- KDB+ 教程
- KDB+ - 首頁
- Q 程式語言
- Q 程式語言
- Q 語言 - 型別轉換
- Q 語言 - 時間資料
- Q 語言 - 列表
- Q 語言 - 索引
- Q 語言 - 字典
- Q 語言 - 表格
- Q 語言 - 動詞 & 副詞
- Q 語言 - 連線
- Q 語言 - 函式
- Q 語言 - 內建函式
- Q 語言 - 查詢
- Q - 程序間通訊
- Q - 訊息處理器 (.Z 庫)
- KDB+ 有用資源
- KDB+ 快速指南
- KDB+ - 有用資源
- KDB+ - 討論
KDB+ 快速指南
KDB+ - 概述
這是一份關於kdb+(來自 kx 系統)的完整指南,主要面向獨立學習的人員。kdb+ 於 2003 年推出,是 kdb 資料庫的新一代產品,旨在捕獲、分析、比較和儲存資料。
一個 kdb+ 系統包含以下兩個元件:
KDB+ - 資料庫(k 資料庫加)
Q - 用於操作 kdb+ 的程式語言
kdb+ 和 q 都是用k 程式語言編寫的(與q相同,但可讀性較差)。
背景
Kdb+/q 最初起源於一個鮮為人知的學術語言,但多年來,它逐漸提高了使用者友好性。
APL (1964, A Programming Language)
A+ (1988, Arthur Whitney 修改的 APL)
K (1993, A+ 的簡潔版本,由 A. Whitney 開發)
Kdb (1998, 記憶體列式資料庫)
Kdb+/q (2003, q 語言 – k 的更易讀版本)
為什麼要使用 KDB+ 以及在哪裡使用
為什麼?- 如果你需要一個用於即時資料分析的單一解決方案,那麼你應該考慮 kdb+。Kdb+ 將資料庫儲存為普通的本地檔案,因此它對硬體和儲存架構沒有特殊需求。值得指出的是,資料庫只是一組檔案,因此你的管理工作不會很困難。
在哪裡使用 KDB+?- 很容易統計哪些投資銀行沒有使用 kdb+,因為大多數銀行目前正在使用或計劃從傳統的資料庫切換到 kdb+。隨著資料量的逐日增加,我們需要一個能夠處理海量資料的系統。KDB+ 滿足了這一需求。KDB+ 不僅儲存大量資料,而且還可以即時分析資料。
入門
有了這些背景知識,讓我們開始學習如何為 KDB+ 設定環境。我們將從如何下載和安裝 KDB+ 開始。
下載 & 安裝 KDB+
您可以從http://kx.com/software-download.php獲取 KDB+ 的免費 32 位版本,它具有 64 位版本的所有功能。
同意許可協議,選擇作業系統(適用於所有主要作業系統)。對於 Windows 作業系統,最新版本為 3.2。下載最新版本。解壓縮後,您將獲得名為“windows”的資料夾,在 windows 資料夾內,您將獲得另一個名為“q”的資料夾。將整個q資料夾複製到您的 c:/ 驅動器上。
開啟“執行”終端,鍵入儲存q資料夾的位置;它將類似於“c:/q/w32/q.exe”。按下 Enter 鍵後,您將獲得一個新的控制檯,如下所示:

在第一行,您可以看到版本號為 3.2,釋出日期為 2015.03.05。
目錄佈局
試用/免費版本通常安裝在以下目錄中:
對於 Linux/Mac -
~/q / main q directory (under the user’s home) ~/q/l32 / location of linux 32-bit executable ~/q/m32 / Location of mac 32-bit executable
對於 Windows -
c:/q / Main q directory c:/q/w32/ / Location of windows 32-bit executable
示例檔案 -
下載 kdb+ 後,Windows 平臺上的目錄結構將如下所示:

在上面的目錄結構中,trade.q 和 sp.q 是我們可以用作參考點的示例檔案。
KDB+ - 架構
Kdb+ 是一個高效能、高容量的資料庫,從一開始就設計用於處理海量資料。它是完全 64 位的,並內建了多核處理和多執行緒功能。相同的架構用於即時和歷史資料。資料庫包含其自身強大的查詢語言q,因此可以直接在資料上執行分析。
kdb+tick 是一種架構,允許捕獲、處理和查詢即時和歷史資料。
Kdb+/ tick 架構
下圖提供了典型 Kdb+/tick 架構的概括性概述,隨後是對各個元件和資料貫穿流程的簡要說明。

資料饋送是指通常由資料饋送提供商(如路透社、彭博社或直接來自交易所)提供的時間序列資料。
為了獲取相關資料,來自資料饋送的資料將由饋送處理器進行解析。
饋送處理器解析資料後,資料將傳送到行情資料處理程式。
為了從任何故障中恢復資料,行情資料處理程式首先將新資料更新/儲存到日誌檔案中,然後更新其自身表格。
更新內部表格和日誌檔案後,即時迴圈資料將持續傳送/釋出到即時資料庫以及所有請求資料的連結訂閱者。
在某個營業日結束時,日誌檔案將被刪除,建立一個新的日誌檔案,並將即時資料庫儲存到歷史資料庫中。所有資料儲存到歷史資料庫後,即時資料庫將清除其表格。
Kdb+ Tick 架構的元件
資料饋送
資料饋送可以是任何市場或其他時間序列資料。將資料饋送視為饋送處理器的原始輸入。饋送可以來自交易所(即時資料流)、來自新聞/資料提供商(如湯森路透、彭博社)或任何其他外部機構。
饋送處理器
饋送處理器將資料流轉換為適合寫入 kdb+ 的格式。它連線到資料饋送,並從特定於饋送的格式中檢索和轉換資料,轉換為 Kdb+ 訊息,並將其釋出到行情資料處理程式程序。通常,饋送處理器用於執行以下操作:
- 根據一組規則捕獲資料。
- 將資料從一種格式轉換為另一種格式(/豐富)。
- 捕獲最新的值。
行情資料處理程式
行情資料處理程式是 KDB+ 架構中最重要的元件。它是行情資料處理程式,即時資料庫或直接訂閱者(客戶端)連線到它以訪問財務資料。它以釋出和訂閱機制執行。一旦你獲得訂閱(許可證),就會定義來自發布者(行情資料處理程式)的滴答(例行)釋出。它執行以下操作:
接收來自饋送處理器的的資料。
行情資料處理程式收到資料後,會立即將其副本儲存為日誌檔案,並在行情資料處理程式獲取任何更新時更新它,以便在發生任何故障時,我們不會丟失任何資料。
客戶端(即時訂閱者)可以直接訂閱行情資料處理程式。
在每個營業日結束時,即即時資料庫收到最後一條訊息後,它會將今天的所有資料儲存到歷史資料庫中,並將其推送到所有訂閱了今天資料的訂閱者。然後它重置所有表格。一旦資料儲存在歷史資料庫或其他直接連結到即時資料庫 (rtdb) 的訂閱者中,日誌檔案也會被刪除。
因此,行情資料處理程式、即時資料庫和歷史資料庫全天候執行。
由於行情資料處理程式是 Kdb+ 應用程式,因此可以使用q像任何其他 Kdb+ 資料庫一樣查詢其表格。所有行情資料處理程式客戶端都應該只能作為訂閱者訪問資料庫。
即時資料庫
即時資料庫 (rdb) 儲存今天的資料。它直接連線到行情資料處理程式。通常,它會在市場交易時間(一天)儲存在記憶體中,並在一天結束時寫入歷史資料庫 (hdb)。由於資料 (rdb 資料) 儲存在記憶體中,因此處理速度非常快。
由於 kdb+ 建議 RAM 大小為每天預期資料大小的四倍或更多,因此在 rdb 上執行的查詢非常快,並提供卓越的效能。由於即時資料庫僅包含今天的資料,因此不需要日期列(引數)。
例如,我們可以執行以下 rdb 查詢:
select from trade where sym = `ibm OR select from trade where sym = `ibm, price > 100
歷史資料庫
如果我們需要計算公司的估值,我們需要其歷史資料可用。歷史資料庫 (hdb) 儲存過去交易的資料。每天的新記錄都會在一天結束時新增到 hdb 中。hdb 中的大型表格要麼被展開儲存(每列儲存在其自己的檔案中),要麼按時間資料進行分割槽儲存。此外,一些非常大的資料庫可以使用par.txt (檔案)進一步分割槽。
這些儲存策略(展開、分割槽等)在搜尋或訪問大型表格中的資料時非常有效。
歷史資料庫還可以用於內部和外部報告目的,即用於分析。例如,假設我們想從 trade(或任何)表格名稱中獲取 IBM 在特定日期的公司交易,我們需要編寫如下查詢:
thisday: 2014.10.12 select from trade where date = thisday, sym =`ibm
注意 - 一旦我們對q語言有所瞭解,我們將編寫所有此類查詢。
Q 程式語言
Kdb+ 帶有其內建的程式語言,稱為q。它包含標準 SQL 的超集,該超集擴充套件用於時間序列分析,並且相對於標準版本提供了許多優勢。任何熟悉 SQL 的人都可以在幾天內學習q,並能夠快速編寫自己的臨時查詢。
啟動“q”環境
要開始使用 kdb+,您需要啟動q會話。有三種方法可以啟動q會話:
在您的執行終端上簡單地鍵入“c:/q/w32/q.exe”。
啟動 MS-DOS 命令終端並鍵入q。
將q.exe檔案複製到“C:\Windows\System32”,並在執行終端上,只需鍵入“q”。
這裡我們假設您正在 Windows 平臺上工作。
資料型別
下表提供了支援的資料型別的列表:
| 名稱 | 示例 | 字元 | 型別 | 大小 |
|---|---|---|---|---|
| 布林值 | 1b | b | 1 | 1 |
| 位元組 | 0xff | x | 4 | 1 |
| 短整型 | 23h | h | 5 | 2 |
| 整型 | 23i | i | 6 | 4 |
| 長整型 | 23j | j | 7 | 8 |
| 實數 | 2.3e | e | 8 | 4 |
| 浮點數 | 2.3f | f | 9 | 8 |
| 字元 | “a” | c | 10 | 1 |
| 可變字元 | `ab | s | 11 | * |
| 月份 | 2003.03m | m | 13 | 4 |
| 日期 | 2015.03.17T18:01:40.134 | z | 15 | 8 |
| 分鐘 | 08:31 | u | 17 | 4 |
| 秒 | 08:31:53 | v | 18 | 4 |
| 時間 | 18:03:18.521 | t | 19 | 4 |
| 列舉 | `u$`b, where u:`a`b | * | 20 | 4 |
原子和列表形成
原子是單個實體,例如,單個數字、字元或符號。在上表(不同資料型別)中,所有支援的資料型別都是原子。列表是原子或其他型別的序列,包括列表。
將任何型別的原子傳遞給一元(即單引數函式)型別函式將返回一個負值,即–n,而將這些原子的簡單列表傳遞給型別函式將返回一個正值n。
示例 1 – 原子和列表的形成
/ Note that the comments begin with a slash “ / ” and cause the parser / to ignore everything up to the end of the line. x: `mohan / `mohan is a symbol, assigned to a variable x type x / let’s check the type of x -11h / -ve sign, because it’s single element. y: (`abc;`bca;`cab) / list of three symbols, y is the variable name. type y 11h / +ve sign, as it contain list of atoms (symbol). y1: (`abc`bca`cab) / another way of writing y, please note NO semicolon y2: (`$”symbols may have interior blanks”) / string to symbol conversion y[0] / return `abc y 0 / same as y[0], also returns `abc y 0 2 / returns `abc`cab, same as does y[0 2] z: (`abc; 10 20 30; (`a`b); 9.9 8.8 7.7) / List of different types, z 2 0 / returns (`a`b; `abc), z[2;0] / return `a. first element of z[2] x: “Hello World!” / list of character, a string x 4 0 / returns “oH” i.e. 4th and 0th(first) element
