- Microsoft認知工具包(CNTK) 教程
- 首頁
- 簡介
- 入門
- CPU和GPU
- CNTK - 序列分類
- CNTK - 邏輯迴歸模型
- CNTK - 神經網路(NN) 概念
- CNTK - 建立第一個神經網路
- CNTK - 訓練神經網路
- CNTK - 記憶體資料集和大型資料集
- CNTK - 效能測量
- 神經網路分類
- 神經網路二元分類
- CNTK - 神經網路迴歸
- CNTK - 分類模型
- CNTK - 迴歸模型
- CNTK - 記憶體不足的資料集
- CNTK - 監控模型
- CNTK - 卷積神經網路
- CNTK - 迴圈神經網路
- Microsoft認知工具包資源
- Microsoft認知工具包 - 快速指南
- Microsoft認知工具包 - 資源
- Microsoft認知工具包 - 討論
Microsoft認知工具包 - 快速指南
Microsoft認知工具包(CNTK) - 簡介
本章,我們將學習什麼是CNTK,它的特性,1.0版和2.0版之間的區別以及2.7版的重要亮點。
什麼是Microsoft認知工具包(CNTK)?
Microsoft認知工具包(CNTK),以前稱為計算網路工具包,是一個免費、易於使用、開源、商用級的工具包,使我們能夠訓練深度學習演算法,使其像人腦一樣學習。它使我們能夠建立一些流行的深度學習系統,例如前饋神經網路時間序列預測系統和卷積神經網路(CNN)影像分類器。
為了獲得最佳效能,其框架函式是用C++編寫的。雖然我們可以使用C++呼叫其函式,但最常用的方法是使用Python程式。
CNTK的特性
以下是Microsoft CNTK最新版本提供的一些特性和功能
內建元件
CNTK具有高度最佳化的內建元件,可以處理來自Python、C++或BrainScript的多維密集或稀疏資料。
我們可以實現CNN、FNN、RNN、批次歸一化和帶注意力的序列到序列。
它為我們提供了從Python在GPU上新增新的使用者定義核心元件的功能。
它還提供自動超引數調整。
我們可以實現強化學習、生成對抗網路(GAN)、監督學習和無監督學習。
對於海量資料集,CNTK具有內建的最佳化讀取器。
高效利用資源
CNTK透過1位SGD為我們提供了在多個GPU/機器上的高精度並行性。
為了將最大的模型放入GPU記憶體中,它提供了記憶體共享和其他內建方法。
輕鬆表達我們自己的網路
CNTK具有完整的API,用於從Python、C++和BrainScript定義您自己的網路、學習器、讀取器、訓練和評估。
使用CNTK,我們可以輕鬆地使用Python、C++、C#或BrainScript評估模型。
它提供高階和低階API。
根據我們的資料,它可以自動調整推理。
它具有完全最佳化的符號迴圈迴圈神經網路(RNN)。
測量模型效能
CNTK提供各種元件來衡量您構建的神經網路的效能。
從您的模型和相關的最佳化器生成日誌資料,我們可以使用這些資料來監控訓練過程。
1.0版與2.0版
下表比較了CNTK 1.0版和2.0版
| 1.0版 | 2.0版 |
|---|---|
| 它於2016年釋出。 | 它是1.0版的重大改寫,於2017年6月釋出。 |
| 它使用一種稱為BrainScript的專有指令碼語言。 | 其框架函式可以使用C++、Python呼叫。我們可以輕鬆地在C#或Java中載入我們的模組。BrainScript也受2.0版支援。 |
| 它在Windows和Linux系統上執行,但不直接在Mac OS上執行。 | 它還在Windows(Win 8.1、Win 10、Server 2012 R2及更高版本)和Linux系統上執行,但不直接在Mac OS上執行。 |
2.7版的重要亮點
2.7版是Microsoft認知工具包的最後一個主要釋出版本。它完全支援ONNX 1.4.1。以下是此最新發布的CNTK版本的一些重要亮點。
完全支援ONNX 1.4.1。
支援Windows和Linux系統的CUDA 10。
它支援ONNX匯出中的高階迴圈神經網路(RNN)迴圈。
它可以匯出超過2GB的ONNX格式模型。
它支援BrainScript指令碼語言的訓練操作中的FP16。
Microsoft認知工具包(CNTK) - 入門
在這裡,我們將瞭解如何在Windows和Linux上安裝CNTK。此外,本章還解釋了安裝CNTK包、安裝Anaconda的步驟、CNTK檔案、目錄結構和CNTK庫組織。
先決條件
為了安裝CNTK,我們的計算機上必須安裝Python。您可以訪問連結https://python.club.tw/downloads/併為您的作業系統(即Windows和Linux/Unix)選擇最新版本。有關Python的基礎教程,您可以參考連結https://tutorialspoint.tw/python3/index.htm。
CNTK支援Windows和Linux,因此我們將逐步介紹兩者。
在Windows上安裝
為了在Windows上執行CNTK,我們將使用Python的Anaconda版本。我們知道,Anaconda是Python的再發行版。它包括CNTK用於執行各種有用計算的附加包,例如Scipy和Scikit-learn。
因此,首先讓我們看看在您的計算機上安裝Anaconda的步驟:
步驟1-首先從公共網站https://www.anaconda.com/distribution/下載安裝檔案。
步驟2-下載安裝檔案後,啟動安裝並按照連結https://docs.anaconda.com/anaconda/install/中的說明進行操作。
步驟3-安裝完成後,Anaconda還將安裝其他一些實用程式,這些實用程式將自動將所有Anaconda可執行檔案包含在您的計算機PATH變數中。我們可以從此提示符管理我們的Python環境,安裝包和執行Python指令碼。
安裝CNTK包
Anaconda安裝完成後,您可以使用最常用的方法透過pip可執行檔案安裝CNTK包,使用以下命令:
pip install cntk
還有其他幾種方法可以在您的計算機上安裝Cognitive Toolkit。Microsoft有一套簡潔的文件,詳細解釋了其他安裝方法。請訪問連結https://docs.microsoft.com/en-us/cognitive-toolkit/Setup-CNTK-on-your-machine。
在Linux上安裝
在Linux上安裝CNTK與在Windows上安裝略有不同。在這裡,對於Linux,我們將使用Anaconda安裝CNTK,但是我們將使用基於終端的安裝程式在Linux上安裝Anaconda,而不是Anaconda的圖形安裝程式。儘管安裝程式幾乎適用於所有Linux發行版,但我們將描述限制在Ubuntu。
因此,首先讓我們看看在您的計算機上安裝Anaconda的步驟:
安裝Anaconda的步驟
步驟1-在安裝Anaconda之前,請確保系統完全是最新的。要檢查,首先在終端中執行以下兩個命令:
sudo apt update sudo apt upgrade
步驟2-計算機更新後,從公共網站https://www.anaconda.com/distribution/獲取最新Anaconda安裝檔案的URL。
步驟3-複製URL後,開啟終端視窗並執行以下命令:
wget -0 anaconda-installer.sh url SHAPE \* MERGEFORMAT
y
f
x
| }
將url佔位符替換為從Anaconda網站複製的URL。
步驟4-接下來,我們可以使用以下命令安裝Anaconda:
sh ./anaconda-installer.sh
上述命令將預設在我們的主目錄中安裝Anaconda3。
安裝CNTK包
Anaconda安裝完成後,您可以使用最常用的方法透過pip可執行檔案安裝CNTK包,使用以下命令:
pip install cntk
檢查CNTK檔案和目錄結構
一旦CNTK作為Python包安裝,我們可以檢查其檔案和目錄結構。它位於C:\Users\
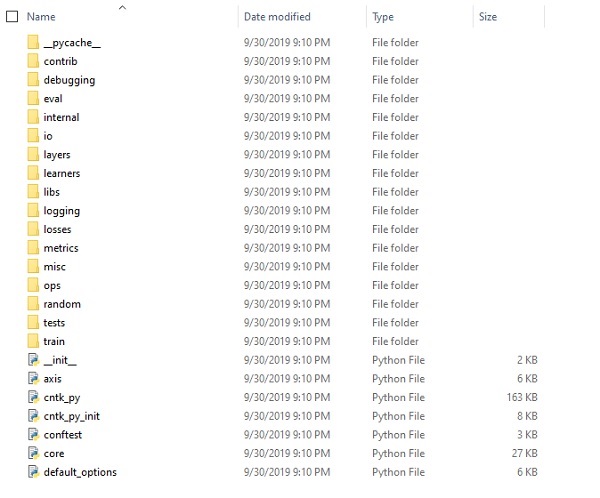
驗證CNTK安裝
一旦CNTK作為Python包安裝,您應該驗證CNTK是否已正確安裝。從Anaconda命令列,透過輸入ipython啟動Python直譯器。然後,透過輸入以下命令匯入CNTK。
import cntk as c
匯入後,使用以下命令檢查其版本:
print(c.__version__)
直譯器將響應已安裝的CNTK版本。如果它沒有響應,則安裝過程中會出現問題。
CNTK庫的組織
CNTK(技術上是一個Python包)被組織成13個高階子包和8個較小的子包。下表包含10個最常用的包
| 序號 | 包名稱和描述 |
|---|---|
| 1 |
cntk.io 包含用於讀取資料的函式。例如:next_minibatch() |
| 2 |
cntk.layers 包含用於建立神經網路的高階函式。例如:Dense() |
| 3 |
cntk.learners 包含用於訓練的函式。例如:sgd() |
| 4 |
cntk.losses 包含用於測量訓練誤差的函式。例如:squared_error() |
| 5 |
cntk.metrics 包含用於測量模型誤差的函式。例如:classificatoin_error |
| 6 |
cntk.ops 包含用於建立神經網路的低階函式。例如:tanh() |
| 7 |
cntk.random 包含用於生成隨機數的函式。例如:normal() |
| 8 |
cntk.train 包含訓練函式。例如:train_minibatch() |
| 9 |
cntk.initializer 包含模型引數初始化器。例如:normal()和uniform() |
| 10 |
cntk.variables 包含低階構造。例如:Parameter()和Variable() |
Microsoft認知工具包(CNTK) - CPU和GPU
Microsoft認知工具包提供了兩個不同的構建版本,即僅CPU和僅GPU。
僅CPU構建版本
CNTK 的僅 CPU 版本使用最佳化的 Intel MKLML,其中 MKLML 是 MKL(數學核心庫)的子集,並作為 Intel MKL for MKL-DNN 的終止版本隨 Intel MKL-DNN 一起釋出。
僅 GPU 版本
另一方面,CNTK 的僅 GPU 版本使用高度最佳化的 NVIDIA 庫,例如CUB 和cuDNN。它支援跨多個 GPU 和多臺機器的分散式訓練。為了在 CNTK 中實現更快的分散式訓練,GPU 版本還包括:
MSR 開發的 1 位量化 SGD。
塊動量 SGD 並行訓練演算法。
在 Windows 上啟用 CNTK 的 GPU
在上一節中,我們瞭解瞭如何安裝 CNTK 的基本版本以與 CPU 一起使用。現在讓我們討論如何安裝 CNTK 以與 GPU 一起使用。但是,在深入研究之前,首先您應該擁有一張受支援的顯示卡。
目前,CNTK 支援至少支援 CUDA 3.0 的 NVIDIA 顯示卡。要確保,您可以訪問https://developer.nvidia.com/cuda-gpus檢視您的 GPU 是否支援 CUDA。
因此,讓我們看看在 Windows 作業系統上啟用 CNTK 的 GPU 的步驟:
步驟 1 - 根據您使用的顯示卡,您首先需要擁有適用於您顯示卡的最新 GeForce 或 Quadro 驅動程式。
步驟 2 - 下載驅動程式後,您需要從 NVIDIA 網站https://developer.nvidia.com/cuda-90-download-archive?target_os=Windows&target_arch=x86_64安裝適用於 Windows 的 CUDA 工具包版本 9.0。安裝後,執行安裝程式並按照說明操作。
步驟 3 - 接下來,您需要從 NVIDIA 網站https://developer.nvidia.com/rdp/form/cudnn-download-survey安裝 cuDNN 二進位制檔案。對於 CUDA 9.0 版本,cuDNN 7.4.1 執行良好。基本上,cuDNN 是 CUDA 之上的一個層,由 CNTK 使用。
步驟 4 - 下載 cuDNN 二進位制檔案後,您需要將 zip 檔案解壓到 CUDA 工具包安裝的根資料夾中。
步驟 5 - 這是最後一步,它將啟用 CNTK 中的 GPU 使用。在 Windows 作業系統的 Anaconda 提示符中執行以下命令:
pip install cntk-gpu
在 Linux 上啟用 CNTK 的 GPU
讓我們看看如何在 Linux 作業系統上啟用 CNTK 的 GPU:
下載 CUDA 工具包
首先,您需要從 NVIDIA 網站https://developer.nvidia.com/cuda-90-download-archive?target_os=Linux&target_arch=x86_64&target_distro=Ubuntu&target_version=1604&target_type=runfilelocal安裝 CUDA 工具包。
執行安裝程式
現在,一旦磁碟上有二進位制檔案,請透過開啟終端並執行以下命令以及螢幕上的說明來執行安裝程式:
sh cuda_9.0.176_384.81_linux-run
修改 Bash 配置檔案
在 Linux 機器上安裝 CUDA 工具包後,您需要修改 BASH 配置檔案。為此,首先在文字編輯器中開啟 $HOME/.bashrc 檔案。現在,在指令碼的末尾,包含以下幾行:
export PATH=/usr/local/cuda-9.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64\
${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
Installing
安裝 cuDNN 庫
最後,我們需要安裝 cuDNN 二進位制檔案。它可以從 NVIDIA 網站https://developer.nvidia.com/rdp/form/cudnn-download-survey下載。對於 CUDA 9.0 版本,cuDNN 7.4.1 執行良好。基本上,cuDNN 是 CUDA 之上的一個層,由 CNTK 使用。
下載適用於 Linux 的版本後,使用以下命令將其解壓到/usr/local/cuda-9.0資料夾:
tar xvzf -C /usr/local/cuda-9.0/ cudnn-9.0-linux-x64-v7.4.1.5.tgz
根據需要更改檔名的路徑。
CNTK - 序列分類
在本章中,我們將詳細瞭解 CNTK 中的序列及其分類。
張量
CNTK 工作的基礎概念是張量。基本上,CNTK 的輸入、輸出以及引數都組織為張量,這通常被認為是廣義矩陣。每個張量都有一個秩:
秩為 0 的張量是標量。
秩為 1 的張量是向量。
秩為 2 的張量是矩陣。
這裡,這些不同的維度被稱為軸。
靜態軸和動態軸
顧名思義,靜態軸在整個網路的生命週期中長度相同。另一方面,動態軸的長度在不同的例項之間可能會有所不同。事實上,在呈現每個小批次之前通常不知道它們的長度。
動態軸類似於靜態軸,因為它們也定義了張量中包含數字的有意義的分組。
示例
為了更清楚地說明,讓我們看看如何在 CNTK 中表示短影片片段的小批次。假設影片片段的解析度均為 640 * 480。此外,剪輯採用彩色拍攝,通常用三個通道編碼。這進一步意味著我們的迷你批次具有以下內容:
長度分別為 640、480 和 3 的 3 個靜態軸。
兩個動態軸;影片的長度和迷你批次軸。
這意味著,如果一個迷你批次包含 16 個影片,每個影片長 240 幀,則將表示為16*240*3*640*480 張量。
在 CNTK 中使用序列
讓我們首先了解長短期記憶網路,然後瞭解 CNTK 中的序列。
長短期記憶網路 (LSTM)

長短期記憶 (LSTM) 網路由 Hochreiter & Schmidhuber 引入。它解決了讓基本迴圈層長時間記住事物的問題。LSTM 的架構如上圖所示。我們可以看到它有輸入神經元、記憶單元和輸出神經元。為了解決梯度消失問題,長短期記憶網路使用顯式記憶單元(儲存先前值)和以下門:
遺忘門 - 顧名思義,它告訴記憶單元忘記先前的值。記憶單元儲存值,直到門即“遺忘門”告訴它忘記它們。
輸入門 - 顧名思義,它向單元新增新內容。
輸出門 - 顧名思義,輸出門決定何時將向量從單元傳遞到下一個隱藏狀態。
在 CNTK 中使用序列非常容易。讓我們藉助以下示例來看:
import sys
import os
from cntk import Trainer, Axis
from cntk.io import MinibatchSource, CTFDeserializer, StreamDef, StreamDefs,\
INFINITELY_REPEAT
from cntk.learners import sgd, learning_parameter_schedule_per_sample
from cntk import input_variable, cross_entropy_with_softmax, \
classification_error, sequence
from cntk.logging import ProgressPrinter
from cntk.layers import Sequential, Embedding, Recurrence, LSTM, Dense
def create_reader(path, is_training, input_dim, label_dim):
return MinibatchSource(CTFDeserializer(path, StreamDefs(
features=StreamDef(field='x', shape=input_dim, is_sparse=True),
labels=StreamDef(field='y', shape=label_dim, is_sparse=False)
)), randomize=is_training,
max_sweeps=INFINITELY_REPEAT if is_training else 1)
def LSTM_sequence_classifier_net(input, num_output_classes, embedding_dim,
LSTM_dim, cell_dim):
lstm_classifier = Sequential([Embedding(embedding_dim),
Recurrence(LSTM(LSTM_dim, cell_dim)),
sequence.last,
Dense(num_output_classes)])
return lstm_classifier(input)
def train_sequence_classifier():
input_dim = 2000
cell_dim = 25
hidden_dim = 25
embedding_dim = 50
num_output_classes = 5
features = sequence.input_variable(shape=input_dim, is_sparse=True)
label = input_variable(num_output_classes)
classifier_output = LSTM_sequence_classifier_net(
features, num_output_classes, embedding_dim, hidden_dim, cell_dim)
ce = cross_entropy_with_softmax(classifier_output, label)
pe = classification_error(classifier_output, label)
rel_path = ("../../../Tests/EndToEndTests/Text/" +
"SequenceClassification/Data/Train.ctf")
path = os.path.join(os.path.dirname(os.path.abspath(__file__)), rel_path)
reader = create_reader(path, True, input_dim, num_output_classes)
input_map = {
features: reader.streams.features,
label: reader.streams.labels
}
lr_per_sample = learning_parameter_schedule_per_sample(0.0005)
progress_printer = ProgressPrinter(0)
trainer = Trainer(classifier_output, (ce, pe),
sgd(classifier_output.parameters, lr=lr_per_sample),progress_printer)
minibatch_size = 200
for i in range(255):
mb = reader.next_minibatch(minibatch_size, input_map=input_map)
trainer.train_minibatch(mb)
evaluation_average = float(trainer.previous_minibatch_evaluation_average)
loss_average = float(trainer.previous_minibatch_loss_average)
return evaluation_average, loss_average
if __name__ == '__main__':
error, _ = train_sequence_classifier()
print(" error: %f" % error)
average since average since examples loss last metric last ------------------------------------------------------ 1.61 1.61 0.886 0.886 44 1.61 1.6 0.714 0.629 133 1.6 1.59 0.56 0.448 316 1.57 1.55 0.479 0.41 682 1.53 1.5 0.464 0.449 1379 1.46 1.4 0.453 0.441 2813 1.37 1.28 0.45 0.447 5679 1.3 1.23 0.448 0.447 11365 error: 0.333333
上述程式的詳細解釋將在下一節中介紹,尤其是在構建迴圈神經網路時。
CNTK - 邏輯迴歸模型
本章介紹如何在 CNTK 中構建邏輯迴歸模型。
邏輯迴歸模型的基礎知識
邏輯迴歸是最簡單的機器學習技術之一,是一種專門用於二元分類的技術。換句話說,在需要預測變數的值可能只有兩個分類值之一的情況下建立預測模型。邏輯迴歸最簡單的例子之一是根據人的年齡、聲音、頭髮等等來預測此人是否為男性或女性。
示例
讓我們藉助另一個例子從數學角度瞭解邏輯迴歸的概念:
假設,我們想根據申請人的債務、收入和信用評級來預測貸款申請的信用價值;0 表示拒絕,1 表示批准。我們用 X1 表示債務,用 X2 表示收入,用 X3 表示信用評級。
在邏輯迴歸中,我們為每個特徵確定一個權重值,用w表示,並確定一個偏差值,用b表示。
現在假設:
X1 = 3.0 X2 = -2.0 X3 = 1.0
並且假設我們確定權重和偏差如下:
W1 = 0.65, W2 = 1.75, W3 = 2.05 and b = 0.33
現在,為了預測類別,我們需要應用以下公式:
Z = (X1*W1)+(X2*W2)+(X3+W3)+b i.e. Z = (3.0)*(0.65) + (-2.0)*(1.75) + (1.0)*(2.05) + 0.33 = 0.83
接下來,我們需要計算P = 1.0/(1.0 + exp(-Z))。這裡,exp() 函式是尤拉數。
P = 1.0/(1.0 + exp(-0.83) = 0.6963
P 值可以解釋為類別為 1 的機率。如果 P < 0.5,則預測類別 = 0;否則預測 (P >= 0.5) 類別 = 1。
為了確定權重和偏差的值,我們必須獲得一組具有已知輸入預測值和已知正確類別標籤值的訓練資料。之後,我們可以使用一種演算法(通常是梯度下降)來查詢權重和偏差的值。
LR 模型實現示例
對於此 LR 模型,我們將使用以下資料集:
1.0, 2.0, 0 3.0, 4.0, 0 5.0, 2.0, 0 6.0, 3.0, 0 8.0, 1.0, 0 9.0, 2.0, 0 1.0, 4.0, 1 2.0, 5.0, 1 4.0, 6.0, 1 6.0, 5.0, 1 7.0, 3.0, 1 8.0, 5.0, 1
要在 CNTK 中啟動此 LR 模型實現,我們首先需要匯入以下包:
import numpy as np import cntk as C
程式的結構如下所示,包含 main() 函式:
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
現在,我們需要將訓練資料載入到記憶體中,如下所示:
data_file = ".\\dataLRmodel.txt"
print("Loading data from " + data_file + "\n")
