- PL/SQL 教程
- PL/SQL - 首頁
- PL/SQL - 概述
- PL/SQL - 環境
- PL/SQL - 基本語法
- PL/SQL - 資料型別
- PL/SQL - 變數
- PL/SQL - 常量和字面量
- PL/SQL - 運算子
- PL/SQL - 條件語句
- PL/SQL - 迴圈語句
- PL/SQL - 字串
- PL/SQL - 陣列
- PL/SQL - 過程
- PL/SQL - 函式
- PL/SQL - 遊標
- PL/SQL - 記錄
- PL/SQL - 異常處理
- PL/SQL - 觸發器
- PL/SQL - 包
- PL/SQL - 集合
- PL/SQL - 事務
- PL/SQL - 日期和時間
- PL/SQL - DBMS 輸出
- PL/SQL - 面向物件
- PL/SQL 有用資源
- PL/SQL - 常見問題解答
- PL/SQL 快速指南
- PL/SQL - 有用資源
- PL/SQL - 討論
PL/SQL 快速指南
PL/SQL - 概述
PL/SQL程式語言是由Oracle公司在20世紀80年代後期開發的,它是SQL和Oracle關係資料庫的過程擴充套件語言。以下是關於PL/SQL的一些值得注意的事實:
PL/SQL是一種完全可移植的、高效能的事務處理語言。
PL/SQL提供了一個內建的、解釋型的、與作業系統無關的程式設計環境。
PL/SQL也可以直接從命令列**SQL*Plus介面**呼叫。
也可以從外部程式語言呼叫資料庫。
PL/SQL的通用語法基於ADA和Pascal程式語言。
除了Oracle之外,PL/SQL還在**TimesTen記憶體資料庫**和**IBM DB2**中可用。
PL/SQL 的特性
PL/SQL具有以下特性:
- PL/SQL與SQL緊密整合。
- 它提供了廣泛的錯誤檢查。
- 它提供了許多資料型別。
- 它提供了各種程式設計結構。
- 它透過函式和過程支援結構化程式設計。
- 它支援面向物件程式設計。
- 它支援Web應用程式和伺服器頁面的開發。
PL/SQL 的優點
PL/SQL具有以下優點:
SQL是標準的資料庫語言,PL/SQL與SQL緊密整合。PL/SQL支援靜態SQL和動態SQL。靜態SQL支援來自PL/SQL塊的DML操作和事務控制。在動態SQL中,SQL允許在PL/SQL塊中嵌入DDL語句。
PL/SQL允許一次將整個語句塊傳送到資料庫。這減少了網路流量,併為應用程式提供了高效能。
PL/SQL可以提高程式設計師的生產力,因為它可以查詢、轉換和更新資料庫中的資料。
PL/SQL透過強大的功能(例如異常處理、封裝、資料隱藏和麵向物件資料型別)節省了設計和除錯時間。
用PL/SQL編寫的應用程式是完全可移植的。
PL/SQL提供高安全級別。
PL/SQL可以訪問預定義的SQL包。
PL/SQL支援面向物件程式設計。
PL/SQL支援開發Web應用程式和伺服器頁面。
PL/SQL - 環境設定
本章將討論PL/SQL的環境設定。PL/SQL不是一種獨立的程式語言;它是Oracle程式設計環境中的一個工具。**SQL*Plus**是一個互動式工具,允許您在命令提示符下鍵入SQL和PL/SQL語句。然後將這些命令傳送到資料庫進行處理。語句處理完成後,結果將被髮送回並顯示在螢幕上。
要執行PL/SQL程式,您的計算機上應安裝Oracle RDBMS伺服器。這將負責執行SQL命令。最新的Oracle RDBMS版本是11g。您可以從以下連結下載Oracle 11g的試用版:
您需要根據您的作業系統下載32位或64位版本的安裝程式。通常有兩個檔案。我們下載了64位版本。您也可以在您的作業系統上使用類似的步驟,無論它是Linux還是Solaris。
win64_11gR2_database_1of2.zip
win64_11gR2_database_2of2.zip
下載上述兩個檔案後,您需要將它們解壓到單個目錄**database**中,並在該目錄下找到以下子目錄:

步驟 1
現在讓我們使用安裝檔案啟動Oracle資料庫安裝程式。以下是第一個螢幕。您可以提供您的電子郵件ID並選中複選框,如下面的螢幕截圖所示。單擊**下一步**按鈕。

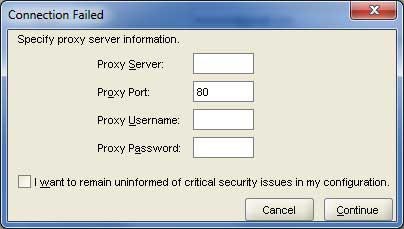
步驟 2
您將被定向到以下螢幕;取消選中複選框並單擊**繼續**按鈕繼續。
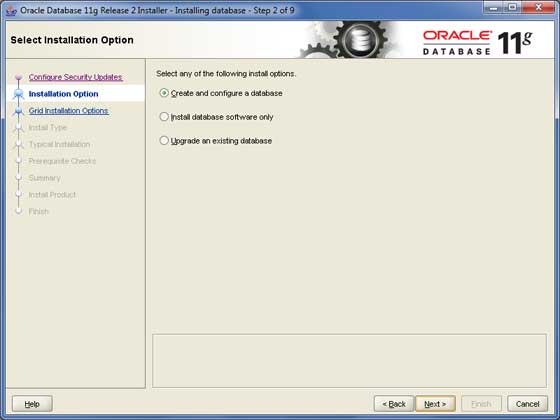
步驟 3
只需選擇第一個選項**建立和配置資料庫**,然後單擊**下一步**按鈕繼續。
步驟 4
我們假設您安裝Oracle是為了學習基本目的,並且您將其安裝在您的PC或筆記型電腦上。因此,選擇**桌面級**選項,然後單擊**下一步**按鈕繼續。

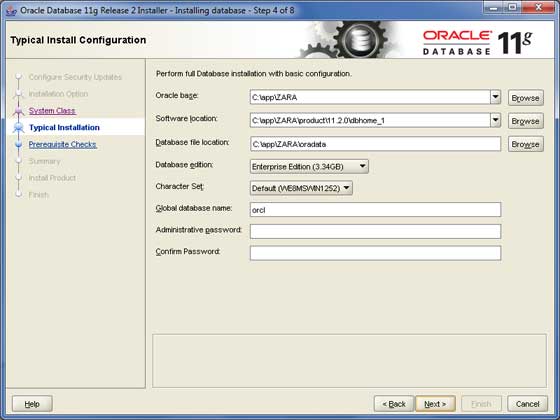
步驟 5
提供一個安裝Oracle伺服器的位置。只需修改**Oracle Base**,其他位置將自動設定。您還必須提供密碼;系統DBA將使用此密碼。提供所需資訊後,單擊**下一步**按鈕繼續。
步驟 6
再次單擊**下一步**按鈕繼續。

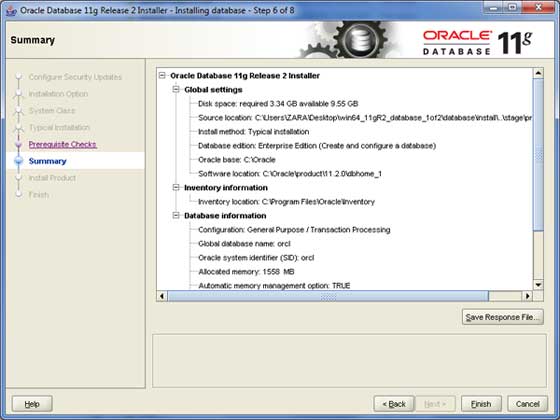
步驟 7
單擊**完成**按鈕繼續;這將啟動實際的伺服器安裝。
步驟 8
這將需要一些時間,直到Oracle開始執行所需的配置。
步驟 9
在這裡,Oracle安裝將複製所需的配置檔案。這應該需要一些時間:
步驟 10
複製資料庫檔案後,您將看到以下對話方塊。只需單擊**確定**按鈕並退出。
步驟 11
安裝後,您將看到以下最終視窗。
最後一步
現在是驗證您的安裝的時候了。如果您使用的是Windows,請在命令提示符下使用以下命令:
sqlplus "/ as sysdba"
您應該會看到SQL提示符,您可以在其中編寫PL/SQL命令和指令碼:

文字編輯器
從命令提示符執行大型程式可能會導致您無意中丟失一些工作。始終建議使用命令檔案。要使用命令檔案:
在文字編輯器(如**記事本、Notepad+**或**EditPlus**等)中鍵入您的程式碼。
將檔案儲存為**.sql**副檔名,並儲存在主目錄中。
從建立PL/SQL檔案的目錄啟動**SQL*Plus命令提示符**。
在SQL*Plus命令提示符下鍵入**@file_name**以執行您的程式。
如果您不使用檔案來執行PL/SQL指令碼,則只需複製您的PL/SQL程式碼,然後右鍵單擊顯示SQL提示符的黑色視窗;使用**貼上**選項將完整程式碼貼上到命令提示符中。最後,只需按**Enter**鍵執行程式碼(如果尚未執行)。
PL/SQL - 基本語法
本章將討論PL/SQL的基本語法,它是一種**塊結構**語言;這意味著PL/SQL程式被劃分為邏輯程式碼塊。每個塊都包含三個子部分:
| 序號 | 部分及描述 |
|---|---|
| 1 |
宣告部分 此部分以關鍵字**DECLARE**開頭。它是可選部分,定義程式中將使用的所有變數、遊標、子程式和其他元素。 |
| 2 |
可執行命令 此部分包含在關鍵字**BEGIN**和**END**之間,它是必填部分。它包含程式的可執行PL/SQL語句。它應該至少有一行可執行程式碼,這可能只是一條**NULL命令**,表示不執行任何操作。 |
| 3 | 異常處理 此部分以關鍵字**EXCEPTION**開頭。此可選部分包含處理程式中錯誤的**異常**。 |
每個PL/SQL語句都以分號(;)結尾。PL/SQL塊可以使用**BEGIN**和**END**巢狀在其他PL/SQL塊中。以下是PL/SQL塊的基本結構:
DECLARE <declarations section> BEGIN <executable command(s)> EXCEPTION <exception handling> END;
“Hello World”示例
DECLARE message varchar2(20):= 'Hello, World!'; BEGIN dbms_output.put_line(message); END; /
**end;**行表示PL/SQL塊的結尾。要從SQL命令列執行程式碼,您可能需要在程式碼最後一行後的第一行空白行開頭鍵入/。當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Hello World PL/SQL procedure successfully completed.
PL/SQL識別符號
PL/SQL識別符號是常量、變數、異常、過程、遊標和保留字。識別符號由一個字母組成,後面可以選擇跟更多字母、數字、美元符號、下劃線和數字符號,並且不應超過30個字元。
預設情況下,**識別符號不區分大小寫**。因此,您可以使用**integer**或**INTEGER**來表示數值。您不能使用保留關鍵字作為識別符號。
PL/SQL分隔符
分隔符是一個具有特殊含義的符號。以下是PL/SQL中分隔符的列表:
| 分隔符 | 描述 |
|---|---|
| +, -, *, / | 加法、減法/負號、乘法、除法 |
| % | 屬性指示符 |
| ' | 字元字串分隔符 |
| . | 元件選擇器 |
| (,) | 表示式或列表分隔符 |
| : | 主機變數指示符 |
| , | 專案分隔符 |
| " | 帶引號的識別符號分隔符 |
| = | 關係運算符 |
| @ | 遠端訪問指示符 |
| ; | 語句終止符 |
| := | 賦值運算子 |
| => | 關聯運算子 |
| || | 連線運算子 |
| ** | 求冪運算子 |
| <<, >> | 標籤分隔符(begin 和 end) |
| /*, */ | 多行註釋分隔符(begin 和 end) |
| -- | 單行註釋指示符 |
| .. | 範圍運算子 |
| <, >, <=, >= | 關係運算符 |
| <>, '=, ~=, ^= | 不同版本的NOT EQUAL |
PL/SQL註釋
程式註釋是可以包含在您編寫的PL/SQL程式碼中的解釋性語句,可以幫助任何閱讀其原始碼的人。所有程式語言都允許某種形式的註釋。
PL/SQL支援單行和多行註釋。PL/SQL編譯器會忽略任何註釋中包含的所有字元。PL/SQL單行註釋以分隔符--(雙連字元)開頭,多行註釋用/*和*/括起來。
DECLARE -- variable declaration message varchar2(20):= 'Hello, World!'; BEGIN /* * PL/SQL executable statement(s) */ dbms_output.put_line(message); END; /
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Hello World PL/SQL procedure successfully completed.
