KNIME - 探索工作流
如果您檢視工作流中的節點,您會發現它包含以下內容:
檔案讀取器,
顏色管理器
分割槽
決策樹學習器
決策樹預測器
評分
互動式表格
散點圖
統計
這些在大綱檢視中很容易看到,如下所示:
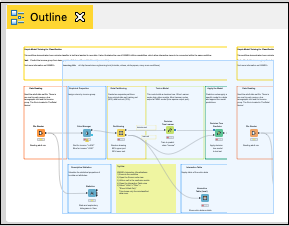
每個節點在工作流中提供特定的功能。我們現在將探討如何配置這些節點以滿足所需的功能。請注意,我們只討論與我們當前探索工作流的上下文相關的節點。
檔案讀取器
檔案讀取器節點在下面的螢幕截圖中顯示:

視窗頂部有一些由工作流建立者提供的描述。它說明此節點讀取成人資料集。從節點符號下方的描述中可以看出,檔名為adult.csv。檔案讀取器有兩個輸出 - 一個連線到顏色管理器節點,另一個連線到統計節點。
如果您右鍵單擊檔案管理器,將顯示如下彈出選單:
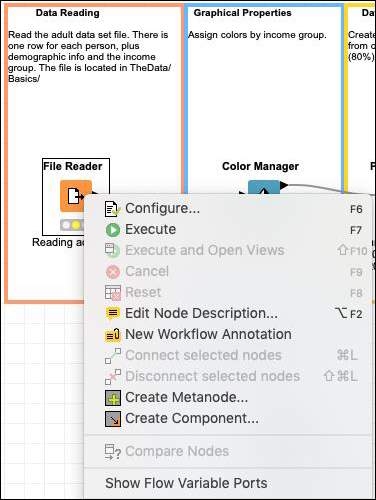
配置選單選項允許節點配置。執行選單執行節點。請注意,如果節點已經執行並且處於綠色狀態,則此選單將被停用。此外,請注意編輯註釋描述選單選項的存在。這允許您為您的節點編寫描述。
現在,選擇配置選單選項,它將顯示包含來自 adult.csv 檔案的資料的螢幕,如此處螢幕截圖所示:
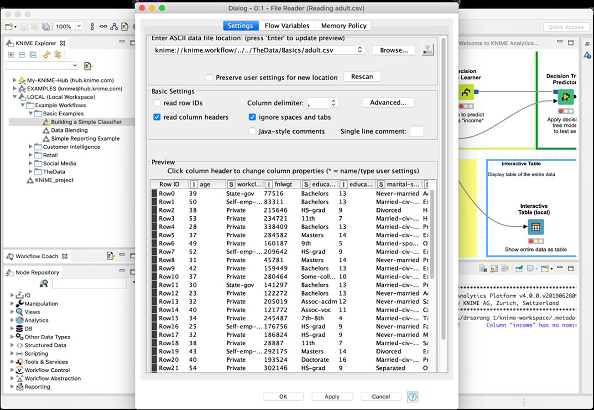
當您執行此節點時,資料將載入到記憶體中。整個資料載入程式程式碼對使用者隱藏。您現在可以理解此類節點的有用性 - 無需編碼。
我們的下一個節點是顏色管理器。
顏色管理器
選擇顏色管理器節點,然後右鍵單擊它進入其配置。將出現顏色設定對話方塊。從下拉列表中選擇收入列。
您的螢幕將如下所示:

注意兩個約束的存在。如果收入低於 50K,則資料點將獲得綠色;如果高於 50K,則獲得紅色。當我們稍後在本章中檢視散點圖時,您將看到資料點對映。
分割槽
在機器學習中,我們通常將所有可用資料分成兩部分。較大部分用於訓練模型,而較小部分用於測試。有不同的策略用於對資料進行分割槽。
要定義所需的分割槽,請右鍵單擊分割槽節點並選擇配置選項。您將看到以下螢幕:
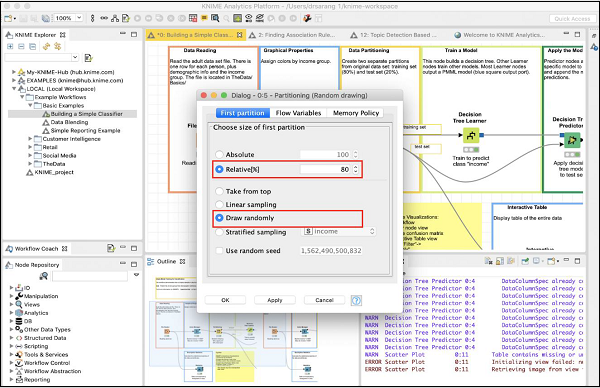