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[0,1])
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[2], ndmin=2)
現在,我們將建立一個訓練程式,該程式建立一個與訓練資料相容的邏輯迴歸模型:
features_dim = 2 labels_dim = 1 X = C.ops.input_variable(features_dim, np.float32) y = C.input_variable(labels_dim, np.float32) W = C.parameter(shape=(features_dim, 1)) # trainable cntk.Parameter b = C.parameter(shape=(labels_dim)) z = C.times(X, W) + b p = 1.0 / (1.0 + C.exp(-z)) model = p
現在,我們需要建立學習器和訓練器,如下所示:
ce_error = C.binary_cross_entropy(model, y) # CE a bit more principled for LR fixed_lr = 0.010 learner = C.sgd(model.parameters, fixed_lr) trainer = C.Trainer(model, (ce_error), [learner]) max_iterations = 4000
LR 模型訓練
一旦我們建立了 LR 模型,接下來就是開始訓練過程:
np.random.seed(4)
N = len(features_mat)
for i in range(0, max_iterations):
row = np.random.choice(N,1) # pick a random row from training items
trainer.train_minibatch({ X: features_mat[row], y: labels_mat[row] })
if i % 1000 == 0 and i > 0:
mcee = trainer.previous_minibatch_loss_average
print(str(i) + " Cross-entropy error on curr item = %0.4f " % mcee)
現在,藉助以下程式碼,我們可以列印模型權重和偏差:
np.set_printoptions(precision=4, suppress=True)
print("Model weights: ")
print(W.value)
print("Model bias:")
print(b.value)
print("")
if __name__ == "__main__":
main()
訓練邏輯迴歸模型 -完整示例
import numpy as np
import cntk as C
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
data_file = ".\\dataLRmodel.txt" # provide the name and the location of data file
print("Loading data from " + data_file + "\n")
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[0,1])
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[2], ndmin=2)
features_dim = 2
labels_dim = 1
X = C.ops.input_variable(features_dim, np.float32)
y = C.input_variable(labels_dim, np.float32)
W = C.parameter(shape=(features_dim, 1)) # trainable cntk.Parameter
b = C.parameter(shape=(labels_dim))
z = C.times(X, W) + b
p = 1.0 / (1.0 + C.exp(-z))
model = p
ce_error = C.binary_cross_entropy(model, y) # CE a bit more principled for LR
fixed_lr = 0.010
learner = C.sgd(model.parameters, fixed_lr)
trainer = C.Trainer(model, (ce_error), [learner])
max_iterations = 4000
np.random.seed(4)
N = len(features_mat)
for i in range(0, max_iterations):
row = np.random.choice(N,1) # pick a random row from training items
trainer.train_minibatch({ X: features_mat[row], y: labels_mat[row] })
if i % 1000 == 0 and i > 0:
mcee = trainer.previous_minibatch_loss_average
print(str(i) + " Cross-entropy error on curr item = %0.4f " % mcee)
np.set_printoptions(precision=4, suppress=True)
print("Model weights: ")
print(W.value)
print("Model bias:")
print(b.value)
if __name__ == "__main__":
main()
輸出
Using CNTK version = 2.7 1000 cross entropy error on curr item = 0.1941 2000 cross entropy error on curr item = 0.1746 3000 cross entropy error on curr item = 0.0563 Model weights: [-0.2049] [0.9666]] Model bias: [-2.2846]
使用訓練好的 LR 模型進行預測
一旦 LR 模型經過訓練,我們就可以使用它進行預測,如下所示:
首先,我們的評估程式匯入 numpy 包並將訓練資料載入到特徵矩陣和類別標籤矩陣中,方法與我們上面實現的訓練程式相同:
import numpy as np def main(): data_file = ".\\dataLRmodel.txt" # provide the name and the location of data file features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=(0,1)) labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[2], ndmin=2)
接下來,是時候設定訓練程式確定的權重和偏差的值了:
print("Setting weights and bias values \n")
weights = np.array([0.0925, 1.1722], dtype=np.float32)
bias = np.array([-4.5400], dtype=np.float32)
N = len(features_mat)
features_dim = 2
接下來,我們的評估程式將透過遍歷每個訓練專案來計算邏輯迴歸機率,如下所示:
print("item pred_prob pred_label act_label result")
for i in range(0, N): # each item
x = features_mat[i]
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
pred_prob = 1.0 / (1.0 + np.exp(-z))
pred_label = 0 if pred_prob < 0.5 else 1
act_label = labels_mat[i]
pred_str = ‘correct’ if np.absolute(pred_label - act_label) < 1.0e-5 \
else ‘WRONG’
print("%2d %0.4f %0.0f %0.0f %s" % \ (i, pred_prob, pred_label, act_label, pred_str))
現在讓我們演示如何進行預測:
x = np.array([9.5, 4.5], dtype=np.float32)
print("\nPredicting class for age, education = ")
print(x)
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
p = 1.0 / (1.0 + np.exp(-z))
print("Predicted p = " + str(p))
if p < 0.5: print("Predicted class = 0")
else: print("Predicted class = 1")
完整的預測評估程式
import numpy as np
def main():
data_file = ".\\dataLRmodel.txt" # provide the name and the location of data file
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=(0,1))
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=[2], ndmin=2)
print("Setting weights and bias values \n")
weights = np.array([0.0925, 1.1722], dtype=np.float32)
bias = np.array([-4.5400], dtype=np.float32)
N = len(features_mat)
features_dim = 2
print("item pred_prob pred_label act_label result")
for i in range(0, N): # each item
x = features_mat[i]
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
pred_prob = 1.0 / (1.0 + np.exp(-z))
pred_label = 0 if pred_prob < 0.5 else 1
act_label = labels_mat[i]
pred_str = ‘correct’ if np.absolute(pred_label - act_label) < 1.0e-5 \
else ‘WRONG’
print("%2d %0.4f %0.0f %0.0f %s" % \ (i, pred_prob, pred_label, act_label, pred_str))
x = np.array([9.5, 4.5], dtype=np.float32)
print("\nPredicting class for age, education = ")
print(x)
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
p = 1.0 / (1.0 + np.exp(-z))
print("Predicted p = " + str(p))
if p < 0.5: print("Predicted class = 0")
else: print("Predicted class = 1")
if __name__ == "__main__":
main()
輸出
設定權重和偏差值。
Item pred_prob pred_label act_label result 0 0.3640 0 0 correct 1 0.7254 1 0 WRONG 2 0.2019 0 0 correct 3 0.3562 0 0 correct 4 0.0493 0 0 correct 5 0.1005 0 0 correct 6 0.7892 1 1 correct 7 0.8564 1 1 correct 8 0.9654 1 1 correct 9 0.7587 1 1 correct 10 0.3040 0 1 WRONG 11 0.7129 1 1 correct Predicting class for age, education = [9.5 4.5] Predicting p = 0.526487952 Predicting class = 1
CNTK - 神經網路(NN) 概念
本章介紹關於 CNTK 的神經網路概念。
眾所周知,使用多層神經元來構建神經網路。但是,問題出現了,在 CNTK 中我們如何模擬 NN 的層?這可以透過層模組中定義的層函式來完成。
層函式
實際上,在 CNTK 中,使用層具有明顯的函數語言程式設計風格。層函式看起來像一個常規函式,它產生一個具有預定義引數集的數學函式。讓我們看看如何藉助層函式建立最基本的層型別 Dense。
示例
藉助以下基本步驟,我們可以建立最基本的層型別:
步驟 1 - 首先,我們需要從 CNTK 的 layers 包中匯入 Dense 層函式。
from cntk.layers import Dense
步驟 2 - 接下來,我們需要從 CNTK 根包中匯入 input_variable 函式。
from cntk import input_variable
步驟 3 - 現在,我們需要使用 input_variable 函式建立一個新的輸入變數。我們還需要提供它的 size。
feature = input_variable(100)
步驟 4 - 最後,我們將使用 Dense 函式建立一個新層,並提供我們想要的神經元數量。
layer = Dense(40)(feature)
現在,我們可以呼叫已配置的 Dense 層函式來將 Dense 層連線到輸入。
完整的實現示例
from cntk.layers import Dense from cntk import input_variable feature= input_variable(100) layer = Dense(40)(feature)
自定義層
正如我們所看到的,CNTK 為我們提供了一套相當不錯的預設設定來構建 NN。根據我們選擇的啟用函式和其他設定,NN 的行為和效能有所不同。這是另一個非常有用的詞幹提取演算法。這就是為什麼瞭解我們可以配置什麼內容很重要。
配置 Dense 層的步驟
NN 中的每個層都有其獨特的配置選項,當我們談論 Dense 層時,我們有以下重要的設定需要定義:
shape - 顧名思義,它定義了層的輸出形狀,這進一步決定了該層中的神經元數量。
activation - 它定義了該層的啟用函式,因此它可以轉換輸入資料。
init - 它定義了該層的初始化函式。當我們開始訓練 NN 時,它將初始化該層的引數。
讓我們看看我們可以使用哪些步驟來配置Dense層:
步驟 1 - 首先,我們需要從 CNTK 的 layers 包中匯入Dense層函式。
from cntk.layers import Dense
步驟2 − 接下來,我們需要從 CNTK ops 包中匯入 sigmoid 運算元。它將用作啟用函式。
from cntk.ops import sigmoid
步驟3 − 現在,我們需要從 initializer 包中匯入 glorot_uniform 初始化器。
from cntk.initializer import glorot_uniform
步驟4 − 最後,我們將使用 Dense 函式建立一個新層,並將神經元數量作為第一個引數提供。此外,將 sigmoid 運算元作為啟用函式,並將 glorot_uniform 作為該層的初始化函式。
layer = Dense(50, activation = sigmoid, init = glorot_uniform)
完整的實現示例 -
from cntk.layers import Dense from cntk.ops import sigmoid from cntk.initializer import glorot_uniform layer = Dense(50, activation = sigmoid, init = glorot_uniform)
最佳化引數
到目前為止,我們已經瞭解瞭如何建立神經網路的結構以及如何配置各種設定。在這裡,我們將瞭解如何最佳化神經網路的引數。藉助學習器和訓練器這兩個元件的組合,我們可以最佳化神經網路的引數。
訓練器元件
用於最佳化神經網路引數的第一個元件是訓練器元件。它基本上實現了反向傳播過程。如果我們談論它的工作原理,它會將資料透過神經網路以獲得預測。
之後,它使用另一個稱為學習器的元件來獲取神經網路中引數的新值。一旦獲得新值,它就會應用這些新值並重復此過程,直到滿足退出條件。
學習器元件
用於最佳化神經網路引數的第二個元件是學習器元件,它主要負責執行梯度下降演算法。
CNTK 庫中包含的學習器
以下是 CNTK 庫中包含的一些有趣的學習器的列表 -
隨機梯度下降 (SGD) − 此學習器表示基本的隨機梯度下降,沒有任何額外功能。
動量隨機梯度下降 (MomentumSGD) − 使用 SGD,此學習器應用動量來克服區域性最大值的問題。
RMSProp − 此學習器為了控制下降速率,使用了衰減學習率。
Adam − 此學習器為了隨時間推移降低下降速率,使用了衰減動量。
Adagrad − 此學習器對頻繁出現和不頻繁出現的特徵使用不同的學習率。
CNTK - 建立第一個神經網路
本章將詳細闡述在 CNTK 中建立神經網路。
構建網路結構
為了應用 CNTK 概念來構建我們的第一個神經網路,我們將使用神經網路根據萼片寬度和長度以及花瓣寬度和長度的物理屬性對鳶尾花物種進行分類。我們將使用的這個資料集是鳶尾花資料集,它描述了不同品種鳶尾花的物理屬性 -
- 萼片長度
- 萼片寬度
- 花瓣長度
- 花瓣寬度
- 類別,即山鳶尾、雜色鳶尾或弗吉尼亞鳶尾
在這裡,我們將構建一個稱為前饋神經網路的常規神經網路。讓我們看看構建神經網路結構的實現步驟 -
步驟1 − 首先,我們將從 CNTK 庫中匯入必要的元件,例如我們的層型別、啟用函式和允許我們為神經網路定義輸入變數的函式。
from cntk import default_options, input_variable from cntk.layers import Dense, Sequential from cntk.ops import log_softmax, relu
步驟2 − 之後,我們將使用 sequential 函式建立我們的模型。建立完成後,我們將向其中輸入我們想要的層。在這裡,我們將在神經網路中建立兩層不同的層;一層有四個神經元,另一層有三個神經元。
model = Sequential([Dense(4, activation=relu), Dense(3, activation=log_sogtmax)])
步驟3 − 最後,為了編譯神經網路,我們將網路繫結到輸入變數。它具有一個具有四個神經元的輸入層和一個具有三個神經元的輸出層。
feature= input_variable(4) z = model(feature)
應用啟用函式
有很多啟用函式可供選擇,選擇正確的啟用函式肯定會對深度學習模型的效能產生重大影響。
在輸出層
在輸出層選擇啟用函式將取決於我們將用模型解決的問題型別。
對於迴歸問題,我們應該在輸出層使用線性啟用函式。
對於二元分類問題,我們應該在輸出層使用 sigmoid 啟用函式。
對於多類分類問題,我們應該在輸出層使用 softmax 啟用函式。
在這裡,我們將構建一個用於預測三個類別之一的模型。這意味著我們需要在輸出層使用 softmax 啟用函式。
在隱藏層
在隱藏層選擇啟用函式需要一些實驗來監控效能,以檢視哪個啟用函式效果好。
在分類問題中,我們需要預測樣本屬於特定類別的機率。這就是為什麼我們需要一個啟用函式來為我們提供機率值。為了達到這個目標, sigmoid 啟用函式可以幫助我們。
與 sigmoid 函式相關的主要問題之一是梯度消失問題。為了克服這個問題,我們可以使用 ReLU 啟用函式,它將所有負值轉換為零,並作為正值的直通濾波器。
選擇損失函式
一旦我們有了神經網路模型的結構,我們就必須對其進行最佳化。為了最佳化,我們需要一個損失函式。與啟用函式不同的是,我們可選擇的損失函式很少。但是,選擇損失函式將取決於我們將用模型解決的問題型別。
例如,在分類問題中,我們應該使用一個可以衡量預測類別和實際類別之間差異的損失函式。
損失函式
對於我們將用神經網路模型解決的分類問題,交叉熵損失函式是最佳選擇。在 CNTK 中,它實現為cross_entropy_with_softmax,可以從cntk.losses包中匯入,如下所示:
label= input_variable(3) loss = cross_entropy_with_softmax(z, label)
指標
有了神經網路模型的結構和要應用的損失函式,我們就具備了開始制定最佳化深度學習模型方案的所有要素。但是,在深入研究之前,我們應該瞭解指標。
cntk.metrics
CNTK 有一個名為cntk.metrics的包,我們可以從中匯入我們將使用的指標。由於我們正在構建一個分類模型,我們將使用classification_error指標,它將產生一個介於 0 和 1 之間的數字。介於 0 和 1 之間的數字表示正確預測的樣本的百分比 -
首先,我們需要從cntk.metrics包中匯入指標 -
from cntk.metrics import classification_error error_rate = classification_error(z, label)
上述函式實際上需要神經網路的輸出和預期標籤作為輸入。
CNTK - 訓練神經網路
在這裡,我們將瞭解如何在 CNTK 中訓練神經網路。
在 CNTK 中訓練模型
在上一節中,我們已經定義了深度學習模型的所有元件。現在是時候訓練它了。正如我們前面討論的那樣,我們可以使用學習器和訓練器的組合在 CNTK 中訓練神經網路模型。
選擇學習器並設定訓練
在本節中,我們將定義學習器。CNTK 提供了多種學習器可供選擇。對於我們在前面幾節中定義的模型,我們將使用隨機梯度下降 (SGD) 學習器。
為了訓練神經網路,讓我們使用以下步驟配置學習器和訓練器 -
步驟1 − 首先,我們需要從cntk.learners包中匯入sgd函式。
from cntk.learners import sgd
步驟2 − 接下來,我們需要從cntk.train.trainer包中匯入Trainer函式。
from cntk.train.trainer import Trainer
步驟3 − 現在,我們需要建立一個學習器。可以透過呼叫sgd函式並提供模型的引數和學習率的值來建立它。
learner = sgd(z.parametrs, 0.01)
步驟4 − 最後,我們需要初始化訓練器。必須向其提供網路、損失和指標的組合以及學習器。
trainer = Trainer(z, (loss, error_rate), [learner])
控制最佳化速度的學習率應為 0.1 到 0.001 之間的較小數字。
選擇學習器並設定訓練 - 完整示例
from cntk.learners import sgd from cntk.train.trainer import Trainer learner = sgd(z.parametrs, 0.01) trainer = Trainer(z, (loss, error_rate), [learner])
將資料饋送到訓練器
一旦我們選擇並配置了訓練器,就該載入資料集了。我們將鳶尾花資料集儲存為 .CSV 檔案,我們將使用名為pandas的資料整理包來載入資料集。
從 .CSV 檔案載入資料集的步驟
步驟1 − 首先,我們需要匯入pandas包。
from import pandas as pd
步驟2 − 現在,我們需要呼叫名為read_csv的函式來從磁碟載入 .csv 檔案。
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, index_col=False)
載入資料集後,我們需要將其拆分為一組特徵和一個標籤。
將資料集拆分為特徵和標籤的步驟
步驟1 − 首先,我們需要從資料集中選擇所有行和前四列。這可以透過使用iloc函式來完成。
x = df_source.iloc[:, :4].values
步驟2 − 接下來,我們需要從鳶尾花資料集中選擇 species 列。我們將使用 values 屬性來訪問底層的numpy陣列。
x = df_source[‘species’].values