Q 語言 - 型別轉換
通常需要將某些資料的資料型別從一種型別更改為另一種型別。標準的轉換函式是“$”二元運算子。
有三種方法用於從一種型別轉換為另一種型別(字串除外)−
- 透過其符號名稱指定所需的資料型別
- 透過其字元指定所需的資料型別
- 透過其短值指定所需的資料型別。
將整數轉換為浮點數
在以下將整數轉換為浮點數的示例中,所有三種不同的轉換方式都是等效的−
q)a:9 18 27 q)$[`float;a] / Specify desired data type by its symbol name, 1st way 9 18 27f q)$["f";a] / Specify desired data type by its character, 2nd way 9 18 27f q)$[9h;a] / Specify desired data type by its short value, 3rd way 9 18 27f
檢查所有三個操作是否等效,
q)($[`float;a]~$["f";a]) and ($[`float;a] ~ $[9h;a]) 1b
將字串轉換為符號
將字串轉換為符號反之亦然的工作方式略有不同。讓我們用一個例子來檢查一下−
q)b: ("Hello";"World";"HelloWorld") / define a list of strings
q)b
"Hello"
"World"
"HelloWorld"
q)c: `$b / this is how to cast strings to symbols
q)c / Now c is a list of symbols
`Hello`World`HelloWorld
嘗試使用關鍵字`symbol 或 11h 將字串轉換為符號將導致型別錯誤−
q)b "Hello" "World" "HelloWorld" q)`symbol$b 'type q)11h$b 'type
將字串轉換為非符號
將字串轉換為除符號以外的資料型別,方法如下−
q)b:900 / b contain single atomic integer
q)c:string b / convert this integer atom to string “900”
q)c
"900"
q)`int $ c / converting string to integer will return the
/ ASCII equivalent of the character “9”, “0” and
/ “0” to produce the list of integer 57, 48 and
/ 48.
57 48 48i
q)6h $ c / Same as above
57 48 48i
q)"i" $ c / Same a above
57 48 48i
q)"I" $ c
900i
因此,要將整個字串(字元列表)轉換為資料型別為x的單個原子,我們需要將表示資料型別x的大寫字母指定為$運算子的第一個引數。如果以任何其他方式指定資料型別x,則會導致轉換應用於字串的每個字元。
Q 語言 - 時間資料
q語言有許多不同的方法來表示和操作時間資料,例如時間和日期。
日期
kdb+中的日期在內部儲存為自我們的參考日期2000年1月1日以來的天數整數。此日期之後的日期在內部儲存為正數,在此日期之前的日期則引用為負數。
預設情況下,日期以“YYYY.MM.DD”格式寫入
q)x:2015.01.22 / This is how we write 22nd Jan 2015 q)`int$x / Number of days since 2000.01.01 5500i q)`year$x / Extracting year from the date 2015i q)x.year / Another way of extracting year 2015i q)`mm$x / Extracting month from the date 1i q)x.mm / Another way of extracting month 1i q)`dd$x / Extracting day from the date 22i q)x.dd / Another way of extracting day 22i
可以直接對日期執行算術和邏輯運算。
q)x+1 / Add one day 2015.01.23 q)x-7 / Subtract 7 days 2015.01.15
2000年1月1日是星期六。因此,歷史上或未來任何一個星期六除以7,餘數都為0,星期日為1,星期一為2。
Day mod 7
Saturday 0
Sunday 1
Monday 2
Tuesday 3
Wednesday 4
Thursday 5
Friday 6
時間
時間在內部儲存為自午夜開始的毫秒數整數。時間以HH:MM:SS.MSS格式寫入
q)tt1: 03:30:00.000 / tt1 store the time 03:30 AM q)tt1 03:30:00.000 q)`int$tt1 / Number of milliseconds in 3.5 hours 12600000i q)`hh$tt1 / Extract the hour component from time 3i q)tt1.hh 3i q)`mm$tt1 / Extract the minute component from time 30i q)tt1.mm 30i q)`ss$tt1 / Extract the second component from time 0i q)tt1.ss 0i
與日期一樣,可以直接對時間執行算術運算。
日期時間
日期時間是日期和時間的組合,以ISO標準格式中的“T”分隔。日期時間值儲存自2000年1月1日午夜以來的小數天數。
q)dt:2012.12.20T04:54:59:000 / 04:54.59 AM on 20thDec2012 q)type dt -15h q)dt 2012.12.20T04:54:59.000 9 q)`float$dt 4737.205
可以透過轉換為浮點數來獲取底層的小數天數。
Q 語言 - 列表
列表是q語言的基本構建塊,因此徹底瞭解列表非常重要。列表只是原子(原子元素)和其他列表(一個或多個原子的組)的有序集合。
列表型別
通用列表將其專案括在匹配的括號內,並用分號分隔。例如−
(9;8;7) or ("a"; "b"; "c") or (-10.0; 3.1415e; `abcd; "r")
如果列表包含相同型別的原子,則稱為統一列表。否則,稱為通用列表(混合型別)。
計數
我們可以透過列表的計數獲取列表中的專案數。
q)l1:(-10.0;3.1415e;`abcd;"r") / Assigning variable name to general list q)count l1 / Calculating number of items in the list l1 4
簡單列表的示例
q)h:(1h;2h;255h) / Simple Integer List
q)h
1 2 255h
q)f:(123.4567;9876.543;98.7) / Simple Floating Point List
q)f
123.4567 9876.543 98.7
q)b:(0b;1b;0b;1b;1b) / Simple Binary Lists
q)b
01011b
q)symbols:(`Life;`Is;`Beautiful) / Simple Symbols List
q)symbols
`Life`Is`Beautiful
q)chars:("h";"e";"l";"l";"o";" ";"w";"o";"r";"l";"d")
/ Simple char lists and Strings.
q)chars
"hello world"
**注意 - 字元的簡單列表稱為字串。**
列表包含原子或列表。要建立單項列表,我們使用−
q)singleton:enlist 42 q)singleton ,42
要區分原子和等效的單例,檢查其型別的符號。
q)signum type 42 -1i q)signum type enlist 42 1i
Q 語言 - 索引
列表按其專案的順序從左到右排序。專案從列表開頭到其位置的偏移量稱為其索引。因此,第一個專案的索引為0,第二個專案(如果有)的索引為1,依此類推。計數為n的列表的索引域為0到n–1。
索引表示法
給定一個列表L,索引為i的專案透過L[i]訪問。透過其索引檢索專案稱為專案索引。例如,
q)L:(99;98.7e;`b;`abc;"z") q)L[0] 99 q)L[1] 98.7e q)L[4] "z
索引賦值
列表中的專案也可以透過專案索引進行賦值。因此,
q)L1:9 8 7
q)L1[2]:66 / Indexed assignment into a simple list
/ enforces strict type matching.
q)L1
9 8 66
來自變數的列表
q)l1:(9;8;40;200) q)l2:(1 4 3; `abc`xyz) q)l:(l1;l2) / combining the two list l1 and l2 q)l 9 8 40 200 (1 4 3;`abc`xyz)
連線列表
兩個列表上最常見的操作是將它們連線在一起以形成一個更大的列表。更準確地說,連線運算子 (,) 將其右運算元追加到左運算元的末尾並返回結果。它接受任一引數中的原子。
q)1,2 3 4
1 2 3 4
q)1 2 3, 4.4 5.6 / If the arguments are not of uniform type,
/ the result is a general list.
1
2
3
4.4
5.6
巢狀
資料複雜性是透過使用列表作為列表的專案來構建的。
深度
列表的巢狀級別數稱為其深度。原子的深度為0,簡單列表的深度為1。
q)l1:(9;8;(99;88)) q)count l1 3
這是一個深度為3且有兩個專案的列表−
q)l5 9 (90;180;900 1800 2700 3600) q)count l5 2 q)count l5[1] 3
深度索引
可以直接索引到巢狀列表的專案中。
重複專案索引
透過單個索引檢索專案始終從巢狀列表中檢索最上面的專案。
q)L:(1;(100;200;(300;400;500;600))) q)L[0] 1 q)L[1] 100 200 300 400 500 600
由於結果L[1]本身是一個列表,因此我們可以使用單個索引檢索其元素。
q)L[1][2] 300 400 500 600
我們可以再次重複單個索引以從最內部的巢狀列表中檢索專案。
q)L[1][2][0] 300
您可以這樣理解,
從 L 中獲取索引為 1 的專案,並從中檢索索引為 2 的專案,並從中檢索索引為 0 的專案。
深度索引表示法
對於重複索引到巢狀列表的組成部分,有一種替代表示法。最後一次檢索也可以寫成,
q)L[1;2;0] 300
透過索引的賦值也適用於深度。
q)L[1;2;1]:900 q)L 1 (100;200;300 900 500 600)
省略索引
省略通用列表的索引
q)L:((1 2 3; 4 5 6 7); (`a`b`c;`d`e`f`g;`0`1`2);("good";"morning"))
q)L
(1 2 3;4 5 6 7)
(`a`b`c;`d`e`f`g;`0`1`2)
("good";"morning")
q)L[;1;]
4 5 6 7
`d`e`f`g
"morning"
q)L[;;2]
3 6
`c`f`2
"or"
將 L[;1;] 解釋為,
檢索頂層每個列表中第二個位置的所有專案。
將 L[;;2] 解釋為,
檢索第二級每個列表中第三個位置的專案。
Q 語言 - 字典
字典是列表的擴充套件,為建立表提供了基礎。在數學術語中,字典建立了
“域 → 範圍”
或者一般(簡短)建立
“鍵 → 值”
元素之間的關係。
字典是有序的鍵值對集合,大致相當於雜湊表。字典是透過位置對應關係由域列表和範圍列表之間的顯式 I/O 關聯定義的對映。字典的建立使用“xkey”原語(!)
