- OpenNLP 教程
- OpenNLP - 首頁
- OpenNLP - 概述
- OpenNLP - 環境配置
- OpenNLP - 參考 API
- OpenNLP - 句子檢測
- OpenNLP - 分詞
- 命名實體識別
- OpenNLP - 詞性標註
- OpenNLP - 句子解析
- OpenNLP - 句子組塊
- OpenNLP - 命令列介面
- OpenNLP 有用資源
- OpenNLP 快速指南
- OpenNLP - 有用資源
- OpenNLP - 討論
OpenNLP 快速指南
OpenNLP - 概述
NLP 是一套用於從自然語言來源(例如網頁和文字文件)中提取有意義和有用資訊的工具。
什麼是 OpenNLP?
Apache OpenNLP 是一個開源的 Java 庫,用於處理自然語言文字。您可以使用此庫構建高效的文字處理服務。
OpenNLP 提供的服務包括分詞、句子分割、詞性標註、命名實體提取、組塊、解析和共指消解等。
OpenNLP 的特性
以下是 OpenNLP 的顯著特性:
命名實體識別 (NER) - OpenNLP 支援 NER,您可以使用它即使在處理查詢時也能提取地點、人物和事物的名稱。
摘要 - 使用摘要功能,您可以總結 NLP 中的段落、文章、文件或它們的集合。
搜尋 - 在 OpenNLP 中,即使給定的單詞被更改或拼寫錯誤,也可以在給定的文字中識別給定的搜尋字串或其同義詞。
標註 (POS) - NLP 中的標註用於將文字分解成各種語法元素以進行進一步分析。
翻譯 - 在 NLP 中,翻譯有助於將一種語言翻譯成另一種語言。
資訊分組 - NLP 中的此選項將文件內容中的文字資訊分組,就像詞性一樣。
自然語言生成 - 它用於從資料庫生成資訊並自動化資訊報告,例如天氣分析或醫療報告。
反饋分析 - 顧名思義,NLP 收集了人們關於產品的各種反饋,以分析產品在贏得他們芳心的成功程度。
語音識別 - 雖然分析人類語音很困難,但 NLP 有一些內建功能可以滿足此要求。
OpenNLP API
Apache OpenNLP 庫提供類和介面來執行各種自然語言處理任務,例如句子檢測、分詞、查詢名稱、詞性標註、句子組塊、解析、共指消解和文件分類。
除了這些任務外,我們還可以為任何這些任務訓練和評估我們自己的模型。
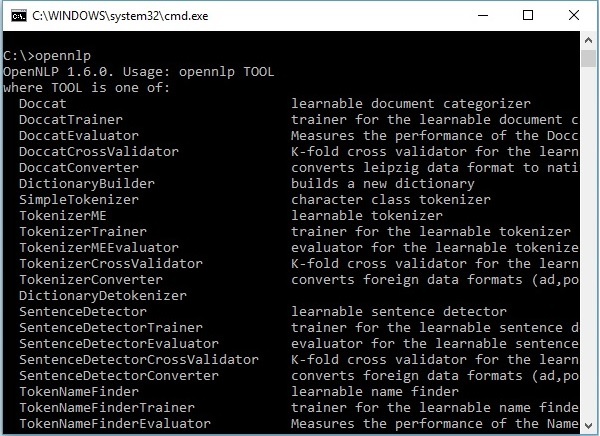
OpenNLP 命令列介面 (CLI)
除了庫之外,OpenNLP 還提供了一個命令列介面 (CLI),我們可以在其中訓練和評估模型。我們將在本教程的最後一章詳細討論這個主題。
OpenNLP 模型
為了執行各種 NLP 任務,OpenNLP 提供了一組預定義的模型。此集合包含針對不同語言的模型。
下載模型
您可以按照以下步驟下載 OpenNLP 提供的預定義模型。
步驟 1 - 點選以下連結開啟 OpenNLP 模型的索引頁面:http://opennlp.sourceforge.net/models-1.5/。
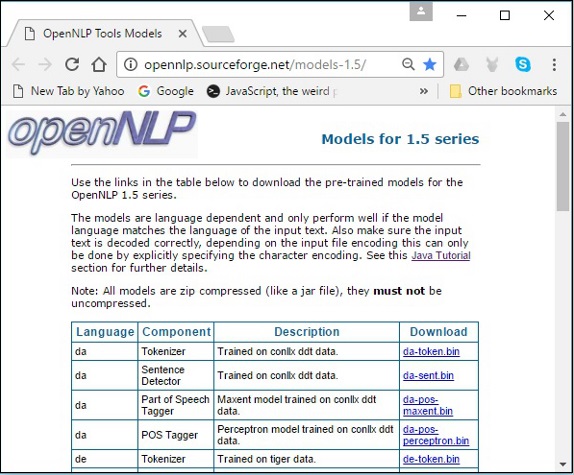
步驟 2 - 訪問給定連結後,您將看到各種語言的元件列表及其下載連結。在這裡,您可以獲取 OpenNLP 提供的所有預定義模型的列表。
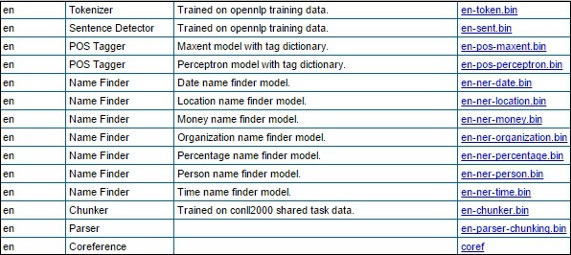
透過點選各自的連結,將所有這些模型下載到C:/OpenNLP_models/>資料夾中。所有這些模型都依賴於語言,使用這些模型時,您必須確保模型語言與輸入文字的語言匹配。
OpenNLP 的歷史
2010 年,OpenNLP 進入 Apache 孵化器。
2011 年,Apache OpenNLP 1.5.2 孵化版釋出,同年畢業成為頂級 Apache 專案。
2015 年,OpenNLP 1.6.0 釋出。
OpenNLP - 環境配置
在本節中,我們將討論如何在您的系統中設定 OpenNLP 環境。讓我們從安裝過程開始。
安裝 OpenNLP
以下是將Apache OpenNLP 庫下載到您的系統的步驟。
步驟 1 - 點選以下連結開啟Apache OpenNLP的主頁:https://opennlp.apache.org/。
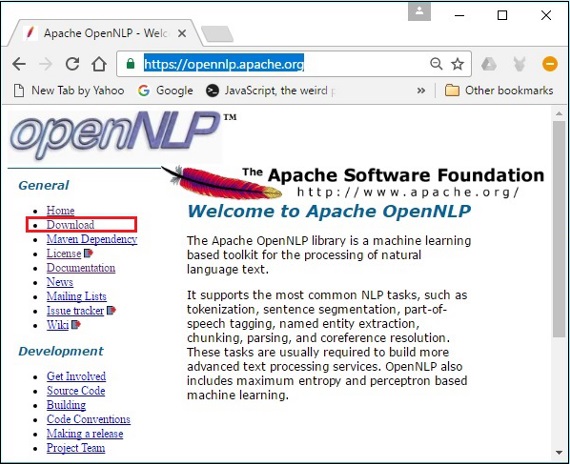
步驟 2 - 現在,點選下載連結。點選後,您將被定向到一個頁面,您可以在其中找到各種映象,這些映象將重定向您到 Apache 軟體基金會分發目錄。
步驟 3 - 在此頁面中,您可以找到下載各種 Apache 分發的連結。瀏覽它們並找到 OpenNLP 分發版並點選它。
步驟 4 - 點選後,您將被重定向到一個目錄,您可以在其中看到 OpenNLP 分發的索引,如下所示。
從可用的分發版中點選最新版本。
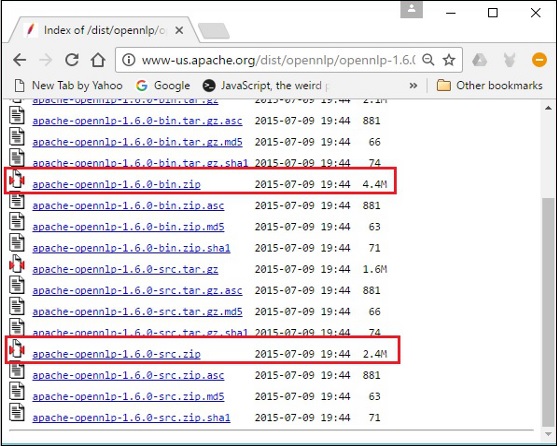
步驟 5 - 每個分發版都提供各種格式的 OpenNLP 庫的原始檔和二進位制檔案。下載原始檔和二進位制檔案,apache-opennlp-1.6.0-bin.zip 和 apache-opennlp1.6.0-src.zip(適用於 Windows)。
設定類路徑
下載 OpenNLP 庫後,您需要將其路徑設定為bin目錄。假設您已將 OpenNLP 庫下載到系統的 E 盤。
現在,按照以下步驟操作:
步驟 1 - 右鍵單擊“我的電腦”並選擇“屬性”。
步驟 2 - 在“高階”選項卡下點選“環境變數”按鈕。
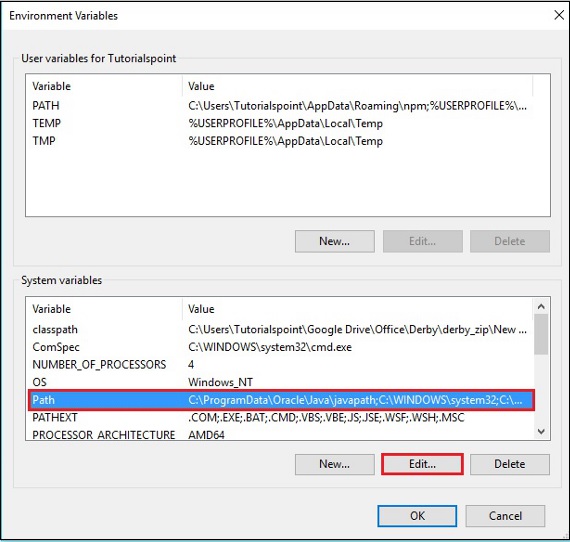
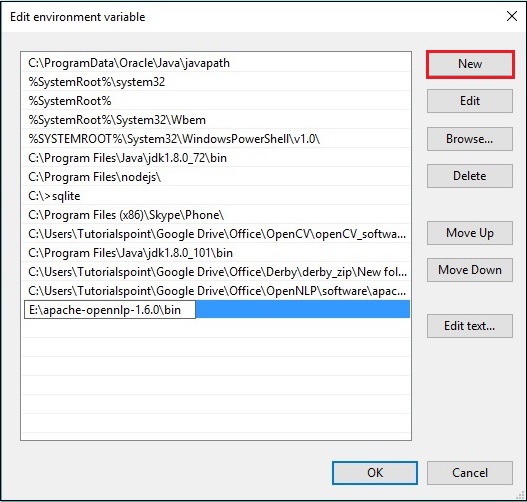
步驟 3 - 選擇path變數並點選編輯按鈕,如下圖所示。
步驟 4 - 在“編輯環境變數”視窗中,點選新建按鈕並新增 OpenNLP 目錄的路徑E:\apache-opennlp-1.6.0\bin,然後點選確定按鈕,如下圖所示。
Eclipse 安裝
您可以透過將構建路徑設定為 JAR 檔案或使用pom.xml來設定 OpenNLP 庫的 Eclipse 環境。
將構建路徑設定為 JAR 檔案
按照以下步驟在 Eclipse 中安裝 OpenNLP:
步驟 1 - 確保您的系統中已安裝 Eclipse 環境。
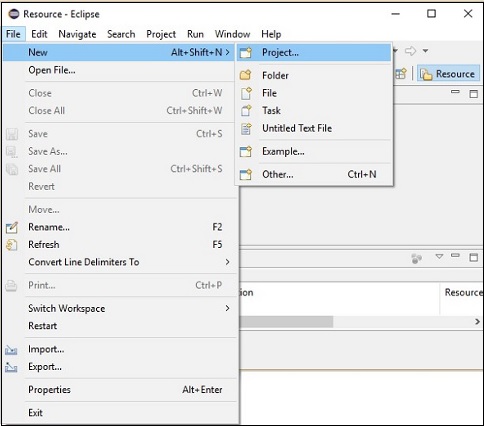
步驟 2 - 開啟 Eclipse。點選檔案 → 新建 → 開啟一個新專案,如下所示。
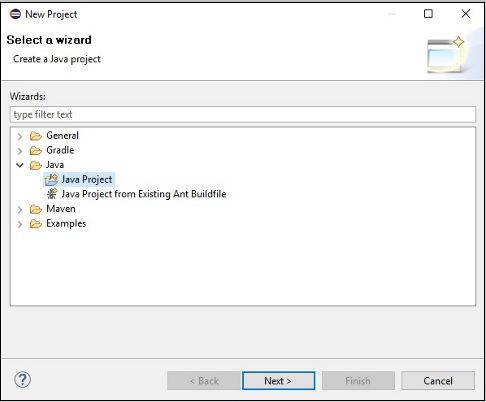
步驟 3 - 您將獲得新建專案嚮導。在此嚮導中,選擇 Java 專案,然後點選下一步按鈕繼續。
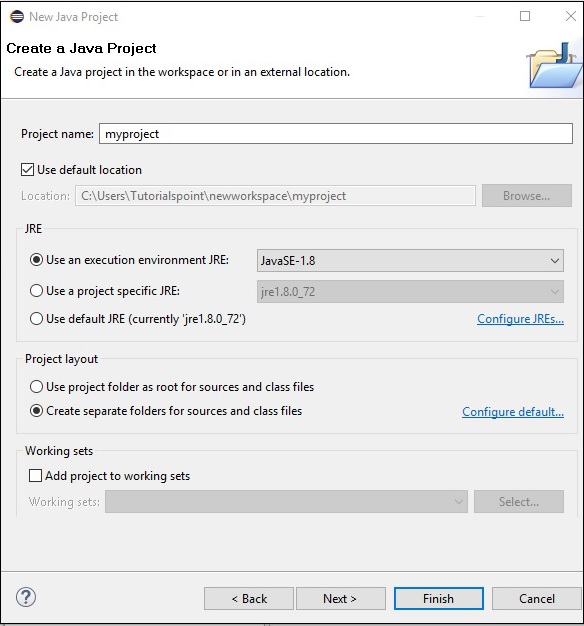
步驟 4 - 接下來,您將獲得新建 Java 專案嚮導。在這裡,您需要建立一個新專案並點選下一步按鈕,如下所示。
步驟 5 - 建立新專案後,右鍵單擊它,選擇構建路徑,然後點選配置構建路徑。
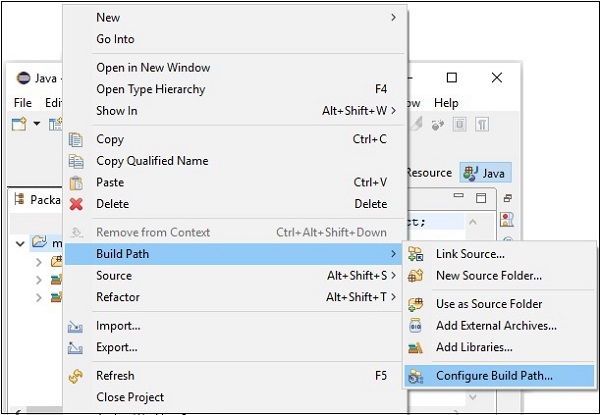
步驟 6 - 接下來,您將獲得Java 構建路徑嚮導。在這裡,點選新增外部 JARs按鈕,如下所示。
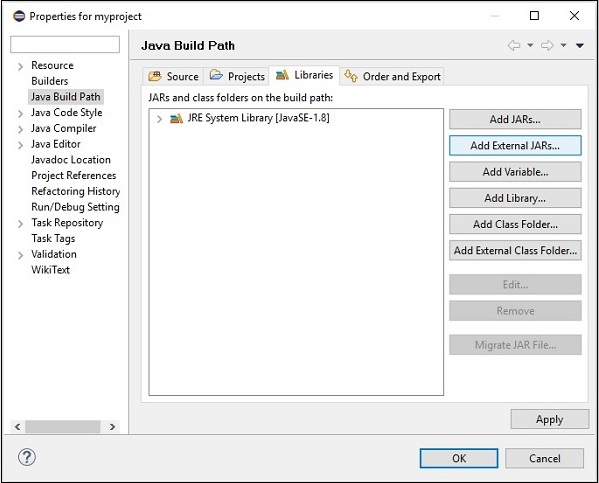
步驟 7 - 選擇位於apache-opennlp-1.6.0資料夾的lib資料夾中的 jar 檔案opennlp-tools-1.6.0.jar和opennlp-uima-1.6.0.jar。
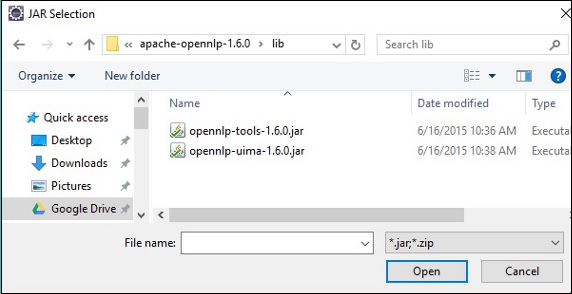
在上面螢幕中點選開啟按鈕,所選檔案將新增到您的庫中。
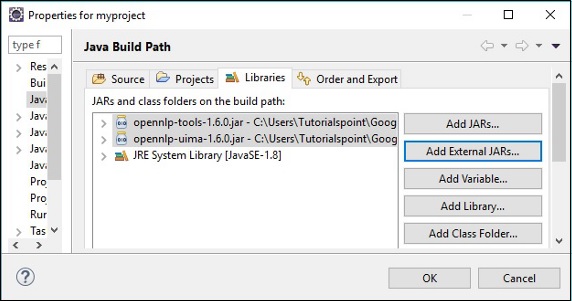
點選確定,您將成功地將所需的 JAR 檔案新增到當前專案中,您可以透過展開“引用庫”來驗證這些已新增的庫,如下所示。
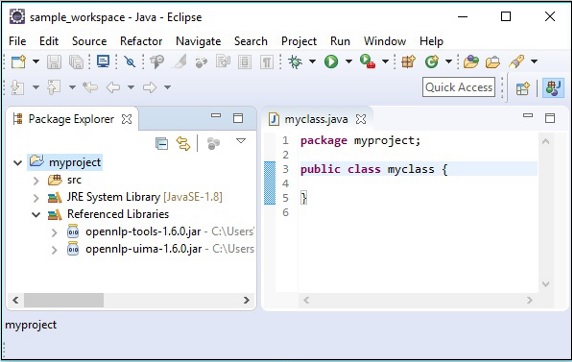
使用 pom.xml
將專案轉換為 Maven 專案並將以下程式碼新增到其pom.xml中。
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>myproject</groupId>
<artifactId>myproject</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-tools</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-uima</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>
</project>
OpenNLP - 參考 API
在本節中,我們將討論在本教程後續章節中將使用的類和方法。
句子檢測
SentenceModel 類
此類表示用於檢測給定原始文字中句子的預定義模型。此類屬於包opennlp.tools.sentdetect。
此類的建構函式接受句子檢測模型檔案 (en-sent.bin) 的InputStream物件。
SentenceDetectorME 類
此類屬於包opennlp.tools.sentdetect,它包含用於將原始文字分割成句子 的方法。此類使用最大熵模型來評估字串中的句子結束字元,以確定它們是否表示句子的結尾。
以下是此類的重要方法。
| 序號 | 方法和說明 |
|---|---|
| 1 |
sentDetect() 此方法用於檢測傳遞給它的原始文字中的句子。它接受一個 String 變數作為引數,並返回一個 String 陣列,其中包含給定原始文字中的句子。 |
| 2 |
sentPosDetect() 此方法用於檢測給定文字中句子的位置。此方法接受一個表示句子的字串變數,並返回一個型別為Span的物件陣列。 名為Span的opennlp.tools.util包中的類用於儲存集合的開始和結束整數。 |
| 3 |
getSentenceProbabilities() 此方法返回與最近對sentDetect()方法的呼叫相關的機率。 |
分詞
TokenizerModel 類
此類表示用於對給定句子進行分詞的預定義模型。此類屬於包opennlp.tools.tokenizer。
此類的建構函式接受分詞模型檔案 (entoken.bin) 的InputStream物件。
類
為了執行分詞,OpenNLP 庫提供了三個主要的類。所有這三個類都實現了名為Tokenizer的介面。
| 序號 | 類和說明 |
|---|---|
| 1 |
SimpleTokenizer 此類使用字元類對給定的原始文字進行分詞。 |
| 2 |
WhitespaceTokenizer 此類使用空格對給定的文字進行分詞。 |
| 3 |
TokenizerME 此類將原始文字轉換為單獨的標記。它使用最大熵來做出決定。 |
這些類包含以下方法。
| 序號 | 方法和說明 |
|---|---|
| 1 |
tokenize() 此方法用於對原始文字進行分詞。此方法接受一個 String 變數作為引數,並返回一個 String 陣列(標記)。 |
| 2 |
sentPosDetect() 此方法用於獲取標記的位置或跨度。它以字串形式接受句子(或)原始文字,並返回一個型別為Span的物件陣列。 |
除了上述兩種方法外,TokenizerME類還具有getTokenProbabilities()方法。
| 序號 | 方法和說明 |
|---|---|
| 1 |
getTokenProbabilities() 此方法用於獲取與最近對tokenizePos()方法的呼叫相關的機率。 |
命名實體識別
TokenNameFinderModel 類
此類表示用於查詢給定句子中命名實體的預定義模型。此類屬於包opennlp.tools.namefind。
此類的建構函式接受名稱查詢模型檔案 (enner-person.bin) 的InputStream物件。
NameFinderME 類
該類屬於包opennlp.tools.namefind,包含執行命名實體識別 (NER) 任務的方法。此類使用最大熵模型來查詢給定原始文字中的命名實體。
| 序號 | 方法和說明 |
|---|---|
| 1 |
find() 此方法用於檢測原始文字中的命名實體。它接受一個表示原始文字的字串變數作為引數,並返回一個Span型別物件的陣列。 |