將 species 列編碼為數值向量表示的步驟
正如我們前面討論的那樣,我們的模型基於分類,它需要數值輸入值。因此,這裡我們需要將 species 列編碼為數值向量表示。讓我們看看執行此操作的步驟 -
步驟1 − 首先,我們需要建立一個列表表示式來迭代陣列中的所有元素。然後為每個值在 label_mapping 字典中執行查詢。
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
步驟2 − 接下來,將這個轉換後的數值轉換為獨熱編碼向量。我們將使用one_hot函式,如下所示 -
def one_hot(index, length): result = np.zeros(length) result[index] = 1 return result
步驟3 − 最後,我們需要將這個轉換後的列表轉換為numpy陣列。
y = np.array([one_hot(label_mapping[v], 3) for v in y])
檢測過擬合的步驟
當你的模型記住樣本但無法從訓練樣本中推匯出規則時,這種情況就是過擬合。藉助以下步驟,我們可以檢測模型的過擬合 -
步驟1 − 首先,從sklearn包的model_selection模組中匯入train_test_split函式。
from sklearn.model_selection import train_test_split
步驟2 − 接下來,我們需要使用特徵 x 和標籤 y 呼叫 train_test_split 函式,如下所示 -
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0-2, stratify=y)
我們指定了 0.2 的 test_size 以留出 20% 的總資料。
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
將訓練集和驗證集饋送到我們的模型的步驟
步驟1 − 為了訓練我們的模型,首先,我們將呼叫train_minibatch方法。然後向它提供一個字典,該字典將輸入資料對映到我們用來定義神經網路及其關聯損失函式的輸入變數。
trainer.train_minibatch({ features: X_train, label: y_train})
步驟2 − 接下來,使用以下 for 迴圈呼叫train_minibatch -
for _epoch in range(10):
trainer.train_minbatch ({ feature: X_train, label: y_train})
print(‘Loss: {}, Acc: {}’.format(
trainer.previous_minibatch_loss_average,
trainer.previous_minibatch_evaluation_average))
將資料饋送到訓練器 - 完整示例
from import pandas as pd
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, index_col=False)
x = df_source.iloc[:, :4].values
x = df_source[‘species’].values
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return result
y = np.array([one_hot(label_mapping[v], 3) for v in y])
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0-2, stratify=y)
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
trainer.train_minibatch({ features: X_train, label: y_train})
for _epoch in range(10):
trainer.train_minbatch ({ feature: X_train, label: y_train})
print(‘Loss: {}, Acc: {}’.format(
trainer.previous_minibatch_loss_average,
trainer.previous_minibatch_evaluation_average))
衡量神經網路的效能
為了最佳化我們的神經網路模型,每當我們透過訓練器傳遞資料時,它都會透過我們為訓練器配置的指標來衡量模型的效能。這種在訓練期間對神經網路模型效能的測量是在訓練資料上進行的。但另一方面,為了對模型效能進行全面分析,我們還需要使用測試資料。
因此,為了使用測試資料來衡量模型的效能,我們可以呼叫訓練器上的test_minibatch方法,如下所示 -
trainer.test_minibatch({ features: X_test, label: y_test})
使用神經網路進行預測
一旦你訓練了一個深度學習模型,最重要的事情就是使用它進行預測。為了使用上面訓練的神經網路進行預測,我們可以遵循以下步驟 -
步驟1 − 首先,我們需要使用以下函式從測試集中選擇一個隨機項 -
np.random.choice
步驟2 − 接下來,我們需要使用sample_index從測試集中選擇樣本資料。
步驟 3 − 現在,為了將神經網路 (NN) 的數值輸出轉換為實際標籤,建立一個反向對映。
步驟 4 − 現在,使用選定的樣本資料。透過呼叫 NN z 作為函式來進行預測。
步驟 5 − 現在,一旦你得到預測輸出,將值最大的神經元的索引作為預測值。可以使用numpy包中的np.argmax函式來實現。
步驟 6 − 最後,使用inverted_mapping將索引值轉換為真實標籤。
使用神經網路進行預測 -完整示例
sample_index = np.random.choice(X_test.shape[0])
sample = X_test[sample_index]
inverted_mapping = {
1:’Iris-setosa’,
2:’Iris-versicolor’,
3:’Iris-virginica’
}
prediction = z(sample)
predicted_label = inverted_mapping[np.argmax(prediction)]
print(predicted_label)
輸出
訓練上述深度學習模型並執行後,您將得到以下輸出:
Iris-versicolor
CNTK - 記憶體資料集和大型資料集
本章我們將學習如何在CNTK中處理記憶體中和大型資料集。
使用小型記憶體資料集進行訓練
當我們談到將資料饋送到CNTK訓練器時,可能有許多方法,但這將取決於資料集的大小和資料的格式。資料集可以是小型的記憶體資料集或大型資料集。
在本節中,我們將使用記憶體資料集。為此,我們將使用以下兩個框架:
- Numpy
- Pandas
使用Numpy陣列
在這裡,我們將使用基於numpy的隨機生成資料集在CNTK中工作。在這個例子中,我們將模擬二元分類問題的數 據。假設我們有一組具有4個特徵的觀察結果,並希望用我們的深度學習模型預測兩個可能的標籤。
實現示例
為此,我們首先必須生成一組包含標籤的獨熱向量表示的標籤,我們想要預測。這可以透過以下步驟完成:
步驟 1 − 如下匯入numpy包:
import numpy as np num_samples = 20000
步驟 2 − 接下來,使用np.eye函式生成標籤對映,如下所示:
label_mapping = np.eye(2)
步驟 3 − 現在,使用np.random.choice函式,收集20000個隨機樣本,如下所示:
y = label_mapping[np.random.choice(2,num_samples)].astype(np.float32)
步驟 4 − 現在最後使用np.random.random函式,生成一個隨機浮點值的陣列,如下所示:
x = np.random.random(size=(num_samples, 4)).astype(np.float32)
一旦我們生成一個隨機浮點值陣列,我們需要將它們轉換為32位浮點數,以便它可以與CNTK期望的格式匹配。讓我們按照以下步驟操作:
步驟 5 − 從cntk.layers模組匯入Dense和Sequential層函式,如下所示:
from cntk.layers import Dense, Sequential
步驟 6 − 現在,我們需要為網路中的層匯入啟用函式。讓我們匯入sigmoid作為啟用函式。
from cntk import input_variable, default_options from cntk.ops import sigmoid
步驟 7 − 現在,我們需要匯入損失函式來訓練網路。讓我們匯入binary_cross_entropy作為損失函式。
from cntk.losses import binary_cross_entropy
步驟 8 − 接下來,我們需要定義網路的預設選項。在這裡,我們將提供sigmoid啟用函式作為預設設定。還可以使用Sequential層函式建立模型,如下所示:
with default_options(activation=sigmoid): model = Sequential([Dense(6),Dense(2)])
步驟 9 − 接下來,初始化一個具有4個輸入特徵的input_variable作為網路的輸入。
features = input_variable(4)
步驟 10 − 現在,為了完成它,我們需要將特徵變數連線到NN。
z = model(features)
所以,現在我們有一個NN,藉助以下步驟,讓我們使用記憶體資料集對其進行訓練:
步驟 11 − 要訓練此NN,首先需要從cntk.learners模組匯入學習器。我們將匯入sgd學習器,如下所示:
from cntk.learners import sgd
步驟 12 − 同時從cntk.logging模組匯入ProgressPrinter。
from cntk.logging import ProgressPrinter progress_writer = ProgressPrinter(0)
步驟 13 − 接下來,為標籤定義一個新的輸入變數,如下所示:
labels = input_variable(2)
步驟 14 − 為了訓練NN模型,接下來,我們需要使用binary_cross_entropy函式定義損失。還要提供模型z和標籤變數。
loss = binary_cross_entropy(z, labels)
步驟 15 − 接下來,初始化sgd學習器,如下所示:
learner = sgd(z.parameters, lr=0.1)
步驟 16 − 最後,在損失函式上呼叫train方法。還要提供輸入資料、sgd學習器和progress_printer。
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=[progress_writer])
完整的實現示例
import numpy as np num_samples = 20000 label_mapping = np.eye(2) y = label_mapping[np.random.choice(2,num_samples)].astype(np.float32) x = np.random.random(size=(num_samples, 4)).astype(np.float32) from cntk.layers import Dense, Sequential from cntk import input_variable, default_options from cntk.ops import sigmoid from cntk.losses import binary_cross_entropy with default_options(activation=sigmoid): model = Sequential([Dense(6),Dense(2)]) features = input_variable(4) z = model(features) from cntk.learners import sgd from cntk.logging import ProgressPrinter progress_writer = ProgressPrinter(0) labels = input_variable(2) loss = binary_cross_entropy(z, labels) learner = sgd(z.parameters, lr=0.1) training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=[progress_writer])
輸出
Build info:
Built time: *** ** **** 21:40:10
Last modified date: *** *** ** 21:08:46 2019
Build type: Release
Build target: CPU-only
With ASGD: yes
Math lib: mkl
Build Branch: HEAD
Build SHA1:ae9c9c7c5f9e6072cc9c94c254f816dbdc1c5be6 (modified)
MPI distribution: Microsoft MPI
MPI version: 7.0.12437.6
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.52 1.52 0 0 32
1.51 1.51 0 0 96
1.48 1.46 0 0 224
1.45 1.42 0 0 480
1.42 1.4 0 0 992
1.41 1.39 0 0 2016
1.4 1.39 0 0 4064
1.39 1.39 0 0 8160
1.39 1.39 0 0 16352
使用Pandas DataFrames
Numpy陣列在其可以包含的內容方面非常有限,並且是儲存資料的最基本方法之一。例如,單個n維陣列可以包含單個數據型別的資料。但另一方面,對於許多現實世界的案例,我們需要一個可以處理單個數據集中多個數據型別的庫。
名為Pandas的Python庫之一使處理此類資料集更容易。它引入了DataFrame (DF)的概念,並允許我們將儲存在各種格式中的磁碟資料集載入為DF。例如,我們可以讀取儲存為CSV、JSON、Excel等的DF。
您可以在 https://tutorialspoint.tw/python_pandas/index.htm瞭解更多關於Python Pandas庫的細節。
實現示例
在這個例子中,我們將使用根據四個屬性對三種可能的鳶尾花物種進行分類的例子。我們之前也已經建立了這個深度學習模型。模型如下:
from cntk.layers import Dense, Sequential from cntk import input_variable, default_options from cntk.ops import sigmoid, log_softmax from cntk.losses import binary_cross_entropy model = Sequential([ Dense(4, activation=sigmoid), Dense(3, activation=log_softmax) ]) features = input_variable(4) z = model(features)
上述模型包含一個隱藏層和一個具有三個神經元的輸出層,以匹配我們可以預測的類別數。
接下來,我們將使用train方法和loss函式來訓練網路。為此,我們必須首先載入和預處理鳶尾花資料集,使其與NN的預期佈局和資料格式匹配。這可以透過以下步驟完成:
步驟 1 − 如下匯入numpy和Pandas包:
import numpy as np import pandas as pd
步驟 2 − 接下來,使用read_csv函式將資料集載入到記憶體中:
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, ‘species’], index_col=False)
步驟 3 − 現在,我們需要建立一個字典,它將資料集中的標籤與其對應的數字表示進行對映。
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
步驟 4 − 現在,透過在DataFrame上使用iloc索引器,選擇前四列,如下所示:
x = df_source.iloc[:, :4].values
步驟 5 −接下來,我們需要選擇物種列作為資料集的標籤。這可以按如下方式完成:
y = df_source[‘species’].values
步驟 6 − 現在,我們需要對映資料集中的標籤,這可以透過使用label_mapping來完成。還要使用one-hot編碼將它們轉換為one-hot編碼陣列。
y = np.array([one_hot(label_mapping[v], 3) for v in y])
步驟 7 − 接下來,要將特徵和對映的標籤與CNTK一起使用,我們需要將它們都轉換為浮點數:
x= x.astype(np.float32) y= y.astype(np.float32)
眾所周知,標籤以字串形式儲存在資料集中,而CNTK無法使用這些字串。這就是為什麼它需要表示標籤的one-hot編碼向量。為此,我們可以定義一個函式,例如one-hot,如下所示:
def one_hot(index, length): result = np.zeros(length) result[index] = index return result
現在,我們有了正確格式的numpy陣列,藉助以下步驟,我們可以使用它們來訓練我們的模型:
步驟 8 − 首先,我們需要匯入損失函式來訓練網路。讓我們匯入binary_cross_entropy_with_softmax作為損失函式:
from cntk.losses import binary_cross_entropy_with_softmax
步驟 9 − 要訓練此NN,我們還需要從cntk.learners模組匯入學習器。我們將匯入sgd學習器,如下所示:
from cntk.learners import sgd
步驟 10 − 同時從cntk.logging模組匯入ProgressPrinter。
from cntk.logging import ProgressPrinter progress_writer = ProgressPrinter(0)
步驟 11 − 接下來,為標籤定義一個新的輸入變數,如下所示:
labels = input_variable(3)
步驟 12 − 為了訓練NN模型,接下來,我們需要使用binary_cross_entropy_with_softmax函式定義損失。還要提供模型z和標籤變數。
loss = binary_cross_entropy_with_softmax (z, labels)
步驟 13 − 接下來,初始化sgd學習器,如下所示:
learner = sgd(z.parameters, 0.1)
步驟 14 − 最後,在損失函式上呼叫train方法。還要提供輸入資料、sgd學習器和progress_printer。
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks= [progress_writer],minibatch_size=16,max_epochs=5)
完整的實現示例
from cntk.layers import Dense, Sequential
from cntk import input_variable, default_options
from cntk.ops import sigmoid, log_softmax
from cntk.losses import binary_cross_entropy
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
z = model(features)
import numpy as np
import pandas as pd
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, ‘species’], index_col=False)
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
x = df_source.iloc[:, :4].values
y = df_source[‘species’].values
y = np.array([one_hot(label_mapping[v], 3) for v in y])
x= x.astype(np.float32)
y= y.astype(np.float32)
def one_hot(index, length):
result = np.zeros(length)
result[index] = index
return result
from cntk.losses import binary_cross_entropy_with_softmax
from cntk.learners import sgd
from cntk.logging import ProgressPrinter
progress_writer = ProgressPrinter(0)
labels = input_variable(3)
loss = binary_cross_entropy_with_softmax (z, labels)
learner = sgd(z.parameters, 0.1)
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=[progress_writer],minibatch_size=16,max_epochs=5)
輸出
Build info:
Built time: *** ** **** 21:40:10
Last modified date: *** *** ** 21:08:46 2019
Build type: Release
Build target: CPU-only
With ASGD: yes
Math lib: mkl
Build Branch: HEAD
Build SHA1:ae9c9c7c5f9e6072cc9c94c254f816dbdc1c5be6 (modified)
MPI distribution: Microsoft MPI
MPI version: 7.0.12437.6
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.1 1.1 0 0 16
0.835 0.704 0 0 32
1.993 1.11 0 0 48
1.14 1.14 0 0 112
[………]
使用大型資料集進行訓練
在上一節中,我們使用Numpy和pandas處理了小型記憶體資料集,但並非所有資料集都這麼小。特別是包含影像、影片、聲音樣本的資料集很大。MinibatchSource是一個元件,它可以分塊載入資料,由CNTK提供,用於處理此類大型資料集。MinibatchSource元件的一些特性如下:
MinibatchSource可以透過自動隨機化從資料來源讀取的樣本,防止NN過度擬合。
它具有內建的轉換管道,可用於增強資料。
它在與訓練過程分開的後臺執行緒上載入資料。
在以下各節中,我們將探討如何將小批次源與記憶體外資料一起使用以處理大型資料集。我們還將探討如何使用它來饋送用於訓練NN的資料。
建立MinibatchSource例項
在上一節中,我們使用了鳶尾花示例,並使用Pandas DataFrames處理了小型記憶體資料集。在這裡,我們將使用MinibatchSource替換使用來自pandas DF的資料的程式碼。首先,我們需要使用以下步驟建立一個MinibatchSource例項:
實現示例
步驟 1 − 首先,從cntk.io模組匯入小批次源的元件,如下所示:
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer, INFINITY_REPEAT
步驟 2 − 現在,使用StreamDef類,為標籤建立一個流定義。
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)
步驟 3 − 接下來,要讀取輸入檔案中的特徵欄位,請建立另一個StreamDef例項,如下所示。
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)
步驟 4 − 現在,我們需要提供iris.ctf檔案作為輸入並初始化deserializer,如下所示:
deserializer = CTFDeserializer(‘iris.ctf’, StreamDefs(labels= label_stream, features=features_stream)