ListOfDomain ! ListOfRange
最基本的字典將簡單列表對映到簡單列表。
| 輸入 (I) | 輸出 (O) |
|---|---|
| `姓名 | `約翰 |
| `年齡 | 36 |
| `性別 | “M” |
| 體重 | 60.3 |
q)d:`Name`Age`Sex`Weight!(`John;36;"M";60.3) / Create a dictionary d q)d Name | `John Age | 36 Sex | "M" Weight | 60.3 q)count d / To get the number of rows in a dictionary. 4 q)key d / The function key returns the domain `Name`Age`Sex`Weight q)value d / The function value returns the range. `John 36 "M" 60.3 q)cols d / The function cols also returns the domain. `Name`Age`Sex`Weight
查詢
查詢與輸入值對應的字典輸出值稱為查詢輸入。
q)d[`Name] / Accessing the value of domain `Name `John q)d[`Name`Sex] / extended item-wise to a simple list of keys `John "M"
使用動詞 @ 進行查詢
q)d1:`one`two`three!9 18 27 q)d1[`two] 18 q)d1@`two 18
字典操作
修改和更新
與列表一樣,可以透過索引賦值修改字典的專案。
d:`Name`Age`Sex`Weight! (`John;36;"M";60.3)
/ A dictionary d
q)d[`Age]:35 / Assigning new value to key Age
q)d
/ New value assigned to key Age in d
Name | `John
Age | 35
Sex | "M"
Weight | 60.3
可以透過索引賦值擴充套件字典。
q)d[`Height]:"182 Ft" q)d Name | `John Age | 35 Sex | "M" Weight | 60.3 Height | "182 Ft"
使用查詢 (?) 進行反向查詢
查詢 (?) 運算子用於透過將一系列元素對映到其域元素來執行反向查詢。
q)d2:`x`y`z!99 88 77 q)d2?77 `z
如果列表的元素不唯一,則查詢返回從域列表中對映到它的第一個專案。
刪除條目
要從字典中刪除條目,可以使用刪除 ( _ ) 函式。(_) 的左運算元是字典,右運算元是鍵值。
q)d2:`x`y`z!99 88 77 q)d2 _`z x| 99 y| 88
如果第一個運算元是變數,則需要在 _ 的左側新增空格。
q)`x`y _ d2 / Deleting multiple entries z| 77
列字典
列字典是建立表的基石。請考慮以下示例−
q)scores: `name`id!(`John`Jenny`Jonathan;9 18 27)
/ Dictionary scores
q)scores[`name] / The values for the name column are
`John`Jenny`Jonathan
q)scores.name / Retrieving the values for a column in a
/ column dictionary using dot notation.
`John`Jenny`Jonathan
q)scores[`name][1] / Values in row 1 of the name column
`Jenny
q)scores[`id][2] / Values in row 2 of the id column is
27
翻轉字典
翻轉列字典的最終效果只是反轉索引的順序。這在邏輯上等同於轉置行和列。
在列字典上翻轉
字典的轉置是透過應用一元翻轉運算子獲得的。看看下面的例子−
q)scores name | John Jenny Jonathan id | 9 18 27 q)flip scores name id --------------- John 9 Jenny 18 Jonathan 27
翻轉列字典的翻轉
如果轉置字典兩次,則會獲得原始字典,
q)scores ~ flip flip scores 1b
Q 語言 - 表格
表是kdb+的核心。表是作為字典實現的命名列的集合。q表是面向列的。
建立表
使用以下語法建立表−
q)trade:([]time:();sym:();price:();size:()) q)trade time sym price size -------------------
在上面的例子中,我們沒有指定每一列的型別。這將由第一次插入表中設定。
另一種方法,我們可以在初始化時指定列型別−
q)trade:([]time:`time$();sym:`$();price:`float$();size:`int$())
或者我們也可以定義非空表−
q)trade:([]sym:(`a`b);price:(1 2)) q)trade sym price ------------- a 1 b 2
如果方括號內沒有列,如上例所示,則表為無鍵。
要建立鍵表,我們將鍵的列插入方括號中。
q)trade:([sym:`$()]time:`time$();price:`float$();size:`int$()) q)trade sym | time price size ----- | ---------------
也可以透過將值設定為各種型別的空列表來定義列型別−
q)trade:([]time:0#0Nt;sym:0#`;price:0#0n;size:0#0N)
獲取表資訊
讓我們建立一個交易表−
trade: ([]sym:`ibm`msft`apple`samsung;mcap:2000 4000 9000 6000;ex:`nasdaq`nasdaq`DAX`Dow) q)cols trade / column names of a table `sym`mcap`ex q)trade.sym / Retrieves the value of column sym `ibm`msft`apple`samsung q)show meta trade / Get the meta data of a table trade. c | t f a ----- | ----- Sym | s Mcap | j ex | s
主鍵和鍵表
鍵表
鍵表是一個字典,它將唯一鍵表中的每一行對映到值表中的對應行。讓我們舉個例子−
val:flip `name`id!(`John`Jenny`Jonathan;9 18 27)
/ a flip dictionary create table val
id:flip (enlist `eid)!enlist 99 198 297
/ flip dictionary, having single column eid
現在建立一個包含 eid 作為鍵的簡單鍵表,
q)valid: id ! val q)valid / table name valid, having key as eid eid | name id --- | --------------- 99 | John 9 198 | Jenny 18 297 | Jonathan 27
外部索引鍵
外部索引鍵定義了從定義它的表的行到具有相應主鍵的表的行的對映。
外部索引鍵提供引用完整性。換句話說,嘗試插入主鍵中不存在的外部索引鍵值將失敗。
請考慮以下示例。在第一個示例中,我們將在外部索引鍵初始化時顯式定義外部索引鍵。在第二個示例中,我們將使用外部索引鍵追溯,它不假設兩個表之間存在任何先前的關係。
示例 1 - 在初始化時定義外部索引鍵
q)sector:([sym:`SAMSUNG`HSBC`JPMC`APPLE]ex:`N`CME`DAQ`N;MC:1000 2000 3000 4000) q)tab:([]sym:`sector$`HSBC`APPLE`APPLE`APPLE`HSBC`JPMC;price:6?9f) q)show meta tab c | t f a ------ | ---------- sym | s sector price | f q)show select from tab where sym.ex=`N sym price ---------------- APPLE 4.65382 APPLE 4.643817 APPLE 3.659978
示例 2 - 表之間沒有預定義的關係
sector: ([symb:`IBM`MSFT`HSBC]ex:`N`CME`N;MC:1000 2000 3000) tab:([]sym:`IBM`MSFT`MSFT`HSBC`HSBC;price:5?9f)
要使用外部索引鍵追溯,我們必須建立一個表來作為扇區的鍵。
q)show update mc:(sector([]symb:sym))[`MC] from tab sym price mc -------------------------- IBM 7.065297 1000 MSFT 4.812387 2000 MSFT 6.400545 2000 HSBC 3.704373 3000 HSBC 4.438651 3000
預定義外部索引鍵的一般表示法 -
從 c 中選擇 a.b 其中 a 是外部索引鍵 (sym),b 是
主鍵表中的欄位 (ind),c 是
外部索引鍵表 (trade)
操作表
讓我們建立一個交易表並檢查不同表表達式的結果 -
q)trade:([]sym:5?`ibm`msft`hsbc`samsung;price:5?(303.00*3+1);size:5?(900*5);time:5?(.z.T-365)) q)trade sym price size time ----------------------------------------- msft 743.8592 3162 02:32:17.036 msft 641.7307 2917 01:44:56.936 hsbc 838.2311 1492 00:25:23.210 samsung 278.3498 1983 00:29:38.945 ibm 838.6471 4006 07:24:26.842
現在讓我們看一下用於使用q語言操作表的語句。
選擇
使用Select語句的語法如下 -
select [columns] [by columns] from table [where clause]
現在讓我們舉一個例子來演示如何使用Select語句 -
q)/ select expression example
q)select sym,price,size by time from trade where size > 2000
time | sym price size
------------- | -----------------------
01:44:56.936 | msft 641.7307 2917
02:32:17.036 | msft 743.8592 3162
07:24:26.842 | ibm 838.6471 4006
插入
使用Insert語句的語法如下 -
`tablename insert (values) Insert[`tablename; values]
現在讓我們舉一個例子來演示如何使用Insert語句 -
q)/ Insert expression example q)`trade insert (`hsbc`apple;302.0 730.40;3020 3012;09:30:17.00409:15:00.000) 5 6 q)trade sym price size time ------------------------------------------ msft 743.8592 3162 02:32:17.036 msft 641.7307 2917 01:44:56.936 hsbc 838.2311 1492 00:25:23.210 samsung 278.3498 1983 00:29:38.945 ibm 838.6471 4006 07:24:26.842 hsbc 302 3020 09:30:17.004 apple 730.4 3012 09:15:00.000 q)/Insert another value q)insert[`trade;(`samsung;302.0; 3333;10:30:00.000] '] q)insert[`trade;(`samsung;302.0; 3333;10:30:00.000)] ,7 q)trade sym price size time ---------------------------------------- msft 743.8592 3162 02:32:17.036 msft 641.7307 2917 01:44:56.936 hsbc 838.2311 1492 00:25:23.210 samsung 278.3498 1983 00:29:38.945 ibm 838.6471 4006 07:24:26.842 hsbc 302 3020 09:30:17.004 apple 730.4 3012 09:15:00.000 samsung 302 3333 10:30:00.000
刪除
使用Delete語句的語法如下 -
delete columns from table delete from table where clause
現在讓我們舉一個例子來演示如何使用Delete語句 -
q)/Delete expression example q)delete price from trade sym size time ------------------------------- msft 3162 02:32:17.036 msft 2917 01:44:56.936 hsbc 1492 00:25:23.210 samsung 1983 00:29:38.945 ibm 4006 07:24:26.842 hsbc 3020 09:30:17.004 apple 3012 09:15:00.000 samsung 3333 10:30:00.000 q)delete from trade where price > 3000 sym price size time ------------------------------------------- msft 743.8592 3162 02:32:17.036 msft 641.7307 2917 01:44:56.936 hsbc 838.2311 1492 00:25:23.210 samsung 278.3498 1983 00:29:38.945 ibm 838.6471 4006 07:24:26.842 hsbc 302 3020 09:30:17.004 apple 730.4 3012 09:15:00.000 samsung 302 3333 10:30:00.000 q)delete from trade where price > 500 sym price size time ----------------------------------------- samsung 278.3498 1983 00:29:38.945 hsbc 302 3020 09:30:17.004 samsung 302 3333 10:30:00.000
更新
使用Update語句的語法如下 -
update column: newValue from table where ….
