Nagios - 檢查和狀態
一旦在 Nagios 上配置了主機和服務,就會使用檢查來檢視主機和服務是否按預期工作。讓我們來看一個執行主機檢查的示例:
假設您已將主機定義放在 /usr/local/nagios/etc/objects 目錄下的 host1.cfg 檔案中。
cd /usr/local/nagios/etc/objects gedit host1.cfg
這是您目前的主機定義:
define host {
host_name host1
address 10.0.0.1
}
現在讓我們新增 check_interval 指令。此指令用於根據您設定的數字執行主機的計劃檢查;預設單位為分鐘。使用下面的定義,將每 3 分鐘對主機執行一次檢查。
define host {
host_name host1
address 10.0.0.1
check_interval 3
}
在 Nagios 中,對主機和服務執行兩種型別的檢查:
- 主動檢查
- 被動檢查
主動檢查
主動檢查由 Nagios 程序啟動,然後定期執行。Nagios 程序內的檢查邏輯啟動主動檢查。為了監控遠端機器上執行的主機和服務,Nagios 執行外掛並告知要收集哪些資訊。然後外掛在遠端機器上執行,在那裡收集所需的資訊並將其傳送回 Nagios 守護程序。根據接收到的主機和服務狀態,將採取相應的措施。
下圖顯示了一個主動檢查:

這些檢查按 check_interval 和 retry_interval 定義的定期間隔執行。
被動檢查由外部程序執行,並將結果返回給 Nagios 進行處理。
被動檢查的工作原理如下:
外部應用程式檢查主機/服務的狀態,並將結果寫入外部命令檔案。當 Nagios 守護程序讀取外部命令檔案時,它讀取併發送佇列中所有被動檢查以供稍後處理。定期處理這些檢查時,將根據檢查結果中的資訊傳送通知或警報。
下圖顯示了一個被動檢查:
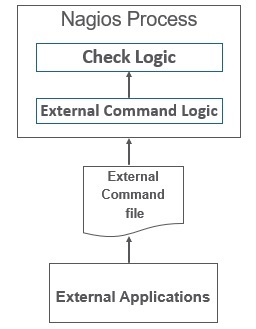
因此,主動檢查和被動檢查之間的區別在於,主動檢查由 Nagios 執行,而被動檢查由外部應用程式執行。
當您無法定期監控主機/服務時,這些檢查非常有用。
Nagios 儲存其監控的主機和服務的狀態,以確定它們是否正常工作。在許多情況下,故障會隨機發生並且是暫時的;因此,Nagios 使用狀態來檢查主機或服務的當前狀態。
有兩種型別的狀態:
- 軟狀態
- 硬狀態
軟狀態
當主機或服務在很短的時間內停止執行並且其狀態未知或與之前的狀態不同時,則使用軟狀態。主機或服務將反覆測試,直到狀態永久為止。
硬狀態
當執行 max_check_attempts 並且主機或服務的狀態仍然不是 OK 時,則使用硬狀態。Nagios 執行事件處理程式來處理硬狀態。
下圖顯示了軟狀態和硬狀態。