PL/SQL程式單元
PL/SQL單元可以是以下任何一個:
- PL/SQL塊
- 函式
- 包
- 包體
- 過程
- 觸發器
- 型別
- 型別體
這些單元中的每一個都將在後續章節中討論。
PL/SQL - 資料型別
本章將討論PL/SQL中的資料型別。PL/SQL變數、常量和引數必須具有有效的資料型別,該型別指定儲存格式、約束和有效值範圍。本章將重點介紹**標量**和**LOB**資料型別。其他兩種資料型別將在其他章節中介紹。
| 序號 | 類別及描述 |
|---|---|
| 1 | 標量 沒有內部元件的單值,例如數字、日期或布林值。 |
| 2 | 大型物件 (LOB) 指向儲存在其他資料項之外的大型物件的指標,例如文字、圖形影像、影片剪輯和聲音波形。 |
| 3 | 複合型別 具有可單獨訪問的內部元件的資料項。例如,集合和記錄。 |
| 4 | 引用 指向其他資料項的指標。 |
PL/SQL 標量資料型別和子型別
PL/SQL 標量資料型別和子型別屬於以下類別:
| 序號 | 資料型別和描述 |
|---|---|
| 1 | 數值型 執行算術運算的數值。 |
| 2 | 字元型 表示單個字元或字元字串的字母數字值。 |
| 3 | 布林型 執行邏輯運算的邏輯值。 |
| 4 | 日期時間型 日期和時間。 |
PL/SQL 提供資料型別的子型別。例如,資料型別 NUMBER 具有名為 INTEGER 的子型別。您可以在 PL/SQL 程式中使用子型別,以使資料型別與其他程式中的資料型別相容,同時將 PL/SQL 程式碼嵌入到另一個程式中,例如 Java 程式。
PL/SQL 數值資料型別和子型別
下表列出了 PL/SQL 預定義的數值資料型別及其子型別:
| 序號 | 資料型別和描述 |
|---|---|
| 1 | PLS_INTEGER 範圍為 -2,147,483,648 到 2,147,483,647 的帶符號整數,用 32 位表示 |
| 2 | BINARY_INTEGER 範圍為 -2,147,483,648 到 2,147,483,647 的帶符號整數,用 32 位表示 |
| 3 | BINARY_FLOAT 單精度 IEEE 754 格式浮點數 |
| 4 | BINARY_DOUBLE 雙精度 IEEE 754 格式浮點數 |
| 5 | NUMBER(prec, scale) 定點或浮點數,絕對值範圍為 1E-130 到(但不包括)1.0E126。NUMBER 變數也可以表示 0 |
| 6 | DEC(prec, scale) ANSI 特定的定點型別,最大精度為 38 位小數 |
| 7 | DECIMAL(prec, scale) IBM 特定的定點型別,最大精度為 38 位小數 |
| 8 | NUMERIC(pre, secale) 最大精度為 38 位小數的浮點型別 |
| 9 | DOUBLE PRECISION ANSI 特定的浮點型別,最大精度為 126 位二進位制數字(大約 38 位小數) |
| 10 | FLOAT ANSI 和 IBM 特定的浮點型別,最大精度為 126 位二進位制數字(大約 38 位小數) |
| 11 | INT ANSI 特定的整數型別,最大精度為 38 位小數 |
| 12 | INTEGER ANSI 和 IBM 特定的整數型別,最大精度為 38 位小數 |
| 13 | SMALLINT ANSI 和 IBM 特定的整數型別,最大精度為 38 位小數 |
| 14 | REAL 浮點型別,最大精度為 63 位二進位制數字(大約 18 位小數) |
以下是一個有效的宣告:
DECLARE num1 INTEGER; num2 REAL; num3 DOUBLE PRECISION; BEGIN null; END; /
編譯並執行上述程式碼後,將產生以下結果:
PL/SQL procedure successfully completed
PL/SQL 字元資料型別和子型別
以下是 PL/SQL 預定義的字元資料型別及其子型別的詳細資訊:
| 序號 | 資料型別和描述 |
|---|---|
| 1 | CHAR 最大大小為 32,767 位元組的固定長度字元字串 |
| 2 | VARCHAR2 最大大小為 32,767 位元組的可變長度字元字串 |
| 3 | RAW 最大大小為 32,767 位元組的可變長度二進位制或位元組字串,PL/SQL 不解釋 |
| 4 | NCHAR 最大大小為 32,767 位元組的固定長度國家字元字串 |
| 5 | NVARCHAR2 最大大小為 32,767 位元組的可變長度國家字元字串 |
| 6 | LONG 最大大小為 32,760 位元組的可變長度字元字串 |
| 7 | LONG RAW 最大大小為 32,760 位元組的可變長度二進位制或位元組字串,PL/SQL 不解釋 |
| 8 | ROWID 物理行識別符號,普通表中行的地址 |
| 9 | UROWID 通用行識別符號(物理、邏輯或外部行識別符號) |
PL/SQL 布林資料型別
BOOLEAN 資料型別儲存用於邏輯運算的邏輯值。邏輯值是布林值 TRUE 和 FALSE 以及值 NULL。
但是,SQL 沒有與 BOOLEAN 等效的資料型別。因此,布林值不能用於:
- SQL 語句
- 內建 SQL 函式(例如 TO_CHAR)
- 從 SQL 語句呼叫的 PL/SQL 函式
PL/SQL 日期時間和區間型別
DATE 資料型別用於儲存固定長度的日期時間,其中包括自午夜以來的秒數。有效日期範圍從公元前 4712 年 1 月 1 日到公元 9999 年 12 月 31 日。
預設日期格式由 Oracle 初始化引數 NLS_DATE_FORMAT 設定。例如,預設值可能是 'DD-MON-YY',其中包括月份的兩位數字、月份名稱的縮寫和年份的後兩位數字。例如,01-OCT-12。
每個 DATE 包括世紀、年份、月份、日期、小時、分鐘和秒。下表顯示每個欄位的有效值:
| 欄位名稱 | 有效日期時間值 | 有效區間值 |
|---|---|---|
| YEAR | -4712 到 9999(不包括年份 0) | 任何非零整數 |
| MONTH | 01 到 12 | 0 到 11 |
| DAY | 01 到 31(根據區域設定日曆規則,受 MONTH 和 YEAR 值的限制) | 任何非零整數 |
| HOUR | 00 到 23 | 0 到 23 |
| MINUTE | 00 到 59 | 0 到 59 |
| SECOND | 00 到 59.9(n),其中 9(n) 是時間小數秒的精度 | 0 到 59.9(n),其中 9(n) 是區間小數秒的精度 |
| TIMEZONE_HOUR | -12 到 14(範圍適應夏令時變化) | 不適用 |
| TIMEZONE_MINUTE | 00 到 59 | 不適用 |
| TIMEZONE_REGION | 在動態效能檢視 V$TIMEZONE_NAMES 中找到 | 不適用 |
| TIMEZONE_ABBR | 在動態效能檢視 V$TIMEZONE_NAMES 中找到 | 不適用 |
PL/SQL 大型物件 (LOB) 資料型別
大型物件 (LOB) 資料型別指的是大型資料項,例如文字、圖形影像、影片剪輯和聲音波形。LOB 資料型別允許對這些資料進行高效的、隨機的、分段的訪問。以下是預定義的 PL/SQL LOB 資料型別:
| 資料型別 | 描述 | 大小 |
|---|---|---|
| BFILE | 用於在資料庫外部的作業系統檔案中儲存大型二進位制物件。 | 系統相關。不能超過 4 千兆位元組 (GB)。 |
| BLOB | 用於在資料庫中儲存大型二進位制物件。 | 8 到 128 太位元組 (TB) |
| CLOB | 用於在資料庫中儲存大型字元資料塊。 | 8 到 128 TB |
| NCLOB | 用於在資料庫中儲存大型 NCHAR 資料塊。 | 8 到 128 TB |
PL/SQL 使用者定義的子型別
子型別是另一種資料型別的子集,稱為其基型別。子型別與其基型別具有相同的有效操作,但只有其有效值的子集。
PL/SQL 在包 STANDARD 中預定義了幾個子型別。例如,PL/SQL 預定義了子型別 CHARACTER 和 INTEGER,如下所示:
SUBTYPE CHARACTER IS CHAR; SUBTYPE INTEGER IS NUMBER(38,0);
您可以定義和使用您自己的子型別。以下程式說明了定義和使用使用者定義的子型別:
DECLARE
SUBTYPE name IS char(20);
SUBTYPE message IS varchar2(100);
salutation name;
greetings message;
BEGIN
salutation := 'Reader ';
greetings := 'Welcome to the World of PL/SQL';
dbms_output.put_line('Hello ' || salutation || greetings);
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Hello Reader Welcome to the World of PL/SQL PL/SQL procedure successfully completed.
PL/SQL 中的 NULL 值
PL/SQL NULL 值表示缺失或未知資料,它們不是整數、字元或任何其他特定資料型別。請注意,NULL 與空資料字串或空字元值 '\0' 不相同。可以賦值 NULL,但不能將其與任何東西等同,包括自身。
PL/SQL - 變數
在本章中,我們將討論 Pl/SQL 中的變數。變數只不過是程式可以操作的儲存區域的名稱。PL/SQL 中的每個變數都具有特定的資料型別,這決定了變數記憶體的大小和佈局;可以儲存在該記憶體中的值的範圍以及可以應用於該變數的操作集。
PL/SQL 變數的名稱由一個字母組成,後面可以選擇跟多個字母、數字、美元符號、下劃線和數字符號,並且不應超過 30 個字元。預設情況下,變數名稱不區分大小寫。您不能使用保留的 PL/SQL 關鍵字作為變數名。
PL/SQL 程式語言允許定義各種型別的變數,例如日期時間資料型別、記錄、集合等,我們將在後續章節中介紹。對於本章,讓我們只學習基本的變數型別。
PL/SQL 中的變數宣告
必須在宣告部分或包中作為全域性變數宣告 PL/SQL 變數。宣告變數時,PL/SQL 會為變數的值分配記憶體,並且儲存位置由變數名標識。
宣告變數的語法如下:
variable_name [CONSTANT] datatype [NOT NULL] [:= | DEFAULT initial_value]
其中,variable_name 是 PL/SQL 中的有效識別符號,datatype 必須是有效的 PL/SQL 資料型別或任何我們已經在上一章中討論過的使用者定義的資料型別。一些有效的變數宣告及其定義如下所示:
sales number(10, 2); pi CONSTANT double precision := 3.1415; name varchar2(25); address varchar2(100);
當您為資料型別提供大小、比例或精度限制時,這稱為受約束宣告。受約束宣告比不受約束宣告需要更少的記憶體。例如:
sales number(10, 2); name varchar2(25); address varchar2(100);
在 PL/SQL 中初始化變數
每當您宣告一個變數時,PL/SQL 都會為其分配 NULL 的預設值。如果要使用非 NULL 值初始化變數,可以在宣告期間使用以下任一方法:
DEFAULT 關鍵字
賦值運算子
例如:
counter binary_integer := 0; greetings varchar2(20) DEFAULT 'Have a Good Day';
您還可以使用 NOT NULL 約束指定變數不應具有 NULL 值。如果使用 NOT NULL 約束,則必須為該變數顯式分配初始值。
正確初始化變數是一種良好的程式設計習慣,否則,有時程式會產生意外的結果。嘗試以下示例,該示例使用了各種型別的變數:
DECLARE
a integer := 10;
b integer := 20;
c integer;
f real;
BEGIN
c := a + b;
dbms_output.put_line('Value of c: ' || c);
f := 70.0/3.0;
dbms_output.put_line('Value of f: ' || f);
END;
/
執行上述程式碼後,將產生以下結果:
Value of c: 30 Value of f: 23.333333333333333333 PL/SQL procedure successfully completed.
PL/SQL 中的變數作用域
PL/SQL 允許巢狀塊,即每個程式塊可能包含另一個內部塊。如果在內部塊中聲明瞭一個變數,則外部塊無法訪問它。但是,如果在外部塊中宣告並可以訪問一個變數,則所有巢狀的內部塊也可以訪問它。有兩種型別的變數作用域:
區域性變數 - 在內部塊中宣告的變數,外部塊無法訪問。
全域性變數 - 在最外層塊或包中宣告的變數。
下面的例子以簡單的方式展示了區域性和全域性變數的用法:
DECLARE
-- Global variables
num1 number := 95;
num2 number := 85;
BEGIN
dbms_output.put_line('Outer Variable num1: ' || num1);
dbms_output.put_line('Outer Variable num2: ' || num2);
DECLARE
-- Local variables
num1 number := 195;
num2 number := 185;
BEGIN
dbms_output.put_line('Inner Variable num1: ' || num1);
dbms_output.put_line('Inner Variable num2: ' || num2);
END;
END;
/
執行上述程式碼後,將產生以下結果:
Outer Variable num1: 95 Outer Variable num2: 85 Inner Variable num1: 195 Inner Variable num2: 185 PL/SQL procedure successfully completed.
將SQL查詢結果賦值給PL/SQL變數
您可以使用SQL的SELECT INTO語句將值賦給PL/SQL變數。對於SELECT列表中的每個專案,都必須在INTO列表中有一個型別相容的對應變數。下面的例子說明了這個概念。讓我們建立一個名為CUSTOMERS的表:
(關於SQL語句,請參考SQL教程)
CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), SALARY DECIMAL (18, 2), PRIMARY KEY (ID) ); Table Created
現在讓我們向表中插入一些值:
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Ramesh', 32, 'Ahmedabad', 2000.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (2, 'Khilan', 25, 'Delhi', 1500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (3, 'kaushik', 23, 'Kota', 2000.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (4, 'Chaitali', 25, 'Mumbai', 6500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (5, 'Hardik', 27, 'Bhopal', 8500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (6, 'Komal', 22, 'MP', 4500.00 );
下面的程式使用SQL的SELECT INTO子句將上述表中的值賦給PL/SQL變數:
DECLARE
c_id customers.id%type := 1;
c_name customers.name%type;
c_addr customers.address%type;
c_sal customers.salary%type;
BEGIN
SELECT name, address, salary INTO c_name, c_addr, c_sal
FROM customers
WHERE id = c_id;
dbms_output.put_line
('Customer ' ||c_name || ' from ' || c_addr || ' earns ' || c_sal);
END;
/
執行上述程式碼後,將產生以下結果:
Customer Ramesh from Ahmedabad earns 2000 PL/SQL procedure completed successfully
PL/SQL - 常量和字面量
本章將討論PL/SQL中的常量和字面量。常量儲存一個值,一旦宣告,程式中就不會改變。常量宣告指定其名稱、資料型別和值,併為其分配儲存空間。宣告還可以施加NOT NULL約束。
宣告常量
常量使用CONSTANT關鍵字宣告。它需要一個初始值,並且不允許更改該值。例如:
PI CONSTANT NUMBER := 3.141592654;
DECLARE
-- constant declaration
pi constant number := 3.141592654;
-- other declarations
radius number(5,2);
dia number(5,2);
circumference number(7, 2);
area number (10, 2);
BEGIN
-- processing
radius := 9.5;
dia := radius * 2;
circumference := 2.0 * pi * radius;
area := pi * radius * radius;
-- output
dbms_output.put_line('Radius: ' || radius);
dbms_output.put_line('Diameter: ' || dia);
dbms_output.put_line('Circumference: ' || circumference);
dbms_output.put_line('Area: ' || area);
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Radius: 9.5 Diameter: 19 Circumference: 59.69 Area: 283.53 Pl/SQL procedure successfully completed.