| 2 |
probs() 此方法用於獲取最後解碼序列的機率。 |
詞性標註
POSModel 類
此類表示預定義模型,用於標註給定句子的詞性。此類屬於包opennlp.tools.postag。
此類的建構函式接受詞性標註模型檔案 (enpos-maxent.bin) 的InputStream物件。
POSTaggerME 類
此類屬於包opennlp.tools.postag,用於預測給定原始文字的詞性。它使用最大熵模型進行決策。
| 序號 | 方法和說明 |
|---|---|
| 1 |
tag() 此方法用於為句子的標記分配詞性標籤。此方法接受一個標記(字串)陣列作為引數,並返回一個標籤陣列。 |
| 2 |
getSentenceProbabilities() 此方法用於獲取最近標註句子的每個標籤的機率。 |
句子解析
ParserModel 類
此類表示預定義模型,用於解析給定句子。此類屬於包opennlp.tools.parser。
此類的建構函式接受解析器模型檔案 (en-parserchunking.bin) 的InputStream物件。
Parser Factory 類
此類屬於包opennlp.tools.parser,用於建立解析器。
| 序號 | 方法和說明 |
|---|---|
| 1 |
create() 這是一個靜態方法,用於建立解析器物件。此方法接受解析器模型檔案的Filestream物件。 |
ParserTool 類
此類屬於opennlp.tools.cmdline.parser包,用於解析內容。
| 序號 | 方法和說明 |
|---|---|
| 1 |
parseLine() ParserTool類的此方法用於在OpenNLP中解析原始文字。此方法接受:
|
分塊
ChunkerModel 類
此類表示預定義模型,用於將句子分成較小的塊。此類屬於包opennlp.tools.chunker。
此類的建構函式接受分塊模型檔案 (enchunker.bin) 的InputStream物件。
ChunkerME 類
此類屬於名為opennlp.tools.chunker的包,用於將給定句子分成較小的塊。
| 序號 | 方法和說明 |
|---|---|
| 1 |
chunk() 此方法用於將給定句子分成較小的塊。它接受句子的標記和詞性標籤作為引數。 |
| 2 |
probs() 此方法返回最後解碼序列的機率。 |
OpenNLP - 句子檢測
在處理自然語言時,確定句子的開始和結束是一個需要解決的問題。此過程稱為句子邊界消歧 (SBD) 或簡單的句子分割。
我們用於檢測給定文字中句子的技術取決於文字的語言。
使用Java進行句子檢測
我們可以使用正則表示式和一組簡單的規則在Java中檢測給定文字中的句子。
例如,讓我們假設句點、問號或感嘆號在給定文字中表示句子的結尾,那麼我們可以使用String類的split()方法分割句子。在這裡,我們必須以字串格式傳遞正則表示式。
以下是使用Java正則表示式(split方法)確定給定文字中句子的程式。將此程式儲存到名為SentenceDetection_RE.java的檔案中。
public class SentenceDetection_RE {
public static void main(String args[]){
String sentence = " Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
String simple = "[.?!]";
String[] splitString = (sentence.split(simple));
for (String string : splitString)
System.out.println(string);
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案。
javac SentenceDetection_RE.java java SentenceDetection_RE
執行後,上述程式將建立一個PDF文件,顯示以下訊息。
Hi How are you Welcome to Tutorialspoint We provide free tutorials on various technologies
使用OpenNLP進行句子檢測
為了檢測句子,OpenNLP使用一個預定義模型,一個名為en-sent.bin的檔案。此預定義模型經過訓練,可以檢測給定原始文字中的句子。
opennlp.tools.sentdetect包包含用於執行句子檢測任務的類和介面。
要使用OpenNLP庫檢測句子,您需要:
使用SentenceModel類載入en-sent.bin模型
例項化SentenceDetectorME類。
使用此類的sentDetect()方法檢測句子。
以下是編寫檢測給定原始文字中句子的程式需要遵循的步驟。
步驟1:載入模型
句子檢測模型由名為SentenceModel的類表示,該類屬於opennlp.tools.sentdetect包。
要載入句子檢測模型:
建立模型的InputStream物件(例項化FileInputStream並將模型路徑以字串格式傳遞給其建構函式)。
例項化SentenceModel類,並將模型的InputStream(物件)作為引數傳遞給其建構函式,如下面的程式碼塊所示:
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/ensent.bin");
SentenceModel model = new SentenceModel(inputStream);
步驟2:例項化SentenceDetectorME類
opennlp.tools.sentdetect包中的SentenceDetectorME類包含將原始文字分割成句子方法。此類使用最大熵模型來評估字串中的句子結束字元,以確定它們是否表示句子的結尾。
例項化此類,並將上一步中建立的模型物件作為引數傳遞,如下所示。
//Instantiating the SentenceDetectorME class SentenceDetectorME detector = new SentenceDetectorME(model);