使用以下語法使用cast函式更新列的格式/資料型別 -
update column:newValue from `table where …
現在讓我們舉一個例子來演示如何使用Update語句 -
q)/Update expression example q)update size:9000 from trade where price > 600 sym price size time ------------------------------------------ msft 743.8592 9000 02:32:17.036 msft 641.7307 9000 01:44:56.936 hsbc 838.2311 9000 00:25:23.210 samsung 278.3498 1983 00:29:38.945 ibm 838.6471 9000 07:24:26.842 hsbc 302 3020 09:30:17.004 apple 730.4 9000 09:15:00.000 samsung 302 3333 10:30:00.000 q)/Update the datatype of a column using the cast function q)meta trade c | t f a ----- | -------- sym | s price| f size | j time | t q)update size:`float$size from trade sym price size time ------------------------------------------ msft 743.8592 3162 02:32:17.036 msft 641.7307 2917 01:44:56.936 hsbc 838.2311 1492 00:25:23.210 samsung 278.3498 1983 00:29:38.945 ibm 838.6471 4006 07:24:26.842 hsbc 302 3020 09:30:17.004 apple 730.4 3012 09:15:00.000 samsung 302 3333 10:30:00.000 q)/ Above statement will not update the size column datatype permanently q)meta trade c | t f a ------ | -------- sym | s price | f size | j time | t q)/to make changes in the trade table permanently, we have do q)update size:`float$size from `trade `trade q)meta trade c | t f a ------ | -------- sym | s price | f size | f time | t
Q 語言 - 動詞 & 副詞
Kdb+ 具有名詞、動詞和副詞。所有資料物件和函式都是名詞。動詞透過減少表示式中方括號和圓括號的數量來增強可讀性。副詞修改二元(2 個引數)函式和動詞以生成新的相關動詞。由副詞生成的函式稱為派生函式或派生動詞。
每個
副詞each,用 ( ` ) 表示,修改二元函式和動詞以應用於列表的專案而不是列表本身。請檢視以下示例 -
q)1, (2 3 5) / Join 1 2 3 5 q)1, '( 2 3 4) / Join each 1 2 1 3 1 4
對於一元函式,有一種Each形式使用關鍵字“each”。例如,
q)reverse ( 1 2 3; "abc") /Reverse a b c 1 2 3 q)each [reverse] (1 2 3; "abc") /Reverse-Each 3 2 1 c b a q)'[reverse] ( 1 2 3; "abc") 3 2 1 c b a
Each-Left 和 Each-Right
對於二元函式,Each 有兩個變體,稱為Each-Left(\:)和Each-Right(/:)。以下示例說明了如何使用它們。
q)x: 9 18 27 36
q)y:10 20 30 40
q)x,y / join
9 18 27 36 10 20 30 40
q)x,'y / each
9 10
18 20
27 30
36 40
q)x: 9 18 27 36
q)y:10 20 30 40
q)x,y / join
9 18 27 36 10 20 30 40
q)x,'y / each, will return a list of pairs
9 10
18 20
27 30
36 40
q)x, \:y / each left, returns a list of each element
/ from x with all of y
9 10 20 30 40
18 10 20 30 40
27 10 20 30 40
36 10 20 30 40
q)x,/:y / each right, returns a list of all the x with
/ each element of y
9 18 27 36 10
9 18 27 36 20
9 18 27 36 30
9 18 27 36 40
q)1 _x / drop the first element
18 27 36
q)-2_y / drop the last two element
10 20
q) / Combine each left and each right to be a
/ cross-product (cartesian product)
q)x,/:\:y
9 10 9 20 9 30 9 40
18 10 18 20 18 30 18 40
27 10 27 20 27 30 27 40
36 10 36 20 36 30 36 40
Q 語言 - 連線
在q語言中,我們根據提供的輸入表和我們所需的連線表型別,有不同型別的連線。連線組合來自兩個表的資料。除了外部索引鍵追溯之外,還有四種連線表的方法 -
- 簡單連線
- Asof 連線
- 左連線
- 聯合連線
在本節中,我們將詳細討論這些連線中的每一個。
簡單連線
簡單連線是最基本的連線型別,用逗號“,”執行。在這種情況下,兩個表必須型別一致,即兩個表具有相同數量的列,順序相同,並且鍵相同。
table1,:table2 / table1 is assigned the value of table2
我們可以對長度相同的表使用逗號連線來進行橫向連線。其中一個表可以在這裡加鍵,
Table1, `Table2
Asof 連線 (aj)
它是功能最強大的連線,用於獲取一個表中欄位的值,作為另一個表中時間點的值。通常用於獲取每次交易時的現行買價和賣價。
通用格式
aj[joinColumns;tbl1;tbl2]
例如,
aj[`sym`time;trade;quote]
示例
q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9)) q)tab2:([]a:(2 3 4);b:(3 4 5); c:( 4 5 6)) q)show aj[`a`b;tab1;tab2] a b d c ------------- 1 2 6 2 3 7 4 3 4 8 5 4 5 9 6
左連線(lj)
它是 aj 的一個特例,其中第二個引數是鍵控表,第一個引數包含右引數鍵的列。
通用格式
table1 lj Keyed-table
示例
q)/Left join- syntax table1 lj table2 or lj[table1;table2] q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9)) q)tab2:([a:(2 3 4);b:(3 4 5)]; c:( 4 5 6)) q)show lj[tab1;tab2] a b d c ------------- 1 2 6 2 3 7 4 3 4 8 5 4 5 9 6
聯合連線 (uj)
它允許建立具有不同模式的兩個表的聯合。它基本上是對簡單連線 ( , ) 的擴充套件。
q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9)) q)tab2:([]a:(2 3 4);b:(3 4 5); c:( 4 5 6)) q)show uj[tab1;tab2] a b d c ------------ 1 2 6 2 3 7 3 4 8 4 5 9 2 3 4 3 4 5 4 5 6
如果您在鍵控表上使用 uj,則主鍵必須匹配。
Q 語言 - 函式
函式型別
函式可以以多種方式分類。在這裡,我們根據它們接受的引數數量和型別以及結果型別對它們進行了分類。函式可以是,
原子 - 引數為原子併產生原子結果
聚合 - 列表中的原子
統一(列表來自列表) - 擴充套件了原子的概念,因為它們適用於列表。引數列表的計數等於結果列表的計數。
其他 - 如果函式不屬於上述類別。
數學中的二元運算在 q 中稱為二元函式;例如,“+”。類似地,一元運算稱為一元函式;例如,“abs”或“floor”。
常用函式
在q程式設計中,有很多函式經常使用。在本節中,我們將瞭解一些常用函式的使用 -
abs
q) abs -9.9 / Absolute value, Negates -ve number & leaves non -ve number 9.9
all
q) all 4 5 0 -4 / Logical AND (numeric min), returns the minimum value 0b
Max (&), Min (|), and Not (!)
q) /And, Or, and Logical Negation q) 1b & 1b / And (Max) 1b q) 1b|0b / Or (Min) 1b q) not 1b /Logical Negate (Not) 0b
asc
q)asc 1 3 5 7 -2 0 4 / Order list ascending, sorted list
/ in ascending order i
s returned
`s#-2 0 1 3 4 5 7
q)/attr - gives the attributes of data, which describe how it's sorted.
`s denotes fully sorted, `u denotes unique and `p and `g are used to
refer to lists with repetition, with `p standing for parted and `g for grouped
avg
q)avg 3 4 5 6 7 / Return average of a list of numeric values 5f q)/Create on trade table q)trade:([]time:3?(.z.Z-200);sym:3?(`ibm`msft`apple);price:3?99.0;size:3?100)
by
q)/ by - Groups rows in a table at given sym q)select sum price by sym from trade / find total price for each sym sym | price ------ | -------- apple | 140.2165 ibm | 16.11385
cols
q)cols trade / Lists columns of a table `time`sym`price`size
count
q)count (til 9) / Count list, count the elements in a list and
/ return a single int value 9
port
q)\p 9999 / assign port number q)/csv - This command allows queries in a browser to be exported to excel by prefixing the query, such as https://:9999/.csv?select from trade where sym =`ibm
cut
q)/ cut - Allows a table or list to be cut at a certain point
q)(1 3 5) cut "abcdefghijkl"
/ the argument is split at 1st, 3rd and 5th letter.
"bc"
"de"
"fghijkl"
q)5 cut "abcdefghijkl" / cut the right arg. Into 5 letters part
/ until its end.
