和訓練網路的輸入資料。要使用的資料集型別取決於我們將在機器學習中執行的任務。在本章中,我們將瞭解以下內容:
- 建立資料集
- 向資料集新增資料
我們首先學習如何建立資料集並使用給定的輸入測試資料集。
建立資料集
要建立資料集,我們需要使用 pybrain 資料集包:pybrain.datasets。
Pybrain 支援諸如 SupervisedDataset、SequentialDataset、ClassificationDataSet 等資料集類。我們將使用 SupervisedDataset 來建立我們的資料集。要使用的資料集取決於使用者嘗試實現的機器學習任務。SupervisedDataset 是最簡單的,我們將在此處使用它。
一個 SupervisedDataset 資料集 需要輸入引數和目標。考慮如下所示的異或真值表:
| A | B | A XOR B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
給定的輸入類似於二維陣列,我們得到 1 個輸出。因此,這裡的輸入成為大小,目標是輸出,即 1。所以輸入到我們的資料集將是 2,1。
createdataset.py
from pybrain.datasets import SupervisedDataSet sds = SupervisedDataSet(2, 1) print(sds)
當我們執行上述程式碼 python createdataset.py 時,我們會得到以下結果:
C:\pybrain\pybrain\src>python createdataset.py input: dim(0, 2) [] target: dim(0, 1) []
它顯示瞭如上所示大小為 2 的輸入和大小為 1 的目標。
向資料集新增資料
現在讓我們向資料集新增樣本資料。
createdataset.py
from pybrain.datasets import SupervisedDataSet
sds = SupervisedDataSet(2, 1)
xorModel = [
[(0,0), (0,)],
[(0,1), (1,)],
[(1,0), (1,)],
[(1,1), (0,)],
]
for input, target in xorModel:
sds.addSample(input, target)
print("Input is:")
print(sds['input'])
print("\nTarget is:")
print(sds['target'])
我們建立了一個 XORModel 陣列,如下所示:
xorModel = [ [(0,0), (0,)], [(0,1), (1,)], [(1,0), (1,)], [(1,1), (0,)], ]
要向資料集新增資料,我們使用 addSample() 方法,該方法接收輸入和目標。
要向 addSample 新增資料,我們將迴圈遍歷 xorModel 陣列,如下所示:
for input, target in xorModel: sds.addSample(input, target)
執行後,我們得到以下輸出:
python createdataset.py
C:\pybrain\pybrain\src>python createdataset.py Input is: [[0. 0.] [0. 1.] [1. 0.] [1. 1.]] Target is: [[0.] [1.] [1.] [0.]]
您可以透過簡單地使用輸入和目標索引從建立的資料集中獲取輸入和目標詳細資訊,如下所示:
print(sds['input']) print(sds[‘target’])
PyBrain - 資料集型別
資料集是要提供給網路進行測試、驗證和訓練的資料。要使用的資料集型別取決於我們將在機器學習中執行的任務。我們將在本章中討論各種資料集型別。
我們可以透過新增以下包來處理資料集:
pybrain.dataset
SupervisedDataSet
SupervisedDataSet 包含輸入和目標欄位。它是資料集的最簡單形式,主要用於監督學習任務。
以下是您如何在程式碼中使用它的示例:
from pybrain.datasets import SupervisedDataSet
SupervisedDataSet 上可用的方法如下:
addSample(inp, target)
此方法將新增一個新的輸入和目標樣本。
splitWithProportion(proportion=0.10)
這會將資料集分成兩部分。第一部分將包含作為輸入給出的資料集的百分比,即,如果輸入為 .10,則為資料集的 10% 和 90% 的資料。您可以根據自己的選擇決定比例。劃分後的資料集可用於測試和訓練您的網路。
copy() - 返回資料集的深複製。
clear() - 清空資料集。
saveToFile(filename, format=None, **kwargs)
將物件儲存到由 filename 指定的檔案中。
示例
這是一個使用 SupervisedDataset 的工作示例:
testnetwork.py
from pybrain.tools.shortcuts import buildNetwork from pybrain.structure import TanhLayer from pybrain.datasets import SupervisedDataSet from pybrain.supervised.trainers import BackpropTrainer # Create a network with two inputs, three hidden, and one output nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=TanhLayer) # Create a dataset that matches network input and output sizes: norgate = SupervisedDataSet(2, 1) # Create a dataset to be used for testing. nortrain = SupervisedDataSet(2, 1) # Add input and target values to dataset # Values for NOR truth table norgate.addSample((0, 0), (1,)) norgate.addSample((0, 1), (0,)) norgate.addSample((1, 0), (0,)) norgate.addSample((1, 1), (0,)) # Add input and target values to dataset # Values for NOR truth table nortrain.addSample((0, 0), (1,)) nortrain.addSample((0, 1), (0,)) nortrain.addSample((1, 0), (0,)) nortrain.addSample((1, 1), (0,)) #Training the network with dataset norgate. trainer = BackpropTrainer(nn, norgate) # will run the loop 1000 times to train it. for epoch in range(1000): trainer.train() trainer.testOnData(dataset=nortrain, verbose = True)
輸出
上述程式的輸出如下:
python testnetwork.py
C:\pybrain\pybrain\src>python testnetwork.py
Testing on data:
('out: ', '[0.887 ]')
('correct:', '[1 ]')
error: 0.00637334
('out: ', '[0.149 ]')
('correct:', '[0 ]')
error: 0.01110338
('out: ', '[0.102 ]')
('correct:', '[0 ]')
error: 0.00522736
('out: ', '[-0.163]')
('correct:', '[0 ]')
error: 0.01328650
('All errors:', [0.006373344564625953, 0.01110338071737218, 0.005227359234093431
, 0.01328649974219942])
('Average error:', 0.008997646064572746)
('Max error:', 0.01328649974219942, 'Median error:', 0.01110338071737218)
ClassificationDataSet
此資料集主要用於處理分類問題。它接收輸入、目標欄位,以及一個名為“class”的額外欄位,它是給定目標的自動備份。例如,輸出將是 1 或 0,或者輸出將根據給定的輸入組合在一起,即,它將屬於一個特定的類別。
以下是您如何在程式碼中使用它的示例:
from pybrain.datasets import ClassificationDataSet Syntax // ClassificationDataSet(inp, target=1, nb_classes=0, class_labels=None)
ClassificationDataSet 上可用的方法如下:
addSample(inp, target) - 此方法將新增一個新的輸入和目標樣本。
splitByClass() - 此方法將給出兩個新的資料集,第一個資料集將包含選定的類 (0..nClasses-1),第二個資料集將包含剩餘的樣本。
_convertToOneOfMany() - 此方法將目標類轉換為 1-of-k 表示,並將舊目標保留為欄位類
這是一個 ClassificationDataSet 的工作示例。
示例
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravel
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i])
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample( training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1] )
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)
trainer = BackpropTrainer(
net, dataset=training_data, momentum=0.1,learningrate=0.01,verbose=True,weightdecay=0.01
)
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