在本例中,系統建模者使用了相對(%)模式,資料以 80:20 的比例分割。在進行拆分時,資料點是隨機選擇的。這確保您的測試資料可能不會有偏差。在進行線性取樣時,用於測試的剩餘 20% 資料可能無法正確地表示訓練資料,因為它在收集過程中可能完全有偏差。
如果您確定在資料收集過程中保證了隨機性,那麼您可以選擇線性取樣。一旦您的資料準備好用於訓練模型,請將其饋送到下一個節點,即決策樹學習器。
決策樹學習器
顧名思義,決策樹學習器節點使用訓練資料並構建模型。檢視此節點的配置設定,如下面的螢幕截圖所示:
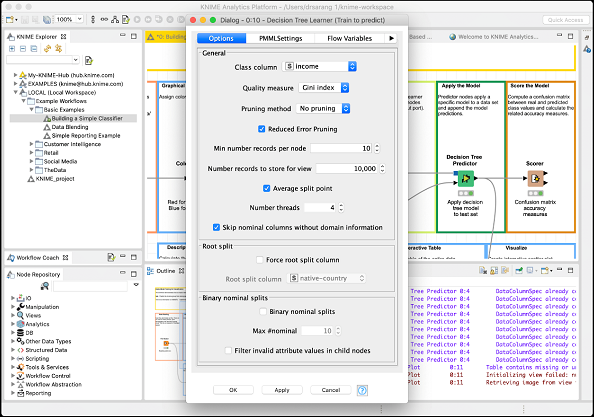
如您所見,類別為收入。因此,樹將基於收入列構建,這就是我們試圖在此模型中實現的目標。我們希望將收入高於或低於 50K 的人分開。
此節點成功執行後,您的模型將準備好進行測試。
決策樹預測器
決策樹預測器節點將開發的模型應用於測試資料集並附加模型預測。
預測器的輸出饋送到兩個不同的節點 - 評分器和散點圖。接下來,我們將檢查預測的輸出。
評分器
此節點生成混淆矩陣。要檢視它,請右鍵單擊節點。您將看到以下彈出選單:
單擊檢視:混淆矩陣選單選項,矩陣將在單獨的視窗中彈出,如此處螢幕截圖所示:
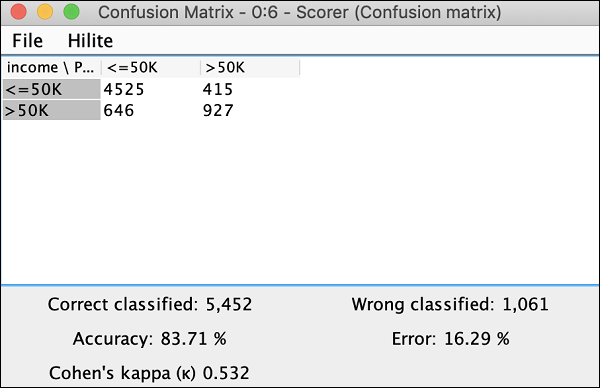
這表明我們開發的模型的準確率為 83.71%。如果您對此不滿意,您可以嘗試更改模型構建中的其他引數,特別是,您可能希望重新審視和清理您的資料。
散點圖
要檢視資料分佈的散點圖,請右鍵單擊散點圖節點並選擇選單選項互動式檢視:散點圖。您將看到以下圖表:
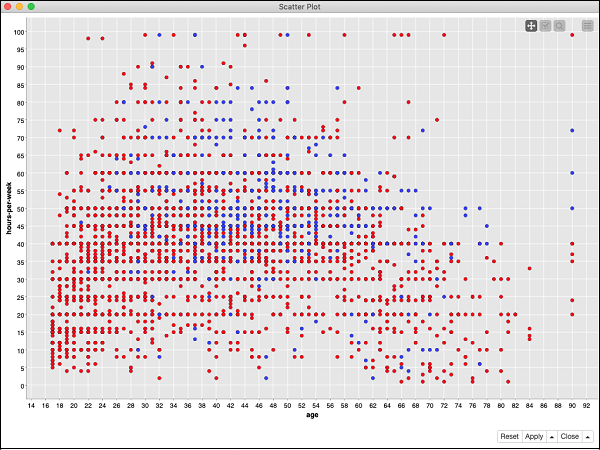
該圖根據 50K 的閾值,以兩種不同顏色的點(紅色和藍色)顯示不同收入群體人員的分佈。這些是在我們的顏色管理器節點中設定的顏色。分佈相對於繪製在 x 軸上的年齡。您可以透過更改節點的配置來為 x 軸選擇不同的特徵。
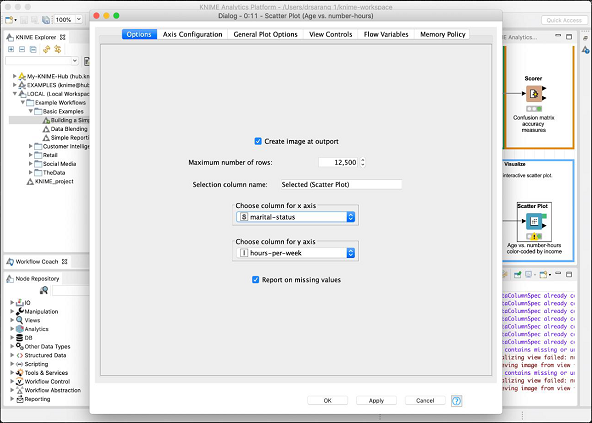
此處顯示配置對話方塊,我們已選擇婚姻狀況作為 x 軸的特徵。
這完成了我們對 KNIME 提供的預定義模型的討論。我們建議您自行學習模型中的其他兩個節點(統計和互動式表格)。
現在讓我們繼續本教程最重要的部分——建立您自己的模型。