步驟 5 − 最後,我們需要使用deserializer建立minisourceBatch例項,如下所示:
Minibatch_source = MinibatchSource(deserializer, randomize=True)
建立MinibatchSource例項 - 完整實現示例
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer, INFINITY_REPEAT labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False) feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False) deserializer = CTFDeserializer(‘iris.ctf’, StreamDefs(labels=label_stream, features=features_stream) Minibatch_source = MinibatchSource(deserializer, randomize=True)
建立MCTF檔案
正如您在上面看到的,我們正在從“iris.ctf”檔案獲取資料。它具有稱為CNTK文字格式(CTF)的檔案格式。必須建立一個CTF檔案才能獲取上面建立的MinibatchSource例項的資料。讓我們看看如何建立一個CTF檔案。
實現示例
步驟 1 − 首先,我們需要匯入pandas和numpy包,如下所示:
import pandas as pd import numpy as np
步驟 2 − 接下來,我們需要將我們的資料檔案(即iris.csv)載入到記憶體中。然後,將其儲存在df_source變數中。
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, ‘species’], index_col=False)
步驟 3 − 現在,使用iloc索引器作為特徵,獲取前四列的內容。還要使用來自物種列的資料,如下所示:
features = df_source.iloc[: , :4].values labels = df_source[‘species’].values
步驟 4 − 接下來,我們需要建立標籤名稱與其數字表示之間的對映。這可以透過建立label_mapping來完成,如下所示:
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
步驟 5 − 現在,將標籤轉換為一組one-hot編碼向量,如下所示:
labels = [one_hot(label_mapping[v], 3) for v in labels]
現在,正如我們之前所做的那樣,建立一個名為one-hot的實用函式來編碼標籤。這可以透過以下方式完成:
def one_hot(index, length): result = np.zeros(length) result[index] = 1 return result
由於我們已經載入並預處理了資料,因此是時候將其以CTF檔案格式儲存在磁碟上了。我們可以使用以下Python程式碼來實現:
With open(‘iris.ctf’, ‘w’) as output_file:
for index in range(0, feature.shape[0]):
feature_values = ‘ ‘.join([str(x) for x in np.nditer(features[index])])
label_values = ‘ ‘.join([str(x) for x in np.nditer(labels[index])])
output_file.write(‘features {} | labels {} \n’.format(feature_values, label_values))
建立MCTF檔案 - 完整實現示例
import pandas as pd
import numpy as np
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, ‘species’], index_col=False)
features = df_source.iloc[: , :4].values
labels = df_source[‘species’].values
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
labels = [one_hot(label_mapping[v], 3) for v in labels]
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return result
With open(‘iris.ctf’, ‘w’) as output_file:
for index in range(0, feature.shape[0]):
feature_values = ‘ ‘.join([str(x) for x in np.nditer(features[index])])
label_values = ‘ ‘.join([str(x) for x in np.nditer(labels[index])])
output_file.write(‘features {} | labels {} \n’.format(feature_values, label_values))
資料饋送
建立**MinibatchSource**例項後,我們需要對其進行訓練。我們可以使用與處理小型記憶體資料集時相同的訓練邏輯。這裡,我們將使用**MinibatchSource**例項作為損失函式訓練方法的輸入,如下所示:
實現示例
**步驟 1** - 為了記錄訓練會話的輸出,首先從**cntk.logging**模組匯入ProgressPrinter,如下所示:
from cntk.logging import ProgressPrinter
**步驟 2** - 接下來,要設定訓練會話,請從**cntk.train**模組匯入**trainer**和**training_session**,如下所示:
from cntk.train import Trainer,
**步驟 3** - 現在,我們需要定義一些常量,例如**minibatch_size**、**samples_per_epoch**和**num_epochs**,如下所示:
minbatch_size = 16 samples_per_epoch = 150 num_epochs = 30
**步驟 4** - 接下來,為了讓CNTK知道如何在訓練期間讀取資料,我們需要定義網路輸入變數和微批次源中的流之間的對映。
input_map = {
features: minibatch.source.streams.features,
labels: minibatch.source.streams.features
}
**步驟 5** - 接下來,要記錄訓練過程的輸出,請使用新的**ProgressPrinter**例項初始化**progress_printer**變數,如下所示:
progress_writer = ProgressPrinter(0)
**步驟 6** - 最後,我們需要在損失上呼叫train方法,如下所示:
train_history = loss.train(minibatch_source, parameter_learners=[learner], model_inputs_to_streams=input_map, callbacks=[progress_writer], epoch_size=samples_per_epoch, max_epochs=num_epochs)
資料饋送 - 完整的實現示例
from cntk.logging import ProgressPrinter
from cntk.train import Trainer, training_session
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30
input_map = {
features: minibatch.source.streams.features,
labels: minibatch.source.streams.features
}
progress_writer = ProgressPrinter(0)
train_history = loss.train(minibatch_source,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer],
epoch_size=samples_per_epoch,
max_epochs=num_epochs)
輸出
------------------------------------------------------------------- average since average since examples loss last metric last ------------------------------------------------------ Learning rate per minibatch: 0.1 1.21 1.21 0 0 32 1.15 0.12 0 0 96 [………]
CNTK - 效能測量
本章將解釋如何在CNKT中衡量模型效能。
驗證模型效能的策略
構建機器學習模型後,我們通常使用一組資料樣本對其進行訓練。透過這種訓練,我們的機器學習模型學習並推匯出一些一般規則。當我們將新樣本(即與訓練時提供的樣本不同的樣本)饋送到模型時,機器學習模型的效能至關重要。在這種情況下,模型的行為會有所不同。它在對這些新樣本進行良好預測方面可能效果較差。
但模型也必須對新樣本表現良好,因為在生產環境中,我們將獲得與用於訓練目的的樣本資料不同的輸入。因此,我們應該使用一組與用於訓練目的的樣本不同的樣本驗證機器學習模型。在這裡,我們將討論兩種不同的技術來建立用於驗證神經網路的資料集。
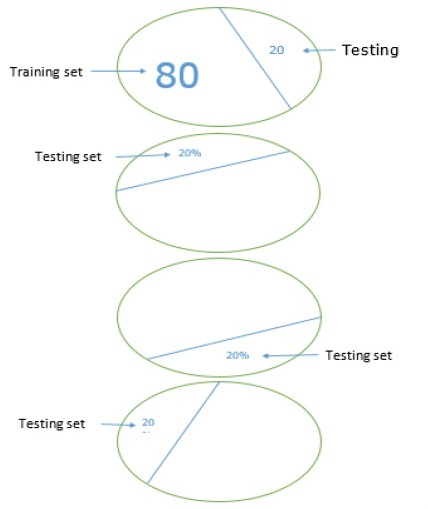
留出資料集
這是建立用於驗證神經網路的資料集的最簡單方法之一。顧名思義,在這種方法中,我們將從訓練中保留一組樣本(例如20%),並用它來測試我們機器學習模型的效能。下圖顯示了訓練樣本和驗證樣本之間的比例:

留出資料集模型確保我們有足夠的資料來訓練我們的機器學習模型,同時我們也將有合理的樣本數量來獲得對模型效能的良好衡量。
為了包含在訓練集和測試集中,最好從主資料集中選擇隨機樣本。它確保訓練集和測試集之間均勻分佈。
以下是一個例子,我們使用**scikit-learn**庫中的**train_test_split**函式建立自己的留出資料集。
示例
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# Here above test_size = 0.2 represents that we provided 20% of the data as test data.
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
classifier_knn = KNeighborsClassifier(n_neighbors=3)
classifier_knn.fit(X_train, y_train)
y_pred = classifier_knn.predict(X_test)
# Providing sample data and the model will make prediction out of that data
sample = [[5, 5, 3, 2], [2, 4, 3, 5]]
preds = classifier_knn.predict(sample)
pred_species = [iris.target_names[p] for p in preds] print("Predictions:", pred_species)
輸出
Predictions: ['versicolor', 'virginica']
在使用CNTK時,每次訓練模型時都需要隨機化資料集的順序,因為:
深度學習演算法受隨機數生成器的強烈影響。
我們在訓練期間向神經網路提供樣本的順序極大地影響其效能。
使用留出資料集技術的主要缺點是它不可靠,因為有時我們會得到非常好的結果,但有時我們會得到糟糕的結果。
K折交叉驗證
為了使我們的機器學習模型更可靠,有一種稱為K折交叉驗證的技術。本質上,K折交叉驗證技術與之前的技術相同,但它會重複多次——通常約5到10次。下圖表示其概念:
K折交叉驗證的工作原理
可以透過以下步驟瞭解K折交叉驗證的工作原理:
**步驟 1** - 與留出資料集技術一樣,在K折交叉驗證技術中,首先需要將資料集分成訓練集和測試集。理想情況下,比例為80-20,即80%的訓練集和20%的測試集。
**步驟 2** - 接下來,我們需要使用訓練集訓練我們的模型。
**步驟 3** - 最後,我們將使用測試集來衡量模型的效能。留出資料集技術和k折交叉驗證技術之間的唯一區別在於,上述過程通常會重複5到10次,最後計算所有效能指標的平均值。該平均值將是最終的效能指標。
讓我們來看一個小型資料集的例子:
示例
from numpy import array
from sklearn.model_selection import KFold
data = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
kfold = KFold(5, True, 1)
for train, test in kfold.split(data):
print('train: %s, test: %s' % (data[train],(data[test]))
輸出
train: [0.1 0.2 0.4 0.5 0.6 0.7 0.8 0.9], test: [0.3 1. ] train: [0.1 0.2 0.3 0.4 0.6 0.8 0.9 1. ], test: [0.5 0.7] train: [0.2 0.3 0.5 0.6 0.7 0.8 0.9 1. ], test: [0.1 0.4] train: [0.1 0.3 0.4 0.5 0.6 0.7 0.9 1. ], test: [0.2 0.8] train: [0.1 0.2 0.3 0.4 0.5 0.7 0.8 1. ], test: [0.6 0.9]
正如我們看到的,由於使用了更現實的訓練和測試場景,k折交叉驗證技術為我們提供了更穩定的效能衡量,但缺點是驗證深度學習模型時需要花費大量時間。
CNTK不支援k折交叉驗證,因此我們需要編寫自己的指令碼來實現。
檢測欠擬合和過擬合
無論我們使用留出資料集還是k折交叉驗證技術,我們都會發現指標的輸出對於用於訓練的資料集和用於驗證的資料集將是不同的。
檢測過擬合
所謂的過擬合現象是指我們的機器學習模型對訓練資料建模非常出色,但在測試資料上表現不佳,即無法預測測試資料。
當機器學習模型學習訓練資料中的特定模式和噪聲到一定程度時,就會發生這種情況,這會對模型從訓練資料泛化到新的(即未見過的)資料的能力產生負面影響。在這裡,噪聲是資料集中不相關的信噪比或隨機性。
以下是我們可以用來檢測我們的模型是否過擬合的兩種方法:
過擬合模型將在我們用於訓練的相同樣本上表現良好,但在新樣本(即與訓練樣本不同的樣本)上表現非常差。
如果測試集上的指標低於我們在訓練集上使用的相同指標,則模型在驗證期間過擬合。
檢測欠擬合
在我們的機器學習中可能出現的另一種情況是欠擬合。在這種情況下,我們的機器學習模型沒有很好地對訓練資料建模,並且無法預測有用的輸出。當我們開始訓練第一個時期時,我們的模型將欠擬合,但隨著訓練的進行,欠擬合程度會降低。
檢測我們的模型是否欠擬合的一種方法是檢視訓練集和測試集的指標。如果測試集上的指標高於訓練集上的指標,則我們的模型將欠擬合。
CNTK - 神經網路分類
在本章中,我們將學習如何使用CNTK對神經網路進行分類。
簡介
分類可以定義為根據給定的輸入資料預測類別輸出標籤或響應的過程。基於模型在訓練階段學習到的內容的分類輸出可以採用“黑色”或“白色”或“垃圾郵件”或“非垃圾郵件”等形式。
另一方面,在數學上,它是逼近對映函式(例如**f**)的任務,該函式將輸入變數(例如X)對映到輸出變數(例如Y)。
分類問題的經典例子可以是電子郵件中的垃圾郵件檢測。很明顯,輸出只有兩個類別,“垃圾郵件”和“非垃圾郵件”。
為了實現這種分類,我們首先需要對分類器進行訓練,其中“垃圾郵件”和“非垃圾郵件”電子郵件將用作訓練資料。一旦分類器成功訓練,就可以用來檢測未知的電子郵件。
在這裡,我們將使用虹膜花資料集建立一個4-5-3神經網路,該資料集具有以下特徵:
4個輸入節點(每個預測值一個)。
5個隱藏處理節點。
3個輸出節點(因為虹膜資料集中有三種可能的物種)。
載入資料集
我們將使用虹膜花資料集,我們希望根據萼片寬度和長度以及花瓣寬度和長度的物理特性對虹膜花的種類進行分類。該資料集描述了不同品種的虹膜花的物理特性:
萼片長度
萼片寬度
花瓣長度
花瓣寬度
類別,即山鳶尾、雜色鳶尾或弗吉尼亞鳶尾
我們有**iris.CSV**檔案,我們在之前的章節中也使用過它。它可以用**Pandas**庫的幫助載入。但是,在我們使用它或將其載入到我們的分類器中之前,我們需要準備訓練和測試檔案,以便它可以輕鬆地與CNTK一起使用。
準備訓練和測試檔案
虹膜資料集是機器學習專案中最流行的資料集之一。它有150個數據項,原始資料如下所示:
5.1 3.5 1.4 0.2 setosa 4.9 3.0 1.4 0.2 setosa … 7.0 3.2 4.7 1.4 versicolor 6.4 3.2 4.5 1.5 versicolor … 6.3 3.3 6.0 2.5 virginica 5.8 2.7 5.1 1.9 virginica
如前所述,每行前四個值描述了不同品種的物理特性,即虹膜花的萼片長度、萼片寬度、花瓣長度、花瓣寬度。
但是,我們必須將資料轉換為可以被CNTK輕鬆使用的格式,該格式是.ctf檔案(我們在上一節中也建立了一個iris.ctf檔案)。它將如下所示:
|attribs 5.1 3.5 1.4 0.2|species 1 0 0 |attribs 4.9 3.0 1.4 0.2|species 1 0 0 … |attribs 7.0 3.2 4.7 1.4|species 0 1 0 |attribs 6.4 3.2 4.5 1.5|species 0 1 0 … |attribs 6.3 3.3 6.0 2.5|species 0 0 1 |attribs 5.8 2.7 5.1 1.9|species 0 0 1
在上述資料中,|attribs標籤標記特徵值的開始,|species標籤標記類標籤值。我們也可以使用任何其他我們想要的標籤名稱,甚至可以新增專案ID。例如,請看以下資料:
|ID 001 |attribs 5.1 3.5 1.4 0.2|species 1 0 0 |#setosa |ID 002 |attribs 4.9 3.0 1.4 0.2|species 1 0 0 |#setosa … |ID 051 |attribs 7.0 3.2 4.7 1.4|species 0 1 0 |#versicolor |ID 052 |attribs 6.4 3.2 4.5 1.5|species 0 1 0 |#versicolor …
虹膜資料集中共有150個數據項,對於此示例,我們將使用80-20留出資料集規則,即80%(120個專案)的資料項用於訓練目的,其餘20%(30個專案)的資料項用於測試目的。
構建分類模型
首先,我們需要處理CNTK格式的資料檔案,為此我們將使用名為**create_reader**的輔助函式,如下所示:
def create_reader(path, input_dim, output_dim, rnd_order, sweeps): x_strm = C.io.StreamDef(field='attribs', shape=input_dim, is_sparse=False) y_strm = C.io.StreamDef(field='species', shape=output_dim, is_sparse=False) streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm) deserial = C.io.CTFDeserializer(path, streams) mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps) return mb_src
現在,我們需要為我們的神經網路設定體系結構引數,並提供資料檔案的位置。這可以使用以下python程式碼完成:
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 5
output_dim = 3
train_file = ".\\...\\" #provide the name of the training file(120 data items)
test_file = ".\\...\\" #provide the name of the test file(30 data items)
現在,藉助以下程式碼行,我們的程式將建立未經訓練的神經網路:
X = C.ops.input_variable(input_dim, np.float32) Y = C.ops.input_variable(output_dim, np.float32) with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)): hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X) oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer) nnet = oLayer model = C.ops.softmax(nnet)
現在,一旦我們建立了未經訓練的雙重模型,我們需要設定一個Learner演算法物件,然後使用它來建立一個Trainer訓練物件。我們將使用SGD學習器和**cross_entropy_with_softmax**損失函式:
tr_loss = C.cross_entropy_with_softmax(nnet, Y) tr_clas = C.classification_error(nnet, Y) max_iter = 2000 batch_size = 10 learn_rate = 0.01 learner = C.sgd(nnet.parameters, learn_rate) trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
編寫學習演算法如下:
max_iter = 2000 batch_size = 10 lr_schedule = C.learning_parameter_schedule_per_sample([(1000, 0.05), (1, 0.01)]) mom_sch = C.momentum_schedule([(100, 0.99), (0, 0.95)], batch_size) learner = C.fsadagrad(nnet.parameters, lr=lr_schedule, momentum=mom_sch) trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
現在,一旦我們完成了Trainer物件,我們需要建立一個reader函式來讀取訓練資料:
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
現在是訓練我們的神經網路模型的時候了:
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))
一旦我們完成了訓練,讓我們使用測試資料項評估模型:
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 30
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)
在評估我們訓練好的神經網路模型的準確性之後,我們將使用它對未見資料進行預測:
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[6.4, 3.2, 4.5, 1.5]], dtype=np.float32)
print("\nPredicting Iris species for input features: ")
print(unknown[0]) pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities are: ")
print(pred_prob[0])
完整的分類模型
Import numpy as np
Import cntk as C