PL/SQL字面量
字面量是顯式的數字、字元、字串或布林值,不以識別符號表示。例如,TRUE、786、NULL、'tutorialspoint'都是布林型、數字型或字串型的字面量。PL/SQL字面量區分大小寫。PL/SQL支援以下型別的字面量:
- 數字字面量
- 字元字面量
- 字串字面量
- 布林字面量
- 日期和時間字面量
下表提供了所有這些類別字面值的示例。
| 序號 | 字面量型別 & 示例 |
|---|---|
| 1 | 數字字面量 050 78 -14 0 +32767 6.6667 0.0 -12.0 3.14159 +7800.00 6E5 1.0E-8 3.14159e0 -1E38 -9.5e-3 |
| 2 | 字元字面量 'A' '%' '9' ' ' 'z' '(' |
| 3 | 字串字面量 'Hello, world!' 'Tutorials Point' '19-NOV-12' |
| 4 | 布林字面量 TRUE、FALSE和NULL。 |
| 5 | 日期和時間字面量 DATE '1978-12-25'; TIMESTAMP '2012-10-29 12:01:01'; |
要在字串字面量中嵌入單引號,請將兩個單引號並排放置,如下程式所示:
DECLARE message varchar2(30):= 'That''s tutorialspoint.com!'; BEGIN dbms_output.put_line(message); END; /
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
That's tutorialspoint.com! PL/SQL procedure successfully completed.
PL/SQL - 運算子
本章將討論PL/SQL中的運算子。運算子是一個符號,它告訴編譯器執行特定的數學或邏輯操作。PL/SQL語言富含內建運算子,並提供以下型別的運算子:
- 算術運算子
- 關係運算符
- 比較運算子
- 邏輯運算子
- 字串運算子
在這裡,我們將逐一瞭解算術、關係、比較和邏輯運算子。字串運算子將在後面的章節中討論:PL/SQL - 字串。
算術運算子
下表顯示了PL/SQL支援的所有算術運算子。假設變數A值為10,變數B值為5,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| + | 將兩個運算元相加 | A + B 將得到 15 |
| - | 從第一個運算元中減去第二個運算元 | A - B 將得到 5 |
| * | 將兩個運算元相乘 | A * B 將得到 50 |
| / | 將分子除以分母 | A / B 將得到 2 |
| ** | 指數運算子,將一個運算元提高到另一個運算元的冪 | A ** B 將得到 100000 |
關係運算符
關係運算符比較兩個表示式或值,並返回布林結果。下表顯示了PL/SQL支援的所有關係運算符。假設變數A值為10,變數B值為20,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| = | 檢查兩個運算元的值是否相等,如果相等則條件為真。 | (A = B) 為假。 |
!= <> ~= |
檢查兩個運算元的值是否不相等,如果不相等則條件為真。 | (A != B) 為真。 |
| > | 檢查左邊運算元的值是否大於右邊運算元的值,如果是則條件為真。 | (A > B) 為假。 |
| < | 檢查左邊運算元的值是否小於右邊運算元的值,如果是則條件為真。 | (A < B) 為真。 |
| >= | 檢查左邊運算元的值是否大於或等於右邊運算元的值,如果是則條件為真。 | (A >= B) 為假。 |
| <= | 檢查左邊運算元的值是否小於或等於右邊運算元的值,如果是則條件為真。 | (A <= B) 為真 |
比較運算子
比較運算子用於比較一個表示式與另一個表示式。結果始終為TRUE、FALSE或NULL。
| 運算子 | 描述 | 示例 |
|---|---|---|
| LIKE | LIKE運算子將字元、字串或CLOB值與模式進行比較,如果值與模式匹配則返回TRUE,如果不匹配則返回FALSE。 | 如果 'Zara Ali' like 'Z% A_i' 返回布林值true,而 'Nuha Ali' like 'Z% A_i' 返回布林值false。 |
| BETWEEN | BETWEEN運算子測試值是否在指定範圍內。x BETWEEN a AND b表示x >= a且x <= b。 | 如果x = 10,則x between 5 and 20返回true,x between 5 and 10返回true,但x between 11 and 20返回false。 |
| IN | IN運算子測試集合成員資格。x IN (set)表示x等於集合的任何成員。 | 如果x = 'm',則x in ('a', 'b', 'c')返回布林值false,但x in ('m', 'n', 'o')返回布林值true。 |
| IS NULL | IS NULL運算子如果其運算元為NULL則返回布林值TRUE,如果不為NULL則返回FALSE。涉及NULL值的比較始終產生NULL。 | 如果x = 'm',則'x is null'返回布林值false。 |
邏輯運算子
下表顯示了PL/SQL支援的邏輯運算子。所有這些運算子都作用於布林運算元併產生布爾結果。假設變數A值為true,變數B值為false,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| and | 稱為邏輯AND運算子。如果兩個運算元都為真,則條件為真。 | (A and B) 為假。 |
| or | 稱為邏輯OR運算子。如果兩個運算元中的任何一個為真,則條件為真。 | (A or B) 為真。 |
| not | 稱為邏輯NOT運算子。用於反轉其運算元的邏輯狀態。如果條件為真,則邏輯NOT運算子將使其為假。 | not (A and B) 為真。 |
PL/SQL運算子優先順序
運算子優先順序決定了表示式中項的分組。這會影響表示式的計算方式。某些運算子的優先順序高於其他運算子;例如,乘法運算子的優先順序高於加法運算子。
例如,x = 7 + 3 * 2;這裡,x被賦值為13,而不是20,因為運算子*的優先順序高於+,所以它先與3*2相乘,然後加到7中。
這裡,優先順序最高的運算子出現在表的最上面,優先順序最低的出現在表的最下面。在一個表示式中,優先順序較高的運算子將首先被計算。
運算子的優先順序如下:=,<,>,<=,>=,<>,!=,~=,^=,IS NULL,LIKE,BETWEEN,IN。
| 運算子 | 操作 |
|---|---|
| ** | 指數 |
| +, - | 恆等式,否定 |
| *, / | 乘法,除法 |
| +, -, || | 加法,減法,連線 |
| 比較 | |
| NOT | 邏輯否定 |
| AND | 連線 |
| OR | 包含 |
PL/SQL - 條件語句
本章將討論PL/SQL中的條件。決策結構要求程式設計師指定一個或多個要由程式評估或測試的條件,以及如果確定條件為真則要執行的語句或語句,以及可選地,如果確定條件為假則要執行的其他語句。
以下是大多數程式語言中常見的條件(即決策)結構的一般形式:
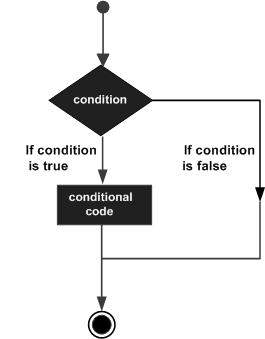
PL/SQL程式語言提供以下型別的決策語句。點選下面的連結檢視它們的詳細資訊。
| 序號 | 語句 & 描述 |
|---|---|
| 1 | IF - THEN語句
IF語句將一個條件與由關鍵字THEN和END IF括起來的語句序列關聯起來。如果條件為真,則語句被執行;如果條件為假或NULL,則IF語句什麼也不做。 |
| 2 | IF-THEN-ELSE語句
IF語句新增關鍵字ELSE,後跟一個備選語句序列。如果條件為假或NULL,則只執行備選語句序列。它確保執行語句序列中的一個。 |
| 3 | IF-THEN-ELSIF語句
它允許您在多個備選方案之間進行選擇。 |
| 4 | Case語句
與IF語句一樣,CASE語句選擇一個語句序列來執行。 但是,為了選擇序列,CASE語句使用選擇器而不是多個布林表示式。選擇器是一個表示式,其值用於選擇多個備選方案中的一個。 |
| 5 | Searched CASE語句
Searched CASE語句沒有選擇器,其WHEN子句包含產生布爾值的搜尋條件。 |
| 6 | 巢狀IF-THEN-ELSE
您可以將一個IF-THEN或IF-THEN-ELSIF語句放在另一個IF-THEN或IF-THEN-ELSIF語句內。 |
PL/SQL - 迴圈語句
本章將討論PL/SQL中的迴圈。可能會有這樣的情況,您需要多次執行一段程式碼。一般來說,語句是順序執行的:函式中的第一個語句首先執行,然後是第二個語句,依此類推。
程式語言提供各種控制結構,允許更復雜的執行路徑。
迴圈語句允許我們多次執行一個語句或一組語句,以下是大多數程式語言中迴圈語句的一般形式:
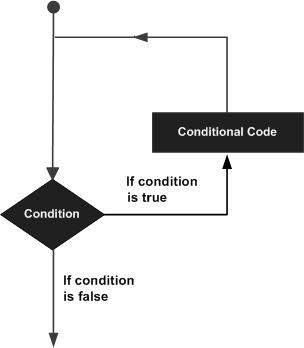
PL/SQL 提供以下幾種迴圈型別來處理迴圈需求。點選以下連結檢視詳情。
| 序號 | 迴圈型別和描述 |
|---|---|
| 1 | PL/SQL 基本 LOOP 迴圈
在這種迴圈結構中,語句序列包含在 LOOP 和 END LOOP 語句之間。每次迭代,都會執行語句序列,然後控制返回到迴圈的頂部。 |
| 2 | PL/SQL WHILE 迴圈
當給定條件為真時,重複執行一條語句或一組語句。它在執行迴圈體之前測試條件。 |
| 3 | PL/SQL FOR 迴圈
多次執行一系列語句,並簡化管理迴圈變數的程式碼。 |
| 4 | PL/SQL 中的巢狀迴圈
可以在任何其他基本迴圈、while 迴圈或 for 迴圈內使用一個或多個迴圈。 |
PL/SQL 迴圈的標註
PL/SQL 迴圈可以加標籤。標籤應包含在雙尖括號(<< 和 >>)中,並出現在 LOOP 語句的開頭。標籤名稱也可以出現在 LOOP 語句的結尾。可以在 EXIT 語句中使用標籤來退出迴圈。
下面的程式演示了這個概念:
DECLARE
i number(1);
j number(1);
BEGIN
<< outer_loop >>
FOR i IN 1..3 LOOP
<< inner_loop >>
FOR j IN 1..3 LOOP
dbms_output.put_line('i is: '|| i || ' and j is: ' || j);
END loop inner_loop;
END loop outer_loop;
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
i is: 1 and j is: 1 i is: 1 and j is: 2 i is: 1 and j is: 3 i is: 2 and j is: 1 i is: 2 and j is: 2 i is: 2 and j is: 3 i is: 3 and j is: 1 i is: 3 and j is: 2 i is: 3 and j is: 3 PL/SQL procedure successfully completed.
迴圈控制語句
迴圈控制語句改變執行的正常順序。當執行離開作用域時,在該作用域中建立的所有自動物件都會被銷燬。
PL/SQL 支援以下控制語句。為迴圈新增標籤也有助於控制退出迴圈。點選以下連結檢視詳情。
| 序號 | 控制語句和描述 |
|---|---|
| 1 | EXIT 語句
EXIT 語句完成迴圈,控制轉移到 END LOOP 後面的語句。 |
| 2 | CONTINUE 語句
使迴圈跳過其主體其餘部分,並在立即重新測試其條件之前重新迭代。 |
| 3 | GOTO 語句
將控制轉移到帶標籤的語句。雖然不建議在程式中使用 GOTO 語句。 |
PL/SQL - 字串
PL/SQL 中的字串實際上是一系列字元,帶有一個可選的長度規範。字元可以是數字、字母、空格、特殊字元或所有字元的組合。PL/SQL 提供三種類型的字串:
定長字串 - 在此類字串中,程式設計師在宣告字串時指定長度。字串用空格向右填充到指定的長度。
變長字串 - 在此類字串中,指定字串的最大長度(最多 32,767),並且不進行填充。
字元大物件 (CLOB) - 這些是變長字串,最大可達 128 TB。
PL/SQL 字串可以是變數或字面量。字串字面量用引號括起來。例如:
'This is a string literal.' Or 'hello world'
要在字串字面量中包含單引號,需要鍵入兩個相鄰的單引號。例如:
'this isn''t what it looks like'
宣告字串變數
Oracle 資料庫提供了許多字串資料型別,例如 CHAR、NCHAR、VARCHAR2、NVARCHAR2、CLOB 和 NCLOB。以'N'為字首的資料型別是'國家字元集'資料型別,用於儲存 Unicode 字元資料。
如果需要宣告變長字串,必須提供該字串的最大長度。例如,VARCHAR2 資料型別。下面的示例演示了宣告和使用一些字串變數:
DECLARE
name varchar2(20);
company varchar2(30);
introduction clob;
choice char(1);
BEGIN
name := 'John Smith';
company := 'Infotech';
introduction := ' Hello! I''m John Smith from Infotech.';
choice := 'y';
IF choice = 'y' THEN
dbms_output.put_line(name);
dbms_output.put_line(company);
dbms_output.put_line(introduction);
END IF;
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
John Smith Infotech Hello! I'm John Smith from Infotech. PL/SQL procedure successfully completed
要宣告定長字串,請使用 CHAR 資料型別。這裡不需要為定長變數指定最大長度。如果省略長度約束,Oracle 資料庫會自動使用所需的最大長度。以下兩個宣告是相同的:
red_flag CHAR(1) := 'Y'; red_flag CHAR := 'Y';
PL/SQL 字串函式和運算子
PL/SQL 提供連線運算子(||)用於連線兩個字串。下表提供了 PL/SQL 提供的字串函式:
| 序號 | 函式和用途 |
|---|---|
| 1 | ASCII(x); 返回字元 x 的 ASCII 值。 |
| 2 | CHR(x); 返回 ASCII 值為 x 的字元。 |
| 3 | CONCAT(x, y); 連線字串 x 和 y 並返回追加的字串。 |
| 4 | INITCAP(x); 將 x 中每個單詞的首字母轉換為大寫並返回該字串。 |
| 5 | INSTR(x, find_string [, start] [, occurrence]); 在 x 中搜索find_string 並返回其出現的位置。 |
| 6 | INSTRB(x); 返回一個字串在另一個字串中的位置,但以位元組為單位返回該值。 |
| 7 | LENGTH(x); 返回 x 中的字元數。 |
| 8 | LENGTHB(x); 對於單位元組字元集,返回字元字串的長度(以位元組為單位)。 |
| 9 | LOWER(x); 將 x 中的字母轉換為小寫並返回該字串。 |
| 10 | LPAD(x, width [, pad_string]) ; 在x的左側用空格填充,使字串的總長度達到 width 個字元。 |
| 11 | LTRIM(x [, trim_string]); 從x的左側修剪字元。 |
| 12 | NANVL(x, value); 如果 x 與 NaN 特殊值(非數字)匹配,則返回 value;否則返回x。 |
| 13 | NLS_INITCAP(x); 與 INITCAP 函式相同,但它可以使用 NLSSORT 指定的不同排序方法。 |
| 14 | NLS_LOWER(x) ; 與 LOWER 函式相同,但它可以使用 NLSSORT 指定的不同排序方法。 |
| 15 | NLS_UPPER(x); 與 UPPER 函式相同,但它可以使用 NLSSORT 指定的不同排序方法。 |
| 16 | NLSSORT(x); 更改字元的排序方法。必須在任何 NLS 函式之前指定;否則,將使用預設排序。 |
| 17 | NVL(x, value); 如果x為 null,則返回 value;否則返回 x。 |
| 18 | NVL2(x, value1, value2); 如果 x 不為 null,則返回 value1;如果 x 為 null,則返回 value2。 |
| 19 | REPLACE(x, search_string, replace_string); 在x中搜索 search_string 並將其替換為 replace_string。 |
| 20 | RPAD(x, width [, pad_string]); 在x的右側填充。 |
| 21 | RTRIM(x [, trim_string]); 從x的右側修剪。 |
| 22 | SOUNDEX(x) ; 返回包含x的語音表示的字串。 |
| 23 | SUBSTR(x, start [, length]); 返回x的子字串,該子字串從 start 指定的位置開始。可以提供子字串的可選長度。 |
| 24 | SUBSTRB(x); 與 SUBSTR 相同,只是對於單位元組字元系統,引數以位元組而不是字元表示。 |
| 25 | TRIM([trim_char FROM) x); 從x的左側和右側修剪字元。 |
| 26 | UPPER(x); 將 x 中的字母轉換為大寫並返回該字串。 |
現在讓我們透過一些示例來理解這個概念:
示例 1
DECLARE
greetings varchar2(11) := 'hello world';
BEGIN
dbms_output.put_line(UPPER(greetings));
dbms_output.put_line(LOWER(greetings));
dbms_output.put_line(INITCAP(greetings));
/* retrieve the first character in the string */
dbms_output.put_line ( SUBSTR (greetings, 1, 1));
/* retrieve the last character in the string */
dbms_output.put_line ( SUBSTR (greetings, -1, 1));
/* retrieve five characters,
starting from the seventh position. */
dbms_output.put_line ( SUBSTR (greetings, 7, 5));
/* retrieve the remainder of the string,
starting from the second position. */
dbms_output.put_line ( SUBSTR (greetings, 2));
/* find the location of the first "e" */
dbms_output.put_line ( INSTR (greetings, 'e'));
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
HELLO WORLD hello world Hello World h d World ello World 2 PL/SQL procedure successfully completed.