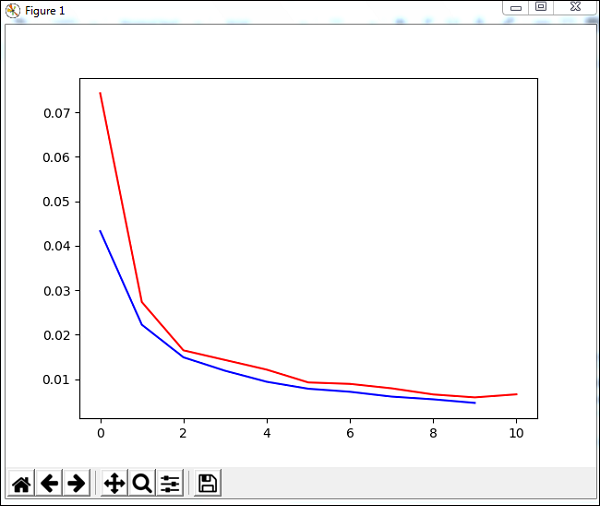
plt.plot(trnerr,'b',valerr,'r')
plt.show()
trainer.trainEpochs(10)
print('Percent Error on testData:',percentError(trainer.testOnClassData(dataset=test_data), test_data['class']))
上述示例中使用的資料集是數字資料集,類別範圍為 0-9,因此共有 10 個類別。輸入為 64,目標為 1,類別為 10。
程式碼使用資料集訓練網路,並輸出訓練誤差和驗證誤差的圖形。它還給出測試資料上的百分比誤差,如下所示:
輸出
Total error: 0.0432857814358
Total error: 0.0222276374185
Total error: 0.0149012052174
Total error: 0.011876985318
Total error: 0.00939854792853
Total error: 0.00782202445183
Total error: 0.00714707652044
Total error: 0.00606068893793
Total error: 0.00544257958975
Total error: 0.00463929281336
Total error: 0.00441275665294
('train-errors:', '[0.043286 , 0.022228 , 0.014901 , 0.011877 , 0.009399 , 0.007
822 , 0.007147 , 0.006061 , 0.005443 , 0.004639 , 0.004413 ]')
('valid-errors:', '[0.074296 , 0.027332 , 0.016461 , 0.014298 , 0.012129 , 0.009
248 , 0.008922 , 0.007917 , 0.006547 , 0.005883 , 0.006572 , 0.005811 ]')
Percent Error on testData: 3.34075723830735
PyBrain - 匯入資料集資料
在本章中,我們將學習如何獲取資料以使用 Pybrain 資料集。
最常用的資料集是:
- 使用 sklearn
- 從 CSV 檔案
使用 sklearn
使用 sklearn
以下是 sklearn 資料集詳細資訊的連結:https://scikit-learn.org/stable/datasets/toy_dataset.html
以下是如何使用 sklearn 資料集的一些示例:
示例 1:load_digits()
from sklearn import datasets from pybrain.datasets import ClassificationDataSet digits = datasets.load_digits() X, y = digits.data, digits.target ds = ClassificationDataSet(64, 1, nb_classes=10) for i in range(len(X)): ds.addSample(ravel(X[i]), y[i])
示例 2:load_iris()
from sklearn import datasets from pybrain.datasets import ClassificationDataSet digits = datasets.load_iris() X, y = digits.data, digits.target ds = ClassificationDataSet(4, 1, nb_classes=3) for i in range(len(X)): ds.addSample(X[i], y[i])
從 CSV 檔案
我們還可以使用來自 csv 檔案的資料,如下所示:
以下是異或真值表的樣本資料:datasettest.csv

以下是如何從 .csv 檔案讀取資料集資料的示例。
示例
from pybrain.tools.shortcuts import buildNetwork
from pybrain.structure import TanhLayer
from pybrain.datasets import SupervisedDataSet
from pybrain.supervised.trainers import BackpropTrainer
import pandas as pd
print('Read data...')
df = pd.read_csv('data/datasettest.csv',header=0).head(1000)
data = df.values
train_output = data[:,0]
train_data = data[:,1:]
print(train_output)
print(train_data)
# Create a network with two inputs, three hidden, and one output
nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=TanhLayer)
# Create a dataset that matches network input and output sizes:
_gate = SupervisedDataSet(2, 1)
# Create a dataset to be used for testing.
nortrain = SupervisedDataSet(2, 1)
# Add input and target values to dataset
# Values for NOR truth table
for i in range(0, len(train_output)) :
_gate.addSample(train_data[i], train_output[i])
#Training the network with dataset norgate.
trainer = BackpropTrainer(nn, _gate)
# will run the loop 1000 times to train it.
for epoch in range(1000):
trainer.train()
trainer.testOnData(dataset=_gate, verbose = True)
Panda 用於從 csv 檔案讀取資料,如示例所示。
輸出
C:\pybrain\pybrain\src>python testcsv.py
Read data...
[0 1 1 0]
[
[0 0]
[0 1]
[1 0]
[1 1]
]
Testing on data:
('out: ', '[0.004 ]')
('correct:', '[0 ]')
error: 0.00000795
('out: ', '[0.997 ]')
('correct:', '[1 ]')
error: 0.00000380
('out: ', '[0.996 ]')
('correct:', '[1 ]')
error: 0.00000826
('out: ', '[0.004 ]')
('correct:', '[0 ]')
error: 0.00000829
('All errors:', [7.94733477723902e-06, 3.798267582566822e-06, 8.260969076585322e
-06, 8.286246525558165e-06])
('Average error:', 7.073204490487332e-06)
('Max error:', 8.286246525558165e-06, 'Median error:', 8.260969076585322e-06)
PyBrain - 在網路上訓練資料集
到目前為止,我們已經瞭解瞭如何建立網路和資料集。要將資料集和網路一起使用,我們必須藉助訓練器來實現。
以下是一個工作示例,展示如何將資料集新增到建立的網路中,然後使用訓練器進行訓練和測試。
testnetwork.py
from pybrain.tools.shortcuts import buildNetwork from pybrain.structure import TanhLayer from pybrain.datasets import SupervisedDataSet from pybrain.supervised.trainers import BackpropTrainer # Create a network with two inputs, three hidden, and one output nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=TanhLayer) # Create a dataset that matches network input and output sizes: norgate = SupervisedDataSet(2, 1) # Create a dataset to be used for testing. nortrain = SupervisedDataSet(2, 1) # Add input and target values to dataset # Values for NOR truth table norgate.addSample((0, 0), (1,)) norgate.addSample((0, 1), (0,)) norgate.addSample((1, 0), (0,)) norgate.addSample((1, 1), (0,)) # Add input and target values to dataset # Values for NOR truth table nortrain.addSample((0, 0), (1,)) nortrain.addSample((0, 1), (0,)) nortrain.addSample((1, 0), (0,)) nortrain.addSample((1, 1), (0,)) #Training the network with dataset norgate. trainer = BackpropTrainer(nn, norgate) # will run the loop 1000 times to train it. for epoch in range(1000): trainer.train() trainer.testOnData(dataset=nortrain, verbose = True)
要測試網路和資料集,我們需要 BackpropTrainer。BackpropTrainer 是一種訓練器,它根據監督資料集(可能是順序的)訓練模組的引數,方法是反向傳播誤差(透過時間)。