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='attribs', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='species', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 5
output_dim = 3
train_file = ".\\...\\" #provide the name of the training file(120 data items)
test_file = ".\\...\\" #provide the name of the test file(30 data items)
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 2000
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
max_iter = 2000
batch_size = 10
lr_schedule = C.learning_parameter_schedule_per_sample([(1000, 0.05), (1, 0.01)])
mom_sch = C.momentum_schedule([(100, 0.99), (0, 0.95)], batch_size)
learner = C.fsadagrad(nnet.parameters, lr=lr_schedule, momentum=mom_sch)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 30
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[7.0, 3.2, 4.7, 1.4]], dtype=np.float32)
print("\nPredicting species for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities: ")
print(pred_prob[0])
if __name__== ”__main__”:
main()
輸出
Using CNTK version = 2.7 batch 0: mean loss = 1.0986, mean accuracy = 40.00% batch 500: mean loss = 0.6677, mean accuracy = 80.00% batch 1000: mean loss = 0.5332, mean accuracy = 70.00% batch 1500: mean loss = 0.2408, mean accuracy = 100.00% Evaluating test data Classification accuracy = 94.58% Predicting species for input features: [7.0 3.2 4.7 1.4] Prediction probabilities: [0.0847 0.736 0.113]
儲存訓練好的模型
這個 Iris 資料集只有 150 個數據項,因此訓練 NN 分類器模型只需要幾秒鐘,但是在一個擁有數百或數千個數據項的大型資料集上訓練可能需要數小時甚至數天。
我們可以儲存我們的模型,這樣我們就不用從頭開始重新訓練了。藉助以下 Python 程式碼,我們可以儲存我們訓練好的 NN:
nn_classifier = “.\\neuralclassifier.model” #provide the name of the file model.save(nn_classifier, format=C.ModelFormat.CNTKv2)
以下是上面使用的 save() 函式的引數:
檔名是 save() 函式的第一個引數。它也可以與檔案路徑一起寫入。
另一個引數是 format 引數,其預設值為 C.ModelFormat.CNTKv2。
載入訓練好的模型
儲存訓練好的模型後,載入該模型非常容易。我們只需要使用 load() 函式。讓我們在下面的例子中檢查一下:
import numpy as np
import cntk as C
model = C.ops.functions.Function.load(“.\\neuralclassifier.model”)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[7.0, 3.2, 4.7, 1.4]], dtype=np.float32)
print("\nPredicting species for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities: ")
print(pred_prob[0])
儲存模型的好處是,一旦載入了儲存的模型,就可以像剛剛訓練好的模型一樣使用。
CNTK - 神經網路二元分類
本章讓我們瞭解一下如何使用 CNTK 進行神經網路二元分類。
使用 NN 進行二元分類類似於多類分類,唯一不同的是隻有兩個輸出節點,而不是三個或更多。在這裡,我們將使用兩種技術(單節點和雙節點技術)使用神經網路進行二元分類。單節點技術比雙節點技術更常見。
載入資料集
為了使用 NN 實現這兩種技術,我們將使用鈔票資料集。該資料集可以從 UCI 機器學習資源庫下載,網址為 https://archive.ics.uci.edu/ml/datasets/banknote+authentication。
在我們的示例中,我們將使用 50 個真鈔資料項(偽造類 = 0),和前 50 個假鈔資料項(偽造類 = 1)。
準備訓練和測試檔案
完整的資料集有 1372 個數據項。原始資料集如下所示:
3.6216, 8.6661, -2.8076, -0.44699, 0 4.5459, 8.1674, -2.4586, -1.4621, 0 … -1.3971, 3.3191, -1.3927, -1.9948, 1 0.39012, -0.14279, -0.031994, 0.35084, 1
現在,首先我們需要將此原始資料轉換為雙節點 CNTK 格式,如下所示:
|stats 3.62160000 8.66610000 -2.80730000 -0.44699000 |forgery 0 1 |# authentic |stats 4.54590000 8.16740000 -2.45860000 -1.46210000 |forgery 0 1 |# authentic . . . |stats -1.39710000 3.31910000 -1.39270000 -1.99480000 |forgery 1 0 |# fake |stats 0.39012000 -0.14279000 -0.03199400 0.35084000 |forgery 1 0 |# fake
您可以使用以下 Python 程式從原始資料建立 CNTK 格式的資料:
fin = open(".\\...", "r") #provide the location of saved dataset text file.
for line in fin:
line = line.strip()
tokens = line.split(",")
if tokens[4] == "0":
print("|stats %12.8f %12.8f %12.8f %12.8f |forgery 0 1 |# authentic" % \
(float(tokens[0]), float(tokens[1]), float(tokens[2]), float(tokens[3])) )
else:
print("|stats %12.8f %12.8f %12.8f %12.8f |forgery 1 0 |# fake" % \
(float(tokens[0]), float(tokens[1]), float(tokens[2]), float(tokens[3])) )
fin.close()
雙節點二元分類模型
雙節點分類和多類分類之間幾乎沒有區別。在這裡,我們首先需要處理 CNTK 格式的資料檔案,為此我們將使用名為 create_reader 的輔助函式,如下所示:
def create_reader(path, input_dim, output_dim, rnd_order, sweeps): x_strm = C.io.StreamDef(field='stats', shape=input_dim, is_sparse=False) y_strm = C.io.StreamDef(field='forgery', shape=output_dim, is_sparse=False) streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm) deserial = C.io.CTFDeserializer(path, streams) mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps) return mb_src
現在,我們需要為我們的神經網路設定體系結構引數,並提供資料檔案的位置。這可以使用以下python程式碼完成:
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 10
output_dim = 2
train_file = ".\\...\\" #provide the name of the training file
test_file = ".\\...\\" #provide the name of the test file
現在,藉助以下程式碼行,我們的程式將建立未經訓練的神經網路:
X = C.ops.input_variable(input_dim, np.float32) Y = C.ops.input_variable(output_dim, np.float32) with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)): hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X) oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer) nnet = oLayer model = C.ops.softmax(nnet)
現在,一旦我們建立了未經訓練的雙節點模型,我們需要設定一個 Learner 演算法物件,然後使用它來建立一個 Trainer 訓練物件。我們將使用 SGD 學習器和 cross_entropy_with_softmax 損失函式:
tr_loss = C.cross_entropy_with_softmax(nnet, Y) tr_clas = C.classification_error(nnet, Y) max_iter = 500 batch_size = 10 learn_rate = 0.01 learner = C.sgd(nnet.parameters, learn_rate) trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
現在,一旦我們完成了 Trainer 物件,我們需要建立一個 reader 函式來讀取訓練資料:
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
現在,是時候訓練我們的 NN 模型了:
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))
訓練完成後,讓我們使用測試資料項評估模型:
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)
在評估我們訓練好的神經網路模型的準確性之後,我們將使用它對未見資料進行預測:
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[0.6, 1.9, -3.3, -0.3]], dtype=np.float32)
print("\nPredicting Banknote authenticity for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities are: ")
print(pred_prob[0])
if pred_prob[0,0] < pred_prob[0,1]:
print(“Prediction: authentic”)
else:
print(“Prediction: fake”)
完整的雙節點分類模型
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='stats', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='forgery', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 10
output_dim = 2
train_file = ".\\...\\" #provide the name of the training file
test_file = ".\\...\\" #provide the name of the test file
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
withC.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 500
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[0.6, 1.9, -3.3, -0.3]], dtype=np.float32)
print("\nPredicting Banknote authenticity for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities are: ")
print(pred_prob[0])
if pred_prob[0,0] < pred_prob[0,1]:
print(“Prediction: authentic”)
else:
print(“Prediction: fake”)
if __name__== ”__main__”:
main()
輸出
Using CNTK version = 2.7 batch 0: mean loss = 0.6928, accuracy = 80.00% batch 50: mean loss = 0.6877, accuracy = 70.00% batch 100: mean loss = 0.6432, accuracy = 80.00% batch 150: mean loss = 0.4978, accuracy = 80.00% batch 200: mean loss = 0.4551, accuracy = 90.00% batch 250: mean loss = 0.3755, accuracy = 90.00% batch 300: mean loss = 0.2295, accuracy = 100.00% batch 350: mean loss = 0.1542, accuracy = 100.00% batch 400: mean loss = 0.1581, accuracy = 100.00% batch 450: mean loss = 0.1499, accuracy = 100.00% Evaluating test data Classification accuracy = 84.58% Predicting banknote authenticity for input features: [0.6 1.9 -3.3 -0.3] Prediction probabilities are: [0.7847 0.2536] Prediction: fake
單節點二元分類模型
實現程式與我們上面針對雙節點分類所做的幾乎一樣。主要區別在於使用雙節點分類技術時。
我們可以使用 CNTK 內建的 classification_error() 函式,但在單節點分類中,CNTK 不支援 classification_error() 函式。這就是我們需要實現一個程式定義的函式的原因,如下所示:
def class_acc(mb, x_var, y_var, model): num_correct = 0; num_wrong = 0 x_mat = mb[x_var].asarray() y_mat = mb[y_var].asarray() for i in range(mb[x_var].shape[0]): p = model.eval(x_mat[i] y = y_mat[i] if p[0,0] < 0.5 and y[0,0] == 0.0 or p[0,0] >= 0.5 and y[0,0] == 1.0: num_correct += 1 else: num_wrong += 1 return (num_correct * 100.0)/(num_correct + num_wrong)
有了這個改變,讓我們看看完整的單節點分類示例:
完整的單節點分類模型
import numpy as np
import cntk as C
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='stats', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='forgery', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def class_acc(mb, x_var, y_var, model):
num_correct = 0; num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
p = model.eval(x_mat[i]
y = y_mat[i]
if p[0,0] < 0.5 and y[0,0] == 0.0 or p[0,0] >= 0.5 and y[0,0] == 1.0:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 10
output_dim = 1
train_file = ".\\...\\" #provide the name of the training file
test_file = ".\\...\\" #provide the name of the test file
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
model = oLayer
tr_loss = C.cross_entropy_with_softmax(model, Y)
max_iter = 1000
batch_size = 10
learn_rate = 0.01
learner = C.sgd(model.parameters, learn_rate)
trainer = C.Trainer(model, (tr_loss), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
banknote_input_map = {X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 100 == 0:
mcee=trainer.previous_minibatch_loss_average
ca = class_acc(curr_batch, X,Y, model)
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, ca))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map)
acc = class_acc(all_test, X,Y, model)
print("Classification accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[0.6, 1.9, -3.3, -0.3]], dtype=np.float32)
print("\nPredicting Banknote authenticity for input features: ")
print(unknown[0])
pred_prob = model.eval({X:unknown})
print("Prediction probability: ")
print(“%0.4f” % pred_prob[0,0])
if pred_prob[0,0] < 0.5:
print(“Prediction: authentic”)
else:
print(“Prediction: fake”)
if __name__== ”__main__”:
main()
輸出
Using CNTK version = 2.7 batch 0: mean loss = 0.6936, accuracy = 10.00% batch 100: mean loss = 0.6882, accuracy = 70.00% batch 200: mean loss = 0.6597, accuracy = 50.00% batch 300: mean loss = 0.5298, accuracy = 70.00% batch 400: mean loss = 0.4090, accuracy = 100.00% batch 500: mean loss = 0.3790, accuracy = 90.00% batch 600: mean loss = 0.1852, accuracy = 100.00% batch 700: mean loss = 0.1135, accuracy = 100.00% batch 800: mean loss = 0.1285, accuracy = 100.00% batch 900: mean loss = 0.1054, accuracy = 100.00% Evaluating test data Classification accuracy = 84.00% Predicting banknote authenticity for input features: [0.6 1.9 -3.3 -0.3] Prediction probability: 0.8846 Prediction: fake
CNTK - 神經網路迴歸
本章將幫助您瞭解關於 CNTK 的神經網路迴歸。
簡介
眾所周知,為了從一個或多個預測變數中預測數值,我們使用迴歸。讓我們以預測某個 100 個城鎮中的一個城鎮的房屋中位數為例。為此,我們有以下資料:
每個城鎮的犯罪統計資料。
每個城鎮房屋的年齡。
衡量每個城鎮到黃金地段的距離。
每個城鎮的學生與教師比例。
每個城鎮的種族人口統計資料。
每個城鎮的房屋中位數。
基於這五個預測變數,我們想預測房屋中位數。為此,我們可以建立一個類似於以下的線性迴歸模型:
Y = a0+a1(crime)+a2(house-age)+(a3)(distance)+(a4)(ratio)+(a5)(racial)
在上式中:
Y 是預測的中位數
a0 是一個常數,並且
a1 到 a5 都是與我們上面討論的五個預測變數相關的常數。
我們還可以使用神經網路作為替代方法。它將建立一個更準確的預測模型。
在這裡,我們將使用 CNTK 建立一個神經網路迴歸模型。
載入資料集
為了使用 CNTK 實現神經網路迴歸,我們將使用波士頓地區房屋價值資料集。該資料集可以從 UCI 機器學習資源庫下載,網址為 https://archive.ics.uci.edu/。該資料集共有 14 個變數和 506 個例項。
但是,在我們的實現程式中,我們將使用 14 個變數中的 6 個和 100 個例項。在 6 個變數中,5 個作為預測變數,1 個作為要預測的值。在 100 個例項中,我們將使用 80 個用於訓練,20 個用於測試。我們想要預測的值是城鎮的房屋中位數。讓我們看看我們將使用的五個預測變數:
城鎮的人均犯罪率 - 我們預計較小的值與該預測變數相關。
自住單元的比例 - 建於 1940 年之前的房屋 - 我們預計較小的值與該預測變數相關,因為較大的值意味著更老的房屋。
到波士頓五個就業中心的加權距離。
地區學校學生與教師比例。
城鎮黑人居民比例的間接指標。
準備訓練和測試檔案
和之前一樣,我們首先需要將原始資料轉換為 CNTK 格式。我們將使用前 80 個數據項用於訓練,因此製表符分隔的 CNTK 格式如下:
|predictors 1.612820 96.90 3.76 21.00 248.31 |medval 13.50 |predictors 0.064170 68.20 3.36 19.20 396.90 |medval 18.90 |predictors 0.097440 61.40 3.38 19.20 377.56 |medval 20.00 . . .