"abcde"
"fghij"
"kl"
刪除
q)/delete - Delete rows/columns from a table
q)delete price from trade
time sym size
---------------------------------------
2009.06.18T06:04:42.919 apple 36
2009.11.14T12:42:34.653 ibm 12
2009.12.27T17:02:11.518 apple 97
Distinct
q)/distinct - Returns the distinct element of a list q)distinct 1 2 3 2 3 4 5 2 1 3 / generate unique set of number 1 2 3 4 5
enlist
q)/enlist - Creates one-item list. q)enlist 37 ,37 q)type 37 / -ve type value -7h q)type enlist 37 / +ve type value 7h
Fill (^)
q)/fill - used with nulls. There are three functions for processing null values. The dyadic function named fill replaces null values in the right argument with the atomic left argument. q)100 ^ 3 4 0N 0N -5 3 4 100 100 -5 q)`Hello^`jack`herry``john` `jack`herry`Hello`john`Hello
Fills
q)/fills - fills in nulls with the previous not null value. q)fills 1 0N 2 0N 0N 2 3 0N -5 0N 1 1 2 2 2 2 3 3 -5 -5
First
q)/first - returns the first atom of a list q)first 1 3 34 5 3 1
Flip
q)/flip - Monadic primitive that applies to lists and associations. It interchange the top two levels of its argument.
q)trade
time sym price size
------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
q)flip trade
time | 2009.06.18T06:04:42.919 2009.11.14T12:42:34.653
2009.12.27T17:02:11.518
sym | apple ibm apple
price | 72.05742 16.11385 68.15909
size | 36 12 97
iasc
q)/iasc - Index ascending, return the indices of the ascended sorted list relative to the input list. q)iasc 5 4 0 3 4 9 2 3 1 4 0 5
Idesc
q)/idesc - Index desceding, return the descended sorted list relative to the input list q)idesc 0 1 3 4 3 2 1 0
in
q)/in - In a list, dyadic function used to query list (on the right-handside) about their contents. q)(2 4) in 1 2 3 10b
insert
q)/insert - Insert statement, upload new data into a table.
q)insert[`trade;((.z.Z);`samsung;48.35;99)],3
q)trade
time sym price size
------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
key
q)/key - three different functions i.e. generate +ve integer number, gives content of a directory or key of a table/dictionary. q)key 9 0 1 2 3 4 5 6 7 8 q)key `:c: `$RECYCLE.BIN`Config.Msi`Documents and Settings`Drivers`Geojit`hiberfil.sys`I..
lower
q)/lower - Convert to lower case and floor
q)lower ("JoHn";`HERRY`SYM)
"john"
`herry`sym
Max and Min (i.e. | and &)
q)/Max and Min / a|b and a&b q)9|7 9 q)9&5 5
null
q)/null - return 1b if the atom is a null else 0b from the argument list q)null 1 3 3 0N 0001b
Peach
q)/peach - Parallel each, allows process across slaves
q)foo peach list1 / function foo applied across the slaves named in list1
'list1
q)foo:{x+27}
q)list1:(0 1 2 3 4)
q)foo peach list1 / function foo applied across the slaves named in list1
27 28 29 30 31
Prev
q)/prev - returns the previous element i.e. pushes list forwards q)prev 0 1 3 4 5 7 0N 0 1 3 4 5
Random( ?)
q)/random - syntax - n?list, gives random sequences of ints and floats q)9?5 0 0 4 0 3 2 2 0 1 q)3?9.9 0.2426823 1.674133 3.901671
Raze
q)/raze - Flattn a list of lists, removes a layer of indexing from a list of lists. for instance:
q)raze (( 12 3 4; 30 0);("hello";7 8); 1 3 4)
12 3 4
30 0
"hello"
7 8
1
3
4
read0
q)/read0 - Read in a text file q)read0 `:c:/q/README.txt / gives the contents of *.txt file
read1
q)/read1 - Read in a q data file q)read1 `:c:/q/t1 0xff016200630b000500000073796d0074696d6500707269636…
reverse
q)/reverse - Reverse a list q)reverse 2 30 29 1 3 4 4 3 1 29 30 2 q)reverse "HelloWorld" "dlroWolleH"
set
q)/set - set value of a variable
q)`x set 9
`x
q)x
9
q)`:c:/q/test12 set trade
`:c:/q/test12
q)get `:c:/q/test12
time sym price size
---------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99
ssr
q)/ssr - String search and replace, syntax - ssr["string";searchstring;replaced-with] q)ssr["HelloWorld";"o";"O"] "HellOWOrld"
string
q)/string - converts to string, converts all types to a string format. q)string (1 2 3; `abc;"XYZ";0b) (,"1";,"2";,"3") "abc" (,"X";,"Y";,"Z") ,"0"
SV
q)/sv - Scalar from vector, performs different tasks dependent on its arguments. It evaluates the base representation of numbers, which allows us to calculate the number of seconds in a month or convert a length from feet and inches to centimeters. q)24 60 60 sv 11 30 49 41449 / number of seconds elapsed in a day at 11:30:49
system
q)/system - allows a system command to be sent, q)system "dir *.py" " Volume in drive C is New Volume" " Volume Serial Number is 8CD2-05B2" "" " Directory of C:\\Users\\myaccount-raj" "" "09/14/2014 06:32 PM 22 hello1.py" " 1 File(s) 22 bytes"
tables
q)/tables - list all tables q)tables ` `s#`tab1`tab2`trade
Til
q)/til - Enumerate q)til 5 0 1 2 3 4
trim
q)/trim - Eliminate string spaces q)trim " John " "John"
vs
q)/vs - Vector from scaler , produces a vector quantity from a scaler quantity q)"|" vs "20150204|msft|20.45" "20150204" "msft" "20.45"
xasc
q)/xasc - Order table ascending, allows a table (right-hand argument) to be sorted such that (left-hand argument) is in ascending order
q)`price xasc trade
time sym price size
----------------------------------------------------------
2009.11.14T12:42:34.653 ibm 16.11385 12
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99
2009.12.27T17:02:11.518 apple 68.15909 97
2009.06.18T06:04:42.919 apple 72.05742 36
xcol
q)/xcol - Renames columns of a table
q)`timeNew`symNew xcol trade
timeNew symNew price size
-------------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99
xcols
q)/xcols - Reorders the columns of a table, q)`size`price xcols trade size price time sym ----------------------------------------------------------- 36 72.05742 2009.06.18T06:04:42.919 apple 12 16.11385 2009.11.14T12:42:34.653 ibm 97 68.15909 2009.12.27T17:02:11.518 apple 99 48.35 2015.04.06T10:03:36.738 samsung 99 48.35 2015.04.06T10:03:47.540 samsung 99 48.35 2015.04.06T10:04:44.844 samsung
xdesc
q)/xdesc - Order table descending, allows tables to be sorted such that the left-hand argument is in descending order.
q)`price xdesc trade
time sym price size
-----------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99
2009.11.14T12:42:34.653 ibm 16.11385 12
xgroup
q)/xgroup - Creates nested table q)`x xgroup ([]x:9 18 9 18 27 9 9;y:10 20 10 20 30 40) 'length q)`x xgroup ([]x:9 18 9 18 27 9 9;y:10 20 10 20 30 40 10) x | y ---- | ----------- 9 | 10 10 40 10 18 | 20 20 27 | ,30
xkey
q)/xkey - Set key on table
q)`sym xkey trade
sym | time price size
--------- | -----------------------------------------------
apple | 2009.06.18T06:04:42.919 72.05742 36
ibm | 2009.11.14T12:42:34.653 16.11385 12
apple | 2009.12.27T17:02:11.518 68.15909 97
samsung | 2015.04.06T10:03:36.738 48.35 99
samsung | 2015.04.06T10:03:47.540 48.35 99
samsung | 2015.04.06T10:04:44.844 48.35 99
系統命令
系統命令控制q環境。它們具有以下形式 -
\cmd [p] where p may be optional
下面討論了一些常用的系統命令 -
\a [名稱空間] – 列出給定名稱空間中的表
q)/Tables in default namespace q)\a ,`trade q)\a .o / table in .o namespace. ,`TI
\b – 檢視依賴項
q)/ views/dependencies q)a:: x+y / global assingment q)b:: x+1 q)\b `s#`a`b
\B – 等待的檢視/依賴項
q)/ Pending views/dependencies q)a::x+1 / a depends on x q)\B / the dependency is pending ' / the dependency is pending q)\B `s#`a`b q)\b `s#`a`b q)b 29 q)a 29 q)\B `symbol$()
\cd – 更改目錄
q)/change directory, \cd [name] q)\cd "C:\\Users\\myaccount-raj" q)\cd ../new-account q)\cd "C:\\Users\\new-account"
\d – 設定當前名稱空間
q)/ sets current namespace \d [namespace] q)\d /default namespace ' q)\d .o /change to .o q.o)\d `.o q.o)\d . / return to default q)key ` /lists namespaces other than .z `q`Q`h`j`o q)\d .john /change to non-existent namespace q.john)\d `.john q.john)\d . q)\d `.
\l – 從 db 載入檔案或目錄
q)/ Load file or directory, \l q)\l test2.q / loading test2.q which is stored in current path. ric | date ex openP closeP MCap ----------- | ------------------------------------------------- JPMORGAN | 2008.05.23 SENSEX 18.30185 17.16319 17876 HSBC | 2002.05.21 NIFTY 2.696749 16.58846 26559 JPMORGAN | 2006.09.07 NIFTY 14.15219 20.05624 14557 HSBC | 2010.10.11 SENSEX 7.394497 25.45859 29366 JPMORGAN | 2007.10.02 SENSEX 1.558085 25.61478 20390 ric | date ex openP closeP MCap ---------- | ------------------------------------------------ INFOSYS | 2003.10.30 DOW 21.2342 7.565652 2375 RELIANCE | 2004.08.12 DOW 12.34132 17.68381 4201 SBIN | 2008.02.14 DOW 1.830857 9.006485 15465 INFOSYS | 2009.06.11 HENSENG 19.47664 12.05208 11143 SBIN | 2010.07.05 DOW 18.55637 10.54082 15873
\p – 埠號
q)/ assign port number, \p q)\p 5001i q)\p 8888 q)\p 8888i
\\ - 從 q 控制檯退出
\\ - exit Exit form q.
