
- 作業系統教程
- 作業系統 - 首頁
- 作業系統 - 需求
- 作業系統 - 概述
- 作業系統 - 歷史
- 作業系統 - 組成部分
- 作業系統 - 結構
- 作業系統 - 架構
- 作業系統 - 服務
- 作業系統 - 屬性
- 作業系統 - TAT & WAT
- 作業系統程序
- 作業系統 - 程序
- 作業系統 - 程序排程
- 作業系統 - 排程演算法
- 先來先服務 (FCFS) 排程演算法
- 最短作業優先 (SJF) 排程演算法
- 輪詢 (Round Robin) 排程演算法
- 最高響應比優先 (HRRN) 排程演算法
- 優先順序排程演算法
- 多級佇列排程
- 上下文切換
- 程序操作
- 彩票程序排程
- SJF 排程中突發時間的預測
- 競爭條件漏洞
- 臨界區同步
- 互斥同步
- 程序控制塊
- 程序間通訊
- 搶佔式和非搶佔式排程
- 作業系統同步
- 程序同步
- 作業系統記憶體管理
- 作業系統 - 記憶體管理
- 作業系統 - 虛擬記憶體
- 作業系統儲存管理
- 作業系統 - 檔案系統
- 作業系統型別
- 作業系統 - 型別
- 作業系統雜項
- 作業系統 - 多執行緒
- 作業系統 - I/O 硬體
- 作業系統 - I/O 軟體
- 作業系統 - 安全
- 作業系統 - Linux
- 考試題庫及答案
- 考試題庫及答案
- 作業系統有用資源
- 作業系統 - 快速指南
- 作業系統 - 有用資源
- 作業系統 - 討論
SJF 排程中突發時間的預測
在許多排程策略中,排程程式的效率取決於對 CPU 程序突發時間的準確預測。
讓我們考慮最短作業優先 (SJF) 演算法的例子,這是吞吐量最高、等待時間最短的最優策略。SJF 按照程序突發大小的遞增順序分配 CPU。我們觀察到,它假設在執行之前可以獲得程序的突發大小。
然而,沒有任何程序能夠預先宣告其 CPU 突發時間,因為它是一個動態變化的引數,在很大程度上取決於計算機的硬體。如果無法獲得正確的突發時間,則排程策略將失敗。這種情況也發生在最高響應比優先 (HRRN) 和最短剩餘時間優先 (SRTN) 演算法中。
為了使這些排程策略能夠用於 CPU 程序排程,一個解決方案是預測 CPU 程序的突發時間。在本主題中,我們將討論各種預測突發時間的技術。
預測程序突發時間的技術
可以使用傳統技術或機器學習方法找到程序的突發時間。在傳統技術中,預測是基於已經完成的程序的突發時間進行的,可以使用靜態或動態演算法。下圖描述了不同的方法:
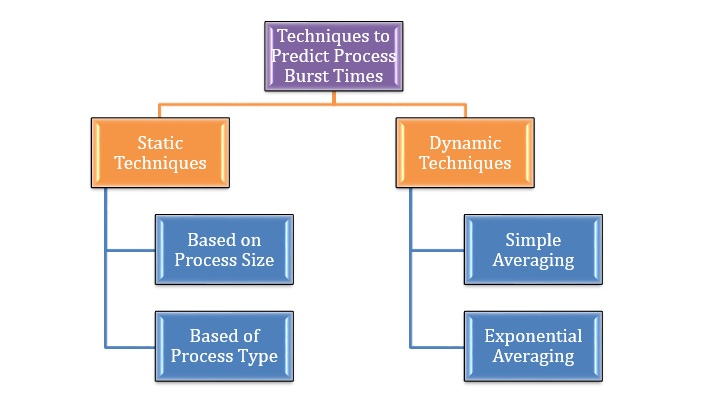
靜態技術
這些技術基於已完成程序的一些啟發式策略進行計算。然而,這些策略並不十分準確,因此可靠性較低。
預測 CPU 突發時間的兩種傳統的靜態技術啟發式方法基於程序大小和程序型別,如下所述:
基於程序大小
在這種情況下考慮的啟發式引數是程序大小。啟發式方法是:“大小相似的程序的突發時間相似”。因此,當程序進入系統時,會考慮分配給該程序的總記憶體空間。考慮過去大小相似的程序的突發時間。由此預測新程序的突發時間。
例如,假設一個大小為 250KB 的程序已到達系統。歷史資料中有五個程序 P1 到 P5,引數如下:
- P1 大小為 100 KB,執行時間為 4 毫秒
- P2 大小為 375 KB,執行時間為 10 毫秒
- P3 大小為 170 KB,執行時間為 5 毫秒
- P4 大小為 245 KB,執行時間為 7 毫秒
- P5 大小為 500 KB,執行時間為 15 毫秒