我們建立了 2 個 SupervisedDataSet 類的 Dataset。我們使用 NOR 資料模型,如下所示:
| A | B | A NOR B |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 0 |
上述資料模型用於訓練網路。
norgate = SupervisedDataSet(2, 1) # Add input and target values to dataset # Values for NOR truth table norgate.addSample((0, 0), (1,)) norgate.addSample((0, 1), (0,)) norgate.addSample((1, 0), (0,)) norgate.addSample((1, 1), (0,))
以下是用於測試的資料集:
# Create a dataset to be used for testing. nortrain = SupervisedDataSet(2, 1) # Add input and target values to dataset # Values for NOR truth table norgate.addSample((0, 0), (1,)) norgate.addSample((0, 1), (0,)) norgate.addSample((1, 0), (0,)) norgate.addSample((1, 1), (0,))
訓練器使用方法如下:
#Training the network with dataset norgate. trainer = BackpropTrainer(nn, norgate) # will run the loop 1000 times to train it. for epoch in range(1000): trainer.train()
要測試資料集,我們可以使用以下程式碼:
trainer.testOnData(dataset=nortrain, verbose = True)
輸出
python testnetwork.py
C:\pybrain\pybrain\src>python testnetwork.py
Testing on data:
('out: ', '[0.887 ]')
('correct:', '[1 ]')
error: 0.00637334
('out: ', '[0.149 ]')
('correct:', '[0 ]')
error: 0.01110338
('out: ', '[0.102 ]')
('correct:', '[0 ]')
error: 0.00522736
('out: ', '[-0.163]')
('correct:', '[0 ]')
error: 0.01328650
('All errors:', [0.006373344564625953, 0.01110338071737218, 0.005227359234093431
, 0.01328649974219942])
('Average error:', 0.008997646064572746)
('Max error:', 0.01328649974219942, 'Median error:', 0.01110338071737218)
如果您檢視輸出,測試資料幾乎與我們提供的資料集匹配,因此誤差為 0.008。
現在讓我們更改測試資料並檢視平均誤差。我們已更改輸出,如下所示:
以下是用於測試的資料集:
# Create a dataset to be used for testing. nortrain = SupervisedDataSet(2, 1) # Add input and target values to dataset # Values for NOR truth table norgate.addSample((0, 0), (0,)) norgate.addSample((0, 1), (1,)) norgate.addSample((1, 0), (1,)) norgate.addSample((1, 1), (0,))
現在讓我們測試它。
輸出
python testnework.py
C:\pybrain\pybrain\src>python testnetwork.py
Testing on data:
('out: ', '[0.988 ]')
('correct:', '[0 ]')
error: 0.48842978
('out: ', '[0.027 ]')
('correct:', '[1 ]')
error: 0.47382097
('out: ', '[0.021 ]')
('correct:', '[1 ]')
error: 0.47876379
('out: ', '[-0.04 ]')
('correct:', '[0 ]')
error: 0.00079160
('All errors:', [0.4884297811030845, 0.47382096780393873, 0.47876378995939756, 0
.0007915982149002194])
('Average error:', 0.3604515342703303)
('Max error:', 0.4884297811030845, 'Median error:', 0.47876378995939756)
我們得到的誤差為 0.36,這表明我們的測試資料與訓練的網路並不完全匹配。
PyBrain - 測試網路
在本章中,我們將看到一些示例,我們將訓練資料並在訓練資料上測試誤差。
我們將使用以下訓練器:
BackpropTrainer
BackpropTrainer 是一種訓練器,它根據監督或 ClassificationDataSet 資料集(可能是順序的)訓練模組的引數,方法是反向傳播誤差(透過時間)。
TrainUntilConvergence
它用於在資料集上訓練模組,直到它收斂。
當我們建立一個神經網路時,它將根據提供給它的訓練資料進行訓練。現在,網路是否經過正確訓練將取決於在該網路上測試的測試資料的預測。
讓我們一步一步地檢視一個工作示例,其中我們將構建一個神經網路並預測訓練誤差、測試誤差和驗證誤差。
測試我們的網路
以下是我們將遵循的測試網路步驟:
- 匯入所需的 PyBrain 和其他包
- 建立 ClassificationDataSet
- 將資料集拆分為 25% 作為測試資料和 75% 作為訓練資料
- 將測試資料和訓練資料轉換回 ClassificationDataSet
- 建立神經網路
- 訓練網路
- 視覺化誤差和驗證資料
- 測試資料誤差百分比
步驟 1
匯入所需的 PyBrain 和其他包。
我們需要匯入的包如下所示:
from sklearn import datasets import matplotlib.pyplot as plt from pybrain.datasets import ClassificationDataSet from pybrain.utilities import percentError from pybrain.tools.shortcuts import buildNetwork from pybrain.supervised.trainers import BackpropTrainer from pybrain.structure.modules import SoftmaxLayer from numpy import ravel
步驟 2
下一步是建立 ClassificationDataSet。
對於資料集,我們將使用 sklearn 資料集中的資料集,如下所示:
請參閱以下連結中 sklearn 中的 load_digits 資料集:
digits = datasets.load_digits() X, y = digits.data, digits.target ds = ClassificationDataSet(64, 1, nb_classes=10) # we are having inputs are 64 dim array and since the digits are from 0-9 the classes considered is 10. for i in range(len(X)): ds.addSample(ravel(X[i]), y[i]) # adding sample to datasets
步驟 3
將資料集拆分為 25% 作為測試資料和 75% 作為訓練資料:
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)
因此,在這裡,我們對名為 splitWithProportion() 的資料集使用了一個方法,其值為 0.25,它將資料集拆分為 25% 作為測試資料和 75% 作為訓練資料。
步驟 4
將測試資料和訓練資料轉換回 ClassificationDataSet。
test_data = ClassificationDataSet(64, 1, nb_classes=10) for n in range(0, test_data_temp.getLength()): test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] ) training_data = ClassificationDataSet(64, 1, nb_classes=10) for n in range(0, training_data_temp.getLength()): training_data.addSample( training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1] ) test_data._convertToOneOfMany() training_data._convertToOneOfMany()
對資料集使用 splitWithProportion() 方法會將資料集轉換為 superviseddataset,因此我們將資料集轉換回 classificationdataset,如上一步所示。
步驟 5
下一步是建立神經網路。
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)
我們正在建立一個網路,其中輸入和輸出來自訓練資料。
步驟 6
訓練網路
現在重要的一步是在資料集上訓練網路,如下所示:
trainer = BackpropTrainer(net, dataset=training_data, momentum=0.1,learningrate=0.01,verbose=True,weightdecay=0.01)
我們使用 BackpropTrainer() 方法並在建立的網路上使用資料集。
步驟 7
下一步是視覺化資料的誤差和驗證。
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10) plt.plot(trnerr,'b',valerr,'r') plt.show()