Q 語言 - 內建函式
q程式語言有一組豐富且強大的內建函式。內建函式可以是以下型別 -
字串函式 - 以字串作為輸入並返回字串。
聚合函式 - 以列表作為輸入並返回原子。
統一函式 - 獲取列表並返回相同計數的列表。
數學函式 - 獲取數字引數並返回數字引數。
雜項函式 - 除上述提到的所有其他函式。
字串函式
Like - 模式匹配
q)/like is a dyadic, performs pattern matching, return 1b on success else 0b q)"John" like "J??n" 1b q)"John My Name" like "J*" 1b
ltrim - 刪除前導空格
q)/ ltrim - monadic ltrim takes string argument, removes leading blanks q)ltrim " Rick " "Rick "
rtrim - 刪除尾隨空格
q)/rtrim - takes string argument, returns the result of removing trailing blanks q)rtrim " Rick " " Rick"
ss - 字串搜尋
q)/ss - string search, perform pattern matching, same as "like" but return the indices of the matches of the pattern in source. q)"Life is beautiful" ss "i" 1 5 13
trim - 刪除前導和尾隨空格
q)/trim - takes string argument, returns the result of removing leading & trailing blanks q)trim " John " "John"
數學函式
acos - cos 的反函式
q)/acos - inverse of cos, for input between -1 and 1, return float between 0 and pi q)acos 1 0f q)acos -1 3.141593 q)acos 0 1.570796
cor - 給出相關性
q)/cor - the dyadic takes two numeric lists of same count, returns a correlation between the items of the two arguments q)27 18 18 9 0 cor 27 36 45 54 63 -0.9707253
cross - 笛卡爾積
q)/cross - takes atoms or lists as arguments and returns their Cartesian product q)9 18 cross `x`y`z 9 `x 9 `y 9 `z 18 `x 18 `y 18 `z
var - 方差
q)/var - monadic, takes a scaler or numeric list and returns a float equal to the mathematical variance of the items q)var 45 0f q)var 9 18 27 36 101.25
wavg
q)/wavg - dyadic, takes two numeric lists of the same count and returns the average of the second argument weighted by the first argument. q)1 2 3 4 wavg 200 300 400 500 400f
聚合函式
all - & 運算
q)/all - monadic, takes a scaler or list of numeric type and returns the result of & applied across the items. q)all 0b 0b q)all 9 18 27 36 1b q)all 10 20 30 1b
Any - | 運算
q)/any - monadic, takes scaler or list of numeric type and the return the result of | applied across the items q)any 20 30 40 50 1b q)any 20012.02.12 2013.03.11 '20012.02.12
prd - 算術乘積
q)/prd - monadic, takes scaler, list, dictionary or table of numeric type and returns the arithmetic product. q)prd `x`y`z! 10 20 30 6000 q)prd ((1 2; 3 4);(10 20; 30 40)) 10 40 90 160
Sum - 算術和
q)/sum - monadic, takes a scaler, list,dictionary or table of numeric type and returns the arithmetic sum. q)sum 2 3 4 5 6 20 q)sum (1 2; 4 5) 5 7
統一函式
Deltas - 與其前一項的差值。
q)/deltas -takes a scalar, list, dictionary or table and returns the difference of each item from its predecessor. q)deltas 2 3 5 7 9 2 1 2 2 2 q)deltas `x`y`z!9 18 27 x | 9 y | 9 z | 9
fills - 填充空值
q)/fills - takes scalar, list, dictionary or table of numeric type and returns a c copy of the source in which non-null items are propagated forward to fill nulls q)fills 1 0N 2 0N 4 1 1 2 2 4 q)fills `a`b`c`d! 10 0N 30 0N a | 10 b | 10 c | 30 d | 30
maxs - 累積最大值
q)/maxs - takes scalar, list, dictionary or table and returns the cumulative maximum of the source items. q)maxs 1 2 4 3 9 13 2 1 2 4 4 9 13 13 q)maxs `a`b`c`d!9 18 0 36 a | 9 b | 18 c | 18 d | 36
雜項函式
Count - 返回元素的數量
q)/count - returns the number of entities in its argument. q)count 10 30 30 3 q)count (til 9) 9 q)count ([]a:9 18 27;b:1.1 2.2 3.3) 3
Distinct - 返回不同的實體
q)/distinct - monadic, returns the distinct entities in its argument q)distinct 1 2 3 4 2 3 4 5 6 9 1 2 3 4 5 6 9
Except - 第二個引數中不存在的元素。
q)/except - takes a simple list (target) as its first argument and returns a list containing the items of target that are not in its second argument q)1 2 3 4 3 1 except 1 2 3 4 3
fill - 用第一個引數填充空值
q)/fill (^) - takes an atom as its first argument and a list(target) as its second argument and return a list obtained by substituting the first argument for every occurrence of null in target q)42^ 9 18 0N 27 0N 36 9 18 42 27 42 36 q)";"^"Life is Beautiful" "Life;is;Beautiful"
Q 語言 - 查詢
q中的查詢更短、更簡單,並擴充套件了sql的功能。主要的查詢表示式是“select表示式”,它最簡單的形式是提取子表,但它也可以建立新列。
Select 表示式的一般形式如下 -
Select columns by columns from table where conditions
**注意 - by & where短語是可選的,只有“from表示式”是必須的。
通常,語法將是 -
select [a] [by b] from t [where c] update [a] [by b] from t [where c]
q表示式的語法看起來與SQL非常相似,但q表示式簡單而強大。上面q表示式的等效sql表示式如下 -
select [b] [a] from t [where c] [group by b order by b] update t set [a] [where c]
所有子句都在列上執行,因此q可以利用順序。由於Sql查詢不是基於順序的,因此它們無法利用該優勢。
與相應的sql相比,q關係查詢的大小通常要小得多。有序和函式式查詢可以完成sql中難以完成的事情。
在歷史資料庫中,where子句的順序非常重要,因為它會影響查詢的效能。partition變數(日期/月/日)始終放在第一位,然後是排序和索引的列(通常是sym列)。
例如,
select from table where date in d, sym in s
比
select from table where sym in s, date in d
基本查詢
讓我們在記事本中編寫一個查詢指令碼(如下所示),儲存(為*.q),然後載入它。
sym:asc`AIG`CITI`CSCO`IBM`MSFT;
ex:"NASDAQ"
dst:`$":c:/q/test/data/"; /database destination
@[dst;`sym;:;sym];
n:1000000;
trade:([]sym:n?`sym;time:10:30:00.0+til
n;price:n?3.3e;size:n?9;ex:n?ex);
quote:([]sym:n?`sym;time:10:30:00.0+til
n;bid:n?3.3e;ask:n?3.3e;bsize:n?9;asize:n?9;ex:n?ex);
{@[;`sym;`p#]`sym xasc x}each`trade`quote;
d:2014.08.07 2014.08.08 2014.08.09 2014.08.10 2014.08.11; /Date vector can also be changed by the user
dt:{[d;t].[dst;(`$string d;t;`);:;value t]};
d dt/:\:`trade`quote;
Note: Once you run this query, two folders .i.e. "test" and "data" will be created under "c:/q/", and date partition data can be seen inside data folder.
帶約束條件的查詢
* 表示 HDB 查詢
選擇所有 IBM 交易
select from trade where sym in `IBM
*選擇某一天的所有 IBM 交易
thisday: 2014.08.11 select from trade where date=thisday,sym=`IBM
選擇價格 > 100 的所有 IBM 交易
select from trade where sym=`IBM, price > 100.0
選擇價格小於或等於 100 的所有 IBM 交易
select from trade where sym=`IBM,not price > 100.0
*選擇某一天上午 10.30 到 10.40 之間的所有 IBM 交易
thisday: 2014.08.11 select from trade where date = thisday, sym = `IBM, time > 10:30:00.000,time < 10:40:00.000
按價格升序選擇所有 IBM 交易
`price xasc select from trade where sym =`IBM
*在特定時間範圍內按價格降序選擇所有 IBM 交易
`price xdesc select from trade where date within 2014.08.07 2014.08.11, sym =`IBM
複合排序 - 按 sym 升序排序,然後按價格降序排序結果
`sym xasc `price xdesc select from trade where date = 2014.08.07,size = 5
選擇所有 IBM 或 MSFT 交易
select from trade where sym in `IBM`MSFT
*計算特定時間範圍內所有符號的計數(升序)
`numsym xasc select numsym: count i by sym from trade where date within 2014.08.07 2014.08.11
*計算特定時間範圍內所有符號的計數(降序)
`numsym xdesc select numsym: count i by sym from trade where date within 2014.08.07 2014.08.11
* IBM 股票在特定時間範圍內的最高價格是多少,以及何時首次出現?
select time,ask from quote where date within 2014.08.07 2014.08.11, sym =`IBM, ask = exec first ask from select max ask from quote where sym =`IBM
選擇每個 sym 在每小時區間內的最後價格
select last price by hour:time.hh, sym from trade
帶聚合的查詢
* 計算所有符號的 vwap(成交量加權平均價格)
select vwap:size wavg price by sym from trade
* 統計某個月的記錄數(以百萬計)
(select trade:1e-6*count i by date.dd from trade where date.month=2014.08m) + select quote:1e-6*count i by date.dd from quote where date.month=2014.08m
* HLOC - 某個月 CSCO 的每日最高價、最低價、開盤價和收盤價
select high:max price,low:min price,open:first price,close:last price by date.dd from trade where date.month=2014.08m,sym =`CSCO
* 某個月 CSCO 的每日 Vwap
select vwap:size wavg price by date.dd from trade where date.month = 2014.08m ,sym = `CSCO
* 計算 AIG 價格的每小時均值、方差和標準差
select mean:avg price, variance:var price, stdDev:dev price by date, hour:time.hh from trade where sym = `AIG
選擇每小時區間內的價格範圍
select range:max[price] – min price by date,sym,hour:time.hh from trade
* 某個月 CSCO 的每日價差(平均買價-賣價)
select spread:avg bid-ask by date.dd from quote where date.month = 2014.08m, sym = `CSCO
* 某個月所有符號的每日交易價值
select dtv:sum size by date,sym from trade where date.month = 2014.08m
提取 CSCO 的 5 分鐘 vwap
select size wavg price by 5 xbar time.minute from trade where sym = `CSCO
* 提取 CSCO 的 10 分鐘 K 線
select high:max price,low:min price,close:last price by date, 10 xbar time.minute from trade where sym = `CSCO
* 查詢 CSCO 價格在某一天超過上次價格 100 個基點 (100e-4) 的時間
select time from trade where date = 2014.08.11,sym = `CSCO,price > 1.01*last price
* 資料庫中最後一天 MSFT 的 1 分鐘間隔的全天價格和成交量
select last price,last size by time.minute from trade where date = last date, sym = `MSFT
Q 語言 - 程序間通訊
KDB+ 允許一個程序透過程序間通訊與另一個程序通訊。Kdb+ 程序可以連線到同一臺計算機、同一網路甚至遠端的任何其他 kdb+。我們只需要指定埠,然後客戶端就可以與該埠通訊。任何q程序都可以與任何其他q程序通訊,只要它在網路上可訪問並且正在偵聽連線。
伺服器程序偵聽連線並處理任何請求
客戶端程序啟動連線並將要執行的命令傳送到伺服器
客戶端和伺服器可以在同一臺機器上或不同的機器上。一個程序可以同時是客戶端和伺服器。
通訊可以是,
同步(等待返回結果)
非同步(無需等待且不返回結果)
初始化伺服器
透過指定要偵聽的埠來初始化q伺服器,
q –p 5001 / command line \p 5001 / session command
通訊控制代碼
通訊控制代碼是一個以“:”開頭的符號,其形式為 -
`:[server]:port-number
示例
`::5001 / server and client on same machine `:jack:5001 / server on machine jack `:192.168.0.156 / server on specific IP address `:www.myfx.com:5001 / server at www.myfx.com
要開始連線,我們使用函式“hopen”,它返回一個整數連線控制代碼。此控制代碼用於所有後續的客戶端請求。例如 -
q)h:hopen `::5001 q)h"til 5" 0 1 2 3 4 q)hclose h
同步和非同步訊息
一旦我們有了控制代碼,我們就可以同步或非同步地傳送訊息。
同步訊息 - 傳送訊息後,它會等待並返回結果。其格式如下 -
handle “message”
非同步訊息 - 傳送訊息後,立即開始處理下一條語句,無需等待並返回結果。其格式如下 -
neg[handle] “message”
需要響應的訊息,例如函式呼叫或 select 語句,通常使用同步形式;而不需要返回輸出的訊息,例如將更新插入表中,將是非同步的。
Q 語言 - 訊息處理器
當一個q程序透過程序間通訊連線到另一個q程序時,它由訊息處理器處理。這些訊息處理器具有預設行為。例如,在同步訊息處理的情況下,處理器返回查詢的值。在這種情況下,同步處理器是.z.pg,我們可以根據需要覆蓋它。
Kdb+ 程序有幾個預定義的訊息處理器。訊息處理器對於配置資料庫非常重要。一些用法包括 -
日誌記錄 - 記錄傳入的訊息(在發生任何致命錯誤時很有用),
安全性 - 根據使用者名稱/IP 地址允許/拒絕訪問資料庫、某些函式呼叫等。它有助於僅向授權的訂閱者提供訪問許可權。
處理來自其他程序的連線/斷開連線。
預定義的訊息處理器
下面討論一些預定義的訊息處理器。
.z.pg
它是一個同步訊息處理器(程序獲取)。每當在 kdb+ 例項上接收到同步訊息時,此函式都會自動呼叫。
引數是要執行的字串/函式呼叫,即傳遞的訊息。預設情況下,其定義如下 -
.z.pg: {value x} / simply execute the message
received but we can overwrite it to
give any customized result.