接下來的 20 個專案也轉換為 CNTK 格式,將用於測試。
構建迴歸模型
首先,我們需要處理 CNTK 格式的資料檔案,為此,我們將使用名為 create_reader 的輔助函式,如下所示:
def create_reader(path, input_dim, output_dim, rnd_order, sweeps): x_strm = C.io.StreamDef(field='predictors', shape=input_dim, is_sparse=False) y_strm = C.io.StreamDef(field='medval', shape=output_dim, is_sparse=False) streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm) deserial = C.io.CTFDeserializer(path, streams) mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps) return mb_src
接下來,我們需要建立一個輔助函式,該函式接受一個 CNTK 小批次物件並計算自定義準確性指標。
def mb_accuracy(mb, x_var, y_var, model, delta): num_correct = 0 num_wrong = 0 x_mat = mb[x_var].asarray() y_mat = mb[y_var].asarray() for i in range(mb[x_var].shape[0]): v = model.eval(x_mat[i]) y = y_mat[i] if np.abs(v[0,0] – y[0,0]) < delta: num_correct += 1 else: num_wrong += 1 return (num_correct * 100.0)/(num_correct + num_wrong)
現在,我們需要為我們的神經網路設定體系結構引數,並提供資料檔案的位置。這可以使用以下python程式碼完成:
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 5
hidden_dim = 20
output_dim = 1
train_file = ".\\...\\" #provide the name of the training file(80 data items)
test_file = ".\\...\\" #provide the name of the test file(20 data items)
現在,藉助以下程式碼行,我們的程式將建立未經訓練的神經網路:
X = C.ops.input_variable(input_dim, np.float32) Y = C.ops.input_variable(output_dim, np.float32) with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)): hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X) oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer) model = C.ops.alias(oLayer)
現在,一旦我們建立了未經訓練的雙節點模型,我們需要設定一個 Learner 演算法物件。我們將使用 SGD 學習器和 squared_error 損失函式:
tr_loss = C.squared_error(model, Y) max_iter = 3000 batch_size = 5 base_learn_rate = 0.02 sch=C.learning_parameter_schedule([base_learn_rate, base_learn_rate/2], minibatch_size=batch_size, epoch_size=int((max_iter*batch_size)/2)) learner = C.sgd(model.parameters, sch) trainer = C.Trainer(model, (tr_loss), [learner])
現在,一旦我們完成了學習演算法物件,我們需要建立一個 reader 函式來讀取訓練資料:
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
現在,是時候訓練我們的 NN 模型了:
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=boston_input_map) trainer.train_minibatch(curr_batch)
if i % int(max_iter/10) == 0:
mcee = trainer.previous_minibatch_loss_average
acc = mb_accuracy(curr_batch, X, Y, model, delta=3.00)
print("batch %4d: mean squared error = %8.4f, accuracy = %5.2f%% " \ % (i, mcee, acc))
訓練完成後,讓我們使用測試資料項評估模型:
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=boston_input_map)
acc = mb_accuracy(all_test, X, Y, model, delta=3.00)
print("Prediction accuracy = %0.2f%%" % acc)
在評估我們訓練好的神經網路模型的準確性之後,我們將使用它對未見資料進行預測:
np.set_printoptions(precision = 2, suppress=True)
unknown = np.array([[0.09, 50.00, 4.5, 17.00, 350.00], dtype=np.float32)
print("\nPredicting median home value for feature/predictor values: ")
print(unknown[0])
pred_prob = model.eval({X: unknown)
print("\nPredicted value is: ")
print(“$%0.2f (x1000)” %pred_value[0,0])
完整的迴歸模型
import numpy as np
import cntk as C
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='predictors', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='medval', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def mb_accuracy(mb, x_var, y_var, model, delta):
num_correct = 0
num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
v = model.eval(x_mat[i])
y = y_mat[i]
if np.abs(v[0,0] – y[0,0]) < delta:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 5
hidden_dim = 20
output_dim = 1
train_file = ".\\...\\" #provide the name of the training file(80 data items)
test_file = ".\\...\\" #provide the name of the test file(20 data items)
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
model = C.ops.alias(oLayer)
tr_loss = C.squared_error(model, Y)
max_iter = 3000
batch_size = 5
base_learn_rate = 0.02
sch = C.learning_parameter_schedule([base_learn_rate, base_learn_rate/2], minibatch_size=batch_size, epoch_size=int((max_iter*batch_size)/2))
learner = C.sgd(model.parameters, sch)
trainer = C.Trainer(model, (tr_loss), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=boston_input_map) trainer.train_minibatch(curr_batch)
if i % int(max_iter/10) == 0:
mcee = trainer.previous_minibatch_loss_average
acc = mb_accuracy(curr_batch, X, Y, model, delta=3.00)
print("batch %4d: mean squared error = %8.4f, accuracy = %5.2f%% " \ % (i, mcee, acc))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=boston_input_map)
acc = mb_accuracy(all_test, X, Y, model, delta=3.00)
print("Prediction accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 2, suppress=True)
unknown = np.array([[0.09, 50.00, 4.5, 17.00, 350.00], dtype=np.float32)
print("\nPredicting median home value for feature/predictor values: ")
print(unknown[0])
pred_prob = model.eval({X: unknown)
print("\nPredicted value is: ")
print(“$%0.2f (x1000)” %pred_value[0,0])
if __name__== ”__main__”:
main()
輸出
Using CNTK version = 2.7 batch 0: mean squared error = 385.6727, accuracy = 0.00% batch 300: mean squared error = 41.6229, accuracy = 20.00% batch 600: mean squared error = 28.7667, accuracy = 40.00% batch 900: mean squared error = 48.6435, accuracy = 40.00% batch 1200: mean squared error = 77.9562, accuracy = 80.00% batch 1500: mean squared error = 7.8342, accuracy = 60.00% batch 1800: mean squared error = 47.7062, accuracy = 60.00% batch 2100: mean squared error = 40.5068, accuracy = 40.00% batch 2400: mean squared error = 46.5023, accuracy = 40.00% batch 2700: mean squared error = 15.6235, accuracy = 60.00% Evaluating test data Prediction accuracy = 64.00% Predicting median home value for feature/predictor values: [0.09 50. 4.5 17. 350.] Predicted value is: $21.02(x1000)
儲存訓練好的模型
這個波士頓房屋價值資料集只有 506 個數據項(其中我們只使用了 100 個)。因此,訓練 NN 迴歸模型只需要幾秒鐘,但是在一個擁有數百或數千個數據項的大型資料集上訓練可能需要數小時甚至數天。
我們可以儲存我們的模型,這樣我們就不用從頭開始重新訓練了。藉助以下 Python 程式碼,我們可以儲存我們訓練好的 NN:
nn_regressor = “.\\neuralregressor.model” #provide the name of the file model.save(nn_regressor, format=C.ModelFormat.CNTKv2)
以下是上面使用的 save() 函式的引數:
檔名是 save() 函式的第一個引數。它也可以與檔案路徑一起寫入。
另一個引數是 format 引數,其預設值為 C.ModelFormat.CNTKv2。
載入訓練好的模型
儲存訓練好的模型後,載入該模型非常容易。我們只需要使用 load() 函式。讓我們在下面的例子中檢查一下:
import numpy as np
import cntk as C
model = C.ops.functions.Function.load(“.\\neuralregressor.model”)
np.set_printoptions(precision = 2, suppress=True)
unknown = np.array([[0.09, 50.00, 4.5, 17.00, 350.00], dtype=np.float32)
print("\nPredicting area median home value for feature/predictor values: ")
print(unknown[0])
pred_prob = model.eval({X: unknown)
print("\nPredicted value is: ")
print(“$%0.2f (x1000)” %pred_value[0,0])
儲存模型的好處是,一旦載入了儲存的模型,就可以像剛剛訓練好的模型一樣使用。
CNTK - 分類模型
本章將幫助您瞭解如何在 CNTK 中衡量分類模型的效能。讓我們從混淆矩陣開始。
混淆矩陣
混淆矩陣 - 一個包含預測輸出與預期輸出的表格是衡量分類問題效能最簡單的方法,其中輸出可以是兩種或多種型別的類別。
為了理解它的工作原理,我們將為一個二元分類模型建立一個混淆矩陣,該模型預測信用卡交易是正常的還是欺詐的。它顯示如下:
| 實際欺詐 | 實際正常 | |
|---|---|---|
|
預測欺詐 |
真陽性 |
假陽性 |
|
預測正常 |
假陰性 |
真陰性 |
如我們所見,上面的示例混淆矩陣包含 2 列,一列用於欺詐類,另一列用於正常類。同樣,我們也有 2 行,一行用於欺詐類,另一行用於正常類。以下是與混淆矩陣相關的術語的解釋:
真陽性 - 當資料點的實際類別和預測類別都為 1 時。
真陰性 - 當資料點的實際類別和預測類別都為 0 時。
假陽性 - 當資料點的實際類別為 0,而預測類別為 1 時。
假陰性 - 當資料點的實際類別為 1,而預測類別為 0 時。
讓我們看看如何從混淆矩陣中計算不同的事物:
準確率 - 這是我們的 ML 分類模型做出的正確預測的數量。可以使用以下公式計算:
精確率 - 它告訴我們,在我們預測的所有樣本中,有多少樣本被正確預測。可以使用以下公式計算:
召回率或靈敏度 - 召回率是我們的 ML 分類模型返回的陽性數量。換句話說,它告訴我們資料集中有多少欺詐案例實際上被模型檢測到。可以使用以下公式計算:
特異性 - 與召回率相反,它給出我們的 ML 分類模型返回的陰性數量。可以使用以下公式計算:




F-測度
我們可以使用 F-測度作為混淆矩陣的替代方法。其主要原因是,我們不能同時最大化召回率和精確率。這兩個指標之間存在非常強的關係,這可以透過以下示例來理解:
假設我們想使用深度學習 (DL) 模型將細胞樣本分類為癌細胞或正常細胞。為了達到最高的精確度,我們需要將預測結果的數量減少到1。雖然這可以使我們達到大約100%的精確度,但召回率將會非常低。
另一方面,如果我們想要達到最高的召回率,我們需要儘可能多地進行預測。雖然這可以使我們達到大約100%的召回率,但精確度將會非常低。
在實踐中,我們需要找到一種在精確度和召回率之間取得平衡的方法。F 值度量允許我們做到這一點,因為它表示精確度和召回率之間的調和平均值。

這個公式稱為F1 值,其中附加項B設定為1,以獲得精確度和召回率的相等比率。為了強調召回率,我們可以將因子B設定為2。另一方面,為了強調精確度,我們可以將因子B設定為0.5。
使用CNTK衡量分類效能
在上一節中,我們使用鳶尾花資料集建立了一個分類模型。在這裡,我們將使用混淆矩陣和F值度量來衡量其效能。
建立混淆矩陣
我們已經建立了模型,因此我們可以開始驗證過程,其中包括**混淆矩陣**。首先,我們將藉助於**scikit-learn**中的**confusion_matrix**函式來建立混淆矩陣。為此,我們需要測試樣本的真實標籤和相同測試樣本的預測標籤。
讓我們使用以下Python程式碼計算混淆矩陣:
from sklearn.metrics import confusion_matrix y_true = np.argmax(y_test, axis=1) y_pred = np.argmax(z(X_test), axis=1) matrix = confusion_matrix(y_true=y_true, y_pred=y_pred) print(matrix)
輸出
[[10 0 0] [ 0 1 9] [ 0 0 10]]
我們還可以使用熱力圖函式來視覺化混淆矩陣,如下所示:
import seaborn as sns
import matplotlib.pyplot as plt
g = sns.heatmap(matrix,
annot=True,
xticklabels=label_encoder.classes_.tolist(),
yticklabels=label_encoder.classes_.tolist(),
cmap='Blues')
g.set_yticklabels(g.get_yticklabels(), rotation=0)
plt.show()

我們還應該有一個單一的效能指標,我們可以用它來比較模型。為此,我們需要使用CNTK中metrics包中的**classification_error**函式計算分類錯誤,就像建立分類模型時所做的那樣。
現在,要計算分類錯誤,請使用包含資料集的損失函式執行測試方法。之後,CNTK將把我們為此函式提供的樣本作為輸入,並根據輸入特徵X_**test**進行預測。
loss.test([X_test, y_test])
輸出
{'metric': 0.36666666666, 'samples': 30}
實現F值
為了實現F值,CNTK還包含一個名為fmeasures的函式。在訓練神經網路時,我們可以使用此函式,將單元**cntk.metrics.classification_error**替換為**cntk.losses.fmeasure**,方法如下:
import cntk @cntk.Function def criterion_factory(output, target): loss = cntk.losses.cross_entropy_with_softmax(output, target) metric = cntk.losses.fmeasure(output, target) return loss, metric
使用cntk.losses.fmeasure函式後,我們將得到**loss.test**方法呼叫的不同輸出,如下所示:
loss.test([X_test, y_test])
輸出
{'metric': 0.83101488749, 'samples': 30}
CNTK - 迴歸模型
在這裡,我們將學習關於衡量回歸模型效能的方法。
迴歸模型驗證的基礎
眾所周知,迴歸模型不同於分類模型,因為對於單個樣本沒有對錯的二元度量。在迴歸模型中,我們想要衡量預測值與實際值的接近程度。預測值越接近預期輸出,模型的效能就越好。
在這裡,我們將使用不同的誤差率函式來衡量用於迴歸的神經網路的效能。
計算誤差範圍
如前所述,在驗證迴歸模型時,我們不能說預測是對還是錯。我們希望我們的預測儘可能接近真實值。但是,這裡可以接受小的誤差範圍。
計算誤差範圍的公式如下:

這裡:
**預測值** = 用帽子表示的y
**真實值** = 預測的y
首先,我們需要計算預測值和真實值之間的距離。然後,為了獲得整體誤差率,我們需要將這些平方距離相加並計算平均值。這稱為**均方誤差**函式。
但是,如果我們想要表示誤差範圍的效能指標,我們需要一個表示絕對誤差的公式。**平均絕對誤差**函式的公式如下:

上述公式取預測值和真實值之間的絕對距離。
使用CNTK衡量回歸效能
在這裡,我們將瞭解如何結合CNTK使用我們討論過的不同度量。我們將使用一個迴歸模型,根據以下步驟預測汽車的每加侖英里數。
實現步驟:
**步驟1** - 首先,我們需要從**cntk**包中匯入所需的元件,如下所示:
from cntk import default_option, input_variable from cntk.layers import Dense, Sequential from cntk.ops import relu
**步驟2** - 接下來,我們需要使用**default_options**函式定義一個預設啟用函式。然後,建立一個新的Sequential層集,並提供兩個各有64個神經元的Dense層。然後,我們將一個額外的Dense層(將作為輸出層)新增到Sequential層集,並提供1個沒有啟用函式的神經元,如下所示:
with default_options(activation=relu): model = Sequential([Dense(64),Dense(64),Dense(1,activation=None)])
**步驟3** - 建立網路後,我們需要建立一個輸入特徵。我們需要確保它與我們將用於訓練的特徵具有相同的形狀。
features = input_variable(X.shape[1])
**步驟4** - 現在,我們需要建立一個大小為1的另一個**input_variable**。它將用於儲存神經網路的預期值。
target = input_variable(1) z = model(features)
現在,我們需要訓練模型,為此,我們將分割資料集並使用以下實現步驟進行預處理:
**步驟5** - 首先,從sklearn.preprocessing匯入StandardScaler以獲得-1和+1之間的值。這將有助於我們避免神經網路中的梯度爆炸問題。
from sklearn.preprocessing import StandardScalar
**步驟6** - 接下來,從sklearn.model_selection匯入train_test_split,如下所示:
from sklearn.model_selection import train_test_split
**步驟7** - 使用**drop**方法從資料集中刪除**mpg**列。最後,使用**train_test_split**函式將資料集分割成訓練集和驗證集,如下所示:
x = df_cars.drop(columns=[‘mpg’]).values.astype(np.float32) y=df_cars.iloc[: , 0].values.reshape(-1, 1).astype(np.float32) scaler = StandardScaler() X = scaler.fit_transform(x) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
**步驟8** - 現在,我們需要建立一個大小為1的另一個input_variable。它將用於儲存神經網路的預期值。
target = input_variable(1) z = model(features)
我們已經分割並預處理了資料,現在我們需要訓練神經網路。就像在前面幾節建立迴歸模型時所做的那樣,我們需要定義損失函式和**度量**函式的組合來訓練模型。
import cntk def absolute_error(output, target): return cntk.ops.reduce_mean(cntk.ops.abs(output – target)) @ cntk.Function def criterion_factory(output, target): loss = squared_error(output, target) metric = absolute_error(output, target) return loss, metric
現在,讓我們看看如何使用訓練好的模型。對於我們的模型,我們將使用criterion_factory作為損失和度量組合。
from cntk.losses import squared_error from cntk.learners import sgd from cntk.logging import ProgressPrinter progress_printer = ProgressPrinter(0) loss = criterion_factory (z, target) learner = sgd(z.parameters, 0.001) training_summary=loss.train((x_train,y_train),parameter_learners=[learner],callbacks=[progress_printer],minibatch_size=16,max_epochs=10)
完整的實現示例
from cntk import default_option, input_variable from cntk.layers import Dense, Sequential from cntk.ops import relu with default_options(activation=relu): model = Sequential([Dense(64),Dense(64),Dense(1,activation=None)]) features = input_variable(X.shape[1]) target = input_variable(1) z = model(features) from sklearn.preprocessing import StandardScalar from sklearn.model_selection import train_test_split x = df_cars.drop(columns=[‘mpg’]).values.astype(np.float32) y=df_cars.iloc[: , 0].values.reshape(-1, 1).astype(np.float32) scaler = StandardScaler() X = scaler.fit_transform(x) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) target = input_variable(1) z = model(features) import cntk def absolute_error(output, target): return cntk.ops.reduce_mean(cntk.ops.abs(output – target)) @ cntk.Function def criterion_factory(output, target): loss = squared_error(output, target) metric = absolute_error(output, target) return loss, metric from cntk.losses import squared_error from cntk.learners import sgd from cntk.logging import ProgressPrinter progress_printer = ProgressPrinter(0) loss = criterion_factory (z, target) learner = sgd(z.parameters, 0.001) training_summary=loss.train((x_train,y_train),parameter_learners=[learner],callbacks=[progress_printer],minibatch_size=16,max_epochs=10)