我們將使用一個名為 trainUntilConvergence 的方法在訓練資料上進行收斂,該方法將收斂 10 個 epoch。它將返回訓練誤差和驗證誤差,我們已將其繪製如下。藍線表示訓練誤差,紅線表示驗證誤差。

執行上述程式碼期間接收到的總誤差如下所示:
Total error: 0.0432857814358
Total error: 0.0222276374185
Total error: 0.0149012052174
Total error: 0.011876985318
Total error: 0.00939854792853
Total error: 0.00782202445183
Total error: 0.00714707652044
Total error: 0.00606068893793
Total error: 0.00544257958975
Total error: 0.00463929281336
Total error: 0.00441275665294
('train-errors:', '[0.043286 , 0.022228 , 0.014901 , 0.011877 , 0.009399 , 0.007
822 , 0.007147 , 0.006061 , 0.005443 , 0.004639 , 0.004413 ]')
('valid-errors:', '[0.074296 , 0.027332 , 0.016461 , 0.014298 , 0.012129 , 0.009
248 , 0.008922 , 0.007917 , 0.006547 , 0.005883 , 0.006572 , 0.005811 ]')
誤差從 0.04 開始,然後在每個 epoch 中下降,這意味著網路正在訓練並且每個 epoch 都變得更好。
步驟 8
測試資料誤差百分比
我們可以使用 percentError 方法檢查百分比誤差,如下所示:
print('Percent Error on
testData:',percentError(trainer.testOnClassData(dataset=test_data),
test_data['class']))
testData 上的百分比誤差 - 3.34075723830735
我們得到了誤差百分比,即 3.34%,這意味著神經網路的準確率為 97%。
以下是完整程式碼:
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravel
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i])
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample(
training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1]
)
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)
trainer = BackpropTrainer(
net, dataset=training_data, momentum=0.1,
learningrate=0.01,verbose=True,weightdecay=0.01
)
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
plt.plot(trnerr,'b',valerr,'r')
plt.show()
trainer.trainEpochs(10)
print('Percent Error on testData:',percentError(
trainer.testOnClassData(dataset=test_data), test_data['class']
))
PyBrain - 使用前饋網路
前饋網路是一種神經網路,其中節點之間資訊沿前向方向移動,永遠不會向後傳播。前饋網路是人工神經網路中第一個也是最簡單的網路。資訊從輸入節點傳遞到隱藏節點,然後傳遞到輸出節點。
在本章中,我們將討論如何:
- 建立前饋網路
- 向 FFN 新增連線和模組
建立前饋網路
您可以使用您選擇的 Python IDE,例如 PyCharm。在這裡,我們使用 Visual Studio Code 編寫程式碼,並在終端中執行相同的程式碼。
要建立前饋網路,我們需要從 pybrain.structure 中匯入它,如下所示:
ffn.py
from pybrain.structure import FeedForwardNetwork network = FeedForwardNetwork() print(network)
執行 ffn.py,如下所示:
C:\pybrain\pybrain\src>python ffn.py FeedForwardNetwork-0 Modules: [] Connections: []
我們沒有向前饋網路新增任何模組和連線。因此,網路顯示模組和連線的空陣列。
新增模組和連線
首先,我們將建立輸入層、隱藏層、輸出層,並將它們新增到模組中,如下所示:
ffy.py
from pybrain.structure import FeedForwardNetwork from pybrain.structure import LinearLayer, SigmoidLayer network = FeedForwardNetwork() #creating layer for input => 2 , hidden=> 3 and output=>1 inputLayer = LinearLayer(2) hiddenLayer = SigmoidLayer(3) outputLayer = LinearLayer(1) #adding the layer to feedforward network network.addInputModule(inputLayer) network.addModule(hiddenLayer) network.addOutputModule(outputLayer) print(network)
輸出
C:\pybrain\pybrain\src>python ffn.py FeedForwardNetwork-3 Modules: [] Connections: []
我們仍然獲取空模組和連線。我們需要為建立的模組提供連線,如下所示:
這是我們建立輸入層、隱藏層和輸出層之間的連線,並將連線新增到網路中的程式碼。
ffy.py
from pybrain.structure import FeedForwardNetwork from pybrain.structure import LinearLayer, SigmoidLayer from pybrain.structure import FullConnection network = FeedForwardNetwork() #creating layer for input => 2 , hidden=> 3 and output=>1 inputLayer = LinearLayer(2) hiddenLayer = SigmoidLayer(3) outputLayer = LinearLayer(1) #adding the layer to feedforward network network.addInputModule(inputLayer) network.addModule(hiddenLayer) network.addOutputModule(outputLayer) #Create connection between input ,hidden and output input_to_hidden = FullConnection(inputLayer, hiddenLayer) hidden_to_output = FullConnection(hiddenLayer, outputLayer) #add connection to the network network.addConnection(input_to_hidden) network.addConnection(hidden_to_output) print(network)
輸出
C:\pybrain\pybrain\src>python ffn.py FeedForwardNetwork-3 Modules: [] Connections: []
我們仍然無法獲取模組和連線。現在讓我們新增最後一步,即我們需要新增 sortModules() 方法,如下所示:
ffy.py
from pybrain.structure import FeedForwardNetwork from pybrain.structure import LinearLayer, SigmoidLayer from pybrain.structure import FullConnection network = FeedForwardNetwork() #creating layer for input => 2 , hidden=> 3 and output=>1 inputLayer = LinearLayer(2) hiddenLayer = SigmoidLayer(3) outputLayer = LinearLayer(1) #adding the layer to feedforward network network.addInputModule(inputLayer) network.addModule(hiddenLayer) network.addOutputModule(outputLayer) #Create connection between input ,hidden and output input_to_hidden = FullConnection(inputLayer, hiddenLayer) hidden_to_output = FullConnection(hiddenLayer, outputLayer) #add connection to the network network.addConnection(input_to_hidden) network.addConnection(hidden_to_output) network.sortModules() print(network)
輸出
C:\pybrain\pybrain\src>python ffn.py FeedForwardNetwork-6 Modules: [<LinearLayer 'LinearLayer-3'gt;, <SigmoidLayer 'SigmoidLayer-7'>, <LinearLayer 'LinearLayer-8'>] Connections: [<FullConnection 'FullConnection-4': 'SigmoidLayer-7' -> 'LinearLayer-8'>, <FullConnection 'FullConnection-5': 'LinearLayer-3' -> 'SigmoidLayer-7'>]
現在我們可以看到前饋網路的模組和連線詳細資訊。
