快取一致性和同步
本章將討論用於應對多快取不一致問題的快取一致性協議。
快取一致性問題
在多處理器系統中,資料不一致可能發生在相鄰級別之間或記憶體層次結構的同一級別內。例如,快取和主記憶體可能具有同一物件的副本不一致。
由於多個處理器並行且獨立地執行,多個快取可能擁有同一記憶體塊的不同副本,這會產生快取一致性問題。快取一致性方案透過維護每個快取資料塊的統一狀態來幫助避免此問題。
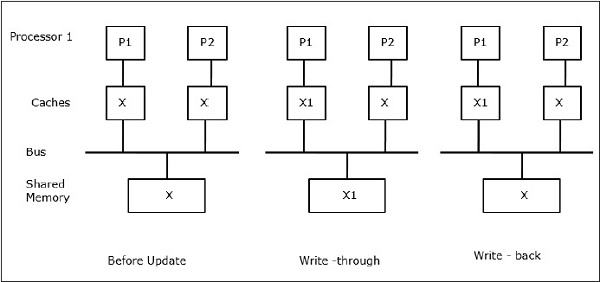
設X為共享資料的元素,已被兩個處理器P1和P2引用。開始時,X的三個副本是一致的。如果處理器P1使用直寫策略將新的資料X1寫入快取,則相同的副本將立即寫入共享記憶體。在這種情況下,快取記憶體和主記憶體之間會發生不一致。當使用寫回策略時,當快取中修改的資料被替換或失效時,主記憶體將被更新。
一般來說,存在三個不一致問題來源:
- 共享可寫資料
- 程序遷移
- I/O活動
窺探匯流排協議
窺探協議透過基於匯流排的記憶體系統實現快取記憶體和共享記憶體之間的資料一致性。寫失效和寫更新策略用於維護快取一致性。


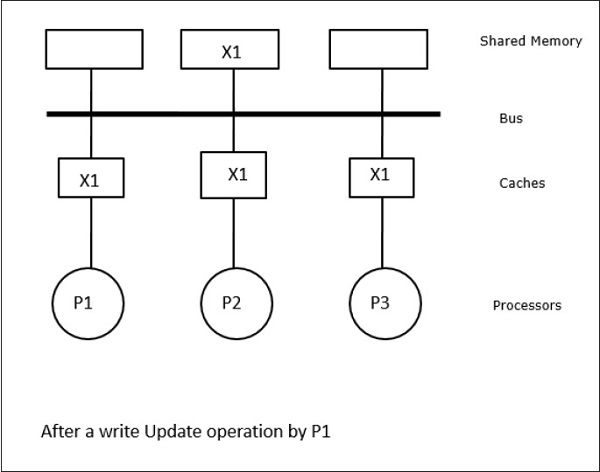
在這種情況下,我們有三個處理器P1、P2和P3,它們的本地快取記憶體和共享記憶體中都具有資料元素“X”的一致副本(圖a)。處理器P1使用寫失效協議將其快取記憶體中的X寫入X1。因此,所有其他副本都透過匯流排失效。它用“I”表示(圖b)。失效的塊也稱為髒塊,即它們不應使用。寫更新協議透過匯流排更新所有快取副本。使用寫回快取,記憶體副本也會更新(圖c)。
快取事件和操作
執行記憶體訪問和失效命令時會發生以下事件和操作:
讀失效 - 當處理器想要讀取一個塊而它不在快取中時,就會發生讀失效。這將啟動匯流排讀取操作。如果不存在髒副本,則具有一致副本的主記憶體會向請求快取記憶體提供副本。如果在遠端快取記憶體中存在髒副本,則該快取將限制主記憶體並向請求快取記憶體傳送副本。在這兩種情況下,快取副本在讀失效後都將進入有效狀態。
寫命中 - 如果副本處於髒或保留狀態,則在本地執行寫入,新狀態為髒。如果新狀態有效,則將寫失效命令廣播到所有快取,使它們的副本失效。當共享記憶體被直寫時,在此第一次寫入之後,結果狀態將被保留。
寫失效 - 如果處理器無法寫入本地快取記憶體,則副本必須來自主記憶體或具有髒塊的遠端快取記憶體。這是透過傳送讀失效命令完成的,該命令將使所有快取副本失效。然後,本地副本將更新為髒狀態。
讀命中 - 讀命中始終在本地快取記憶體中執行,而不會導致狀態轉換或使用窺探匯流排進行失效。
塊替換 - 當副本髒時,它將透過塊替換方法寫回到主記憶體。但是,當副本處於有效、保留或無效狀態時,不會發生替換。
基於目錄的協議
透過使用多級網路構建具有數百個處理器的較大多處理器,需要修改窺探快取協議以適應網路功能。由於在多級網路中執行廣播非常昂貴,因此一致性命令僅傳送給保留塊副本的那些快取。這就是為網路連線的多處理器開發基於目錄的協議的原因。
在基於目錄的協議系統中,要共享的資料放置在一個公共目錄中,該目錄維護快取之間的一致性。在這裡,目錄充當過濾器,處理器請求允許將其條目從主記憶體載入到其快取記憶體中。如果條目更改,目錄會更新它或使具有該條目的其他快取失效。
硬體同步機制
同步是一種特殊的通訊形式,其中不是資料控制,而是駐留在相同或不同處理器中的通訊程序之間交換資訊。
多處理器系統使用硬體機制來實現低階同步操作。大多數多處理器都有硬體機制來強制執行原子操作,例如記憶體讀、寫或讀-修改-寫操作,以實現一些同步原語。除了原子記憶體操作外,還有一些處理器間中斷用於同步目的。
共享記憶體機器中的快取一致性
當處理器包含本地快取記憶體時,維護快取一致性是多處理器系統中的一個問題。在此係統中,不同快取之間的資料不一致很容易發生。
主要關注領域是:
- 共享可寫資料
- 程序遷移
- I/O活動
共享可寫資料
當兩個處理器(P1和P2)在其本地快取中具有相同的資料元素(X),並且一個程序(P1)寫入資料元素(X)時,由於P1的快取是直寫本地快取,主記憶體也會更新。現在,當P2嘗試讀取資料元素(X)時,它找不到X,因為P2快取中的資料元素已過期。