示例 2
DECLARE greetings varchar2(30) := '......Hello World.....'; BEGIN dbms_output.put_line(RTRIM(greetings,'.')); dbms_output.put_line(LTRIM(greetings, '.')); dbms_output.put_line(TRIM( '.' from greetings)); END; /
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
......Hello World Hello World..... Hello World PL/SQL procedure successfully completed.
PL/SQL - 陣列
在本章中,我們將討論 PL/SQL 中的陣列。PL/SQL 程式語言提供了一種稱為VARRAY的資料結構,它可以儲存相同型別元素的固定大小的順序集合。可以使用 varray 儲存有序的資料集合,但是通常最好將陣列視為相同型別變數的集合。
所有 varray 都由連續的記憶體位置組成。最低地址對應於第一個元素,最高地址對應於最後一個元素。

陣列是集合型別資料的一部分,它代表可變大小的陣列。我們將在後面的章節'PL/SQL 集合'中學習其他集合型別。
varray中的每個元素都與一個索引相關聯。它還有一個可以動態更改的最大大小。
建立 Varray 型別
使用CREATE TYPE語句建立 varray 型別。必須指定 varray 中儲存元素的最大大小和型別。
在模式級別建立 VARRAY 型別的基本語法如下:
CREATE OR REPLACE TYPE varray_type_name IS VARRAY(n) of <element_type>
其中:
- varray_type_name 是有效的屬性名稱,
- n 是 varray 中元素的數量(最大值),
- element_type 是陣列元素的資料型別。
可以使用ALTER TYPE語句更改 varray 的最大大小。
例如:
CREATE Or REPLACE TYPE namearray AS VARRAY(3) OF VARCHAR2(10); / Type created.
在 PL/SQL 塊中建立 VARRAY 型別的基本語法如下:
TYPE varray_type_name IS VARRAY(n) of <element_type>
例如:
TYPE namearray IS VARRAY(5) OF VARCHAR2(10); Type grades IS VARRAY(5) OF INTEGER;
現在讓我們透過一些示例來理解這個概念:
示例 1
下面的程式演示了 varray 的用法:
DECLARE
type namesarray IS VARRAY(5) OF VARCHAR2(10);
type grades IS VARRAY(5) OF INTEGER;
names namesarray;
marks grades;
total integer;
BEGIN
names := namesarray('Kavita', 'Pritam', 'Ayan', 'Rishav', 'Aziz');
marks:= grades(98, 97, 78, 87, 92);
total := names.count;
dbms_output.put_line('Total '|| total || ' Students');
FOR i in 1 .. total LOOP
dbms_output.put_line('Student: ' || names(i) || '
Marks: ' || marks(i));
END LOOP;
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Total 5 Students Student: Kavita Marks: 98 Student: Pritam Marks: 97 Student: Ayan Marks: 78 Student: Rishav Marks: 87 Student: Aziz Marks: 92 PL/SQL procedure successfully completed.
請注意:
在 Oracle 環境中,varrays 的起始索引始終為 1。
可以使用 varray 型別的建構函式方法初始化 varray 元素,該方法與 varray 的名稱相同。
Varrays 是一維陣列。
宣告 varray 時,它自動為 NULL,並且必須在引用其元素之前對其進行初始化。
示例 2
varray 的元素也可以是任何資料庫表的 %ROWTYPE 或任何資料庫表字段的 %TYPE。以下示例說明了這個概念。
我們將使用儲存在我們資料庫中的 CUSTOMERS 表,如下所示:
Select * from customers; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | +----+----------+-----+-----------+----------+
以下示例使用了遊標,您將在單獨的章節中詳細學習。
DECLARE
CURSOR c_customers is
SELECT name FROM customers;
type c_list is varray (6) of customers.name%type;
name_list c_list := c_list();
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter + 1;
name_list.extend;
name_list(counter) := n.name;
dbms_output.put_line('Customer('||counter ||'):'||name_list(counter));
END LOOP;
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Customer(1): Ramesh Customer(2): Khilan Customer(3): kaushik Customer(4): Chaitali Customer(5): Hardik Customer(6): Komal PL/SQL procedure successfully completed.
PL/SQL - 過程
在本章中,我們將討論 PL/SQL 中的過程。子程式是一個執行特定任務的程式單元/模組。這些子程式組合起來形成更大的程式。這基本上稱為“模組化設計”。子程式可以由另一個子程式或程式呼叫,該子程式或程式稱為呼叫程式。
可以建立子程式:
- 在模式級別
- 在包內
- 在 PL/SQL 塊內
在模式級別,子程式是獨立子程式。它使用 CREATE PROCEDURE 或 CREATE FUNCTION 語句建立。它儲存在資料庫中,可以使用 DROP PROCEDURE 或 DROP FUNCTION 語句刪除。
在包內建立的子程式是打包子程式。它儲存在資料庫中,只有在使用 DROP PACKAGE 語句刪除包時才能刪除。我們將在章節'PL/SQL - 包'中討論包。
PL/SQL 子程式是命名的 PL/SQL 塊,可以使用一組引數呼叫。PL/SQL 提供兩種子程式:
函式 - 這些子程式返回單個值;主要用於計算和返回值。
過程 - 這些子程式不直接返回值;主要用於執行操作。
本章將介紹PL/SQL 過程的重要方面。我們將在下一章討論PL/SQL 函式。
PL/SQL 子程式的組成部分
每個 PL/SQL 子程式都有一個名稱,並且可能還有一個引數列表。與匿名 PL/SQL 塊一樣,命名塊也包含以下三個部分:
| 序號 | 部分和描述 |
|---|---|
| 1 | 宣告部分 這是一個可選部分。但是,子程式的宣告部分不是以 DECLARE 關鍵字開頭。它包含型別、遊標、常量、變數、異常和巢狀子程式的宣告。這些專案對子程式是區域性的,並且在子程式完成執行時將不復存在。 |
| 2 | 可執行部分 這是必須的部分,包含執行指定操作的語句。 |
| 3 | 異常處理 這又是一個可選部分。它包含處理執行時錯誤的程式碼。 |
建立過程
使用CREATE OR REPLACE PROCEDURE語句建立過程。CREATE OR REPLACE PROCEDURE 語句的簡化語法如下:
CREATE [OR REPLACE] PROCEDURE procedure_name
[(parameter_name [IN | OUT | IN OUT] type [, ...])]
{IS | AS}
BEGIN
< procedure_body >
END procedure_name;
其中:
過程名指定過程的名稱。
[OR REPLACE] 選項允許修改現有過程。
可選引數列表包含引數的名稱、模式和型別。IN 代表從外部傳入的值,OUT 代表用於將值返回到過程外部的引數。
過程體包含可執行部分。
對於建立獨立過程,使用 AS 關鍵字代替 IS 關鍵字。
示例
以下示例建立一個簡單的過程,在執行時在螢幕上顯示字串“Hello World!”。
CREATE OR REPLACE PROCEDURE greetings
AS
BEGIN
dbms_output.put_line('Hello World!');
END;
/
使用 SQL 提示符執行上述程式碼時,將產生以下結果:
Procedure created.
執行獨立過程
可以兩種方式呼叫獨立過程:
使用EXECUTE關鍵字
從 PL/SQL 塊呼叫過程名稱
上述名為'greetings'的過程可以用 EXECUTE 關鍵字呼叫,如下所示:
EXECUTE greetings;
上述呼叫將顯示:
Hello World PL/SQL procedure successfully completed.
也可以從另一個 PL/SQL 塊呼叫該過程:
BEGIN greetings; END; /
上述呼叫將顯示:
Hello World PL/SQL procedure successfully completed.
刪除獨立過程
使用DROP PROCEDURE語句刪除獨立過程。刪除過程的語法如下:
DROP PROCEDURE procedure-name;
可以使用以下語句刪除 greetings 過程:
DROP PROCEDURE greetings;
PL/SQL 子程式中的引數模式
下表列出了 PL/SQL 子程式中的引數模式:
| 序號 | 引數模式 & 說明 |
|---|---|
| 1 | IN IN 引數允許您向子程式傳遞值。它是一個只讀引數。在子程式內部,IN 引數的作用類似於常量。不能為其賦值。您可以將常量、文字、已初始化的變數或表示式作為 IN 引數傳遞。您還可以將其初始化為預設值;但是,在這種情況下,它將從子程式呼叫中省略。它是引數傳遞的預設模式。引數透過引用傳遞。 |
| 2 | OUT OUT 引數將值返回給呼叫程式。在子程式內部,OUT 引數的作用類似於變數。您可以更改其值並在賦值後引用該值。實際引數必須是變數,並且是按值傳遞的。 |
| 3 | IN OUT IN OUT 引數將初始值傳遞給子程式,並將更新後的值返回給呼叫者。可以為其賦值,也可以讀取其值。 與 IN OUT 形式引數對應的實際引數必須是變數,而不是常量或表示式。形式引數必須賦值。實際引數按值傳遞。 |
IN & OUT 模式示例 1
此程式查詢兩個值的最小值。在這裡,過程使用 IN 模式獲取兩個數字,並使用 OUT 引數返回它們的最小值。
DECLARE
a number;
b number;
c number;
PROCEDURE findMin(x IN number, y IN number, z OUT number) IS
BEGIN
IF x < y THEN
z:= x;
ELSE
z:= y;
END IF;
END;
BEGIN
a:= 23;
b:= 45;
findMin(a, b, c);
dbms_output.put_line(' Minimum of (23, 45) : ' || c);
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Minimum of (23, 45) : 23 PL/SQL procedure successfully completed.
IN & OUT 模式示例 2
此過程計算傳遞值的平方。此示例顯示如何使用相同的引數來接受一個值,然後返回另一個結果。
DECLARE
a number;
PROCEDURE squareNum(x IN OUT number) IS
BEGIN
x := x * x;
END;
BEGIN
a:= 23;
squareNum(a);
dbms_output.put_line(' Square of (23): ' || a);
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Square of (23): 529 PL/SQL procedure successfully completed.
傳遞引數的方法
實際引數可以透過三種方式傳遞:
- 位置表示法
- 命名錶示法
- 混合表示法
位置表示法
在位置表示法中,您可以按如下方式呼叫過程:
findMin(a, b, c, d);
在位置表示法中,第一個實際引數將替換第一個形式引數;第二個實際引數將替換第二個形式引數,依此類推。因此,a 將替換 x,b 將替換 y,c 將替換 z,d 將替換 m。
命名錶示法
在命名錶示法中,使用箭頭符號 (=>)將實際引數與形式引數關聯。過程呼叫將如下所示:
findMin(x => a, y => b, z => c, m => d);
混合表示法
在混合表示法中,您可以在過程呼叫中混合兩種表示法;但是,位置表示法應該在命名錶示法之前。
以下呼叫是合法的:
findMin(a, b, c, m => d);
但是,這是非法的
findMin(x => a, b, c, d);
PL/SQL - 函式
在本章中,我們將討論 PL/SQL 中的函式。函式與過程相同,只是它返回一個值。因此,前一章的所有討論也適用於函式。
建立函式
使用CREATE FUNCTION語句建立獨立函式。CREATE OR REPLACE PROCEDURE語句的簡化語法如下:
CREATE [OR REPLACE] FUNCTION function_name
[(parameter_name [IN | OUT | IN OUT] type [, ...])]
RETURN return_datatype
{IS | AS}
BEGIN
< function_body >
END [function_name];
其中:
函式名指定函式的名稱。
[OR REPLACE] 選項允許修改現有函式。
可選引數列表包含引數的名稱、模式和型別。IN 代表從外部傳入的值,OUT 代表用於將值返回到過程外部的引數。
函式必須包含return語句。
RETURN子句指定您將從函式返回的資料型別。
函式體包含可執行部分。
對於建立獨立函式,使用 AS 關鍵字代替 IS 關鍵字。
示例
以下示例說明如何建立和呼叫獨立函式。此函式返回 customers 表中 CUSTOMERS 的總數。
我們將使用 CUSTOMERS 表,我們在PL/SQL 變數章節中建立並使用了該表:
Select * from customers; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | +----+----------+-----+-----------+----------+
CREATE OR REPLACE FUNCTION totalCustomers
RETURN number IS
total number(2) := 0;
BEGIN
SELECT count(*) into total
FROM customers;
RETURN total;
END;
/
使用 SQL 提示符執行上述程式碼時,將產生以下結果:
Function created.