步驟3:檢測句子
SentenceDetectorME類的sentDetect()方法用於檢測傳遞給它的原始文字中的句子。此方法接受一個字串變數作為引數。
透過將句子的字串格式傳遞給此方法來呼叫此方法。
//Detecting the sentence String sentences[] = detector.sentDetect(sentence);
示例
以下是檢測給定原始文字中句子的程式。將此程式儲存到名為SentenceDetectionME.java的檔案中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionME {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac SentenceDetectorME.java java SentenceDetectorME
執行後,上述程式讀取給定的字串並檢測其中的句子,並顯示以下輸出。
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies
檢測句子的位置
我們還可以使用SentenceDetectorME類的sentPosDetect()方法檢測句子的位置。
以下是編寫檢測給定原始文字中句子位置的程式需要遵循的步驟。
步驟1:載入模型
句子檢測模型由名為SentenceModel的類表示,該類屬於opennlp.tools.sentdetect包。
要載入句子檢測模型:
建立模型的InputStream物件(例項化FileInputStream並將模型路徑以字串格式傳遞給其建構函式)。
例項化SentenceModel類,並將模型的InputStream(物件)作為引數傳遞給其建構函式,如下面的程式碼塊所示。
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
步驟2:例項化SentenceDetectorME類
opennlp.tools.sentdetect包中的SentenceDetectorME類包含將原始文字分割成句子方法。此類使用最大熵模型來評估字串中的句子結束字元,以確定它們是否表示句子的結尾。
例項化此類,並將上一步中建立的模型物件作為引數傳遞。
//Instantiating the SentenceDetectorME class SentenceDetectorME detector = new SentenceDetectorME(model);
步驟3:檢測句子的位置
SentenceDetectorME類的sentPosDetect()方法用於檢測傳遞給它的原始文字中句子的位置。此方法接受一個字串變數作為引數。
透過將句子的字串格式作為引數傳遞給此方法來呼叫此方法。
//Detecting the position of the sentences in the paragraph Span[] spans = detector.sentPosDetect(sentence);
步驟4:列印句子的範圍
SentenceDetectorME類的sentPosDetect()方法返回一個Span型別物件的陣列。opennlp.tools.util包中名為Span的類用於儲存集合的開始和結束整數。
您可以將sentPosDetect()方法返回的範圍儲存在Span陣列中並列印它們,如下面的程式碼塊所示。
//Printing the sentences and their spans of a sentence for (Span span : spans) System.out.println(paragraph.substring(span);
示例
以下是檢測給定原始文字中句子的程式。將此程式儲存到名為SentenceDetectionME.java的檔案中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencePosDetection {
public static void main(String args[]) throws Exception {
String paragraph = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the raw text
Span spans[] = detector.sentPosDetect(paragraph);
//Printing the spans of the sentences in the paragraph
for (Span span : spans)
System.out.println(span);
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac SentencePosDetection.java java SentencePosDetection
執行後,上述程式讀取給定的字串並檢測其中的句子,並顯示以下輸出。
[0..16) [17..43) [44..93)
句子及其位置
String類的substring()方法接受開始和結束偏移量並返回相應的字串。我們可以使用此方法來一起列印句子及其範圍(位置),如下面的程式碼塊所示。
for (Span span : spans) System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);
以下是檢測給定原始文字中的句子並顯示它們及其位置的程式。將此程式儲存到名為SentencesAndPosDetection.java的檔案中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencesAndPosDetection {
public static void main(String args[]) throws Exception {
String sen = "Hi. How are you? Welcome to Tutorialspoint."
