KNIME - 構建你自己的模型
在本章中,你將構建你自己的機器學習模型,根據一些觀察到的特徵對植物進行分類。我們將為此目的使用來自UCI 機器學習庫的著名iris資料集。該資料集包含三種不同的植物類別。我們將訓練我們的模型將未知植物分類到這三個類別中的一個。
我們將從在 KNIME 中建立一個新的工作流開始,用於建立我們的機器學習模型。
建立工作流
要建立一個新的工作流,請在 KNIME 工作臺中選擇以下選單選項。
File → New
你將看到以下螢幕:
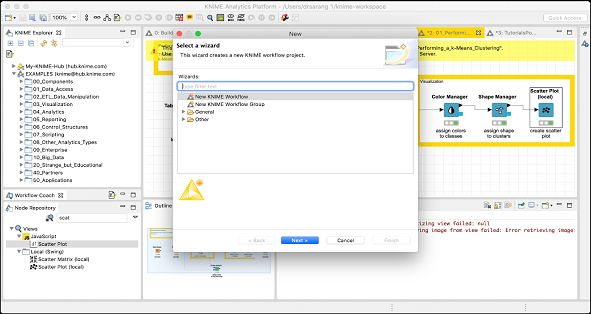
選擇新建 KNIME 工作流選項,然後單擊下一步按鈕。在下一個螢幕上,系統將詢問你工作流的所需名稱以及儲存它的目標資料夾。根據需要輸入此資訊,然後單擊完成以建立一個新的工作區。
一個具有給定名稱的新工作區將新增到工作區檢視中,如下所示:
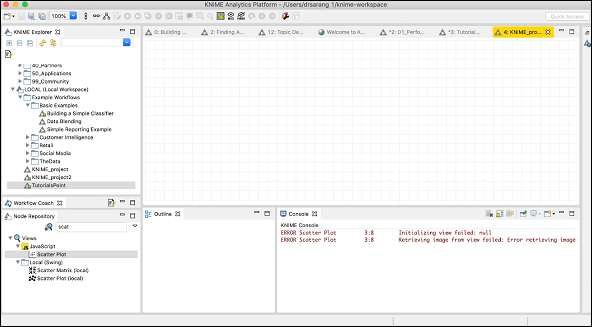
你現在將在此工作區中新增各種節點以建立你的模型。在新增節點之前,你必須下載並準備iris資料集以供我們使用。
準備資料集
從 UCI 機器學習庫網站下載 iris 資料集 下載 Iris 資料集。下載的 iris.data 檔案為 CSV 格式。我們將對其進行一些更改以新增列名。
在您喜歡的文字編輯器中開啟下載的檔案,並在開頭新增以下行:
sepal length, petal length, sepal width, petal width, class
當我們的檔案讀取器節點讀取此檔案時,它將自動將上述欄位作為列名。
現在,你將開始新增各種節點。
新增檔案讀取器
轉到節點資源庫檢視,在搜尋框中輸入“file”以查詢檔案讀取器節點。這在下面的螢幕截圖中可以看到:
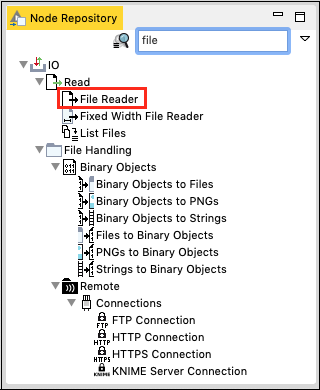
選擇並雙擊檔案讀取器將節點新增到工作區。或者,你可以使用拖放功能將節點新增到工作區。新增節點後,你必須對其進行配置。右鍵單擊節點並選擇配置選單選項。你已經在上一課中完成了此操作。
載入資料檔案後,設定螢幕如下所示。
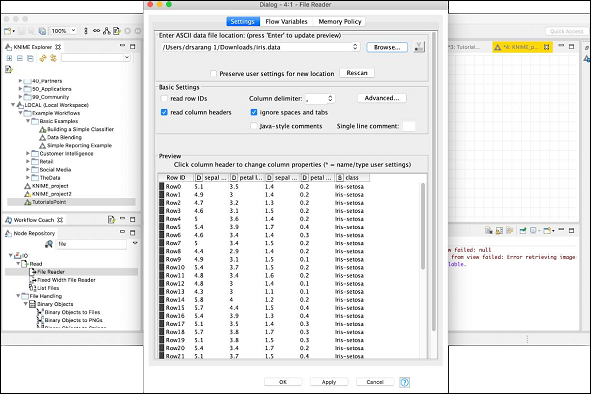
要載入你的資料集,請單擊瀏覽按鈕並選擇 iris.data 檔案的位置。該節點將載入檔案的內容,這些內容顯示在配置框的下部。一旦你確認資料檔案已正確定位並載入,請單擊確定按鈕關閉配置對話方塊。
你現在將為此節點新增一些註釋。右鍵單擊節點並選擇新建工作流注釋選單選項。螢幕上將出現一個註釋框,如下面的螢幕截圖所示
單擊框內並新增以下注釋:
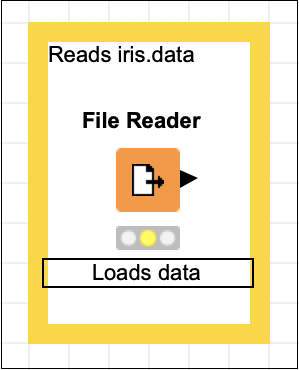
Reads iris.data
單擊框外的任何位置以退出編輯模式。根據需要調整框的大小並將其放置在節點周圍。最後,雙擊節點下方的節點 1文字,將其更改為:
Loads data
此時,你的螢幕將如下所示:
我們現在將新增一個新的節點,用於將我們載入的資料集劃分為訓練集和測試集。
新增分割槽節點
在節點資源庫搜尋視窗中,輸入幾個字元以找到分割槽節點,如下面的螢幕截圖所示:
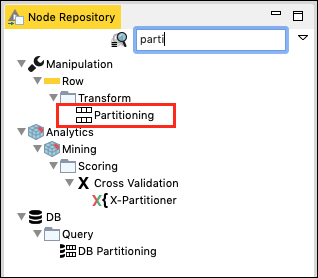
將節點新增到我們的工作區。設定其配置如下:
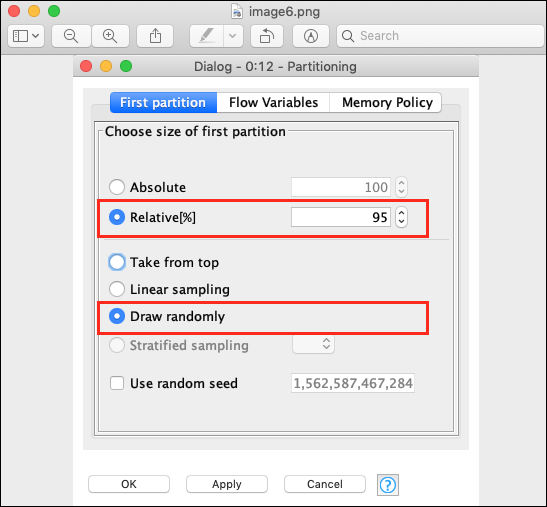
Relative (%) : 95 Draw Randomly
以下螢幕截圖顯示了配置引數。