可以看出,新程序的大小最接近 P4。因此,根據這種程序大小啟發式方法,預測的突發時間為 7 毫秒。
基於程序型別
在這裡,啟發式方法是:“型別相似的程序的突發時間相似”。程序可以是系統程序、使用者程序、即時程序、互動式程序等等。當一個新程序進入系統時,確定程序的型別並據此預測其突發時間。
例如,假設一個系統根據程序型別具有以下近似的突發時間:
- 核心程序的突發時間:4 毫秒
- 前臺程序的突發時間:14 毫秒
- 互動式程序的突發時間:8 毫秒
- 後臺程序的突發時間:20 毫秒
如果核心程序到達此係統,則根據程序型別啟發式方法,其突發時間將預測為 4 毫秒。
動態技術
動態技術將程序的歷史視為時間序列,並將下一個程序的突發時間預測為過去程序的函式。兩種傳統的動態方法使用簡單平均和指數平均,解釋如下:
簡單平均
在這種方法中,下一個程序的突發時間是系統中所有程序的突發時間的簡單平均值。
數學上,假設系統中有 n 個程序 P1, P2, P3,…… Pn,其突發時間為 t1, t2, t3,…… tn,則佇列中下一個程序的突發時間由下式給出:
$$\mathrm{t_{n+1} \: = \: \frac{1}{n}\displaystyle\sum\limits_{i=1}^n t_{i}}$$
例如,假設系統中之前有 5 個程序,其突發時間分別為 4、6、7、5 和 3 毫秒。下一個程序的突發時間將是 (4 + 6 + 7 + 5 + 3) / 5 = 5ms。
指數平均
這是對簡單平均的改進,因為它對近期歷史和過去歷史賦予優先權重。這裡,定義一個平滑因子 α (0 ≤ α ≤ 1) 來給出相對權重。預測的突發時間 τ(n+1) 定義為:
$$\mathrm{\tau_{n+1} \: = \: \alpha t_{n} \: + \: (1 - \alpha)\tau_{n}}$$
其中,tn 是 Pn 的實際突發時間,τn 是之前的預測突發時間。我們可以透過代入 τn 的後續值來展開此公式,得到:
$$\mathrm{\tau_{n+1} \: = \: \alpha t_{n} \: + \: (1 - \alpha) \alpha t_{n-1} \: + \: (1-\alpha)^{2} \alpha t_{n-2} \: + \: \cdots \: + \: (1-\alpha)^{j} \alpha t_{n-j} \: + \: (1- \alpha)^{n}T_{0}}$$
需要注意的是,如果 α 的值為 0,則近期歷史對預測沒有影響,如果 α 為 1,則預測的突發時間等於最近的突發時間。
預測 CPU 突發時間的先進技術
儘管所述動態技術比靜態方法預測得更好,但準確性仍然實用,可以滿足不斷增長的系統需求。可以使用更先進的技術來獲得更準確的結果,例如基於統計和模式的方法、基於模糊邏輯的方法和基於機器學習的方法。
基於馬爾可夫過程的方法
這是一個統計模型,它分析 CPU 突發時間隨時間的變化模式,並以一定的置信度預測下一個 CPU 時間。馬爾可夫模型探索區域性性原理,並擬合曆史資料以獲得結果。
基於模糊邏輯的方法
這是使用模糊邏輯系統改進指數平均技術的一種方法。它將之前的兩次 CPU 突發時間預測作為輸入提供給模糊資訊系統 (FIS),然後 FIS 給出輸出。
基於機器學習的方法
機器學習方法提供了 CPU 突發時間預測的最佳結果之一。它們分析來自其 PCB 的程序資料集,並透過選擇適當數量的特徵(即程序的屬性)來設計特徵向量。然後,它使用支援向量機 (SVM)、K 近鄰、隨機森林、人工神經網路、決策樹和 XGBoost 等演算法來預測未來值。