呼叫函式
在建立函式時,您會給出函式必須執行的操作的定義。要使用函式,您必須呼叫該函式以執行定義的任務。當程式呼叫函式時,程式控制將轉移到被呼叫的函式。
被呼叫的函式執行定義的任務,當執行其 return 語句或到達最後一個 end 語句時,它將程式控制返回到主程式。
要呼叫函式,您只需將所需的引數與函式名稱一起傳遞,如果函式返回值,則可以儲存返回值。以下程式從匿名塊呼叫函式totalCustomers:
DECLARE
c number(2);
BEGIN
c := totalCustomers();
dbms_output.put_line('Total no. of Customers: ' || c);
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Total no. of Customers: 6 PL/SQL procedure successfully completed.
示例
以下示例演示宣告、定義和呼叫一個簡單的 PL/SQL 函式,該函式計算並返回兩個值的較大值。
DECLARE
a number;
b number;
c number;
FUNCTION findMax(x IN number, y IN number)
RETURN number
IS
z number;
BEGIN
IF x > y THEN
z:= x;
ELSE
Z:= y;
END IF;
RETURN z;
END;
BEGIN
a:= 23;
b:= 45;
c := findMax(a, b);
dbms_output.put_line(' Maximum of (23,45): ' || c);
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Maximum of (23,45): 45 PL/SQL procedure successfully completed.
PL/SQL 遞迴函式
我們已經看到,程式或子程式可以呼叫另一個子程式。當子程式呼叫自身時,稱為遞迴呼叫,該過程稱為遞迴。
為了說明這個概念,讓我們計算一個數字的階乘。數字 n 的階乘定義為:
n! = n*(n-1)!
= n*(n-1)*(n-2)!
...
= n*(n-1)*(n-2)*(n-3)... 1
以下程式透過遞迴呼叫自身來計算給定數字的階乘:
DECLARE
num number;
factorial number;
FUNCTION fact(x number)
RETURN number
IS
f number;
BEGIN
IF x=0 THEN
f := 1;
ELSE
f := x * fact(x-1);
END IF;
RETURN f;
END;
BEGIN
num:= 6;
factorial := fact(num);
dbms_output.put_line(' Factorial '|| num || ' is ' || factorial);
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Factorial 6 is 720 PL/SQL procedure successfully completed.
PL/SQL - 遊標
在本章中,我們將討論 PL/SQL 中的遊標。Oracle 建立一個稱為上下文區域的記憶體區域用於處理 SQL 語句,其中包含處理語句所需的所有資訊;例如,處理的行數等。
遊標是指向此上下文區域的指標。PL/SQL 透過遊標控制上下文區域。遊標包含 SQL 語句返回的行(一行或多行)。遊標儲存的行集稱為活動集。
您可以命名遊標,以便可以在程式中引用它來逐一提取和處理 SQL 語句返回的行。有兩種型別的遊標:
- 隱式遊標
- 顯式遊標
隱式遊標
每當執行 SQL 語句時,如果沒有語句的顯式遊標,Oracle 就會自動建立隱式遊標。程式設計師無法控制隱式遊標及其中的資訊。
每當發出 DML 語句(INSERT、UPDATE 和 DELETE)時,都會將隱式遊標與該語句關聯。對於 INSERT 操作,遊標包含需要插入的資料。對於 UPDATE 和 DELETE 操作,遊標標識將受影響的行。
在 PL/SQL 中,您可以將最新的隱式遊標稱為SQL 遊標,它始終具有屬性,例如%FOUND、%ISOPEN、%NOTFOUND和%ROWCOUNT。SQL 遊標具有附加屬性%BULK_ROWCOUNT和%BULK_EXCEPTIONS,專為與FORALL語句一起使用而設計。下表提供了最常用屬性的描述:
| 序號 | 屬性 & 說明 |
|---|---|
| 1 | %FOUND 如果 INSERT、UPDATE 或 DELETE 語句影響了一行或多行,或者 SELECT INTO 語句返回了一行或多行,則返回 TRUE。否則,返回 FALSE。 |
| 2 | %NOTFOUND %FOUND 的邏輯反義詞。如果 INSERT、UPDATE 或 DELETE 語句沒有影響任何行,或者 SELECT INTO 語句沒有返回任何行,則返回 TRUE。否則,返回 FALSE。 |
| 3 | %ISOPEN 對於隱式遊標始終返回 FALSE,因為 Oracle 在執行其關聯的 SQL 語句後會自動關閉 SQL 遊標。 |
| 4 | %ROWCOUNT 返回 INSERT、UPDATE 或 DELETE 語句影響的行數,或者 SELECT INTO 語句返回的行數。 |
任何 SQL 遊標屬性都將作為sql%attribute_name訪問,如下例所示。
示例
我們將使用我們在前幾章中建立和使用的 CUSTOMERS 表。
Select * from customers; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | +----+----------+-----+-----------+----------+
以下程式將更新表並將每個客戶的工資增加 500,並使用SQL%ROWCOUNT屬性確定受影響的行數:
DECLARE
total_rows number(2);
BEGIN
UPDATE customers
SET salary = salary + 500;
IF sql%notfound THEN
dbms_output.put_line('no customers selected');
ELSIF sql%found THEN
total_rows := sql%rowcount;
dbms_output.put_line( total_rows || ' customers selected ');
END IF;
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
6 customers selected PL/SQL procedure successfully completed.
如果您檢查 customers 表中的記錄,您會發現行已被更新:
Select * from customers; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2500.00 | | 2 | Khilan | 25 | Delhi | 2000.00 | | 3 | kaushik | 23 | Kota | 2500.00 | | 4 | Chaitali | 25 | Mumbai | 7000.00 | | 5 | Hardik | 27 | Bhopal | 9000.00 | | 6 | Komal | 22 | MP | 5000.00 | +----+----------+-----+-----------+----------+
顯式遊標
顯式遊標是程式設計師定義的遊標,用於更好地控制上下文區域。顯式遊標應在 PL/SQL 塊的宣告部分定義。它是在返回多行的 SELECT 語句上建立的。
建立顯式遊標的語法為:
CURSOR cursor_name IS select_statement;
使用顯式遊標包括以下步驟:
- 宣告遊標以初始化記憶體
- 開啟遊標以分配記憶體
- 提取遊標以檢索資料
- 關閉遊標以釋放已分配的記憶體
宣告遊標
宣告遊標使用名稱和關聯的 SELECT 語句定義遊標。例如:
CURSOR c_customers IS SELECT id, name, address FROM customers;
開啟遊標
開啟遊標會為遊標分配記憶體,並使其準備好將 SQL 語句返回的行提取到其中。例如,我們將開啟上述定義的遊標,如下所示:
OPEN c_customers;
提取遊標
提取遊標涉及一次訪問一行。例如,我們將從上述開啟的遊標中提取行,如下所示:
FETCH c_customers INTO c_id, c_name, c_addr;
關閉遊標
關閉遊標意味著釋放已分配的記憶體。例如,我們將關閉上述開啟的遊標,如下所示:
CLOSE c_customers;
示例
下面是一個完整的例子,用於說明顯式遊標的概念。
DECLARE
c_id customers.id%type;
c_name customer.name%type;
c_addr customers.address%type;
CURSOR c_customers is
SELECT id, name, address FROM customers;
BEGIN
OPEN c_customers;
LOOP
FETCH c_customers into c_id, c_name, c_addr;
EXIT WHEN c_customers%notfound;
dbms_output.put_line(c_id || ' ' || c_name || ' ' || c_addr);
END LOOP;
CLOSE c_customers;
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
1 Ramesh Ahmedabad 2 Khilan Delhi 3 kaushik Kota 4 Chaitali Mumbai 5 Hardik Bhopal 6 Komal MP PL/SQL procedure successfully completed.
PL/SQL - 記錄
在本章中,我們將討論PL/SQL中的記錄。一個記錄是一個數據結構,可以儲存不同型別的資料項。記錄由不同的欄位組成,類似於資料庫表的一行。
例如,你想跟蹤圖書館裡的書籍。你可能想跟蹤每本書的以下屬性,例如標題、作者、主題、圖書ID。一個包含每個專案欄位的記錄允許將BOOK視為一個邏輯單元,並允許你更好地組織和表示其資訊。
PL/SQL可以處理以下型別的記錄:
- 基於表的記錄
- 基於遊標的記錄
- 使用者定義的記錄
基於表的記錄
%ROWTYPE屬性使程式設計師能夠建立基於表和基於遊標的記錄。
下面的例子說明了基於表記錄的概念。我們將使用我們在前面章節中建立和使用的CUSTOMERS表:
DECLARE
customer_rec customers%rowtype;
BEGIN
SELECT * into customer_rec
FROM customers
WHERE id = 5;
dbms_output.put_line('Customer ID: ' || customer_rec.id);
dbms_output.put_line('Customer Name: ' || customer_rec.name);
dbms_output.put_line('Customer Address: ' || customer_rec.address);
dbms_output.put_line('Customer Salary: ' || customer_rec.salary);
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Customer ID: 5 Customer Name: Hardik Customer Address: Bhopal Customer Salary: 9000 PL/SQL procedure successfully completed.
基於遊標的記錄
下面的例子說明了基於遊標記錄的概念。我們將使用我們在前面章節中建立和使用的CUSTOMERS表:
DECLARE
CURSOR customer_cur is
SELECT id, name, address
FROM customers;
customer_rec customer_cur%rowtype;
BEGIN
OPEN customer_cur;
LOOP
FETCH customer_cur into customer_rec;
EXIT WHEN customer_cur%notfound;
DBMS_OUTPUT.put_line(customer_rec.id || ' ' || customer_rec.name);
END LOOP;
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
1 Ramesh 2 Khilan 3 kaushik 4 Chaitali 5 Hardik 6 Komal PL/SQL procedure successfully completed.
使用者定義的記錄
PL/SQL提供了一種使用者定義的記錄型別,允許你定義不同的記錄結構。這些記錄由不同的欄位組成。假設你想跟蹤圖書館裡的書籍。你可能想跟蹤每本書的以下屬性:
- 標題
- 作者
- 主題
- 圖書ID
定義記錄
記錄型別定義如下:
TYPE type_name IS RECORD ( field_name1 datatype1 [NOT NULL] [:= DEFAULT EXPRESSION], field_name2 datatype2 [NOT NULL] [:= DEFAULT EXPRESSION], ... field_nameN datatypeN [NOT NULL] [:= DEFAULT EXPRESSION); record-name type_name;
Book記錄的宣告方式如下:
DECLARE TYPE books IS RECORD (title varchar(50), author varchar(50), subject varchar(100), book_id number); book1 books; book2 books;
訪問欄位
要訪問記錄的任何欄位,我們使用點(.)運算子。成員訪問運算子被編碼為記錄變數名和我們想要訪問的欄位之間的句點。以下是一個解釋記錄用法的例子:
DECLARE
type books is record
(title varchar(50),
author varchar(50),
subject varchar(100),
book_id number);
book1 books;
book2 books;
BEGIN
-- Book 1 specification
book1.title := 'C Programming';
book1.author := 'Nuha Ali ';
book1.subject := 'C Programming Tutorial';
book1.book_id := 6495407;
-- Book 2 specification
book2.title := 'Telecom Billing';
book2.author := 'Zara Ali';
book2.subject := 'Telecom Billing Tutorial';
book2.book_id := 6495700;
-- Print book 1 record
dbms_output.put_line('Book 1 title : '|| book1.title);
dbms_output.put_line('Book 1 author : '|| book1.author);
dbms_output.put_line('Book 1 subject : '|| book1.subject);
dbms_output.put_line('Book 1 book_id : ' || book1.book_id);
-- Print book 2 record
dbms_output.put_line('Book 2 title : '|| book2.title);
dbms_output.put_line('Book 2 author : '|| book2.author);
dbms_output.put_line('Book 2 subject : '|| book2.subject);
dbms_output.put_line('Book 2 book_id : '|| book2.book_id);
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Book 1 title : C Programming Book 1 author : Nuha Ali Book 1 subject : C Programming Tutorial Book 1 book_id : 6495407 Book 2 title : Telecom Billing Book 2 author : Zara Ali Book 2 subject : Telecom Billing Tutorial Book 2 book_id : 6495700 PL/SQL procedure successfully completed.
記錄作為子程式引數
你可以像傳遞任何其他變數一樣傳遞記錄作為子程式引數。你也可以像在上面的例子中一樣訪問記錄欄位:
DECLARE
type books is record
(title varchar(50),
author varchar(50),
subject varchar(100),
book_id number);
book1 books;
book2 books;
PROCEDURE printbook (book books) IS
BEGIN
dbms_output.put_line ('Book title : ' || book.title);
dbms_output.put_line('Book author : ' || book.author);
dbms_output.put_line( 'Book subject : ' || book.subject);
dbms_output.put_line( 'Book book_id : ' || book.book_id);
END;
BEGIN
-- Book 1 specification
book1.title := 'C Programming';
book1.author := 'Nuha Ali ';
book1.subject := 'C Programming Tutorial';
book1.book_id := 6495407;
-- Book 2 specification
book2.title := 'Telecom Billing';
book2.author := 'Zara Ali';
book2.subject := 'Telecom Billing Tutorial';
book2.book_id := 6495700;
-- Use procedure to print book info
printbook(book1);
printbook(book2);
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Book title : C Programming Book author : Nuha Ali Book subject : C Programming Tutorial Book book_id : 6495407 Book title : Telecom Billing Book author : Zara Ali Book subject : Telecom Billing Tutorial Book book_id : 6495700 PL/SQL procedure successfully completed.
PL/SQL - 異常處理
在本章中,我們將討論PL/SQL中的異常。異常是在程式執行期間發生的錯誤條件。PL/SQL支援程式設計師使用程式中的EXCEPTION塊捕獲此類條件,並對錯誤條件採取適當的措施。異常有兩種型別:
- 系統定義的異常
- 使用者定義的異常
異常處理語法
異常處理的通用語法如下。在這裡,你可以列出儘可能多的你可以處理的異常。預設異常將使用WHEN others THEN處理:
DECLARE
<declarations section>
BEGIN
<executable command(s)>
EXCEPTION
<exception handling goes here >
WHEN exception1 THEN
exception1-handling-statements
WHEN exception2 THEN
exception2-handling-statements
WHEN exception3 THEN
exception3-handling-statements
........