PyBrain - 使用迴圈網路
迴圈網路與前饋網路相同,唯一的區別是您需要記住每個步驟的資料。必須儲存每個步驟的歷史記錄。
我們將學習如何:
- 建立迴圈網路
- 新增模組和連線
建立迴圈網路
要建立迴圈網路,我們將使用 RecurrentNetwork 類,如下所示:
rn.py
from pybrain.structure import RecurrentNetwork recurrentn = RecurrentNetwork() print(recurrentn)
python rn.py
C:\pybrain\pybrain\src>python rn.py RecurrentNetwork-0 Modules: [] Connections: [] Recurrent Connections: []
我們可以看到迴圈網路有一個名為“迴圈連線”的新連線。目前沒有可用資料。
現在讓我們建立層並新增到模組中並建立連線。
新增模組和連線
我們將建立層,即輸入層、隱藏層和輸出層。這些層將新增到輸入和輸出模組中。接下來,我們將建立從輸入到隱藏、從隱藏到輸出以及從隱藏到隱藏的迴圈連線。
以下是包含模組和連線的迴圈網路程式碼。
rn.py
from pybrain.structure import RecurrentNetwork from pybrain.structure import LinearLayer, SigmoidLayer from pybrain.structure import FullConnection recurrentn = RecurrentNetwork() #creating layer for input => 2 , hidden=> 3 and output=>1 inputLayer = LinearLayer(2, 'rn_in') hiddenLayer = SigmoidLayer(3, 'rn_hidden') outputLayer = LinearLayer(1, 'rn_output') #adding the layer to feedforward network recurrentn.addInputModule(inputLayer) recurrentn.addModule(hiddenLayer) recurrentn.addOutputModule(outputLayer) #Create connection between input ,hidden and output input_to_hidden = FullConnection(inputLayer, hiddenLayer) hidden_to_output = FullConnection(hiddenLayer, outputLayer) hidden_to_hidden = FullConnection(hiddenLayer, hiddenLayer) #add connection to the network recurrentn.addConnection(input_to_hidden) recurrentn.addConnection(hidden_to_output) recurrentn.addRecurrentConnection(hidden_to_hidden) recurrentn.sortModules() print(recurrentn)
python rn.py
C:\pybrain\pybrain\src>python rn.py RecurrentNetwork-6 Modules: [<LinearLayer 'rn_in'>, <SigmoidLayer 'rn_hidden'>, <LinearLayer 'rn_output'>] Connections: [<FullConnection 'FullConnection-4': 'rn_hidden' -> 'rn_output'>, <FullConnection 'FullConnection-5': 'rn_in' -> 'rn_hidden'>] Recurrent Connections: [<FullConnection 'FullConnection-3': 'rn_hidden' -> 'rn_hidden'>]
在上面的輸出中,我們可以看到模組、連線和迴圈連線。
現在讓我們使用 activate 方法啟用網路,如下所示:
rn.py
將以下程式碼新增到之前建立的程式碼中:
#activate network using activate() method act1 = recurrentn.activate((2, 2)) print(act1) act2 = recurrentn.activate((2, 2)) print(act2)
python rn.py
C:\pybrain\pybrain\src>python rn.py [-1.24317586] [-0.54117783]
使用最佳化演算法訓練網路
我們已經瞭解瞭如何在 pybrain 中使用訓練器訓練網路。在本章中,我們將使用 Pybrain 提供的最佳化演算法來訓練網路。
在本例中,我們將使用 GA 最佳化演算法,該演算法需要匯入,如下所示:
from pybrain.optimization.populationbased.ga import GA
示例
以下是使用 GA 最佳化演算法訓練網路的工作示例:
from pybrain.datasets.classification import ClassificationDataSet
from pybrain.optimization.populationbased.ga import GA
from pybrain.tools.shortcuts import buildNetwork
# create XOR dataset
ds = ClassificationDataSet(2)
ds.addSample([0., 0.], [0.])
ds.addSample([0., 1.], [1.])
ds.addSample([1., 0.], [1.])
ds.addSample([1., 1.], [0.])
ds.setField('class', [ [0.],[1.],[1.],[0.]])
net = buildNetwork(2, 3, 1)
ga = GA(ds.evaluateModuleMSE, net, minimize=True)
for i in range(100):
net = ga.learn(0)[0]
print(net.activate([0,0]))
print(net.activate([1,0]))
print(net.activate([0,1]))
print(net.activate([1,1]))
輸出
網路對輸入的 activate 方法的結果與輸出幾乎匹配,如下所示:
C:\pybrain\pybrain\src>python example15.py [0.03055398] [0.92094839] [1.12246157] [0.02071285]
PyBrain - 層
層基本上是一組用於網路隱藏層的函式。
在本章中,我們將詳細瞭解以下關於層的內容:
- 理解層
- 使用 Pybrain 建立層
理解層
我們之前已經看到了使用層的示例,如下所示:
- TanhLayer
- SoftmaxLayer
使用 TanhLayer 的示例
以下是一個使用 TanhLayer 構建網路的示例:
testnetwork.py
from pybrain.tools.shortcuts import buildNetwork from pybrain.structure import TanhLayer from pybrain.datasets import SupervisedDataSet from pybrain.supervised.trainers import BackpropTrainer # Create a network with two inputs, three hidden, and one output nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=TanhLayer) # Create a dataset that matches network input and output sizes: norgate = SupervisedDataSet(2, 1) # Create a dataset to be used for testing. nortrain = SupervisedDataSet(2, 1) # Add input and target values to dataset # Values for NOR truth table norgate.addSample((0, 0), (1,)) norgate.addSample((0, 1), (0,)) norgate.addSample((1, 0), (0,)) norgate.addSample((1, 1), (0,)) # Add input and target values to dataset # Values for NOR truth table nortrain.addSample((0, 0), (1,)) nortrain.addSample((0, 1), (0,)) nortrain.addSample((1, 0), (0,)) nortrain.addSample((1, 1), (0,)) #Training the network with dataset norgate. trainer = BackpropTrainer(nn, norgate) # will run the loop 1000 times to train it. for epoch in range(1000): trainer.train() trainer.testOnData(dataset=nortrain, verbose = True)
輸出
上述程式碼的輸出如下:
python testnetwork.py
C:\pybrain\pybrain\src>python testnetwork.py
Testing on data:
('out: ', '[0.887 ]')
('correct:', '[1 ]')
error: 0.00637334
('out: ', '[0.149 ]')
('correct:', '[0 ]')
error: 0.01110338
('out: ', '[0.102 ]')
('correct:', '[0 ]')
error: 0.00522736
('out: ', '[-0.163]')
('correct:', '[0 ]')
error: 0.01328650
('All errors:', [0.006373344564625953, 0.01110338071737218,
0.005227359234093431, 0.01328649974219942])
('Average error:', 0.008997646064572746)