.z.pg : {handle::.z.w;value x} / this will store the remote handle
.z.pg : {show .z.w;value x} / this will show the remote handle
.z.ps
它是一個非同步訊息處理器(程序設定)。它是非同步訊息的等效處理器。引數是要執行的字串/函式呼叫。預設情況下,其定義為,
.z.pg : {value x} / Can be overriden for a customized action.
以下是非同步訊息的自定義訊息處理器,其中我們使用了受保護的執行,
.z.pg: {@[value; x; errhandler x]}
這裡errhandler是發生任何意外錯誤時使用的函式。
.z.po[]
它是一個連線開啟處理器(程序開啟)。當遠端程序開啟連線時執行。要檢視連線到程序時開啟的控制代碼,我們可以將 .z.po 定義為,
.z.po : {Show “Connection opened by” , string h: .z.h}
.z.pc[]
它是一個關閉連線處理器(程序關閉)。當連線關閉時呼叫。我們可以建立自己的關閉處理器,它可以將全域性連線控制代碼重置為 0,併發出命令設定計時器每 3 秒(3000 毫秒)觸發(執行)。
.z.pc : { h::0; value “\\t 3000”}
計時器處理器 (.z.ts) 嘗試重新開啟連線。成功後,它會關閉計時器。
.z.ts : { h:: hopen `::5001; if [h>0; value “\\t 0”] }
.z.pi[]
PI 代表程序輸入。它用於任何型別的輸入。它可以用於處理控制檯輸入或遠端客戶端輸入。使用 .z.pi[],可以驗證控制檯輸入或替換預設顯示。此外,它可以用於任何型別的日誌記錄操作。
q).z.pi
'.z.pi
q).z.pi:{">", .Q.s value x}
q)5+4
>9
q)30+42
>72
q)30*2
>60
q)\x .z.pi
>q)
q)5+4
9
.z.pw
它是一個驗證連線處理器(使用者身份驗證)。當連線到 kdb+ 會話時,它會新增一個額外的回撥。它在 –u/-U 檢查之後和 .z.po(埠開啟)之前呼叫。
.z.pw : {[user_id;passwd] 1b}
輸入是userid(符號)和password(文字)。
Q 語言 - 屬性
列表、字典或表的列可以應用屬性。屬性對列表施加某些屬性。某些屬性在修改時可能會消失。
屬性型別
排序(`s#)
`s# 表示列表按升序排序。如果列表由 asc(或 xasc)顯式排序,則列表將自動設定排序屬性。
q)L1: asc 40 30 20 50 9 4 q)L1 `s#4 9 20 30 40 50
已知排序的列表也可以顯式設定屬性。Q 將檢查列表是否已排序,如果不是,則會丟擲s-fail錯誤。
q)L2:30 40 24 30 2 q)`s#L2 's-fail
在未排序的追加操作後,排序屬性將丟失。
分割槽(`p#)
`p# 表示列表已分割槽,並且相同的項連續儲存。
範圍是int或時間型別,具有底層 int 值,例如年、月、日等。您還可以對提供的符號進行分割槽,前提是它已列舉。
應用分割槽屬性會建立一個索引字典,該字典將每個唯一的輸出值對映到其第一次出現的的位置。當列表被分割槽時,查詢速度快得多,因為線性搜尋被雜湊表查詢取代。
q)L:`p# 99 88 77 1 2 3 q)L `p#99 88 77 1 2 3 q)L,:3 q)L 99 88 77 1 2 3 3
注意 -
分割槽屬性不會在列表上的操作下保留,即使操作保留了分割槽。
當實體數量達到十億並且大部分分割槽都很大時,即存在大量重複時,應考慮分割槽屬性。
分組(`g#)
`g# 表示列表已分組。構建並維護一個內部字典,該字典將每個唯一項對映到其每個索引,需要大量的儲存空間。對於長度為L、包含u個唯一項(大小為s)的列表,這將為(L × 4) + (u × s)位元組。
當無法對列表的結構做出其他假設時,可以將分組應用於列表。
該屬性可以應用於任何型別的列表。它在追加時維護,但在刪除時丟失。
q)L: `g# 1 2 3 4 5 4 2 3 1 4 5 6 q)L `g#1 2 3 4 5 4 2 3 1 4 5 6 q)L,:9 q)L `g#1 2 3 4 5 4 2 3 1 4 5 6 9 q)L _:2 q)L 1 2 4 5 4 2 3 1 4 5 6 9
唯一(`#u)
將唯一屬性(`u#)應用於列表表示列表的項是不同的。知道列表的元素是唯一的,可以大大加快distinct的速度,並允許q儘早執行一些比較。
當列表被標記為唯一時,會為列表中的每個項建立一個內部雜湊對映。列表上的操作必須保持唯一性,否則屬性將丟失。
q)LU:`u#`MSFT`SAMSUNG`APPLE q)LU `u#`MSFT`SAMSUNG`APPLE q)LU,:`IBM /Uniqueness preserved q)LU `u#`MSFT`SAMSUNG`APPLE`IBM q)LU,:`SAMSUNG / Attribute lost q)LU `MSFT`SAMSUNG`APPLE`IBM`SAMSUNG
注意 -
`u# 在保留唯一性的連線上保留。在刪除和非唯一連線上丟失。
對`u#列表的搜尋透過雜湊函式完成。
刪除屬性
可以透過應用`#刪除屬性。
應用屬性
應用屬性的三種格式為 -
L: `s# 14 2 3 3 9/ 在列表建立期間指定
@[ `.; `L ; `s#]/ 函式應用,即應用於變數列表 L
/ 在預設名稱空間(即`。)中應用
/ 排序`s#屬性
更新`s#time 來自`tab
/ 更新表(tab)以應用
/ 屬性。
讓我們用示例應用以上三種不同的格式。
q)/ set the attribute during creation
q)L:`s# 3 4 9 10 23 84 90
q)/apply the attribute to existing list data
q)L1: 9 18 27 36 42 54
q)@[`.;`L1;`s#]
`.
q)L1 / check
`s#9 18 27 36 42 54
q)@[`.;`L1;`#] / clear attribute
`.
q)L1
9 18 27 36 42 54
q)/update a table to apply the attribute
q)t: ([] sym:`ibm`msft`samsung; mcap:9000 18000 27000)
q)t:([]time:09:00 09:30 10:00t;sym:`ibm`msft`samsung; mcap:9000 18000 27000)
q)t
time sym mcap
---------------------------------
09:00:00.000 ibm 9000
09:30:00.000 msft 18000
10:00:00.000 samsung 27000
q)update `s#time from `t
`t
q)meta t / check it was applied
c | t f a
------ | -----
time | t s
sym | s
mcap | j
Above we can see that the attribute column in meta table results shows the time column is sorted (`s#).
