平行計算機體系結構 - 模型
並行處理已發展成為現代計算機中的一項有效技術,以滿足現實應用中對更高效能、更低成本和更準確結果的需求。由於多程式設計、多處理或多計算的實踐,當今的計算機中併發事件很常見。
現代計算機擁有強大而廣泛的軟體包。要分析計算機效能的發展,首先必須瞭解硬體和軟體的基本發展。
計算機發展里程碑 - 計算機的發展有兩個主要階段 - 機械或機電部件。現代計算機是在引入了電子元件後發展起來的。電子計算機中高遷移率的電子取代了機械計算機中的操作部件。為了資訊傳輸,以接近光速傳播的電訊號取代了機械齒輪或槓桿。
現代計算機的組成要素 - 現代計算機系統由計算機硬體、指令集、應用程式、系統軟體和使用者介面組成。

計算問題可分為數值計算、邏輯推理和事務處理。一些複雜問題可能需要三種處理模式的組合。
計算機體系結構的演變 - 在過去的四十年裡,計算機體系結構經歷了革命性的變化。我們從馮諾依曼體系結構開始,現在有了多計算機和多處理器。
計算機系統的效能 - 計算機系統的效能取決於機器能力和程式行為。可以透過更好的硬體技術、先進的體系結構特性和高效的資源管理來提高機器能力。程式行為是不可預測的,因為它取決於應用程式和執行時條件。
多處理器和多計算機
在本節中,我們將討論兩種型別的平行計算機 -
- 多處理器
- 多計算機
共享記憶體多計算機
三種最常見的共享記憶體多處理器模型是 -
統一記憶體訪問 (UMA)
在此模型中,所有處理器都統一共享物理記憶體。所有處理器對所有記憶體字都有相同的訪問時間。每個處理器可能都有一個私有快取記憶體。外設遵循相同的規則。
當所有處理器都能平等訪問所有外設時,該系統稱為對稱多處理器。當只有一個或幾個處理器可以訪問外設時,該系統稱為非對稱多處理器。

非統一記憶體訪問 (NUMA)
在 NUMA 多處理器模型中,訪問時間隨記憶體字的位置而變化。在這裡,共享記憶體在所有處理器之間物理分佈,稱為本地記憶體。所有本地記憶體的集合形成一個全域性地址空間,所有處理器都可以訪問該空間。

僅快取記憶體體系結構 (COMA)
COMA 模型是 NUMA 模型的特例。在這裡,所有分散式主記憶體都轉換為快取記憶體。

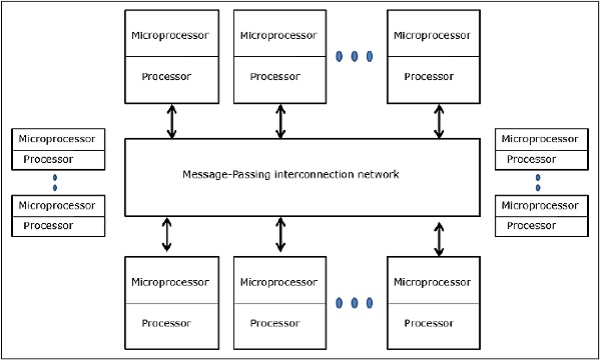
分散式記憶體多計算機 - 分散式記憶體多計算機系統由多個計算機(稱為節點)組成,這些計算機透過訊息傳遞網路互連。每個節點充當一個自治計算機,具有處理器、本地記憶體以及有時是 I/O 裝置。在這種情況下,所有本地記憶體都是私有的,並且只能由本地處理器訪問。這就是為什麼傳統機器被稱為無遠端記憶體訪問 (NORMA) 機器。
多向量和 SIMD 計算機
在本節中,我們將討論用於向量處理和資料並行的超級計算機和並行處理器。
向量超級計算機
在向量計算機中,向量處理器作為可選功能附加到標量處理器。主機計算機首先將程式和資料載入到主記憶體中。然後標量控制單元解碼所有指令。如果解碼的指令是標量運算或程式運算,則標量處理器使用標量功能流水線執行這些運算。
另一方面,如果解碼的指令是向量運算,則指令將傳送到向量控制單元。

SIMD 超級計算機
在 SIMD 計算機中,'N' 個處理器連線到一個控制單元,並且所有處理器都有其各自的記憶體單元。所有處理器都透過互連網路連線。

PRAM 和 VLSI 模型
理想模型為開發並行演算法提供了一個合適的框架,而不考慮物理約束或實現細節。
可以執行這些模型以獲得平行計算機上的理論效能界限,或者在晶片製造之前評估芯片面積和操作時間的 VLSI 複雜性。
並行隨機存取機
Sheperdson 和 Sturgis (1963) 將傳統的單處理器計算機建模為隨機存取機 (RAM)。Fortune 和 Wyllie (1978) 開發了一種並行隨機存取機 (PRAM) 模型,用於對具有零記憶體訪問開銷和同步的理想化平行計算機進行建模。

一個 N 處理器 PRAM 具有一個共享記憶體單元。此共享記憶體可以集中或分佈在處理器之間。這些處理器在同步的讀記憶體、寫記憶體和計算週期上執行。因此,這些模型指定了如何處理併發讀和寫操作。
以下是可能的記憶體更新操作 -
排他讀 (ER) - 在此方法中,在每個週期中,只允許一個處理器從任何記憶體位置讀取。
排他寫 (EW) - 在此方法中,允許至少一個處理器一次寫入記憶體位置。
併發讀 (CR) - 它允許多個處理器在同一週期內從同一記憶體位置讀取相同的資訊。
併發寫 (CW) - 它允許同時寫入同一記憶體位置。為了避免寫入衝突,設定了一些策略。
VLSI 複雜度模型
平行計算機使用 VLSI 晶片來製造處理器陣列、記憶體陣列和大型交換網路。
如今,VLSI 技術是二維的。VLSI 晶片的大小與該晶片中可用的儲存(記憶體)空間量成正比。
我們可以透過演算法的 VLSI 晶片實現的芯片面積 (A) 來計算演算法的空間複雜度。如果 T 是執行演算法所需的時間(延遲),則 A.T 給出了透過晶片(或 I/O)處理的總位數的上限。對於某些計算,存在一個下限 f(s),使得
A.T2 >= O (f(s))
其中 A=芯片面積,T=時間
體系結構發展軌跡
平行計算機的演變沿著以下軌跡發展 -
- 多處理器軌跡
- 多處理器軌跡
- 多計算機軌跡
- 多資料軌跡
- 向量軌跡
- SIMD 軌跡
- 多執行緒軌跡
- 多執行緒軌跡
- 資料流軌跡
在多處理器軌跡中,假設不同的執行緒在不同的處理器上併發執行,並透過共享記憶體(多處理器軌跡)或訊息傳遞(多計算機軌跡)系統進行通訊。
在多資料軌跡中,假設在海量資料上執行相同的程式碼。這是透過對資料元素序列執行相同的指令(向量軌跡)或透過對類似資料集執行相同的指令序列(SIMD 軌跡)來完成的。
在多執行緒軌跡中,假設在同一處理器上交錯執行各種執行緒以隱藏在不同處理器上執行的執行緒之間的同步延遲。執行緒交錯可以是粗粒度的(多執行緒軌跡)或細粒度的(資料流軌跡)。