輸出
------------------------------------------------------------------- average since average since examples loss last metric last ------------------------------------------------------ Learning rate per minibatch: 0.001 690 690 24.9 24.9 16 654 636 24.1 23.7 48 [………]
為了驗證我們的迴歸模型,我們需要確保該模型處理新資料的效果與處理訓練資料一樣好。為此,我們需要使用測試資料在**loss**和**metric**組合上呼叫**test**方法,如下所示:
loss.test([X_test, y_test])
輸出:
{'metric': 1.89679785619, 'samples': 79}
CNTK - 記憶體不足的資料集
本章將解釋如何衡量記憶體外資料集的效能。
在前面幾節中,我們討論了驗證神經網路效能的各種方法,但是我們討論的方法是處理適合記憶體的資料集的方法。
這裡出現了一個問題,那就是記憶體外資料集怎麼辦,因為在生產環境中,我們需要大量資料來訓練**神經網路**。在本節中,我們將討論如何在使用小批次源和手動小批次迴圈時衡量效能。
小批次源
在處理記憶體外資料集(即小批次源)時,我們需要對損失和度量進行略微不同的設定,這與我們在處理小型資料集(即記憶體內資料集)時使用的設定不同。首先,我們將瞭解如何設定將資料饋送到神經網路模型訓練器的方法。
以下是實現步驟:
**步驟1** - 首先,從**cntk.io**模組匯入用於建立小批次源的元件,如下所示:
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer, INFINITY_REPEAT
**步驟2** - 接下來,建立一個名為**create_datasource**的新函式。此函式將有兩個引數,即檔名和限制,預設值為**INFINITELY_REPEAT**。
def create_datasource(filename, limit =INFINITELY_REPEAT)
**步驟3** - 現在,在函式內部,使用**StreamDef**類為讀取具有三個特徵的labels欄位的標籤建立一個流定義。我們還需要將**is_sparse**設定為**False**,如下所示:
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)
**步驟4** - 接下來,建立另一個**StreamDef**例項來讀取輸入檔案中的features欄位。
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)
**步驟5** - 現在,初始化**CTFDeserializer**例項類。指定我們需要反序列化的檔名和流,如下所示:
deserializer = CTFDeserializer(filename, StreamDefs(labels= label_stream, features=features_stream)
**步驟6** - 接下來,我們需要使用反序列化器建立minisourceBatch的例項,如下所示:
Minibatch_source = MinibatchSource(deserializer, randomize=True, max_sweeps=limit) return minibatch_source
**步驟7** - 最後,我們需要提供訓練和測試源,我們在前面的章節中也建立了這些源。我們使用鳶尾花資料集。
training_source = create_datasource(‘Iris_train.ctf’) test_source = create_datasource(‘Iris_test.ctf’, limit=1)
建立**MinibatchSource**例項後,我們需要對其進行訓練。我們可以使用與處理小型記憶體內資料集時相同的訓練邏輯。在這裡,我們將使用**MinibatchSource**例項作為損失函式的train方法的輸入,如下所示:
以下是實現步驟:
**步驟1** - 為了記錄訓練會話的輸出,首先從**cntk.logging**模組匯入**ProgressPrinter**,如下所示:
from cntk.logging import ProgressPrinter
**步驟2** - 接下來,要設定訓練會話,請從**cntk.train**模組匯入**trainer**和**training_session**,如下所示:
from cntk.train import Trainer, training_session
**步驟3** - 現在,我們需要定義一些常量,例如**minibatch_size**、**samples_per_epoch**和**num_epochs**,如下所示:
minbatch_size = 16 samples_per_epoch = 150 num_epochs = 30 max_samples = samples_per_epoch * num_epochs
**步驟4** - 接下來,為了瞭解如何在CNTK中讀取訓練期間的資料,我們需要定義網路的輸入變數與小批次源中的流之間的對映。
input_map = {
features: training_source.streams.features,
labels: training_source.streams.labels
}
**步驟5** - 接下來,要記錄訓練過程的輸出,請使用新的**ProgressPrinter**例項初始化**progress_printer**變數。此外,初始化**trainer**併為其提供模型,如下所示:
progress_writer = ProgressPrinter(0) trainer: training_source.streams.labels
**步驟6** - 最後,要啟動訓練過程,我們需要呼叫**training_session**函式,如下所示:
session = training_session(trainer, mb_source=training_source, mb_size=minibatch_size, model_inputs_to_streams=input_map, max_samples=max_samples, test_config=test_config) session.train()
訓練模型後,我們可以透過使用**TestConfig**物件並將其分配給**train_session**函式的**test_config**關鍵字引數來為此設定新增驗證。
以下是實現步驟:
**步驟1** - 首先,我們需要從**cntk.train**模組匯入**TestConfig**類,如下所示:
from cntk.train import TestConfig
**步驟2** - 現在,我們需要使用**test_source**作為輸入建立一個新的**TestConfig**例項:
Test_config = TestConfig(test_source)
完整示例
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer, INFINITY_REPEAT
def create_datasource(filename, limit =INFINITELY_REPEAT)
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)
deserializer = CTFDeserializer(filename, StreamDefs(labels=label_stream, features=features_stream)
Minibatch_source = MinibatchSource(deserializer, randomize=True, max_sweeps=limit)
return minibatch_source
training_source = create_datasource(‘Iris_train.ctf’)
test_source = create_datasource(‘Iris_test.ctf’, limit=1)
from cntk.logging import ProgressPrinter
from cntk.train import Trainer, training_session
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30
max_samples = samples_per_epoch * num_epochs
input_map = {
features: training_source.streams.features,
labels: training_source.streams.labels
}
progress_writer = ProgressPrinter(0)
trainer: training_source.streams.labels
session = training_session(trainer,
mb_source=training_source,
mb_size=minibatch_size,
model_inputs_to_streams=input_map,
max_samples=max_samples,
test_config=test_config)
session.train()
from cntk.train import TestConfig
Test_config = TestConfig(test_source)
輸出
------------------------------------------------------------------- average since average since examples loss last metric last ------------------------------------------------------ Learning rate per minibatch: 0.1 1.57 1.57 0.214 0.214 16 1.38 1.28 0.264 0.289 48 [………] Finished Evaluation [1]: Minibatch[1-1]:metric = 69.65*30;
手動小批次迴圈
如上所述,透過在使用CNTK的常規API進行訓練時使用度量,可以輕鬆地衡量神經網路模型在訓練期間和訓練後的效能。但是,另一方面,在使用手動小批次迴圈時,事情不會那麼容易。
在這裡,我們使用以下模型,該模型具有4個輸入和3個輸出,來自鳶尾花資料集,在前面的章節中也建立過:
from cntk import default_options, input_variable from cntk.layers import Dense, Sequential from cntk.ops import log_softmax, relu, sigmoid from cntk.learners import sgd model = Sequential([ Dense(4, activation=sigmoid), Dense(3, activation=log_softmax) ]) features = input_variable(4) labels = input_variable(3) z = model(features)
接下來,模型的損失定義為交叉熵損失函式和F值度量的組合,如前幾節中所用。我們將使用**criterion_factory**實用程式將其建立為CNTK函式物件,如下所示:
import cntk
from cntk.losses import cross_entropy_with_softmax, fmeasure
@cntk.Function
def criterion_factory(outputs, targets):
loss = cross_entropy_with_softmax(outputs, targets)
metric = fmeasure(outputs, targets, beta=1)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, 0.1)
label_mapping = {
'Iris-setosa': 0,
'Iris-versicolor': 1,
'Iris-virginica': 2
}
現在,由於我們已經定義了損失函式,我們將瞭解如何在訓練器中使用它來設定手動訓練會話。
以下是實現步驟:
**步驟1** - 首先,我們需要匯入所需的包,例如**numpy**和**pandas**,以載入和預處理資料。
import pandas as pd import numpy as np
**步驟2** - 接下來,為了在訓練期間記錄資訊,請匯入**ProgressPrinter**類,如下所示:
from cntk.logging import ProgressPrinter
**步驟3** - 然後,我們需要從cntk.train模組匯入trainer模組,如下所示:
from cntk.train import Trainer
**步驟4** - 接下來,建立一個新的**ProgressPrinter**例項,如下所示:
progress_writer = ProgressPrinter(0)
**步驟5** - 現在,我們需要使用損失、學習器和**progress_writer**作為引數初始化訓練器,如下所示:
trainer = Trainer(z, loss, learner, progress_writer)
**步驟6** - 接下來,為了訓練模型,我們將建立一個迴圈,該迴圈將迭代資料集三十次。這將是外部訓練迴圈。
for _ in range(0,30):
**步驟7** - 現在,我們需要使用pandas從磁碟載入資料。然後,為了以**小批次**載入資料集,將**chunksize**關鍵字引數設定為16。
input_data = pd.read_csv('iris.csv',
names=['sepal_length', 'sepal_width','petal_length','petal_width', 'species'],
index_col=False, chunksize=16)
**步驟8** - 現在,建立一個內部訓練for迴圈來迭代每個**小批次**。
for df_batch in input_data:
步驟 9 − 現在在這個迴圈內部,使用iloc索引器讀取前四列作為訓練特徵,並將它們轉換為float32型別 −
feature_values = df_batch.iloc[:,:4].values feature_values = feature_values.astype(np.float32)
步驟 10 − 現在,讀取最後一列作為訓練標籤,如下所示 −
label_values = df_batch.iloc[:,-1]
步驟 11 − 接下來,我們將使用獨熱向量將標籤字串轉換為其數值表示,如下所示 −
label_values = label_values.map(lambda x: label_mapping[x])
步驟 12 − 之後,獲取標籤的數值表示。接下來,將它們轉換為NumPy陣列,以便更容易地處理它們,如下所示 −
label_values = label_values.values
步驟 13 − 現在,我們需要建立一個新的NumPy陣列,其行數與我們已轉換的標籤值相同。
encoded_labels = np.zeros((label_values.shape[0], 3))
步驟 14 − 現在,為了建立獨熱編碼標籤,請根據數值標籤值選擇列。
encoded_labels[np.arange(label_values.shape[0]), label_values] = 1.
步驟 15 − 最後,我們需要在訓練器上呼叫train_minibatch方法,併為小批次提供已處理的特徵和標籤。
trainer.train_minibatch({features: feature_values, labels: encoded_labels})
完整示例
from cntk import default_options, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import log_softmax, relu, sigmoid
from cntk.learners import sgd
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
labels = input_variable(3)
z = model(features)
import cntk
from cntk.losses import cross_entropy_with_softmax, fmeasure
@cntk.Function
def criterion_factory(outputs, targets):
loss = cross_entropy_with_softmax(outputs, targets)
metric = fmeasure(outputs, targets, beta=1)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, 0.1)
label_mapping = {
'Iris-setosa': 0,
'Iris-versicolor': 1,
'Iris-virginica': 2
}
import pandas as pd
import numpy as np
from cntk.logging import ProgressPrinter
from cntk.train import Trainer
progress_writer = ProgressPrinter(0)
trainer = Trainer(z, loss, learner, progress_writer)
for _ in range(0,30):
input_data = pd.read_csv('iris.csv',
names=['sepal_length', 'sepal_width','petal_length','petal_width', 'species'],
index_col=False, chunksize=16)
for df_batch in input_data:
feature_values = df_batch.iloc[:,:4].values
feature_values = feature_values.astype(np.float32)
label_values = df_batch.iloc[:,-1]
label_values = label_values.map(lambda x: label_mapping[x])
label_values = label_values.values
encoded_labels = np.zeros((label_values.shape[0], 3))
encoded_labels[np.arange(label_values.shape[0]),
label_values] = 1.
trainer.train_minibatch({features: feature_values, labels: encoded_labels})
輸出
------------------------------------------------------------------- average since average since examples loss last metric last ------------------------------------------------------ Learning rate per minibatch: 0.1 1.45 1.45 -0.189 -0.189 16 1.24 1.13 -0.0382 0.0371 48 [………]
在上面的輸出中,我們得到了訓練期間損失和指標的輸出。這是因為我們將指標和損失組合在一個函式物件中,並在訓練器配置中使用了進度列印器。
現在,為了評估模型效能,我們需要執行與訓練模型相同的任務,但是這次,我們需要使用Evaluator例項來測試模型。這在下面的Python程式碼中顯示 −
from cntk import Evaluator
evaluator = Evaluator(loss.outputs[1], [progress_writer])
input_data = pd.read_csv('iris.csv',
names=['sepal_length', 'sepal_width','petal_length','petal_width', 'species'],
index_col=False, chunksize=16)
for df_batch in input_data:
feature_values = df_batch.iloc[:,:4].values
feature_values = feature_values.astype(np.float32)
label_values = df_batch.iloc[:,-1]
label_values = label_values.map(lambda x: label_mapping[x])
label_values = label_values.values
encoded_labels = np.zeros((label_values.shape[0], 3))
encoded_labels[np.arange(label_values.shape[0]), label_values] = 1.
evaluator.test_minibatch({ features: feature_values, labels:
encoded_labels})
evaluator.summarize_test_progress()
現在,我們將得到類似於以下內容的輸出 −
輸出
Finished Evaluation [1]: Minibatch[1-11]:metric = 74.62*143;
CNTK - 監控模型
本章,我們將瞭解如何在CNTK中監控模型。
簡介
在前面的章節中,我們對我們的NN模型進行了一些驗證。但是,在訓練過程中監控我們的模型是否也必要且可行呢?
是的,我們已經使用ProgressWriter類來監控我們的模型,還有許多其他的方法可以做到這一點。在深入瞭解這些方法之前,讓我們先了解CNTK中的監控機制以及如何使用它來檢測NN模型中的問題。
CNTK中的回撥函式
實際上,在訓練和驗證期間,CNTK允許我們在API的多個位置指定回撥函式。首先,讓我們仔細看看CNTK何時呼叫回撥函式。
CNTK何時呼叫回撥函式?
CNTK將在訓練和測試資料集的以下時刻呼叫回撥函式 −
一個小批次完成。
在訓練期間完成對資料集的完整掃描。
測試小批次完成。
在測試期間完成對資料集的完整掃描。
指定回撥函式
在使用CNTK時,我們可以在API的多個位置指定回撥函式。例如 −
在損失函式上呼叫train時?
在這裡,當我們在損失函式上呼叫train時,我們可以透過callbacks引數指定一組回撥函式,如下所示 −
training_summary=loss.train((x_train,y_train), parameter_learners=[learner], callbacks=[progress_writer]), minibatch_size=16, max_epochs=15)
在使用小批次資料來源或使用手動小批次迴圈時 −
在這種情況下,我們可以在建立Trainer時指定用於監控目的的回撥函式,如下所示 −
from cntk.logging import ProgressPrinter callbacks = [ ProgressPrinter(0) ] Trainer = Trainer(z, (loss, metric), learner, [callbacks])
各種監控工具
讓我們學習不同的監控工具。
ProgressPrinter
在閱讀本教程時,您會發現ProgressPrinter是最常用的監控工具。ProgressPrinter監控工具的一些特性包括 −
ProgressPrinter類實現基於控制檯的基本日誌記錄來監控我們的模型。如果需要,它可以將日誌記錄到磁碟。
在分散式訓練場景中尤其有用。
在我們無法登入到控制檯檢視Python程式輸出的場景中,它也非常有用。
藉助以下程式碼,我們可以建立一個ProgressPrinter例項 −
ProgressPrinter(0, log_to_file=’test.txt’)
我們將得到類似於我們在前面章節中看到的輸出 −
Test.txt CNTKCommandTrainInfo: train : 300 CNTKCommandTrainInfo: CNTKNoMoreCommands_Total : 300 CNTKCommandTrainBegin: train ------------------------------------------------------------------- average since average since examples loss last metric last ------------------------------------------------------ Learning rate per minibatch: 0.1 1.45 1.45 -0.189 -0.189 16 1.24 1.13 -0.0382 0.0371 48 [………]
TensorBoard
使用ProgressPrinter的一個缺點是,我們無法很好地檢視損失和指標隨時間的變化情況。TensorBoardProgressWriter是CNTK中ProgressPrinter類的絕佳替代方案。
在使用它之前,我們需要首先使用以下命令安裝它 −
pip install tensorboard
現在,為了使用TensorBoard,我們需要在我們的訓練程式碼中設定TensorBoardProgressWriter,如下所示 −
import time
from cntk.logging import TensorBoardProgressWriter
tensorbrd_writer = TensorBoardProgressWriter(log_dir=’logs/{}’.format(time.time()),freq=1,model=z)
訓練NN模型完成後,最好在TensorBoardProgressWriter例項上呼叫close方法。
我們可以使用以下命令視覺化TensorBoard日誌資料 −
Tensorboard –logdir logs
CNTK - 卷積神經網路
本章,讓我們學習如何在CNTK中構建卷積神經網路(CNN)。
簡介
卷積神經網路(CNN)也由具有可學習權重和偏差的神經元組成。因此,它們與普通神經網路(NN)類似。
如果我們回憶一下普通NN的工作原理,每個神經元接收一個或多個輸入,取加權和,並透過啟用函式產生最終輸出。這裡的問題是,如果CNN和普通NN有如此多的相似之處,那麼是什麼讓這兩個網路彼此不同呢?