Q 語言 - 函式式查詢
函式式(動態)查詢允許將列名指定為符號,用於典型的 q-sql select/exec/delete 列。當我們想要動態指定列名時,它非常方便。
函式式形式為 -
?[t;c;b;a] / for select ![t;c;b;a] / for update
其中
t是表;
a是聚合的字典;
b是by短語;以及
c是約束列表。
注意 -
a、b和c中的所有q實體都必須按名稱引用,即包含實體名稱的符號。
select 和 update 的語法形式由q直譯器解析成其等效的函式式形式,因此兩種形式之間沒有效能差異。
函式式 select
以下程式碼塊顯示瞭如何使用函式式 select -
q)t:([]n:`ibm`msft`samsung`apple;p:40 38 45 54)
q)t
n p
-------------------
ibm 40
msft 38
samsung 45
apple 54
q)select m:max p,s:sum p by name:n from t where p>36, n in `ibm`msft`apple
name | m s
------ | ---------
apple | 54 54
ibm | 40 40
msft | 38 38
示例 1
讓我們從最簡單的案例開始,“select from t”的函式式版本將如下所示 -
q)?[t;();0b;()] / select from t
n p
-----------------
ibm 40
msft 38
samsung 45
apple 54
示例 2
在以下示例中,我們使用 enlist 函式建立單例以確保適當的實體是列表。
q)wherecon: enlist (>;`p;40)
q)?[`t;wherecon;0b;()] / select from t where p > 40
n p
----------------
samsung 45
apple 54
示例 3
q)groupby: enlist[`p] ! enlist `p q)selcols: enlist [`n]!enlist `n q)?[ `t;(); groupby;selcols] / select n by p from t p | n ----- | ------- 38 | msft 40 | ibm 45 | samsung 54 | apple
函式式 Exec
exec 的函式式形式是select的簡化形式。
q)?[t;();();`n] / exec n from t (functional form of exec) `ibm`msft`samsung`apple q)?[t;();`n;`p] / exec p by n from t (functional exec) apple | 54 ibm | 40 msft | 38 samsung | 45
函式式 Update
update 的函式式形式與select完全類似。在以下示例中,使用 enlist 是為了建立單例,以確保輸入實體是列表。
q)c:enlist (>;`p;0) q)b: (enlist `n)!enlist `n q)a: (enlist `p) ! enlist (max;`p) q)![t;c;b;a] n p ------------- ibm 40 msft 38 samsung 45 apple 54
函式式 delete
函式式 delete 是函式式 update 的簡化形式。其語法如下 -
![t;c;0b;a] / t is a table, c is a list of where constraints, a is a
/ list of column names
現在讓我們舉一個例子來展示函式式 delete 如何工作 -
q)![t; enlist (=;`p; 40); 0b;`symbol$()]
/ delete from t where p = 40
n p
---------------
msft 38
samsung 45
apple 54
Q 語言 - 表格運算
在本章中,我們將學習如何操作字典,然後操作表。讓我們從字典開始 -
q)d:`u`v`x`y`z! 9 18 27 36 45 / Creating a dictionary d q)/ key of this dictionary (d) is given by q)key d `u`v`x`y`z q)/and the value by q)value d 9 18 27 36 45 q)/a specific value q)d`x 27 q)d[`x] 27 q)/values can be manipulated by using the arithmetic operator +-*% as, q)45 + d[`x`y] 72 81
如果需要修改字典值,則修改公式可以為 -
q)@[`d;`z;*;9]
`d
q)d
u | 9
v | 18
x | 27
y | 36
q)/Example, table tab
q)tab:([]sym:`;time:0#0nt;price:0n;size:0N)
q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT
q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)]
0 1 2 3 4 5 6 7 8 9
q)`time xasc `tab
`tab
q)/ to get particular column from table tab
q)tab[`size]
12 10 1 90 73 90 43 90 84 63
q)tab[`size]+9
21 19 10 99 82 99 52 99 93 72
z | 405
q)/Example table tab
q)tab:([]sym:`;time:0#0nt;price:0n;size:0N)
q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT
q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)]
0 1 2 3 4 5 6 7 8 9
q)`time xasc `tab
`tab
q)/ to get particular column from table tab
q)tab[`size]
12 10 1 90 73 90 43 90 84 63
q)tab[`size]+9
21 19 10 99 82 99 52 99 93 72
q)/Example table tab
q)tab:([]sym:`;time:0#0nt;price:0n;size:0N)
q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT
q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)]
0 1 2 3 4 5 6 7 8 9
q)`time xasc `tab
`tab
q)/ to get particular column from table tab
q)tab[`size]
12 10 1 90 73 90 43 90 84 63
q)tab[`size]+9
21 19 10 99 82 99 52 99 93 72
q)/We can also use the @ amend too
q)@[tab;`price;-;2]
sym time price size
--------------------------------------------
APPLE 11:16:39.779 6.388858 12
MSFT 11:16:39.779 17.59907 10
IBM 11:16:39.779 35.5638 1
SAMSUNG 11:16:39.779 59.37452 90
APPLE 11:16:39.779 50.94808 73
SAMSUNG 11:16:39.779 67.16099 90
APPLE 11:16:39.779 20.96615 43
SAMSUNG 11:16:39.779 67.19531 90
IBM 11:16:39.779 45.07883 84
IBM 11:16:39.779 61.46716 63
q)/if the table is keyed
q)tab1:`sym xkey tab[0 1 2 3 4]
q)tab1
sym | time price size
--------- | ----------------------------------
APPLE | 11:16:39.779 8.388858 12
MSFT | 11:16:39.779 19.59907 10
IBM | 11:16:39.779 37.5638 1
SAMSUNG | 11:16:39.779 61.37452 90
APPLE | 11:16:39.779 52.94808 73
q)/To work on specific column, try this
q){tab1[x]`size} each sym
1 90 12 10
q)(0!tab1)`size
12 10 1 90 73
q)/once we got unkeyed table, manipulation is easy
q)2+ (0!tab1)`size
14 12 3 92 75
Q 語言 - 磁碟上的表格
硬碟上的資料(也稱為歷史資料庫)可以儲存為三種不同的格式 - 平檔案、擴充套件表和分割槽表。在這裡,我們將學習如何使用這三種格式儲存資料。
平檔案
平檔案完全載入到記憶體中,因此其大小(記憶體佔用)應該很小。表完全儲存在磁碟上的一個檔案中(因此大小很重要)。
用於操作這些表的函式是set/get -
`:path_to_file/filename set tablename
讓我們舉一個例子來演示它是如何工作的 -
q)tables `. `s#`t`tab`tab1 q)`:c:/q/w32/tab1_test set tab1 `:c:/q/w32/tab1_test
在 Windows 環境中,平檔案儲存在以下位置 - C:\q\w32
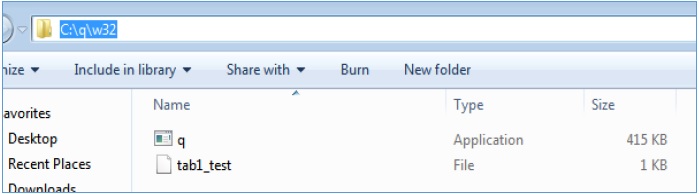
從磁碟(歷史資料庫)獲取平檔案,並使用get命令,如下所示 -
q)tab2: get `:c:/q/w32/tab1_test q)tab2 sym | time price size --------- | ------------------------------- APPLE | 11:16:39.779 8.388858 12 MSFT | 11:16:39.779 19.59907 10 IBM | 11:16:39.779 37.5638 1 SAMSUNG | 11:16:39.779 61.37452 90 APPLE | 11:16:39.779 52.94808 73
建立了一個新表tab2,其內容儲存在tab1_test檔案中。
擴充套件表
如果表中包含太多列,則我們將此類表儲存為擴充套件格式,即我們將它們儲存在磁碟上的目錄中。在目錄內部,每列都儲存在與列名相同的名稱下的單獨檔案中。每列都作為對應型別的列表儲存在 kdb+ 二進位制檔案中。
當我們必須經常訪問其許多列中的一些列時,將表儲存為擴充套件格式非常有用。擴充套件表目錄包含.d二進位制檔案,其中包含列的順序。
與平檔案非常類似,可以使用set命令將表儲存為擴充套件格式。要將表儲存為擴充套件格式,檔案路徑應以反斜槓結尾 -
`:path_to_filename/filename/ set tablename
要讀取擴充套件表,我們可以使用get函式 -
tablename: get `:path_to_file/filename
注意 - 要將表儲存為擴充套件格式,它應該是不帶鍵且已列舉的。
在 Windows 環境中,您的檔案結構將如下所示 -

分割槽表
分割槽表提供了一種有效的方法來管理包含大量資料的龐大表。分割槽表是分佈在更多分割槽(目錄)中的擴充套件表。
在每個分割槽內部,表將有自己的目錄,其結構為擴充套件表。可以按天/月/年劃分表,以便最佳化對其內容的訪問。
要獲取分割槽表的內容,請使用以下程式碼塊 -
q)get `:c:/q/data/2000.01.13 // “get” command used, sample folder quote| +`sym`time`bid`ask`bsize`asize`ex!(`p#`sym!0 0 0 0 0 0 0 0 0 0 0 0 0 0…. trade| +`sym`time`price`size`ex!(`p#`sym!0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ….
讓我們嘗試獲取交易表的內容 -
q)get `:c:/q/data/2000.01.13/trade
sym time price size ex
--------------------------------------------------
0 09:30:00.496 0.4092016 7 T
0 09:30:00.501 1.428629 4 N
0 09:30:00.707 0.5647834 6 T
0 09:30:00.781 1.590509 5 T
0 09:30:00.848 2.242627 3 A
0 09:30:00.860 2.277041 8 T
0 09:30:00.931 0.8044885 8 A
0 09:30:01.197 1.344031 2 A
0 09:30:01.337 1.875 3 A
0 09:30:01.399 2.187723 7 A
注意 - 分割槽模式適用於每天有數百萬條記錄的表(即時間序列資料)
Sym 檔案
sym 檔案是一個 kdb+ 二進位制檔案,包含來自所有擴充套件表和分割槽表的所有符號的列表。可以使用以下命令讀取,
get `:sym
par.txt 檔案(可選)
這是一個配置檔案,用於分割槽分佈在多個目錄/磁碟驅動器上的情況,幷包含磁碟分割槽的路徑。
Q 語言 - 維護函式
.Q.en
.Q.en是一個二元函式,它透過列舉符號列來幫助擴充套件表。當我們處理歷史資料庫(擴充套件表、分割槽表等)時,它特別有用。 -
.Q.en[`:directory;table]
其中directory是歷史資料庫的主目錄,其中sym 檔案位於其中,table是要列舉的表。
不需要手動列舉表以將其儲存為擴充套件表,因為這將由 -
.Q.en[`:directory_where_symbol_file_stored]table_name
.Q.dpft
.Q.dpft函式有助於建立分割槽和分段表。它是.Q.en的高階形式,因為它不僅擴充套件了表,還建立了一個分割槽表。
.Q.dpft 函式使用了四個引數 -
我們要建立分割槽的資料庫的符號檔案控制代碼,
我們將要對錶進行分割槽的q資料值,
將應用`p#`屬性的欄位名稱(通常為`sym`),以及
表名。
讓我們看一個例子來了解它是如何工作的 -
q)tab:([]sym:5?`msft`hsbc`samsung`ibm;time:5?(09:30:30);price:5?30.25) q).Q.dpft[`:c:/q/;2014.08.24;`sym;`tab] `tab q)delete tab from ` 'type q)delete tab from `/ 'type q)delete tab from . 'type q)delete tab from `. `. q)tab 'tab
我們已從記憶體中刪除了表tab。現在讓我們從資料庫中載入它
q)\l c:/q/2014.08.24/ q)\a ,`tab q)tab sym time price ------------------------------- hsbc 07:38:13 15.64201 hsbc 07:21:05 5.387037 msft 06:16:58 11.88076 msft 08:09:26 12.30159 samsung 04:57:56 15.60838
.Q.chk
.Q.chk是一個一元函式,其單個引數是根目錄的符號檔案控制代碼。它透過檢查根目錄中的每個分割槽子目錄,在必要時建立分割槽中的空表。
.Q.chk `:directory
其中directory是歷史資料庫的主目錄。