+ " We provide free tutorials on various technologies";
//Loading a sentence model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the paragraph
Span[] spans = detector.sentPosDetect(sen);
//Printing the sentences and their spans of a paragraph
for (Span span : spans)
System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac SentencesAndPosDetection.java java SentencesAndPosDetection
執行後,上述程式讀取給定的字串並檢測句子及其位置,並顯示以下輸出。
Hi. How are you? [0..16) Welcome to Tutorialspoint. [17..43) We provide free tutorials on various technologies [44..93)
句子機率檢測
SentenceDetectorME類的getSentenceProbabilities()方法返回與最近對sentDetect()方法的呼叫的關聯機率。
//Getting the probabilities of the last decoded sequence double[] probs = detector.getSentenceProbabilities();
以下是列印與對sentDetect()方法的呼叫相關的機率的程式。將此程式儲存到名為SentenceDetectionMEProbs.java的檔案中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionMEProbs {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
//Getting the probabilities of the last decoded sequence
double[] probs = detector.getSentenceProbabilities();
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac SentenceDetectionMEProbs.java java SentenceDetectionMEProbs
執行後,上述程式讀取給定的字串並檢測句子並列印它們。此外,它還返回與最近對sentDetect()方法呼叫的關聯機率,如下所示。
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies 0.9240246995179983 0.9957680129995953 1.0
OpenNLP - 分詞
將給定句子分解成較小的部分(標記)的過程稱為分詞。通常,給定的原始文字是基於一組分隔符(主要是空格)進行分詞的。
分詞用於拼寫檢查、處理搜尋、識別詞性、句子檢測、文件分類等任務。
使用OpenNLP進行分詞
opennlp.tools.tokenize包包含用於執行分詞的類和介面。
為了將給定的句子分解成更簡單的片段,OpenNLP庫提供了三個不同的類:
SimpleTokenizer - 此類使用字元類對給定的原始文字進行分詞。
WhitespaceTokenizer - 此類使用空格對給定的文字進行分詞。
TokenizerME - 此類將原始文字轉換成單獨的標記。它使用最大熵模型進行決策。
SimpleTokenizer
要使用SimpleTokenizer類對句子進行分詞,您需要:
建立一個相應類的物件。
使用tokenize()方法對句子進行分詞。
列印分詞結果。
以下是編寫程式對給定原始文字進行分詞的步驟。
步驟 1 − 例項化相應類
在這兩個類中,都沒有可用的建構函式來例項化它們。因此,我們需要使用靜態變數INSTANCE來建立這些類的物件。
SimpleTokenizer tokenizer = SimpleTokenizer.INSTANCE;
步驟 2 − 對句子進行分詞
這兩個類都包含一個名為tokenize()的方法。此方法接受字串格式的原始文字。呼叫此方法時,它會對給定的字串進行分詞,並返回一個字串陣列(分詞結果)。
使用tokenizer()方法對句子進行分詞,如下所示。
//Tokenizing the given sentence String tokens[] = tokenizer.tokenize(sentence);
步驟 3 − 列印分詞結果
對句子進行分詞後,您可以使用for迴圈列印分詞結果,如下所示。
//Printing the tokens for(String token : tokens) System.out.println(token);
示例
以下是使用SimpleTokenizer類對給定句子進行分詞的程式。將此程式儲存到名為SimpleTokenizerExample.java的檔案中。
import opennlp.tools.tokenize.SimpleTokenizer;
public class SimpleTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Tokenizing the given sentence
String tokens[] = simpleTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens) {
System.out.println(token);
}
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac SimpleTokenizerExample.java java SimpleTokenizerExample
執行上述程式後,程式會讀取給定的字串(原始文字),對其進行分詞,並顯示以下輸出:
Hi . How are you ? Welcome to Tutorialspoint . We provide free tutorials on various technologies
WhitespaceTokenizer
要使用WhitespaceTokenizer類對句子進行分詞,您需要:
建立一個相應類的物件。
使用tokenize()方法對句子進行分詞。
列印分詞結果。
以下是編寫程式對給定原始文字進行分詞的步驟。
步驟 1 − 例項化相應類
在這兩個類中,都沒有可用的建構函式來例項化它們。因此,我們需要使用靜態變數INSTANCE來建立這些類的物件。
WhitespaceTokenizer tokenizer = WhitespaceTokenizer.INSTANCE;
步驟 2 − 對句子進行分詞
這兩個類都包含一個名為tokenize()的方法。此方法接受字串格式的原始文字。呼叫此方法時,它會對給定的字串進行分詞,並返回一個字串陣列(分詞結果)。
使用tokenizer()方法對句子進行分詞,如下所示。
//Tokenizing the given sentence String tokens[] = tokenizer.tokenize(sentence);
步驟 3 − 列印分詞結果
對句子進行分詞後,您可以使用for迴圈列印分詞結果,如下所示。
//Printing the tokens for(String token : tokens) System.out.println(token);
示例
以下是使用WhitespaceTokenizer類對給定句子進行分詞的程式。將此程式儲存到名為WhitespaceTokenizerExample.java的檔案中。
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class WhitespaceTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating whitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Tokenizing the given paragraph
String tokens[] = whitespaceTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens)
System.out.println(token);
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac WhitespaceTokenizerExample.java java WhitespaceTokenizerExample
執行上述程式後,程式會讀取給定的字串(原始文字),對其進行分詞,並顯示以下輸出。
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies
TokenizerME類
OpenNLP也使用預定義模型(名為de-token.bin的檔案)對句子進行分詞。它經過訓練,可以對給定原始文字中的句子進行分詞。
opennlp.tools.tokenizer包的TokenizerME類用於載入此模型,並使用OpenNLP庫對給定的原始文字進行分詞。為此,您需要:
使用TokenizerModel類載入en-token.bin模型。
例項化TokenizerME類。
使用此類的tokenize()方法對句子進行分詞。
以下是使用TokenizerME類對給定原始文字中的句子進行分詞的程式步驟。
步驟 1 − 載入模型
分詞模型由名為TokenizerModel的類表示,該類屬於opennlp.tools.tokenize包。
要載入分詞模型:
建立模型的InputStream物件(例項化FileInputStream並將模型路徑以字串格式傳遞給其建構函式)。
例項化TokenizerModel類,並將模型的InputStream(物件)作為引數傳遞給其建構函式,如下面的程式碼塊所示。
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
步驟 2 − 例項化TokenizerME類
opennlp.tools.tokenize包的TokenizerME類包含將原始文字分割成較小部分(分詞)的方法。它使用最大熵來做出決策。
例項化此類,並將上一步中建立的模型物件作為引數傳遞,如下所示。
//Instantiating the TokenizerME class TokenizerME tokenizer = new TokenizerME(tokenModel);
步驟 3 − 對句子進行分詞
TokenizerME類的tokenize()方法用於對傳遞給它的原始文字進行分詞。此方法接受一個字串變數作為引數,並返回一個字串陣列(分詞結果)。
透過將句子的字串格式傳遞給此方法來呼叫此方法,如下所示。
//Tokenizing the given raw text String tokens[] = tokenizer.tokenize(paragraph);
示例
以下是對給定原始文字進行分詞的程式。將此程式儲存到名為TokenizerMEExample.java的檔案中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
public class TokenizerMEExample {
public static void main(String args[]) throws Exception{
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the given raw text
String tokens[] = tokenizer.tokenize(sentence);
//Printing the tokens
for (String a : tokens)
System.out.println(a);
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac TokenizerMEExample.java java TokenizerMEExample
執行上述程式後,程式會讀取給定的字串,檢測其中的句子,並顯示以下輸出:
Hi . How are you ? Welcome to Tutorialspoint . We provide free tutorials on various technologie
檢索分詞的位置
我們還可以使用tokenizePos()方法獲取分詞的位置或範圍。這是opennlp.tools.tokenize包中Tokenizer介面的方法。由於所有(三個)Tokenizer類都實現了此介面,因此您可以在所有類中找到此方法。
此方法接受字串形式的句子或原始文字,並返回一個型別為Span的物件陣列。
您可以使用tokenizePos()方法獲取分詞的位置,如下所示:
//Retrieving the tokens tokenizer.tokenizePos(sentence);
列印位置(範圍)
名為Span的opennlp.tools.util包中的類用於儲存集合的開始和結束整數。
您可以將tokenizePos()方法返回的範圍儲存在Span陣列中並列印它們,如下面的程式碼塊所示。
//Retrieving the tokens Span[] tokens = tokenizer.tokenizePos(sentence); //Printing the spans of tokens for( Span token : tokens) System.out.println(token);
一起列印分詞及其位置
String類的substring()方法接受起始和結束偏移量,並返回相應的字串。我們可以使用此方法一起列印分詞及其範圍(位置),如下面的程式碼塊所示。
//Printing the spans of tokens for(Span token : tokens) System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
示例(SimpleTokenizer)
以下是使用SimpleTokenizer類檢索原始文字的分詞範圍的程式。它還會列印分詞及其位置。將此程式儲存到名為SimpleTokenizerSpans.java的檔案中。
import opennlp.tools.tokenize.SimpleTokenizer;