程序遷移
在第一階段,P1的快取具有資料元素X,而P2沒有任何資料。P2上的一個程序首先寫入X,然後遷移到P1。現在,程序開始讀取資料元素X,但是由於處理器P1具有過時的資料,因此程序無法讀取它。因此,P1上的一個程序寫入資料元素X,然後遷移到P2。遷移後,P2上的一個程序開始讀取資料元素X,但它在主記憶體中找到X的過時版本。

I/O活動
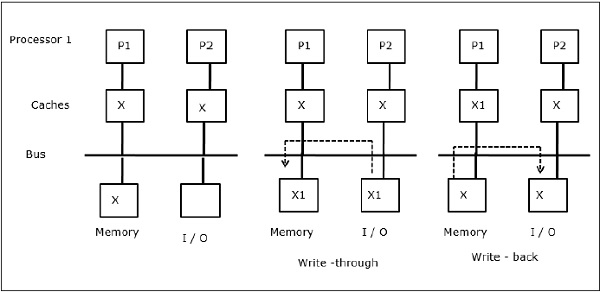
如圖所示,I/O裝置新增到雙處理器多處理器體系結構中的總線上。開始時,兩個快取都包含資料元素X。當I/O裝置接收新的元素X時,它直接將新元素儲存到主記憶體中。現在,當P1或P2(假設為P1)嘗試讀取元素X時,它會獲得過時的副本。因此,P1寫入元素X。現在,如果I/O設備嘗試傳輸X,它會獲得過時的副本。
統一記憶體訪問(UMA)
統一記憶體訪問(UMA)體系結構意味著共享記憶體對於系統中的所有處理器都是相同的。常用的UMA機器類別(用於(檔案)伺服器)是所謂的對稱多處理器(SMP)。在SMP中,所有系統資源(如記憶體、磁碟、其他I/O裝置等)都可以由處理器以統一的方式訪問。
非統一記憶體訪問(NUMA)
在NUMA體系結構中,有多個具有內部間接/共享網路的SMP叢集,它們連線在可擴充套件的訊息傳遞網路中。因此,NUMA體系結構在邏輯上是共享的,在物理上是分散式記憶體體系結構。
在NUMA機器中,處理器的快取控制器確定記憶體引用是本地於SMP的記憶體還是遠端的。為了減少遠端記憶體訪問的數量,NUMA體系結構通常應用可以快取遠端資料的快取處理器。但是當涉及快取時,需要維護快取一致性。因此,這些系統也稱為CC-NUMA(快取一致性NUMA)。
僅快取記憶體體系結構(COMA)
COMA機器類似於NUMA機器,唯一的區別是COMA機器的主記憶體充當直接對映或組相聯快取。資料塊根據其地址雜湊到DRAM快取中的位置。遠端獲取的資料實際上儲存在本地主記憶體中。此外,資料塊沒有固定的儲存位置,它們可以自由地在系統中移動。
COMA體系結構大多具有分層的訊息傳遞網路。此類樹中的交換機包含一個目錄,其資料元素作為其子樹。由於資料沒有儲存位置,因此必須顯式地搜尋它。這意味著遠端訪問需要沿著樹中的交換機進行遍歷以搜尋其目錄中所需的資料。因此,如果網路中的交換機從其子樹接收到對同一資料的多個請求,它會將它們組合成單個請求,然後將其傳送到交換機的父節點。當請求的資料返回時,交換機會將其多個副本傳送到其子樹。
COMA與CC-NUMA
以下是COMA和CC-NUMA的區別。
COMA往往比CC-NUMA更靈活,因為COMA無需作業系統即可透明地支援資料的遷移和複製。
COMA機器的構建成本高且複雜,因為它們需要非標準的記憶體管理硬體,並且一致性協議更難實現。
COMA中的遠端訪問通常比CC-NUMA中的遠端訪問慢,因為需要遍歷樹網路才能找到資料。