接下來,在兩個節點之間建立連線。為此,請單擊檔案讀取器節點的輸出,按住滑鼠按鈕,會出現一個橡皮筋線,將其拖動到分割槽節點的輸入,然後釋放滑鼠按鈕。現在在兩個節點之間建立了連線。
添加註釋,更改描述,根據需要放置節點和註釋檢視。在此階段,你的螢幕應如下所示:
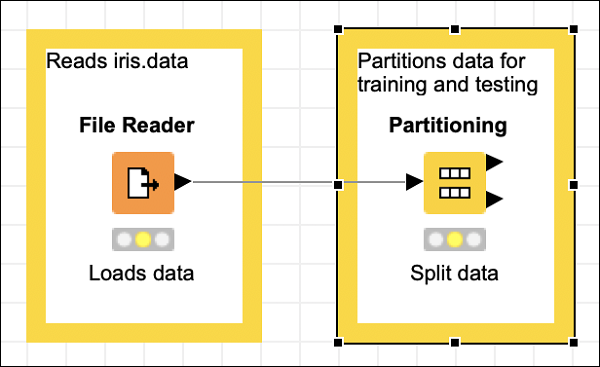
接下來,我們將新增k-Means節點。
新增 k-Means 節點
從資源庫中選擇k-Means節點並將其新增到工作區。如果你想複習 k-Means 演算法的知識,只需在工作臺的描述檢視中查詢其描述。這在下面的螢幕截圖中顯示:

順便說一句,你可以在做出最終決定使用哪個演算法之前,在描述視窗中查詢不同演算法的描述。
開啟節點的配置對話方塊。我們將使用此處顯示的所有欄位的預設值:
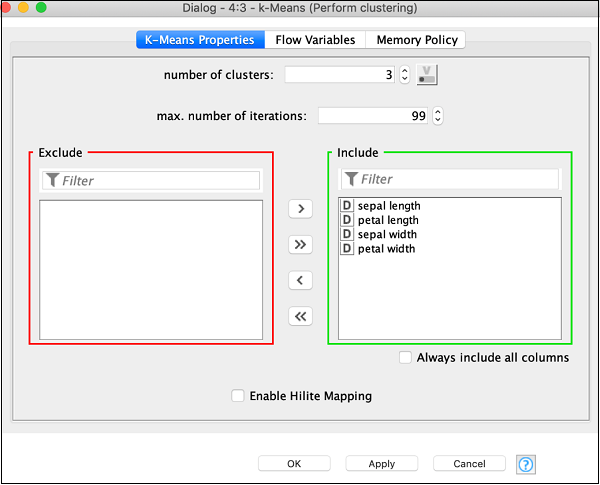
單擊確定以接受預設值並關閉對話方塊。
將註釋和描述設定為以下內容:
註釋:分類叢集
描述:執行聚類
將分割槽節點的頂部輸出連線到k-Means節點的輸入。重新定位你的專案,你的螢幕應如下所示:
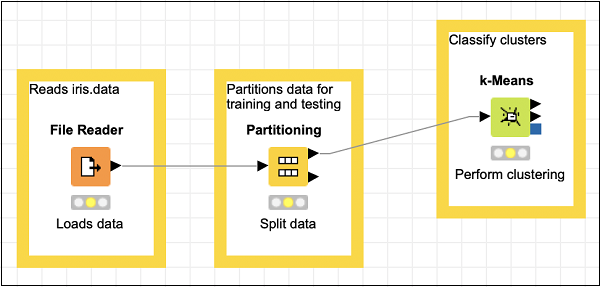
接下來,我們將新增一個聚類分配器節點。
新增聚類分配器
聚類分配器將新資料分配給一組現有的原型。它有兩個輸入——原型模型和包含輸入資料的datatable。在下面的螢幕截圖中描述了節點的描述:
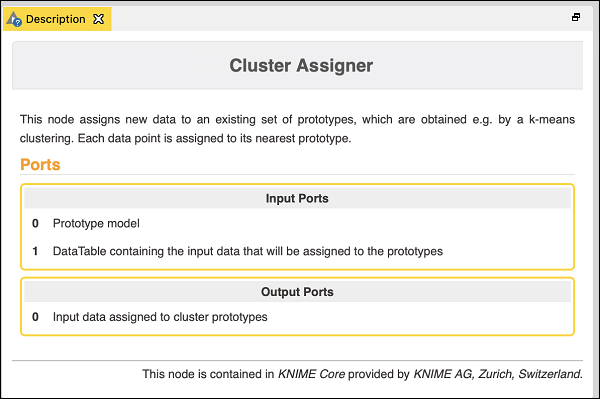
因此,對於此節點,你必須進行兩個連線:
分割槽節點的 PMML 聚類模型輸出→聚類分配器的原型輸入
分割槽節點的第二個分割槽輸出→聚類分配器的輸入資料