WHEN others THEN
exception3-handling-statements
END;
示例
讓我們編寫一個程式碼來說明這個概念。我們將使用我們在前面章節中建立和使用的CUSTOMERS表:
DECLARE
c_id customers.id%type := 8;
c_name customerS.Name%type;
c_addr customers.address%type;
BEGIN
SELECT name, address INTO c_name, c_addr
FROM customers
WHERE id = c_id;
DBMS_OUTPUT.PUT_LINE ('Name: '|| c_name);
DBMS_OUTPUT.PUT_LINE ('Address: ' || c_addr);
EXCEPTION
WHEN no_data_found THEN
dbms_output.put_line('No such customer!');
WHEN others THEN
dbms_output.put_line('Error!');
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
No such customer! PL/SQL procedure successfully completed.
上面的程式顯示了ID已知的客戶的姓名和地址。由於我們的資料庫中沒有ID值為8的客戶,程式引發了執行時異常NO_DATA_FOUND,該異常在EXCEPTION塊中被捕獲。
引發異常
每當發生任何內部資料庫錯誤時,異常都會由資料庫伺服器自動引發,但是程式設計師可以使用RAISE命令顯式引發異常。以下是引發異常的簡單語法:
DECLARE
exception_name EXCEPTION;
BEGIN
IF condition THEN
RAISE exception_name;
END IF;
EXCEPTION
WHEN exception_name THEN
statement;
END;
你可以使用上面的語法來引發Oracle標準異常或任何使用者定義的異常。在下一節中,我們將提供一個關於引發使用者定義異常的例子。你可以以類似的方式引發Oracle標準異常。
使用者定義的異常
PL/SQL允許你根據程式的需要定義自己的異常。使用者定義的異常必須宣告,然後使用RAISE語句或過程DBMS_STANDARD.RAISE_APPLICATION_ERROR顯式引發。
宣告異常的語法是:
DECLARE my-exception EXCEPTION;
示例
下面的例子說明了這個概念。該程式請求客戶ID,當用戶輸入無效ID時,將引發異常invalid_id。
DECLARE
c_id customers.id%type := &cc_id;
c_name customerS.Name%type;
c_addr customers.address%type;
-- user defined exception
ex_invalid_id EXCEPTION;
BEGIN
IF c_id <= 0 THEN
RAISE ex_invalid_id;
ELSE
SELECT name, address INTO c_name, c_addr
FROM customers
WHERE id = c_id;
DBMS_OUTPUT.PUT_LINE ('Name: '|| c_name);
DBMS_OUTPUT.PUT_LINE ('Address: ' || c_addr);
END IF;
EXCEPTION
WHEN ex_invalid_id THEN
dbms_output.put_line('ID must be greater than zero!');
WHEN no_data_found THEN
dbms_output.put_line('No such customer!');
WHEN others THEN
dbms_output.put_line('Error!');
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Enter value for cc_id: -6 (let's enter a value -6) old 2: c_id customers.id%type := &cc_id; new 2: c_id customers.id%type := -6; ID must be greater than zero! PL/SQL procedure successfully completed.
預定義異常
PL/SQL提供了許多預定義的異常,當程式違反任何資料庫規則時,這些異常就會被執行。例如,當SELECT INTO語句不返回任何行時,將引發預定義異常NO_DATA_FOUND。下表列出了一些重要的預定義異常:
| 異常 | Oracle錯誤 | SQLCODE | 描述 |
|---|---|---|---|
| ACCESS_INTO_NULL | 06530 | -6530 | 當空物件自動賦值時引發。 |
| CASE_NOT_FOUND | 06592 | -6592 | 當CASE語句的WHEN子句中沒有選擇任何選項,並且沒有ELSE子句時引發。 |
| COLLECTION_IS_NULL | 06531 | -6531 | 當程式嘗試對未初始化的巢狀表或varray應用EXISTS以外的集合方法,或者程式嘗試為未初始化的巢狀表或varray的元素賦值時引發。 |
| DUP_VAL_ON_INDEX | 00001 | -1 | 當嘗試將重複值儲存到具有唯一索引的列中時引發。 |
| INVALID_CURSOR | 01001 | -1001 | 當嘗試進行不允許的遊標操作時引發,例如關閉未開啟的遊標。 |
| INVALID_NUMBER | 01722 | -1722 | 當字元字串轉換為數字失敗時引發,因為該字串不代表有效的數字。 |
| LOGIN_DENIED | 01017 | -1017 | 當程式嘗試使用無效使用者名稱或密碼登入資料庫時引發。 |
| NO_DATA_FOUND | 01403 | +100 | 當SELECT INTO語句不返回任何行時引發。 |
| NOT_LOGGED_ON | 01012 | -1012 | 當在未連線到資料庫的情況下發出資料庫呼叫時引發。 |
| PROGRAM_ERROR | 06501 | -6501 | 當PL/SQL出現內部問題時引發。 |
| ROWTYPE_MISMATCH | 06504 | -6504 | 當遊標在具有不相容資料型別的變數中獲取值時引發。 |
| SELF_IS_NULL | 30625 | -30625 | 當呼叫成員方法但未初始化物件型別的例項時引發。 |
| STORAGE_ERROR | 06500 | -6500 | 當PL/SQL記憶體不足或記憶體損壞時引發。 |
| TOO_MANY_ROWS | 01422 | -1422 | 當SELECT INTO語句返回多於一行時引發。 |
| VALUE_ERROR | 06502 | -6502 | 當發生算術、轉換、截斷或大小約束錯誤時引發。 |
| ZERO_DIVIDE | 01476 | 1476 | 當嘗試將數字除以零時引發。 |
PL/SQL - 觸發器
在本章中,我們將討論PL/SQL中的觸發器。觸發器是儲存的程式,當發生某些事件時會自動執行或觸發。觸發器實際上是編寫來響應以下任何事件執行的:
資料庫操作(DML)語句(DELETE、INSERT或UPDATE)
資料庫定義(DDL)語句(CREATE、ALTER或DROP)。
資料庫操作(SERVERERROR、LOGON、LOGOFF、STARTUP或SHUTDOWN)。
觸發器可以在表、檢視、模式或與事件關聯的資料庫上定義。
觸發器的優點
觸發器可以用於以下目的:
- 自動生成一些派生列值
- 強制參照完整性
- 事件日誌記錄和儲存表訪問資訊
- 審計
- 表的同步複製
- 實施安全授權
- 防止無效事務
建立觸發器
建立觸發器的語法是:
CREATE [OR REPLACE ] TRIGGER trigger_name
{BEFORE | AFTER | INSTEAD OF }
{INSERT [OR] | UPDATE [OR] | DELETE}
[OF col_name]
ON table_name
[REFERENCING OLD AS o NEW AS n]
[FOR EACH ROW]
WHEN (condition)
DECLARE
Declaration-statements
BEGIN
Executable-statements
EXCEPTION
Exception-handling-statements
END;
其中:
CREATE [OR REPLACE] TRIGGER trigger_name - 建立或替換現有觸發器,觸發器名為 *trigger_name*。
{BEFORE | AFTER | INSTEAD OF} - 指定觸發器何時執行。INSTEAD OF子句用於在檢視上建立觸發器。
{INSERT [OR] | UPDATE [OR] | DELETE} - 指定DML操作。
[OF col_name] - 指定將更新的列名。
[ON table_name] - 指定與觸發器關聯的表名。
[REFERENCING OLD AS o NEW AS n] - 允許你引用各種DML語句(如INSERT、UPDATE和DELETE)的新舊值。
[FOR EACH ROW] - 指定行級觸發器,即觸發器將針對每個受影響的行執行。否則,觸發器只會在執行SQL語句時執行一次,這稱為表級觸發器。
WHEN (condition) - 為觸發器將觸發的行提供條件。此子句僅對行級觸發器有效。
示例
首先,我們將使用我們在前面章節中建立和使用的CUSTOMERS表:
Select * from customers; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | +----+----------+-----+-----------+----------+
以下程式為customers表建立了一個行級觸發器,該觸發器將在對CUSTOMERS表執行INSERT、UPDATE或DELETE操作時觸發。此觸發器將顯示舊值和新值之間的薪資差異:
CREATE OR REPLACE TRIGGER display_salary_changes
BEFORE DELETE OR INSERT OR UPDATE ON customers
FOR EACH ROW
WHEN (NEW.ID > 0)
DECLARE
sal_diff number;
BEGIN
sal_diff := :NEW.salary - :OLD.salary;
dbms_output.put_line('Old salary: ' || :OLD.salary);
dbms_output.put_line('New salary: ' || :NEW.salary);
dbms_output.put_line('Salary difference: ' || sal_diff);
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Trigger created.
這裡需要注意以下幾點:
OLD和NEW引用不適用於表級觸發器,而你可以將它們用於記錄級觸發器。
如果你想在同一個觸發器中查詢表,那麼你應該使用AFTER關鍵字,因為觸發器只有在應用初始更改並且表恢復到一致狀態後才能查詢表或再次更改它。
上面的觸發器是這樣編寫的,它將在表上執行任何DELETE、INSERT或UPDATE操作之前觸發,但是你可以在單個或多個操作上編寫觸發器,例如BEFORE DELETE,它將在每次使用DELETE操作在表上刪除記錄時觸發。
觸發觸發器
讓我們對CUSTOMERS表執行一些DML操作。這是一個INSERT語句,它將在表中建立一個新記錄:
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (7, 'Kriti', 22, 'HP', 7500.00 );
當在CUSTOMERS表中建立記錄時,上面的建立觸發器display_salary_changes將被觸發,並將顯示以下結果:
Old salary: New salary: 7500 Salary difference:
因為這是一個新記錄,所以舊工資不可用,上面的結果為null。現在讓我們對CUSTOMERS表執行另一個DML操作。UPDATE語句將更新表中的現有記錄:
UPDATE customers SET salary = salary + 500 WHERE id = 2;
當在CUSTOMERS表中更新記錄時,上面的建立觸發器display_salary_changes將被觸發,並將顯示以下結果:
Old salary: 1500 New salary: 2000 Salary difference: 500
PL/SQL - 包
在本章中,我們將討論PL/SQL中的包。包是模式物件,它將邏輯相關的PL/SQL型別、變數和子程式分組。
一個包將有兩個必須的部分:
- 包規範
- 包體或定義
包規範
規範是包的介面。它只宣告可以從包外部引用的型別、變數、常量、異常、遊標和子程式。換句話說,它包含關於包內容的所有資訊,但不包括子程式的程式碼。
放在規範中的所有物件都稱為公共物件。不在包規範中但在包體中編碼的任何子程式都稱為私有物件。
以下程式碼片段顯示了一個包含單個過程的包規範。你可以在包中定義許多全域性變數和多個過程或函式。
CREATE PACKAGE cust_sal AS PROCEDURE find_sal(c_id customers.id%type); END cust_sal; /
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Package created.
包體
包體包含包規範中宣告的各種方法的程式碼以及其他私有宣告,這些宣告對包外部的程式碼隱藏。
CREATE PACKAGE BODY語句用於建立包體。以下程式碼片段顯示了上面建立的cust_sal包的包體宣告。我假設我們已經在我們的資料庫中建立了CUSTOMERS表,如PL/SQL - 變數章節所述。
CREATE OR REPLACE PACKAGE BODY cust_sal AS
PROCEDURE find_sal(c_id customers.id%TYPE) IS
c_sal customers.salary%TYPE;
BEGIN
SELECT salary INTO c_sal
FROM customers
WHERE id = c_id;
dbms_output.put_line('Salary: '|| c_sal);
END find_sal;
END cust_sal;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Package body created.
使用包元素
包元素(變數、過程或函式)使用以下語法訪問:
package_name.element_name;
假設我們已經在我們的資料庫模式中建立了上面的包,以下程式使用cust_sal包的find_sal方法:
DECLARE code customers.id%type := &cc_id; BEGIN cust_sal.find_sal(code); END; /
在 SQL 提示符下執行上述程式碼時,系統會提示輸入客戶 ID,輸入 ID 後,將顯示相應的工資,如下所示:
Enter value for cc_id: 1 Salary: 3000 PL/SQL procedure successfully completed.
示例
下面的程式提供了一個更完整的包。我們將使用儲存在資料庫中的 CUSTOMERS 表,其中包含以下記錄:
Select * from customers; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 3000.00 | | 2 | Khilan | 25 | Delhi | 3000.00 | | 3 | kaushik | 23 | Kota | 3000.00 | | 4 | Chaitali | 25 | Mumbai | 7500.00 | | 5 | Hardik | 27 | Bhopal | 9500.00 | | 6 | Komal | 22 | MP | 5500.00 | +----+----------+-----+-----------+----------+
包規範
CREATE OR REPLACE PACKAGE c_package AS -- Adds a customer PROCEDURE addCustomer(c_id customers.id%type, c_name customers.Name%type, c_age customers.age%type, c_addr customers.address%type, c_sal customers.salary%type); -- Removes a customer PROCEDURE delCustomer(c_id customers.id%TYPE); --Lists all customers PROCEDURE listCustomer; END c_package; /
在 SQL 提示符下執行上述程式碼時,它將建立上述包並顯示以下結果:
Package created.
建立包體
CREATE OR REPLACE PACKAGE BODY c_package AS
PROCEDURE addCustomer(c_id customers.id%type,
c_name customers.Name%type,
c_age customers.age%type,
c_addr customers.address%type,
c_sal customers.salary%type)
IS
BEGIN
INSERT INTO customers (id,name,age,address,salary)
VALUES(c_id, c_name, c_age, c_addr, c_sal);
END addCustomer;
PROCEDURE delCustomer(c_id customers.id%type) IS
BEGIN
DELETE FROM customers
WHERE id = c_id;
END delCustomer;
PROCEDURE listCustomer IS
CURSOR c_customers is
SELECT name FROM customers;
TYPE c_list is TABLE OF customers.Name%type;
name_list c_list := c_list();
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter +1;
name_list.extend;
name_list(counter) := n.name;
dbms_output.put_line('Customer(' ||counter|| ')'||name_list(counter));
END LOOP;
END listCustomer;
END c_package;
/
上面的例子使用了**巢狀表**。我們將在下一章討論巢狀表的概念。
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Package body created.