import opennlp.tools.util.Span;
public class SimpleTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Retrieving the boundaries of the tokens
Span[] tokens = simpleTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac SimpleTokenizerSpans.java java SimpleTokenizerSpans
執行上述程式後,程式會讀取給定的字串(原始文字),對其進行分詞,並顯示以下輸出:
[0..2) Hi [2..3) . [4..7) How [8..11) are [12..15) you [15..16) ? [17..24) Welcome [25..27) to [28..42) Tutorialspoint [42..43) . [44..46) We [47..54) provide [55..59) free [60..69) tutorials [70..72) on [73..80) various [81..93) technologies
示例(WhitespaceTokenizer)
以下是使用WhitespaceTokenizer類檢索原始文字的分詞範圍的程式。它還會列印分詞及其位置。將此程式儲存到名為WhitespaceTokenizerSpans.java的檔案中。
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class WhitespaceTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Retrieving the tokens
Span[] tokens = whitespaceTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
}
}
使用以下命令從命令提示符編譯並執行儲存的java檔案
javac WhitespaceTokenizerSpans.java java WhitespaceTokenizerSpans
執行上述程式後,程式會讀取給定的字串(原始文字),對其進行分詞,並顯示以下輸出。
[0..3) Hi. [4..7) How [8..11) are [12..16) you? [17..24) Welcome [25..27) to [28..43) Tutorialspoint. [44..46) We [47..54) provide [55..59) free [60..69) tutorials [70..72) on [73..80) various [81..93) technologies
示例(TokenizerME)
以下是使用TokenizerME類檢索原始文字的分詞範圍的程式。它還會列印分詞及其位置。將此程式儲存到名為TokenizerMESpans.java的檔案中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMESpans {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac TokenizerMESpans.java java TokenizerMESpans
執行上述程式後,程式會讀取給定的字串(原始文字),對其進行分詞,並顯示以下輸出:
[0..5) Hello [6..10) John [11..14) how [15..18) are [19..22) you [23..30) welcome [31..33) to [34..48) Tutorialspoint
分詞機率
TokenizerME類的getTokenProbabilities()方法用於獲取與最近對tokenizePos()方法的呼叫的關聯機率。
//Getting the probabilities of the recent calls to tokenizePos() method double[] probs = detector.getSentenceProbabilities();
以下是列印與tokenizePos()方法呼叫相關的機率的程式。將此程式儲存到名為TokenizerMEProbs.java的檔案中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac TokenizerMEProbs.java java TokenizerMEProbs
執行上述程式後,程式會讀取給定的字串,對句子進行分詞並列印它們。此外,它還會返回與最近對tokenizerPos()方法的呼叫的關聯機率。
[0..5) Hello [6..10) John [11..14) how [15..18) are [19..22) you [23..30) welcome [31..33) to [34..48) Tutorialspoint 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
OpenNLP - 命名實體識別
從給定文字中查詢名稱、人物、地點和其他實體的過程稱為命名實體識別 (NER)。本章將討論如何使用OpenNLP庫透過Java程式執行NER。
使用OpenNLP進行命名實體識別
為了執行各種NER任務,OpenNLP使用不同的預定義模型,例如en-ner-date.bin、en-ner-location.bin、en-ner-organization.bin、en-ner-person.bin和en-ner-time.bin。所有這些檔案都是預定義模型,經過訓練可以檢測給定原始文字中的相應實體。
opennlp.tools.namefind包包含用於執行NER任務的類和介面。要使用OpenNLP庫執行NER任務,您需要:
使用TokenNameFinderModel類載入相應的模型。
例項化NameFinder類。
查詢名稱並列印它們。
以下是編寫程式從給定原始文字中檢測命名實體的步驟。
步驟1:載入模型
句子檢測模型由名為TokenNameFinderModel的類表示,該類屬於opennlp.tools.namefind包。
要載入NER模型:
建立模型的InputStream物件(例項化FileInputStream並將相應NER模型的路徑(字串格式)傳遞給其建構函式)。
例項化TokenNameFinderModel類,並將模型的InputStream(物件)作為引數傳遞給其建構函式,如下面的程式碼塊所示。
//Loading the NER-person model
InputStream inputStreamNameFinder = new FileInputStream(".../en-nerperson.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
步驟 2:例項化NameFinderME類
opennlp.tools.namefind包的NameFinderME類包含執行NER任務的方法。此類使用最大熵模型在給定的原始文字中查詢命名實體。
例項化此類,並將上一步中建立的模型物件作為引數傳遞,如下所示:
//Instantiating the NameFinderME class NameFinderME nameFinder = new NameFinderME(model);
步驟 3:查詢句子中的名稱
NameFinderME類的find()方法用於檢測傳遞給它的原始文字中的名稱。此方法接受一個字串變數作為引數。
透過將句子的字串格式傳遞給此方法來呼叫此方法。
//Finding the names in the sentence Span nameSpans[] = nameFinder.find(sentence);
步驟 4:列印句子中名稱的範圍
NameFinderME類的find()方法返回一個型別為Span的物件陣列。opennlp.tools.util包中的Span類用於儲存整數集合的起始和結束位置。
您可以將find()方法返回的範圍儲存在Span陣列中並列印它們,如下面的程式碼塊所示。
//Printing the sentences and their spans of a sentence for (Span span : spans) System.out.println(paragraph.substring(span);
NER示例
以下是讀取給定句子並識別其中人名範圍的程式。將此程式儲存到名為NameFinderME_Example.java的檔案中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.util.Span;
public class NameFinderME_Example {
public static void main(String args[]) throws Exception{
/Loading the NER - Person model InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-ner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStream);
//Instantiating the NameFinder class
NameFinderME nameFinder = new NameFinderME(model);
//Getting the sentence in the form of String array
String [] sentence = new String[]{
"Mike",
"and",
"Smith",
"are",
"good",
"friends"
};
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(sentence);
//Printing the spans of the names in the sentence
for(Span s: nameSpans)
System.out.println(s.toString());
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac NameFinderME_Example.java java NameFinderME_Example
執行上述程式後,程式會讀取給定的字串(原始文字),檢測其中的人名,並顯示它們的位置(範圍),如下所示。
[0..1) person [2..3) person
名稱及其位置
String類的substring()方法接受起始和結束偏移量,並返回相應的字串。我們可以使用此方法一起列印名稱及其範圍(位置),如下面的程式碼塊所示。
for(Span s: nameSpans) System.out.println(s.toString()+" "+tokens[s.getStart()]);
以下是檢測給定原始文字中的名稱並將其與其位置一起顯示的程式。將此程式儲存到名為NameFinderSentences.java的檔案中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class NameFinderSentences {
public static void main(String args[]) throws Exception{
//Loading the tokenizer model
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the sentence in to a string array
String sentence = "Mike is senior programming
manager and Rama is a clerk both are working at
Tutorialspoint";
String tokens[] = tokenizer.tokenize(sentence);
//Loading the NER-person model
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/enner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(tokens);
//Printing the names and their spans in a sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac NameFinderSentences.java java NameFinderSentences
執行上述程式後,程式會讀取給定的字串(原始文字),檢測其中的人名,並顯示它們的位置(範圍),如下所示。
[0..1) person Mike
查詢地點名稱
透過載入各種模型,您可以檢測各種命名實體。以下是一個Java程式,它載入en-ner-location.bin模型並檢測給定句子中的地點名稱。將此程式儲存到名為LocationFinder.java的檔案中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class LocationFinder {
public static void main(String args[]) throws Exception{
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//String paragraph = "Mike and Smith are classmates";
String paragraph = "Tutorialspoint is located in Hyderabad";
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
String tokens[] = tokenizer.tokenize(paragraph);
//Loading the NER-location moodel
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/en- ner-location.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names of a location
Span nameSpans[] = nameFinder.find(tokens);