('Max error:', 0.01328649974219942, 'Median error:', 0.01110338071737218)
使用 SoftMaxLayer 的示例
以下是一個使用 SoftmaxLayer 構建網路的示例:
from pybrain.tools.shortcuts import buildNetwork from pybrain.structure.modules import SoftmaxLayer from pybrain.datasets import SupervisedDataSet from pybrain.supervised.trainers import BackpropTrainer # Create a network with two inputs, three hidden, and one output nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=SoftmaxLayer) # Create a dataset that matches network input and output sizes: norgate = SupervisedDataSet(2, 1) # Create a dataset to be used for testing. nortrain = SupervisedDataSet(2, 1) # Add input and target values to dataset # Values for NOR truth table norgate.addSample((0, 0), (1,)) norgate.addSample((0, 1), (0,)) norgate.addSample((1, 0), (0,)) norgate.addSample((1, 1), (0,)) # Add input and target values to dataset # Values for NOR truth table nortrain.addSample((0, 0), (1,)) nortrain.addSample((0, 1), (0,)) nortrain.addSample((1, 0), (0,)) nortrain.addSample((1, 1), (0,)) #Training the network with dataset norgate. trainer = BackpropTrainer(nn, norgate) # will run the loop 1000 times to train it. for epoch in range(1000): trainer.train() trainer.testOnData(dataset=nortrain, verbose = True)
輸出
輸出如下:
C:\pybrain\pybrain\src>python example16.py
Testing on data:
('out: ', '[0.918 ]')
('correct:', '[1 ]')
error: 0.00333524
('out: ', '[0.082 ]')
('correct:', '[0 ]')
error: 0.00333484
('out: ', '[0.078 ]')
('correct:', '[0 ]')
error: 0.00303433
('out: ', '[-0.082]')
('correct:', '[0 ]')
error: 0.00340005
('All errors:', [0.0033352368788838365, 0.003334842961037291,
0.003034328685718761, 0.0034000458892589056])
('Average error:', 0.0032761136037246985)
('Max error:', 0.0034000458892589056, 'Median error:', 0.0033352368788838365)
在 Pybrain 中建立層
在 Pybrain 中,您可以建立自己的層,如下所示:
要建立層,您需要使用 **NeuronLayer 類**作為基類來建立所有型別的層。
示例
from pybrain.structure.modules.neuronlayer import NeuronLayer
class LinearLayer(NeuronLayer):
def _forwardImplementation(self, inbuf, outbuf):
outbuf[:] = inbuf
def _backwardImplementation(self, outerr, inerr, outbuf, inbuf):
inerr[:] = outer
要建立層,我們需要實現兩個方法:_forwardImplementation() 和 _backwardImplementation()。
**_forwardImplementation() 接收 2 個引數 inbuf 和 outbuf**,它們是 Scipy 陣列。其大小取決於層的輸入和輸出維度。
_backwardImplementation() 用於計算給定輸出相對於輸入的導數。
因此,要在 Pybrain 中實現一個層,這是層類的框架:
from pybrain.structure.modules.neuronlayer import NeuronLayer
class NewLayer(NeuronLayer):
def _forwardImplementation(self, inbuf, outbuf):
pass
def _backwardImplementation(self, outerr, inerr, outbuf, inbuf):
pass
如果您想將二次多項式函式實現為一個層,我們可以這樣做:
假設我們有一個多項式函式:
f(x) = 3x2
上述多項式函式的導數如下:
f(x) = 6 x
上述多項式函式的最終層類如下:
testlayer.py
from pybrain.structure.modules.neuronlayer import NeuronLayer
class PolynomialLayer(NeuronLayer):
def _forwardImplementation(self, inbuf, outbuf):
outbuf[:] = 3*inbuf**2
def _backwardImplementation(self, outerr, inerr, outbuf, inbuf):
inerr[:] = 6*inbuf*outerr
現在讓我們使用建立的層,如下所示:
testlayer1.py
from testlayer import PolynomialLayer from pybrain.tools.shortcuts import buildNetwork from pybrain.tests.helpers import gradientCheck n = buildNetwork(2, 3, 1, hiddenclass=PolynomialLayer) n.randomize() gradientCheck(n)
GradientCheck() 將測試層是否正常工作。我們需要傳遞使用該層的網路到 gradientCheck(n)。如果層工作正常,它將輸出“Perfect Gradient”。
輸出
C:\pybrain\pybrain\src>python testlayer1.py Perfect gradient
PyBrain - 連線
連線的工作方式類似於層;唯一的區別在於它將資料從網路中的一個節點轉移到另一個節點。
在本章中,我們將學習:
- 理解連線
- 建立連線
理解連線
以下是在建立網路時使用連線的工作示例。
示例
ffy.py
from pybrain.structure import FeedForwardNetwork from pybrain.structure import LinearLayer, SigmoidLayer from pybrain.structure import FullConnection network = FeedForwardNetwork() #creating layer for input => 2 , hidden=> 3 and output=>1 inputLayer = LinearLayer(2) hiddenLayer = SigmoidLayer(3) outputLayer = LinearLayer(1) #adding the layer to feedforward network network.addInputModule(inputLayer) network.addModule(hiddenLayer) network.addOutputModule(outputLayer) #Create connection between input ,hidden and output input_to_hidden = FullConnection(inputLayer, hiddenLayer) hidden_to_output = FullConnection(hiddenLayer, outputLayer) #add connection to the network network.addConnection(input_to_hidden) network.addConnection(hidden_to_output) network.sortModules() print(network)
輸出
C:\pybrain\pybrain\src>python ffn.py FeedForwardNetwork-6 Modules: [<LinearLayer 'LinearLayer-3'>, <SigmoidLayer 'SigmoidLayer-7'>, <LinearLayer 'LinearLayer-8'>] Connections: [<FullConnection 'FullConnection-4': 'SigmoidLayer-7' -> 'LinearLayer-8'>, <FullConnection 'FullConnection-5': 'LinearLayer-3' -> 'SigmoidLayer-7'>]
建立連線
在 Pybrain 中,我們可以使用 connection 模組建立連線,如下所示:
示例
connect.py
from pybrain.structure.connections.connection import Connection
class YourConnection(Connection):
def __init__(self, *args, **kwargs):
Connection.__init__(self, *args, **kwargs)
def _forwardImplementation(self, inbuf, outbuf):
outbuf += inbuf