使用包
下面的程式使用在包 *c_package* 中宣告和定義的方法。
DECLARE code customers.id%type:= 8; BEGIN c_package.addcustomer(7, 'Rajnish', 25, 'Chennai', 3500); c_package.addcustomer(8, 'Subham', 32, 'Delhi', 7500); c_package.listcustomer; c_package.delcustomer(code); c_package.listcustomer; END; /
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Customer(1): Ramesh Customer(2): Khilan Customer(3): kaushik Customer(4): Chaitali Customer(5): Hardik Customer(6): Komal Customer(7): Rajnish Customer(8): Subham Customer(1): Ramesh Customer(2): Khilan Customer(3): kaushik Customer(4): Chaitali Customer(5): Hardik Customer(6): Komal Customer(7): Rajnish PL/SQL procedure successfully completed
PL/SQL - 集合
在本章中,我們將討論 PL/SQL 中的集合。集合是具有相同資料型別的一組有序元素。每個元素都由一個唯一的下標標識,該下標表示其在集合中的位置。
PL/SQL 提供三種集合型別:
- 按索引表或關聯陣列
- 巢狀表
- 變長陣列或 Varray
Oracle 文件為每種型別的集合提供了以下特性:
| 集合型別 | 元素數量 | 下標型別 | 密集型或稀疏型 | 建立位置 | 可以是物件型別屬性 |
|---|---|---|---|---|---|
| 關聯陣列(或按索引表) | 無界 | 字串或整數 | 兩者皆可 | 僅在 PL/SQL 塊中 | 否 |
| 巢狀表 | 無界 | 整數 | 初始為密集型,可以變為稀疏型 | 在 PL/SQL 塊中或在模式級別 | 是 |
| 變長陣列 (Varray) | 有界 | 整數 | 始終密集型 | 在 PL/SQL 塊中或在模式級別 | 是 |
我們已經在**“PL/SQL 陣列”**一章中討論了 varray。在本章中,我們將討論 PL/SQL 表。
兩種 PL/SQL 表(即按索引表和巢狀表)具有相同的結構,並且它們的行的訪問使用下標表示法。但是,這兩種型別的表在一個方面有所不同;巢狀表可以儲存在資料庫列中,而按索引表則不能。
按索引表
**按索引**表(也稱為**關聯陣列**)是一組**鍵值**對。每個鍵都是唯一的,用於定位對應的值。鍵可以是整數或字串。
按索引表使用以下語法建立。在這裡,我們正在建立一個名為**table_name**的**按索引**表,其鍵將為 `subscript_type` 型別,關聯值將為 `element_type` 型別。
TYPE type_name IS TABLE OF element_type [NOT NULL] INDEX BY subscript_type; table_name type_name;
示例
下面的示例演示如何建立一個表來儲存整數及其名稱,然後列印相同的名稱列表。
DECLARE
TYPE salary IS TABLE OF NUMBER INDEX BY VARCHAR2(20);
salary_list salary;
name VARCHAR2(20);
BEGIN
-- adding elements to the table
salary_list('Rajnish') := 62000;
salary_list('Minakshi') := 75000;
salary_list('Martin') := 100000;
salary_list('James') := 78000;
-- printing the table
name := salary_list.FIRST;
WHILE name IS NOT null LOOP
dbms_output.put_line
('Salary of ' || name || ' is ' || TO_CHAR(salary_list(name)));
name := salary_list.NEXT(name);
END LOOP;
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Salary of James is 78000 Salary of Martin is 100000 Salary of Minakshi is 75000 Salary of Rajnish is 62000 PL/SQL procedure successfully completed.
示例
按索引表的元素也可以是任何資料庫表的**%ROWTYPE** 或任何資料庫表字段的**%TYPE**。以下示例說明了這個概念。我們將使用儲存在資料庫中的**CUSTOMERS** 表,如下所示:
Select * from customers; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | +----+----------+-----+-----------+----------+
DECLARE
CURSOR c_customers is
select name from customers;
TYPE c_list IS TABLE of customers.Name%type INDEX BY binary_integer;
name_list c_list;
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter +1;
name_list(counter) := n.name;
dbms_output.put_line('Customer('||counter||'):'||name_lis t(counter));
END LOOP;
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Customer(1): Ramesh Customer(2): Khilan Customer(3): kaushik Customer(4): Chaitali Customer(5): Hardik Customer(6): Komal PL/SQL procedure successfully completed
巢狀表
**巢狀表**類似於具有任意數量元素的一維陣列。但是,巢狀表在以下方面與陣列不同:
陣列具有宣告的元素數量,但巢狀表沒有。巢狀表的大小可以動態增加。
陣列始終是密集型的,即始終具有連續的下標。巢狀陣列最初是密集型的,但是當從中刪除元素時,它可能會變為稀疏型。
巢狀表使用以下語法建立:
TYPE type_name IS TABLE OF element_type [NOT NULL]; table_name type_name;
此宣告類似於**按索引**表的宣告,但是沒有**INDEX BY** 子句。
巢狀表可以儲存在資料庫列中。它可以進一步用於簡化 SQL 操作,在這些操作中,您將單列表與更大的表連線。關聯陣列不能儲存在資料庫中。
示例
以下示例說明了巢狀表的使用:
DECLARE
TYPE names_table IS TABLE OF VARCHAR2(10);
TYPE grades IS TABLE OF INTEGER;
names names_table;
marks grades;
total integer;
BEGIN
names := names_table('Kavita', 'Pritam', 'Ayan', 'Rishav', 'Aziz');
marks:= grades(98, 97, 78, 87, 92);
total := names.count;
dbms_output.put_line('Total '|| total || ' Students');
FOR i IN 1 .. total LOOP
dbms_output.put_line('Student:'||names(i)||', Marks:' || marks(i));
end loop;
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Total 5 Students Student:Kavita, Marks:98 Student:Pritam, Marks:97 Student:Ayan, Marks:78 Student:Rishav, Marks:87 Student:Aziz, Marks:92 PL/SQL procedure successfully completed.
示例
**巢狀表**的元素也可以是任何資料庫表的**%ROWTYPE** 或任何資料庫表字段的 %TYPE。以下示例說明了這個概念。我們將使用儲存在資料庫中的 CUSTOMERS 表,如下所示:
Select * from customers; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | +----+----------+-----+-----------+----------+
DECLARE
CURSOR c_customers is
SELECT name FROM customers;
TYPE c_list IS TABLE of customerS.No.ame%type;
name_list c_list := c_list();
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter +1;
name_list.extend;
name_list(counter) := n.name;
dbms_output.put_line('Customer('||counter||'):'||name_list(counter));
END LOOP;
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Customer(1): Ramesh Customer(2): Khilan Customer(3): kaushik Customer(4): Chaitali Customer(5): Hardik Customer(6): Komal PL/SQL procedure successfully completed.
集合方法
PL/SQL 提供內建集合方法,使集合更易於使用。下表列出了這些方法及其用途:
| 序號 | 方法名稱和用途 |
|---|---|
| 1 | EXISTS(n) 如果集合中存在第 n 個元素,則返回 TRUE;否則返回 FALSE。 |
| 2 | COUNT 返回集合當前包含的元素數量。 |
| 3 | LIMIT 檢查集合的最大大小。 |
| 4 | FIRST 返回使用整數下標的集合中的第一個(最小)索引號。 |
| 5 | LAST 返回使用整數下標的集合中的最後一個(最大)索引號。 |
| 6 | PRIOR(n) 返回集合中位於索引 n 之前的索引號。 |
| 7 | NEXT(n) 返回集合中位於索引 n 之後的索引號。 |
| 8 | EXTEND 將一個空元素附加到集合。 |
| 9 | EXTEND(n) 將 n 個空元素附加到集合。 |
| 10 | EXTEND(n,i) 將第 i 個元素的 n 個副本附加到集合。 |
| 11 | TRIM 從集合末尾刪除一個元素。 |
| 12 | TRIM(n) 從集合末尾刪除 n 個元素。 |
| 13 | DELETE 刪除集合中的所有元素,並將 COUNT 設定為 0。 |
| 14 | DELETE(n) 從具有數字鍵的關聯陣列或巢狀表中刪除第 **n** 個元素。如果關聯陣列具有字串鍵,則刪除對應於鍵值的元素。如果 **n** 為空,則 **DELETE(n)** 不執行任何操作。 |
| 15 | DELETE(m,n) 從關聯陣列或巢狀表中刪除範圍 **m..n** 內的所有元素。如果 **m** 大於 **n** 或 **m** 或 **n** 為空,則 **DELETE(m,n)** 不執行任何操作。 |
集合異常
下表提供了集合異常及其引發的時間:
| 集合異常 | 引發情況 |
|---|---|
| COLLECTION_IS_NULL | 嘗試對原子空集合進行操作。 |
| NO_DATA_FOUND | 下標指定已刪除的元素,或關聯陣列中不存在的元素。 |
| SUBSCRIPT_BEYOND_COUNT | 下標超過集合中的元素數量。 |
| SUBSCRIPT_OUTSIDE_LIMIT | 下標超出允許的範圍。 |
| VALUE_ERROR | 下標為空或無法轉換為鍵型別。如果鍵定義為 **PLS_INTEGER** 範圍,並且下標在此範圍之外,則可能會發生此異常。 |
PL/SQL - 事務
在本章中,我們將討論 PL/SQL 中的事務。資料庫**事務**是可能包含一個或多個相關 SQL 語句的原子工作單元。它被稱為原子,因為構成事務的 SQL 語句帶來的資料庫修改可以集體地提交(即永久儲存到資料庫)或回滾(從資料庫撤消)。
成功執行的 SQL 語句和提交的事務並不相同。即使成功執行了 SQL 語句,除非包含該語句的事務已提交,否則它可以回滾,並且該語句所做的所有更改都可以撤消。
啟動和結束事務
事務有**開始**和**結束**。當發生以下事件之一時,事務開始:
連線到資料庫後執行第一個 SQL 語句。
在事務完成後發出的每個新的 SQL 語句。
當發生以下事件之一時,事務結束:
發出 **COMMIT** 或 **ROLLBACK** 語句。
發出 **DDL** 語句(例如 **CREATE TABLE** 語句);因為在這種情況下會自動執行 COMMIT。
發出 **DCL** 語句(例如 **GRANT** 語句);因為在這種情況下會自動執行 COMMIT。
使用者與資料庫斷開連線。
使用者透過發出 **EXIT** 命令退出 **SQL*PLUS**,將自動執行 COMMIT。
SQL*Plus 異常終止,將自動執行 **ROLLBACK**。
**DML** 語句失敗;在這種情況下,將自動執行 ROLLBACK 以撤消該 DML 語句。
提交事務
透過發出 SQL 命令 COMMIT 來使事務永久化。COMMIT 命令的通用語法為:
COMMIT;
例如:
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Ramesh', 32, 'Ahmedabad', 2000.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (2, 'Khilan', 25, 'Delhi', 1500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (3, 'kaushik', 23, 'Kota', 2000.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (4, 'Chaitali', 25, 'Mumbai', 6500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (5, 'Hardik', 27, 'Bhopal', 8500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (6, 'Komal', 22, 'MP', 4500.00 ); COMMIT;
回滾事務
未提交的資料庫更改可以使用 ROLLBACK 命令撤消。
ROLLBACK 命令的通用語法為:
ROLLBACK [TO SAVEPOINT < savepoint_name>];
當事務由於某些意外情況(例如系統故障)而中止時,自提交以來整個事務將自動回滾。如果您沒有使用**儲存點**,則只需使用以下語句即可回滾所有更改:
ROLLBACK;
儲存點
儲存點是某種標記,透過設定一些檢查點來幫助將長事務分割成更小的單元。透過在長事務中設定儲存點,如果需要,您可以回滾到檢查點。這是透過發出 **SAVEPOINT** 命令來完成的。
SAVEPOINT 命令的通用語法為:
SAVEPOINT < savepoint_name >;
例如
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (7, 'Rajnish', 27, 'HP', 9500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (8, 'Riddhi', 21, 'WB', 4500.00 ); SAVEPOINT sav1; UPDATE CUSTOMERS SET SALARY = SALARY + 1000; ROLLBACK TO sav1; UPDATE CUSTOMERS SET SALARY = SALARY + 1000 WHERE ID = 7; UPDATE CUSTOMERS SET SALARY = SALARY + 1000 WHERE ID = 8; COMMIT;
**ROLLBACK TO sav1** - 此語句將回滾所有更改,直到您標記儲存點 sav1 的位置。
之後,您所做的更改將開始。
自動事務控制
要每當執行 **INSERT、UPDATE** 或 **DELETE** 命令時自動執行 **COMMIT**,您可以設定 **AUTOCOMMIT** 環境變數,如下所示:
SET AUTOCOMMIT ON;
您可以使用以下命令關閉自動提交模式:
SET AUTOCOMMIT OFF;
PL/SQL - 日期和時間
在本章中,我們將討論 PL/SQL 中的日期和時間。PL/SQL 中有兩類與日期和時間相關的資料型別:
- 日期時間資料型別
- 間隔資料型別
日期時間資料型別為:
- DATE
- TIMESTAMP
- TIMESTAMP WITH TIME ZONE
- TIMESTAMP WITH LOCAL TIME ZONE
間隔資料型別為:
- INTERVAL YEAR TO MONTH
- INTERVAL DAY TO SECOND
日期時間和間隔資料型別的欄位值
**日期時間**和**間隔**資料型別都包含**欄位**。這些欄位的值決定了資料型別的的值。下表列出了日期時間和間隔的欄位及其可能的值。
| 欄位名稱 | 有效日期時間值 | 有效區間值 |
|---|---|---|
| YEAR | -4712 到 9999(不包括年份 0) | 任何非零整數 |
| MONTH | 01 到 12 | 0 到 11 |
| DAY | 01 到 31(根據區域設定日曆規則,受 MONTH 和 YEAR 值的限制) | 任何非零整數 |
| HOUR | 00 到 23 | 0 到 23 |
| MINUTE | 00 到 59 | 0 到 59 |
| SECOND | 00 到 59.9(n),其中 9(n) 是時間小數秒的精度 9(n) 部分不適用於 DATE。 |
0 到 59.9(n),其中 9(n) 是區間小數秒的精度 |
| TIMEZONE_HOUR | -12 到 14(範圍適應夏令時變化) 不適用於 DATE 或 TIMESTAMP。 |
不適用 |
| TIMEZONE_MINUTE | 00 到 59 不適用於 DATE 或 TIMESTAMP。 |
不適用 |
| TIMEZONE_REGION | 不適用於 DATE 或 TIMESTAMP。 | 不適用 |
| TIMEZONE_ABBR | 不適用於 DATE 或 TIMESTAMP。 | 不適用 |
日期時間資料型別和函式
以下是日期時間資料型別:
DATE
它以字元和數字資料型別儲存日期和時間資訊。它包含有關世紀、年份、月份、日期、小時、分鐘和秒的資訊。它被指定為:
TIMESTAMP
它是DATE資料型別的一個擴充套件。它儲存DATE資料型別的年份、月份和日期,以及小時、分鐘和秒的值。它用於儲存精確的時間值。
TIMESTAMP WITH TIME ZONE
它是TIMESTAMP的一個變體,在其值中包含時區區域名稱或時區偏移量。時區偏移量是當地時間與UTC之間的差值(以小時和分鐘表示)。此資料型別對於跨地理區域收集和評估日期資訊非常有用。
TIMESTAMP WITH LOCAL TIME ZONE
它是TIMESTAMP的另一個變體,在其值中包含時區偏移量。
下表提供了日期時間函式(其中,x 具有日期時間值):