//Printing the spans of the locations in the sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac LocationFinder.java java LocationFinder
執行上述程式後,程式會讀取給定的字串(原始文字),檢測其中的人名,並顯示它們的位置(範圍),如下所示。
[4..5) location Hyderabad
NameFinder機率
NameFinderME類的probs()方法用於獲取最後解碼序列的機率。
double[] probs = nameFinder.probs();
以下是列印機率的程式。將此程式儲存到名為TokenizerMEProbs.java的檔案中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac TokenizerMEProbs.java java TokenizerMEProbs
執行上述程式後,程式會讀取給定的字串,對句子進行分詞並列印它們。此外,它還會返回最後解碼序列的機率,如下所示。
[0..5) Hello [6..10) John [11..14) how [15..18) are [19..22) you [23..30) welcome [31..33) to [34..48) Tutorialspoint 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
OpenNLP - 詞性標註
使用OpenNLP,您還可以檢測給定句子的詞性並列印它們。OpenNLP不使用詞性的全稱,而是使用每個詞性的縮寫。下表顯示了OpenNLP檢測到的各種詞性及其含義。
| 詞性 | 詞性含義 |
|---|---|
| NN | 名詞,單數或不可數 |
| DT | 限定詞 |
| VB | 動詞,基本形式 |
| VBD | 動詞,過去時 |
| VBZ | 動詞,第三人稱單數現在時 |
| IN | 介詞或從屬連詞 |
| NNP | 專有名詞,單數 |
| TO | to |
| JJ | 形容詞 |
詞性標註
為了標註句子的詞性,OpenNLP 使用一個模型,名為 en-posmaxent.bin 的檔案。這是一個預定義的模型,經過訓練可以標註給定原始文字的詞性。
opennlp.tools.postag 包中的 POSTaggerME 類用於載入此模型,並使用 OpenNLP 庫標註給定原始文字的詞性。為此,您需要:
使用 POSModel 類載入 en-pos-maxent.bin 模型。
例項化 POSTaggerME 類。
分詞句子。
使用 tag() 方法生成標籤。
使用 POSSample 類列印標記和標籤。
以下是使用 POSTaggerME 類編寫程式來標註給定原始文字中詞性的步驟。
步驟 1:載入模型
詞性標註模型由名為 POSModel 的類表示,該類屬於 opennlp.tools.postag 包。
要載入分詞模型:
建立模型的InputStream物件(例項化FileInputStream並將模型路徑以字串格式傳遞給其建構函式)。
例項化 POSModel 類並將模型的 InputStream(物件)作為引數傳遞給其建構函式,如下面的程式碼塊所示:
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
步驟 2:例項化 POSTaggerME 類
opennlp.tools.postag 包中的 POSTaggerME 類用於預測給定原始文字的詞性。它使用最大熵來做出決策。
例項化此類並將上一步建立的模型物件作為引數傳遞,如下所示:
//Instantiating POSTaggerME class POSTaggerME tagger = new POSTaggerME(model);
步驟 3:分詞句子
whitespaceTokenizer 類的 tokenize() 方法用於對傳遞給它的原始文字進行分詞。此方法接受一個字串變數作為引數,並返回一個字串陣列(標記)。
例項化 whitespaceTokenizer 類,並透過將句子的字串格式傳遞給此方法來呼叫此方法。
//Tokenizing the sentence using WhitespaceTokenizer class WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE; String[] tokens = whitespaceTokenizer.tokenize(sentence);
步驟 4:生成標籤
whitespaceTokenizer 類的 tag() 方法為標記的句子分配詞性標籤。此方法接受一個標記(字串)陣列作為引數並返回標籤(陣列)。
透過將上一步生成的標記傳遞給它來呼叫 tag() 方法。
//Generating tags String[] tags = tagger.tag(tokens);
步驟 5:列印標記和標籤
POSSample 類表示詞性標註的句子。要例項化此類,我們需要一個文字標記陣列和一個標籤陣列。
此類的 toString() 方法返回標註後的句子。透過傳遞上一步建立的標記和標籤陣列來例項化此類,並呼叫其 toString() 方法,如下面的程式碼塊所示。
//Instantiating the POSSample class POSSample sample = new POSSample(tokens, tags); System.out.println(sample.toString());
示例
以下是標註給定原始文字中詞性的程式。將此程式儲存到名為 PosTaggerExample.java 的檔案中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerExample {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
String sentence = "Hi welcome to Tutorialspoint";
//Tokenizing the sentence using WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac PosTaggerExample.java java PosTaggerExample
執行後,上述程式將讀取給定的文字並檢測這些句子的詞性,然後顯示它們,如下所示。
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB
詞性標註器效能
以下是標註給定原始文字詞性的程式。它還會監控效能並顯示標註器的效能。將此程式儲存到名為 PosTagger_Performance.java 的檔案中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.PerformanceMonitor;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTagger_Performance {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Monitoring the performance of POS tagger
PerformanceMonitor perfMon = new PerformanceMonitor(System.err, "sent");
perfMon.start();
perfMon.incrementCounter();
perfMon.stopAndPrintFinalResult();
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac PosTaggerExample.java java PosTaggerExample
執行後,上述程式將讀取給定的文字,標註這些句子的詞性並顯示它們。此外,它還會監控詞性標註器的效能並顯示它。
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB Average: 0.0 sent/s Total: 1 sent Runtime: 0.0s
詞性標註器機率
POSTaggerME 類的 probs() 方法用於查詢最近標註句子的每個標籤的機率。
//Getting the probabilities of the recent calls to tokenizePos() method double[] probs = detector.getSentenceProbabilities();
以下是顯示最後標註句子的每個標籤的機率的程式。將此程式儲存到名為 PosTaggerProbs.java 的檔案中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerProbs {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_mdl/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Probabilities for each tag of the last tagged sentence.
double [] probs = tagger.probs();
System.out.println(" ");
//Printing the probabilities
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac TokenizerMEProbs.java java TokenizerMEProbs
執行後,上述程式將讀取給定的原始文字,標註其中每個標記的詞性,並顯示它們。此外,它還會顯示給定句子中每個詞性的機率,如下所示。
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB 0.6416834779738033 0.42983612874819177 0.8584513635863117 0.4394784478206072
OpenNLP - 句子解析
使用 OpenNLP API,您可以解析給定的句子。在本章中,我們將討論如何使用 OpenNLP API 解析原始文字。
使用 OpenNLP 庫解析原始文字
為了檢測句子,OpenNLP 使用一個預定義的模型,名為 en-parserchunking.bin 的檔案。這是一個預定義的模型,經過訓練可以解析給定的原始文字。
opennlp.tools.Parser 包中的 Parser 類用於儲存解析成分,而 opennlp.tools.cmdline.parser 包中的 ParserTool 類用於解析內容。
以下是使用 ParserTool 類編寫程式來解析給定原始文字的步驟。
步驟1:載入模型
文字解析模型由名為 ParserModel 的類表示,該類屬於 opennlp.tools.parser 包。
要載入分詞模型:
建立模型的InputStream物件(例項化FileInputStream並將模型路徑以字串格式傳遞給其建構函式)。
例項化 ParserModel 類並將模型的 InputStream(物件)作為引數傳遞給其建構函式,如下面的程式碼塊所示。
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);
步驟 2:建立 Parser 類的物件
opennlp.tools.parser 包中的 Parser 類表示用於儲存解析成分的資料結構。您可以使用 ParserFactory 類的靜態 create() 方法建立此類的物件。
透過傳遞上一步建立的模型物件來呼叫 ParserFactory 的 create() 方法,如下所示:
//Creating a parser Parser parser = ParserFactory.create(model);
步驟 3:解析句子
ParserTool 類的 parseLine() 方法用於在 OpenNLP 中解析原始文字。此方法接受:
表示要解析的文字的字串變數。
一個解析器物件。
一個整數,表示要執行的解析次數。
透過將句子、上一步建立的解析物件和一個整數(表示要執行的所需解析次數)作為引數來呼叫此方法。
//Parsing the sentence String sentence = "Tutorialspoint is the largest tutorial library."; Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);
示例
以下是解析給定原始文字的程式。將此程式儲存到名為 ParserExample.java 的檔案中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.parser.ParserTool;
import opennlp.tools.parser.Parse;
import opennlp.tools.parser.Parser;
import opennlp.tools.parser.ParserFactory;
import opennlp.tools.parser.ParserModel;
public class ParserExample {
public static void main(String args[]) throws Exception{
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);
//Creating a parser
Parser parser = ParserFactory.create(model);
//Parsing the sentence
String sentence = "Tutorialspoint is the largest tutorial library.";
Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);
for (Parse p : topParses)
p.show();
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac ParserExample.java java ParserExample
執行後,上述程式將讀取給定的原始文字,對其進行解析,並顯示以下輸出:
(TOP (S (NP (NN Tutorialspoint)) (VP (VBZ is) (NP (DT the) (JJS largest) (NN tutorial) (NN library.)))))