使它們不同的在於輸入資料的處理和層型別?普通NN忽略輸入資料的結構,所有資料在饋送到網路之前都轉換為一維陣列。
但是,卷積神經網路架構可以考慮影像的二維結構,對其進行處理,並允許它提取特定於影像的屬性。此外,CNN具有一個或多個卷積層和池化層的優勢,它們是CNN的主要構建塊。
這些層之後是一個或多個全連線層,就像標準的多層NN一樣。因此,我們可以將CNN視為全連線網路的特例。
卷積神經網路(CNN)架構
CNN的架構基本上是一個層列表,它將影像體積的三維(即寬度、高度和深度)轉換為三維輸出體積。這裡需要注意的一點是,當前層中的每個神經元都連線到前一層輸出的小塊,這就像將N*N濾波器疊加在輸入影像上。
它使用M個濾波器,這些濾波器基本上是特徵提取器,可以提取邊緣、角點等特徵。以下是用於構建卷積神經網路(CNN)的層[INPUT-CONV-RELU-POOL-FC] −
INPUT −顧名思義,此層儲存原始畫素值。原始畫素值表示影像資料本身。例如,INPUT [64×64×3]是一個具有64寬度、64高度和3深度的3通道RGB影像。
CONV −此層是CNN的構建塊之一,因為大部分計算都在此層中完成。例如,如果我們在上面提到的INPUT [64×64×3]上使用6個濾波器,這可能會導致體積[64×64×6]。
RELU −也稱為整流線性單元層,它將啟用函式應用於前一層的輸出。換句話說,RELU會向網路新增非線性。
POOL −此層,即池化層是CNN的另一個構建塊。此層的'主要任務是下采樣,這意味著它獨立地作用於輸入的每個切片並對其進行空間調整大小。
FC −稱為全連線層,更具體地說,是輸出層。它用於計算輸出類別分數,生成的輸出是大小為1*1*L的體積,其中L是對應於類別分數的數字。
下圖表示CNN的典型架構 −

建立CNN結構
我們已經瞭解了CNN的架構和基礎知識,現在我們將使用CNTK構建卷積網路。在這裡,我們將首先了解如何將CNN的結構組合在一起,然後我們將研究如何訓練它的引數。
最後,我們將瞭解如何透過使用各種不同的層設定更改其結構來改進神經網路。我們將使用MNIST影像資料集。
因此,讓我們首先建立一個CNN結構。通常,當我們構建CNN來識別影像中的模式時,我們會執行以下操作 −
我們使用卷積層和池化層的組合。
網路末尾的一個或多個隱藏層。
最後,我們使用softmax層完成網路以進行分類。
藉助以下步驟,我們可以構建網路結構 −
步驟 1 −首先,我們需要匯入CNN所需的層。
from cntk.layers import Convolution2D, Sequential, Dense, MaxPooling
步驟 2 −接下來,我們需要匯入CNN的啟用函式。
from cntk.ops import log_softmax, relu
步驟 3 −之後,為了稍後初始化卷積層,我們需要匯入glorot_uniform_initializer,如下所示 −
from cntk.initializer import glorot_uniform
步驟 4 −接下來,要建立輸入變數,請匯入input_variable函式。並匯入default_option函式,以便更容易地配置NN。
from cntk import input_variable, default_options
步驟 5 −現在,為了儲存輸入影像,建立一個新的input_variable。它將包含三個通道,即紅色、綠色和藍色。它的大小為28 x 28畫素。
features = input_variable((3,28,28))
步驟 6 −接下來,我們需要建立另一個input_variable來儲存要預測的標籤。
labels = input_variable(10)
步驟 7 −現在,我們需要為NN建立default_option。並且,我們需要使用glorot_uniform作為初始化函式。
with default_options(initialization=glorot_uniform, activation=relu):
步驟 8 −接下來,為了設定NN的結構,我們需要建立一個新的Sequential層集。
步驟 9 −現在,我們需要在Sequential層集中新增一個Convolutional2D層,其filter_shape為5,strides設定為1。此外,啟用填充,以便填充影像以保留原始尺寸。
model = Sequential([ Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True),
步驟 10 −現在是時候新增一個MaxPooling層了,其filter_shape為2,strides設定為2,以將影像壓縮一半。
MaxPooling(filter_shape=(2,2), strides=(2,2)),
步驟 11 −現在,就像在步驟9中所做的那樣,我們需要新增另一個Convolutional2D層,其filter_shape為5,strides設定為1,使用16個濾波器。此外,啟用填充,以便保留前一層池化層生成的影像的大小。
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True),
步驟 12 −現在,就像在步驟10中所做的那樣,新增另一個MaxPooling層,其filter_shape為3,strides設定為3,以將影像縮小到三分之一。
MaxPooling(filter_shape=(3,3), strides=(3,3)),
步驟 13 −最後,為10個可能的類別新增一個具有十個神經元的Dense層,網路可以預測。為了將網路轉換為分類模型,請使用log_softmax啟用函式。
Dense(10, activation=log_softmax) ])
建立CNN結構的完整示例
from cntk.layers import Convolution2D, Sequential, Dense, MaxPooling from cntk.ops import log_softmax, relu from cntk.initializer import glorot_uniform from cntk import input_variable, default_options features = input_variable((3,28,28)) labels = input_variable(10) with default_options(initialization=glorot_uniform, activation=relu): model = Sequential([ Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True), MaxPooling(filter_shape=(2,2), strides=(2,2)), Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True), MaxPooling(filter_shape=(3,3), strides=(3,3)), Dense(10, activation=log_softmax) ]) z = model(features)
使用影像訓練CNN
網路結構搭建完成後,接下來就是訓練網路。但在開始訓練之前,我們需要設定小批次資料來源(minibatch sources),因為訓練處理影像的神經網路(NN)需要的記憶體比大多數計算機都多。
我們在之前的章節中已經建立了小批次資料來源。以下是設定兩個小批次資料來源的 Python 程式碼:
有了`create_datasource`函式,我們現在可以建立兩個獨立的資料來源(一個用於訓練,一個用於測試)來訓練模型。
train_datasource = create_datasource('mnist_train')
test_datasource = create_datasource('mnist_test', max_sweeps=1, train=False)
現在,影像準備就緒,我們可以開始訓練我們的神經網路了。與之前的章節一樣,我們可以使用損失函式上的`train`方法啟動訓練。以下是相應的程式碼:
from cntk import Function from cntk.losses import cross_entropy_with_softmax from cntk.metrics import classification_error from cntk.learners import sgd @Function def criterion_factory(output, targets): loss = cross_entropy_with_softmax(output, targets) metric = classification_error(output, targets) return loss, metric loss = criterion_factory(z, labels) learner = sgd(z.parameters, lr=0.2)
透過之前的程式碼,我們已經為神經網路設定了損失函式和學習器。以下程式碼將訓練和驗證神經網路:
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
labels: train_datasource.streams.labels
}
loss.train(train_datasource,
max_epochs=10,
minibatch_size=64,
epoch_size=60000,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config])
完整實現示例
from cntk.layers import Convolution2D, Sequential, Dense, MaxPooling
from cntk.ops import log_softmax, relu
from cntk.initializer import glorot_uniform
from cntk import input_variable, default_options
features = input_variable((3,28,28))
labels = input_variable(10)
with default_options(initialization=glorot_uniform, activation=relu):
model = Sequential([
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True),
MaxPooling(filter_shape=(2,2), strides=(2,2)),
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True),
MaxPooling(filter_shape=(3,3), strides=(3,3)),
Dense(10, activation=log_softmax)
])
z = model(features)
import os
from cntk.io import MinibatchSource, StreamDef, StreamDefs, ImageDeserializer, INFINITELY_REPEAT
import cntk.io.transforms as xforms
def create_datasource(folder, train=True, max_sweeps=INFINITELY_REPEAT):
mapping_file = os.path.join(folder, 'mapping.bin')
image_transforms = []
if train:
image_transforms += [
xforms.crop(crop_type='randomside', side_ratio=0.8),
xforms.scale(width=28, height=28, channels=3, interpolations='linear')
]
stream_definitions = StreamDefs(
features=StreamDef(field='image', transforms=image_transforms),
labels=StreamDef(field='label', shape=10)
)
deserializer = ImageDeserializer(mapping_file, stream_definitions)
return MinibatchSource(deserializer, max_sweeps=max_sweeps)
train_datasource = create_datasource('mnist_train')
test_datasource = create_datasource('mnist_test', max_sweeps=1, train=False)
from cntk import Function
from cntk.losses import cross_entropy_with_softmax
from cntk.metrics import classification_error
from cntk.learners import sgd
@Function
def criterion_factory(output, targets):
loss = cross_entropy_with_softmax(output, targets)
metric = classification_error(output, targets)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, lr=0.2)
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
labels: train_datasource.streams.labels
}
loss.train(train_datasource,
max_epochs=10,
minibatch_size=64,
epoch_size=60000,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config])
輸出
------------------------------------------------------------------- average since average since examples loss last metric last ------------------------------------------------------ Learning rate per minibatch: 0.2 142 142 0.922 0.922 64 1.35e+06 1.51e+07 0.896 0.883 192 [………]
影像變換
正如我們所看到的,訓練用於影像識別的神經網路很困難,而且它們需要大量資料進行訓練。另一個問題是,它們傾向於過度擬合訓練中使用的影像。例如,如果我們只有直立姿勢的人臉照片,我們的模型將很難識別旋轉到其他方向的人臉。
為了克服這個問題,我們可以使用影像增強,而CNTK在為影像建立小批次資料來源時支援特定的變換。我們可以使用以下幾種變換:
我們可以通過幾行程式碼隨機裁剪用於訓練的影像。
我們還可以使用縮放和顏色變換。
讓我們透過下面的Python程式碼來看看如何透過在前面用於建立小批次資料來源的函式中包含裁剪變換來更改變換列表。
import os
from cntk.io import MinibatchSource, StreamDef, StreamDefs, ImageDeserializer, INFINITELY_REPEAT
import cntk.io.transforms as xforms
def create_datasource(folder, train=True, max_sweeps=INFINITELY_REPEAT):
mapping_file = os.path.join(folder, 'mapping.bin')
image_transforms = []
if train:
image_transforms += [
xforms.crop(crop_type='randomside', side_ratio=0.8),
xforms.scale(width=28, height=28, channels=3, interpolations='linear')
]
stream_definitions = StreamDefs(
features=StreamDef(field='image', transforms=image_transforms),
labels=StreamDef(field='label', shape=10)
)
deserializer = ImageDeserializer(mapping_file, stream_definitions)
return MinibatchSource(deserializer, max_sweeps=max_sweeps)
藉助上述程式碼,我們可以增強函式以包含一組影像變換,這樣,在訓練時可以隨機裁剪影像,從而獲得更多影像變化。
CNTK - 迴圈神經網路
現在,讓我們瞭解如何在CNTK中構建迴圈神經網路(RNN)。
簡介
我們學習瞭如何使用神經網路對影像進行分類,這是深度學習中的一個標誌性任務。但是,神經網路擅長且研究活躍的另一個領域是迴圈神經網路(RNN)。在這裡,我們將瞭解RNN是什麼以及如何在需要處理時間序列資料的情況下使用它。
什麼是迴圈神經網路?
迴圈神經網路(RNN)可以定義為一種特殊的神經網路,能夠進行時間推理。RNN主要用於需要處理隨時間變化的值(即時間序列資料)的場景。為了更好地理解它,讓我們比較一下常規神經網路和迴圈神經網路:
我們知道,在常規神經網路中,我們只能提供一個輸入。這限制了它只能產生一個預測結果。例如,我們可以使用常規神經網路進行文字翻譯工作。
另一方面,在迴圈神經網路中,我們可以提供一系列樣本,從而得到單個預測結果。換句話說,使用RNN,我們可以根據輸入序列預測輸出序列。例如,RNN在翻譯任務中已經進行了一些相當成功的實驗。
迴圈神經網路的用途
RNN可以多種方式使用。其中一些如下:
預測單個輸出
在深入探討RNN如何根據序列預測單個輸出的步驟之前,讓我們看看基本的RNN是什麼樣的:
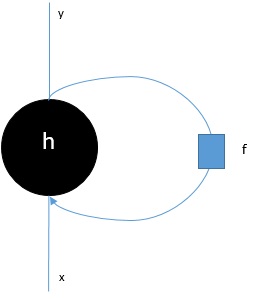
正如上圖所示,RNN包含一個反饋連線到輸入,每當我們饋送一系列值時,它將把序列中的每個元素作為時間步進行處理。
此外,由於反饋連線,RNN可以將生成的輸出與序列中下一個元素的輸入結合起來。透過這種方式,RNN將在整個序列上構建一個記憶,可用於進行預測。
為了用RNN進行預測,我們可以執行以下步驟:
首先,為了建立初始隱藏狀態,我們需要饋送輸入序列的第一個元素。
之後,為了產生更新的隱藏狀態,我們需要獲取初始隱藏狀態並將其與輸入序列中的第二個元素結合。
最後,為了產生最終的隱藏狀態並預測RNN的輸出,我們需要獲取輸入序列中的最後一個元素。
透過這種方式,藉助這種反饋連線,我們可以訓練RNN識別隨時間發生的模式。
預測序列
上面討論的基本RNN模型也可以擴充套件到其他用例。例如,我們可以使用它根據單個輸入預測一系列值。在這種情況下,為了用RNN進行預測,我們可以執行以下步驟:
首先,為了建立初始隱藏狀態並預測輸出序列中的第一個元素,我們需要將輸入樣本饋送到神經網路。
之後,為了產生更新的隱藏狀態和輸出序列中的第二個元素,我們需要將初始隱藏狀態與相同的樣本結合。
最後,為了再次更新隱藏狀態並預測輸出序列中的最後一個元素,我們需要再次饋送樣本。
預測序列
我們已經瞭解瞭如何根據序列預測單個值以及如何根據單個值預測序列。現在讓我們看看如何預測序列的序列。在這種情況下,為了用RNN進行預測,我們可以執行以下步驟:
首先,為了建立初始隱藏狀態並預測輸出序列中的第一個元素,我們需要獲取輸入序列中的第一個元素。
之後,為了更新隱藏狀態並預測輸出序列中的第二個元素,我們需要獲取初始隱藏狀態。
最後,為了預測輸出序列中的最後一個元素,我們需要獲取更新的隱藏狀態和輸入序列中的最後一個元素。
RNN的工作原理
為了理解迴圈神經網路(RNN)的工作原理,我們需要首先了解網路中迴圈層的工作原理。因此,讓我們首先討論如何使用標準迴圈層預測輸出。
使用標準RNN層預測輸出
正如我們前面所討論的,RNN中的基本層與神經網路中的常規層有很大的不同。在上一節中,我們還在圖中演示了RNN的基本架構。為了更新序列中第一個時間步的隱藏狀態,我們可以使用以下公式:

在上式中,我們透過計算初始隱藏狀態和一組權重之間的點積來計算新的隱藏狀態。
現在對於下一步,當前時間步的隱藏狀態將用作序列中下一個時間步的初始隱藏狀態。這就是為什麼為了更新第二個時間步的隱藏狀態,我們可以重複在第一步中執行的計算,如下所示:

接下來,我們可以重複更新序列中第三步(也是最後一步)的隱藏狀態的過程,如下所示:
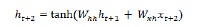
當我們處理了序列中的所有上述步驟後,我們可以計算輸出,如下所示:
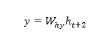
對於上述公式,我們使用了第三組權重和來自最終時間步的隱藏狀態。
高階迴圈單元
基本迴圈層的主要問題是梯度消失問題,因此它在學習長期相關性方面不是很好。簡而言之,基本迴圈層不能很好地處理長序列。這就是為什麼其他一些更適合處理較長序列的迴圈層型別如下所示:
長短期記憶網路(LSTM)

長短期記憶 (LSTM) 網路由 Hochreiter & Schmidhuber 引入。它解決了讓基本迴圈層長時間記住事物的問題。LSTM 的架構如上圖所示。我們可以看到它有輸入神經元、記憶單元和輸出神經元。為了解決梯度消失問題,長短期記憶網路使用顯式記憶單元(儲存先前值)和以下門:
**遺忘門** —顧名思義,它告訴記憶單元忘記之前的數值。記憶單元儲存數值,直到門(即“遺忘門”)告訴它忘記它們。
**輸入門** —顧名思義,它向單元新增新內容。
**輸出門** —顧名思義,輸出門決定何時將向量從單元傳遞到下一個隱藏狀態。
門控迴圈單元(GRU)

**門控迴圈單元**(GRU)是LSTM網路的一個輕微變體。它少了一個門,並且與LSTM的連線方式略有不同。其架構如上圖所示。它具有輸入神經元、門控記憶單元和輸出神經元。門控迴圈單元網路具有以下兩個門:
**更新門** —它確定以下兩件事:
應該保留多少來自最後狀態的資訊?
應該從前一層輸入多少資訊?
**重置門** —重置門的功能與LSTM網路的遺忘門非常相似。唯一的區別是它的位置略有不同。
與長短期記憶網路相比,門控迴圈單元網路執行速度更快,更容易執行。
建立RNN結構
在我們開始對任何資料來源的輸出進行預測之前,我們需要首先構建RNN,構建RNN與我們在上一節中構建常規神經網路的方式非常相似。以下是構建一個RNN的程式碼:
from cntk.losses import squared_error from cntk.io import CTFDeserializer, MinibatchSource, INFINITELY_REPEAT, StreamDefs, StreamDef from cntk.learners import adam from cntk.logging import ProgressPrinter from cntk.train import TestConfig BATCH_SIZE = 14 * 10 EPOCH_SIZE = 12434 EPOCHS = 10
堆疊多層
我們還可以在CNTK中堆疊多個迴圈層。例如,我們可以使用以下層的組合:
from cntk import sequence, default_options, input_variable
from cntk.layers import Recurrence, LSTM, Dropout, Dense, Sequential, Fold
features = sequence.input_variable(1)
with default_options(initial_state = 0.1):
model = Sequential([
Fold(LSTM(15)),
Dense(1)
])(features)
target = input_variable(1, dynamic_axes=model.dynamic_axes)
正如我們在上述程式碼中看到的,我們有以下兩種在CNTK中建模RNN的方法:
首先,如果我們只需要迴圈層的最終輸出,我們可以將`Fold`層與迴圈層(如GRU、LSTM甚至RNNStep)結合使用。
其次,作為另一種方法,我們還可以使用`Recurrence`塊。
使用時間序列資料訓練RNN
構建模型後,讓我們看看如何在CNTK中訓練RNN:
from cntk import Function @Function def criterion_factory(z, t): loss = squared_error(z, t) metric = squared_error(z, t) return loss, metric loss = criterion_factory(model, target) learner = adam(model.parameters, lr=0.005, momentum=0.9)
現在,為了將資料載入到訓練過程中,我們必須從一組CTF檔案中反序列化序列。以下程式碼包含`create_datasource`函式,這是一個有用的實用程式函式,用於建立訓練和測試資料來源。
target_stream = StreamDef(field='target', shape=1, is_sparse=False)
features_stream = StreamDef(field='features', shape=1, is_sparse=False)
deserializer = CTFDeserializer(filename, StreamDefs(features=features_stream, target=target_stream))
datasource = MinibatchSource(deserializer, randomize=True, max_sweeps=sweeps)
return datasource
train_datasource = create_datasource('Training data filename.ctf')#we need to provide the location of training file we created from our dataset.
test_datasource = create_datasource('Test filename.ctf', sweeps=1) #we need to provide the location of testing file we created from our dataset.
現在,我們已經設定了資料來源、模型和損失函式,我們可以開始訓練過程了。這與我們在前面使用基本神經網路時非常相似。
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
target: train_datasource.streams.target
}
history = loss.train(
train_datasource,
epoch_size=EPOCH_SIZE,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config],
minibatch_size=BATCH_SIZE,
max_epochs=EPOCHS
)
我們將得到類似於以下的輸出:
輸出:
average since average since examples loss last metric last ------------------------------------------------------ Learning rate per minibatch: 0.005 0.4 0.4 0.4 0.4 19 0.4 0.4 0.4 0.4 59 0.452 0.495 0.452 0.495 129 […]
驗證模型
實際上,使用RNN進行預測與使用任何其他CNK模型進行預測非常相似。唯一的區別是,我們需要提供序列而不是單個樣本。
現在,我們的RNN最終完成了訓練,我們可以使用一些樣本序列對其進行測試來驗證模型,如下所示:
import pickle
with open('test_samples.pkl', 'rb') as test_file:
test_samples = pickle.load(test_file)
model(test_samples) * NORMALIZE
輸出:
array([[ 8081.7905], [16597.693 ], [13335.17 ], ..., [11275.804 ], [15621.697 ], [16875.555 ]], dtype=float32)