def _backwardImplementation(self, outerr, inerr, inbuf):
inerr += outer
要建立連線,有兩種方法:_forwardImplementation() 和 _backwardImplementation()。
_forwardImplementation() 使用傳入模組的輸出緩衝區 inbuf 和傳出模組的輸入緩衝區 outbuf 呼叫。inbuf 被新增到傳出模組 outbuf 中。
_backwardImplementation() 使用 outerr、inerr 和 inbuf 呼叫。傳出模組的錯誤在 _backwardImplementation() 中新增到傳入模組的錯誤中。
現在讓我們在網路中使用 **YourConnection**。
testconnection.py
from pybrain.structure import FeedForwardNetwork from pybrain.structure import LinearLayer, SigmoidLayer from connect import YourConnection network = FeedForwardNetwork() #creating layer for input => 2 , hidden=> 3 and output=>1 inputLayer = LinearLayer(2) hiddenLayer = SigmoidLayer(3) outputLayer = LinearLayer(1) #adding the layer to feedforward network network.addInputModule(inputLayer) network.addModule(hiddenLayer) network.addOutputModule(outputLayer) #Create connection between input ,hidden and output input_to_hidden = YourConnection(inputLayer, hiddenLayer) hidden_to_output = YourConnection(hiddenLayer, outputLayer) #add connection to the network network.addConnection(input_to_hidden) network.addConnection(hidden_to_output) network.sortModules() print(network)
輸出
C:\pybrain\pybrain\src>python testconnection.py FeedForwardNetwork-6 Modules: [<LinearLayer 'LinearLayer-3'>, <SigmoidLayer 'SigmoidLayer-7'>, <LinearLayer 'LinearLayer-8'>] Connections: [<YourConnection 'YourConnection-4': 'LinearLayer-3' -> 'SigmoidLayer-7'>, <YourConnection 'YourConnection-5': 'SigmoidLayer-7' -> 'LinearLayer-8'>]
PyBrain - 強化學習模組
強化學習 (RL) 是機器學習中的一個重要部分。強化學習使智慧體能夠根據環境的輸入學習其行為。
在強化學習過程中相互作用的元件如下:
- 環境
- 智慧體
- 任務
- 實驗
強化學習的佈局如下所示:

在 RL 中,智慧體與環境進行迭代互動。在每次迭代中,智慧體都會收到一個包含獎勵的觀察結果。然後它選擇動作併發送到環境中。環境在每次迭代中都會轉移到一個新的狀態,並且每次收到的獎勵都會被儲存。
RL 智慧體的目標是收集儘可能多的獎勵。在迭代之間,智慧體的效能會與以良好方式執行動作的智慧體的效能進行比較,並且效能差異會導致獎勵或失敗。RL 主要用於解決機器人控制、電梯、電信、遊戲等問題。
讓我們看看如何在 Pybrain 中使用 RL。
我們將使用迷宮 **環境**,該環境將使用二維 numpy 陣列表示,其中 1 是牆壁,0 是空閒區域。智慧體的職責是在空閒區域移動並找到目標點。
以下是使用迷宮環境的分步流程。
步驟 1
使用以下程式碼匯入所需的包:
from scipy import * import sys, time import matplotlib.pyplot as pylab # for visualization we are using mathplotlib from pybrain.rl.environments.mazes import Maze, MDPMazeTask from pybrain.rl.learners.valuebased import ActionValueTable from pybrain.rl.agents import LearningAgent from pybrain.rl.learners import Q, QLambda, SARSA #@UnusedImport from pybrain.rl.explorers import BoltzmannExplorer #@UnusedImport from pybrain.rl.experiments import Experiment from pybrain.rl.environments import Task
步驟 2
使用以下程式碼建立迷宮環境:
# create the maze with walls as 1 and 0 is a free field mazearray = array( [[1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 1, 0, 0, 0, 0, 1], [1, 0, 0, 1, 0, 0, 1, 0, 1], [1, 0, 0, 1, 0, 0, 1, 0, 1], [1, 0, 0, 1, 0, 1, 1, 0, 1], [1, 0, 0, 0, 0, 0, 1, 0, 1], [1, 1, 1, 1, 1, 1, 1, 0, 1], [1, 0, 0, 0, 0, 0, 0, 0, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1]] ) env = Maze(mazearray, (7, 7)) # create the environment, the first parameter is the maze array and second one is the goal field tuple
步驟 3
下一步是建立智慧體。
智慧體在 RL 中起著重要作用。它將使用 getAction() 和 integrateObservation() 方法與迷宮環境進行互動。
智慧體有一個控制器(將狀態對映到動作)和一個學習器。
PyBrain 中的控制器就像一個模組,其輸入是狀態,並將它們轉換為動作。
controller = ActionValueTable(81, 4) controller.initialize(1.)
**ActionValueTable** 需要 2 個輸入,即狀態數和動作數。標準迷宮環境有 4 個動作:北、南、東、西。
現在我們將建立一個學習器。我們將使用 SARSA() 學習演算法作為學習器,以便與智慧體一起使用。
learner = SARSA() agent = LearningAgent(controller, learner)
步驟 4
此步驟是將智慧體新增到環境中。
要將智慧體連線到環境,我們需要一個稱為任務的特殊元件。**任務**的作用是在環境中尋找目標,以及智慧體如何獲得動作獎勵。
環境有自己的任務。我們使用的迷宮環境具有 MDPMazeTask 任務。MDP 代表 **“馬爾可夫決策過程”**,這意味著智慧體知道自己在迷宮中的位置。環境將作為任務的引數。
task = MDPMazeTask(env)
步驟 5
將智慧體新增到環境中的下一步是建立實驗。
現在我們需要建立實驗,以便任務和智慧體可以相互協調。
experiment = Experiment(task, agent)
現在我們將執行實驗 1000 次,如下所示:
for i in range(1000): experiment.doInteractions(100) agent.learn() agent.reset()
當以下程式碼執行時,環境將在智慧體和任務之間執行 100 次。
experiment.doInteractions(100)
每次迭代後,它都會將新狀態返回給任務,任務會決定應該將哪些資訊和獎勵傳遞給智慧體。我們將在學習和重置 for 迴圈內的智慧體後繪製一個新表格。
for i in range(1000):
experiment.doInteractions(100)
agent.learn()
agent.reset()
pylab.pcolor(table.params.reshape(81,4).max(1).reshape(9,9))
pylab.savefig("test.png")
以下是完整程式碼:
示例
maze.py
from scipy import *
import sys, time
import matplotlib.pyplot as pylab
from pybrain.rl.environments.mazes import Maze, MDPMazeTask
from pybrain.rl.learners.valuebased import ActionValueTable
from pybrain.rl.agents import LearningAgent
from pybrain.rl.learners import Q, QLambda, SARSA #@UnusedImport
from pybrain.rl.explorers import BoltzmannExplorer #@UnusedImport
from pybrain.rl.experiments import Experiment
from pybrain.rl.environments import Task
# create maze array
mazearray = array(
[[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 1, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1]]
)
env = Maze(mazearray, (7, 7))
# create task
task = MDPMazeTask(env)
#controller in PyBrain is like a module, for which the input is states and
convert them into actions.
controller = ActionValueTable(81, 4)
controller.initialize(1.)