OpenNLP - 句子組塊
句子分塊是指將句子分解/劃分成單詞部分,例如片語和動片語。
使用 OpenNLP 進行句子分塊
為了檢測句子,OpenNLP 使用一個模型,名為 en-chunker.bin 的檔案。這是一個預定義的模型,經過訓練可以對給定原始文字中的句子進行分塊。
opennlp.tools.chunker 包包含用於查詢非遞迴句法註釋(例如名詞短語塊)的類和介面。
您可以使用 ChunkerME 類的 chunk() 方法對句子進行分塊。此方法接受句子的標記和詞性標籤作為引數。因此,在開始分塊過程之前,首先需要對句子進行分詞並生成其詞性標籤。
要使用 OpenNLP 庫對句子進行分塊,您需要:
分詞句子。
為其生成詞性標籤。
使用 ChunkerModel 類載入 en-chunker.bin 模型
例項化 ChunkerME 類。
使用此類的 chunk() 方法對句子進行分塊。
以下是編寫程式從給定原始文字中分塊句子的步驟。
步驟 1:分詞句子
使用 whitespaceTokenizer 類的 tokenize() 方法對句子進行分詞,如下面的程式碼塊所示。
//Tokenizing the sentence String sentence = "Hi welcome to Tutorialspoint"; WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE; String[] tokens = whitespaceTokenizer.tokenize(sentence);
步驟 2:生成詞性標籤
使用 POSTaggerME 類的 tag() 方法生成句子的詞性標籤,如下面的程式碼塊所示。
//Generating the POS tags
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
步驟 3:載入模型
句子分塊模型由名為 ChunkerModel 的類表示,該類屬於 opennlp.tools.chunker 包。
要載入句子檢測模型:
建立模型的InputStream物件(例項化FileInputStream並將模型路徑以字串格式傳遞給其建構函式)。
例項化 ChunkerModel 類並將模型的 InputStream(物件)作為引數傳遞給其建構函式,如下面的程式碼塊所示:
//Loading the chunker model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
步驟 4:例項化 chunkerME 類
opennlp.tools.chunker 包中的 chunkerME 類包含用於分塊句子的方法。這是一個基於最大熵的分塊器。
例項化此類,並將上一步中建立的模型物件作為引數傳遞。
//Instantiate the ChunkerME class ChunkerME chunkerME = new ChunkerME(chunkerModel);
步驟 5:分塊句子
ChunkerME 類的 chunk() 方法用於對傳遞給它的原始文字中的句子進行分塊。此方法接受兩個字串陣列作為引數,分別表示標記和標籤。
透過將上一步建立的標記陣列和標籤陣列作為引數來呼叫此方法。
//Generating the chunks String result[] = chunkerME.chunk(tokens, tags);
示例
以下是分塊給定原始文字中句子的程式。將此程式儲存到名為 ChunkerExample.java 的檔案中。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerExample{
public static void main(String args[]) throws IOException {
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating the POS tags
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
//Instantiate the ChunkerME class
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the chunks
String result[] = chunkerME.chunk(tokens, tags);
for (String s : result)
System.out.println(s);
}
}
使用以下命令從命令提示符編譯並執行儲存的 Java 檔案:
javac ChunkerExample.java java ChunkerExample
執行後,上述程式將讀取給定的字串,對其進行句子分塊,並顯示如下所示的結果:
Loading POS Tagger model ... done (1.040s) B-NP I-NP B-VP I-VP
檢測標記的位置
我們還可以使用 ChunkerME 類的 chunkAsSpans() 方法檢測塊的位置或跨度。此方法返回一個 Span 型別的物件陣列。opennlp.tools.util 包中的 Span 類用於儲存集合的 start 和 end 整數。
您可以將 chunkAsSpans() 方法返回的跨度儲存在 Span 陣列中並列印它們,如下面的程式碼塊所示。
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());
示例
以下是檢測給定原始文字中句子的程式。將此程式儲存到名為 ChunkerSpansEample.java 的檔案中。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class ChunkerSpansEample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac ChunkerSpansEample.java java ChunkerSpansEample
執行後,上述程式將讀取給定的字串,並顯示其塊的跨度,顯示以下輸出:
Loading POS Tagger model ... done (1.059s) [0..2) NP [2..4) VP
分塊器機率檢測
ChunkerME 類的 probs() 方法返回最後解碼序列的機率。
//Getting the probabilities of the last decoded sequence double[] probs = chunkerME.probs();
以下是列印 chunker 最後解碼序列的機率的程式。將此程式儲存到名為 ChunkerProbsExample.java 的檔案中。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerProbsExample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel cModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(cModel);
//Generating the chunk tags
chunkerME.chunk(tokens, tags);
//Getting the probabilities of the last decoded sequence
double[] probs = chunkerME.probs();
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}
使用以下命令從命令提示符編譯並執行儲存的Java檔案:
javac ChunkerProbsExample.java java ChunkerProbsExample
執行後,上述程式將讀取給定的字串,對其進行分塊,並列印最後解碼序列的機率。
0.9592746040797778 0.6883933131241501 0.8830563473996004 0.8951150529746051
OpenNLP - 命令列介面
OpenNLP 提供了一個命令列介面 (CLI) 用於透過命令列執行不同的操作。在本章中,我們將透過一些示例來演示如何使用 OpenNLP 命令列介面。
分詞
input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies
語法
> opennlp TokenizerME path_for_models../en-token.bin <inputfile..> outputfile..
命令
C:\> opennlp TokenizerME C:\OpenNLP_models/en-token.bin <input.txt >output.txt
輸出
Loading Tokenizer model ... done (0.207s) Average: 214.3 sent/s Total: 3 sent Runtime: 0.014s
output.txt
Hi . How are you ? Welcome to Tutorialspoint . We provide free tutorials on various technologies
句子檢測
input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies
語法
> opennlp SentenceDetector path_for_models../en-token.bin <inputfile..> outputfile..
命令
C:\> opennlp SentenceDetector C:\OpenNLP_models/en-sent.bin <input.txt > output_sendet.txt
輸出
Loading Sentence Detector model ... done (0.067s) Average: 750.0 sent/s Total: 3 sent Runtime: 0.004s
Output_sendet.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies
命名實體識別
input.txt
<START:person> <START:person> Mike <END> <END> is senior programming manager and <START:person> Rama <END> is a clerk both are working at Tutorialspoint
語法
> opennlp TokenNameFinder path_for_models../en-token.bin <inputfile..
命令
C:\>opennlp TokenNameFinder C:\OpenNLP_models\en-ner-person.bin <input_namefinder.txt
輸出
Loading Token Name Finder model ... done (0.730s) <START:person> <START:person> Mike <END> <END> is senior programming manager and <START:person> Rama <END> is a clerk both are working at Tutorialspoint Average: 55.6 sent/s Total: 1 sent Runtime: 0.018s
詞性標註
Input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies
語法
> opennlp POSTagger path_for_models../en-token.bin <inputfile..
命令
C:\>opennlp POSTagger C:\OpenNLP_models/en-pos-maxent.bin < input.txt
輸出
Loading POS Tagger model ... done (1.315s) Hi._NNP How_WRB are_VBP you?_JJ Welcome_NNP to_TO Tutorialspoint._NNP We_PRP provide_VBP free_JJ tutorials_NNS on_IN various_JJ technologies_NNS Average: 66.7 sent/s Total: 1 sent Runtime: 0.015s