| 序號 | 函式名稱及描述 |
|---|---|
| 1 | ADD_MONTHS(x, y); 將y個月新增到x。 |
| 2 | LAST_DAY(x); 返回該月的最後一天。 |
| 3 | MONTHS_BETWEEN(x, y); 返回x和y之間的月數。 |
| 4 | NEXT_DAY(x, day); 返回x之後下一個day的日期時間。 |
| 5 | NEW_TIME; 返回使用者指定的時區的時間/日期值。 |
| 6 | ROUND(x [, unit]); 對x進行四捨五入。 |
| 7 | SYSDATE(); 返回當前日期時間。 |
| 8 | TRUNC(x [, unit]); 截斷x。 |
時間戳函式(其中,x 具有時間戳值):
| 序號 | 函式名稱及描述 |
|---|---|
| 1 | CURRENT_TIMESTAMP(); 返回一個包含當前會話時間以及會話時區的TIMESTAMP WITH TIME ZONE。 |
| 2 | EXTRACT({ YEAR | MONTH | DAY | HOUR | MINUTE | SECOND } | { TIMEZONE_HOUR | TIMEZONE_MINUTE } | { TIMEZONE_REGION | } TIMEZONE_ABBR ) FROM x) 提取並返回來自x的年份、月份、日期、小時、分鐘、秒或時區。 |
| 3 | FROM_TZ(x, time_zone); 將TIMESTAMP x 和time_zone指定的時區轉換為TIMESTAMP WITH TIMEZONE。 |
| 4 | LOCALTIMESTAMP(); 返回一個包含會話時區中本地時間的TIMESTAMP。 |
| 5 | SYSTIMESTAMP(); 返回一個包含當前資料庫時間以及資料庫時區的TIMESTAMP WITH TIME ZONE。 |
| 6 | SYS_EXTRACT_UTC(x); 將TIMESTAMP WITH TIMEZONE x 轉換為包含UTC中日期和時間的TIMESTAMP。 |
| 7 | TO_TIMESTAMP(x, [format]); 將字串x轉換為TIMESTAMP。 |
| 8 | TO_TIMESTAMP_TZ(x, [format]); 將字串x轉換為TIMESTAMP WITH TIMEZONE。 |
示例
以下程式碼片段說明了上述函式的用法:
示例 1
SELECT SYSDATE FROM DUAL;
輸出:
08/31/2012 5:25:34 PM
示例 2
SELECT TO_CHAR(CURRENT_DATE, 'DD-MM-YYYY HH:MI:SS') FROM DUAL;
輸出:
31-08-2012 05:26:14
示例3
SELECT ADD_MONTHS(SYSDATE, 5) FROM DUAL;
輸出:
01/31/2013 5:26:31 PM
示例4
SELECT LOCALTIMESTAMP FROM DUAL;
輸出:
8/31/2012 5:26:55.347000 PM
區間資料型別和函式
以下是區間資料型別:
IINTERVAL YEAR TO MONTH — 它使用YEAR和MONTH日期時間欄位儲存一段時間。
INTERVAL DAY TO SECOND — 它以天、小時、分鐘和秒為單位儲存一段時間。
區間函式
| 序號 | 函式名稱及描述 |
|---|---|
| 1 | NUMTODSINTERVAL(x, interval_unit); 將數字x轉換為INTERVAL DAY TO SECOND。 |
| 2 | NUMTOYMINTERVAL(x, interval_unit); 將數字x轉換為INTERVAL YEAR TO MONTH。 |
| 3 | TO_DSINTERVAL(x); 將字串x轉換為INTERVAL DAY TO SECOND。 |
| 4 | TO_YMINTERVAL(x); 將字串x轉換為INTERVAL YEAR TO MONTH。 |
PL/SQL - DBMS 輸出
本章將討論PL/SQL中的DBMS輸出。DBMS_OUTPUT是一個內建包,它允許您顯示輸出、除錯資訊以及從PL/SQL塊、子程式、包和觸發器傳送訊息。在我們的教程中,我們已經多次使用過此包。
讓我們來看一個小程式碼片段,它將顯示資料庫中所有使用者表。請在您的資料庫中嘗試它以列出所有表名:
BEGIN
dbms_output.put_line (user || ' Tables in the database:');
FOR t IN (SELECT table_name FROM user_tables)
LOOP
dbms_output.put_line(t.table_name);
END LOOP;
END;
/
DBMS_OUTPUT子程式
DBMS_OUTPUT包具有以下子程式:
| 序號 | 子程式及用途 | |
|---|---|---|
| 1 | DBMS_OUTPUT.DISABLE; 停用訊息輸出。 |
|
| 2 | DBMS_OUTPUT.ENABLE(buffer_size IN INTEGER DEFAULT 20000); 啟用訊息輸出。buffer_size的NULL值表示緩衝區大小不限。 |
|
| 3 | DBMS_OUTPUT.GET_LINE (line OUT VARCHAR2, status OUT INTEGER); 檢索緩衝區中的一行資訊。 |
|
| 4 | DBMS_OUTPUT.GET_LINES (lines OUT CHARARR, numlines IN OUT INTEGER); 從緩衝區檢索一系列行。 |
|
| 5 | DBMS_OUTPUT.NEW_LINE; 放置一個行尾標記。 |
|
| 6 | DBMS_OUTPUT.PUT(item IN VARCHAR2); 將部分行放入緩衝區。 |
|
| 7 | DBMS_OUTPUT.PUT_LINE(item IN VARCHAR2); 將一行放入緩衝區。 |
示例
DECLARE
lines dbms_output.chararr;
num_lines number;
BEGIN
-- enable the buffer with default size 20000
dbms_output.enable;
dbms_output.put_line('Hello Reader!');
dbms_output.put_line('Hope you have enjoyed the tutorials!');
dbms_output.put_line('Have a great time exploring pl/sql!');
num_lines := 3;
dbms_output.get_lines(lines, num_lines);
FOR i IN 1..num_lines LOOP
dbms_output.put_line(lines(i));
END LOOP;
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Hello Reader! Hope you have enjoyed the tutorials! Have a great time exploring pl/sql! PL/SQL procedure successfully completed.
PL/SQL - 面向物件
本章將討論面向物件的PL/SQL。PL/SQL允許定義物件型別,這有助於在Oracle中設計面向物件的資料庫。物件型別允許您建立複合型別。使用物件允許您實現具有特定資料結構和操作方法的現實世界物件。物件具有屬性和方法。屬性是物件的屬性,用於儲存物件的狀態;方法用於模擬其行為。
使用CREATE [OR REPLACE] TYPE語句建立物件。以下是如何建立一個包含少量屬性的簡單address物件的示例:
CREATE OR REPLACE TYPE address AS OBJECT (house_no varchar2(10), street varchar2(30), city varchar2(20), state varchar2(10), pincode varchar2(10) ); /
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Type created.
讓我們再建立一個customer物件,我們將屬性和方法組合在一起,以獲得面向物件的感覺:
CREATE OR REPLACE TYPE customer AS OBJECT (code number(5), name varchar2(30), contact_no varchar2(12), addr address, member procedure display ); /
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Type created.
例項化物件
定義物件型別提供物件的藍圖。要使用此物件,您需要建立此物件的例項。您可以使用例項名稱和訪問運算子 (.)訪問物件的屬性和方法,如下所示:
DECLARE
residence address;
BEGIN
residence := address('103A', 'M.G.Road', 'Jaipur', 'Rajasthan','201301');
dbms_output.put_line('House No: '|| residence.house_no);
dbms_output.put_line('Street: '|| residence.street);
dbms_output.put_line('City: '|| residence.city);
dbms_output.put_line('State: '|| residence.state);
dbms_output.put_line('Pincode: '|| residence.pincode);
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
House No: 103A Street: M.G.Road City: Jaipur State: Rajasthan Pincode: 201301 PL/SQL procedure successfully completed.
成員方法
成員方法用於操作物件的屬性。在宣告物件型別時,您提供成員方法的宣告。物件主體定義成員方法的程式碼。物件主體使用CREATE TYPE BODY語句建立。
建構函式是返回新物件作為其值的函式。每個物件都有一個系統定義的建構函式方法。建構函式的名稱與物件型別相同。例如:
residence := address('103A', 'M.G.Road', 'Jaipur', 'Rajasthan','201301');
比較方法用於比較物件。比較物件有兩種方法:
Map方法
Map方法是一個以這種方式實現的函式,其值取決於屬性的值。例如,對於客戶物件,如果兩個客戶的客戶程式碼相同,則這兩個客戶可能相同。因此,這兩個物件之間的關係將取決於程式碼的值。
Order方法
Order方法實現了一些用於比較兩個物件的內部邏輯。例如,對於矩形物件,如果矩形的兩邊都更大,則一個矩形大於另一個矩形。
使用Map方法
讓我們使用以下矩形物件來理解上述概念:
CREATE OR REPLACE TYPE rectangle AS OBJECT (length number, width number, member function enlarge( inc number) return rectangle, member procedure display, map member function measure return number ); /
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Type created.
建立型別主體:
CREATE OR REPLACE TYPE BODY rectangle AS
MEMBER FUNCTION enlarge(inc number) return rectangle IS
BEGIN
return rectangle(self.length + inc, self.width + inc);
END enlarge;
MEMBER PROCEDURE display IS
BEGIN
dbms_output.put_line('Length: '|| length);
dbms_output.put_line('Width: '|| width);
END display;
MAP MEMBER FUNCTION measure return number IS
BEGIN
return (sqrt(length*length + width*width));
END measure;
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Type body created.
現在使用矩形物件及其成員函式:
DECLARE
r1 rectangle;
r2 rectangle;
r3 rectangle;
inc_factor number := 5;
BEGIN
r1 := rectangle(3, 4);
r2 := rectangle(5, 7);
r3 := r1.enlarge(inc_factor);
r3.display;
IF (r1 > r2) THEN -- calling measure function
r1.display;
ELSE
r2.display;
END IF;
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Length: 8 Width: 9 Length: 5 Width: 7 PL/SQL procedure successfully completed.
使用Order方法
現在,可以使用order方法實現相同的效果。讓我們使用order方法重新建立矩形物件:
CREATE OR REPLACE TYPE rectangle AS OBJECT (length number, width number, member procedure display, order member function measure(r rectangle) return number ); /
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Type created.
建立型別主體:
CREATE OR REPLACE TYPE BODY rectangle AS
MEMBER PROCEDURE display IS
BEGIN
dbms_output.put_line('Length: '|| length);
dbms_output.put_line('Width: '|| width);
END display;
ORDER MEMBER FUNCTION measure(r rectangle) return number IS
BEGIN
IF(sqrt(self.length*self.length + self.width*self.width)>
sqrt(r.length*r.length + r.width*r.width)) then
return(1);
ELSE
return(-1);
END IF;
END measure;
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Type body created.
使用矩形物件及其成員函式:
DECLARE
r1 rectangle;
r2 rectangle;
BEGIN
r1 := rectangle(23, 44);
r2 := rectangle(15, 17);
r1.display;
r2.display;
IF (r1 > r2) THEN -- calling measure function
r1.display;
ELSE
r2.display;
END IF;
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Length: 23 Width: 44 Length: 15 Width: 17 Length: 23 Width: 44 PL/SQL procedure successfully completed.
PL/SQL物件的繼承
PL/SQL允許從現有的基物件建立物件。要實現繼承,基物件應宣告為NOT FINAL。預設值為FINAL。
以下程式說明了PL/SQL物件中的繼承。讓我們建立另一個名為TableTop的物件,它繼承自Rectangle物件。為此,我們需要建立基rectangle物件:
CREATE OR REPLACE TYPE rectangle AS OBJECT (length number, width number, member function enlarge( inc number) return rectangle, NOT FINAL member procedure display) NOT FINAL /
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Type created.
建立基型別主體:
CREATE OR REPLACE TYPE BODY rectangle AS
MEMBER FUNCTION enlarge(inc number) return rectangle IS
BEGIN
return rectangle(self.length + inc, self.width + inc);
END enlarge;
MEMBER PROCEDURE display IS
BEGIN
dbms_output.put_line('Length: '|| length);
dbms_output.put_line('Width: '|| width);
END display;
END;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Type body created.
建立子物件tabletop:
CREATE OR REPLACE TYPE tabletop UNDER rectangle ( material varchar2(20), OVERRIDING member procedure display ) /
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Type created.
建立子物件tabletop的型別主體
CREATE OR REPLACE TYPE BODY tabletop AS
OVERRIDING MEMBER PROCEDURE display IS
BEGIN
dbms_output.put_line('Length: '|| length);
dbms_output.put_line('Width: '|| width);
dbms_output.put_line('Material: '|| material);
END display;
/
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Type body created.
使用tabletop物件及其成員函式:
DECLARE t1 tabletop; t2 tabletop; BEGIN t1:= tabletop(20, 10, 'Wood'); t2 := tabletop(50, 30, 'Steel'); t1.display; t2.display; END; /
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Length: 20 Width: 10 Material: Wood Length: 50 Width: 30 Material: Steel PL/SQL procedure successfully completed.
PL/SQL中的抽象物件
NOT INSTANTIABLE子句允許您宣告抽象物件。您不能按原樣使用抽象物件;您必須建立此類物件的子型別或子型別才能使用其功能。
例如:
CREATE OR REPLACE TYPE rectangle AS OBJECT (length number, width number, NOT INSTANTIABLE NOT FINAL MEMBER PROCEDURE display) NOT INSTANTIABLE NOT FINAL /
當上述程式碼在SQL提示符下執行時,它會產生以下結果:
Type created.