# create agent with controller and learner - using SARSA()
learner = SARSA()
# create agent
agent = LearningAgent(controller, learner)
# create experiment
experiment = Experiment(task, agent)
# prepare plotting
pylab.gray()
pylab.ion()
for i in range(1000):
experiment.doInteractions(100)
agent.learn()
agent.reset()
pylab.pcolor(controller.params.reshape(81,4).max(1).reshape(9,9))
pylab.savefig("test.png")
輸出
python maze.py

空閒區域的顏色將在每次迭代時更改。
PyBrain - API 和工具
現在我們知道如何構建網路並對其進行訓練。在本章中,我們將瞭解如何建立和儲存網路,以及在需要時如何使用網路。
儲存和恢復網路
我們將使用 Pybrain 工具中的 NetworkWriter 和 NetworkReader,即 pybrain.tools.customxml。
以下是一個工作示例:
from pybrain.tools.shortcuts import buildNetwork
from pybrain.tools.customxml import NetworkWriter
from pybrain.tools.customxml import NetworkReader
net = buildNetwork(2,1,1)
NetworkWriter.writeToFile(net, 'network.xml')
net = NetworkReader.readFrom('network.xml')
網路儲存在 network.xml 中。
NetworkWriter.writeToFile(net, 'network.xml')
要讀取所需的 xml,我們可以使用以下程式碼:
net = NetworkReader.readFrom('network.xml')
以下是建立的 network.xml 檔案:
<?xml version="1.0" ?>
<PyBrain>
<Network class="pybrain.structure.networks.feedforward.FeedForwardNetwork" name="FeedForwardNetwork-8">
<name val="'FeedForwardNetwork-8'"/>
<Modules>
<LinearLayer class="pybrain.structure.modules.linearlayer.LinearLayer" inmodule="True" name="in">
<name val="'in'"/>
<dim val="2"/>
</LinearLayer>
<LinearLayer class="pybrain.structure.modules.linearlayer.LinearLayer" name="out" outmodule="True">
<name val="'out'"/>
<dim val="1"/>
</LinearLayer>
<BiasUnit class="pybrain.structure.modules.biasunit.BiasUnit" name="bias">
<name val="'bias'"/>
</BiasUnit>
<SigmoidLayer class="pybrain.structure.modules.sigmoidlayer.SigmoidLayer" name="hidden0">
<name val="'hidden0'"/>
<dim val="1"/>
</SigmoidLayer>
</Modules>
<Connections>
<FullConnection class="pybrain.structure.connections.full.FullConnection" name="FullConnection-6">
<inmod val="bias"/>
<outmod val="out"/>
<Parameters>[1.2441093186965146]</Parameters>
</FullConnection>
<FullConnection class="pybrain.structure.connections.full.FullConnection" name="FullConnection-7">
<inmod val="bias"/>
<outmod val="hidden0"/>
<Parameters>[-1.5743530012126412]</Parameters>
</FullConnection>
<FullConnection class="pybrain.structure.connections.full.FullConnection" name="FullConnection-4">
<inmod val="in"/>
<outmod val="hidden0"/>
<Parameters>[-0.9429546042034236, -0.09858196752687162]</Parameters>
</FullConnection>
<FullConnection class="pybrain.structure.connections.full.FullConnection" name="FullConnection-5">
<inmod val="hidden0"/>
<outmod val="out"/>
<Parameters>[-0.29205472354634304]</Parameters>
</FullConnection>
</Connections>
</Network>
</PyBrain>
API
以下是我們在本教程中使用過的 API 列表。
對於網路
**activate(input)** - 它接受引數,即要測試的值。它將根據給定的輸入返回結果。
**activateOnDataset(dataset)** - 它將遍歷給定的資料集並返回輸出。
**addConnection(c)** - 將連線新增到網路。
**addInputModule(m)** - 將給定的模組新增到網路並將其標記為輸入模組。
**addModule(m)** - 將給定的模組新增到網路。
**addOutputModule(m)** - 將模組新增到網路並將其標記為輸出模組。
**reset()** - 重置模組和網路。
**sortModules()** - 它透過內部排序來準備網路進行啟用。必須在啟用之前呼叫它。
對於監督資料集
**addSample(inp, target)** - 新增輸入和目標的新樣本。
**splitWithProportion(proportion=0.5)** - 將資料集分成兩部分,第一部分包含比例部分資料,下一部分包含其餘資料。
對於訓練器
**trainUntilConvergence(dataset=None, maxEpochs=None, verbose=None, continueEpochs=10, validationProportion=0.25)** - 用於在模組收斂之前對其進行訓練。如果未給出資料集,它將嘗試訓練在開始時使用的訓練資料集。
PyBrain - 示例
在本章中,列出了所有使用 PyBrain 執行的示例。
示例 1
使用 NOR 真值表並測試其正確性。
from pybrain.tools.shortcuts import buildNetwork from pybrain.structure import TanhLayer from pybrain.datasets import SupervisedDataSet from pybrain.supervised.trainers import BackpropTrainer # Create a network with two inputs, three hidden, and one output nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=TanhLayer) # Create a dataset that matches network input and output sizes: norgate = SupervisedDataSet(2, 1) # Create a dataset to be used for testing. nortrain = SupervisedDataSet(2, 1) # Add input and target values to dataset # Values for NOR truth table norgate.addSample((0, 0), (1,)) norgate.addSample((0, 1), (0,)) norgate.addSample((1, 0), (0,)) norgate.addSample((1, 1), (0,)) # Add input and target values to dataset # Values for NOR truth table nortrain.addSample((0, 0), (1,)) nortrain.addSample((0, 1), (0,)) nortrain.addSample((1, 0), (0,)) nortrain.addSample((1, 1), (0,)) #Training the network with dataset norgate. trainer = BackpropTrainer(nn, norgate) # will run the loop 1000 times to train it. for epoch in range(1000): trainer.train() trainer.testOnData(dataset=nortrain, verbose = True)
輸出
C:\pybrain\pybrain\src>python testnetwork.py
Testing on data:
('out: ', '[0.887 ]')
('correct:', '[1 ]')
error: 0.00637334
('out: ', '[0.149 ]')
('correct:', '[0 ]')
error: 0.01110338
('out: ', '[0.102 ]')
('correct:', '[0 ]')
error: 0.00522736
('out: ', '[-0.163]')
('correct:', '[0 ]')
error: 0.01328650
('All errors:', [0.006373344564625953, 0.01110338071737218,
0.005227359234093431, 0.01328649974219942])
('Average error:', 0.008997646064572746)
('Max error:', 0.01328649974219942, 'Median error:', 0.01110338071737218)
示例 2
對於資料集,我們將使用來自 sklearn 資料集的資料集,如下所示:參考 sklearn 中的 load_digits 資料集: scikit-learn.org
它有 10 個類別,即需要預測的數字 0-9。
X 中的總輸入資料為 64。
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravel
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10) )
# we are having inputs are 64 dim array and since the digits are from 0-9
the classes considered is 10.
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i]) # adding sample to datasets
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)
#Splitting the datasets 25% as testdata and 75% as trained data
# Using splitWithProportion() method on dataset converts the dataset to
#superviseddataset, so we will convert the dataset back to classificationdataset
#as shown in above step.
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample(
training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1]
)
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()
net = buildNetwork(
training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer
)
#creating a network wherein the input and output are used from the training data.
trainer = BackpropTrainer(
net, dataset=training_data, momentum=0.1,learningrate=0.01,verbose=True,weightdecay=0.01
)
#Training the Network
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
#Visualizing the error and validation data
plt.plot(trnerr,'b',valerr,'r')
plt.show()
trainer.trainEpochs(10)
print('Percent Error on testData:',percentError(
trainer.testOnClassData(dataset=test_data), test_data['class']
))
輸出

Total error: 0.0432857814358
Total error: 0.0222276374185
Total error: 0.0149012052174
Total error: 0.011876985318
Total error: 0.00939854792853
Total error: 0.00782202445183
Total error: 0.00714707652044
Total error: 0.00606068893793
Total error: 0.00544257958975
Total error: 0.00463929281336
Total error: 0.00441275665294
('train-errors:', '[0.043286 , 0.022228 , 0.014901 , 0.011877 , 0.009399 , 0.007
822 , 0.007147 , 0.006061 , 0.005443 , 0.004639 , 0.004413 ]')
('valid-errors:', '[0.074296 , 0.027332 , 0.016461 , 0.014298 , 0.012129 , 0.009
248 , 0.008922 , 0.007917 , 0.006547 , 0.005883 , 0.006572 , 0.005811 ]')
Percent Error on testData: 3.34075723830735