這兩個連線在下面的螢幕截圖中顯示:
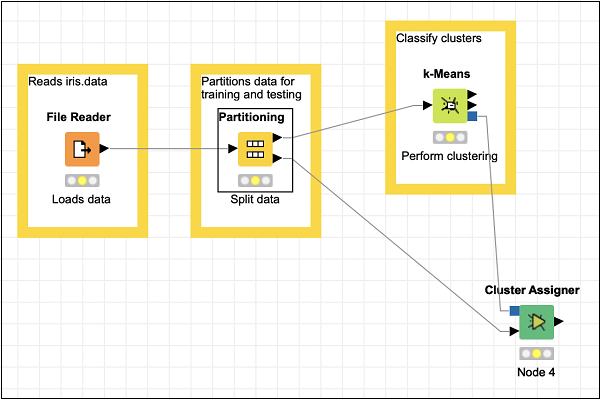
聚類分配器不需要任何特殊配置。只需接受預設值即可。
現在,為此節點新增一些註釋和描述。重新排列你的節點。你的螢幕應如下所示:
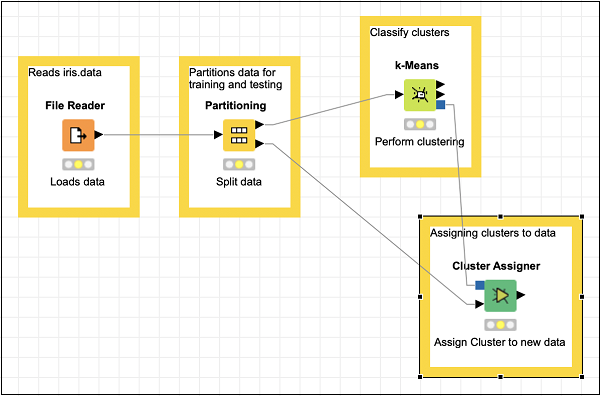
此時,我們的聚類已完成。我們需要以圖形方式視覺化輸出。為此,我們將新增一個散點圖。我們將在散點圖中為三個類別設定不同的顏色和形狀。因此,我們將首先透過顏色管理器節點,然後透過形狀管理器節點過濾k-Means節點的輸出。
新增顏色管理器
在資源庫中找到顏色管理器節點。將其新增到工作區。將配置保留為預設值。請注意,你必須開啟配置對話方塊並點選確定以接受預設值。設定節點的描述文字。
從k-Means的輸出到顏色管理器的輸入建立連線。在此階段,你的螢幕將如下所示:
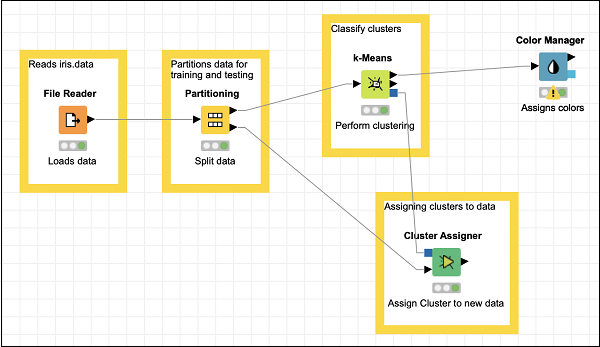
新增形狀管理器
在資源庫中找到形狀管理器並將其新增到工作區。將配置保留為預設值。與前一個一樣,你必須開啟配置對話方塊並點選確定以設定預設值。從顏色管理器的輸出到形狀管理器的輸入建立連線。設定節點的描述。
你的螢幕應如下所示:

現在,你將在我們的模型中新增最後一個節點,那就是散點圖。
新增散點圖
在資源庫中找到散點圖節點並將其新增到工作區。將形狀管理器的輸出連線到散點圖的輸入。將配置保留為預設值。設定描述。
最後,為最近新增的三個節點新增一個組註釋
註釋:視覺化
根據需要重新定位節點。在此階段,你的螢幕應如下所示。
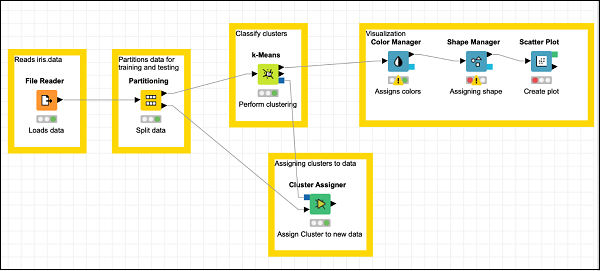
這完成了模型構建的任務。